甲狀腺疾病輔助診斷機器學習模型研究
2023-05-30 10:48:04王瑩顧大勇
電腦知識與技術 2023年2期
關鍵詞:機器學習
王瑩 顧大勇


關鍵詞:甲亢;甲減;機器學習;邏輯回歸;醫學檢驗
中圖分類號:TP181 文獻標識碼:A
文章編號:1009-3044(2023)02-0007-04
1概述
甲狀腺是人體內分泌系統的重要組成部分,通過穩定甲狀腺激素,維持人體的新陳代謝。甲狀腺功能減退癥(甲減)和甲狀腺功能亢進癥(甲亢)是兩種最常見的甲狀腺疾病[1]。甲亢的特征是甲狀腺激素合成和甲狀腺分泌增加,造成機體代謝亢進和交感神經興奮,引起心悸、出汗、進食和便次增多及體重減少的病癥。部分患者同時有突眼、眼瞼水腫、視力減退等癥狀。甲減是指甲狀腺激素缺乏癥,如果得不到及時治療,將嚴重影響健康,甚至導致死亡。甲狀腺疾病和代謝異常綜合征、糖尿病、高血壓和血脂異常的多發性在老年人中很常見[2]。甲狀腺疾病的早診斷、早治療在預防和減少其并發癥方面起著重要作用,可以降低相關疾病的發病率和死亡率。
甲狀腺疾病的病因復雜,與自身免疫狀態、環境、營養、遺傳基因等都有著密切的關系。目前,醫學實驗室檢查是臨床診斷甲狀腺功能障礙的常用方式,主要通過檢測總甲狀腺素(Total Thyroxine ,TT4)、游離甲狀腺素(Free Thyroxine,FT4)、總三碘甲狀腺氨酸(Total Triiodothyronine ,TT3)、游離三碘甲狀腺氨酸(Free Triiodothyronine,FT3)及促甲狀腺激素(ThyroidStimulating Hormone, TSH)五項醫學檢驗項目,從而根據其水平判斷甲狀腺功能(甲功)是否正常,甲功五項檢測結果具有相對較高的臨床診斷符合率[3-5]。甲功五項對甲狀腺疾病的類型判斷、療效監測、病情評估都具有重要價值,直接影響臨床醫生的診斷及用藥[6]。在臨床上, 采用何種檢查方式評價甲狀腺功能并無統一說法[7],研究發現其他醫學實驗室檢查項目與甲狀腺疾病相關,例如尿碘、糖化血紅蛋白和血糖等,尿碘與甲狀腺疾病的關系日益突出并受到關注,尿碘監測對于防治甲狀腺疾病具有重要的現實意義[8-10],糖化血紅蛋白與血糖同樣與甲狀腺疾病相關,患糖尿病人群發生甲狀腺功能障礙的概率較非糖尿病人群高出2~3倍[11]。因此有必要全面發掘醫學檢驗項目與甲狀腺疾病的相關性。醫學檢驗項目具有數據量大、數據結構復雜和數據維度高等特點,傳統的數理統計工具已經無法滿足要求,機器學習是用計算機通過算法來學習數據中包含的內在規律和信息,從而獲得新的經驗和知識,以提高計算機的智能性,使計算機面對問題時能夠做出與人類相似的決策[12]。機器學習有助于從海量的醫學數據中發現傳統數理統計無法發現的問題,為臨床診斷提供新的解決問題思路[13]。
為了發掘醫學檢驗項目與甲狀腺疾病的相關性,本研究采用機器學習算法對全維度醫學檢驗數據進行挖掘,直觀地展示每一項醫學檢驗項目與甲狀腺疾病的相關性。
2 資料與方法
2.1 一般資料
本研究共包括65723例甲亢患者、48028例甲減患者和19841例體檢人員的1355項醫學檢驗數據。其中甲亢患者、甲減患者和體檢人員均以臨床診斷結果作為篩選依據。在進行機器學習計算時65723例甲亢患者數據,插入19841例體檢人員數據獲得85564 例人員數據作為甲亢機器學習數據源。48028例甲減患者數據插入19841例體檢人員數據獲得67869例人員數據作為甲減機器學習數據源。
2.1.1資料來源
以某醫院近5年(2016年10月1日至2021年09 月30日)的全量醫學檢驗數據經過數據治理、開發后形成包含4903891條記錄的數據寬表為基礎。
2.1.2數據集成
