Transformer優化及其在蘋果病蟲命名實體識別中的應用
2023-06-20 04:51:52聶炎明黃鋁文
農業機械學報 2023年6期
蒲 攀 張 越 劉 勇 聶炎明 黃鋁文,2
(1.西北農林科技大學信息工程學院, 陜西楊凌 712100; 2.農業農村部農業物聯網重點實驗室, 陜西楊凌 712100)
0 引言
我國是世界第一大蘋果生產國[1],果業病蟲害問題對我國蘋果產業影響顯著,進而直接關系到國家和從業者的經濟收益提升。基于知識圖譜的問答系統通過對實體間關系描述能夠幫助蘋果種植人員快速準確獲得病蟲管理專業知識,命名實體識別作為一種智能化實體抽取方法,是構建高質量蘋果知識圖譜的關鍵環節。因此,如何準確識別出蘋果病蟲領域相關實體對于蘋果種植信息化發展具有重要作用。
近年來,命名實體識別技術被廣泛應用在農業[2]、醫學[3]等領域,文獻[4]通過融合ALBERT與規則,針對小麥病蟲害16類實體進行識別,其F1值達到94.97%;文獻[5]提出基于多核的卷積神經網絡,對水產醫學領域動物名稱、發病部位、病原體等6項實體進行識別,其F1值達到88.48%。雖然已開展了豐富的相關研究工作,然而在現有的農業命名實體識別的研究中仍存在以下問題:對沒有明顯邊界特征的詞匯識別率較低,如文獻[6-7]中對于病原的識別F1值僅為88%和81.48%;現有研究中常用BiLSTM來捕捉文本長距離依賴信息,但當文本距離過長時,其獲取長距離依賴信息的能力會有所下降;對蘋果病蟲害實體識別方面的研究較少,同時缺乏公開權威的數據集,文獻[8]構建了蘋果病蟲相關的ApdCNER語料庫,提出將字典和相似詞匯合并到基于字符的模型中,解決實體類別分布不均、別名和稀有實體識別困難的問題,其F1值盡管達到92.14%,但是該方法需要依靠專家手動構建領域字典,容易對一些實體產生遺漏。此外,不同的人對一些相同實體可能也存在不一樣的認識標準,進而字典構建的質量將直接影響模型的識別性能。
Transformer可以實現并行化計算,同時處理長序列樣本,常用于自然語言處理中的機器翻譯[9]、文本生成[10]等領域。但是由于文本信息中不同位置的語義信息差別,其內部的絕對位置編碼不能很好地表征位置信息,進而對中文語義信息的提取造成了困難。國內外學者對Transformer的文本性能優化做出了一系列改進。在較長序列建模方面,文獻[11]引入段級遞歸,將絕對位置編碼改為相對位置編碼,提出了Transfortmer-XL模型。為降低文本分類復雜性,文獻[12]使用星型拓撲代替全連通的注意力連接,提出了Star Transformer模型。在命名實體識別領域,文獻[13]通過改進的相對位置編碼,使用非縮放的點乘注意力,提出TENER模型。
