基于機(jī)器學(xué)習(xí)的大學(xué)生家教適配系統(tǒng)的設(shè)計(jì)與實(shí)現(xiàn)
2023-04-27 04:05:42高晨昊何謙胡梓
電腦知識(shí)與技術(shù) 2023年8期
關(guān)鍵詞:機(jī)器學(xué)習(xí)
高晨昊 何謙 胡梓

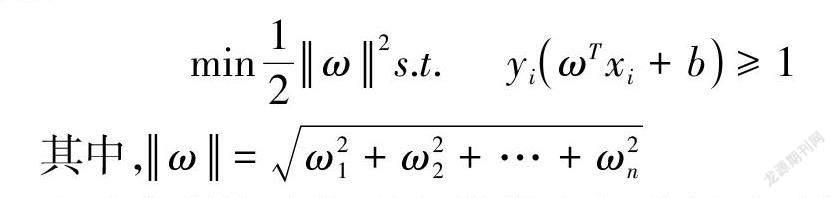


關(guān)鍵詞:大學(xué)生家教;機(jī)器學(xué)習(xí);SVM支持向量機(jī);家教系統(tǒng);App
中圖分類號(hào):TP311 文獻(xiàn)標(biāo)識(shí)碼:A
文章編號(hào):1009-3044(2023)08-0005-04
0 背景概述
當(dāng)下,“互聯(lián)網(wǎng)+教育”已經(jīng)融入學(xué)生的方方面面,在“互聯(lián)網(wǎng)+”背景下,學(xué)生借助互聯(lián)網(wǎng)瀏覽教育信息,實(shí)現(xiàn)個(gè)性化教學(xué)目的。家教行業(yè)也借助這一背景,涌現(xiàn)出部分個(gè)性化教育平臺(tái)[1]。家教群體中有這么一個(gè)群體,占據(jù)家教市場近4成,和學(xué)生溝通強(qiáng),物美價(jià)廉,這便是大學(xué)生家教。
有學(xué)者曾調(diào)研過遼寧省的大學(xué)生家教市場。調(diào)研指出,有85%的家長會(huì)選擇為孩子報(bào)名課后輔導(dǎo)班;所調(diào)查的近300家教育機(jī)構(gòu)中,參與過家教兼職人員多達(dá)1萬人,目標(biāo)學(xué)生群體約60萬人,學(xué)生平均年消費(fèi)達(dá)2500 元[2]。據(jù)項(xiàng)目組成員調(diào)查,在一二線城市,約每10個(gè)學(xué)生中有8個(gè)學(xué)生上過課外補(bǔ)習(xí)班。因此,只要大學(xué)生有兼職意向,只要中小學(xué)生有補(bǔ)課需求,那么大學(xué)生家長市場將持續(xù)存在,并且會(huì)隨著人數(shù)、教育發(fā)展、教育需求提高而持續(xù)擴(kuò)大,線上家教匹配系統(tǒng)的未來前景仍是一片光明。
但是,大學(xué)生家教市場也存在著諸多問題。最主要的是大學(xué)生家教市場信息閉塞,大學(xué)生尋找家教系統(tǒng)途徑單一[3]。
根據(jù)項(xiàng)目組成員考察調(diào)研,將目前市場上的家教平臺(tái)分成以下三類:
1) 綜合性兼職平臺(tái)分屬家教模塊(如58同城、BOSS直聘);
