基于深度學習的端到端人崗匹配模型
2023-05-18 08:14:12魏嘉銀盧友軍
智能計算機與應用 2023年4期
朱 瑜, 魏嘉銀, 盧友軍, 王 琳, 江 漫
(貴州民族大學 數據科學與信息工程學院, 貴陽 550025)
0 引言
為了找到滿足崗位需求的人才,傳統方法是由招聘人員手動審查求職者的簡歷,以決定是否提供面試機會。 然而,面對海量的簡歷,招聘人員不得不花費大量的時間和精力篩選簡歷,優中選優以便能夠找到合適的求職者。 傳統的簡歷審查方式存在招聘速度慢、成本高等問題。 因此,如何從簡歷中挖掘出求職者自身的價值并將其與已有的職位相匹配成為一個亟待解決的問題,這個問題則稱為人崗匹配問題。
職位推薦作為人才招聘中的一項重要任務,已經有許多學者對其進行研究。 早期研究者根據用戶的學歷以及用戶在每個職位上的點擊、瀏覽時間等交互信息,采用協同過濾等推薦算法向用戶推薦職位[1]。 早期方法忽視了工作和簡歷文檔的文本語義信息,因此,為了充分利用簡歷和職位要求中豐富的文本語義信息,大多數研究將人崗匹配任務視為文本匹配任務,就是將工作描述和簡歷內容表示為維數相同的隱藏向量,然后計算2 個向量的匹配得分,并據此預測簡歷與職位的匹配程度[2]。
CNN 作為近年來最流行的深度學習算法之一,已被廣泛應用于人崗匹配領域。 Nasser 等學者[3]將簡歷分為不同的類別,并提出了一個CNN 模型,將簡歷與工作配對。 Zhu 等學者[4]提出了一個PJFNN模型,將簡歷和職位描述中嵌入的每個詞分別用2個CNN 模型進行建模,并利用簡歷和職位之間的余弦相似度計算匹配分數。 Khatua 等學者[5]使用Twitter 中的雙卷積網絡來匹配招聘人員和求職者。雖然CNN 模型提取局部特征效果較好,但是容易忽略單詞之間的順序和關系,導致語義特征提取不夠準確[6]。 LSTM 可以更有效地處理文本信息,更高效地挖掘文本潛在的語義信息,緩解梯度爆炸問題。于是,Zhou 等學者[7]將LSTM 應用于文本分類領域,提高了文本分類的準確度。 Qin 等學者[8]將分層RNN 模型應用于工作文檔,提出了一種基于分層能力感知注意力機制的循環神經網絡結構來學習文本的語義表示。 Jiang 等學者[9]通過LSTM 模型學習求職者和招聘人員的隱含意圖,結合語義生成求職者和招聘人員的有效表示。 為了充分發揮CNN與RNN 提取特征時的優勢,許多研究者將CNN 與LSTM 結合使用,以便提高模型提取特征的能力。如:李超凡等學者[10]提出了一種基于注意力機制結合CNN-BiLSTM 的文本分類模型,解決了中文電子病歷文本高度稀疏且分類效果不佳的問題。 吉興全等學者[11]使用CNN 與LSTM 對短期電價進行預測,提高了電價預測的精度及預測效率。 任建吉等學者[12]針對電網數據具有非線性和時序性的特點,將CNN 與BiLSTM 結合提取數據本身的時空特征,提高了模型的預測精度。 以上模型雖然提升了模型提取特征的效果,但大多采用遞進式網絡結構,導致提取到的信息向后傳遞時容易發生梯度消失或梯度爆炸的問題,同時遞進式網絡結構提取文本特征時只用到單一網絡的優勢,無法融合CNN 和RNN 提取文本信息的優勢,因此最終效果有待提升。
