一種基于注意力機制的文物圖像顯著性檢測方法
2023-03-15 03:50:46雷雨晴
大連民族大學學報 2023年1期
雷雨晴,楊 楠,冉 勇,閆 宇
(1.大連民族大學 a.計算機科學與工程學院;b.大連市漢字計算機字庫設計技術創新中心, 遼寧 大連 116650;2.德江儺堂戲博物館,貴州 銅仁 565200)
視覺顯著性檢測是通過模擬人類視覺來提取圖像顯著區域的算法,在圖像重定位、圖像自動裁剪、圖像壓縮和目標識別領域具有重要的應用。1998年Itti等從視覺心理學對人類自下而上的視覺選擇性注意過程進行研究并提出了顯著性檢測模型[1]。顯著性目標檢測方法可分為傳統顯著性檢測方法和基于深度學習的顯著性檢測方法。傳統顯著性檢測方法研究中,Liu等提出將顯著性檢測定義為二元分割問題[2], Zhang L等利用背景和前景區分,進而構建圖層排序的顯著性檢測方法[3], Hou X等通過觀察圖片背景的特征分布和屬性,通過剔除圖像背景信息得到顯著區域[4]。深度學習的顯著性方法研究中又分為傳統的卷積神經網絡方法和完全卷積神經網絡方法。傳統的卷積神經網絡方法中,Wang L等提出了一種結合局部估計和全局搜索的顯著性檢測算法[5],Li G等將嵌套窗口中提取的多尺度CNN特征與具有多個完全連接層的深度神經網絡結合將圖像分為三個區域再對他們進行特征提取而后進行整和[6]。完全卷積神經網絡中,Wu R等提出以VGG16作為基礎網絡附加互學習模塊、邊緣模塊和解碼模塊的模型[7],Wang W等通過完整的迭代前饋和反饋策略擴展深度顯著性目標檢測(Salient Object Detection,SOD)模型,使其足夠通用和靈活,涵蓋大多數其他基于全卷積網絡(Fully Convolutional Network,FCN)的顯著性模型[8], Liu J J等人基于U形結構的模型[9]。
顯著性檢測在文物圖像縮略圖生成時具有重要作用。在文物系統展示中需要對大量的文物圖像進行剪切顯著性區域,這些需要大量人工進行。本文通過分析文物圖像的背景屬性和規律,提出了一種基于注意力機制的文物圖像顯著性檢測方法。
自2014年以來,深度學習在顯著性檢測方向以其優異的性能,證明了其在顯著性檢測方向的可行性。然而,深層網絡在面對如書畫類文物圖像這樣圖像特征多樣化的情況下,現有的深度學習方法很難區分對象邊界和周圍相似區域域的像素,因此深層網絡可能會輸出高度模糊且邊界不準確的顯著圖。2017年pinghu等提出了一個深層次的“層次集”(Deep Level Sets)網絡來生成緊湊而統一的顯著性圖,即DLS[10]。DLS模型主要包括基于CNN的VGG16網絡、超像素過濾(GSF)層和重量函數(HF)三個部分。首先原始圖像通過基于CNN的VGG16網絡,并輸出全分辨率的粗略顯著圖像,于此同時對原始圖像使用gSLICr進行超像素分割,統一輸入到超像素過濾層,最后使用重量函數將GSF層的輸出轉換為最終顯著圖。但作用于文物圖像時會存在不足。