為提高蘋果生產領域實體識別的準確性,本文基于以上研究,通過融合文本的位置特征與語義特征,實現一種新的Transformer優化模型。該模型通過結合字向量與詞向量以豐富語義信息,平均集成BiLSTM和Transformer,并引入具有方向和距離感知的注意力機制,結合文本上下文依賴特征和位置特征,最后通過條件隨機場(Conditional random fields, CRF)得到最優預測序列。
1 材料與方法
1.1 數據來源與標注
實驗數據來源于中國農化招商網(http:∥www.1988.tv/bch/list-4.html)爬取的農業知識,在西北農林科技大學國家級蘋果試驗示范站的植保和栽培專家團隊指導和協助下,人工對所爬取數據進行去空格、空行及特殊符號處理,去除重復數據和無效數據。綜合《中國蘋果病害病原菌物名錄》電子版數據,建立蘋果病蟲知識數據集,其中包含3 928個病蟲相關實體。
本文采用“BIO”的標注方式進行實體標注,其中,B標注實體名稱的開始,I標注實體名稱的內部信息,O標注語料中的非實體部分。實體名稱共包括DIS、PES、NAM、PAR、MED、CAU共6種,DIS表示蘋果病害名稱,PES表示蘋果蟲害名稱,NAM表示蘋果病蟲害的別稱,PAR表示為害部位名稱,MED表示防治藥劑名稱,CAU表示病原名稱。將B、I、O三元組與實體名稱進行結合,形成標簽,可得B-DIS、B-PES、B-NAM、B-PAR、B-MED、B-CAU、I-DIS、I-PES、I-NAM、I-PAR、I-MED、I-CAU、O共計13種實體標簽,并以8∶1∶1將數據集分為訓練集、測試集和驗證集,數據集劃分如表1所示。蘋果樹腐爛病是我國西北地區蘋果樹常發病害,以蘋果樹腐爛病為例,依據此標簽進行數據標注,標注示例如圖1所示。
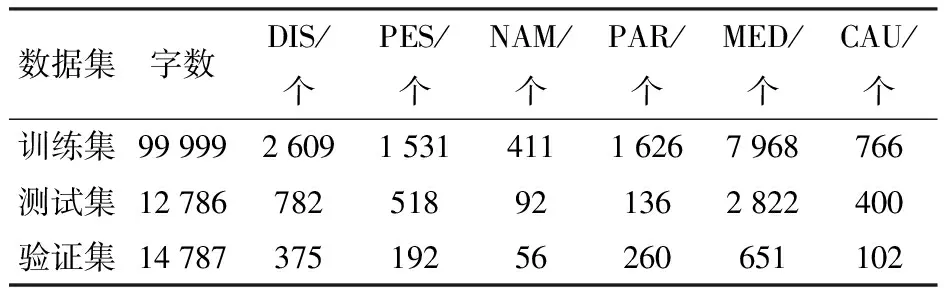
表1 蘋果知識數據集Tab.1 Dataset of apple knowledge
1.2 特征分析
與通用語料相比,蘋果病蟲領域內的實體名稱在結構和專業性等方面有明顯自身特點,具體體現為以下4方面:
(1)構成成分多。蘋果病蟲領域的實體命名除了單純的文字外,還常由數字、特殊符號等多種符號構成,如藥劑名稱“蘇脲1號”、“多菌靈·異菌脲懸浮劑”等。
(2)生僻字較多。在藥劑實體和病原實體中常出現生僻字,如藥劑“噻霉酮”,病原“河口槭膠銹菌”,從而造成模型在識別上的困難。
(3)嵌套實體較常見。在藥劑名稱中常出現由多個子實體構成的實體,如“阿維菌素·噠螨靈乳油”易被拆分為“阿維菌素”“噠螨靈”“乳油”,容易干擾模型判斷。
(4)一詞多義現象較多存在。與其他農業作物病蟲害實體不同的是,在中文文本中,“蘋果”具有水果名稱和商品品牌(手機、服裝)多種含義,在蘋果病蟲領域,“蘋果”一詞出現在不同位置,代表著不同標簽。如“蘋果”在“蘋果褐斑病”中的正確標簽為“B-DIS I-DIS”,在病原實體“蘋果星殼孢”中的正確標簽應為“B-CAU I-CAU”,但其單獨出現時又不是病蟲相關實體,其具體標簽由上下文語義共同決定,這給模型提取上下文關系帶來難度。
