基于MEA-BP 神經網絡的印刷車間能耗預測
2023-05-18 08:15:12張明月賀福強李思佳聶文豪
智能計算機與應用 2023年4期
關鍵詞:模型
張明月, 賀福強, 李思佳, 聶文豪
(1 貴州大學 機械工程學院, 貴陽 550025; 2 貴州西牛王印務有限公司, 貴陽 550008)
0 引言
在全球經濟迅速發展變革的洪流中,制造業作為國內國民經濟的基礎正面臨巨大的挑戰。 能量資源是國民經濟的命脈,是經濟發展中至關重要的戰略資源,因此節約資源、保護環境、實現可持續發展已成為當發展共識。 據統計,國內人均能源資源擁有量處于較低水平[1]。 但是,國內的人均能耗比國際平均值要大得多,而且國內經濟發展正處在高度智能化和工業化的進程中。 處于當前狀態下的能源問題尤為緊迫,如何有效提高能源使用的效率已成了所有企業持續關注的重點問題。 在印刷企業實施綠色節能、智慧管理的過程中,往往需要預先確定下一階段或未來季度的能耗量,從而為企業制訂節能戰略和進行節能效果評估提供依據。 因此,為了達到企業節能降耗的目的,必須采取一種科學合理的運行方案。 作為節能控制優化的基礎,能耗預測也是印刷企業長久運行的關鍵,在印刷工藝的節能優化中具有決定性和根本性的作用。
1 MEA 算法優化BP 神經網絡模型
1.1 MEA 算法原理
與傳統的搜索算法比較,思維進化算法[2-4]可以模仿人類思考。 思維進化算法(MEA)主要的系統框架如圖1 所示。 由圖1 可看到,該架構的組成部分主要有:由參數空間、個體元素、子群體、公告板以及特征提取。
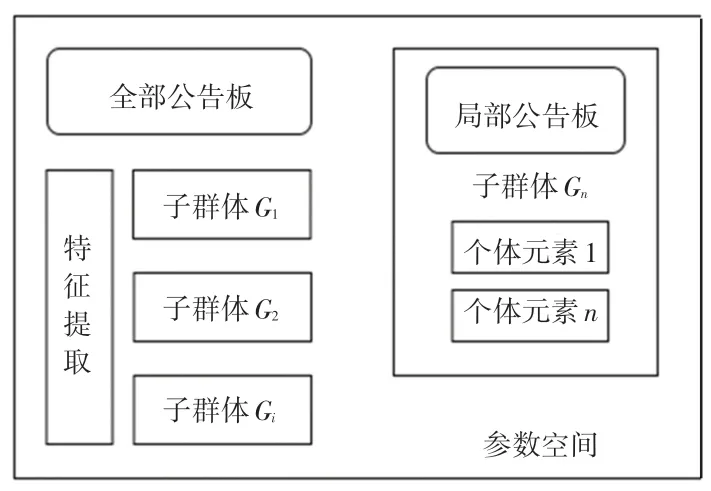
圖1 思維進化算法系統結構圖Fig. 1 System structure diagram of thinking evolution algorithm
這個算法的要點是:“趨同”和“異化”,并分別在不同的空間范圍內作業。 其中,趨同是在子群體內的局部操作。 這種運算存在于每個子群體中,組內個體元素競爭成為最優勝個體,并將最優勝個體作為目標隨機進行搜索,如果經過連續幾代,一個子群體的得分未見明顯增長,則說明該子群體內沒有生成新的最優勝個體,那就可以將該子群體看作成熟的子群體。
