結合特征增強和多尺度感受野的低照度目標檢測
2023-04-19 18:33:34江澤濤翟豐碩張少欽
計算機研究與發展 2023年4期
江澤濤 翟豐碩 錢 藝 肖 蕓 張少欽
1 (廣西圖像圖形與智能處理重點實驗室(桂林電子科技大學)廣西桂林 541004)
2 (南昌航空大學土木建筑學院 南昌 330063)
(zetaojiang@126.com)
目標檢測是計算機視覺領域的研究熱點之一,目標檢測近年來也取得了很大的進展,它廣泛應用于機器人視覺[1]、車輛識別與跟蹤[2]、行人檢測[3]和軍事視頻監控[4]. 然而,在不利光照條件下,目標檢測仍然具有挑戰性.因為缺乏足夠照明,采集到的圖像會出現一系列退化,例如低亮度、低對比度、強烈的噪聲等,目標檢測的漏檢率和誤檢率會大幅增加. 低照度目標檢測需要克服低照度圖像細節特征不明顯的缺陷,充分提取利用有限特征,最后輸出高精度的檢測結果.
早期低照度目標檢測[5]一般使用紅外成像相機實現,紅外熱成像相機對物體的溫度信息敏感,但無法區分溫差較小的物體. 隨著深度學習的快速發展,目前的低照度目標檢測[6]主要依靠RGB 數碼相機拍攝圖像,再將數字圖像輸入計算機完成目標檢測算法. 這種方法圖像數據獲取成本較低,圖像的動態范圍更大,進而可以捕獲更多的視覺信息,因此檢測精度也有了較大提升. 目前基于域適應的低照度目標檢測算法[7]需要用到明暗成對的數據集訓練生成對抗網絡(generate against network, GAN)[8],再由通用目標檢測算法輸出檢測結果. 這種方案模型較難擬合,實現條件較為苛刻,檢測結果輸出在原圖上,人眼無法直觀評估檢測結果的好壞. 此外,低照度圖像增強算法很好地實現了低照度圖像到正常照度圖像的轉換,但是其模擬的增強效果是基于人眼視覺效果的,對于計算機而言,增強過后的圖像目標特征信息會有所損失,將其直接送入主流目標檢測模型,很難得到較好的檢測精度.
針對上述不足,本文研究一種結構簡單、精度較高且能夠在正常照度風格圖像上輸出檢測結果的端到端低照度目標檢測算法. 該算法結合高清攝像機的數據優勢和深度神經網絡的強大學習能力,提出一種像素級高階映射(pixel-level high-order mapping,PHM)模塊去增強低照度圖像特征,這個初步增強圖像特征的過程視為粗調. 粗調之后的圖像特征經過關鍵信息增強(key information enhancement, KIE)模塊過濾噪聲信息,再次對特征信息進行優化,這個再次增強圖像特征的過程視為細調. 2 階段調整使得網絡輸出更加顯著的低照度圖像特征信息,然后利用特征金字塔網絡將全局特征和局部特征信息充分融合,提高每張特征圖的特征表達能力. 此外,在特征金字塔中添加長距離特征捕獲(long distance feature capture,LFC)模塊,搜尋特征圖中目標的長距離依賴關系,利用多種不同尺度的感受野,提高算法的目標檢測精度. 最后,使用多個預測分支去直接回歸目標檢測框的位置和大小.
本文的主要貢獻有3 點:
1) 提出PHM 模塊,增大低照度圖像待檢測物體的局部特征梯度,進而提升目標檢測精度;
2) 在富含大量特征信息的中等尺寸特征圖上,添加KIE 模塊,突出重要信息,過濾噪聲信息,促進檢測網絡的快速收斂;
3) 提出LFC 模塊,捕獲孤立區域的長距離關系,提高對極端長寬比物體的檢測能力.
1 相關工作
1.1 低照度圖像增強
低照度圖像普遍存在整體亮度不足、對比度較低等問題,人眼難以獲取圖像信息,低照度圖像增強算法可以有效解決這些視覺難題. 目前已有大量圖像增強算法被提出,早期基于直方圖均衡化[9]的圖像增強算法使用額外的先驗和約束,試圖放大相鄰像素之間的灰度差,擴展了圖像的動態范圍. 基于去霧的圖像增強算法[10]借鑒將圖像求反然后去霧的思路,將低照度圖像求反去霧再求反的方式進行處理,用于還原低照度圖像更多的細節,但是基于去霧的算法丟失了過亮區域的細節. Retinex 理論[11]指出物體亮度由物體本身的反射分量和環境光照2 個因素構成. 基于該理論,RetinexNet[12],KinD[13]等算法通過處理環境光照分量來達到增強圖像的效果. MBLLEN[14]算法在不同等級中提取出豐富的圖像特征,利用多個子網絡做圖像增強,最后通過多分支融合產生輸出圖像,圖像質量從不同的方向得到了提升,但有時會出現過曝光的增強結果. 這些算法都需要使用成對的明暗數據集訓練端到端的低照度圖像增強網絡.Zero-DCE[15]使用一系列零參考的損失函數來引導低照度圖像向正常照度和高質量視覺特征的方向轉換,不需要使用成對的明暗數據集,該算法可以泛化到各種光照條件下,同時計算量很小,可以方便地應用到其他下游任務中,提高目標檢測任務的檢測精度.
1.2 目標檢測
近年來,目標檢測領域已經取得了長足的進步. 很多優秀的目標檢測算法被提出:YOLO 系列目標檢測算法(YOLOv1[16]、YOLOv2[17]、YOLOv3[18]、YOLOv4[19]、YOLOv5[20]、YOLOX[21]),該系列的主體框架為特征提取器和檢測頭. YOLOv1 中的檢測頭為2 個全連接層,直接預測邊界框的位置和寬高,速度快,但是精度較低;YOLOv2 引入偏移量的概念,預先定義大量已知位置和寬高的錨框(anchor),降低直接預測邊界框的位置和寬高的難度;YOLOv3 主要對YOLOv2 進行了改進,將檢測頭分成3 部分,分別負責檢測大、中、小目標;YOLOv4 進一步對檢測頭進行了改進,并使用了CIOU[22]損失函數來進行網絡模型的訓練,還改進了特征提取和特征融合模塊等;YOLOv5 采用了自適應的錨框,在特征融合部分添加FPN[23]和PAN[24]結構,損失函數使用GIOU[25]損失函數等;YOLOX 放棄先驗框的設置,使用無錨框的訓練方式,提升網絡模型的通用性. 此外,R-CNN 系列目標檢測算法(R-CNN[26]、Fast R-CNN[27]、Faster R-CNN[28])有著更高的檢測精度,但是檢測速度較慢,R-CNN 首先對圖像選取若干建議區域并標注類別和邊界框,然后對每個建議區域提取特征,進一步確定邊界框和目標類別;Fast R-CNN對整幅圖像進行特征提取,減少R-CNN 中對每個建議區域特征提取導致的重復計算;Faster R-CNN 將生成建議區域的算法從選擇性搜索變成了區域建議網絡. 另外,EfficientDet[29]為不同應用場景提供了7 種不同大小的模型,實現了速度和精度之間的均衡;Foveabox[30]、FCOS[31]、CornerNet[32]等基于關鍵點或中心域法的無錨框(anchor-free)目標檢測算法也有較高檢測精度和檢測速度. 同時,特征金字塔、Focal loss[33]等關鍵技術被廣泛應用到各個目標檢測算法中. 但這些目標檢測算法在低照度場景下都不能取得很好的檢測精度,本文研究在這些目標檢測算法的基礎上構建一個端到端的低照度目標檢測算法框架.
