基于KG-GCNASL方法的人類癌癥合成致死預(yù)測研究
2023-03-15 03:50:44朱曉敏
大連民族大學(xué)學(xué)報(bào) 2023年1期
朱曉敏, 劉 爽
(大連民族大學(xué) 計(jì)算機(jī)科學(xué)與工程學(xué)院,遼寧 大連 116650)
1 問題提出
合成致死指對于細(xì)胞中的兩個基因,其中任何一個單獨(dú)突變或不發(fā)揮作用時,都不會導(dǎo)致細(xì)胞死亡,兩者同時突變或者不能表達(dá)時,會導(dǎo)致細(xì)胞死亡[1]。在合成致死基因?qū)χ校粋€基因突變不會影響細(xì)胞的生存能力,兩個基因同時突變則會導(dǎo)致細(xì)胞死亡;通過抑制致癌突變基因的合成致死伙伴基因,可殺死致癌基因發(fā)生突變的癌細(xì)胞,且不損害正常細(xì)胞。SL作為一種選擇性殺死癌細(xì)胞新的靶向策略,為癌癥治療帶來了新機(jī)遇;也為發(fā)現(xiàn)新的藥物靶標(biāo)和潛在的癌癥藥物聯(lián)合策略提供了可能性。
SL預(yù)測是鏈接預(yù)測在生物醫(yī)學(xué)領(lǐng)域一個很重要的應(yīng)用。隨著人們生活壓力越來越大和快餐式的生活方式越來越頻繁,癌癥已經(jīng)成為了危害人類健康的主要?dú)⑹种唬渲饕蚴羌?xì)胞生長不受控制導(dǎo)致過度增殖而引起的。傳統(tǒng)化學(xué)療法通過藥物靶向快速分裂細(xì)胞從而殺死癌細(xì)胞,當(dāng)患者使用這些藥物時,會快速損害正常細(xì)胞的分裂,對不能迅速分裂的正常細(xì)胞也有毒性,因此限制了抗癌藥物的有效性。
知識圖譜是由語義網(wǎng)絡(luò)發(fā)展而來的[2],當(dāng)知識圖譜被應(yīng)用到各個領(lǐng)域后發(fā)現(xiàn)存在一些問題需要被解決,如鏈接預(yù)測問題。鏈接預(yù)測是將知識圖譜中實(shí)體和關(guān)系的內(nèi)容映射到連續(xù)向量空間中,對實(shí)體或關(guān)系進(jìn)行預(yù)測,包涵(h,r,?),(?,r,t),(h,?,t)三種任務(wù)[3],癌癥合成致死預(yù)測是知識圖譜鏈接預(yù)測在生物醫(yī)療領(lǐng)域非常重要的研究。
1.1 現(xiàn)有癌癥合成致死預(yù)測方法與面臨的挑戰(zhàn)
合成致死是抗癌藥物研發(fā)的全新思路,目前用于癌癥合成致死預(yù)測的方法主要包括以下三種。第一種是基于代謝網(wǎng)絡(luò)模型進(jìn)行基因敲除模擬[4],如圖1。通過整合基因組、轉(zhuǎn)錄組、蛋白組和熱力學(xué)數(shù)據(jù)實(shí)現(xiàn)基于各種約束的模型構(gòu)建,在基因靶點(diǎn)識別、系統(tǒng)代謝工程研究等多方面取得進(jìn)一步發(fā)展和理論突破;但缺點(diǎn)是嚴(yán)重依賴于代謝網(wǎng)絡(luò)模型、領(lǐng)域知識和基因組數(shù)據(jù)等,不能充分利用已知合成致死對象有價值的信息。

圖1 基于代謝網(wǎng)絡(luò)的預(yù)測方法
第二種是基于知識數(shù)據(jù)挖掘即面向知識的方法[5]進(jìn)行SL預(yù)測,如圖2。主要是利用特定領(lǐng)域的知識進(jìn)行特征工程,通過相關(guān)方法從海量數(shù)據(jù)中抽取出潛在且有價值的知識規(guī)則,其缺點(diǎn)是SL預(yù)測的濕實(shí)驗(yàn)篩選存在著成本高、成批效應(yīng)和脫靶等問題,不能充分利用有價值的信息。

