基于YOLOv5的衛(wèi)星遙感圖像滑窗目標檢測*
2023-06-05 00:49:50劉佳銘
艦船電子工程 2023年1期
劉佳銘
(海裝上海局駐上海地區(qū)第五代表室 上海 200135)
1 引言
光學遙感目標檢測在遙感圖像分析和處理中具有重大作用,是土地利用、城市規(guī)劃、航空探測等應用的重要基礎(chǔ)。隨著目前對地觀測技術(shù)的發(fā)展,獲取到的高分辨率遙感圖像數(shù)據(jù)能夠提供更豐富的圖像細節(jié)信息,這為目標檢測在遙感領(lǐng)域的發(fā)展提供了契機。
之前較早提出的遙感圖像目標檢測算法大部分都是基于手工設計特征的模式,先提取候選區(qū)域,之后針對待檢測目標設計手工特征,然后結(jié)合SVM 或其他分類器進行分類。然而候選區(qū)域提取方法需要設置大量的滑動窗口,導致模型計算復雜度非常高,因此模型較為低效;另外人工設計特征主要通過待檢測目標視覺信息(邊緣、顏色、紋理等)提取得到,雖然可解釋性較強,但是其特征表達能力較弱、適應范圍小,魯棒性較差難以應用在復雜多變的環(huán)境中。因此,綜上所述,早期提出的光學遙感圖像目標檢測算法遠不能滿足實際應用需求。
自從卷積神經(jīng)網(wǎng)絡引入以來,其在計算機視覺技術(shù)取得了長足的進步。得益于ImageNet[1]、MS COCO[2]和PASCAL VOC[3]等大型高質(zhì)量標記數(shù)據(jù)集的支持,正常尺度的目標檢測算法已經(jīng)較為成熟,從最早的兩階段的RCNN[4]、Fast-RCNN[5]和Faster-RCNN[6]到現(xiàn)在的基于錨框的兩階段的SSD、YOLO[7~11]系列等模型。雖然這些框架的性能令人印象深刻,但沒有一個框架可以有效地處理輸入尺寸為16000×16000 的遙感衛(wèi)星圖像。針對圖像尺度過大的問題,通常是采用分塊切割或者滑窗切割的方式,將超大圖像切割成小圖像塊,然后分別對每張小圖進行檢測識別,最后把所有的檢測結(jié)果進行拼接和后處理,完成全圖的最終檢測[12~15]。為了解決這個問題,Wang 等[16]以一定的重疊率對原圖進行切割,增加了分塊小圖邊緣目標完整性的可能,但是卻增加了子圖像的數(shù)量,使得大圖的處理時間變得冗余,同時依然無法避免目標檢測結(jié)果一分為二的問題。為了減少大圖檢測的時間冗余,基于圖像中絕大多數(shù)區(qū)域為背景、待測目標只集中于較小區(qū)域的現(xiàn)狀,R2-CNN[17]設計了輕量級主干Tiny-Net 來進行特征提取,并采用先判斷、后定位的方式,將不含目標的子圖像塊進行濾除,從而減小后續(xù)檢測識別過程的計算負擔,該方法保證了檢測效果,同時提高了檢測效率,但是依然會對重疊區(qū)域進行多次檢測。算法YOLT[18]對切割后的子圖,采用多個輕量級模型進行檢測,并將檢測結(jié)果進行融合,保持檢測精度的同時,一定程度上提升了檢測的速度。以上方法均需要對原始遙感圖像進行分塊處理,這種切割的方式始終不是一種最優(yōu)的方式,但目前來看很難通過非切割的辦法進行完美的檢測。