1.3 注意力機制
注意力機制已廣泛應用于計算機視覺的各個領域,并取得了良好的效果. 注意力機制對輸入數據的各個部分按照其對結果的影響程度分配不同的權重.Hu 等人[34]提出了通道注意力,對特征通道間的相關性進行建模,降低無關信息的影響,強化重要區域的特征,幫助網絡模型具備更好的語義表達能力.
通道注意力機制的實現分為3 個部分:擠壓、激勵和注意. 通過擠壓函數可以將H×W×C的特征圖變換成1×1×C的特征向量,如式(1)所示:
其中H,W分別表示特征圖的長和寬,將每個通道內所有的特征值相加再取平均,即得到代表每個通道信息的特征向量.
激勵過程學習各通道的依賴程度,并根據依賴程度對不同的特征圖進行調整,得到權重向量:
其中 δ表示ReLU 激活函數,σ表示Sigmoid 激活函數,w1和w2分別表示激勵階段的前后2 個特征向量.
注意階段將權重向量與特征圖對應通道的每個特征值相乘,如式(3)所示:
其中,x表示輸入特征圖,w表示權重向量.
Wang 等人[35]提出了空間注意力,讓網絡關注圖像特征中的特定區域,顯著提升了圖像分類任務的準確率. 在目標檢測領域,除了語義信息外,位置信息也相當重要,Woo 等人[36]將空間注意力和通道注意力進行整合,使目標檢測網絡更積極地關注含有待檢測目標信息的重要特征. Vaswani 等人[37]提出了自注意力機制,將特征圖每個位置的更新都由計算特征圖的加權和得到,這個權重來源于所有位置中的成對關聯,這樣可以建立長距離依賴.
2 低照度目標檢測框架
2.1 基本思路和總體設計
本文提出結合特征增強和多尺度感受野(feature enhancement and multi-scale receptive field, FEMR)的低照度目標檢測模型,將像素級高階映射(PHM)模塊、關鍵信息增強(KIE)模塊、長距離特征捕獲(LFC)模塊與YOLOX 目標檢測模型相結合. 首先輸入低照度圖像數據,通過人工設計的損失函數去擬合高階映射模塊的網絡參數,使其在前向傳播中向正常照度圖像的特征分布逼近,得到初步增強的特征圖,提升模型對低照度圖像特征的利用效率. 其次在此基礎上,使用特征提取網絡對初步增強的特征圖進行深層次特征提取,得到3 種不同大小尺度的特征圖,該特征提取網絡結構與YOLOX 模型結構保持一致,再利用通道空間注意力和外連接注意力機制的差異化特性,對特征圖進行引導,讓模型關注對檢測結果貢獻更大的關鍵特征,為多尺度感受野特征金字塔部分提供富含高層語義信息和淺層位置信息的高質量特征圖. 在低照度圖像中,觀察發現孤立區域內經常存在極端比例的待檢測目標,引入條狀感受野可以加強對長距離特征關系的捕獲能力,提升網絡模型對該類目標的檢測能力,同時不會帶來過多的參數和計算量. 最后利用3 個檢測頭進行特征解碼,去預測目標框的位置、高寬和對應的類別. 本文所提模型具備直接檢測低照度圖像中不易識別和極端比例目標物體的能力,并輸出帶有目標框信息的正常照度風格圖像.
如圖1 所示,模型整體可分為5 個部分,分別是圖中上方的像素級高階映射,下方左邊的特征提取,中間的關鍵信息增強和多尺度感受野特征金字塔,右邊的特征解碼.各部分相互獨立,因此該模型結構具有較高的靈活性.
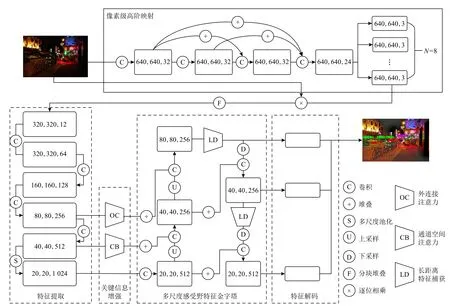
Fig.1 Architecture for FEMR low illumination object detection algorithm圖1 FEMR 低照度目標檢測算法結構圖
2.2 像素級高階映射模塊
低照度圖像特征的不顯著性嚴重影響目標檢測算法的檢測精度,因此本文設計圖像特征增強模塊去解決這個問題. 具有RGB 三通道的低照度圖像,經過固定尺寸縮放和歸一化后,作為模塊的輸入,輸出為經過初步特征增強的三通道特征圖. 該模塊可以擬合出一個高階映射曲線,為輸入圖像的每一個像素建立映射關系.
本文設計的PHM 模塊結構細節如圖2 所示,模塊主要由4 層卷積構成,其中卷積核大小均為3×3,步長為1,卷積過程中保持與輸入相同的尺度大小,前3 次卷積擴充通道數為32,并用ReLU 激活函數[38]激活,消除網絡運算過程中得到的負值,第4 層卷積將通道數調整為24,并用tanh 激活函數[39]激活,將輸出結果壓縮到(0,1)區間范圍內,并拆分成N張三通道的特征圖,N=8.