圖2 支持向量機(jī)模型的預(yù)測方法
第三種方法應(yīng)用機(jī)器學(xué)習(xí)的算法進(jìn)行癌癥合成致死預(yù)測,如圖3所示:其特征基于領(lǐng)域知識和啟發(fā)式函數(shù)設(shè)計(jì)的[6],如支持向量機(jī)等注入基因組和蛋白質(zhì)組數(shù)據(jù)來促進(jìn)癌癥合成致死預(yù)測;基于圖網(wǎng)絡(luò)的方法[7]對輸入特征等信息進(jìn)行編碼,但缺點(diǎn)在于需手工提取特征,會遺漏特征。
圖3 基于決策樹的預(yù)測方法
綜上可知,現(xiàn)有方法大多傾向于假設(shè)合成致死對象是相互獨(dú)立的,并未考慮到潛在的共享生物機(jī)制。一些方法雖結(jié)合基因組和蛋白質(zhì)組數(shù)據(jù)來幫助癌癥合成致死預(yù)測,但涉及手工特征工程,嚴(yán)重依賴醫(yī)藥學(xué)、腫瘤學(xué)等相關(guān)領(lǐng)域知識。
1.2 癌癥合成致死預(yù)測的研究意義
綜上,其現(xiàn)有方法的局限和意義啟發(fā)著應(yīng)該尋找一個新改進(jìn)方法或模型去更多地進(jìn)行癌癥合成致死預(yù)測等相關(guān)研究。本文將進(jìn)行如下工作:基于知識圖譜鏈接預(yù)測與圖神經(jīng)網(wǎng)絡(luò)及注意力機(jī)制Attention方法使得實(shí)體特征向量融合所有鄰域?qū)嶓w特征及相應(yīng)的關(guān)系特征,更好地捕捉給定多跳鄰域中的信息和關(guān)聯(lián)特征,從而達(dá)到更好的效果來解決相關(guān)問題。可知知識圖譜與圖卷積網(wǎng)絡(luò)及注意力機(jī)制等相結(jié)合的方法進(jìn)行人類癌癥致死預(yù)測研究對醫(yī)療領(lǐng)域與生物信息領(lǐng)域的研究具有重要意義,尤其是癌癥治療方面。
2 相關(guān)方法與模型介紹
2.1 癌癥合成致死預(yù)測相關(guān)方法介紹
2.1.1 基于知識圖譜圖卷積神經(jīng)網(wǎng)絡(luò)模型介紹
KG-GCNASL方法將知識圖譜與圖卷積網(wǎng)絡(luò)結(jié)合引入癌癥合成致死關(guān)系預(yù)測中,基于圖卷積神經(jīng)網(wǎng)絡(luò)模型通過結(jié)合知識和數(shù)據(jù)更好地解決生物醫(yī)藥領(lǐng)域的復(fù)雜問題[8],圖卷積網(wǎng)絡(luò)模型如圖4。新預(yù)測的合成致死基因可幫助生物學(xué)家更快篩選到新抗癌藥物靶點(diǎn)[9],實(shí)現(xiàn)AI技術(shù)加速新藥研發(fā)進(jìn)程。通過知識圖譜來揭示SL背后的生物學(xué)機(jī)理,使深度學(xué)習(xí)模型具有更好的可解釋性,加速癌癥藥物靶點(diǎn)發(fā)現(xiàn),促進(jìn)AI制藥技術(shù)發(fā)展。