(1)當文物圖像較為復雜,前景背景差異較小的情況下,基于CNN的VGG16網絡處理得到的粗略顯著圖會過于模糊,即使經過與超像素結果優化,得到的效果依舊不好。
(2)文物圖像中會存在如圖1a這類圖像,圖像邊緣會有邊框將其部分突出,但對于網絡模型來說只能得出如圖1b的結果。
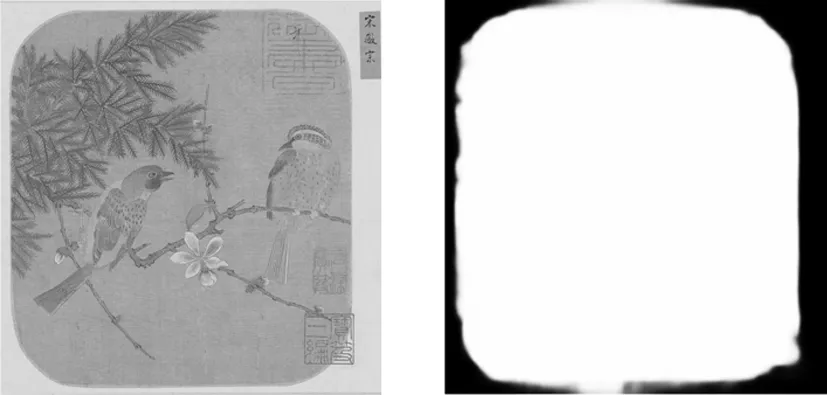
a)邊緣突出類圖像 b)預測結果 圖1 邊緣突出類圖像及其預測結果
2 本文方法
2.1 DLS模型
針對上文提到的問題,在DLS的基礎上對其進行修改。
(1)基于CNN的VGG16網絡部分。首先使用膨脹的卷積層替換了最后三個Max-pooling層,并最后一個完全連接的層更改為卷積層和Sigmoid層,以便網絡獲取RGB圖像224×224。作為輸入并產生56×56。最后,添加沒有學習參數的上采樣層,以將圖像縮放到全分辨率。
由于后續算法中使用了水平集的方法,因此將卷積神經網絡輸出的顯著性值線性的轉移至[-0.5,0.5]并將其視為水平集。
(2)超像素過濾(GSF)層部分。在CNN網絡運算的過程中,利用gSLICr將圖像分割為400×500個超像素,而后將其與CNN網絡產生后轉換為的水平集一同輸入GSF超像素過濾層。
(3)重量函數(HF)部分。由于如果使用簡單的Heaviside函數作用于零水平集,會陷入局部最小值。為解決這種問題,采用了文獻中提出的近似重載函數(AHF),該函數作用于所有的水平曲線并趨向于尋找一個全局最小化器,最終即可得到最終顯著圖。
其次設定閾值,在最終圖像輸出后對其進行判斷,如大于閾值則在處理后重新輸入網絡。修改后網絡模型如圖2。
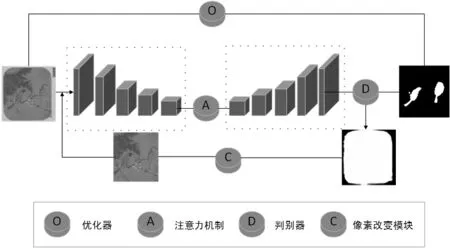
圖2 基于注意力機制的DLS模型
其中網絡部分是對稱的編解碼器架構,編碼器組件基于ResNet-50來提取多級特征,編碼器結構與解碼器結構一一對應。A模型為注意力機制模塊[11],D模塊為自制的判別模塊,C模塊為圖像像素改變模塊。
2.2 注意力機制模塊
注意力機制是通過算法模擬生物觀察這一行為,將內部經驗和外部感覺融合,增加部分區域觀察仔細度的一個機制。而自注意力機制是在注意力機制的基礎上做出改進,可有效的減少對外部信息的依賴,與注意力機制相比,自注意力機制更擅長捕捉特征或數據的內部相關性。
在未引入自注意力機制之前,大多數用于圖像處理的模型都是用卷積操作堆疊起來的。但這存在一個明顯的問題,卷積運算僅僅關注整個圖像的局部區域,因此通過使用卷積層來建模圖像中的依存關系是無效的或效果不明顯的。而這導致了一個后果,對于多類別的數據集,哪怕是最新的生成模型,都難以捕捉某些類別中經常出現的幾何或結構模式。為了解決這些問題,通常在網絡中引入自注意力機制來緩解這一難題。