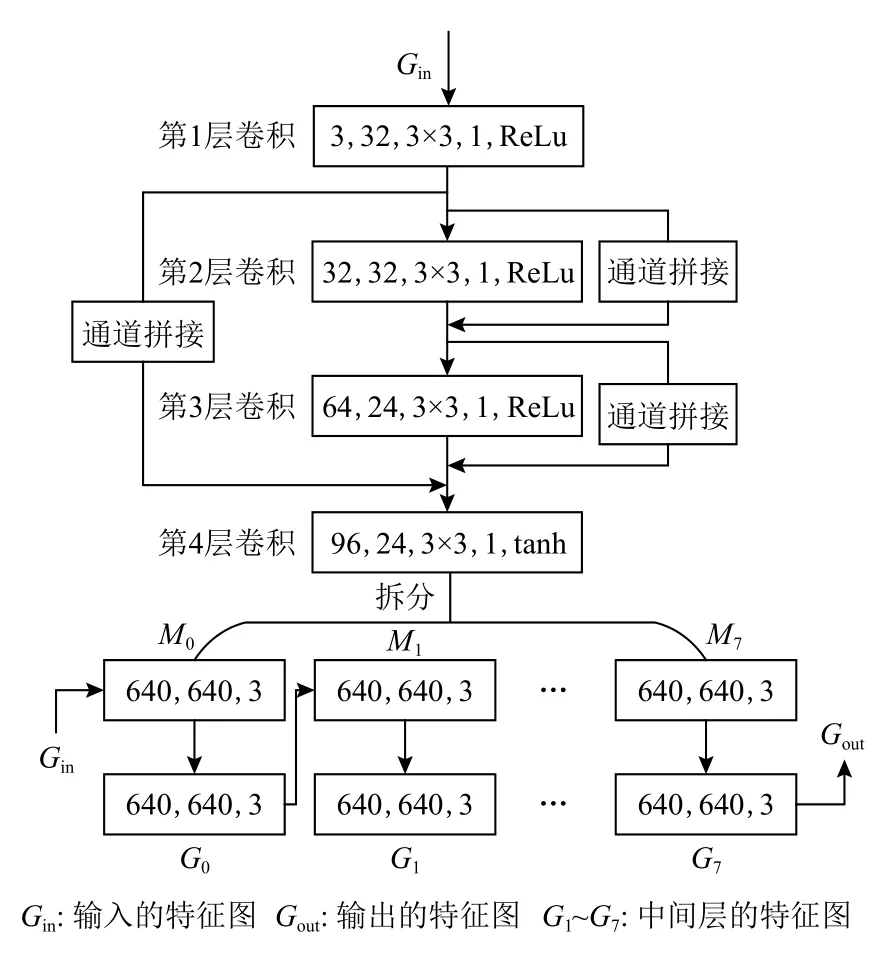
Fig.2 PHM module structure diagram圖2 PHM 模塊結構示意圖
將輸入圖像與這N張特征圖上對應的值進行運算,得到初步增強的特征圖,該運算過程為
為了引導網絡得到合理的增強映射關系,本文設計了3 個損失函數:曝光損失、光照平滑損失、色彩一致性損失. 曝光損失函數控制圖像的曝光強度范圍,首先預設一個正常光照強度[40]等級E,然后計算固定大小區域內的平均灰度值等級Yk與預設E之間的L1距離,本文設定的固定區域大小為16×16,同時設置E=0.6. 這個正常光照強度等級E是一個超參數,通過不斷縮小該距離,讓網絡學習到將低光圖像特征映射成正常光照圖像特征的參數值. 該損失函數表示為
其中S表示特征圖被劃分的區域個數,Yk表示各個區域的平均灰度值等級,E表示預設的正常光照強度等級.
為了保持相鄰像素之間的單調關系,本文設計了一個光照平滑損失函數,通過減小水平方向、豎直方向和對角方向的灰度差值,來達到光照平滑的效果.該光照平滑損失函數可以用式(6)表示:
其中H,W表示特征圖的高和寬,Mi,j表示對應第i行第j列的灰度值大小.
圖像的淺層特征主要包含顏色等信息,同時考慮到圖像RGB 顏色三通道的色彩穩定性[41]. 因此本文設計了一個提升色彩一致性的損失函數,將RGB三通道拆分成(R,G),(R,B),(G,B)三個組合,然后不斷減小每2 個通道之間平均強度的L2 距離,最后實現色彩的一致性. 該損失函數表示為
其中Jp和Jq分別表示對應p和q通道的整體灰度值強度大小,?表示各通道進行組合的列表.
特征增強的高階映射模塊整體損失由式(5)(6)(7)3 個損失函數聯合計算,可以用式(8)表示:
其中Wexposure和Wcolor表示對應損失函數的權重.
2.3 關鍵信息增強模塊
如何充分利用從特征提取網絡提取的低照度圖像特征信息,是提高低照度目標檢測性能的關鍵問題. 本文設計了KIE 模塊,使網絡能夠關注重要信息;過濾噪聲信息,從少數重要的凸顯特征中獲取所需要的類別和位置信息,其中包括通道空間注意力和外連接注意力機制.
通道空間注意力結構如圖3 所示,其中的通道部分由2 個同時進行的平均池化和最大池化組成,將輸出的2 個向量逐位相加,并分2 次使用全連接層整合特征信息,最后使用Sigmoid 激活函數,壓縮它們的數值范圍并進行輸出,作為原始特征圖各個通道的權重系數. 空間部分主要在通道維度上使用最大池化和平均池化,將得到的2 張單通道的特征圖進行堆疊,再使用一個膨脹系數為2 的3×3 卷積調整通道數為1,每個位置的數值作為原始特征圖對應空間位置的權重. 空間注意力機制加權引導后的特征圖具有重點關注不同區域特征的能力;通道注意力機制加權引導后的特征圖具有關注不同通道維度特征的能力,將它們逐像素相加,可以最大化利用低照度圖像有限特征信息,使該模塊具有識別目標檢測關鍵信息的能力.