2) 專職線下家教平臺(tái)(如學(xué)而思,學(xué)大教育);
3) 較強(qiáng)地域性的家教小網(wǎng)站和小平臺(tái)(如知善師家教)。
三種模式各有利弊,本項(xiàng)目設(shè)計(jì)為第三類家教平臺(tái)。
團(tuán)隊(duì)利用機(jī)器學(xué)習(xí)算法庫中的SVM算法,將中小學(xué)生在本平臺(tái)的上課習(xí)慣、成績、學(xué)習(xí)能力以及家教需求等個(gè)人數(shù)據(jù)作為輸入,作為每個(gè)學(xué)生的學(xué)習(xí)模型,存儲(chǔ)在數(shù)據(jù)庫中,然后通過家教匹配系統(tǒng),按需匹配最適合中小學(xué)生的大學(xué)生教員。該平臺(tái)依據(jù)個(gè)體學(xué)習(xí)模型提供更契合的教員,從而滿足個(gè)性化需求,解決潛在的教員“講授方式”和“能力不足”等問題,減少中小學(xué)生找家教的時(shí)間,同時(shí)也為大學(xué)生提供了兼職渠道,進(jìn)一步提高平臺(tái)的競爭力[4]。
App前端使用基于Vue.js所搭載的uniapp框架搭建,同時(shí)利用MySQL數(shù)據(jù)庫進(jìn)行信息整合與存放,借助node.js搭建后端、調(diào)用數(shù)據(jù),實(shí)現(xiàn)了教員信息展示、學(xué)生信息展示、喜歡教員、聯(lián)絡(luò)教員等諸多基礎(chǔ)功能[5]。同時(shí),使用Python 語言在jupyter notebook 中調(diào)用機(jī)器學(xué)習(xí)算法庫中的SVM支持向量機(jī),訓(xùn)練已獲得的數(shù)據(jù)得到模型,模型實(shí)現(xiàn)了教員與中小學(xué)生匹配,減少了中小學(xué)生挑選聯(lián)絡(luò)教員以及與教員磨合的時(shí)間,并對(duì)教員的教學(xué)方式提供即時(shí)反饋。
本系統(tǒng)的主要目標(biāo)是通過匹配中小學(xué)生與教員特點(diǎn),滿足不同學(xué)生的個(gè)性化需求,同時(shí)解決大學(xué)生家教市場信息閉塞的現(xiàn)實(shí)問題。
1 系統(tǒng)的需求分析與設(shè)計(jì)
1.1 需求分析
本系統(tǒng)解決的核心是完成滿足學(xué)生和教員的相互匹配,找到合適的“最優(yōu)”伙伴。系統(tǒng)主要分為兩個(gè)角色:學(xué)生和教員。
