基于輕量級卷積神經網絡的小樣本虹膜圖像分割
2023-05-21 03:53:30林大為劉元寧朱曉冬
吉林大學學報(理學版) 2023年3期
霍 光,林大為,劉元寧,朱曉冬,袁 夢
(1.東北電力大學 計算機學院,吉林 吉林 132012; 2.吉林大學 計算機科學與技術學院,長春 130012; 3.吉林大學 符號計算與知識工程教育部重點實驗室,長春 130012)
虹膜識別可用于安防、國防和電子商務等領域[1],具有方便、穩定、獨特等特點.虹膜識別系統包括虹膜圖像采集、預處理、虹膜分割、虹膜歸一化、虹膜特征提取和虹膜匹配驗證[2].虹膜分割的精度直接影響虹膜圖像識別的準確率.目前虹膜分割方法主要分為傳統的分割方法和基于卷積神經網絡的分割方法.
傳統的虹膜分割方法主要包括基于Hough變換的算法[3]和基于梯度微分的算法[4].許多后續的傳統算法都使用微積分算子變體[5]和Hough變換變體[6]定位虹膜邊界.傳統方法不需要大量的圖像樣本訓練模型參數,但在非理想的拍攝條件下,采集的虹膜圖像可能包含了光斑、睫毛遮擋、眼瞼遮擋等噪聲,這些噪聲會嚴重影響虹膜識別的準確率.
為解決傳統方法的不足,虹膜分割領域開始結合卷積神經網絡方法,并取得了較好的成果.目前,大部分虹膜分割模型使用FCN(fully convolutional networks)[7]和UNet(U-shaped networks)[8]作為基準網絡.為提高模型的魯棒性,Chen等[1]提出了一種基于FCN和密集連接塊相結合的架構,雖然該模型有效降低了無關噪聲對模型的干擾,但該模型的可訓練參數高達142.5×106.隨著神經網絡的加深,需要學習的參數也會隨之增加.當數據集較小時,過多的參數會擬合數據集的所有特點,并非數據之間的共性,從而導致過擬合現象.因此,復雜的虹膜分割算法無法在小樣本數據庫上最大限度地發揮卷積神經網絡的性能.
目前解決小樣本學習主要通過數據增強和減少網絡參數兩種方法.數據增強是對原始數據采用縮放、裁剪、平移等方式增加訓練集的數量.該方法應用于深度學習中的各領域.但在虹膜分割領域,使用數據增強后的數據集訓練網絡不僅不能提升模型的擬合能力,還會大幅度增加模型的訓練時間.因此,減少網絡參數已成為解決小樣本虹膜分割的主要方法.Huo等[2]和周銳燁等[9]通過使用輕量級網絡替換傳統卷積的方法減少網絡參數,雖然該方法可明顯減少網絡的參數量,但這些分割模型的可訓練參數仍超過2×106.因此,如何在少量數據庫上訓練好模型的參數,是小樣本虹膜分割面臨的挑戰.基于此,本文提出一個適用于小樣本數據集的虹膜分割模型.