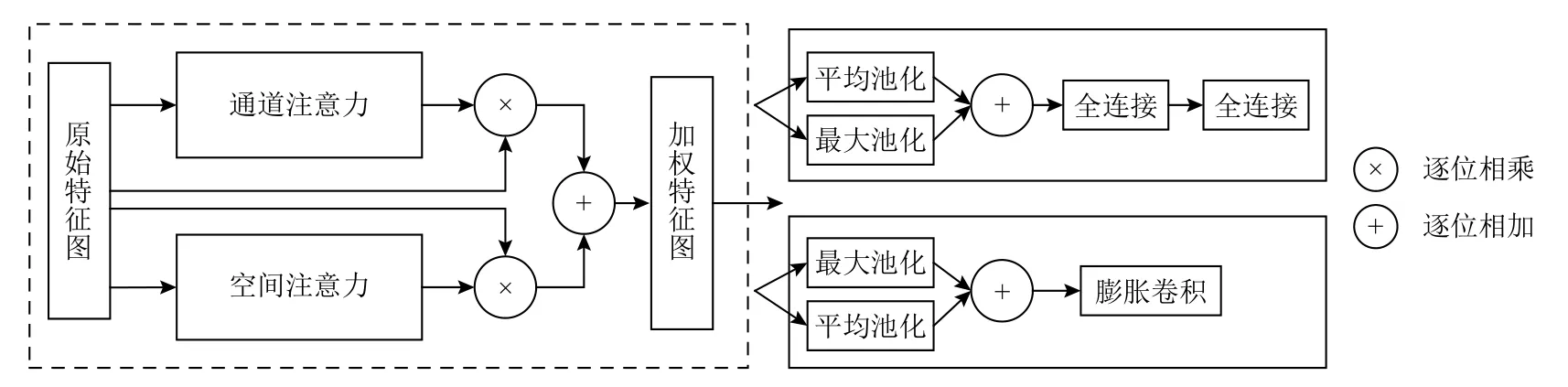
Fig.3 Channel spatial attention structure diagram圖3 通道空間注意力結構示意圖
通道空間注意力應用在40×40 的中等尺寸特征圖上,該層級的特征圖位置信息和高層語義信息都極為豐富,可以充分發揮注意力的自動分配權重的能力,以加快網絡模型訓練擬合速度.
對于大尺度特征圖,本文設計外連接注意力去讓網絡利用自身樣本內的信息,通過引入2 個外部記憶單元,隱式地學習整個數據集的特征,加強不同樣本間的潛在特征關系,外連接注意力結構如圖4所示. 首先,輸入特征圖經過維度變換,將特征圖轉換為特征向量,在全連接層中將其變換成其他維度大小,該層為線性層,不使用激活函數. 獲得第1 個輔助記憶單元,將一些和任務相關的信息保存在輔助記憶中,在需要時再進行讀取,這樣可以有效地增加網絡容量. 將第1 個記憶單元獲得的先驗知識經過線性變換得到第2 個記憶單元,增強網絡的建模能力. 外連接注意力使用較少的訓練參數,大幅增強特征信息的表達能力,并最終提高模型的檢測精度.
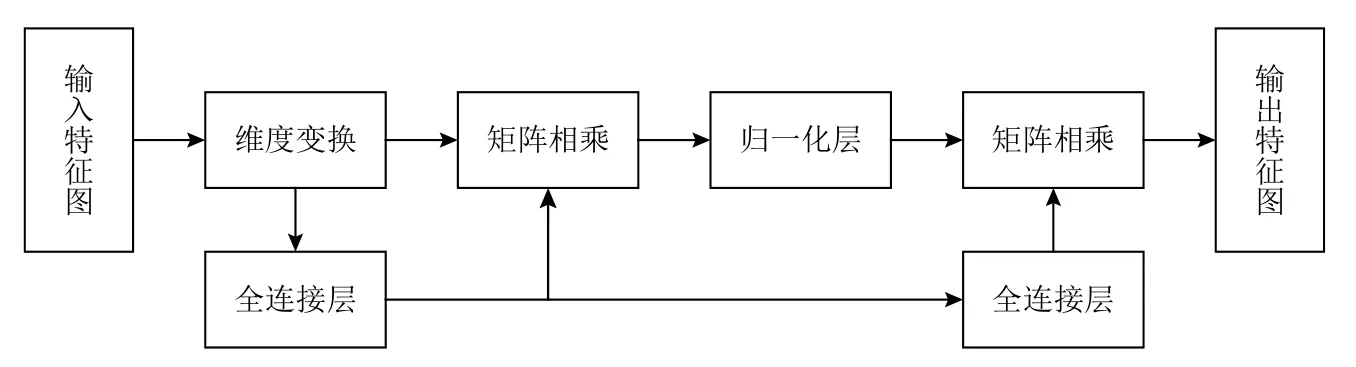
Fig.4 External connection attention structure diagram圖4 外連接注意力結構示意圖
2.4 長距離特征捕獲模塊
為了提高網絡對特征遠程依賴關系建模的能力,業界普遍采用自注意力機制和Non-Local 模塊[42],但這類算法的復雜度是相當高的. 因此,本文設計將長距離特征捕獲模塊嵌入到特征金字塔中,讓網絡有意識地關注場景中極端比例,前后位置距離相差較遠的特征信息.
LFC 模塊的結構細節如圖5 所示. 輸入特征圖經過2 個不同的卷積分支,得到同樣尺寸的特征圖,然后在2 個分支中采用不同的自適應池化策略. 上半部分分支中,第1 層特征圖被進一步特征提取,依次是利用3×3 的感受野進行卷積操作,不改變特征圖尺寸,使用自適應池化,將特征縮小為原來的1/3 倍和1/5 倍,對應著小感受野和稍大的感受野,然后通過上采樣和通道堆疊再壓縮,將多尺度感受野的特征信息進一步融合. 下半部分分支中,第1 層特征圖被進一步變換為2 個特征向量,其中1 個將寬壓縮為1,另一個將高壓縮為1,分別對應特征圖中每一行和每一列的遠距離關系,然后通過上采樣和通道堆疊再壓縮得到能夠捕獲水平方向和豎直方向的遠距離依賴關系的特征圖,最后將2 個分支得到的特征圖再次融合并輸出. 集成長而狹窄的池化核,使網絡可以同時聚合全局和局部上下文,在該模塊的幫助下,多尺度感受野特征金字塔網絡可以增強對孤立區域比例特殊目標的檢測能力.
