大數據背景下事業單位人力資源管理的創新策略研究
2023-04-04 02:40:20云南省騰沖市退役軍人事務局軍隊離退休干部管理所
現代經濟信息 2023年9期
李 軒 云南省騰沖市退役軍人事務局—軍隊離退休干部管理所
隨著事業單位人員結構復雜化、數據信息的海量化,傳統以人工統計為主的人力資源管理模式,已難以適應新時代多種生產服務要素、人員信息的管理需求。這一背景下,從數據驅動理念、360度考核法角度出發,探討用于事業單位人力資源招聘、培訓、薪酬、績效管理的系統建設方案,由人力資源管理系統、相應Kmeans算法,進行數據資源的挖掘、處理與分析,完成事業單位中不同類別人力資源的數據挖掘、分析與管理。
一、大數據時代創新事業單位人力資源管理模式的重要意義
(一)優化與改進傳統的人力資源管理模式
大數據檔案資源管理模式,應用于事業單位人力資源的管理工作過程中,既能夠迅速普及信息化的人力資源管理技術,也能夠最大程度地改進傳統以人工統計為主的人力資源管理模式。[1]特別以黨政領導為主的事業單位管理方案,對不同部門人力資源檔案、業務及工作信息、薪酬信息、績效信息的管理,需通過上下級之間的層層匯報,或者由本部財會人員對多種人力資源信息,作出分類統計后,匯總并上傳至上級完成管理。
而大數據挖掘技術、云服務管理平臺的應用,有效緩解與減少了基層財會人員的工作任務,不同管理人員只需將人力資源檔案、其它信息資源,輸入至人力資源管理系統,系統后臺即可進行自動化的數據整理、篩選、分類與存儲操作,可降低人力資源管理的數據缺漏或遺失問題。
(二)落實對人力資源信息的科學量化管理
隨著近年來網絡化招聘、績效考核與薪酬管理模式的興起,如何從海量化人力資源信息中,篩選出有價值的簡歷、做好薪酬與績效考核管理,成為事業單位日常工作關注的重要問題。運用大數據技術、云服務管理平臺,可先保存事業單位的海量化人力資源信息,再從中挖掘出有價值的人力資源信息,[2]一是能夠為人力資源工作績效、薪酬分配衡量標準的制定,提供科學化、可量化的參考數據信息;二是可作為事業單位人員招聘時簡歷篩選以及基層人員績效考核、薪酬發放管理的依據,帶動事業單位人力資源管理的提質增效發展。
二、事業單位人力資源管理系統的模型架構設計
(一)人力資源管理系統的整體架構設計
