面向機器學習的醫學檢驗大數據構建與實踐
2023-04-27 04:00:42王瑩周玉利顧大勇
電腦知識與技術 2023年7期
王瑩 周玉利 顧大勇


關鍵詞:檢驗醫學;大數據;機器學習;數據集成;數據治理;數據開發
0 引言
檢驗醫學作為醫學科學的重要支撐性技術學科,在疾病的早期診斷、病情監測、預后判斷與風險評估等方面發揮著重要作用。隨著醫學檢驗實驗室自動化、現代化技術水平的提升,醫學檢驗數據飛速增長,日積月累產生了海量數據資源,其中蘊藏著大量已知和未知的臨床相關規律。科研人員通過回顧性或前瞻性研究,重新解讀醫學檢驗數據將發揮其重要價值,不僅有助于進一步了解疾病的本質,確定疾病精準診療的方法,而且有利于發現新型診斷標志物和持續優化醫學檢驗項目的參考區間[1]。據不完全統計,臨床決策所需信息的70%來自醫學檢驗,為臨床診斷提供強有力的數據支持[2-4] 。醫學檢驗數據不僅體量巨大、類型繁多,還有特征高維和冗余等特點,傳統的數據存儲和統計分析方法已難以處理愈加龐大的醫學檢驗數據[5-7]。
目前,醫學檢驗數據主要作為一次性的臨床診斷參考以及小樣本量的研究分析,導致這種狀況的客觀原因,一方面是醫學檢驗數據量大、醫學檢驗項目參考區間相對固定的顯性信息明確,另一方面是醫學檢驗數據散落在實驗室信息管理系統(Laboratory Infor? mation System,LIS) 中,傳統的數理統計工具和小樣本量難以全面、系統地發掘海量醫學檢驗數據中蘊藏的信息。主觀原因,一方面是傳統科研的問題導向流程,采用“發現問題、形成假說、收集數據、分析數據”的模式,數據的作用是支持假說而不是用于發現問題或規律;另一方面是把大數據平臺或工具充當計算能力更強、存儲空間更大的數據平臺[8-13]。這些原因導致醫學檢驗數據應用方式不同程度存在四個方面的缺憾:①人為把“大數據”裁剪為“小數據”,方便使用傳統的統計分析工具,可能會錯失被裁剪掉數據所蘊含的有價值信息;②對大數據重點關注數據量的維度,卻忽略了大數據的另一重要特征——數據種類多;③數據收集僅用于一次性特定的研究目的,沒有考慮復用于其他研究,導致產生大量重復的數據收集、數據清洗等工作;④傾向選擇理想的數據集作為標準的機器學習數據源,這與真實世界的數據分布情況差異較大,生成的機器學習模型普適性存疑。
傳統的數據收集、處理方式無法滿足機器學習和大數據對數據的需求,機器學習涵蓋了廣泛的方法,旨在為計算機提供學習任務的能力。這些方法依賴于從幾乎沒有人工輸入的數據中獲取模式的算法。這與嚴格依賴人類知識來驗證模型假設和變量選擇的統計技術形成鮮明對比。大數據方法通常不受經驗知識的影響,無偏見地收集和分析數據,并發現重要的模式,支持循證醫學,通過構建相關的預測模型,從而更準確地評估疾病風險以及改善預后[14-15]。現有各種醫院信息化系統的設計初衷主要是為了滿足醫療業務流程需要,因此,在后續數據分析與應用的需求滿足上尚存在較大差距,數據的收集和管理方面缺乏結合人工智能等高價值的數據二次利用的設計考慮[16]。傳統科研模式中存在的“科研構思難、數據獲取難、想法驗證難、數據處理難”等弊端,已嚴重阻礙臨床研究水平的進一步提升,亟待使用新的技術手段加以解決[17]。
本研究針對醫學檢驗數據的大數據化進行創新,面向機器學習對數據質量的要求,綜合考慮實驗成本和實驗目標需要,選擇近5年的全量醫學檢驗數據,使用大數據技術把選定時間段的全量醫學檢驗數據系統化治理、開發,形成時段性醫學檢驗大數據,實現對醫學檢驗數據的高效率復用和可持續積累模式的探索與驗證。
1 醫學檢驗大數據關鍵技術
1.1 轉置數據結構