3 實驗結果與分析
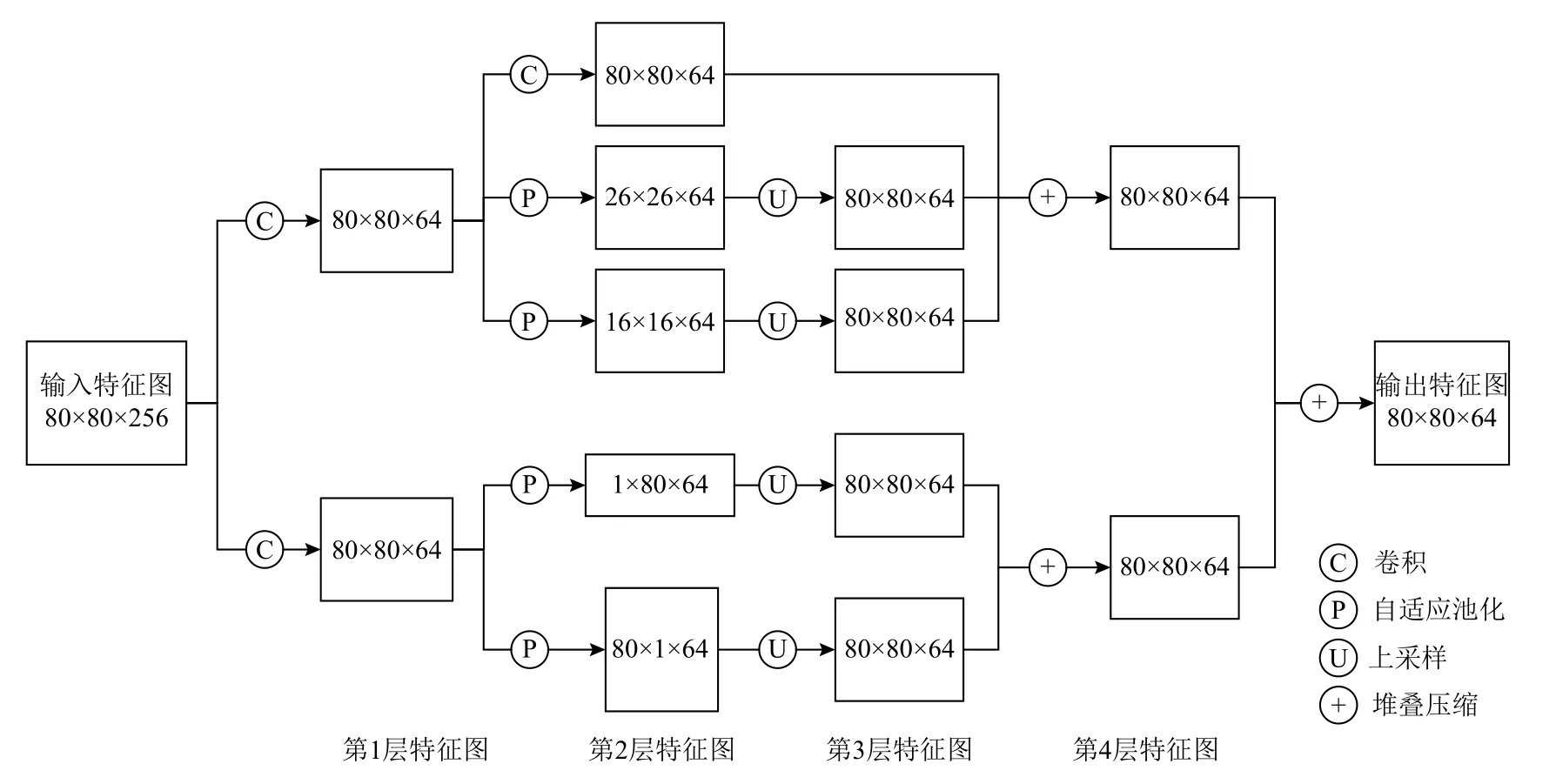
Fig.5 LFC module structure diagram圖5 LFC 模塊結構示意圖
本節主要在ExDark 低照度圖像數據集[43]上進行實驗,采用平均精度(mean average precision, mAP)作為衡量本文提出算法在低照度目標檢測性能上的評價指標. 本文所提出的低照度目標檢測算法具有低照度特征增強、多尺度感受野等特點,可以有效解決低光照帶來的問題. 本節重點討論3 個部分:實現細節、檢測性能、消融實驗. 本文的算法主要針對低照度環境,因此以ExDark 數據集的實驗結果作為主要的評價標準.
3.1 實現細節
本文的算法使用CSPDarknet53 作為主干特征提取網絡特征,特征提取網絡的預訓練權重是在ImageNet 圖像數據集[44]上訓練得到的. 模型訓練選擇AdaBelief[45]優化器,訓練分為前50 輪和后50 輪.前50 輪凍結主干特征提取網絡的權重,只訓練主干網絡以外的部分權重,學習率設置為1×10?3,一次傳入8 張圖片數據;后50 輪釋放主干特征提取網絡的權重梯度,允許網絡自動調整所有的訓練參數,學習率設置為1×10?4,1 次傳入4 張圖片數據. 訓練過程中使用余弦退火學習率算法[46],周期值設置為5,ETA最小值設置為1,使用標簽平滑算法[47],默認參數值設置為0.01. 實驗設備為Tesla P40 GPU,運行環境為Ubuntu 20.0.4.
3.2 檢測性能
本文在低照度圖像數據集(ExDark)上綜合評估所提出的低照度目標檢測算法,它包含12 個類別:單車、船、瓶子、公交、汽車、貓、椅子、杯子、狗、摩托、人和桌子. 在輸入尺寸為640×640 的條件下,本文算法在測試集上取得了77.80%的mAP,相比于目前最先進的YOLOv5 和YOLOX 等目標檢測算法,在檢測精度mAP上有了較大的提升. 表1 展示了本文所提出的算法與目前主流目標檢測算法的精度比較結果. 同時,本文還為模型設置了3 種不同版本的網絡模型. 通過改變網絡模型中的特征圖通道數,增大或減小模型所使用參數數量,以此來達到讓模型能夠適應不同的顯存大小顯卡的目的.
