基于SMOTE-GWO-SVM模型的儲罐底板腐蝕聲發射檢測智能評價
2023-03-11 07:46:34薛永強劉祥彪徐海豐
無損檢測 2023年1期
李 偉,薛永強,賈 鑫,劉祥彪,徐海豐
(1.東北石油大學 機械科學與工程學院,大慶 163318; 2.中國石油天然氣集團有限公司 工程和物裝管理部,北京 100007)
隨著經濟的快速發展,我國對石油能源的需求不斷增加,而常壓儲罐作為石油的專用儲存容器,保障其長期安全穩定運行極為重要。儲罐所有部位中底板是最易腐蝕但也是最難檢測的部位,常規無損檢測方法在不開罐的前提下無法對儲罐底板進行有效檢測和評價,目前聲發射檢測是儲罐底板腐蝕狀態在線檢測的主要技術之一[1]。依據標準 JB/T 10764-2007 《無損檢測 常壓金屬儲罐聲發射檢測及評價方法》 能夠對儲罐的底板腐蝕情況做出評價,該標準將儲罐底板腐蝕狀態劃分為5個等級,其中1級最好,5級最差,然而標準中某些關鍵參數值的確定仍需依靠經驗,這給儲罐底板腐蝕狀況的評價帶來了不確定因素,同時限制了聲發射檢測技術在儲罐底板腐蝕檢測中的推廣應用。
隨著機器學習技術的發展,利用機器學習算法、統計方法對數據進行分析,智能化評價儲罐底板的腐蝕狀態,對擺脫對傳統經驗的依賴具有十分重要的意義。美國聲學物理公司基于其掌握的大量儲罐檢測數據研發了大型常壓金屬儲罐底板聲發射檢測專家評估系統(TANKPAC),目前已在全世界進行了大規模應用。國內,陳榮剛[2]通過遺傳算法優化貝葉斯網絡實現了對儲罐底板腐蝕狀態的預測,并將儲罐的宏觀特征作為評價模型的輸入特征,提高模型預測的準確率。張延兵等[3]、宋高峰等[4]、劉琪華等[5]等則利用BP神經網絡及其優化算法建立了儲罐底板腐蝕狀態的預測模型,實現了對儲罐底板腐蝕等級的預測。