基于Eclipse編譯平臺、Java web可拓展開發工具,建構起用于人力資源管理的Javaswing網站圖形界面以及JSP服務器頁面。隨后基于Java web客戶端的JSP服務技術、Servlet技術,搭建起前臺界面、后臺頁面間的鏈接橋梁。[3]通過MVC設計模式,從客戶端發起通信請求httpRequest、從服務器返回客戶端響應httpResponse,并將響應的數據處理結果在前臺顯示,具體的事業單位人力資源管理系統架構,如圖1所示。
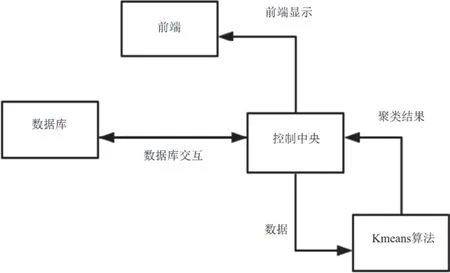
圖1 事業單位人力資源管理系統架構
為更好地完成不同類別的人力資源數據處理、保存,采用MySQL數據庫的功能模塊、I/O接口,對人力資源數據進行挖掘、增刪與修改操作。其中中央控制器接收到Web客戶端請求后,可處理用戶訪問、數據分析請求的動作(action),對前端的人力資源管理事件,作出合理的數據分配和處理,包括用戶登錄、數據資源訪問、數據庫接口訪問的請求處理,按照不同的請求訪問事件,分配數據任務或事件到后臺處理,將處理完成的前端反饋、后端響應數據存儲至數據庫,將每個人力資源數據信息,完整的顯示給用戶調用與查看。
(二)數據庫表管理流程設計
通過依托于前端客戶端、中央控制器、數據庫等的基本功能模塊,設置后臺數據庫內的數據表,作為事業單位內不同人力資源信息管理的數據庫表。本系統對后臺數據庫內的人力資源信息管理表設置,通常包括應聘人員表、基本檔案信息表、業務及工作表、績效考核表、薪資發放表等多張表格,不同表格分別記錄不同的人力資源信息。然后將多種數據庫表的信息,通過事業單位人員的工號進行鏈接,關聯起不同的數據庫表信息,以便于管理人員的使用操作。具體的數據庫表管理流程,如圖2所示。
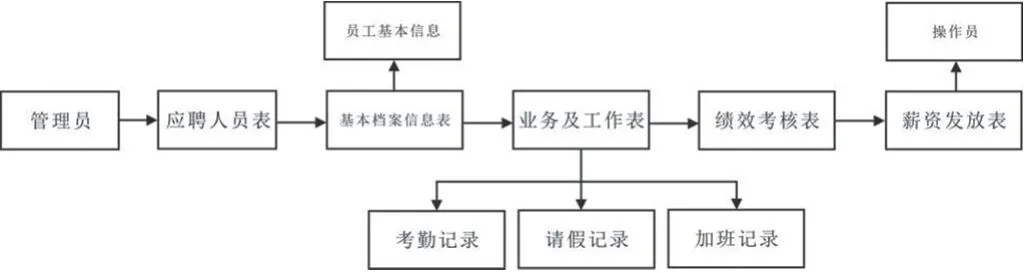
圖2 人力資源數據庫表管理流程
(三)Kmeans聚類算法設計
利用K-means聚類算法,進行事業單位人力資源信息的數據挖掘與分析。K-means聚類算法作為無監督的均值聚類算法,通常以K個樣本數據為初始聚類中心,將每個樣本對象分配至距離其最近的聚類中心,直至所有數據都分配到相應的聚類中心,或聚類對象都達到局部誤差平方和最優時,結束該算法。[4]因而使用K均值聚類算法,進行不同類別數據要素的分析,需考慮聚類對象、對象初始位置、聚類中心個數、模型樣本性質等因素,特別需謹慎選擇聚類中心的初始值,圍繞K個起始樣本進行聚類運算,以避免K均值聚類算法陷入局部最優解。
本文將K-means聚類算法,應用到事業單位人力資源信息的管理中,首先要將Kmeans算法作出線性匯編,封裝為第三方的jar包。之后由系統通過I/O接口進行jar包的調用,客戶端頁面會調用編寫完成的Kmeans算法,對后臺的數據庫信息進行聚類分析,包括以上多種人力資源管理信息的分析,將管理員調用的人力資源信息、聚類效果,在前端窗口上加載與顯示。