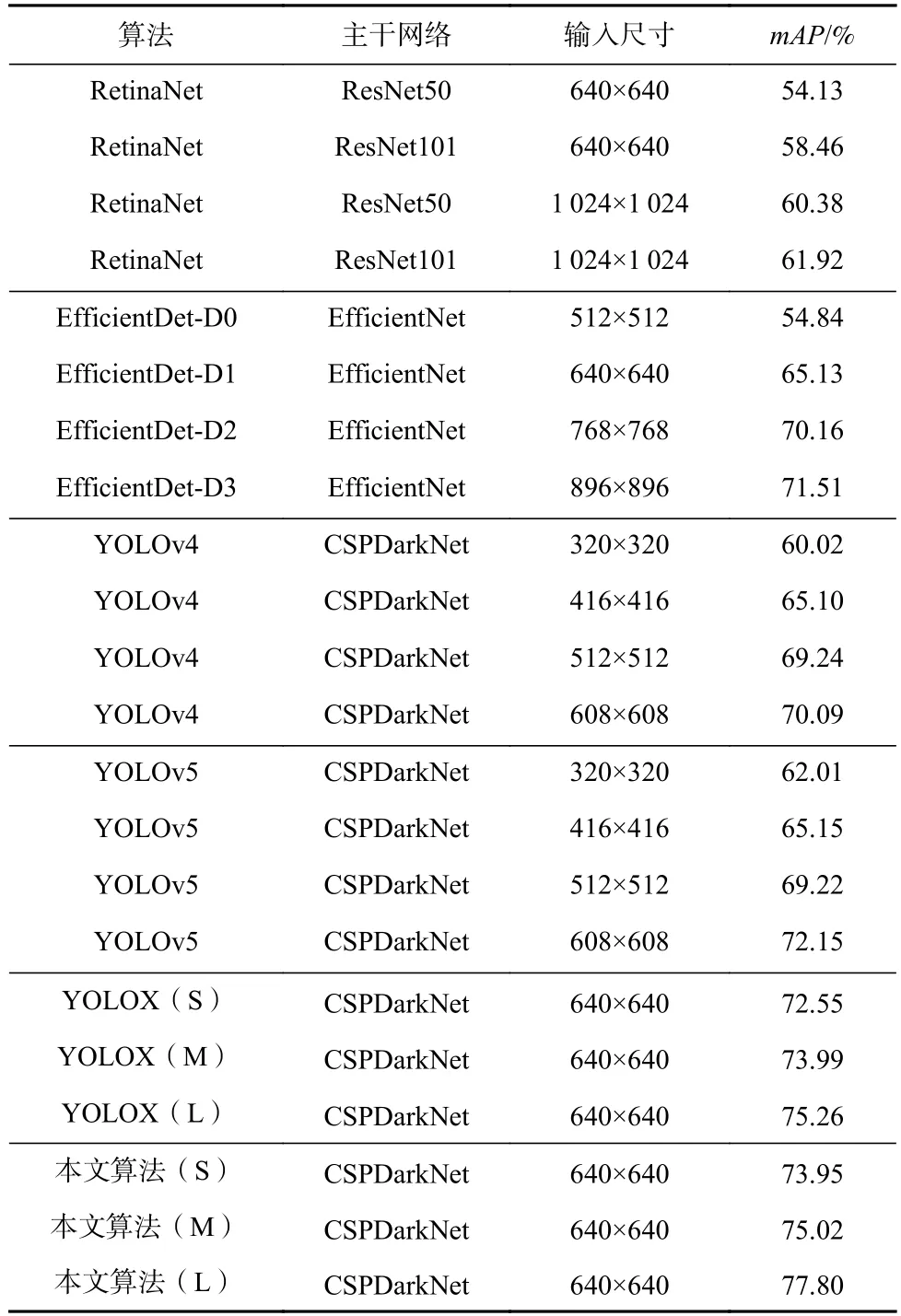
Table 1 Accuracy Comparison of Different Object Detection Algorithms on ExDark Dataset表1 在ExDark 數據集上不同物體檢測算法的精度比較
圖6 展示了本文提出的低照度目標檢測算法與其他主流目標檢測算法的比較,其中第1 行為標簽對應的真實框,最后一行為FEMR 的輸出結果,相比其他算法,可以直接由高階映射模塊得到的中間層輸出便于人眼觀察的增強圖像,從圖6 中可以看到本文提出的算法可以在低照度圖像對應的正常照度風格圖像上生成合理的目標邊界框,漏檢率和誤檢率相比前幾種算法都有了一定程度的下降. 在共同檢測到的物體上,本文提出的算法的識別準確率也會更高. 從第1 列對比圖中,可以看出SSD 算法會漏檢桌上大量杯子;EfficientDet 算法對桌上杯子的識別準確率較低;YOLOv4、YOLOv5 則會漏檢旁邊重疊的人,或是將桌上的餐具誤檢測成杯子,且識別準確率都相對較低. 從右邊的4 列對比結果來看,也存在大量類似的問題.

Fig.6 Comparison of detection results of mainstream object detection algorithms圖6 主流目標檢測算法檢測結果對比圖
本節還通過對比圖像增強算法+YOLO 系列的組合算法與本文提出的低照度目標檢測算法在檢測精度、訓練時間和檢測時間上進行對比,驗證本文所提算法在低照度目標檢測任務上的顯著提升效果.
在實驗中,本節在基礎檢測模型的基礎上,分別組合了EnlightenGAN[48]、KinD[13]、MBLLEN[14]、Zero-DCE[15]這些基于深度學習的低照度圖像增強算法[49],這些算法沿用原作者的設計方案,并按照作者提供的訓練方案,重新訓練對應圖像增強網絡的模型權重. 將ExDark 數據集中的測試集先進行圖像增強,再送入YOLOv5 和YOLOX 目標檢測器中,得出對應算法的mAP. 記錄所有圖像完成先增強后檢測時間的總時間,最后取平均值得到該算法單張圖像完成先增強后檢測的時間,其中每種算法所用圖像相同,檢測時間僅包含模型前向運算時間,不包含模型導入和畫框等時間,訓練時間為模型訓練所消耗的總時間.
通過表2 可以看出,本文提出的端到端低照度目標檢測算法在檢測精度、檢測時間和訓練時間等方面都具有顯著優勢,而由低照度圖像增強算法增強過后的圖像再送入目標檢測器中,這種方式相比于直接送入對應目標檢測器,檢測精度還可能出現大幅下降的現象,說明經過增強的圖像雖然在一定程度上在人眼視覺方面可以取得一定提升效果,但是對于計算機而言,損失掉了一部分有助于目標檢測的重要特征信息. 同時生成圖像的過程也占據了大量運算時間,不利于快速得到檢測結果.