為了提高人崗匹配的效果,本文提出一種端到端的人崗匹配模型BATPJF,該模型采用并列式網絡結構,充分發揮了CNN 提取局部特征的優勢與BiLSTM 記憶功能的優勢,有效改善了模型的整體結構,提升了人崗匹配的效果。
1 模型構建
1.1 問題定義
令jobi={jobi,1,jobi,2,…,jobi,p} 為一條崗位招聘信息,其中jobi,j(j∈[1,p]) 為具體的崗位需求或職責,令表示崗位jobi,j的信息中包含的s個詞。 又令ri={ri,1,ri,2,…,ri,q} 表示一份簡歷,其中ri,j(j∈[1,q]) 表示該簡歷包含的具體工作經歷,再令表示工作經歷ri,j的信息中包含的u個詞。 給 定 一 組 數 據S =〈J,R,Y〉, 其 中,J =為 招 聘 信 息,R =為簡歷信息,Y為招聘結果標簽。 本文的目標是訓練一個匹配函數M,并根據M來快速精準地預測一份簡歷ri與jobj之間的匹配結果。 由于人崗匹配問題很難直接得到一個絕對的匹配分數,且很可能會導致過擬合和模型偏差[13],因此采用Top-K 的方法優化排名。
1.2 模型概述
本文提出的模型BATPJF 主要由TextCNN 網絡、BiLSTM-Attention 網絡、融合層和匹配預測層構成。 模型的總體框架如圖1 所示。
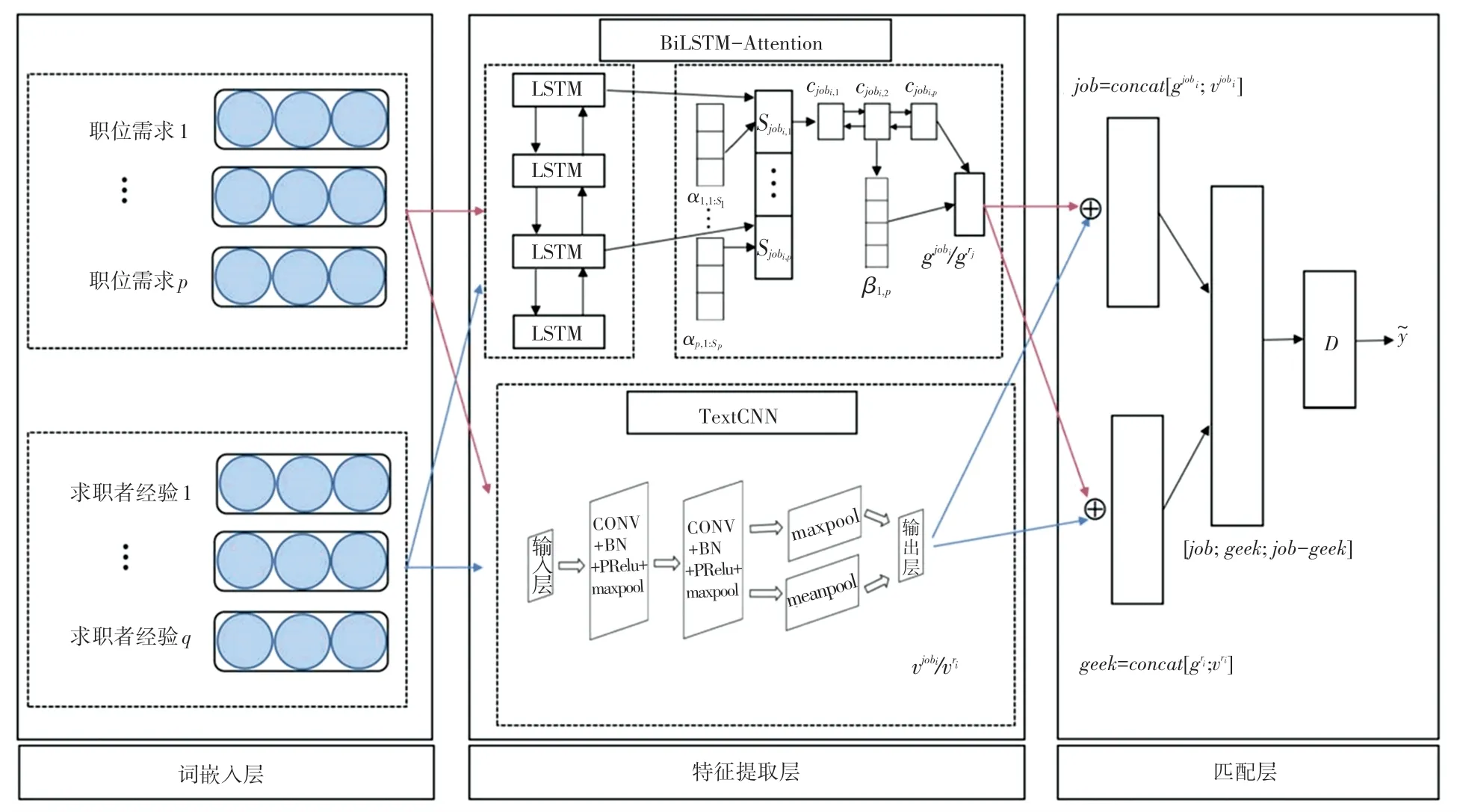
圖1 BATPJF 模型圖Fig. 1 Structure diagram of BATPJF
考慮到職位描述和簡歷中包含大量描述職位要求或求職者經歷的詞語,而TextCNN 在捕捉文本數據的層次關系和局部語義方面效果較好,因此本文運用TextCNN 模型用于提取數據中的關鍵性詞語。卷積層與池化層的交替結構對于數據特征的提取是有效的,因此在TextCNN 中,使用卷積層和最大池化層以交錯堆疊的方式自動提取職位描述和簡歷文本數據的局部特征,并將所得特征向量輸出。
TextCNN 模型通過卷積核提取輸入文本的局部特征,但是濾波器的大小限制了模型學習文本數據前后的依賴關系。 所以本文使用BiLSTM-Attenion模型用于提取文本上下文依賴關系并分別對不同的詞和句子分配相應的權重。 具體如下:首先使用BiLSTM 分別獲取簡歷和職位描述的詞級別的文本表征,然后將文本表征作為注意力機制層的輸入來預估每個單詞的重要性,接著根據每個能力要求的隱藏狀態和所有能力要求的上下文向量之間的相似性計算出每個能力要求的重要性并輸出。
最后,將TextCNN 模型捕捉到的局部特征,以及經過并行的BiLSTM-Attenion 模型提取到的上下文特征進行特征拼接后,輸入到全連接層,并經由Softmax層輸出結果。
1.3 TextCNN 層
TextCNN 主要由輸入層、卷積層、歸一化層和池化層構成。 本文以崗位描述部分為例進行說明。TextCNN 層模型如圖2 所示。
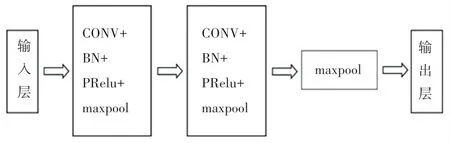
圖2 TextCNN 層Fig. 2 TextCNN layer