從實驗室信息管理系統(Laboratory InformationManagement System, LIS)和醫院信息管理系統(Hospi?tal Information System, HIS)中抽取2016 年10 月至2021年9月的全量醫學檢驗數據,字段包括患者的ID、年齡、性別、患者就診類別(門診或住院)、檢驗日期、檢驗項目編碼、檢驗結果、診斷結果。
2.1.3數據治理、開發
在大數據平臺采用結構化查詢語言(StructuredQuery Language, SQL)腳本對數據實施行列轉置,實現每例患者在同一檢驗日期的所有檢驗項目處于同一行,不同患者的同一個檢驗項目結果處于同一列。獲得4903891條記錄的數據寬表。對數據寬表進行數據清洗、數據類型轉換、數據歸一化操作(數據值壓縮到[0,1]區間,實現字段間統一量綱)。
2.2 方法
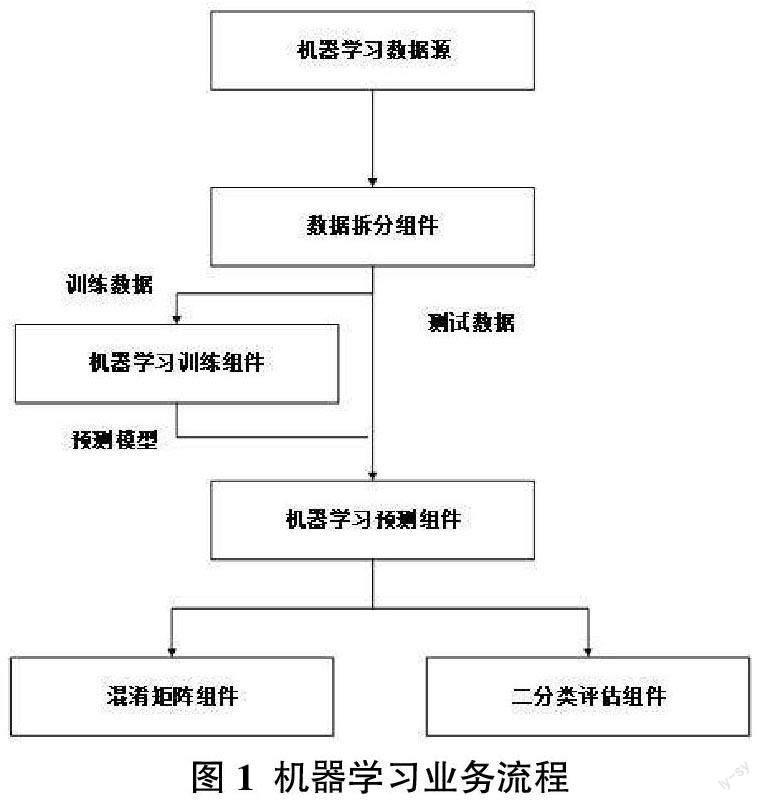
邏輯回歸(Logistic Regression,LR)是用于解決二分類問題的經典機器學習算法[14]。LR模型構造簡單、結果方便易懂,是數據挖掘方法在醫學領域應用的一個典型方法[15]。機器學習數據源首先被讀取到機器學習業務流程,數據源通過數據拆分組件按照一定比例隨機拆分為兩部分數據:一部分訓練數據,另一部分為測試數據。訓練數據導入機器學習訓練組件生成預測模型。測試數據和預測模型分別導入預測組件對測試數據進行預測。預測的結果分別導入混淆矩陣組件和二分類評估組件。對預測模型進行評估,判斷預測模型的可用性。業務流程如圖1所示。
2.3 工具與評估指標
2.3.1工具
大數據平臺Maxcompute用于數據的存儲、計算和管理,大數據治理開發平臺Dataworks用于數據治理、開發,機器學習平臺PAI提供的模塊化組件用于模型開發和統計分析。
2.3.2評估指標
模型評估采用混淆矩陣和二分類評估兩種方法分別評估。
(1)混淆矩陣
混淆矩陣每一列代表一個類的預測情況,每一行表示一個類的實際樣本情況。其中正例樣本數量記為陽性(Positive, P),負例樣本數量記為陰性(Nega?tive,N),被正確預測的正例數量記為真陽性(True Pos?itive, TP),負例樣本被預測呈正例樣本數量記為假陽性(False Positive,FP),正例樣本被預測成負例樣本數量記為假陰性(False Negative, FN),正確預測到的負例樣本數量記為真陰性(True Negative, TN)[17]。如圖2所示。
(2)二分類評估
二分類評估通過計算AUC 和F1-Score 兩項指標對預測模型進行評估。ROC曲線全稱為受試者工作特征曲線(Receiver Operating Characteristic curve,ROC),ROC 的重要特征是曲線下面積(Area Under Curve, AUC),AUC 取值范圍是[0,1], AUC 越接近于1識別能力越強。F1 -Score 與混淆矩陣計算公式相同。
3結果
3.1 甲亢機器學習模型及評估
3.1.1模型特征權重排序
LR二分類模型展示了1355項特征列(檢驗項目)的權重,按照權重降序排列,選擇前20 項,如表1 所示。
其中項目編碼為檢驗項目的唯一編碼、項目名稱為檢驗項目的中文名稱、權重為該檢驗項目在LR二分類模型中的系數,權重數值越大,該檢驗項目與目標列對應診斷結果的相關性越大。項目編碼:s8604 和s6437;s8603、s8003和s5239;s5516和s8002;s8005 和s6440;s8601和s8001均為來自不同檢驗設備的同一個檢驗項目,dep對應的住院或門診表示患者來源。