2 模型框架
本文所提模型的整體結構包含嵌入層、Transformer層、BiLSTM層、特征融合層和CRF層5部分,其基本構成如圖2所示。其中,x1、x2、x3、x4、x5、x6為嵌入層輸出;LSTM為長短時記憶網絡;BiLSTM為雙向長短時記憶網絡;Multi-Head Attention為多頭注意力機制;Add&Norm為殘差和標準化;Feed Forward為前饋神經網絡;CRF為條件隨機場。
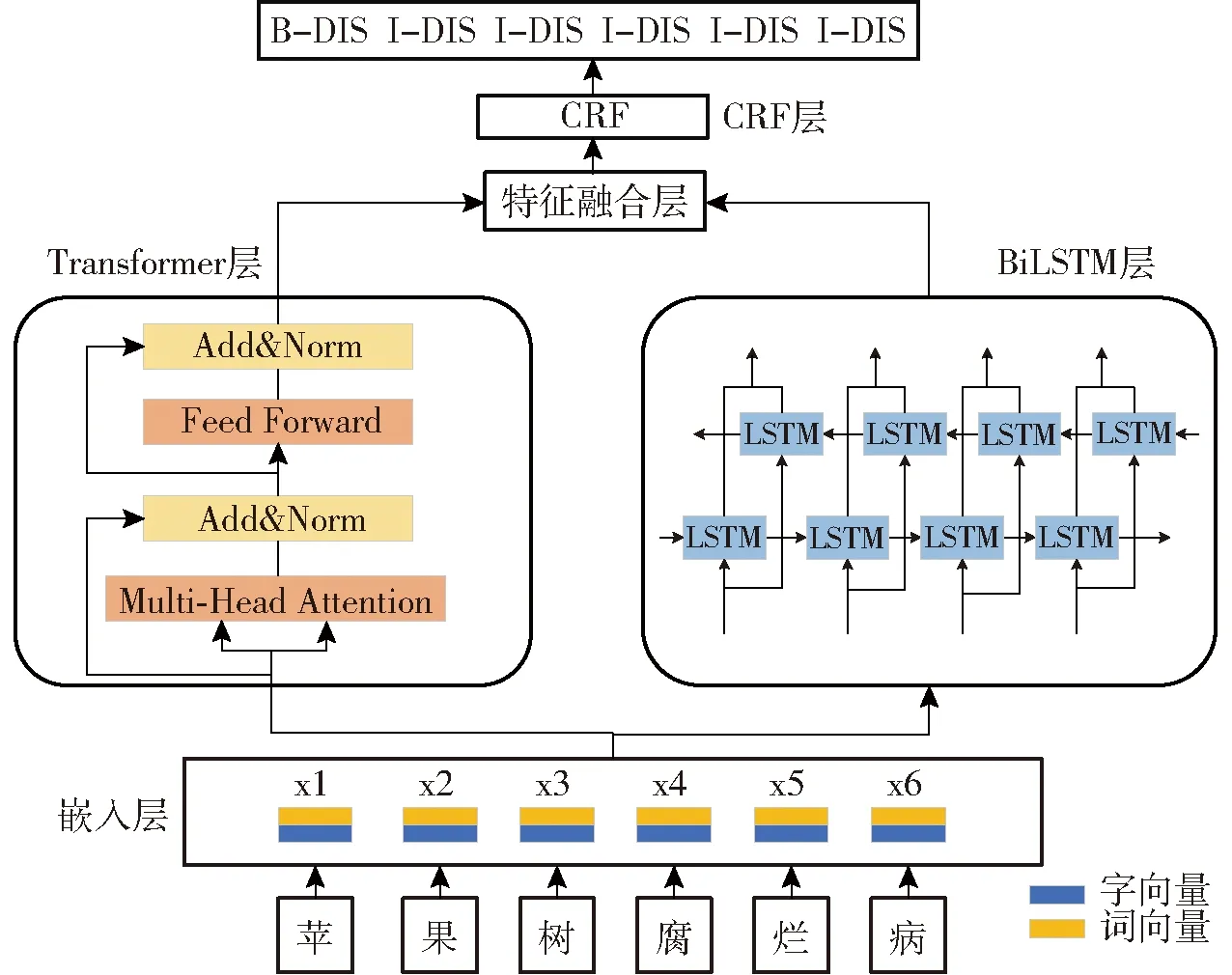
圖2 模型結構Fig.2 Model structure
2.1 嵌入層
由于中文分詞存在錯誤拆分的現象[7],如病害名稱“斑點落葉病”的分詞結果為“斑點/落葉/病”,蟲害實體“金紋細蛾”的分詞結果為“金/紋/細/蛾”,這些實體的錯誤拆分會導致模型不能正確獲取實體特征[14]。雖有研究表明,在嵌入層中基于字符的模型比基于單詞的模型性能要好[15],但在中文里單個字符可表達的語義有限,而通過使用預先訓練的詞嵌入作為特征可進行改進。本文使用Lattice LSTM[16]模型提供的預訓練向量集,同時采用基于字向量與詞向量拼接的嵌入方式來增強文本的語義信息。
2.2 Transformer層
在中文命名實體識別任務中,文本的位置與語義密切相關。已有的多數研究更偏重文本的語義特征、偏旁特征或拼音特征,而忽略了文本的位置特征。而傳統的Transformer模型在嵌入層引入了絕對位置編碼,其計算方式為
Pt,2i=sin(t/10 0002i/d)
(1)
Pt,2i+1=cos(t/10 0002i/d)
(2)
式中t——文本位置
i——維度位置索引
Pt,2i——第t個token在偶數維度的位置編碼
Pt,2i+1——第t個token在奇數維度的位置編碼
d——輸入維度
在傳統的Transformer注意力計算方法中,序列中第t個字和第j個字的注意力分數計算公式為
(3)
式中WQ、WK、WV——輸入字符的查詢向量Q、鍵向量K、值向量V的權重參數矩陣
X——字嵌入向量
P——位置編碼
j——token的索引
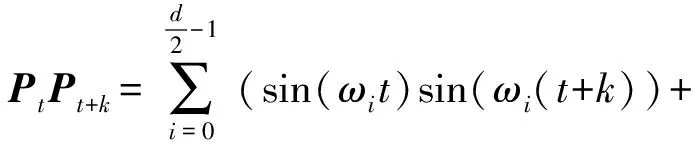
(4)
由三角函數的性質cos(x)=cos(-x)可知,傳統計算方式所得出的相對位置信息僅有兩個token之間的距離關系,而對于兩個token的位置無法判斷,例如在“蘋果”與“果蘋”中,兩個字相對位置雖不同,但其位置編碼乘積相同,同時這樣的位置信息在經過查詢向量和鍵向量的映射后會消失。
為了充分利用中文文本的位置特征,本文改進使用
(Q,K,V)=(HWQ,HWK,HWV)
(5)
(6)
(7)
A(Q,K,V)=softmax(S)V
(8)
式中H——嵌入層輸出