儲罐底板腐蝕聲發射智能評價系統的建立需要大量的聲發射檢測數據支持,這不僅對數據的量有要求,數據的分布情況也同樣會影響智能評價系統的準確性。儲罐底板腐蝕檢測數據庫中各等級樣本分布如圖1所示,可見,儲罐底板腐蝕狀況的實際分布情況往往并不均衡,其中1級(非常微小腐蝕)和4級(存在動態腐蝕)的儲罐均只有20臺,而大部分儲罐的聲發射評價等級為2級(存在少量腐蝕)和3級(存在中等腐蝕)。缺陷樣本在數據空間分布上存在差異,尤其是在底板腐蝕狀態極好和極差的儲罐聲發射檢測數據不足的情況下,往往會造成1,4,5等級的欠學習和2,3等級的過學習,從而降低底板腐蝕狀態智能評價系統的準確性。
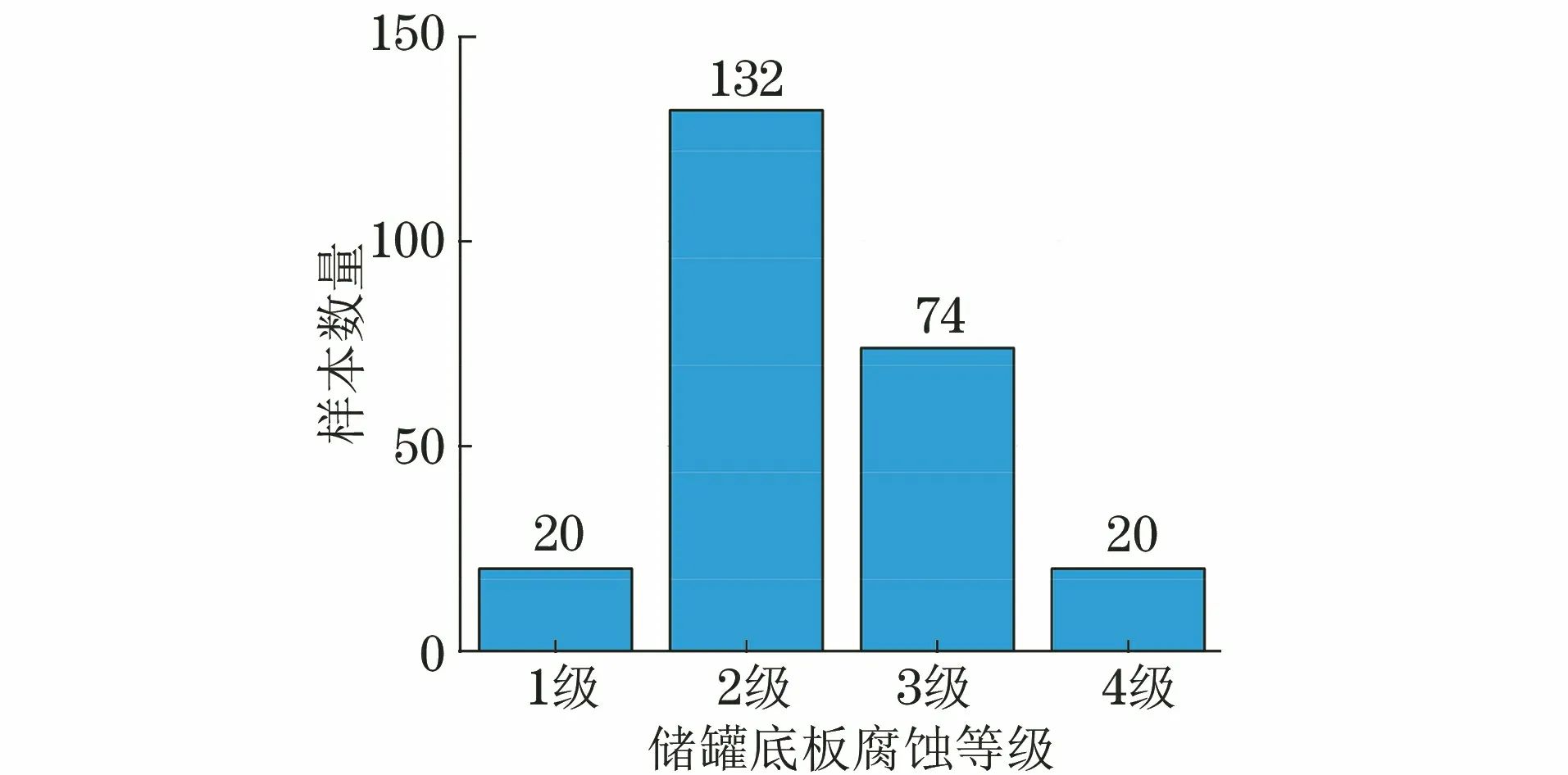
圖1 儲罐底板腐蝕檢測數據庫中各等級樣本分布
針對以上問題,在結合專業人員相關經驗的基礎上,充分考慮了儲罐的宏觀特征和聲發射特征,并以可能的腐蝕導向對特征進行了合理的預處理,同時提出采用過采樣技術來優化樣本空間,改善數據集的平衡性。過采樣技術是一種廣泛應用的數據增強方法,其中SMOTE算法是該領域影響力最大的過采樣方法,能大幅度改善數據集的平衡性[6],最后結合灰狼算法優化的支持向量機(GWO-SVM),實現對儲罐底板腐蝕聲發射檢測等級的智能評價。
1 SMOTE-GWO-SVM儲罐底板腐蝕聲發射檢測等級智能評價模型
1.1 基于SMOTE算法的樣本優化
與試驗數據不同,儲罐底板腐蝕的現場聲發射檢測數據非常珍貴,在246個樣本數據中,2,3級占83.7%,1,4級均僅占16.3%,存在樣本分布不均衡的情況,為提高后續模型的訓練效果,采用SMOTE算法對少數類樣本進行擴充。SMOTE算法對距離較近的少數類樣本進行線性插值生成新的少數類樣本,以實現數據平衡[7]。