本文針對大尺寸光學遙感圖像目標檢測問題,提出了一種基于改進的YOLOv5 的解決辦法,在YOLOv5 網(wǎng)絡的基礎(chǔ)上,增加注意力模塊提升模型對于小目標細粒度特征的提取能力,然后利用滑動窗口方法進行目標檢測,最后綜合所有窗口的檢測框執(zhí)行非極大值抑制,獲得檢測結(jié)果。實驗結(jié)果證明,對于測試實驗中的大尺寸圖像,我們的模型在比較快的推理速度下,各個種類都可以得到比較高的F1定位分數(shù)。
2 方法
2.1 CBAM
CBAM[19]是一種輕量級注意力模塊,它綜合使用了空間注意力機制和通道注意力機制。引入CBAM 后,注意力機制能夠讓網(wǎng)絡學會關(guān)注重點信息,從而提升模型細粒度特征提取能力。CBAM 大致結(jié)構(gòu)如圖1所示。

圖1 CBAM注意力模塊具體結(jié)構(gòu)圖
如圖1,每個CBAM 模塊由一個空間注意力(SAM)模塊和通道注意力(CAM)模塊組成,假設CBAM 的輸入為大小為N×H×W×C 的特征塊F,則其先經(jīng)過一個通道注意力模塊,計算如下式所示。
上式中,Mc代表通道注意力卷積模塊;avg和maxp分別代表全局平均池化層和全局最大池化層;MLP是多個線性層的表示,在CBAM 中層數(shù)為2;σ代表sigmoid 函數(shù);F′為通道注意力模塊的輸出,其大小仍為N×H×W×C。
然后將從CAM 得到的F'喂入一個空間注意力模塊中,計算如下。
上式中Ms表示空間注意力模塊;Concat 表示疊加層;F″表示CBAM 的輸出;其他的定義與式(1)、(2)中的定義一樣。
日本《讀賣新聞》7日早間發(fā)布政府消息稱,日本政府內(nèi)部已決定將在2018年12月10日修改內(nèi)部采購規(guī)定,禁止政府部門采購來自華為和中興2家公司的通信設備,來防止情報泄露和網(wǎng)絡攻擊。不過,日本擔憂中日兩國友好關(guān)系,因而在會議上并未直接點2家公司的名字。
CBAM 綜合兩種不同的注意力模塊,能夠提升檢測模型提取細粒度特征的能力,并且其參數(shù)量和計算量較小,這使得我們不必擔心添加CBAM 對于大圖像檢測會增加很多耗時。在實驗中我們將CBAM 放置上采樣之前的Concat 操作之前,如圖2所示。
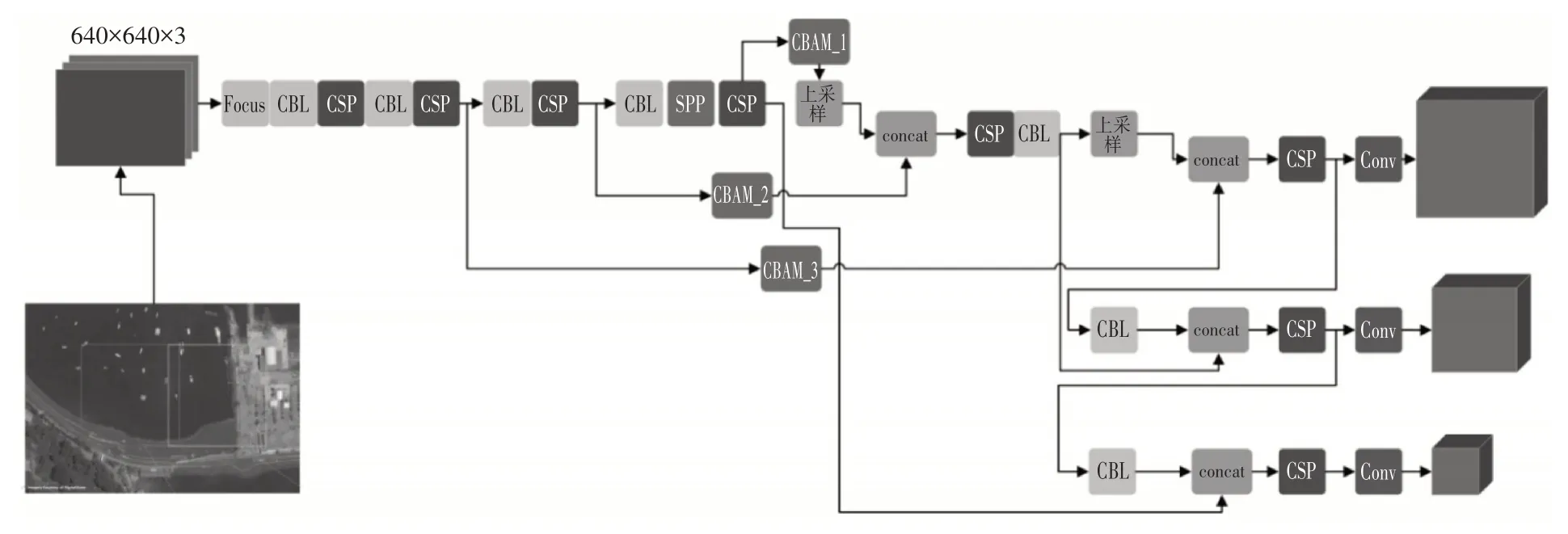
圖2 大尺寸遙感圖像檢測架構(gòu)
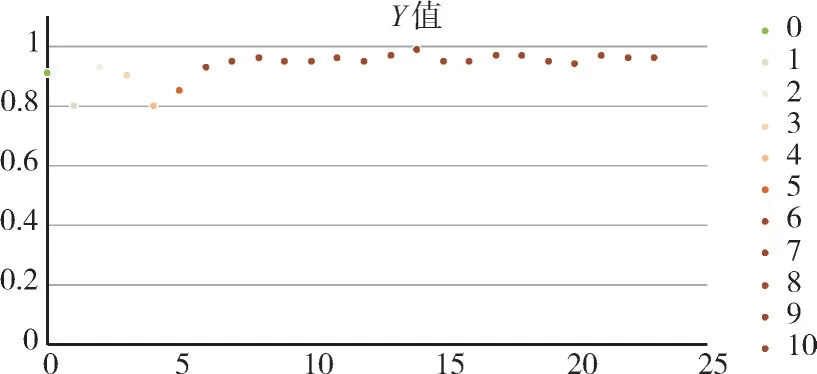
圖3 本文模型在COWC每個測試場景下的F1分數(shù)
2.2 Backbone