u、v——可學習的參數
Rt-j——相對位置編碼
St,j——第t、j個token之間相似度得分
Qt,Kj——第t、j個token的查詢向量和鍵向量
A——注意力得分
來計算整體注意力分數,通過式(6)計算位置編碼,利用三角函數的性質,通過正弦函數捕捉方向性,余弦函數捕捉字符的絕對位置關系,從而解決傳統Transformer模型相對位置信息易丟失的問題。通過式(7)計算輸入序列中每個單詞之間的相關性得分,式(8)對于輸入序列中每個單詞之間的相關性得分進行了歸一化,使每個字與其他字的注意力權重之和為1。
通過計算每個字與其他字的相關性,即可獲得全局特征表示。當實體中的生僻字缺失語義信息時,根據其與前后文本的位置關系,依然可以依據其他文本而獲取到。如病原實體中常以“菌”、“殼”、“孢”等字結尾,在實體“河口槭膠銹菌”中,“槭”為生僻字,但由于其后面的“菌”通常是病原中最后一字,且僅相隔兩個字,根據其位置信息也可確定其為病原實體的一部分。
2.3 BiLSTM層
通過分析蘋果病蟲數據集發現,在長句子中常會出現多類實體,且實體長度不一,為害部位大多常以兩個字符出現,而部分藥劑名稱則多達9個字符,如“代森錳鋅可濕性粉劑”。使用LSTM[17]不僅可以處理長序列問題,同時解決了RNN在訓練時所產生的梯度爆炸或梯度消失現象[18-19],而且能夠有效利用上一時刻特征來判斷下一時刻特征,因此本文使用LSTM網絡實現對局部語義特征的提取。
在命名實體識別任務中,句子的前向信息和后向信息都很關鍵,而普通LSTM只能捕獲前向信息[20]。如病害實體“斑點落葉病”,LSTM提取到“葉”字時需提取到之前的“斑點落”幾個字的特征,而無法考慮到與后面“病”字的關系。針對上述問題,本文選擇雙向LSTM(BiLSTM)[21]結構實現對句子級別的特征提取,以更好地解決蘋果領域中一詞多義的問題。
2.4 特征融合層
在命名實體識別研究中,許多研究者采用基于CNN、基于LSTM和基于Transformer等方法作為上下文編碼器,但是采用單一的編碼器通常也會引起特征提取不充分問題。LSTM模型雖然能夠在序列信息建模方面凸顯優勢,卻存在冗余信息;Transformer能夠關注重點詞匯特征和加速訓練速度,但存在上下文信息建模不足的缺陷。基于上述情況,本研究使用平均融合法實現對特征的融合,以降低模型陷入局部極小點的可能,進而達到提高識別率的目的。本文設計平均法、投票法、拼接法3種方案,其對應的計算公式分別為
(9)
(10)
H(x)=h(x)⊕f(x)
(11)
式中h(x)、f(x)——Transformer、BiLSTM的輸出
N——模型個數
wj——第j個模型的權重
pi,j,k——第j個模型對樣本i的預測結果為類別k的概率
2.5 CRF層