其主要計算過程為:① 對于每一個少數類樣本x,計算其到該類中其余所有樣本的歐氏距離并得到k近鄰;② 根據數據集的不平衡比例設置采樣倍率N,從少數類樣本x的k近鄰中隨機選擇若干個實例,假設選擇的近鄰樣本為xn;③ 將隨機選擇的樣本xn按照式(1)計算出新的樣本,并加入到數據集中。
xnew=x+rand(0,1)×(xn-x)
(1)
式中:x為少數類樣本;xnew為生成的新樣本;rand為隨機函數。
1.2 基于灰狼優化算法的支持向量機(GWO-SVM)智能評價模型
SVM(支持向量機)是一種處理分類和回歸問題的監督式機器學習算法。在樣本數據量不充足的情況下,與人工神經網絡等其他需要大量數據訓練的分類算法相比,具有更好的學習效果[8]。對于線性分類問題,其利用間隔最大化求解最優分離超平面;對于非線性分類問題,其通過核函數將原空間的數據映射到新空間,在新的空間里用線性分類學習方法學習分類模型。對于非線性可分的SVM形式可描述為[9]
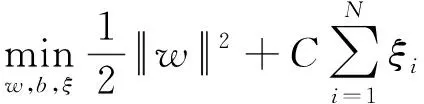
(2)
s.t.yi(wxi+b)≥1-ξi,i=1,2,1,…,N
(3)
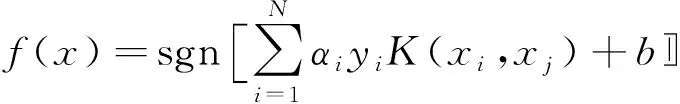
(4)
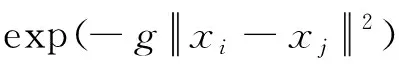
(5)
式中:w為權值;b為誤差;C為懲罰因子;ξi為松弛變量;N為訓練樣本數;s.t.為約束條件;xi,xj為樣本;yi為類別號;K(xi,xj)為核函數;αi為拉格朗日乘子;sgn為判別函數;f(x)為分類決策函數;σ2為核函數參數;g為內部參數,g=1/(2σ2)。