圖4 圖卷積網(wǎng)絡(luò)模型
2.1.2 注意力機(jī)制模型介紹
通過引入注意力機(jī)制模型來跟蹤不同基因間發(fā)生癌癥合成致死的可能性,從而實(shí)現(xiàn)可解釋性;除此還解決了語義向量無法關(guān)注到表示序列的重要信息問題[10]。當(dāng)獲取詞向量被逐個送入圖卷積網(wǎng)絡(luò)模型后會產(chǎn)生一系列的編碼端隱藏狀態(tài)參與到注意力系數(shù)的計(jì)算。每輪訓(xùn)練中,解碼端輸出狀態(tài)也將參與注意力系數(shù)的計(jì)算,然后使用注意力權(quán)重將原子集成到分子表示中。解碼器狀態(tài)與隱藏狀態(tài)經(jīng)過加權(quán)求和后得到最終的概率分布。此方法可以在任何給定實(shí)體的鄰域中同時捕獲實(shí)體和關(guān)系特征;還在模型中封裝關(guān)系聚類和多跳關(guān)系,從而捕捉給定藥物多跳鄰域中的信息和關(guān)聯(lián)特征,為基于注意力模型的有效性提供見解,其注意力機(jī)制模型如圖5。

圖5 注意力機(jī)制模型圖
2.2 癌癥合成致死預(yù)測模型介紹
本文提出KG-GCNASL合成致死預(yù)測方法,將預(yù)測問題定義為圖上鏈接預(yù)測問題,擴(kuò)展到圖結(jié)構(gòu)上神經(jīng)網(wǎng)絡(luò)方法進(jìn)行非線性節(jié)點(diǎn)嵌入學(xué)習(xí),并重構(gòu)新鄰接矩陣或重構(gòu)新圖上鏈接,以得到基因間合成致死關(guān)系,整體模型框架如圖6。
模型將知識圖譜合并到圖卷積神經(jīng)網(wǎng)絡(luò)中,通過直接在圖中引入潛在因素作為節(jié)點(diǎn)緩解獨(dú)立性問題;知識圖譜中注入各種可能與合成致死相關(guān)的生物過程、疾病等因素來解決獨(dú)立性問題。KG-GCNASL主要由三部分組成:首先從每個基因的原始知識圖譜中推導(dǎo)出一個基因特異性子圖;其次在基因特異性子圖上進(jìn)行MP,自動將基因與可能識別合成致死對象過程中起決定性作用的因素關(guān)聯(lián)起來,加入注意力機(jī)制以捕獲給定實(shí)體多跳鄰域中的實(shí)體和關(guān)系特征,使得模型能夠?qū)Σ煌従庸?jié)點(diǎn)指定不同權(quán)值,避免采集的有效鄰居節(jié)點(diǎn)信息量過大帶來的噪聲影響從而影響預(yù)測的結(jié)果;最后,定義了一個以監(jiān)督方式重構(gòu)基因-基因相似度的譯碼器實(shí)現(xiàn)癌癥合成致死預(yù)測。此模型與目前先進(jìn)的合成致死預(yù)測方法進(jìn)行了比較,在ROC曲線下面積(AUC)、precision-recall曲線下面積(AUPR)和F1值等方面優(yōu)于目前流行的baseline方法,證明了該模型的有效性。
(1)圖譜的生成:SynLeth KG中包含11個實(shí)體、24種關(guān)系,如(gene, regulates, gene)、(gene, interactions, gene)等。 11種實(shí)體中有7種與基因直接相關(guān),即途徑、細(xì)胞成分、疾病、化合物等。知識圖譜生成如圖7。首先在SynLethKG數(shù)據(jù)庫中篩選出需要的信息,給定一個癌癥合成致死相關(guān)基因;然后使用Bio2RDF工具構(gòu)建鏈接數(shù)據(jù)網(wǎng)絡(luò),基于傳輸定義從不同格式數(shù)據(jù)源中獲取數(shù)據(jù)后創(chuàng)建與RDF數(shù)據(jù)格式兼容的鏈接數(shù)據(jù);最后,使用RDF將數(shù)據(jù)集處理成三元組形式用于知識圖譜構(gòu)建,從構(gòu)建好的KG中構(gòu)建一個加權(quán)子圖,再識別出相關(guān)的節(jié)點(diǎn)和決定邊感重。