BiLSTM與Transformer雖然適合處理長距離的文本信息,但都忽略了標簽之間的依賴關系[22],而在命名實體識別任務中,如果不考慮字符標簽與相鄰標簽的相關性則極可能會給出錯誤標簽。CRF[23]能通過訓練數據學習到標簽之間的約束性[4-5],并通過這種約束性獲得一個最優的預測序列,具體約束性主要有以下兩點:①句子中的第一個字的標簽只能是“B-”或者“O”,不能是“I-”。②語句中的標簽“B-label I-label I-label”,“label”應該是相同的命名實體標簽,如“褐斑病”的標簽應為“B-DIS I-DIS I-DIS”,而在蘋果病蟲數據集中,當“蘋果”后為病害實體時,通常當作一個整體,如“蘋果褐斑病”的標簽為“B-DIS I-DIS I-DIS I-DIS I-DIS”;“蘋果”后為病原實體時,如“蘋果鏈核盤菌”,其標簽應為“B-CAU I-CAU I-CAU I-CAU I-CAU I-CAU”。
3 實驗與分析
3.1 實驗環境搭建和模型參數設置
實驗運行系統為Ubuntu 18.04,顯卡型號NVIDIA GeForce RTX 3080 Ti,編程語言使用Python 3.7版本,采用Pytorch 1.7.1深度框架完成模型構建和訓練評估。在實驗過程中,所使用的模型參數,是通過前期的實驗參數優化調整所得的最優參數組合:即迭代次數為35,學習率0.000 6,多頭注意力數量為4,每個頭維度為48,批量大小4,隨機失活率0.45。由參數優化實驗發現,學習率過大,會造成網絡不能收斂,而學習率過小容易陷入局部最優解,進而造成識別效果變差;批量大小設置過小會不利于收斂,過大容易陷入局部最小值;為防止模型過擬合,本文添加了隨機失活率來減少神經元之間的復雜關系,以增強模型魯棒性。本文使用的優化實驗參數如表2所示。對實體抽取模型結果和各項性能進行定量分析,所采用的評價指標為精確率、召回率、F1值[24]。

表2 BIO標注的實驗參數Tab.2 Experimental parameters of BIO
3.2 實驗結果與分析
3.2.1不同模型實驗結果對比
為了對比所提方法的識別效果,本文基于相同數據集,選取命名實體識別領域的3種傳統常用模型BiLSTM-CRF、Transformer-CRF和TENER模型分別進行了性能對比實驗。各個模型的性能結果如表3所示。
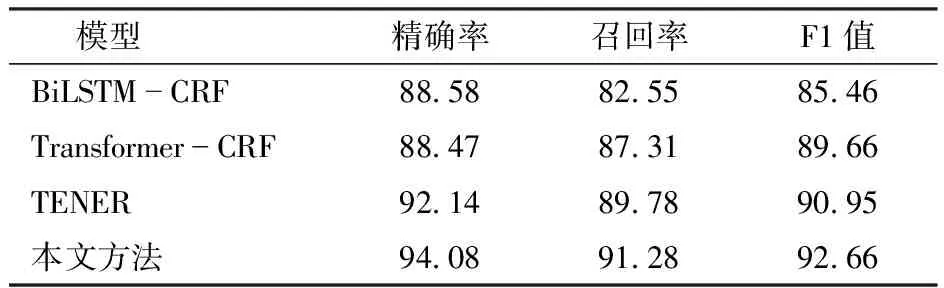
表3 不同模型對比實驗結果Tab.3 Comparative experimental results of different models %