相比于趨同的生效范圍,異化是在全局環境中生效。 在整個參數空間中,各個子群體通過連續不斷地搜索新的個體的方法,不斷更新最優勝子群體。如果經過數代的臨時子群得分,沒有一個能替代已有的優勝子群體,那么該個體就會到達最佳狀態,并求得了思維進化的最優解。
思維進化算法的核心理念是對參數空間進行持續的進化,通過不斷探索進化產生更多優質個體,從而得到最優個體。 也就是通過“趨同”與“異化”的操作,經過反復計算,生成新的個體的子群體,并從中尋找出最佳的解決方案。
1.2 BP 神經網絡原理
BP(Back Propagation)算法[5-9]、即誤差反傳算法,是當前較為常用的一種學習算法。 研究可知,BP 算法的實現可以分為2 個步驟:前向傳播信號和反向傳播誤差。 采用BP 神經網絡對印刷過程進行能量消耗的預測。 BP 神經網絡一般采用輸入層、隱藏層和輸入層。 BP 神經網絡拓撲結構如圖2 所示。
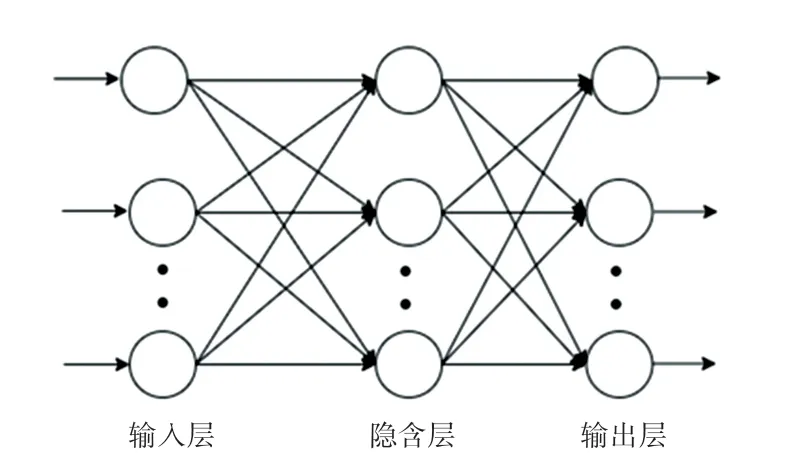
圖2 BP 神經網絡拓撲結構圖Fig. 2 Topological structure of BP neural network
在實際中,對于具有一定滯后性的非線性系統,建立一層隱藏層的神經網絡就可以做到精準預測。所以,在本論文所要探討的印刷能耗,只需要建立一層隱藏層即可。 因此,研究選用3 層神經網絡作為預測模型。 研究者們主要是依據過去的研究和模型的預報結果來調整BP 神經網絡中的神經元數目。通過式(1)計算得到隱含層的神經元個數:
其中,l表示隱含層神經元個數;m表示輸出層神經元個數;n表示輸入層神經元個數;a為常數,通常取2~10。
1.3 優化思路
本部分主要分析了BP 神經網絡存在的問題,并對其進行了優化和改進。 BP 神經網絡作為一種預測算法雖然有一定的優勢,但是在某些方面也存在不足。 對此擬展開闡釋分述如下。
(1)BP 神經網絡訓練過程中容易產生局部極小值。 該算法將誤差信息傳遞到權值和閾值處,為下一次的調節提供數據和方向,屬于“下坡”的做法。 因此網絡很容易陷入局部化,無法達到全局最小值。 該過程示意如圖3 所示。
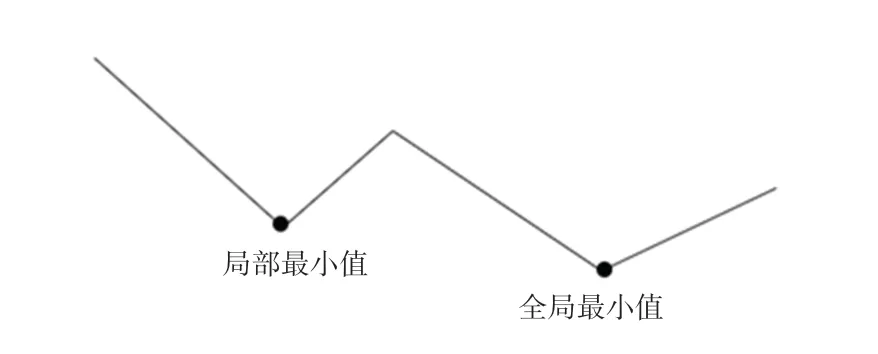