圖6 模型框架圖

圖7 知識圖譜生成圖
(2)對實(shí)體進(jìn)行鄰居采樣:為每個實(shí)體抽取固定數(shù)量的鄰居表征局部結(jié)構(gòu)引入?yún)?shù)H(CNN感知域)重復(fù)H跳,節(jié)點(diǎn)可被重復(fù)采樣。然后將信息聚合起來,作為下個網(wǎng)絡(luò)的輸入[11]。由于每一個基因?qū)嶓w的鄰域分布情況是不一樣的,先對實(shí)體進(jìn)行鄰域采樣:H=1時只考慮與當(dāng)前節(jié)點(diǎn)直接相連的鄰居節(jié)點(diǎn),H=2時考慮二階相連的節(jié)點(diǎn)情況,能夠?qū)W習(xí)到更多鄰域?qū)嶓w信息。每個實(shí)體抽取固定數(shù)量k個鄰居來表征其局部結(jié)構(gòu),并重復(fù)該過程H跳(H >=1)。邊上權(quán)重代表關(guān)系重要性,則邊權(quán)重在子圖計(jì)算方式:
(1)
式中an表示基因,ra,a′表示關(guān)聯(lián)的embedding。
(3)聚合鄰域信息:在構(gòu)建的知識圖譜中,和基因直接相連的節(jié)點(diǎn)定義為Nneigh(a)。由于每個藥物節(jié)點(diǎn)鄰域的分布不同,在采樣完成后,通過聚合方法將實(shí)體自身嵌入表示和鄰域信息嵌入表示聚合起來,最終得到當(dāng)前實(shí)體的嵌入表示。
①對子圖中每個節(jié)點(diǎn)進(jìn)行信息聚合與更新,在對每個節(jié)點(diǎn)計(jì)算加權(quán)平均和,公式如下所示:
(2)
式中a′表示子圖中一個實(shí)體,Za表示子圖中實(shí)體集合,wama,a′表示基因關(guān)系間的重要性權(quán)重。
Q是使用softmax函數(shù)進(jìn)行normalize后的基因關(guān)聯(lián)分?jǐn)?shù),公式如下所示:
(3)

②得到中心節(jié)點(diǎn)的鄰居的表達(dá)后,再對其進(jìn)行信息的聚合與更新,公式如下所示:
A[h+1]=?(Q(a[g]+Az(a))+g)。
(4)
式中:Q表示線性transform層權(quán)重;g表示線性transform層偏置;?表示激活函數(shù),A表示實(shí)體表示;h+1表示更新后的實(shí)體表示;a[g]表示線性變化后的權(quán)重;Az(a) 表示計(jì)算后的加權(quán)平均和。
③在得到兩個基因的表達(dá)之后,它們之間的反應(yīng)概率通過下列公式計(jì)算:
sm,n=?(f(am,an)。
(5)
其中,f()表示基因表達(dá)公式,am,表示基因。
(4)注意力機(jī)制Attention層:將上層輸出作為注意力機(jī)制模型的輸入,從而有效捕獲局部鄰居及全局鄰居的注意力權(quán)重,用來學(xué)習(xí)節(jié)點(diǎn)的局部和全局表示。利用多層感知器將原始特征、局部和全局表示進(jìn)行聚合,從而得到特定的特征表示并對其進(jìn)行整合。對于一個節(jié)點(diǎn),在圖中與其直接相連的節(jié)點(diǎn)定義為局部鄰居。使用下面公式計(jì)算注意力打分:
④對于一個節(jié)點(diǎn),在圖中與其直接相連的節(jié)點(diǎn)定義為它的局部鄰居。考慮到不同的鄰居重要性不同,設(shè)計(jì)注意力機(jī)制來學(xué)習(xí)節(jié)點(diǎn)表示:
(6)
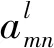
⑤將注意力打分進(jìn)行歸一化,公式如下:
(7)