1 網絡模型的設計
1.1 整體結構設計
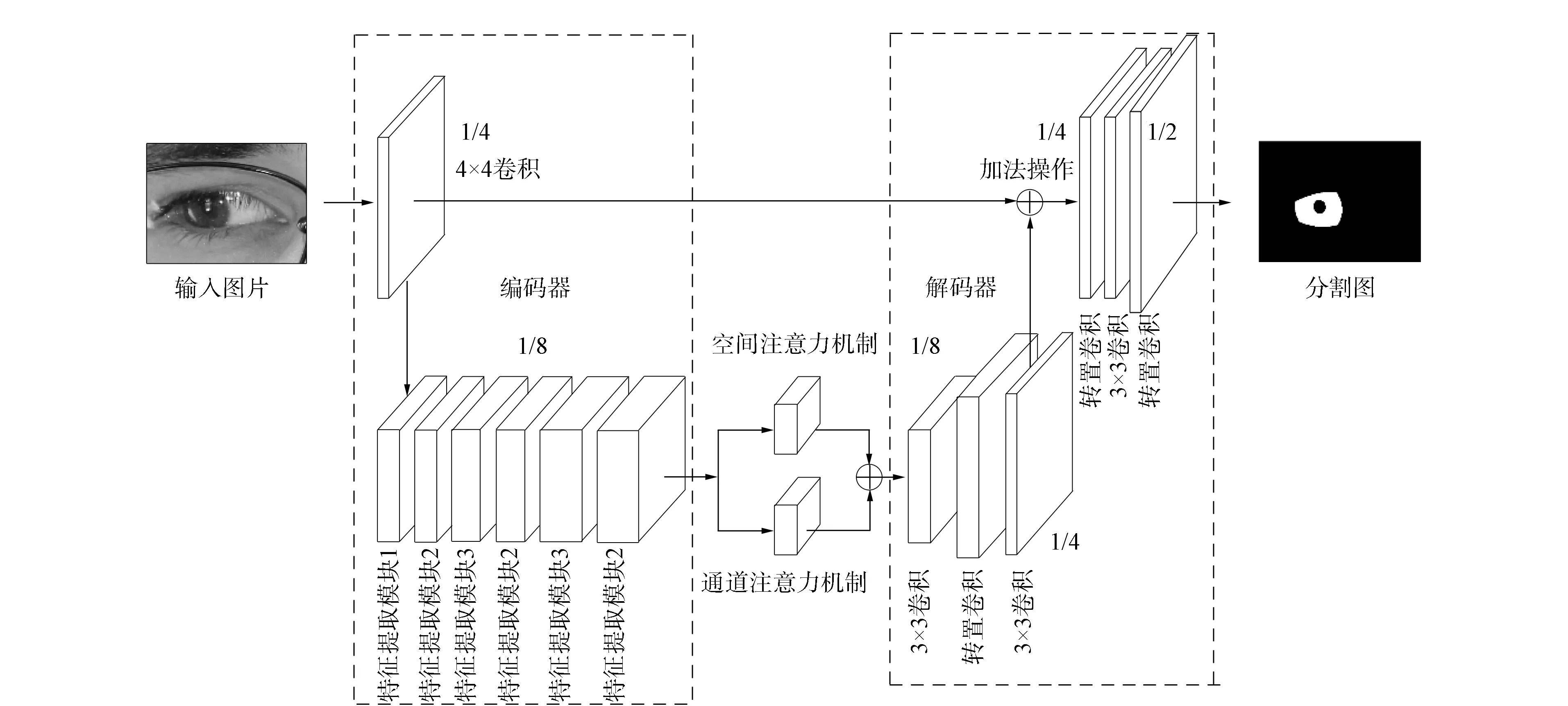
圖1 本文模型的整體網絡結構Fig.1 Overall network structure of proposed model
本文網絡模型的整體結構如圖1所示,模型的實現細節列于表1.網絡模型由編碼器、解碼器和注意力機制組成.編碼器用于提取虹膜圖像的特征信息,解碼器用于將特征信息轉化為語義信息.
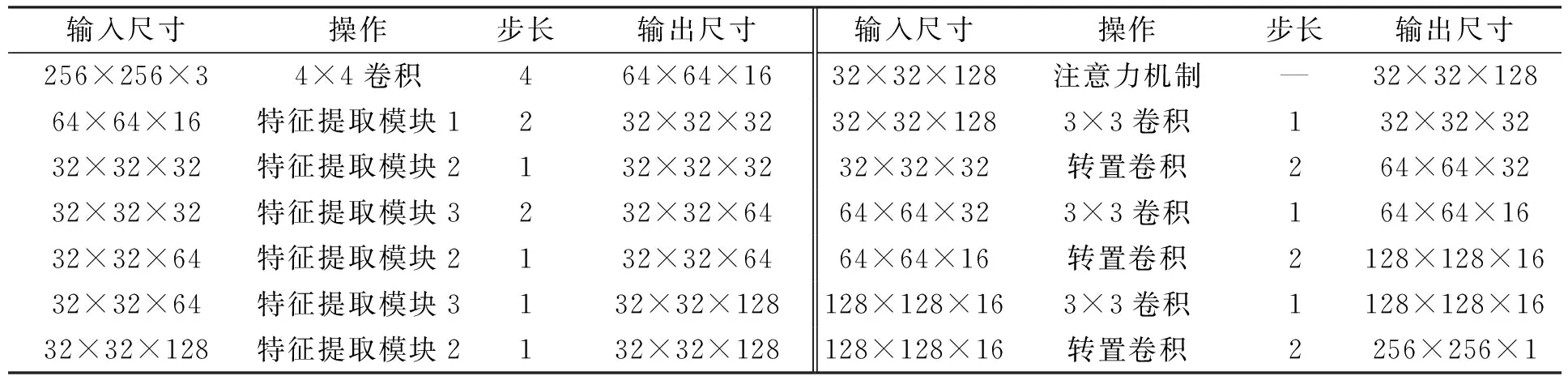
表1 本文模型結構實現細節
1.1.1 編碼器
輸入圖像首先經過4×4卷積層,其卷積核的數量為16,步長為4.在網絡下采樣后期階段使用傳統的3×3卷積層和5×5卷積層會引入大量的模型參數.深度可分離卷積通過采用逐通道卷積和逐點卷積執行卷積運算.在網絡中使用深度可分離卷積能在保證特征提取能力的前提下,大幅度降低網絡的可訓練參數.本文基于深度分離卷積設計3個特征提取模塊: 特征提取模塊1~3.特征提取模塊結構如圖2所示.模塊1由兩個深度可分離卷積層和兩個1×1卷積層組成.其中第一個1×1卷積層用于減少特征圖的通道數,第二個深度可分離卷積層用于縮小特征圖的寬和高為原來的1/2.因為模塊2輸出特征圖的維度與輸入特征圖的維度一致,所以輸入特征圖與輸出特征圖通過相加操作進行融合.