從表3可以看出,使用BiLSTM對序列提取特征,F1值僅為85.46%,其可能原因是當文本序列長度過長時BiLSTM對上下文特征的提取能力會下降;而在傳統的Transformer模型中,其位置編碼信息沒有得到充分利用,較于BiLSTM模型其僅在召回率和F1值上有所提高;TENER通過改進位置編碼函數,采用非縮放點積的注意力機制,與Transformer相比精確率、召回率和F1值分別提高3.67、2.47、1.29個百分點。本文提出的模型利用了TENER的優勢,使用了具有方向和距離感知的注意力機制,充分結合了文本的位置特征,同時通過引入BiLSTM增強了上下文語義特征,使模型對上下文相關性的提取能力有所提高,其精確率、召回率和F1值分別達到94.08%、91.28%和92.66%,在所比較模型中均達到最高。對比結果表明所提方法對于句子語義特征的學習是有效的。
3.2.2不同實體類別實驗結果對比
為了驗證模型在各類實體上的提取能力,表4列出了所提方法在蘋果病蟲數據集中對各類實體的識別結果。從表中可知,本文方法對病害名稱、蟲害名稱、為害部位、藥品名稱、病原5類實體的F1值均在90%以上,但對別名的F1值僅為83.33%,這可能是由于在數據集中別名實體數量較少,同時病害與蟲害的別名通常具有相同的邊界特征,如病害名稱與其別名都常以“病”字結尾,導致模型在判斷中容易混淆,造成F1值較低。
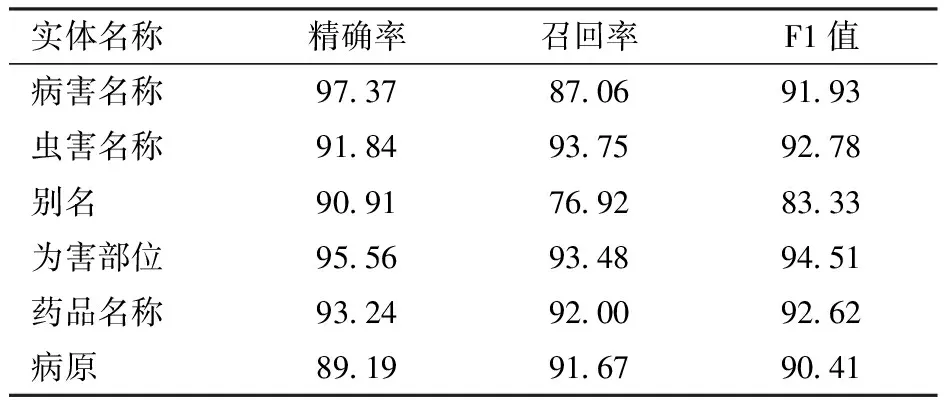
表4 Transformer優化模型在各類實體上的表現Tab.4 Optimized Transformer’s performance on various entities %
圖3~5展示了不同模型在各實體上的性能表現對比,本文方法在藥品名稱(MED)、病害名稱(DIS)、病原(CAU)、為害部位(PAR)、別名(NAM)實體上的F1值均優于其他模型。對實體蟲害名稱(PES)的F1值為92.78%,低于其他模型,原因可能是在蟲害實體中,大多以“蟲”、“蛾”、“蚜”等特征詞作為結尾,但存在部分蟲害名稱中不存在這些特征詞,如“金龜子”,從而導致模型易將這些蟲害實體識別錯誤。參考蘋果病蟲領域的實體特征,一詞多義、生僻字、構成成分多等情況通常多出現在藥品名稱、病原、別名的實體中,因此,可以說明本文方法能夠有效解決蘋果病蟲領域的命名實體識別問題。
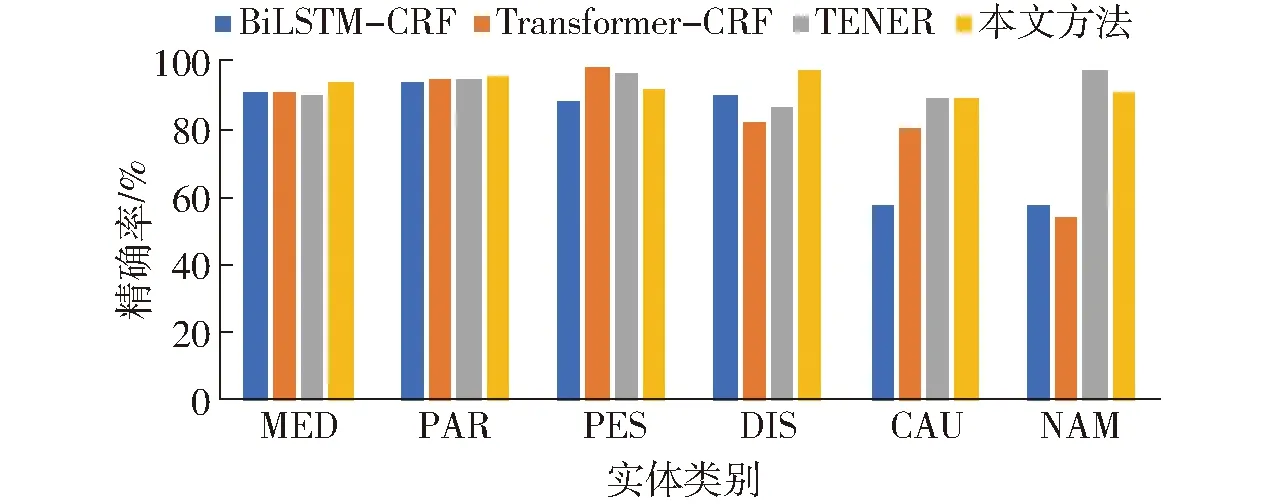
圖3 各實體精確率對比Fig.3 Comparison of precision of each entity
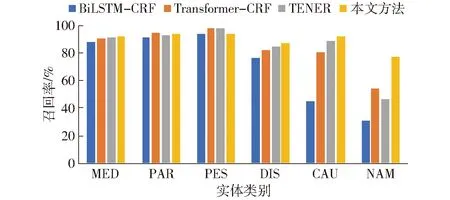
圖4 各實體召回率對比Fig.4 Comparison of recall rate of each entity
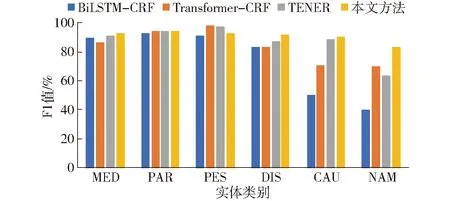
圖5 各實體F1值對比Fig.5 Comparison of F1 score of each entities
