基于隨機森林和優化GRU算法的柴油機NOx預測
2023-05-09 09:46:56郭智剛閆立冰馮健洧
汽車實用技術 2023年8期
郭智剛,申 宗,江 楠,閆立冰,馮健洧
(濰柴動力股份有限公司,山東 濰坊 261021)
近年來,中國環境污染越來越嚴重,涉及水污染、空氣污染等各種污染,其中最引人關注的當屬空氣污染[1]。機動車排放是大氣污染物的主要貢獻者,且柴油車排放的NOx 超過機動車氮氧化物的80%[2]。傳感器測量排放污染物由于受到成本、精度誤差等因素制約[3],通常采用模型預測柴油機的NOx 排放[4]。基于MAP 映射是一種常用的方法,根據發動機的轉速與噴油量查找對應工況下MAP 圖的NOx 排放,而對MAP 圖的標定是依賴于發動機臺架標定實驗。隨著對性能的追求以及排放要求的提升,各種新技術會應用到發動機上,這也就使得發動機系統變得更加復雜,進而使得標定實驗變得更加復雜困難,再加之標定工作的效果很大程度上依賴于標定人員的操作,這使得整個試驗成本較高并且耗費的時間較長。設計結構簡單又能表達非線性系統特征的模型成為研究人員關注的問題[5]。隨著機器學習與神經網絡的發展,借助于神經網絡模型預測排放物濃度成為研究的熱點問題[6-8]。文獻[6]提出使用深度極限學習機,基于發動機不同運行狀態下的數據對尾氣排放進行預測。周斌[5]建立不依賴于研究對象數學模型的三層Back Propagation(BP)神經網絡預測發動機的排放。胡杰等[8]選用最小二乘法提取特征并利用神經網絡進行擬合,建立柴油機NOx排放預測模型。
上述研究并沒有考慮到樣本之間的時間序列聯系,網絡表達能力有限。本文考慮到影響NOx產生的因素過多,導致整個模型的訓練與預測時間過長,采用隨機森林選取重要特征,同時注意到內燃機的NOx 排放與各參數的變化時序有關,即上個狀態的各個工況參數與當前NOx 的排放有一定關系,使用基于優化的門控循環單元(Gate Recurrent Unit, GRU)網絡對最終結果的預測更加有效。綜上提出使用隨機森林與GRU 結合的方法建立NOx 預測模型。
1 基于隨機森林的特征選擇算法
NOx 的產生影響因素較多,本文初步選擇了18 個相關參數作為影響NOx 的特征:增壓壓力、軌壓、進氣溫度、進氣壓力、廢氣再循環(Exhaust Gas Recirculation, EGR)冷卻溫度、燃油流量、進氣流量、EGR 流量、EGR 開度、EGR 設定、節流閥位置、節流閥設定、發動機轉速、發動機扭矩、主噴提前角、主噴油量、預噴油量、后噴油量。