隨著深度卷積神經(jīng)網(wǎng)絡的發(fā)展,目標檢測技術(shù)獲得了巨大的發(fā)展。目前現(xiàn)有的目標檢測方法基本上可分為anchor-based 的方法和anchor-free 的方法。基于錨框的方法比較有代表性的為雙階段的Faster-RCNN 和單階段的YOLO 系列,錨框free的方法有CenterNet,CornerNet 等。YOLO 系列中YOLOv5 網(wǎng)絡架構(gòu)運行速度快、檢測精度高,其最快檢測速度可達每秒檢測140 幀圖像。另一方面,該網(wǎng)絡模型的模型復雜度并不高,與前一代的YOLOv4 模型相比模型大小減小了大約90%左右,因此YOLOv5 模型非常適合部署到大尺寸遙感圖像的目標檢測中來。為了保證檢測速度和準確率,本研究以YOLOv5 架構(gòu)為基礎(chǔ),改進遙感圖像目標檢測網(wǎng)絡。
YOLOv5 網(wǎng)絡包含YOLOv5m、YOLOv5s、YOLOv5x和YOLOv5l 這四種架構(gòu),這四種網(wǎng)絡架構(gòu)的主要區(qū)別在于在網(wǎng)絡的特定位置處所包含的卷積核數(shù)量和特征提取模塊數(shù)量不同,這幾種架構(gòu)的模型參數(shù)量和占用內(nèi)存依次增大,詳細指標參數(shù)如表1所示。
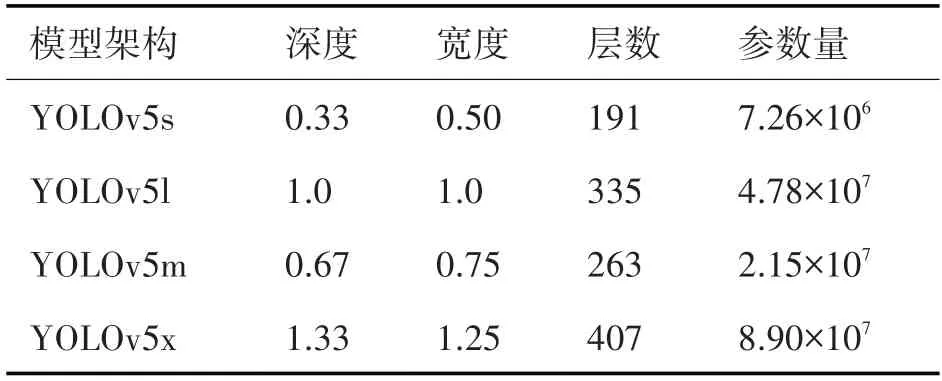
表1 YOLOv5四種架構(gòu)模型的指標參數(shù)
由于本研究需要通過滑窗的方式對大尺度遙感圖像進行目標檢測,而滑窗的過程本身耗時較大,因上采用輕量化且準確度較高的目標檢測模型是非常有必要的,我們綜合考慮YOLOv5 這四種架構(gòu),選取YOLOv5m(圖2)架構(gòu)為基本架構(gòu),改進設計遙感光學圖像目標檢測模型。
YOLOv5m 架構(gòu)主要由主干網(wǎng)絡、Neck 模塊和Detect 模塊組成。主干網(wǎng)絡為特征提取網(wǎng)絡,是在不同的圖像細粒度上聚合并形成圖像特征的卷積神經(jīng)網(wǎng)絡。主干網(wǎng)絡的第1 層是Focus 模塊,這個模塊主要的作用是減少模型的計算量提升快訓練速度,具體操作是通過切片操作將輸入尺寸為3×640×640的3 通道圖像切分成4個3×320×320 的切片,然后使用通道疊加操作在深度維度上堆疊這4個切片部分,輸出尺寸為12×320×320的特征圖,進而通過一個卷積核數(shù)量為48 的卷積層,生成48×320×32 的輸出,最后經(jīng)過批歸一化層和Hardswish激活函數(shù)后將結(jié)果輸入到下一層。