圖3 BP 神經網絡訓練過程示意圖Fig. 3 Schematic diagram of the training process of BP neural network
(2)網絡的學習收斂性差,學習時間長。 為了保證算法的收斂性,BP 神經網絡在學習率控制上存在一定的局限性,當遇到特定問題時,學習時間可能較長。
(3)無法保證網絡的泛化能力。 BP 神經網絡的泛化能力受網絡設置參數、樣本質量、網絡初始值等因素的影響。
針對BP 神經網絡存在的問題,本文采用思維進化算法(MEA)對BP 神經網絡進行了改進。 通過對其權值、閾值進行優化,以期得到全局最優結果。思維進化算法利用算法解空間內多個子群體共同尋找最優值個體。 算法通過采用“趨同”以及“異化”的有機結合,優化神經網絡初始權值和閾值。 既可以有效地改善BP 神經網絡的收斂率和泛化能力,又保證了權值和閾值的全局代表性,從而改善了BP神經網絡的預測準確率。
1.4 MEA-BP 神經網絡算法
MEA-BP 神經網絡[10-15]的建模中,最重要的是利用MEA 算法的全局尋優的優點,得出最優解。 解碼作為BP 神經網絡的初始權值和閾值,保證初始值的合理性,進而提高模型的準確率。 其中,MEABP 神經網絡算法流程如圖4 所示。 由圖4 可知,其操作流程具體如下。
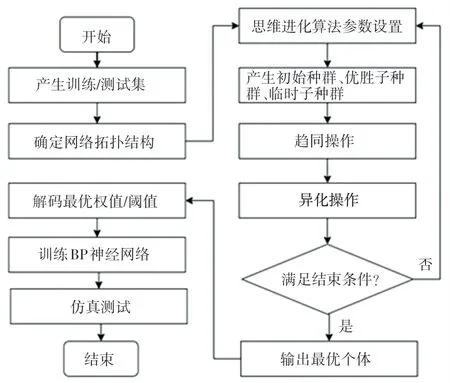
圖4 MEA-BP 神經網絡算法流程圖Fig. 4 Flowchart of MEA-BP neural network algorithm
步驟1產生訓練樣本集。
步驟2確定網絡的拓撲結構。
步驟3產生初始種群、臨時子種群和優勝子種群。
步驟4各個子群體內部完成趨同操作,即子群內部不再產生新的最優解個體。
步驟5執行子群體之間的異化操作,并依據該運算產生的結果進行組合產生新的子群體,從而保持數量穩定。
步驟6判斷是否滿足結束條件。
步驟7解析最優解個體,運用臨時子群體與優勝子群體之間的互相競爭、更新得到最優解,解碼最優權值和閾值。
步驟8BP 神經網絡的訓練。
步驟9MEA-BP 神經網絡預測模型的預測。訓練結束后,輸入樣本測試數據,進行預測,并進行相關分析。
2 實驗結果與分析
2.1 數據處理