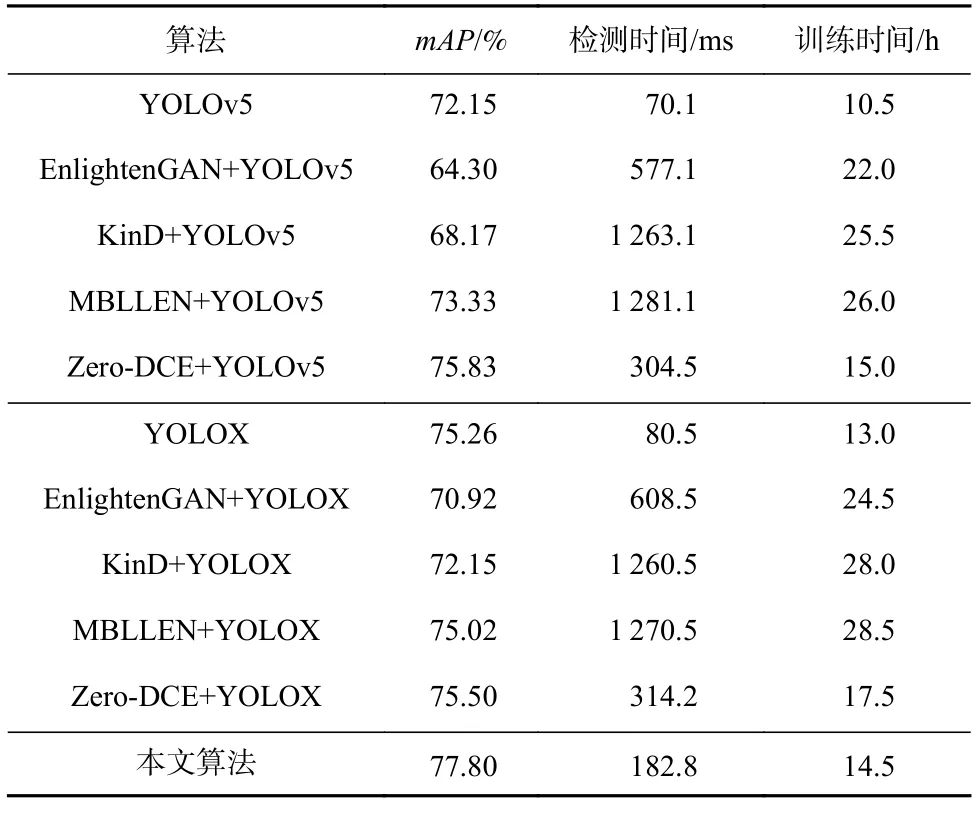
Table 2 Comparison of the Proposed Algorithm and Algorithms Enhanced Before Detection表2 本文算法與先增強后檢測算法的比較
3.3 超參數設置實驗與分析
本節對像素級高階映射模塊中的超參數N和E進行相關實驗與理論分析,其中改變N的大小的同時需要改變上一層的特征圖通道數,并與之匹配.
在實驗中發現,通過8 輪及以上的增強過程,像素級高階映射模塊可以實現更大的曲率,應對不同的情況. 由圖7 可以看出,增強次數過少會導致在訓練階段曝光損失、光照平滑損失和色彩一致性損失難以實現同步下降. 同時,表3 展現了當增大N值時,本文所提模型的檢測精度呈現上升趨勢,且N值增加會帶來大量的運算,為了維持模型檢測精度和檢測速度的平衡,本文將設置N=8.
為了實現圖像局部曝光強度處于正常狀態,即不接近0(欠曝光)或1(過曝光). 本節分別將E值設置為0.2、0.3、0.4、0.5、0.6、0.7、0.8,由表4 可以看到,當E=0.6 時,模型檢測性能較高,因此本文將設置E=0.6.
3.4 消融實驗

Fig.7 Loss curves of training processes圖7 訓練過程損失曲線圖
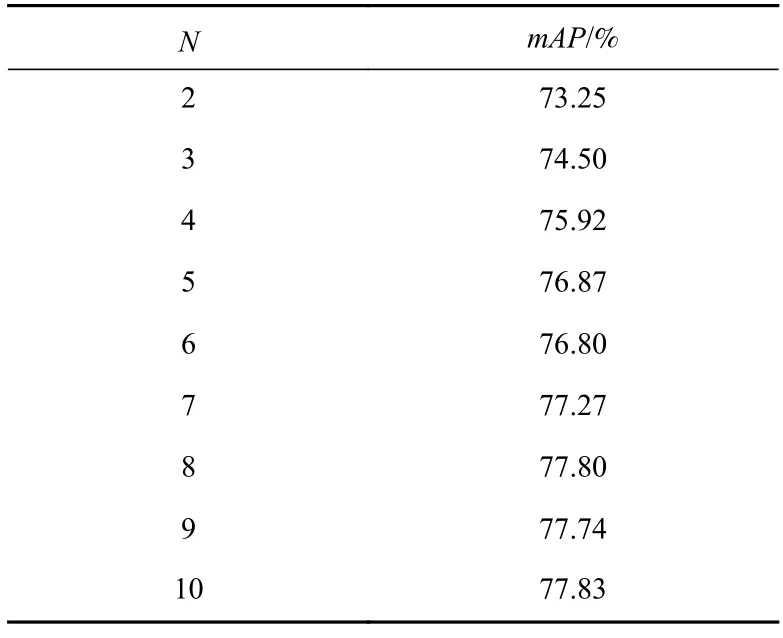
Table 3 Relationship Between Hyperparameter N and mAP表3 超參數N 與mAP 的關系

Table 4 Relationship Between Hyperparameter E and mAP表4 超參數E 與mAP 的關系
為了進一步探討本文提出的算法的有效性,本節對像素級高階映射(PHM)模塊、關鍵信息增強(KIE)模塊、長距離特征捕獲(LFC)模塊進行了消融實驗,并對各個模塊對實驗結果的影響進行了分析,通過刪減1 個或2 個模塊,組合得到FEMR_del_KIE_LFC、FEMR_del_PHM_LFC、FEMR_del_PHM_KIE、FEMR_del_LFC、FEMR_del_KIE、FEMR_del_PHM 這6 種算法,還將各個模塊嵌入到其他目標檢測模型中,探討其通用性. 在本節的實驗中,只考慮算法模型對ExDark 數據集的性能影響,如表5 所示,其中以YOLOv5 算法作為基線模型,為了便于比較精度變化,各類別的mAP進行取整處理.
3.4.1 像素級高階映射模塊
本節增加像素級高階映射模塊后的檢測模型,與基線模型相比,mAP提高了2.5%,有效提升了低照度圖像的目標檢測精度. 本節分析得出經過增強后的圖像,其特征與正常光照的圖像特征的差異較小,能夠使網絡在原始圖像灰度梯度較小處能夠得到更多的圖像特征,以便于完成目標檢測任務.
對該模塊包含的3 個損失函數進行消融實驗,通過刪減1 項或2 項損失函數,組合得到FEMR_del_smooth_color、FEMR_del_exposure_color、FEMR_del_exposure_smooth、FEMR_del_color、FEMR_del_smooth、FEMR_del_exposure 這6 種算法. 由表6 可以看出,該模塊的3 個損失函數的組合使用均對模型檢測精度有不同程度的提升效果,側面印證了提升圖像質量對增強目標檢測能力的幫助.
3.4.2 關鍵信息增強模塊
本節增加關鍵信息增強模塊后的檢測模型與基線模型相比,mAP提高了1.68%,其中使用2 個注意力模塊,分別對2 種特征尺寸的特征圖進行關鍵信息的增強. 本文算法可以從2 個角度出發對特征圖中目標的關鍵位置信息和語義信息,完成高效的激活,使網絡更多地關注這類重要信息,消除噪聲的干擾.