通過這種連接可有效減少梯度消失問題.模塊3輸出的特征圖維度在高度和寬度方向保持不變,深度方向增加.通過增加網絡的深度可學習到更豐富的特征信息.網絡通過兩次下采樣操作將特征圖變為原來的1/16.
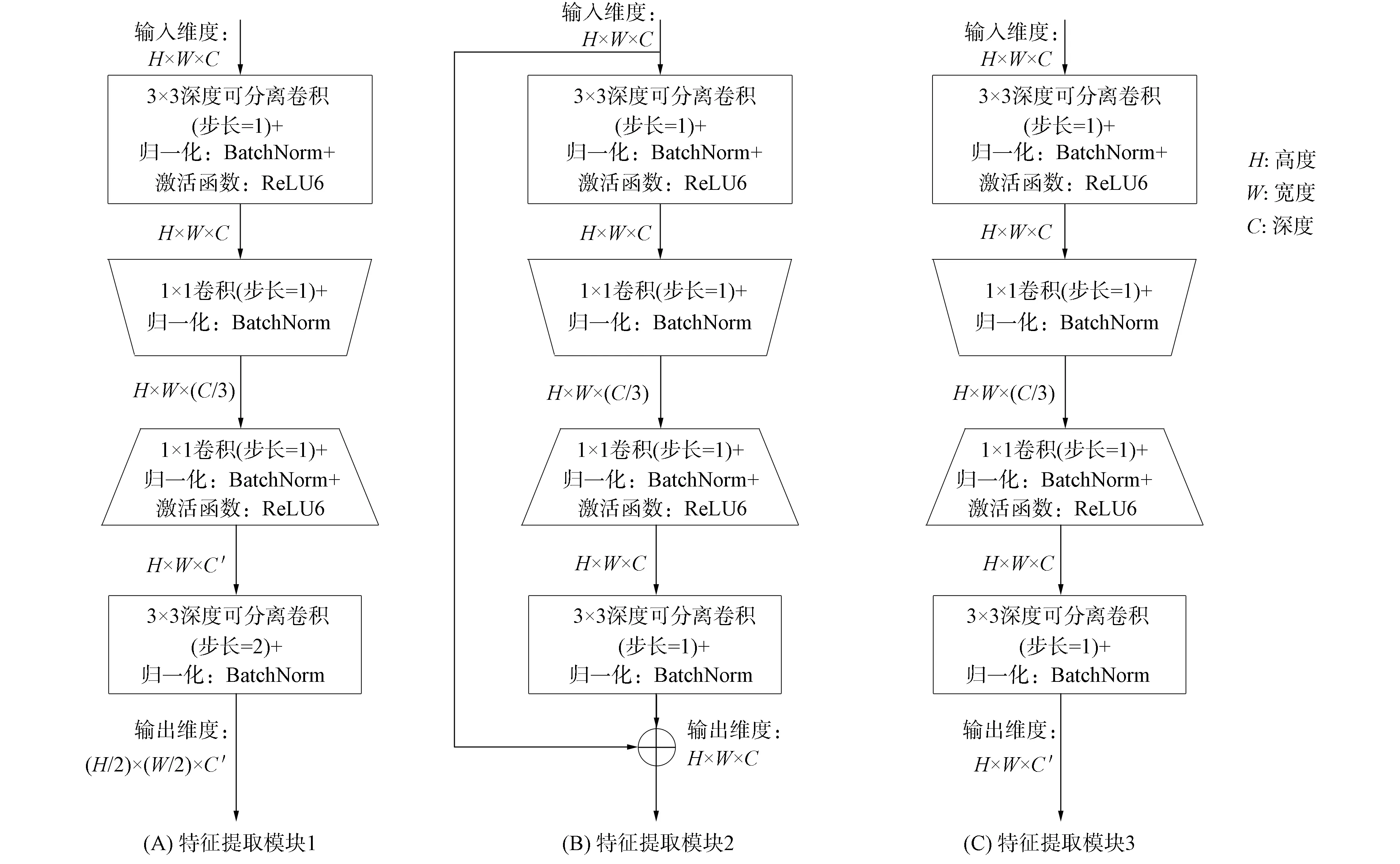
圖2 特征提取模塊的設計Fig.2 Design of feature extraction module
1.1.2 注意力機制
注意力機制由空間注意力機制和通道注意力機制組成.空間注意力機制用于增加模型的感受野,提取更豐富的上下文特征信息; 通道注意力機制用于增加模型對虹膜區域通道的學習能力,降低對無關噪聲的響應能力.
1.1.3 解碼器 特征圖通過一系列的卷積層和轉置卷積層逐步恢復到原始尺寸.3×3卷積層用于將提取到的特征信息轉化為語義信息,轉置卷積用于增大特征圖的寬和高為原來的2倍.為減少特征信息丟失,編碼器通過跳躍連接與解碼器相連.預測的分割圖為二值圖像,其中1表示虹膜區域,0表示非虹膜區域.
1.2 注意力機制
在非理想條件下拍攝的虹膜圖像可能會包含大量無關噪聲.隨著下采樣次數的增加,虹膜圖像的空間特征信息會逐漸丟失.這些都會影響虹膜分割的準確率.為解決上述問題,本文在編碼器和解碼器之間加入了通道和空間注意力機制,該模塊的結構如圖3所示.輸入模塊的特征圖維度為H×W×C,其中H,W,C分別表示特征圖的寬、高和通道數.