醫學檢驗數據采集、處理、存儲均依托LIS,LIS作為業務系統通常采用關系型數據庫,關系型數據庫具有強大的事務處理能力,盡可能降低數據冗余度,節約存儲空間,關系型數據庫的結構特點決定了其只能做簡單的統計分析,不能做復雜的邏輯運算。基于關系型數據庫的數據結構不能滿足復雜的數據分析需求。隨著計算、存儲技術的發展,計算和存儲資源的成本飛速下降,在數據結構方面以空間換時間的數據寬表結構應運而生,數據寬表是一張把業務主題相關的指標、維度、屬性關聯在一起的數據庫表,數據寬表具有降低數據復雜度、結構簡單、數據完備度高、減少數據交互、數據訪問效率高和易于業務人員自主使用數據等優點,廣泛應用于數據挖掘模型訓練前的數據準備[18-20]。
傳統的醫學檢驗數據結構是以患者為中心,以提供患者個體的檢驗報告為目的,構成醫學檢驗數據的醫學檢驗項目及結果以多行的形式存在,方便直觀展示患者個體各個醫學檢驗項目結果,不利于對不同患者同一個醫學檢驗項目結果做復雜邏輯運算。轉為數據寬表可以實現患者ID主關鍵字的所有醫學檢驗項目位于同一行,不同患者的同一醫學檢驗項目結果位于同一列。可以在一張數據表中直接對不同患者的同一醫學檢驗項目數據治理、數據開發后進行統計分析和復雜邏輯運算。
1.2 建立數據治理標準
數據質量是數據發揮價值的關鍵,數據治理是提升數據質量、降低數據管理成本、保障數據安全和控制數據風險的方法。醫學檢驗數據通常來自不同廠家的不同類型的設備,以實現醫學檢驗功能為目的,缺乏全局性的數據標準,數據類型和質量參差不齊,主要存在非結構化數據、數據格式混亂、無效數據、重復數據、錯誤數據、數據缺失等問題。大部分的醫學檢驗數據為結構化數據,天然符合復雜邏輯運算需求,但數據的使用維度是面向檢驗報告,導致大量的非結構化數據混雜其中,如定性的陰性、弱陽性和陽性等非結構化文本。數據格式混亂包括定量的格式化數據中混雜“<”“>”“+”“.”“*”“中英文注解”和“NULL”等,錯誤數據包括人工錄入錯誤(如:1.00錄入1.0.0) 、年齡為負值、數據類型轉換錯誤(數值區間1~2轉為1月2日)等,無效數據包括定標數據、測試數據、系統無法出具檢驗項目結果的默認數據等。
醫學檢驗數據治理需要全面統計分析醫學檢驗數據,在符合實際業務需求的前提下,建立數據清洗和數據轉換的標準。對于多值有序非結構化數據按照業務要求的順序直接轉化為有序數值,對于多值無序非結構化數據,則留待后續實際使用時采用獨熱編碼(One-Hot Encoding)方式處理;對于格式化數據中混雜的非格式化符號一般采用針對性刪除的方式;對于錯誤數據根據實際業務情況核驗后的結果,采用正確的數據做替換;對于定標數據、測試數據和系統無結果默認數據等采用針對性刪除的方式。對于診斷結果通過統計分析基于不同語言、縮略方式、命名習慣等方式帶來的同一疾病的重復情況,根據業務需求對其做標準化統一。
2 醫學檢驗大數據實驗方案設計
大數據的基礎是數據與應用分離,把數據作為資源實現數據資產化,避免重復數據集成、數據治理和數據開發,該理念貫穿數據的全生命周期。在方案設計時采用分層策略實現清晰數據結構、減少重復開發、統一數據口徑和復雜問題簡單化。
2.1 整體方案
整體方案分為三層,分別為數據應用層、數據操作層和數據來源層,如圖1所示。其中數據應用層包括數據統計分析、機器學習和數據展示等應用。數據操作層對數據來源首先進行數據集成,數據集成后的一個副本做行列轉置,實現數據結構從關系型向數據寬表轉換。通過數據洞察全面分析數據質量,根據分析結果制定數據標準。按照數據標準采用計算機程序做數據清洗和數字化轉換。根據需要做數據歸一化,通過數據服務的方式向數據應用層提供數據調用查詢服務。數據來源層主要為LIS和醫院信息系統(Hospital Information System,HIS)的關系型數據庫。
2.2 方法設計
在數據操作層采用整體分級模式和分段清洗模式的數據治理方法,實現關系型數據平滑向數據寬表轉化。
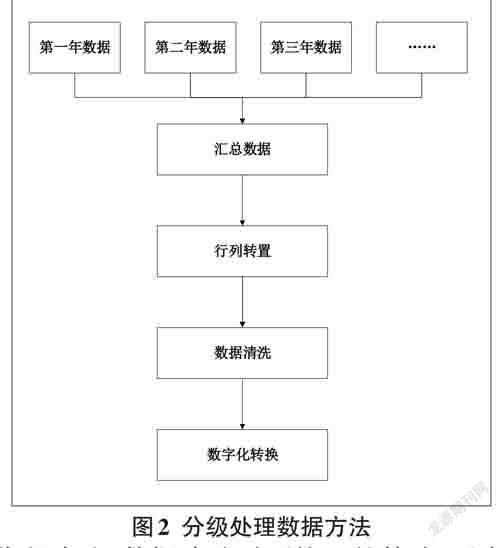
整體分級模式:數據集成、數據治理和數據開發涉及多個環節,產生錯誤則牽一發而動全身。采用分級處理的方法來實現功能分工、隔離穩定和方便實現的原則。主要分為數據集成、行列轉置、數據清洗和數字化轉換,如圖2所示。每一級的輸入和輸出均有對應的數據表,每一級產生的系統或人工操作錯誤不會波及上一級,從而實現錯誤的有效隔離。