在卷積神經網絡中,每張圖片初始會由RGB三通道表示出來,之后經過不同的卷積核之后,每一個通道又會生成新的信號,比如圖片特征的每個通道使用64核卷積,就會產生64個新通道的矩陣(H,W, 64),其中H,W分別表示圖片特征的高度和寬度每個通道的特征其實就表示該圖片在不同卷積核上的分量,類似于時頻變換,而這里面用卷積核的卷積類似于信號做了傅里葉變換,從而能夠將這個特征一個通道的信息給分解成64個卷積核上的信號分量。
既然每個信號都可以被分解成核函數上的分量,產生的新的64個通道對于關鍵信息的貢獻肯定有多有少,如果我們給每個通道上的信號都增加一個權重,來代表該通道與關鍵信息的相關度的話,這個權重越大,則表示相關度越高,也就是我們越需要去注意的通道了。
模塊的具體結構如圖3。原始圖像通過編譯器,產生了新的特征信號U。U有C個通道,我們希望通過注意力模塊來學習出每個通道的權重,從而產生通道域的注意力。該注意力機制主要分成三個部分:擠壓(squeeze),激勵(excitation),以及注意(attention)。
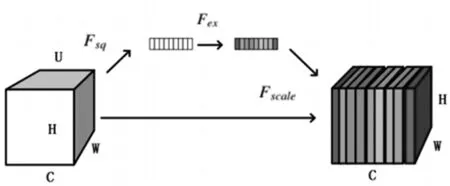
圖3 模塊具體結構圖
2.3 判別模塊
當文物圖片有邊框突出的情況,進行顯著性檢測會將其突出部分視作顯著區域,因此對于網絡輸出的顯著圖S,置顯著圖S中顯著點個數為nums,總像素個數numall,這樣網絡輸出顯著圖的顯著率rr為
(1)
根據數據集標注人員對數據集圖像的判斷,最終決定設置閾值T="80%" ,如果顯著率rr大于閾值T,則會將顯著圖S輸入圖像像素改變模塊。
2.4 圖像像素改變模塊
該模塊主要接收判別模塊傳入的顯著率過大的顯著圖,在接收后會按照圖像寬高比例,去除圖像邊緣區域,直到得到的矩陣均為如圖1b圖中白色的區域。而后記錄裁切位置,將裁切后的圖像重新輸入至模型,直至生成的顯著圖的顯著率小于閾值,按照裁切的位置重新生成新的顯著圖像,過程與結果如圖4。

a)裁剪后圖像 b)最終結果圖4 邊緣突出類圖像及其預測結果
3 實驗結果與分析
采用人手工標注的方法制作逐像素標注圖像,對于陶瓷、雕塑和青銅器具等物品展示類的文物圖,顯著目標區域通常為一個很明顯的區域,對于這部分的文物圖的標注通常是沒有爭議的,可以由一個人完成。而對于復雜的書畫類文物圖像,顯著目標通常并不明顯,因此該類文物標注由三個人分別完成,標注后采取少數服從多數的原則,最終決定圖像的標注區域。這兩類的文物圖的標注結果如圖5。

a)物品展示類圖像 b)書畫類圖像圖5 物品展示類和書畫類圖像
3.1 評估方法
與其他顯著性檢測論文相同,本文主要使用定性分析和定量分析的以下三種數值比較方法,對所提到的文物顯著區域檢測算法進行評估:準確率(Precision)和召回率(Recall)構成的PR曲線、真正率(True Positive Rate)和假正率(False Positive Rate)構成的ROC曲線以及F值柱狀圖。
3.2 性能評估
本文從定性和定量兩方面對比傳統顯著性檢測算法與深度學習模型,包含的傳統方法有LC算法[12]和SBM算法[13],DLS模型[10]和SCRN模型[14]。