學(xué)生端需要功能:注冊(cè)登錄、教師信息預(yù)覽、收藏喜歡的教員、教員匹配、分?jǐn)?shù)教學(xué)反饋。
教員端需要功能:注冊(cè)登錄、學(xué)生信息預(yù)覽、學(xué)生匹配、學(xué)生反饋。
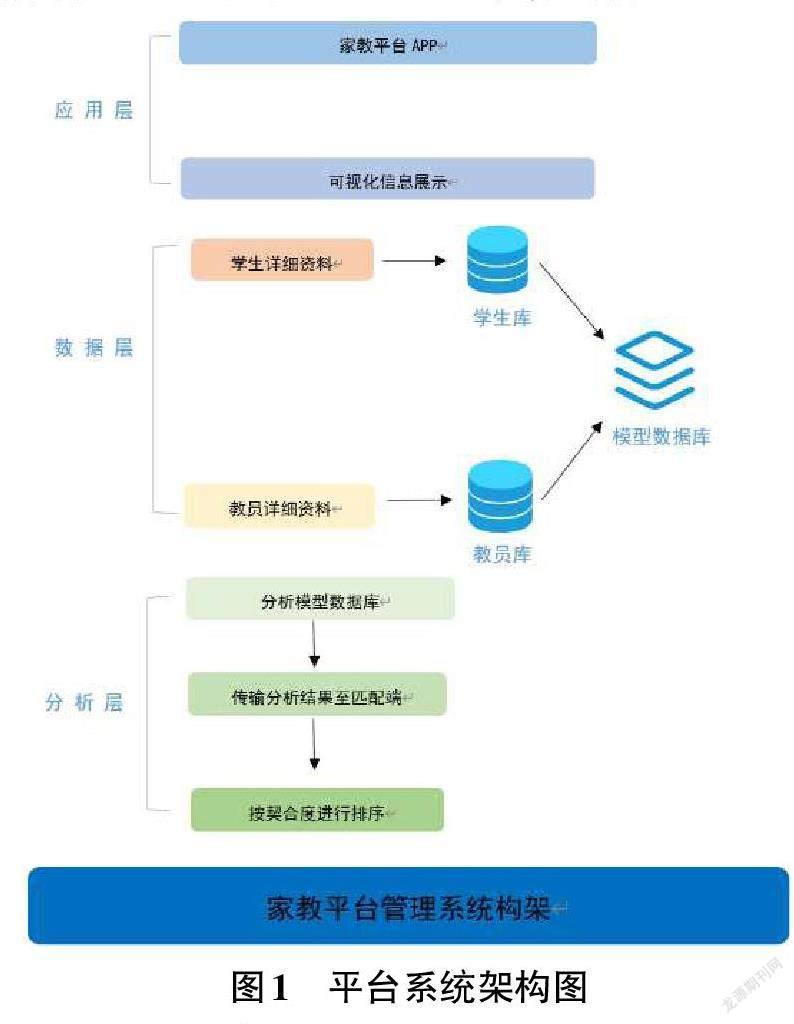
1.1.1 系統(tǒng)架構(gòu)圖
整個(gè)系統(tǒng)主要由三層組成:應(yīng)用層,邏輯分析層,數(shù)據(jù)層。
數(shù)據(jù)層:底層數(shù)據(jù)庫存儲(chǔ):1) 教員庫:教員基本信息、教室模型;2) 學(xué)生庫:學(xué)生基本信息、學(xué)生需求、成績、課程記錄反饋。學(xué)生庫中的數(shù)據(jù)輸入相關(guān)算法,抽象出特征模型后存儲(chǔ)在模型數(shù)據(jù)庫中。
邏輯分析層:對(duì)模型數(shù)據(jù)庫進(jìn)行分析,將分析結(jié)果發(fā)送到匹配端,庫中模擬匹配出若干結(jié)果按契合度從高到低排序
應(yīng)用層:利用下層的算法接口,將匹配的最優(yōu)信息用前端頁面可視化地展示出來,具體如圖1所示。
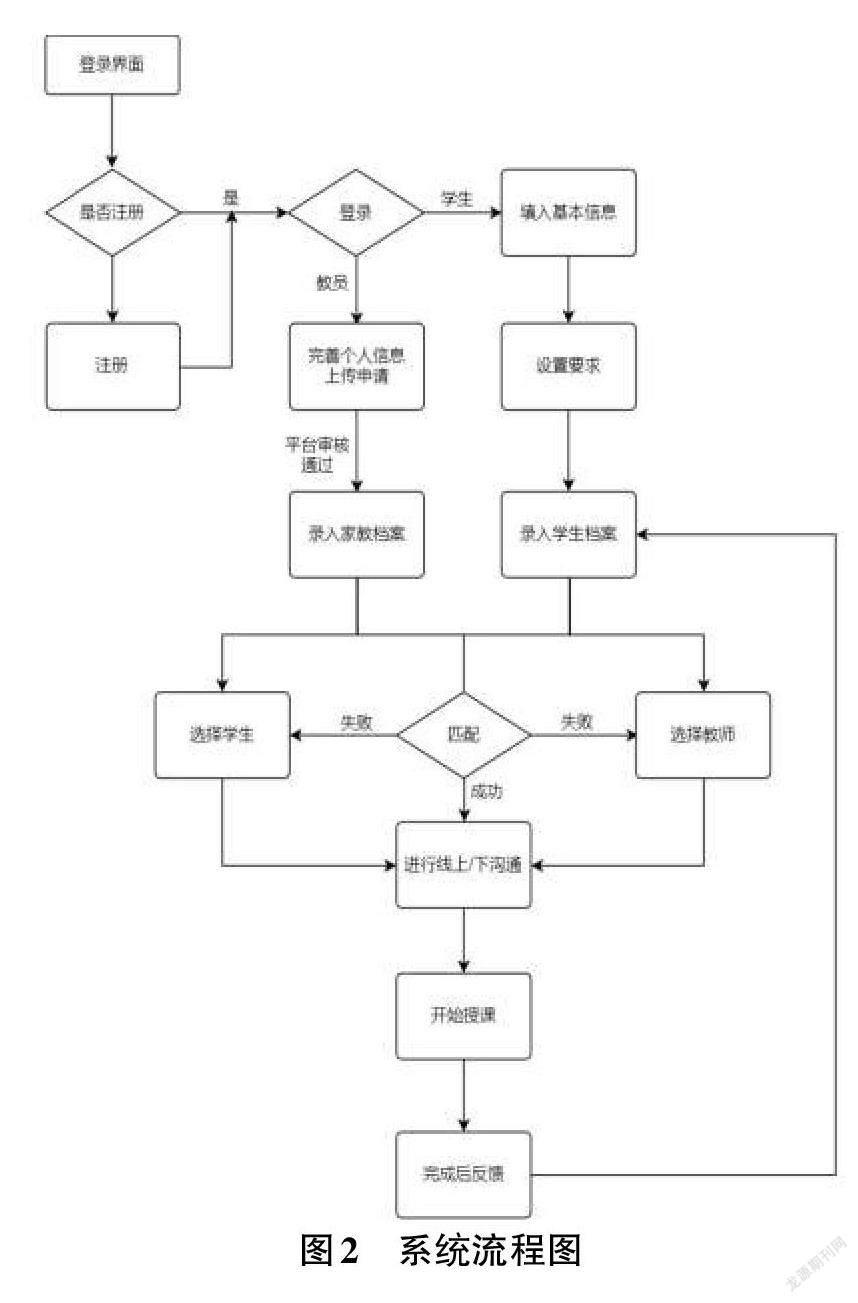
1.1.2 系統(tǒng)流程圖設(shè)計(jì)
圖2為系統(tǒng)流程圖。
1.2 系統(tǒng)數(shù)據(jù)庫設(shè)計(jì)
1.2.1 數(shù)據(jù)庫設(shè)計(jì)的原則
在創(chuàng)建數(shù)據(jù)庫之前,根據(jù)系統(tǒng)的數(shù)據(jù)需求和處理需求,設(shè)定以下建表要求:具有同一主題的數(shù)據(jù)應(yīng)盡量存儲(chǔ)在同一個(gè)表中,減少不必要的字段出現(xiàn),也要根據(jù)存儲(chǔ)數(shù)據(jù)的實(shí)際情況確定字段類型,提高后端查詢數(shù)據(jù)的工作效率;建立表與表之間的關(guān)系時(shí),表的主鍵及外鍵關(guān)系要盡量少,降低聯(lián)合查詢的復(fù)雜度;表的安全性和保密性要強(qiáng),不能將系統(tǒng)關(guān)鍵字設(shè)置在表中,防止SQL注入攻擊,對(duì)如用戶賬號(hào)密碼此類信息不能采用明文形式儲(chǔ)存,要對(duì)其進(jìn)行加密后再儲(chǔ)存;表與表間的管理要合理化,減少SQL查詢帶來的系統(tǒng)性能下降。
1.2.2 數(shù)據(jù)庫表的設(shè)計(jì)