在數據預處理過程中,原始數據的標準化是一個重要環節。 不同的評估指數往往存在著差異性,使用不同維度的數據資料進行分析會對數據資料的處理效率產生一定的負面作用。 為了避免數據的不同維度帶來的影響,需要對數據資料進行歸一化處理。 本文采用歸一化的方法,將原始數據線性轉換為0~1 之間的自然數。 數據處理方法見式(2):
其中,X為處理后的數據;xi為輸入數據;xmax為最大值;xmin為最小值。
2.2 算法參數設計
主要選用3 層前饋神經網絡建立了印刷工藝能耗預測的BP 神經網絡模型,由于影響印刷車間能耗的因素主要有5 種,分別是:產量、工人工作時間、設備運行時間、設備加工時間、加工能耗。 因此本實驗確定輸入層輸入個數為5,輸出層的神經元個數為1,即能耗預測量。 利用式(2)得到隱含層神經元個數為5。 基于以上參數選擇,設計了MEA-BP 神經網絡的拓撲結構如圖5 所示。
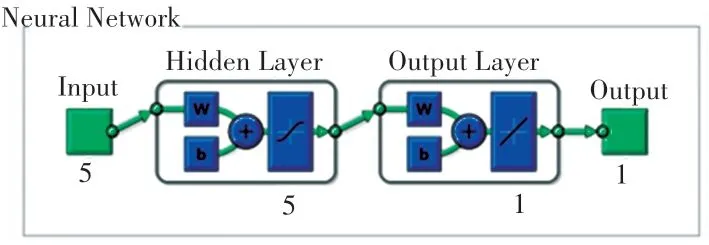
圖5 神經網絡拓撲結構Fig. 5 Neural network topology
思維進化算法的參數設置見表1。

表1 算法參數表Tab. 1 Parameters table of the algorithm
2.3 結果分析
確定了BP 神經網絡的訓練參數以及MEA 算法參數設計后,選擇建立在Windows10 系統上的Matlab 軟件進行實驗仿真,軟件版本選擇Matlab R2018a。 模型首先隨機產生初始種群,對10 個子種群分別進行趨同。 選擇ismature函數判斷是否繼續進行趨同。 若子種群尚未成熟,則以新的中心產生子種群;若已經成熟,則子種群的趨同結束。 對子種群的趨同操作如圖6 所示。
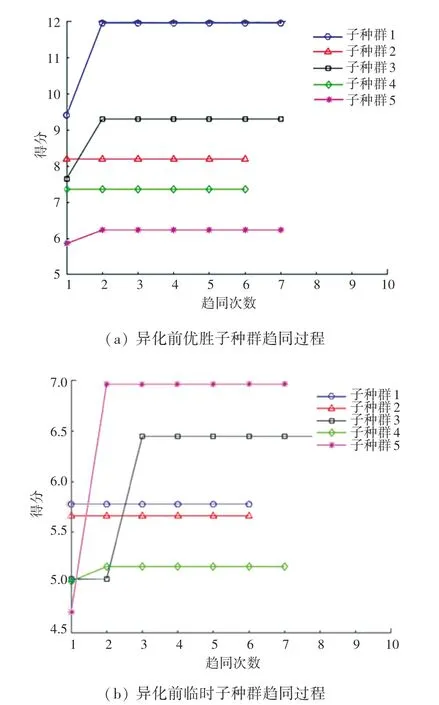
圖6 異化前子種群趨同過程Fig. 6 Subpopulation convergence process before dissimilation
尋找臨時子群體得分高于優勝子群體的編號,由圖6 可以看出,優勝子種群5 的得分較低。 因此需要異化,將得分高的臨時子種群替換到優勝子種群中去,而臨時子種群則需要重新生成一組子種群,以滿足數量不變。 異化操作如圖7 所示。