三、事業單位不同人力資源管理的數據庫表設置
(一)應聘人員表設置
事業單位人力資源招聘的數據信息管理,通常由事業單位管理部門發放招聘表,應聘人員填寫表格中的相關內容,作為人力資源管理的應聘表。[5]其中應聘表記錄了人力資源的姓名、性別、年齡、畢業院校、所學專業、應聘職位、工作經驗、健康狀況、聯系方式、電子郵件等信息,多種應聘數據信息被設置為字段,存儲于后臺數據庫中,具體如下表1所示。當人員應聘結束或入職后,相關的應聘信息會被刪除。
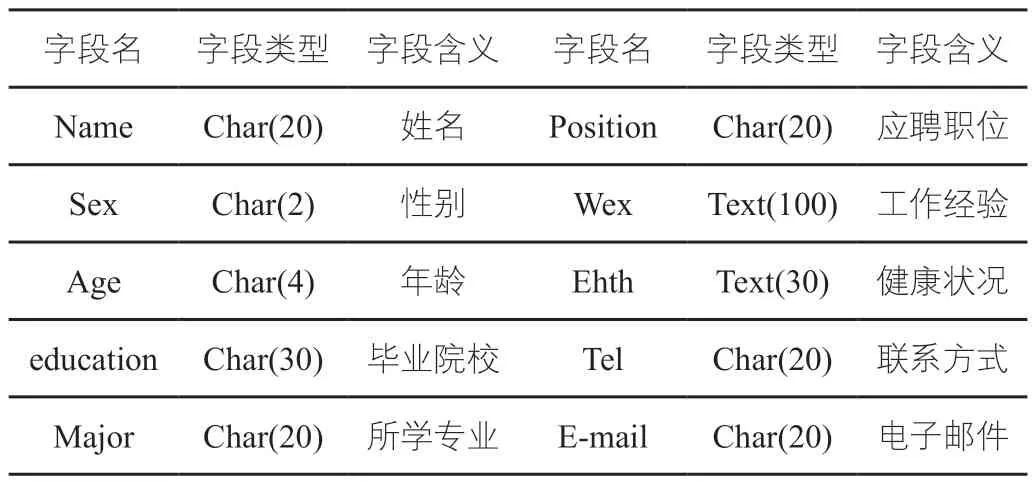
表1 應聘人員表設置
(二)基本檔案信息表設置
事業單位內部職工基本檔案信息的管理,也是以數據庫表的形式,記錄相關的人員工號、姓名、性別、照片、職位、編制類別、入職日期、專業能力、管理能力等信息。其中前面字段為基本的人員信息,后面字段為人力資源技術與能力的評估信息,可通過利用Kmeans算法模型,進行人力資源信息挖掘、標準化數據分類后得到,如表2所示。
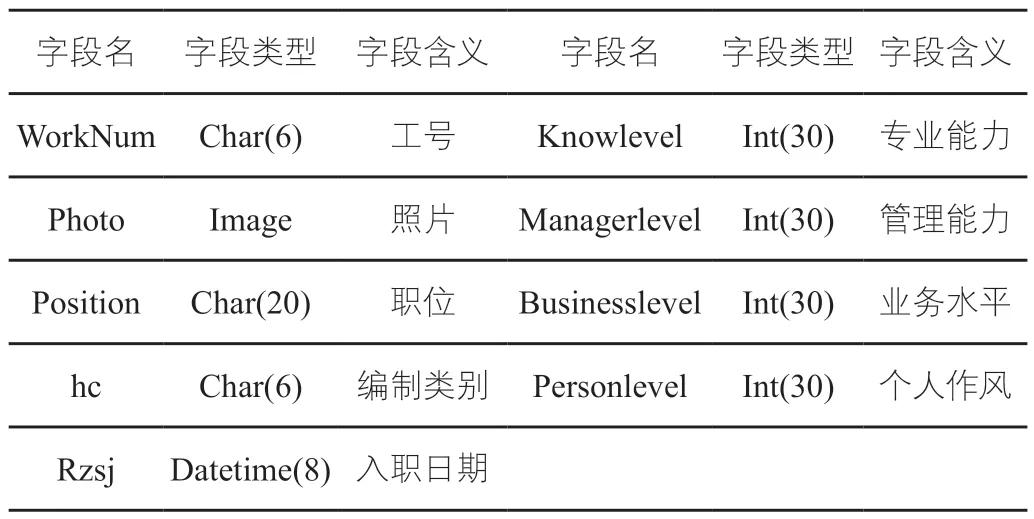
表2 基本檔案信息表設置
(三)業務及績效表設置
在事業單位日常的人力資源管理中,為更好地對不同崗位的人力資源進行管理,需圍繞人員工號、姓名、職位、照片、考勤記錄、請假記錄、加班記錄、專業能力、業務水平、個人作風等信息,梳理內部人員職級、崗位和上下級關系以及對某一時間段內,不同部門人力資源的專業能力、業務完成水平、個人作風等作出評估。其中不同字段用于記錄績效的執行基本信息,也可作為事業單位人員工作完成度、專業能力評估的參考依據,具體如下表3所示。
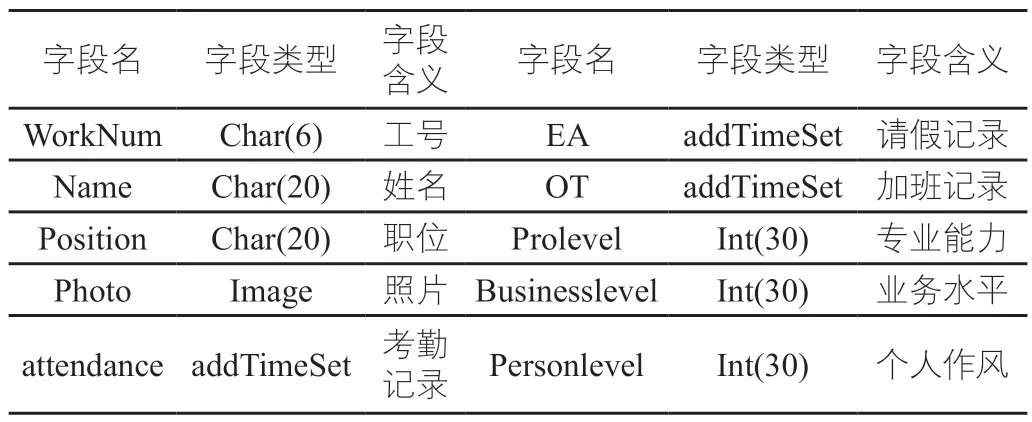
表3 業務及績效表設置
(四)薪資發放表設置
事業單位人力資源薪資的統計與發放表設置,是在現有人力資源業務及績效表格的基礎上,用于記錄分析每個員工的基本薪資、績效薪資、職務工資、考勤扣除、補貼薪資、獎勵薪資、薪資發放日期、部門意見等。使用不同的字段長度記錄相關薪資信息,得到最終的薪資發放表,如表4所示。通過工號鏈接形成表內信息的關聯訪問,幫助管理人員更為便捷地完成事業單位人力資源的信息管理。
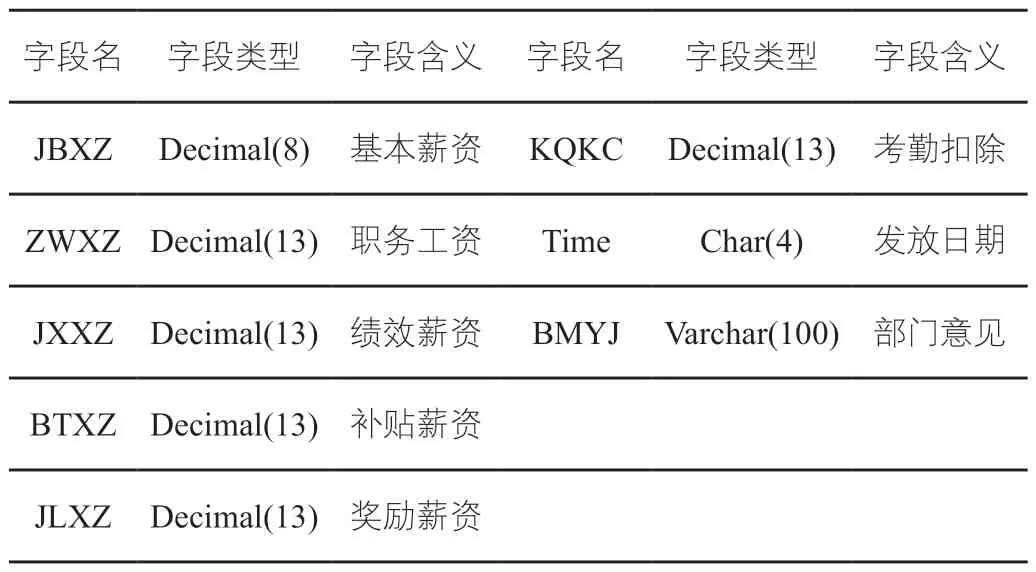