(1) 教員信息表:字段包括:photo、id、username、name、age、sex、phone、grade、location、score、school、所在地、subject、characteristics。
(2) 學(xué)生信息表:字段包括:id、sname、sage、ssex、sgrade、slocation、sscore、sschool、schara、sneed。表1為學(xué)生信息表樣例。
2 基于支持向量機(jī)的教員和學(xué)生數(shù)據(jù)匹配
為了實(shí)現(xiàn)教員和學(xué)生之間的最優(yōu)匹配,本文擬使用支持向量機(jī)SVM進(jìn)行模型構(gòu)建與訓(xùn)練,以達(dá)到教員和學(xué)生的最佳數(shù)據(jù)匹配。
2.1 支持向量機(jī)
1992年,Vapnik 對(duì)有限樣本下的機(jī)器學(xué)習(xí)問題進(jìn)行研究,提出一種小樣本統(tǒng)計(jì)學(xué)習(xí)理論SLT。SLT為機(jī)器學(xué)習(xí)問題建立了理論框架,發(fā)展出一種新的學(xué)習(xí)算法:SVM-支持向量機(jī)[6]。支持向量機(jī)(SupportVector Machine, SVM) 是一類按監(jiān)督學(xué)習(xí)(supervised
learning) 方式對(duì)數(shù)據(jù)進(jìn)行二元分類的廣義線性分類器(generalized linear classifier) ,其決策邊界是對(duì)學(xué)習(xí)樣本求解的最大邊距超平面(maximum-margin hyper?plane) [7-8]。
跳過理論證明,SVM 所處理的最優(yōu)化解決問題為:
上述方程即為找到各類樣本點(diǎn)到超平面的距離最遠(yuǎn),也就是找到最大間隔超平面。也就是說,此方法的距離求解即為求解由學(xué)生和教師屬性構(gòu)成超平面,用得分來刻畫該數(shù)據(jù)到超平面的距離。
2.2 基于SVM 的教員和學(xué)生的數(shù)據(jù)匹配
按需求來說,學(xué)生將自己的基本信息輸入系統(tǒng),然后根據(jù)算法推出一個(gè)最合適學(xué)生的教員。但是在實(shí)際操作上,只輸入學(xué)生的信息給模型算法是不可以的。因?yàn)橥ㄟ^模型算法給出的y 值要么是一個(gè)數(shù),要么是一個(gè)矩陣,性格相關(guān)均為并列關(guān)系,無法給出各項(xiàng)的準(zhǔn)確分?jǐn)?shù)的標(biāo)準(zhǔn)。比如算法給出教員的數(shù)據(jù)為:幽默18和嚴(yán)肅42,但是庫中有一位教員A:幽默20,嚴(yán)肅40;教員B:幽默16,嚴(yán)肅44,沒有辦法比較哪一位是最匹配的教員。針對(duì)此問題,項(xiàng)目組提出的解決方案是對(duì)數(shù)據(jù)進(jìn)行歸并。