⑥同時基于局部鄰居信息聚合節(jié)點(diǎn)vi的表示,公式如下所示:
(8)

⑦由于注意力系數(shù)的不穩(wěn)定性,單個節(jié)點(diǎn)的注意力機(jī)制可能會引入噪聲。公式如下所示:
(9)

(5)總loss和優(yōu)化:模型設(shè)計(jì)了兩種loss,基本loss和L2 loss,進(jìn)行cross-entropy計(jì)算:
J=min(sm,n,0)-sm,n*sm,n+log(b+exp(-|sm,n|)。
(10)
式中:sm,n是預(yù)測值;sm,n是真實(shí)值;b是常數(shù)。
⑧‖Γ‖代表對實(shí)體embedding,關(guān)聯(lián)embedding及聚合權(quán)重的L2正則:
(11)
(3)還加入了L2正則loss,公式如下所示:
minW,K,bι=minW,K,b∑m,nj+α‖Γ‖。
(12)
式中:K表示可訓(xùn)練權(quán)重矩陣;bι表示基因關(guān)系評分權(quán)值;∑m,nJ表示關(guān)聯(lián)embedding及聚合權(quán)重后的正則;α表示平衡超參數(shù)。
3 實(shí)驗(yàn)部分
SynLethDB是一個合成致死基因?qū)Φ木C合數(shù)據(jù)庫,包含11個實(shí)體及24種關(guān)系。為使正、負(fù)樣本平衡,隨機(jī)選取未知對作為負(fù)對,使正、負(fù)SL pair數(shù)量相等,包含10 004個基因之間的72 804對基因,去除孤立節(jié)點(diǎn)后,最終包含了54 012個節(jié)點(diǎn)和2 231 921條邊,SL數(shù)據(jù)集見表1。

表1 數(shù)據(jù)集介紹
實(shí)驗(yàn)部分分別用AUC、AURP、F1值三個指標(biāo)進(jìn)行分析,與多種baseline方法比較,包括ML、GRSMF、HOPE、DeepWalk、Node2vec、LINE、GCN、GAT等,實(shí)驗(yàn)結(jié)果對比見表2。

表2 各模型實(shí)驗(yàn)結(jié)果
KG-GCNASL優(yōu)于表中所有baseline方法,與第二優(yōu)模型GRSMF相比,KG-GCNASL在AUC、AUPR和F1上的性能分別提高了4%、3%和3%,證明了模型的有效性。因?yàn)镵G-GCNASL模型可從合成致死對象的相似性中學(xué)習(xí),豐富SL預(yù)測的基因嵌入,表明從包含GO信息的KG中學(xué)習(xí)基因表征和其它基因特征可進(jìn)一步提高SL預(yù)測。
另外對本實(shí)驗(yàn)中一些關(guān)鍵超參數(shù)進(jìn)行了敏感性分析:括鄰居采樣大小k和實(shí)體嵌入維數(shù)d。首先,通過改變鄰居k的樣本數(shù)觀察模型性能,不同鄰居采樣大小對模型的的敏感度分析如圖8。可知,該模型在相鄰采樣尺寸k=64時AUC、F1和AUPR效果最好。當(dāng)k值越高時鄰居采樣越多,采樣信息變得冗余,k為128時模型性能略有下降。
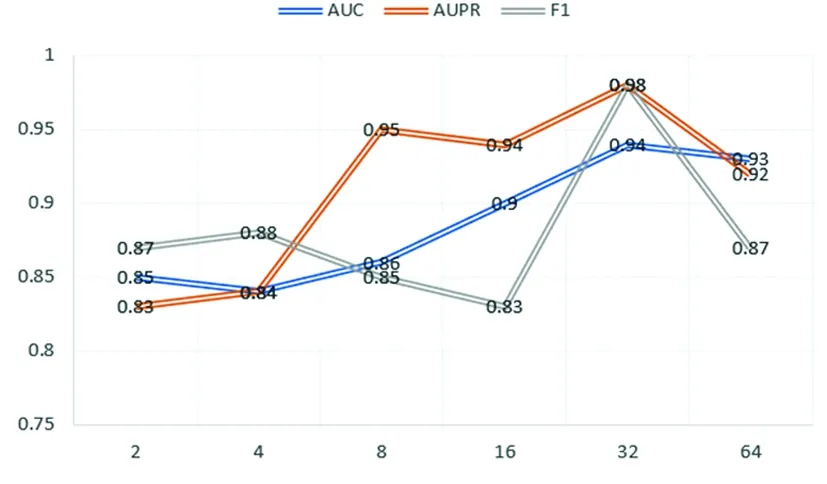
圖8 鄰居采樣大小k的敏感分析
其次,實(shí)驗(yàn)還分析了實(shí)體嵌入維度d對模型敏感度的影響,如圖9。當(dāng)模型嵌入維數(shù)d為256時已經(jīng)有了很好的性能。太大的嵌入維度會給內(nèi)存和計(jì)算帶來負(fù)擔(dān)。最終,實(shí)驗(yàn)中設(shè)置模型的鄰居采樣大小為64,嵌入維數(shù)為256。