分段清洗:數據清洗需要統一的策略,避免數據被多次清洗[21]。數據清洗通常采用結構化查詢語言(Structured Query Language,SQL) ,SQL功能豐富、應用靈活,但在實際應用中運行環境出于系統安全考慮會做相應的資源限制,如果一次清洗的字段過多,會導致清洗語句的長度或者清洗程序占用空間超出資源限制,從而產生系統錯誤。如果將源數據表拆分為多個數據表再進行數據清洗,雖然可以避免該錯誤,但在數據量較大時,拆分過程的操作復雜,效率較低。采用分段清洗模式在保持整體一致性的基礎上,通過對字段的分段實施,靈活適應運行環境可提供的資源。如圖3所示,S1、S2、……Sn為源數據表中的字段名稱,T1-1、T1-2、……T1-n為目標數據表T1中的字段名稱,“as”代表字段對應數值的簡單的復制賦值,“->”代表字段對應數值經過SQL語句(例如Case when條件語句)處理后的結果賦值。整體清洗程序在運行環境資源許可的情況下一次性完成,如果超出運行環境資源限制,可以針對一部分字段進行清洗處理,另外一部分保持簡單賦值模式。例如第一段清洗程序只對源數據表S 中的S1、S2和S3三個字段的數值進行清洗,清洗后的結果分別賦值到目標數據表T1 中對應的T1-1、T1-2、T1-3三個字段,源數據表S 中其余字段(S4至Sn)不做處理,直接賦值到目標數據表T1中對應的(T1-4至T1-n)。在第二段清洗中數據表T1為目標數據表,已經完成清洗的字段T1-1、T1-2、T1-3直接賦值新的目標數據表T2對應T2-1、T2-2、T2-3字段。T1-4、T1-5、T1-6三個字段的數值經過清洗后賦值到目標數據表T2的T2-4、T2-5、T2-6三個字段。源數據表T1的剩余字段(T1-7至T1-n) 不做處理直接賦值到目標數據表T2中對應的(T2-7至T2-n),后續分段依此類推,直至完成所有字段的清洗工作。
3 實驗實施與分析
3.1 實驗環境與實驗數據
研究采用的實驗環境為商用公有云服務提供的大數據計算服務平臺Maxcomputer和大數據開發治理平臺Dataworks。數據清洗采用SQL腳本。數據為某醫院2016年10月1日至2021年09月30日的LIS和HIS中全量醫學檢驗數據及診斷結果。原始數據包括患者的ID、年齡、性別、部門(門診或住院)、檢驗日期、醫學檢驗項目編碼、檢驗結果、診斷結果共8個字段。醫學檢驗項目總計1 297項(包括部分來自不同儀器設備對相同檢驗項目的重復),醫學檢驗數據合計141 477 953條。在實驗中,把醫學檢驗數據轉化為醫學檢驗大數據。
3.2 實驗實施過程
數據集成:以年為單位,從LIS和HIS中抽取患者的全量醫學檢驗數據和診斷結果生成數據文件,刪除861 252條無效醫學檢驗數據后剩余140 616 701條醫學檢驗數據的數據文件依次導入大數據計算服務平臺Maxcomputer。并逐年核對數據總量,保證數據導入過程不存在遺漏或丟失。
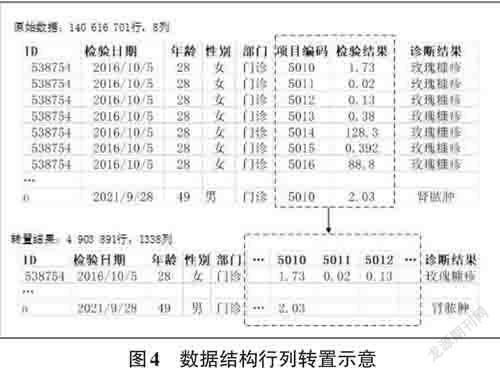
數據結構轉置:以患者ID為主關鍵字、檢驗日期為次關鍵字,把對應的醫學檢驗項目和結果從多行模式轉為多列模式,每位患者在確定的檢驗日期的所有醫學檢驗數據成為數據寬表的一條記錄,如圖4所示,140 616 701 行、8 列關系型數據表轉置為4 903 891 行、1 338列的數據寬表。
數據清洗:對轉置后的數據寬表的每一列分別做不重復數據查詢,并統計相應的數據類型、數值型數據數值區間、數據量、錯誤數據類型等。根據統計分析結果和對應字段的醫學意義制定數據治理標準。按照數據治理標準針對每一列在SQL腳本中實現相應的措施。例如對于簡單的“>”“<”和“*”等無效字符的清除,直接采用空字符替換方式,對于結構混亂數據,采用正則表達式去除非法字符,對于少量的人工錄入錯誤,采用正確數值替換的方式。