以上結果表明,本文利用了Transformer中注意力機制,使模型具有更加關注重點詞、抑制無用詞的特點。采用具有方向和距離感知的注意力機制來充分利用文本位置特征,通過引入BiLSTM來增強上下文信息,在本文所構建的數據集中綜合識別能力優于所比較的其他傳統模型。
3.2.3Transformer與不同模型融合結果對比
學習任務假設空間往往很大,會有多個假設在訓練集上達到同等性能,使用單一學習器可能會出現泛化能力不佳的情況,通過結合多個學習器可以有效降低這一風險。為了得到最佳的模型,本文設計了Transformer分別與RNN、LSTM、BiLSTM和BiGRU進行融合,實驗結果如表5所示。
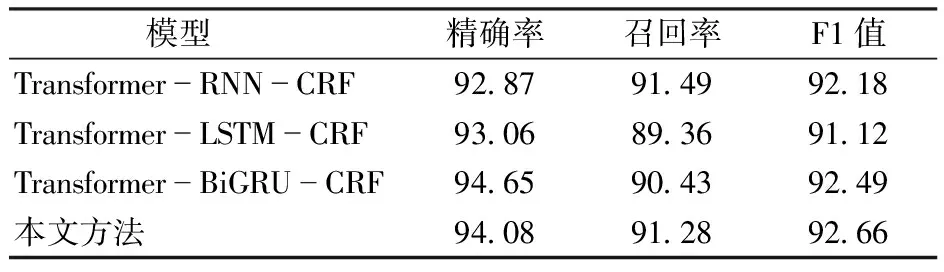
表5 Transformer與不同模型融合結果Tab.5 Transformer integrated with different models %
由表5可以看到,與傳統RNN進行融合,模型精確率為92.87%。而LSTM與GRU都屬于門控RNN,更適合處理長序列數據,與LSTM融合后的精確率達到93.06%。為了可以更好地捕捉雙向的語義依賴,選擇分別與BiGRU和BiLSTM模型進行融合,在精確率和F1值上均有提高,結果表明,BiLSTM模型可以更大范圍地補充Transformer提取不到的依賴關系和語義特征,因此與BiLSTM融合的效果更好。
3.2.4不同融合方法對模型的影響
為了選擇最佳的特征融合方法,本文使用3種不同的融合方法(平均法、投票法、拼接融合法),比較不同融合方法對于模型性能的影響。在不同融合方法下,模型的性能參數結果如表6所示。
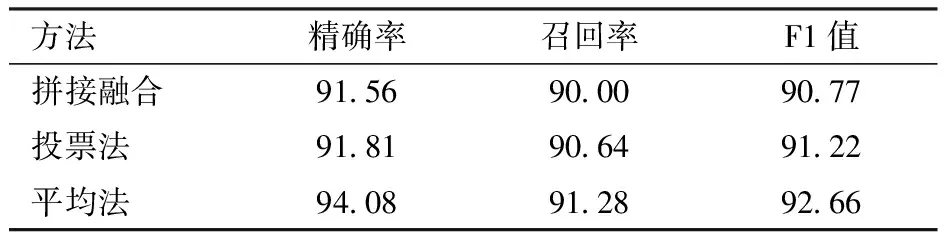
表6 不同融合方法對比
實驗表明,使用簡單拼接融合效果最差,平均法效果最好,其可能原因是拼接融合將多個特征向量拼接在一起,其中一些特征可能存在多個特征重復出現,導致模型在進行訓練時過度依賴重復特征,從而降低模型性能。而由于本文蘋果數據集中實體占比較小,投票法可能會受到噪聲數據的干擾,從而導致錯誤的預測結果。平均融合法通過平均多個模型的預測結果,可以減少單個模型的偏差和方差,從而提高整體的準確性。
3.2.5與同領域相似研究比較
文獻[9]通過整理蘋果病蟲領域相關書籍,構建了包含130 448個漢字的蘋果病蟲害庫ApdCNER,共標注相關實體11 876個;本文先通過爬蟲技術爬取網頁中對蘋果病蟲害的描述,隨后在專家指導下進行修正,構建了蘋果病蟲語料庫,共標注127 572個漢字,包含3 928個實體,與文獻[9]相比,本文構建的數據集中各實體數量相對更少,分布更稀疏;在實體的標注方面,文獻[9]將蘋果相關各實體分為21個類別,更考驗模型的提取能力。在本文構建的數據集中根據日常使用情況將實體分為6個類別,更適用于普通問答系統的構建;在模型提取能力方面,文獻[9]將蘋果數據集中的字典和類似的單詞納入BiLSTM CRF模型,其精確率、召回率和F1值分別為92.29%、91.99%和92.14%,本文所提方法的精確率、召回率和F1值分別為94.08%、91.28%、92.66%,F1值相較提高0.52個百分點,表明了本文方法與當前同領域較先進的模型達到同等性能水平。考慮到所需的樣本數量,本方法對小樣本量的蘋果領域命名實體識別任務具有較高的特征提取能力。