懲罰因子C和核函數內部參數g共同決定了SVM模型的精度,依靠經驗確定SVM的參數難以使模型達到最大準確率,因此對SVM的參數C和g進行優化,確定最優值十分重要。
在眾多支持向量機的優化方法中,灰狼優化算法(GWO)與其他傳統方法相比具有在復雜空間的全局搜索能力,GWO算法是受狼群捕獵行為啟發而提出的群體優化算法,優化過程分為以下3個部分[10]。
(1) 包圍獵物。狼群在狩獵過程中需要確定獵物位置并包圍獵物,用數學方程描述為
D=|SXP(t)-X(t)|
(6)
X(t+1)=XP(t)-AD
(7)
A=2ar1-a
(8)
a=2-2t/T
(9)
S=2r2
(10)
式中:D為灰狼與獵物之間的距離;XP(t)為當前最優解即獵物位置;X(t)表示灰狼當前位置;X(t+1)為迭代至t+1次時灰狼的位置;A和S為系數;r1和r2為在 [0,1] 區間內的隨機數;a為收斂因子,隨著迭代次數增加從2線性遞減到0;T為最大迭代數。
(2) 狩獵過程。在狩獵時,狼群的位置不斷變化,此過程在α狼、β狼、δ狼的引導下,計算ω狼群與前3個狼的距離并不斷更新位置,接近獵物,此過程的數學描述為
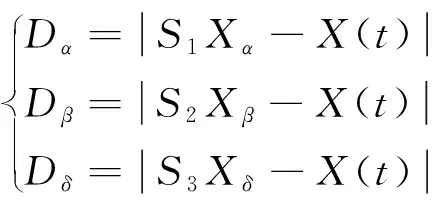
(11)

(12)
Xt+1=(X1+X2+X3)/3
(13)
式中:Dα,Dβ,Dδ分別為α,β,δ狼與其他狼之間的距離;Xα,Xβ,Xδ分別為α,β,δ狼的當前位置;S1,S2,S3,A1,A2,A3為系數;X1,X2,X3為普通灰狼向α,β,δ狼移動的步長;Xt+1為迭代至t+1次時獵物的位置。
(3) 攻擊獵物。在最后階段,狼群攻擊追捕獵物即完成尋優過程,獲取最優解。在收斂因子a從2線性遞減到0的過程中,當|A|≤1時狼群集中攻擊,捕獲獵物位置進行局部搜索,當|A|≥1時狼群發散,遠離獵物進行全局搜索。