主干網(wǎng)絡同時使用了空間金字塔池化模塊(Spatial Pyramid Pooling,SPP),該模塊的使用能夠?qū)⑷我獬叽绲奶卣鲌D都轉(zhuǎn)換成固定尺寸的特征向量,從而能夠提高網(wǎng)絡的感受野。YOLOv5m 中SPP 模塊的輸入為尺寸為768×20×20 的特征圖,那么首先經(jīng)過1×1 的卷積層,輸出尺寸為384×20×20的特征圖,然后將該特征圖與其分別經(jīng)過3 個并列最大池化層進行下采樣后的輸出特征圖從深度上進行疊加,輸出尺寸為1536×20×20的特征圖,最后再經(jīng)過卷積核數(shù)量為768 的卷積層后輸出尺寸為768×20×20的特征圖。
2.3 遙感目標檢測模型
為了提升目標檢測模型對于小目標檢測的能力,我們在2.2中提到的YOLOv5m的基礎(chǔ)上引入了CBAM 模塊,提升模型提取目標細粒度特征的能力。CBAM模塊穿插位置如圖2所示。我們主要使用車以及建筑物的大尺寸遙感圖像數(shù)據(jù)集重新訓練了改進的YOLOv5 模型,另一方面,在錨框設計上,為了更好地貼合小目標的實際情況,我們使用K-means 聚類算法獲取更合適的錨框。訓練模型時網(wǎng)絡的損失函數(shù)Loss 由回歸框預測損失Lossreg,目標分類損失Lossclass以及置信度損失Lossconf組成,計算如下式:
其中,置信度損失和目標分類損失采用的是二進制交叉熵損失函數(shù)(BCELoss),計算公式為
上式中y為種類真值,p為預測概率值。
回歸框預測損失采用的是GIoU Loss 函數(shù)。其中,GIoU Loss計算如下式:
上式中IOU 表示預測框與真實框的交并比;B表示預測框,Bgt表示真實框,C表示能夠包含預測框與真實框的最小矩形。
我們針對大尺寸遙感圖像的檢測沿用了YOLT的基本做法,使用滑窗分塊的方法實現(xiàn)遙感圖像的目標檢測。假設滑窗大小為(h,w),那么對應的滑動步長(slide_h,slide_w)的選取對于目標檢測的精度影響較大。若滑動步長設置過大,例如直接設置為窗口尺寸,容易出現(xiàn)由于目標截斷引起的回歸框位置不準確以及漏檢情況,而較小的滑動步長又會嚴重影響模型的推理速度,與實際需求沖突。經(jīng)過分析,綜合推理速度和模型精度,滑動窗口步長應該依靠待檢測目標尺寸如下設置:
上式中,hobjmax,wobjmax分別為待檢測目標數(shù)據(jù)庫的寬高尺寸估測最大值。考慮到增強模型的泛化能力,實驗實現(xiàn)過程中采取一個泛化的經(jīng)驗設定如下式:
上式中overlap 表示滑動窗口重疊率,在實驗中取15%。這種設定能一定程度上減小遙感目標檢測模型準確度受到不同場景下目標多變形狀的影響。
檢測后處理包括兩次非極大值抑制(NMS)。首次為YOLOv5 原有的操作,另外針對滑窗目標檢測,我們整合所有滑窗分塊的預測框,執(zhí)行第二次NMS操作,這能夠極大地增強模型的預測精度。
3 實驗數(shù)據(jù)集