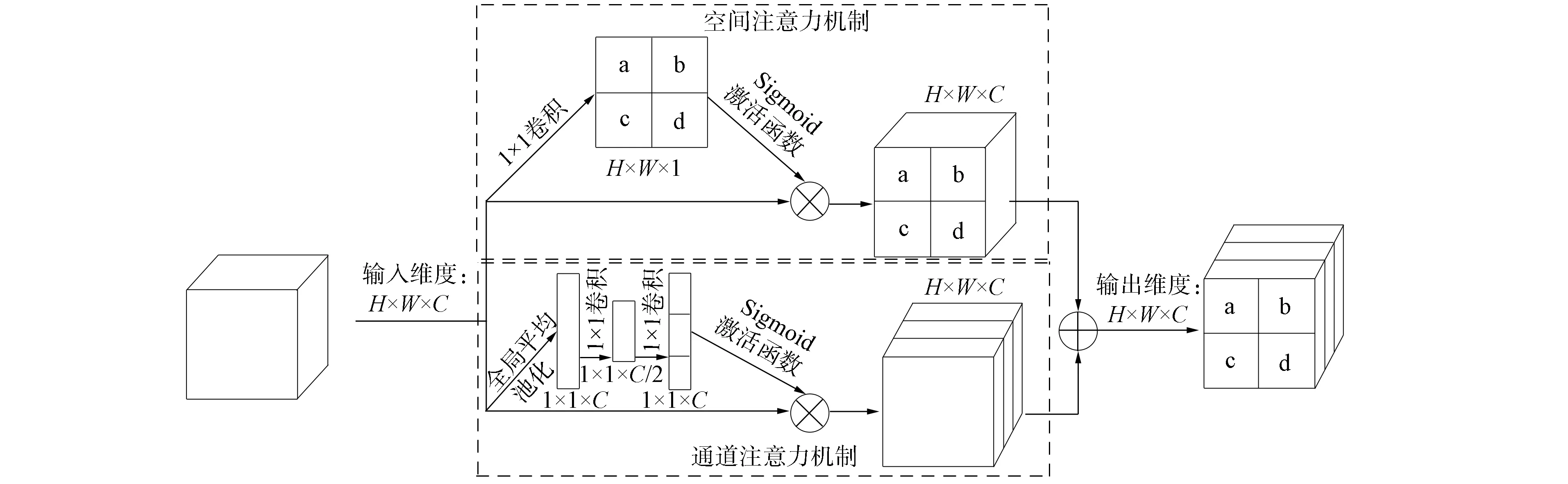
圖3 注意力機制模塊結構Fig.3 Attention mechanism module structure
空間注意力機制: 先輸入特征圖通過1×1卷積層將特征圖的通道數壓縮到1; 然后輸出的特征圖通過Sigmoid激活函數得到空間注意力圖; 最后將空間注意力圖與輸入特征圖相乘完成空間信息的校準.
通道注意力機制: 先輸入特征圖通過全局平均池化得到維度為1×1×C的特征圖.使用全局平均池化可幫助模型捕獲全局信息,通過兩個1×1卷積層對特征圖進行信息處理,最終得到維度為1×1×C的特征圖; 然后特征圖通過Sigmoid激活函數進行歸一化,對通道賦予不同的權重; 最后與輸入特征圖相乘,得到經過加權的特征圖.
空間注意力機制輸出的特征圖與通道注意力機制輸出的特征圖通過相加操作實現信息融合.該注意力機制不僅考慮了通道和空間信息,還考慮了方向和位置信息.該模塊在不明顯增加參數量的條件下,將網絡模型的注意力更多關注于虹膜區域.
2 實驗結果及分析
2.1 數據集
實驗在虹膜數據庫UBIRIS.V2[10]上進行.UBIRIS.V2數據庫中虹膜圖像是在非合作條件下拍攝的.因為該數據庫中的大量虹膜圖像包含各種無關噪聲,所以是最具有挑戰性的公共虹膜數據庫之一.