對于jobi,j中的第l條需求中的第t個詞的d0維詞向量于是第l項需求對應的矩陣可表示為。 首先,使用卷積層提取第l項需求的文本特征,然后對卷積層的輸出應用批歸一化處理以降低訓練成本,接著運用Prelu激活函數對輸出值做非線性變換操作,最后使用池化層壓縮提取到的特征以減少模型的計算量,同時增加模型識別特征的抗干擾能力。在此基礎上,將所有需求項的向量通過最大池化層投 影 到 一 個 向 量 上:vjobi=[max(vjobi,1),max(vjobi,2),…,max(vjobi,p)],以表示職位描述。
簡歷部分的模型與崗位部分的相似。 唯一不同的是最后一層使用均值池化將求職者經驗表示集成到簡歷表示中。 對此可用如下公式進行描述:
1.4 BiLSTM-Attention 層
1.4.1 BiLSTM
LSTM 模 型 是Hochreiter 等 學 者[14]為 了 解 決RNN 模型因處理信息過多導致的梯度消失或梯度爆炸問題提出的模型。 BiLSTM 作為LSTM 的一種變體,由一個正向LSTM 和一個反向LSTM 模型拼接而成。 其結構如圖3 所示。首先獲得招聘信息中jobi,j的詞向量表示:其中,表示第l條需求中第t個詞的d0維詞嵌入,We是參數矩陣,表示jobi中第l條需求的第t個詞向量。 對jobi,l中的每個詞,計算對應的語義表征可表示為:。 同理,可得R對應的語義表征:

圖3 BiLSTM 結構圖Fig. 3 Structure diagram of BiLSTM
1.4.2 注意力層
在自然語言處理領域,注意力機制被用來為不同重要性的詞或句子分配權重,權重越大的詞越重要。將經過BiLSTM 處理后的語義表征作為全連接層的輸入,計算字符級別文本向量間的關聯度,然后使用Softmax函數計算注意力分數α,即:
其中,vα、Wα和bα分別表示訓練過程中的可學習參數;vα表示jobi,l的上下文向量。 接著通過式(5)計算詞級別的崗位需求表征:
再將詞級別的崗位需求表征{sjobi,1,sjobi,2,…,sjobi,p} 作為BiLSTM 層的輸入,并可推得:
運算得到隱層狀態向量{cjobi,1,cjobi,2,…,cjobi,p},此后根據每個能力要求的隱藏狀態和所有能力要求的上下文向量間的相似性計算出每個能力要求的重要性βt,即:
其中,Wβ、bβ和vβ是可學習參數,最后句子級別的崗位需求表征可用式(9)計算:
同理可得簡歷的需求表征為:
1.5 匹配預測層
將TextCNN 層輸出的職位需求向量vjobi與通過BiLSTM-Attention 表示的職位向量gjobi進行融合,即job =concat[gjobi;vjobi],同理可以得到簡歷的特征為geek =concat[gri;vri]。 為了預測彼此之間的匹配程度,將其輸入全連接網絡預測人崗匹配程度,即:
其中,Wd、bd、Wy、by是可學習參數。
2 實驗結果與分析
2.1 數據集描述
為驗證BATPJF 模型的有效性,實驗使用智聯招聘人崗匹配數據集。 為保護用戶隱私,所有簡歷都做了脫敏處理。 原始數據集包含4500 份簡歷、269534 份招聘信息和700938 條申請記錄,在剔除職位描述為空、沒有成功申請的數據之后,最終數據集見表1。 將數據集按8 ∶1 ∶1 的比例劃分為訓練集、測試集和驗證集。 本文為每個正樣本均勻地抽取一個負樣本組成訓練集。