神經網絡訓練過程中,并不是特征越多性能就會越好,輸入特征數過多造成的最直接影響就是計算量劇增,除了給計算量帶來不利的影響外,有些特征對于最后結果的表達貢獻并不大,這就需要通過特征提取去壓縮數據特征維數,在滿足最終預測精度的前提下,盡量減少處理數據的冗余度。因此,有保留地選擇出對最終結果影響最大的特征參數成了重要的過程,也是必不可少的一步[9-11]。文獻[9]利用主成分分析法(Principal Component Analysis, PCA)對內燃機的噪聲特征進行提取并取得了較好結果。文獻[10]在軸承狀態監測的故障分類中使用PCA 進行最優特征選取。文獻[11]選用通過特征降維后提高了柴油機部件的故障識別率。
隨機森林是一種有效的機器學習方法,在諸多領域均有應用,如疲勞駕駛檢測[12]、癌癥診斷[13]、信用評估[14]等。隨機森林的突出優點是計算復雜度低,隨機選擇樣本和特征,泛化能力較強、特征重要性評估準確性高[15]。隨機森林基本組成單元為決策樹,通過隨機的選擇樣本建立不同的決策樹,從而組成性能更加強大的隨機森林。本文中的隨機森林算法具體過程如下:
1)從共計含有18 880 個樣本的數據集中有放回的隨機抽取70%的樣本作為一個訓練集;
2)利用步驟1)中的樣本集生成一顆決策樹,決策樹每個節點的生成規則,如重復的選擇隨機,不重復地選擇16 個特征;
3)在所選樣本集中尋找16 個特征的最優劃分點,特征劃分的基本原則為使得劃分后的熵增益最大;
4)重復步驟1)、步驟2)建立150 棵決策樹,即建立成隨機森林;
5)用隨機森林對測試樣本進行預測,并利用票選法決定預測結果。
隨機森林算法流程如圖1 所示。
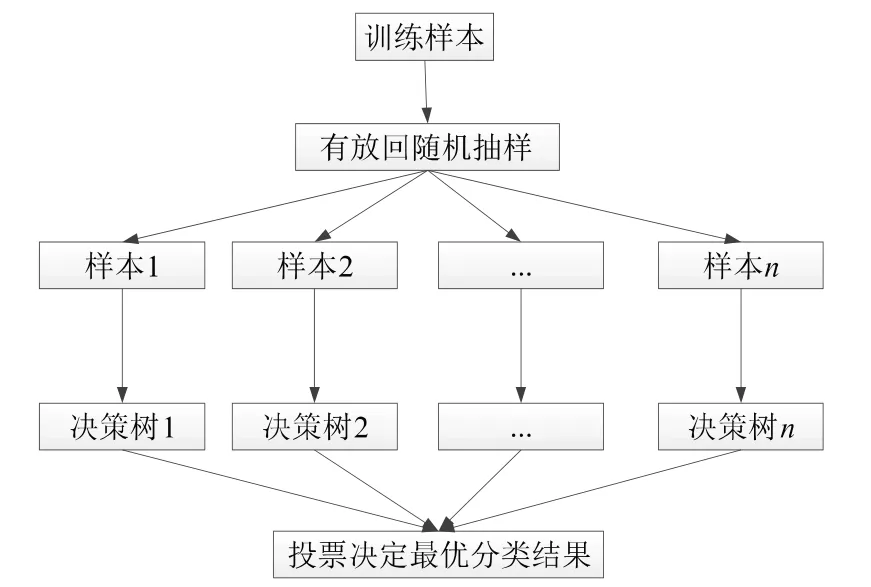
圖1 隨機森林算法流程
由圖1 可見,隨機森林的強大之處體現在隨機性上,不僅在樣本的選擇上隨機選取,建立決策樹時也會隨機選擇特征。隨機森林的一個重要的用途便是評估重要特征,本文采用袋外數據分類的準確性來測試特征的重要性,流程如下:
1)計算每一棵決策樹的袋外數據誤差,記為err1;
2)對袋外數據所有樣本的特征隨機添加噪聲,再次計算袋外誤差,記為err2;
3)計算特征的重要性I。