本文將數據庫按7∶1∶2分為訓練集、驗證集和測試集三部分.其中: 小樣本數據庫1中訓練集的數量為280張,驗證集的數量為40張,測試集的數量為80張; 小樣本數據庫2中訓練集的數量為560張,驗證集的數量為80張,測試集的數量為160張; 大樣本數據庫中訓練集的數量為1 575張,驗證集的數量為225張,測試集的數量為450張.
2.2 訓練參數
本文實驗環境基于Pytorch深度學習框架.硬件設備為NVIDIA 1080Ti GPU,11 GB顯存.采用Adam優化器,初始學習率設為0.01,第一次衰減率設為0.9,第二次衰減率設為0.999.每次訓練從訓練集中取16個樣本進行訓練,選擇Dice損失函數[11]訓練網絡.
2.3 評價指標
本文通過參數量衡量模型的復雜程度.參數量即模型的可訓練參數,模型的參數量越大,訓練模型所需的數據量就越大.為衡量模型的分割精度,本文選擇平均交并比(mean intersection over union,MIOU)和F1得分(F1)作為評價指標,計算公式如下:

(1)
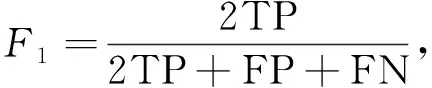
(2)
其中TP表示真陽性樣本的數量,FP表示假陽性樣本的數量,FN表示假陰性樣本的數量,TN表示真陰性樣本的數量.MIOU和F1值介于0~1之間,MIOU和F1值越接近于1表示模型的分割精度越高.