數(shù)據(jù)歸并是指將學(xué)生希望教員的數(shù)據(jù)和庫中所有教員的數(shù)據(jù)進(jìn)行組合,得到若干條原始數(shù)據(jù),得出的分?jǐn)?shù)為系統(tǒng)給教員的評(píng)分,將評(píng)分從高到低排序,得到分?jǐn)?shù)最高的ID,后臺(tái)將該ID傳送給后端,由前端進(jìn)行數(shù)據(jù)渲染,完成教員的推送。
因此,在數(shù)據(jù)收集初期,讓挑選出的大學(xué)生教員錄制/線下試講5分鐘的習(xí)題,將錄制的視頻發(fā)至收集數(shù)據(jù)的中小學(xué)生,不告訴其教員的相關(guān)信息,由第一感覺評(píng)判該大學(xué)生教員是否符合自己的心意,并給這些教員打分,由此獲得最初的完整數(shù)據(jù)集,從而完成教員和學(xué)生的匹配。
2.2.1 信息庫的建立
本文使用jupyter notebook工具進(jìn)行研究,首先導(dǎo)入學(xué)生教員信息庫的csv文件。
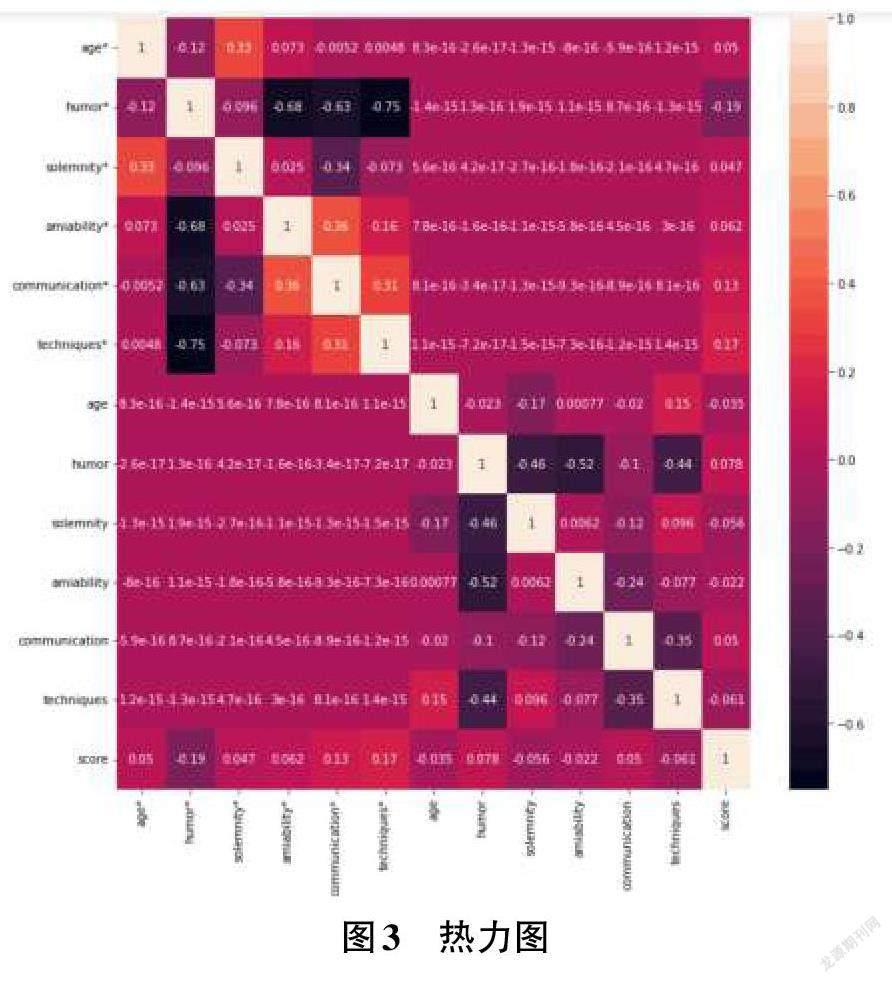
發(fā)現(xiàn)數(shù)據(jù)有分類類型與數(shù)值類型,首先需要進(jìn)行數(shù)據(jù)的分析與統(tǒng)計(jì),為了更好地展示數(shù)據(jù)信息,利用seaborn庫中的繪圖功能進(jìn)行可視化地展示圖片,根據(jù)繪制出的熱力圖,可以更好地查看各個(gè)屬性之間的相關(guān)性,如圖3所示。
2.2.2 數(shù)據(jù)標(biāo)準(zhǔn)化
接下來,需要對(duì)分類數(shù)據(jù)與數(shù)值數(shù)據(jù)分別進(jìn)行處理,對(duì)于類別字段,采用OneHot進(jìn)行數(shù)字編碼,對(duì)于數(shù)值數(shù)據(jù)進(jìn)行去均值和方差標(biāo)準(zhǔn)化,以此達(dá)到分離特征矩陣X和預(yù)估向量Y的目的。
針對(duì)數(shù)值數(shù)據(jù)標(biāo)準(zhǔn)化,可以利用scikit-learn 中自帶的preprocessing 庫中Standard?Scaler 很快進(jìn)行實(shí)現(xiàn),如圖4所示。