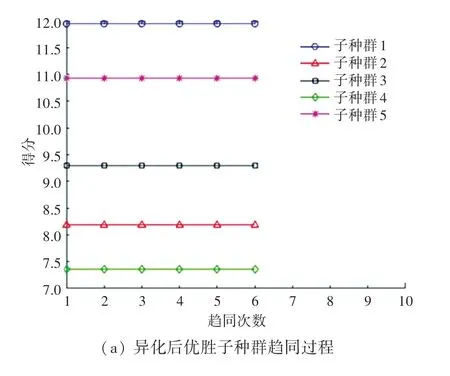
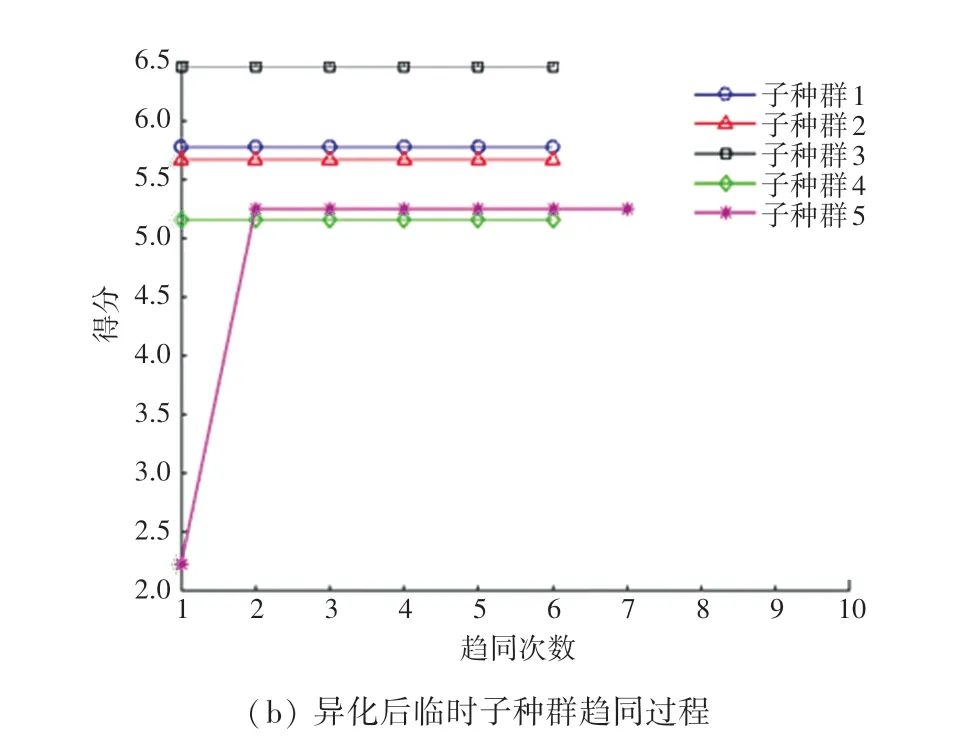
圖7 異化后子種群趨同過程Fig. 7 Subpopulation convergence process after alienation
輸出思維進化算法當前迭代獲得的最佳個體,對其進行解碼。 將其設置為網絡的初始權值和閾值。 利用印刷車間能耗數據樣本對MEA-BP 神經網絡進行訓練,輸出預測結果與樣本值的數據對比如圖8 所示。
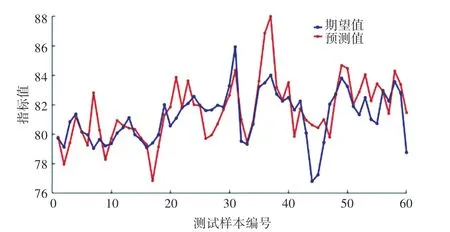
圖8 預測結果對比圖Fig. 8 Comparison of prediction results
選用相同訓練參數、設置相同拓撲結構的BP神經網絡,采用相同的能耗數據樣本進行訓練,得到該模型下的輸出數據。 將2 種模型的輸出數據進行對比,見表2。
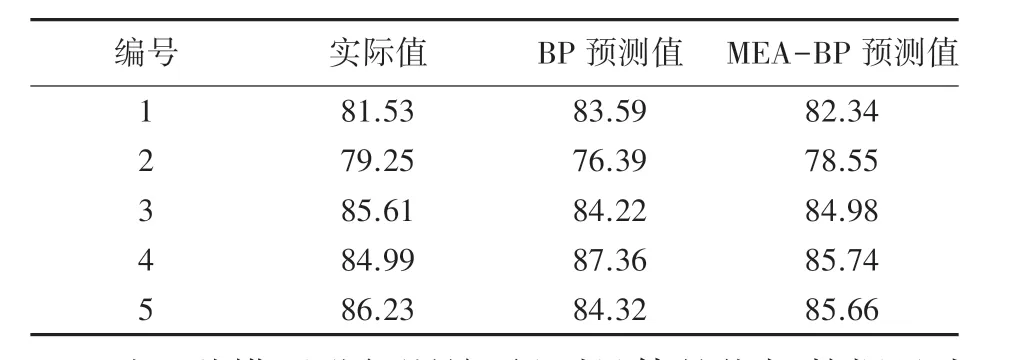
表2 輸出數據對比Tab. 2 Output data comparison
對2 種模型進行訓練,得到具體的指標數據見表3。 表3 中,MAE為平均絕對誤差,RMSE為均方根誤差,R為相關系數。 相比之下,MEA-BP 神經網絡模型的MAE與RMSE的數值較小,R值較大,表明該改進模型回歸性能較好,與數據的擬合度較高。
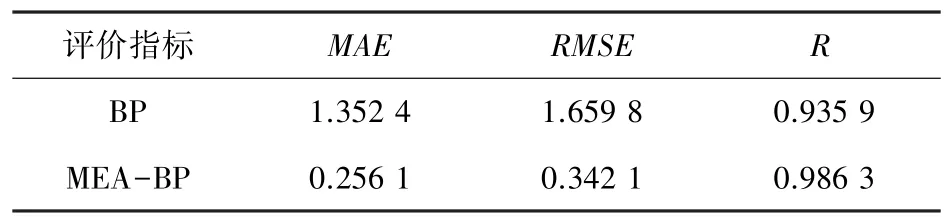
表3 模型評價指標Tab. 3 Model evaluation indicators
3 結束語
本文針對印刷車間的能耗進行預測分析,基于影響因素的復雜性,能耗特質分布規律不明顯。 選用MEA 算法對BP 神經網絡進行改進,利用MEA算法的全局尋優的優點,得出最優解。 將其解碼作為BP 神經網絡的初始權值和閾值,保證初始值的合理性,進而提高模型的準確率。 通過仿真實驗,根據模型評價指標,可以得到:與BP 神經網絡相比,MEA-BP 神經網絡的誤差更小,在印刷車間能耗預測方面有一定的實用價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