其中,袋外數據是指在進行隨機有放回選擇樣本的時候,沒有用于建立決策樹的數據,而這部分數據會被用作評估決策樹,這樣避免造成使用訓練數據進行評估而造成的數值誤差。模型在袋外數據下的預測錯誤率,被稱為袋外錯誤率,重要性I計算公式為
式中,N為隨機森林中的N棵樹。越重要的特征在被改變后,對最后的結果產生的影響越大,因此,在對特征添加隨機噪聲后,使得袋外誤差增加越大,說明對最終預測結果的重要性越大。
依據以上步驟進行特征重要性的繪制如圖2所示,根據特征重要圖的特征重要性排序選取EGR 冷卻溫度、進氣溫度、增壓壓力、轉速、扭矩、進氣流量的六個特征作為網絡特征輸入。
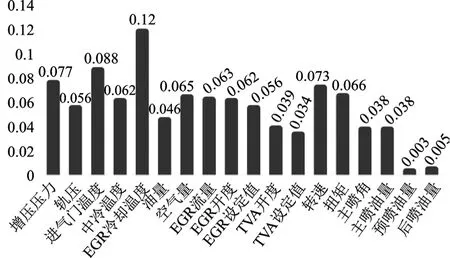
圖2 特征重要性
2 基于門控單元的排放模型與優化
深度學習中對于傳統的序列問題通常使用循環神經網絡(Recurrent Neural Network, RNN),t時刻接收到輸入Xt之后,隱藏層的值為St,輸出為Ot,此時關鍵點在于St的計算參考St-1,即上個時刻的狀態,這時的網絡初步具備了“記憶”功能,也就是說對于一個序列,后一個輸入與前一個輸入并不是沒有關系,通過將本時刻的輸入與上一時刻的狀態建立聯系,從而提高網絡的表達能力。隨著時間序列的推移,后面的時間節點對之前節點的感知能力會逐漸下降,并且 RNN 無法控制寫入記憶模塊的內容[4]。GRU 可以很好地解決這種問題,且能夠更好地捕捉序列中較長的依賴關系[16]。
GRU 的基本結構如圖3 所示,其使用門控機制控制輸入信息和記憶信息,并在當前時間狀態下給出預測信息。GRU 通過兩個門控制神經網絡的輸出,能長時間保存時間序列信息,不會隨時間推移和預測結果不同而被丟棄[17]。

圖3 GRU 基本結構
圖3 中的zt與γt分別為GRU 的update gate(更新門)與reset gate(重置門)。更新門反映的是前一狀態信息對當前狀態信息的影響權重,該值越大表明,當前信息應該增大包含前一狀態信息的權重。重置門反映的是拋棄前一信息的權重,該值越大應該更多忽略上一狀態信息。GRU 通過使用一種“門”的結構,極大地避免了梯度消失的問題,可以更有效地分析長期依賴關系,同時GRU化簡了單元復雜度[18],實際運行過程中效率更高,其中σ為Sigmoid 激活函數;tanh為激活函數。GRU 前向傳播公式為