2.2.3 特征矩陣和預(yù)估向量的構(gòu)建
處理好數(shù)據(jù)后,開始構(gòu)建最終特征矩陣和最終預(yù)估的向量,特征矩陣是指分類特征數(shù)據(jù)和數(shù)值特征數(shù)據(jù)之間的拼接,利用numpy中的np.has?tack,將預(yù)估的向量轉(zhuǎn)換成numpy數(shù)組,至此完成了特征矩陣和預(yù)估向量的構(gòu)建。
2.3 模型訓(xùn)練
構(gòu)建完成后,需要進(jìn)行模型的訓(xùn)練。首先將數(shù)據(jù)集分為測試集和訓(xùn)練集,利用scikit-learn 中的model_selec?tion子包進(jìn)行數(shù)據(jù)集的劃分,本模型將80%的數(shù)據(jù)作為訓(xùn)練集,20% 的數(shù)據(jù)作為測試集,如圖5所示。
使用SVM支持向量機(jī)進(jìn)行模型的訓(xùn)練,在scikitlearn中引入SVM庫,使用fit的方法進(jìn)行訓(xùn)練,在fit中傳入特征矩陣X-train和預(yù)估目標(biāo)y-train,就可以很快完成訓(xùn)練。接著在測試集中進(jìn)行預(yù)估,傳入X-test,可以得到預(yù)估的匹配度,即y-predict,如圖6所示。
最后,模型在訓(xùn)練集上的分?jǐn)?shù)為0.94,測試機(jī)上的結(jié)果為0.92,證明SVM算法和本文的要求有極高的匹配度。本文將該組數(shù)據(jù)采用KNN臨近算法進(jìn)行模型訓(xùn)練,在KNN回歸模型中,結(jié)果如圖7所示,訓(xùn)練集上的準(zhǔn)確度是0.90,測試集上的準(zhǔn)確度為0.86,將兩者相比較,發(fā)現(xiàn)SVM模型比KNN模型有著更高的準(zhǔn)確性,如圖7所示。
3 系統(tǒng)實(shí)現(xiàn)以及介紹
3.1 部分頁面功能實(shí)現(xiàn)
3.1.1 教員大廳、學(xué)生大廳頁面的實(shí)現(xiàn)
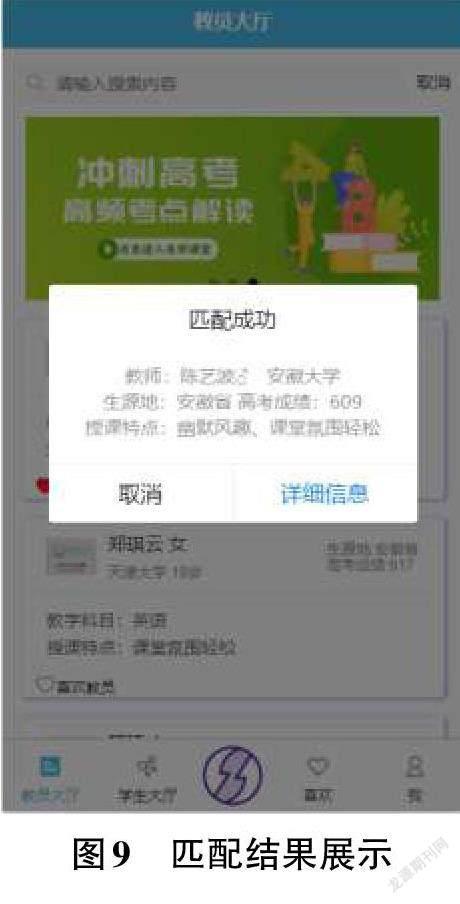
學(xué)生用戶登錄成功后,系統(tǒng)將自動(dòng)跳轉(zhuǎn)到“教員大廳”頁(如圖),學(xué)生用戶可使用頂部搜索欄進(jìn)行關(guān)鍵詞檢索,尋找心儀的教員;通過首頁輪播圖點(diǎn)擊進(jìn)入“金牌名師”的課堂報(bào)名;通過首頁展示的教員卡片閱讀教員的生源地、高考成績、教學(xué)科目、授課特點(diǎn)等信息,并根據(jù)自身需求選擇心儀教員。