表1 數據集的基本統計信息Tab. 1 Basic statistics of data set
由表1 的交互(申請、成功、失敗)記錄可知,成功率僅約為4%,這從側面反映了人才招聘工作的困難,而這正是本文工作的意義與價值所在。
2.2 實驗描述
本文以申請成功的工作-簡歷對作為正樣本,以未申請成功的工作-簡歷對作為負樣本對模型進行訓練。 以下是實驗中的一些基礎設置:batch_size設置為128,epoch設置為300。 測試集的大小設置為128,驗證集的大小設置為1024,若驗證集上的評估結果連續10 個epoch沒有增加,訓練將提前停止。 為了盡可能地避免過擬合現象的發生,將drop_out設置為0.5,并在TextCNN、BiLSTM 中分別選擇Prelu、LeakyRelu作為激活函數,以提高模型的非線性表達能力并加速模型收斂速度。 為了更好地學習模型參數,選擇Adam 作為優化器進行訓練。模型的具體參數見表2。

表2 參數設置表Tab. 2 Parameters setting
2.3 實驗結果
為驗證本文提出的BATPJF 模型性能,將其與BPR[15]、 BPJFNN[16]、 APJFNN[16]、 LightGCN[16]、PJFFF[17]模型進行比較,評價指標主要采用命中率(Hit Rate @ k,HR) 和 歸 一 化 折 損 累 計 增 益(NDCG@k) 來綜合判斷模型的性能。 實驗結果見表3。 表3 中,帶“?”符號的表示對比模型中的最佳結果。
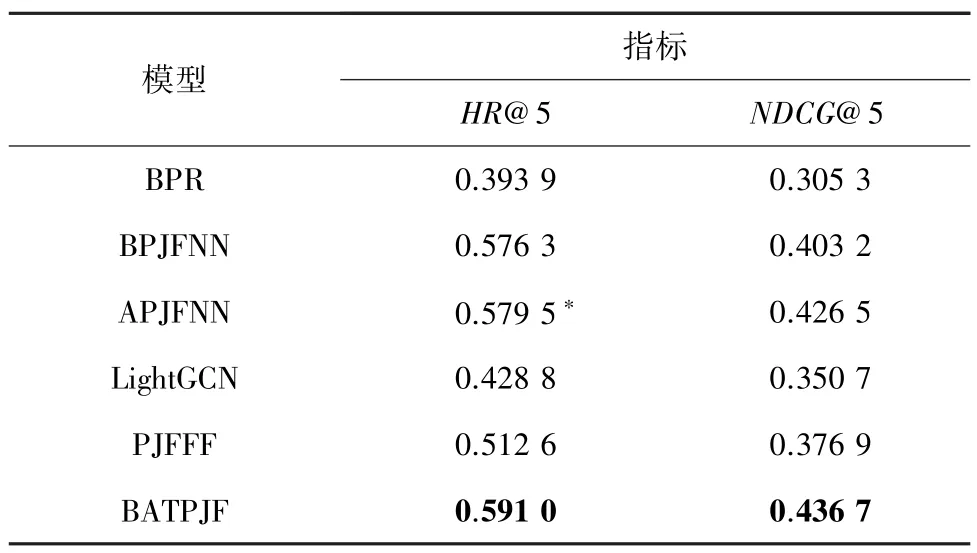
表3 不同模型在數據集的結果Tab. 3 Results of different models in the dataset
由表3 可知,本文提出的模型相比參照模型中最好的模型APJFNN 在指標HR@5 和NDCG@5 上分別提高了1.98%和2.39%。 由此可見,BATPJF 模型能充分發揮TextCNN 提取局部特征的優點與BiLSTM 具有記憶功能的優點,且注意力機制的加入,可以計算工作要求對不同工作經驗的重要性以及工作經驗對不同工作要求的貢獻,因此性能優于其他對比模型。
3 結束語
本文針對人崗匹配問題提出了一種基于深度學習的端到端人崗匹配模型,模型首先通過詞嵌入將文本表示成低維詞向量矩陣,接著利用TextCNN 和BiLSTM 分別提取職位描述和個人經歷文本中的局部關鍵信息和上下文信息,最后將得到的結果進行融合,提高了人崗匹配的效果。 通過與其他模型進行對比,證明了本文模型BATPJF 的有效性。 由于人崗匹配包括結構化和非結構化數據的匹配,而本文僅考慮了非結構化文本數據的匹配,所以下一階段的工作是將結構化的信息也考慮進模型中,以便進行更好的人崗匹配。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語文知識(2014年1期)2014-02-28 21:59:13