2.4 不同算法性能比較
在UBIRIS.V2數據庫上,將本文算法與傳統算法Caht[12],Ifpp[13],Wahet[14],Osiris[15],IFPP[16]和基于卷積神經網絡的算法Linknet[17],PI-Unet[9],DMS-UNet[2]性能進行對比,結果分別列于表2和表3.基于神經網絡的分割方法在3個數據庫上的損失衰減曲線如圖4所示.為更好觀察算法的性能,本文可視化了所提方法與基于神經網絡方法在小樣本數據庫1上的分割結果,對比結果如圖5所示.

表2 本文算法與傳統算法的對比結果
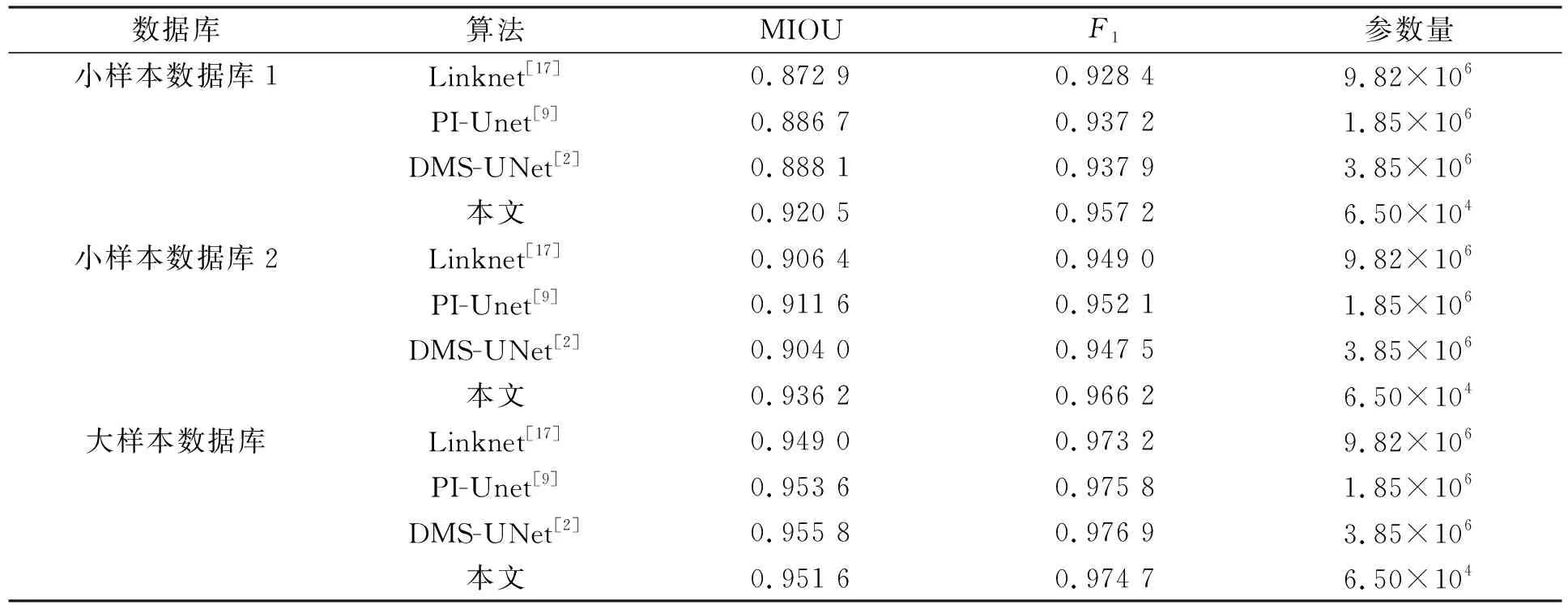
表3 本文算法與基于深度學習算法的對比結果
本文所選數據庫是在非合作環境下拍攝的,因此虹膜圖像中包含了大量無關噪聲.實驗結果表明,傳統算法在非理想虹膜數據集上的表現較差,難以準確分割出虹膜邊界.相比于傳統算法,本文模型大幅度提高了分割精度.
損失表示模型在訓練集上的預測結果與真實標簽之間的誤差.不同算法在小樣本數據庫上損失和準確率的變化曲線如圖4所示.由圖4可見,相比于其他算法,本文算法的損失曲線隨著迭代次數的增加而快速收斂,曲線穩定,沒有明顯震蕩,表明本文算法在小樣本數據集上有效地學習了虹膜圖像的特征,未發生過擬合現象.