圖9 實(shí)體嵌入維度d的敏感分析
通過對SL領(lǐng)域知識的了解與分析,對該領(lǐng)域圖譜實(shí)體類別進(jìn)行設(shè)計(jì):11種實(shí)體有7種與基因直接相關(guān),即途徑、分子功能、疾病等。每類實(shí)體類別中包含多個實(shí)體,每個實(shí)體中包含相應(yīng)屬性信息用于刻畫該實(shí)體的內(nèi)在特征,定義關(guān)系來刻畫實(shí)體和實(shí)體或?qū)傩蚤g的聯(lián)系,其癌癥合成致死預(yù)測研究生成的圖譜如圖10。

圖10 生成的知識圖譜
4 結(jié) 語
合成致死是一種很有前途的基因相互作用類型,在靶向抗癌治療中起著關(guān)鍵作用。本文提出KG-GCNASL方法實(shí)現(xiàn)癌癥合成致死預(yù)測,將知識圖消息傳遞納入到圖卷積神經(jīng)網(wǎng)絡(luò)與注意力機(jī)制模型預(yù)測中:利用包括基因、疾病等在內(nèi)11種實(shí)體和24種SL關(guān)系進(jìn)行構(gòu)建,通過對KG進(jìn)行信息傳遞解決獨(dú)立性問題,模型雖取得了良好的預(yù)測性能但仍有一些局限,希望研究自動特征提取預(yù)訓(xùn)練策略,基于更新的版本的SynLethDB驗(yàn)證預(yù)測的SL對。此模型在AUC、AUPR和F1指標(biāo)上優(yōu)于所有最先進(jìn)baseline方法,并且證明了將知識圖譜納入GCN中對SL預(yù)測的顯著影響。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
 大連民族大學(xué)學(xué)報(bào)2023年1期
大連民族大學(xué)學(xué)報(bào)2023年1期
- 大連民族大學(xué)學(xué)報(bào)的其它文章
- 深入學(xué)習(xí)貫徹黨的二十大精神全面推進(jìn)高水平現(xiàn)代化綜合大學(xué)建設(shè)
- 人類活動影響下蒙遼農(nóng)牧交錯區(qū)的生態(tài)系統(tǒng)服務(wù)空間格局
- 不同環(huán)境介質(zhì)中有機(jī)磷酸酯賦存狀況和源解析研究
- 新工科背景下專業(yè)學(xué)位研究生校外導(dǎo)師隊(duì)伍建設(shè)探索
- 論高校體育課程思政建設(shè)的學(xué)生主體性堅(jiān)守
- 新工科背景下民族院校應(yīng)用化學(xué)專業(yè)實(shí)踐教學(xué)探索