3.1.2模型預測結果評估
(1)混淆矩陣評估結果
混淆矩陣對測試數據的預測結果進行統計分析,如表2所示。準確率、精確率、召回率、F1- Score 評估結果均在90%以上(大于50%則具有概率意義上的分辨能力)。
(2)二分類評估結果
二分類評估對測試數據的預測結果進行統計分析,如表3所示,AUC 和F1- Score 的結果均大于0.95,表明模型的預測準確性高,可用性強。
3.2 甲減機器學習模型及評估
3.2.1模型特征權重排序
LR二分類模型展示了1355項特征列(檢驗項目)的權重,對權重按照降序排列,選擇前20項。如表4所示。
其中項目編碼為檢驗項目的唯一編碼、項目名稱為檢驗項目的中文名稱、權重為該檢驗項目在LR二分類模型中的系數,權重數值越大,該檢驗項目與目標列對應診斷結果的相關性越大。項目編碼:s8604、s6437和s5240;s8603、s8003和s5239;s8002和s5516;s6440、s5241和s8005均為來自不同檢驗設備的同一個檢驗項目,dep對應的住院或門診表示患者來源。
3.2.2模型預測結果評估
(1)混淆矩陣評估結果
混淆矩陣對測試數據的預測結果進行統計分析,如表5所示。準確率、精確率、召回率、F1-Score 評估結果均在95%以上。
(2)二分類評估結果
4結論
本研究對某醫院近5年的全量醫學檢驗數據進行治理、開發形成數據寬表。在此基礎上采用機器學習邏輯回歸二分類算法構建并驗證了甲亢和甲減的預測模型。
對預測模型中部分檢驗項目與他人研究成果進行比對,在甲亢和甲減的兩個模型中FT4的權重均位居第一,表明FT4與診斷結果的強相關關系。多項研究表明FT4 與TSH 是檢測甲狀腺疾病的優選指標[18-20]。在本研究的甲亢相關權重中,肝功能指標中的谷草轉氨酶和間接膽紅素也位列其中,證明了甲亢對肝功能的影響。谷草轉氨酶與甲狀腺激素水平大致呈正相關,說明在一定程度上甲亢合并肝損害程度越重,甲狀腺激素水平也越高[21-22]。研究發現甲亢、甲減患者的血糖水平與正常體檢者比較差異具有統計學意義(P<0.05),甲狀腺功能減退癥患者的糖化血紅蛋白水平顯著高于對照組[23-24]。有研究發現中性粒細胞與甲減發生率密切相關,中性粒細胞聯合性別、甲狀腺體積等其他檢測指標采用邏輯回歸算法可以預測甲減發生率(AUC=0.777)[25]。
綜合以上國內外研究成果,在對1355項特征列的機器學習構建的預測模型在具有較高輔助診斷能力的基礎上,按照權重降序排列的甲亢和甲減的前二十項特征大部分與臨床診斷研究結果吻合。說明了預測模型的輔助診斷可用性和可解釋性。預測模型中每個權重描述相應預測變量對結果的貢獻大小,并不是獨立的決定因素。需要包括上述20項在內的1355 項特征列構成的完整LR二分類模型發揮整體作用。考慮到真實數據的分布情況,本研究沒有對來自不同檢測設備對同一個檢驗項目的重復數據進行合并處理,這必然會影響到具體的檢驗項目的真實權重,另一方面,同一個檢驗項目的權重基本相同也進一步佐證了機器學習發掘的與診斷結果強相關檢驗項目的可信度。未來可以對同一個檢驗項目合理去重后進一步研究驗證預測模型,從而糾正目前一些數據不規范的影響。由于整個預測模型是將所有檢驗項目都納入預測計算的范圍,比單項或少數指標更能反映病人的真實情況,減少了醫生綜合判斷時若干項指標矛盾或不符時帶來的困惑,在未來人工智能診斷及療效評估中有著重大的意義和應用前景。二分類評估對測試數據的預測結果進行統計分析,如表6所示,AUC 和F1-Score 的結果均大于0.95,表明模型的預測準確性高,具有較好的可用性。
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