3.1.2 個(gè)性化匹配功能實(shí)現(xiàn)
點(diǎn)擊“匹配”按鈕,前端向后端發(fā)送匹配請(qǐng)求,后端將前端捕捉的數(shù)據(jù)傳入后臺(tái)模型,由模型得出各個(gè)教員的評(píng)分,在后臺(tái)從高到低排序,將排名第一的教員ID傳送給后端,由后端將該教員信息傳送到前端渲染展示。
4 結(jié)束語
本文設(shè)計(jì)的基于機(jī)器學(xué)習(xí)的大學(xué)生家教適配系統(tǒng),即利用SVM支持向量機(jī)算法對(duì)教員和學(xué)生數(shù)據(jù)進(jìn)行機(jī)器學(xué)習(xí),通過建立“評(píng)價(jià)反饋”機(jī)制為模型進(jìn)行修正,訓(xùn)練完成的模型可以進(jìn)行學(xué)生和教員的適配。通過實(shí)驗(yàn)驗(yàn)證,SVM支持向量機(jī)對(duì)于本項(xiàng)目來說優(yōu)于其他算法。本文采用的:前端-后端-后臺(tái)-后端-前端的數(shù)據(jù)傳送模式也十分契合本項(xiàng)目。在前后端優(yōu)化過程中,注重信息保護(hù),信息推送的合理性。同時(shí)考慮到面向的用戶為年輕群體,UI總體設(shè)計(jì)簡約,配色清新活潑,符合系統(tǒng)用戶的審美特點(diǎn)。
猜你喜歡
電子技術(shù)與軟件工程(2016年22期)2016-12-26 21:36:42
時(shí)代金融(2016年27期)2016-11-25 17:51:36
科教導(dǎo)刊(2016年26期)2016-11-15 20:19:33
科學(xué)與財(cái)富(2016年28期)2016-10-14 21:19:17
科教導(dǎo)刊·電子版(2016年10期)2016-06-02 18:04:11

- 電腦知識(shí)與技術(shù)的其它文章
- 職業(yè)院校《C語言程序設(shè)計(jì)》課程思政教學(xué)實(shí)踐探究
- 工程教育專業(yè)認(rèn)證背景下應(yīng)用型高校計(jì)算機(jī)專業(yè)多元融合教學(xué)體系改革研究
- “對(duì)分課堂+混合式學(xué)習(xí)”在醫(yī)學(xué)類高職院校計(jì)算機(jī)基礎(chǔ)課程中的實(shí)踐研究
- 教育信息化背景下應(yīng)用型高校一流教材建設(shè)研究
- 大數(shù)據(jù)+人工智能背景下混合式教學(xué)案例設(shè)計(jì)
- 產(chǎn)教融合背景下高校計(jì)算機(jī)專業(yè)人才培養(yǎng)模式探索