式中,[]為向量相連;*為矩陣乘積,即損失函數是神經網絡中衡量預測值與真實值之間差距的指標,損失函數的設計優劣對網絡的最終訓練結果有重要的影響,損失函數選用Smooth L1 Loss 函數,公式為
Smooth L1 Loss 的優勢在于真實值與預測值差別較小時,神經網絡的梯度更新較小,使得神經網絡的效果更精準,如圖4 所示。而真實值與預測值差別較大時,梯度值并不會太大以至于產生梯度爆炸的情況。
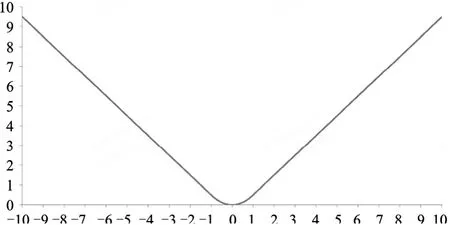
圖4 Smooth L1 Loss 函數圖像
神經網絡的優化通過梯度下降的方法實現,針對梯度下降的優化算法[19-21]有很多。本文選用Adam(適應性動量估計)的優化算法,Adam 參數更新為
Adam 綜合了文獻[19]與文獻[20]的方法,全面估計了梯度的一階矩和二階矩,其中β1通常取0.9,β2通常取0.999,相比于其他優化算法,Adam算法計算高效,同時能自適應調整學習率,在神經網絡的優化過程中表現更優。
GRU 網絡參數設置如表1 所示。

表1 GRU 網絡參數設置
受制于影響NOx 排放的因素過多,且各個工況下內燃機的運行復雜性,部分樣本的預測結果不理想。提高網絡的預測結果,最直接的方法就是對樣本的處理,困難樣本加強的核心思想是使用網絡模型對樣本進行處理,把其中難以達到預期的樣本統一放置一個集合中,之后使用該集合繼續訓練分類器。也就是說,訓練結束后使用訓練的模型對樣本進行測試,測試結束后挑選困難樣本,將困難樣本形成一個集合后,對原有的模型使用困難樣本集合繼續訓練,當閾值過大時認定為是困難樣本需要重新訓練,反之不進行重新訓練。對困難樣本的挖掘重新訓練,可以增強網絡的泛化能力,提高模型的魯棒性。
綜上,基于優化GRU 的NOx 預測排放框架如圖5 所示。
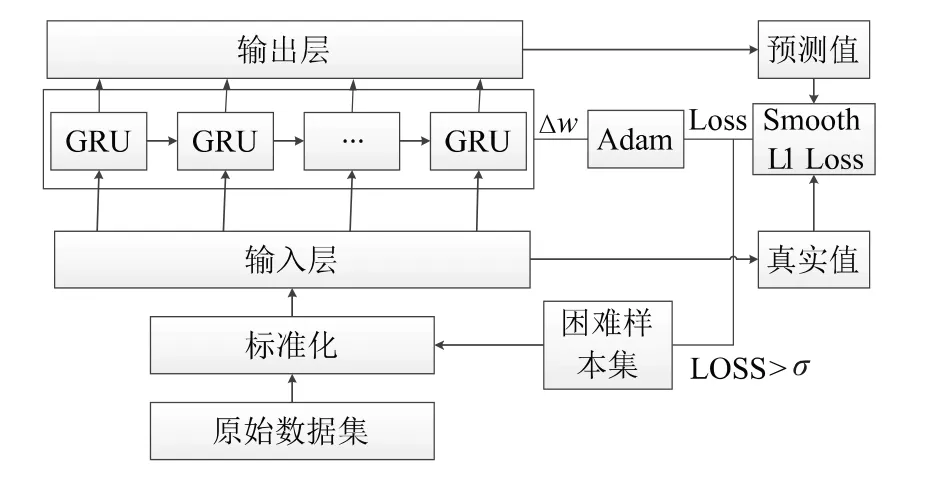
圖5 優化GRU 架構
3 實驗過程和結果
為了驗證模型的效果,進行全球統一瞬態試驗循環(World Harmonized Transient Cycle, WHTC)試驗,以穩態數據作為實驗數據,其中實驗數據70%作為訓練集,30%作為測試集,其中模型在瞬態工況下預測效果如圖6 所示。
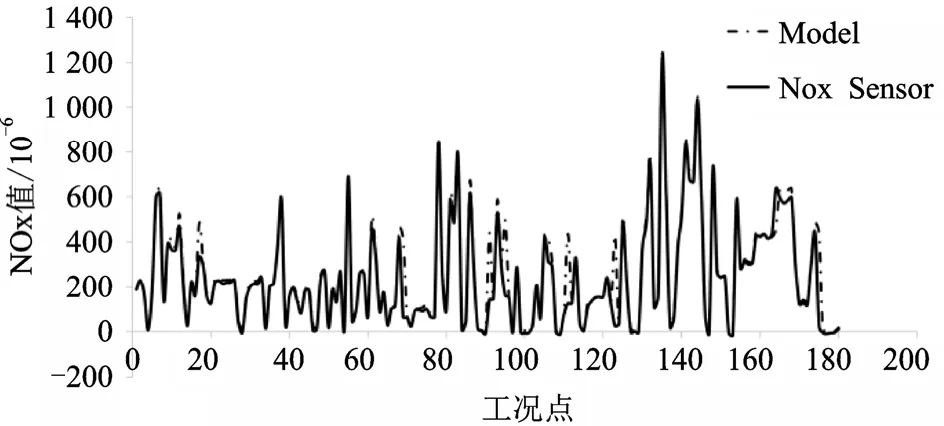
圖6 瞬態工況下GRU 與傳感器結果對比
模型在穩態工況下預測效果如圖7 所示。