另外,由于與文獻[9]采用了不同的實體標注方式,為了排除標注方法的可能影響,本文又使用文獻[9]的BMES標注方式對所建數據集進行了實體標注,B表示該漢字是一個詞語的開頭,E表示該漢字是一個詞語的結尾,M表示該漢字是一個詞語的中間部分,S則表示該漢字單獨構成一個詞語,該標注方法對所標注實體增加了對應標簽,而對于實體數量較BIO標注并未發生改變。BMES標注后重新訓練該模型并對識別性能評估,模型的優化實驗參數如表7所示,重新標注后所建模型的精確率為94.40%、召回率為92.21%、F1值達到93.29%。對比3.2.1節使用BIO標注方法的模型運行結果,可以發現兩種標注方法的運行效果基本達到相同水平,使用BMES方法更加準確地標注出每個漢字的位置和類型,提供了比BIO方法更多的信息,方便后續進行分詞處理,因而是其F1值略有提升的可能原因。對比表7與表2可以看到,模型的優化參數會受標注方式影響。

表7 BMES標注的實驗參數Tab.7 Experimental parameters of BMES
最后,為了測試所建模型在實際使用過程中的有效性,通過百度貼吧平臺抽取了蘋果種植相關的問題,并使用本文模型對文本數據進行了實體識別,結果如表8所示,本模型對實際病蟲提問均準確提取出了問題中的實體。
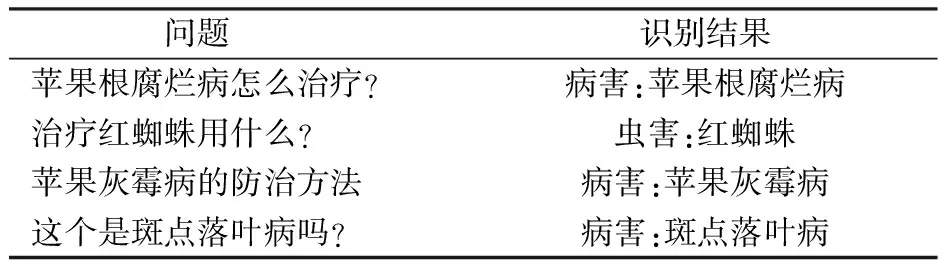
表8 識別結果示例Tab.8 Examples of recognition results
4 結論
(1)針對蘋果生產領域存在病蟲害相關數據集缺失的問題,本文基于西北農林科技大學在陜西省渭南市白水縣的蘋果試驗示范站所收集的蘋果病蟲知識,以及通過爬取中國農化招商網,綜合《中國蘋果病害病原菌物名錄》電子版數據,建立了蘋果病蟲知識數據集。
(2)為提高蘋果病蟲害實體識別的準確性,本文通過在Transformer中引入具有方向和距離感知的注意力機制,融合BiLSTM提取到的語義特征來提高Transformer在蘋果病蟲害實體識別領域的識別效果,通過對比BiLSTM-CRF、Transformer-CRF、TENER模型,驗證了傳統Transformer模型在命名實體識別領域的不足。實驗結果表明,本文所提方法在蘋果命名實體識別中的F1值可達92.66%。相較于傳統的識別方法,其性能進一步提升,對小樣本量數據集優勢明顯。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