3.4.3 長距離特征捕獲模塊
本節增加長距離特征捕獲模塊后的建模與基線模型相比,mAP提高了2.12%,其中人和單車類別的mAP分別提升了5%和8%,提升最為明顯,說明長距離特征捕獲模塊對這類比例較為特殊的目標的檢測能力具有明顯的加強,同時低照度數據集中這類目標占據的比重也較大,因此對整體檢測精度有了較好的提升效果.
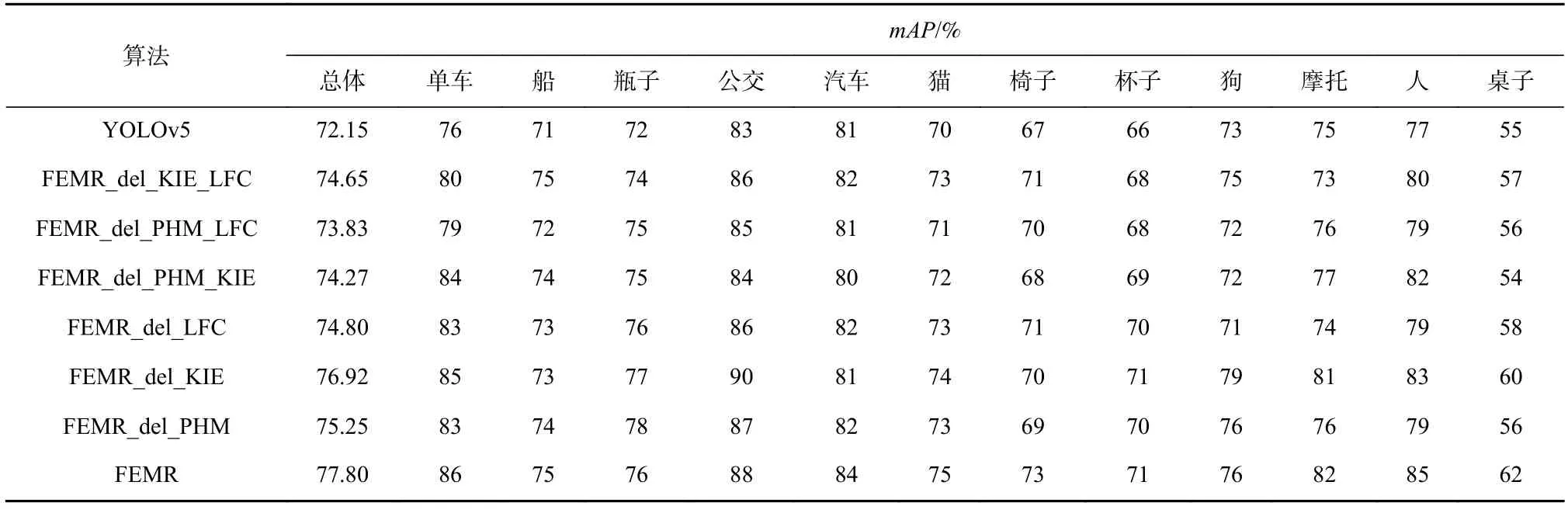
Table 5 Ablation Experiment of Each Algorithm on ExDark Dataset表5 在ExDark 數據集上各算法的消融實驗

Table 6 Ablation Experiment of Loss Function表6 損失函數的消融實驗
3.4.4 各模塊通用性測試
表7 展示了向3 種其他目標檢測模型中添加1 個、2 個或3 個模塊時共得到21 種算法的檢測結果.
從比較結果來看,本文提出的3 個模塊均有一定的通用性,對大部分目標檢測模型有精度上的提升.
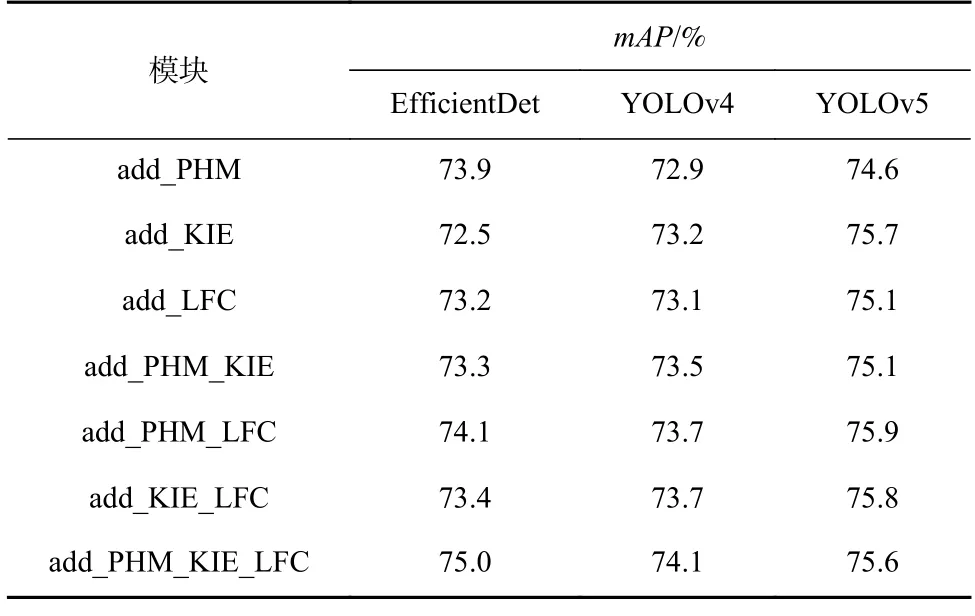
Table 7 Universality Test of Each Module表7 各模塊通用性測試
4 結 論
本文針對低照度目標檢測問題提出了結合特征增強和多尺度感受野的低照度目標檢測算法.為了充分利用低照度圖像中的不顯著特征,設計了像素級的高階映射模塊和關鍵信息增強模塊,分2 步去增強低照度圖像特征,還設計了長距離特征捕獲模塊加強網絡模型對長距離依賴關系的捕獲能力,以此來共同提高模型的檢測能力. 與其他經典目標檢測算法在ExDark 數據集上的檢測結果相比,本文提出的算法具有更高的檢測精度. 然而本算法在檢測速度、GPU 資源消耗方面有待提高,因此在后續的工作中也將針對網絡的輕量化展開進一步研究.
作者貢獻聲明:江澤濤提出了文章整體思路并負責撰寫與修改論文;翟豐碩負責完成算法設計與實驗,并撰寫與修改論文;錢藝修改論文;肖蕓負責圖表繪制;張少欽參與了論文的審閱與修改.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