我們基于從空中平臺大型圖像小芯片中收集的COWC 數(shù)據(jù)集對提出的基于滑窗的衛(wèi)星遙感目標檢測模型進行訓練和驗證。COWC 數(shù)據(jù)集是一個大型、高質(zhì)量的注釋汽車集,來自多個地點收集的高架圖像。數(shù)據(jù)是通過空中平臺收集的,但視角較低,類似于衛(wèi)星圖像。COWC數(shù)據(jù)集中的圖像的分辨率為15cm GSD,大約是當前商業(yè)衛(wèi)星圖像最佳分辨率(DigitalGlobe 為30cm GSD)的兩倍。通過原始圖像與高斯核卷積,并將圖像尺寸減少一半,以創(chuàng)建等效于30cm GSD圖像的圖像。
我們在實驗中按照6:4 的比例將數(shù)據(jù)集劃分為訓練集和測試集,使用SGD 進行訓練,初始學習率為10-3,權(quán)重衰減為0.0005,動量為0.8。訓練在單個NVIDIA 3090Ti GPU上運行。
4 實驗結(jié)果與分析
為了提升模型準確度,我們在YOLOv5m 的基礎(chǔ)上添加了CBAM 注意力模塊提升模型的細粒度特征提取能力,表2展示了有無CBAM 模塊目標檢測模型的F1分數(shù)。

表2 CBAM融合實驗結(jié)果
由表2的實驗結(jié)果可知,YOLOv5m 融合CBAM在COWC測試集上驗證的F1分數(shù)為0.93±0.06,而單純用YOLOv5 模型目標檢測的F1 分數(shù)為0.90 ±0.09,各個測試場景下的F1 均值提升了0.03%,并且改進的遙感圖像目標檢測模型在測試集上的穩(wěn)定性更好,目標檢測精度浮動更小。因此CBAM 注意力模塊增強了模型細粒度特征提取能力,這對于遙感圖像的小目標檢測具有一定的增強。
本文的改進YOLOv5 滑窗檢測模型在COWC測試效果如圖4所示。通過圖4可以看出我們提出的改進模型可以較為完美地預測超大圖像車輛的位置,并且預測框比較貼合實際的真實框。

圖4 滑窗遙感目標檢測模型的預測結(jié)果
綜合以上分析,我們提出的基于滑窗的改進YOLOv5m 目標檢測模型很好地實現(xiàn)了對于大型遙感圖像的目標檢測和提取。
5 結(jié)語
本文針對大尺寸遙感圖像目標檢測問題,提出了一種基于改進的YOLOv5m 的算法,在YOLOv5m網(wǎng)絡的基礎(chǔ)上,增加注意力模塊提升模型對于細粒度特征的提取能力,增強模型小目標檢測能力,然后利用滑動窗口方法進行目標檢測,最后綜合所有窗口的檢測框執(zhí)行非極大值抑制,獲得檢測結(jié)果。實驗結(jié)果證明,對于測試實驗中的大尺寸圖像,我們的模型在比較快的推理速度下,獲得了很好的模型準確度。
本文提出的遙感影像目標檢測模型同樣可以應用于對大尺寸遙感圖像中的艦船目標檢測,這對于海上目標識別具有重要意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