(1)定性分析。對上述對比模型和本模型分別在上述文物數據集上進行訓練,并選取各類型圖像,在多種模型檢測方法內得到的對比結果如圖6。
從圖6中前四幅圖的對比結果可以看出深度學習的算法要優于傳統算法,但是在最后一幅圖這樣有存在明顯邊框的圖像中基于深度學習的算法會將邊框突出部分認為顯著區域,而不會像傳統方法那樣依次計算每個像素點的顯著值。從以上對比可以看出,在手工標注的圖像顯著區域數據集中,相較于其他方法,本文提出的方法能夠更好的檢測出圖像顯著區域。
(2)定量分析。為上述方法在手工標注的文物圖像顯著性數據集的準確率和召回率構成的P-R曲線如圖7。P-R曲線就是精確率precision vs召回率recall曲線,以recall作為橫坐標軸,precision作為縱坐標軸。可以合理的評估檢測算法在輸入圖像上的運行效果,是計算機視覺領域中最常用的評估方法。準確率是指顯著性算法正確檢測出來的顯著性像素的總數與檢測到的像素總數的比率;召回率是指正確檢測出來的顯著性像素個數占標準集中顯著性像素總數的比率。
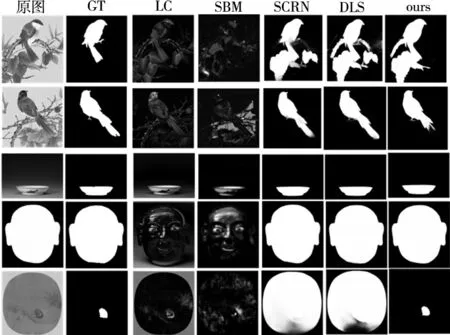
圖6 文物圖像數據對比結果
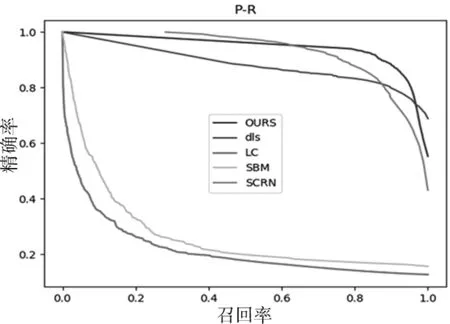
圖7 P-R曲線
真正值率和假正值率構成的ROC曲線如圖8。ROC曲線的全稱是ReceiverOperating Chara-cteristic Curve,中文名字叫“受試者工作特征曲線”,和PR曲線皆為類別不平衡問題中常用的評估方法,二者既有相同也有不同點。ROC曲線常用于二分類問題中的模型比較,主要表現為一種真正例率 (TPR) 和假正例率 (FPR) 的權衡。其中,真正類率(True Postive Rate)代表分類器預測的正類中實際正實例占所有正實例的比例,負正類率(False Postive Rate)代表分類器預測的正類中實際負實例占所有負實例的比例。
F值柱狀圖如圖9。對于一個性能優越的檢測算法來說,應該同時具備良好的準確率和召回率。但在實際情況中,通常是準確率的提高就意味著召回率的下降,反之亦然。綜合了P和R的結果,而當F較高時則能說明試驗方法比較有效,見表1。
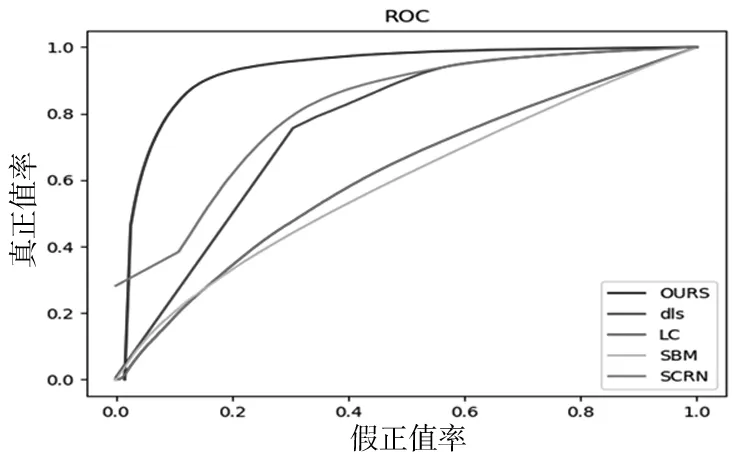
圖8 ROC曲線
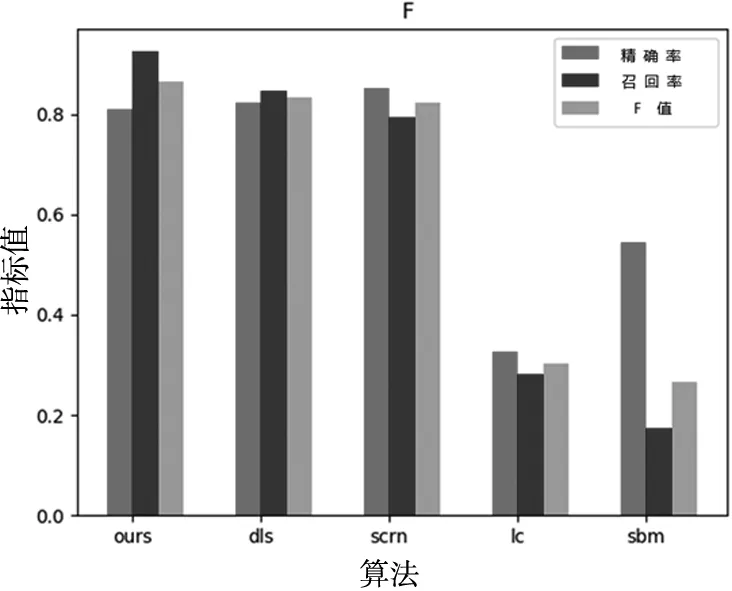
圖9 F值柱狀圖
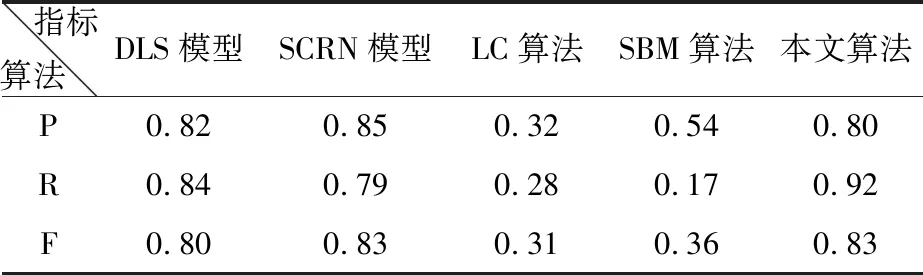
表1 對比結果
4 總 結
本文詳細的介紹了基于視覺顯著性的文物顯著區域提取方法。根據DLS顯著性檢測模型在文物數據集中存在的問題,對DLS模型部分功能進行修改,使其在上文中的文物數據集進行訓練并與現有比較經典的視覺顯著性檢測算法結果進行比較。實驗結果表明:本文提出的檢測方法對于圖像顯著性區域的檢測非常有效。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