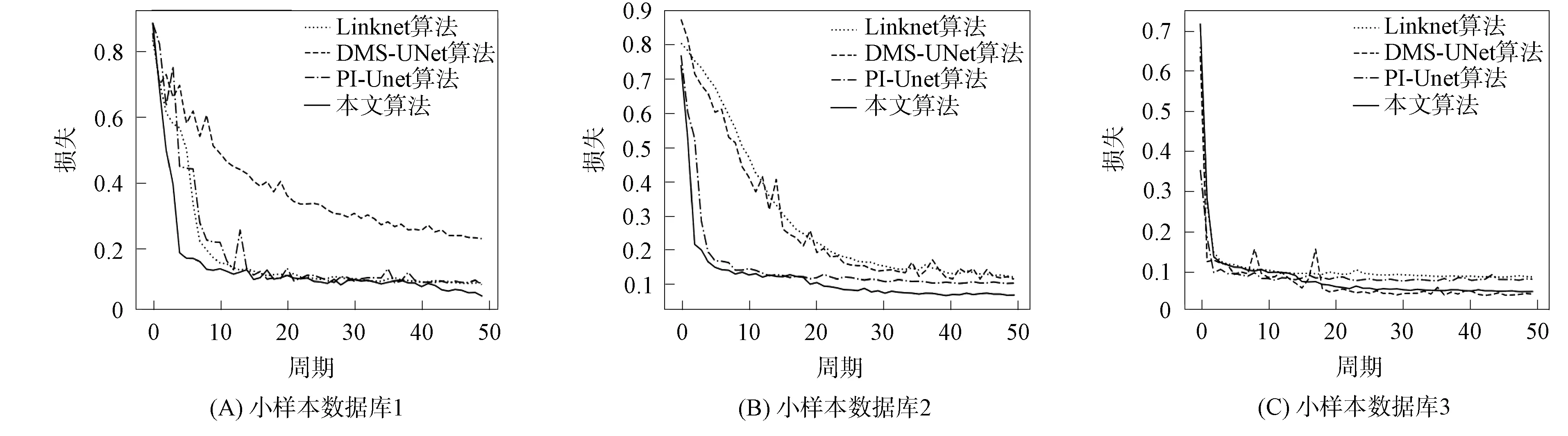
圖4 不同算法在小樣本數據庫上損失和準確率的變化曲線Fig.4 Variation curves of loss and accuracy of different algorithms on small sample database

圖5 不同算法在小樣本數據庫1上的分割結果Fig.5 Segmentation results of different algorithms on small sample database 1
由圖5可見,其他虹膜分割算法未準確分割出瞳孔區域.這是因為在網絡執行下采樣操作中,瞳孔區域特征隨之丟失.因為本文算法僅采用兩次下采樣操作,并且加入了空間注意力機制關注虹膜區域,因此該算法可準確地分割出瞳孔區域.本文算法分割出的虹膜內外邊界更平滑、像素錯分率更低、分割結果更接近于真實標簽.
在小樣本數據庫1上的結果表明,與最新的輕量級虹膜分割模型PI-Unet相比,本文算法的MIOU和F1分別提高了3.81%和2.13%; 與高性能的虹膜分割模型DMS-UNet相比,本文算法的MIOU和F1分別提高了3.65%和2.06%.本文網絡在小樣本數據庫2上的虹膜分割精度均優于其他分割方法.
在大樣本數據庫上的結果表明,本文網絡的分割精度略低于DMS-UNet和PI-Unet.與PI-Unet相比,本文網絡的參數量下降了96.49%; 與DMS-UNet相比,本文網絡的參數量下降了98.31%.DMS-UNet和PI-Unet具有更深的網絡深度和更多的卷積核數量,因此這些網絡具有更多的可訓練參數.額外的網絡參數量能存儲更豐富的特征信息以增加網絡的分割精度.
不同網絡方法在小樣本數據庫和大樣本數據庫上的對比結果如圖6所示.由圖6可見,隨著訓練樣本數量的增加,網絡的分割精度也隨之增加,這是因為網絡參數在大樣本數據庫下可得到更充分的訓練.本文網絡在小樣本數據庫上的分割精度優于其他方法,在大樣本數據庫上取得了較好的虹膜分割精度.