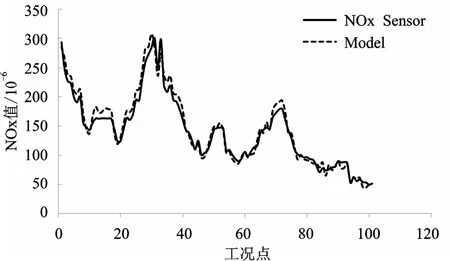
圖7 穩態工況下GRU 與傳感器結果對比
使用隨機森林選擇的六個特征(EGR 冷卻溫度、進氣溫度、增壓壓力、轉速、扭矩、進氣流量)進行試驗,預測值基本符合實際值的變化,表明該模型具有較高的精準度,但部分工況點存在偏差,推測原因如下:
1)網絡表達能力的限制,網絡的表達能力與網絡的設置結構有重要關系,但復雜的結構不僅會造成訓練時間過長,甚至可能造成過擬合情況出現,導致模型在訓練集中表現良好但測試集中表現較差,實際使用中需要在模型精度與訓練時間做一個有效權衡;
2)實際采集數據中可能存在的異常點導致部分工況無法準確學習。
設置對照試驗,使用相同數據設置BP 模型與多項式模型的NOx 預測對照試驗。使用均方根誤差(Root Mean Square Error, RMSE)與R2 兩個參數來量化訓練效果,RMSE 與R2 是回歸分析中常用的兩個評價指標,其中RMSE 的計算公式為
R2 決定系數用以衡量預測值與真實值之間的偏差,其計算公式為
式中,為當前樣本的預測值;為樣本的平均值。
為說明算法的有效性,將本文算法與BP 神經網絡以及多項式模型進行對比,其中BP 神經網絡的相關參數設置同與本文算法GRU 參數設置相同。而多項式模型中使用最小均方誤差進行擬合,各個模型分別對相同的穩態和瞬態數據進行試驗,相關對比結果如表2、表3 所示。由實驗結果可知,在瞬態工況與穩態工況下,相比于BP 模型與多項式擬合模型,隨機森林結合GRU 具有更高的精準度。

表2 瞬態工況下預測結果圖
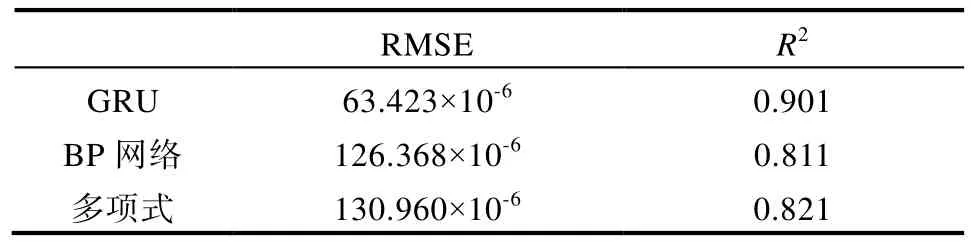
表3 穩態工況下預測結果圖
4 結論
本文以柴油機NOx 的排放預測為研究對象,提出使用隨機森林與GRU 神經網絡結合的方法進行預測,隨機森林選取對預測結果影響較大的特征,構建基于門結構的循環神經網絡,并針對實際訓練提出一些優化訓練的方法。針對上述算法,以WHTC 工況數據以及萬有數據為輸入,進行了對比實驗,根據實驗結果顯示,本文使用的方法在穩態工況與瞬態工況均有良好表現,瞬態工況下較傳統的BP 模型精度提高了54.3%,穩態工況下較傳統的BP 模型精度提高了49.81%,從而證明本算法預測NOx 排放的高精準度以及良好的泛化性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