表4 薪資發放表設置
四、事業單位人力資源管理系統的測試與實現
(一)用戶身份登錄與校驗
由外部用戶訪問人力資源管理系統,通過輸入用戶名、密碼并點擊登錄按鈕,進行用戶身份校驗,具體如下圖3所示。[6]登錄至系統主界面后,通過點擊左側菜單欄的功能模塊,進行系統的不同功能調用、接口使用,點擊后跳轉到不同的頁面鏈接,查看需要的人力資源數據信息。
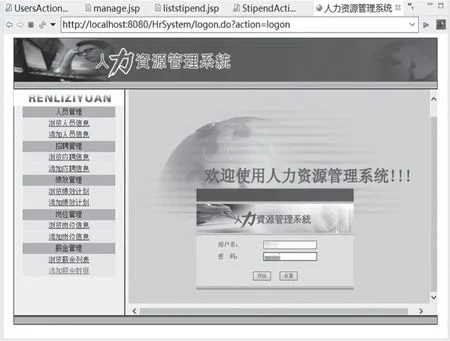
圖3 用戶身份登錄與校驗
通過點擊不同界面,可更好地展示與管理事業單位的所有人力資源個人檔案信息、崗位及工作信息、績效與薪酬信息,使其較為直觀、詳細地了解不同人力資源的管理狀況。通過點擊不同人員的崗位及工作柱狀圖,系統會自動導入后臺數據庫的數據信息,并采用Kmeans算法進行數據挖掘、分析,將最終的數據處理結果加載至繪制的圖表界面。
(二)系統測試與實現
基于主動數據庫的事業單位人力資源管理系統,涉及到職工個人檔案、考勤記錄、請假記錄、加班記錄、薪資福利等功能模塊。以該系統的個人檔案管理界面為例,其實現的關鍵代碼,如圖4所示。

圖4 事業單位人力資源的個人檔案管理代碼
管理員登錄至系統后臺后,可針對不同用戶角色,進行相應功能模塊信息的查詢、新增、修改、刪除等操作,通過觸發器可基本實現數據庫的自動化操作,以保證整個系統的安全穩定運行。
五、結語
大數據環境下事業單位的人力資源管理,要引入大數據及云計算技術、云服務管理平臺,構建起基于數據驅動的人力資源管理系統,設置多個不同功能的管理模塊,在人力資源招聘、檔案信息整合、專業技能培訓、薪酬及績效管理等方面發揮作用。因而通過借助于大數據挖掘技術、云服務管理平臺,可對事業單位內的多源數據信息,進行自動化搜集、挖掘、處理與存儲,整合人力資源的檔案信息、業務及服務信息,將其存儲至MySQL主動數據庫之中,方便管理人員的資源調用與共享。
猜你喜歡
現代經濟信息(2020年34期)2020-06-08 06:02:40
當代陜西(2019年10期)2019-06-03 10:12:40
消費導刊(2018年8期)2018-05-25 13:20:26
消費導刊(2018年8期)2018-05-25 13:20:08
中華手工(2017年2期)2017-06-06 23:00:31
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中外會展(2014年4期)2014-11-27 07:46:46