2.5 消融實驗
為驗證注意力機制的有效性,本文將通道注意力機制模塊(squeeze and expand,SE)[18]、通道-空間注意力機制模塊(convolutional block attention module,CBAM)[19]、空間注意力機制模塊(coordinate attention,CA)[20]與本文的注意力機制模塊進行對比,其中基準網絡不加任何注意力機制模塊.為進行公平的比較,其他注意力機制模塊與本文模塊都在分割網絡的編碼器和解碼器之間引入,不同注意力機制的對比實驗結果列于表4.

表4 不同注意力機制對網絡性能的影響
由表4可見,在基準網絡中加入SE模塊和CA模塊使基準網絡的MIOU值分別提高了0.64%和0.76%,在分割網絡中加入CBAM模塊未提高網絡的分割精度.相比于使用SE模塊和CA模塊,本文網絡的MIOU值分別提高了2.13%和2.01%.實驗結果表明,本文網絡的注意力機制可有效提高網絡的分割精度.
為驗證注意力機制融合方式的有效性,本文設計4種不同的網絡結構進行消融實驗,其中基準網絡中不含注意力機制.本文對空間-通道注意力機制采用串聯和并聯兩種方式融合,其中串聯方式有兩種: 通道注意力機制在前,空間注意力機制在后; 空間注意力機制在前,通道注意力機制在后.注意力機制不同融合方式消融實驗的結果列于表5.

表5 注意力機制不同融合方式的實驗結果
由表5可見,注意力機制采用串聯的融合方式并不會增加網絡的分割精度.這是因為不恰當的融合方式會影響特征圖的數據分布,干擾特征圖中有效信息的表達.相比于兩種串聯方式的分割精度,使用并聯方式的MIOU值分別提高了3.74%和3.13%.因此本文采用并聯的方式融合兩種注意力機制輸出的特征圖.
為驗證本文算法的各模塊在提高虹膜分割性能方面的有效性,設計4種不同的網絡進行消融實驗,其中基準網絡中不含注意力機制.4種網絡在相同測試集上的分割精度列于表6,分割結果如圖7所示.由表6可見,相比于基準網絡,加入注意力機制網絡的MIOU分別提高了2.12%和1.70%.在雙注意力機制的作用下,本文算法獲得了最高的分割精度.在不明顯提升參數量的前提下,本文算法的分割精度相比于基準網絡分別提升了2.78%和1.55%.

表6 不同模型的消融實驗結果
不同模型基于不同模塊的分割結果如圖7所示.由圖7可見,基準網絡無法準確分割出瞳孔區域.實驗結果表明,加入注意力機制可在很大程度上解決上述缺陷.基于空間注意力機制的模型雖然可分割出瞳孔區域,但預測的分割圖中包含許多無關噪聲.加入通道注意力機制可在訓練階段學習通道之間的相關性,抑制光斑和遮擋等無關噪聲的干擾,加強虹膜區域的權重.

圖7 不同模型基于不同模塊的分割結果Fig.7 Segmentation results of different models based on different modules
綜上所述,針對復雜網絡在小樣本數據集上訓練易發生過擬合的現象,本文提出了一個適用于小樣本數據庫的輕量級虹膜分割模型.在編解碼結構的基礎上,設計了一個高效的特征提取網絡; 空間注意力機制模塊用于關注虹膜區域和提取豐富的上下文特征信息; 通道注意力機制模塊用于提高模型對無關噪聲的抗噪能力.消融實驗結果表明了本文使用不同模塊的有效性.對比實驗結果表明,本文模型在小樣本虹膜數據集上不僅取得了最優的分割精度,而且需要更少的模型參數.在分割結果上,本文算法能在含有噪聲的虹膜圖像中分割出更多的邊緣細節,分割的圖像更接近于真實標簽.因此,本文模型在小樣本虹膜數據庫上具有良好的應用價值.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2018年21期)2018-11-09 01:23:06
財經(2017年2期)2017-03-10 14:35:35
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中國衛生(2015年9期)2015-11-10 03:11:12