數字化轉換:對于多值有序非結構化數據第一項為0、公差為1,構建數值列對多值有序非結構化數據做相應的字符替換。
3.3 實驗結果
經過上述處理環節,4 903 891行、1 338列的數據寬表中絕大數列已轉為結構化數據,極少數因為源數據標準不一且數據量較少的醫學檢驗項目結果未做處理,數據寬表每一條記錄對應的診斷結果未做處理,主要是為了保障按照疾病種類查詢的便利和靈活性。在研究思路產生階段快速查詢所關心疾病所對應的數據量或若干項醫學檢驗項目的數據量來決定是否有必要進行研究。在數據應用階段,可以根據研究需要,隨時檢索抽取其所包含的所有疾病類別對應的全項醫學檢驗數據,在數據挖掘分析階段,不但可以繼續使用傳統數理統計工具處理進行分析,而且可以直接被各種機器學習算法讀取,而無須重復為不同的機器學習算法或不同的疾病做煩瑣的數據處理工作。通過實驗不但可以全面掌握醫學檢驗項目實際覆蓋率,而且可以分鐘級快速驗證科研構思的可行性,分鐘級完成機器學習數據源準備。
對4 903 891條記錄中每個醫學檢驗項目的檢驗數量做了統計,檢驗數量超過百萬的41項,其中最高項平均紅細胞體積為2 128 955,占記錄總數的43.41%,即43.41%的患者均做了平均紅細胞體積這個醫學檢驗項目。檢驗數量為50萬至100萬26項,檢驗數量為10萬至50萬142項,檢驗數量為1萬~10 萬439項,檢驗數量為1萬以內651項。通過時段性全量檢驗數據統計,第一次全景展示選定時段的所有醫學檢驗項目的實際覆蓋率。
大數據可以有效地節省臨床操作和研發兩個方面的投入,本研究成果帶來了直觀的科研高效率,通過幾分鐘的檢索驗證了B淋巴母細胞瘤白血病、慢性中性粒細胞白血病、毛細胞白血病等只有數十到數百不等病例的科研構思的不可行性。只需要通過診斷結果的簡單篩選,用時幾分鐘即可具備一種疾病類型的機器學習業務流程所需的數據源。已經生成了急性髓系白血病、慢性粒細胞白血病、甲狀腺疾病、乳腺惡性腫瘤等疾病的機器學習模型,機器學習模型不但具有較高的預測水平,預測評估結果的主要指標受試者工作特征曲線下面積(Area Under Curve,AUC)、F1- Score大部分在0.9以上;而且發現了一些醫學檢驗項目和某些疾病存在常規研究無法察覺的相關性,例如淀粉酶與慢性粒細胞白血病密切相關。
4 結束語
在傳統的臨床研究模式下,數據采集和數據處理分析均是耗費大量人力、物力的工作,嚴重制約臨床科研成果的產出效率。據統計,在醫院采用傳統人工模式僅在數據處理階段就需要1~2個月、數據抽取耗時5個月、科學研究約需1個月,醫護科研人員的時間大量花費在數據的準備階段[22]。有研究認為,臨床數據獲取困難且需要大量的手工處理,導致科研周期長、效率低下。合理的方式是科研人員將精力放在科研本身,節約科研人員的時間,提高科研產出[23]。大數據時代需要大數據思維,大數據思維強調整體性,要求用整體的眼光看待數據,與個體化時代強調研究部分有代表性的數據大不相同[24]。
本研究采用了離線方式抽取2016—2021年近5 年的某綜合性三甲醫院全量臨床檢驗數據,沿用了現存業務部門與信息技術部門的合作模式和流程。使用了基于公有云服務的大數據平臺和機器學習平臺,大幅降低了試錯成本,提高了研究效率。對全項醫學檢驗數據不做p特定需求的處理并采用SQL腳本固化了數據治理、開發的方法和經驗,可以平滑遷移到將來的自建醫療大數據平臺,既可對歷年醫學檢驗數據統一處理,又可以實時處理新增醫學檢驗數據,彌補本研究僅離線處理時段性歷史數據的不足。
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
科學與財富(2016年28期)2016-10-14 21:19:17
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