1.3 SMOTE-GWO-SVM模型構建
首先利用SMOTE算法處理擴充數據集,實現樣本數據的平衡,利用SVM算法進行訓練,并采用GWO算法優化SVM算法中的參數,從而得出使儲罐底板腐蝕等級評價精度最高的最佳參數,優化評價結果。SMOTE-GWO-SVM模型的流程圖如圖2所示。
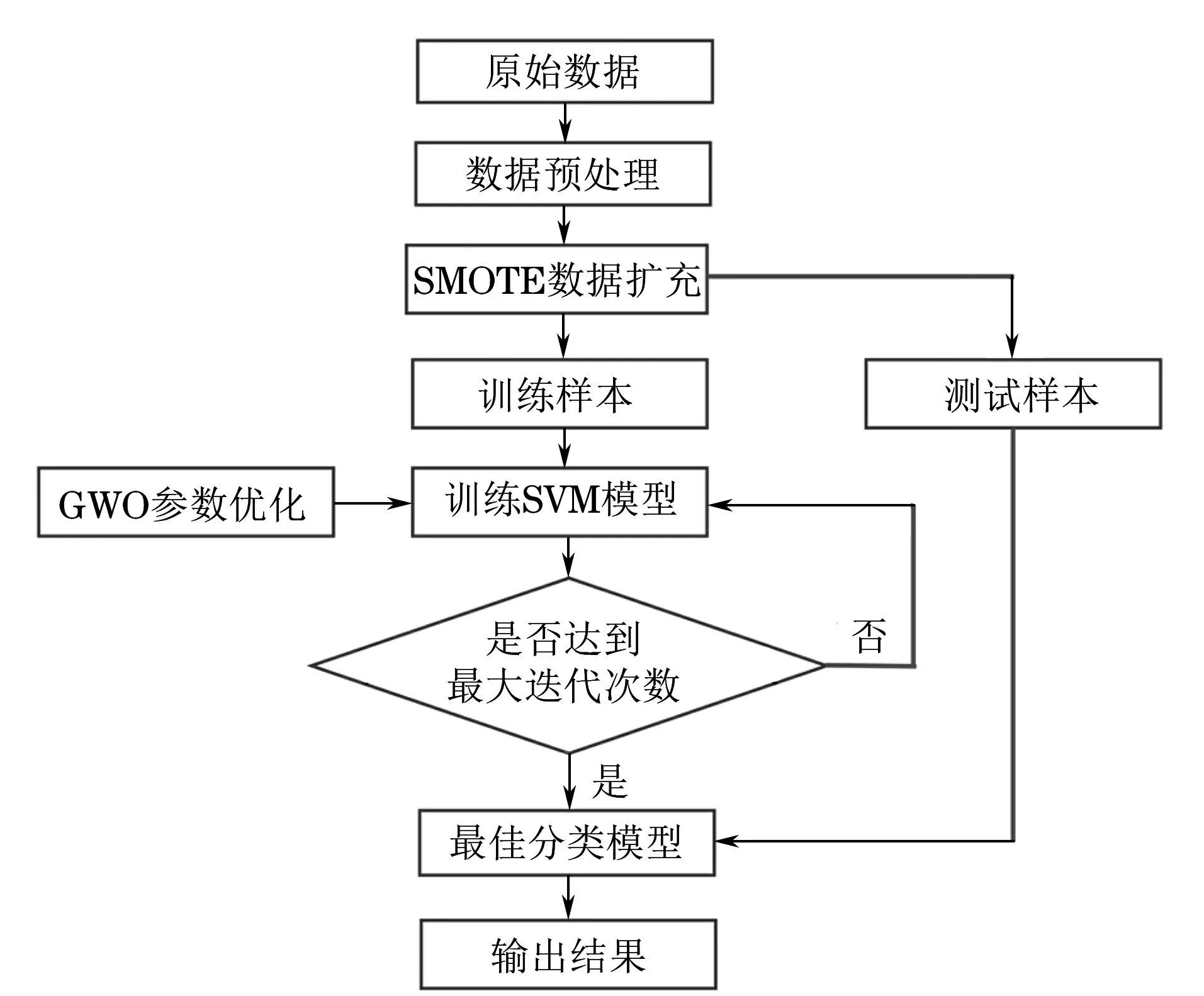
圖2 SMOTE-GWO-SVM模型流程圖
2 儲罐底板腐蝕狀態聲發射智能評價模型的應用
2.1 數據預處理
儲罐聲發射檢測數據均來源于課題組所依托的國家認證聲發射檢測實驗室近年來進行現場儲罐聲發射檢測所建立的數據庫。每條數據有兩類特征(宏觀特征和聲發射特征),共20個特征參數,具體如表1所示。
表1中數據類型復雜,部分宏觀特征并不是數值型數據,考慮到不同條件底板腐蝕的情況不同,因此并沒有直接采用one-hot編碼,而是以可能的腐蝕狀況為導向對儲罐字符型宏觀特征進行預處理,預處理結果如圖3所示(腐蝕速率為歸一化數值,無量綱)。處理分析如下所述。
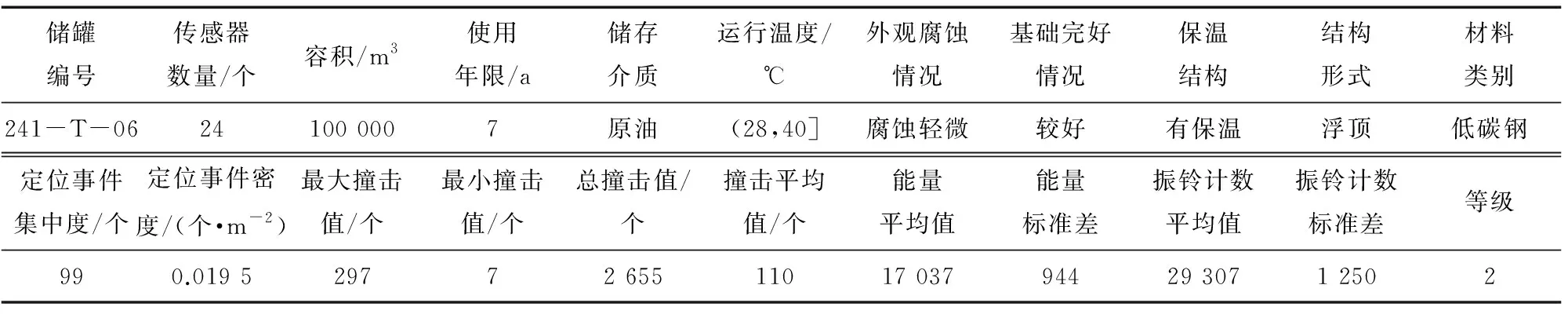
表1 儲罐宏觀特征和聲發射特征數據
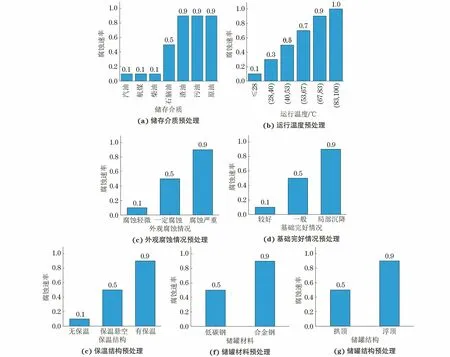
圖3 儲罐宏觀特征腐蝕導向預處理結果
(1) 儲存介質。儲罐內的各儲存介質對儲罐的腐蝕程度不同,重質儲罐的腐蝕程度比輕質儲罐的腐蝕程度更嚴重[11]。
(2) 運行溫度。對于絕大多數化學反應,反應速率會隨溫度升高而加快[12]。
(3) 外觀腐蝕情況。外觀腐蝕情況包括罐壁、罐底邊緣板及焊縫腐蝕情況,防腐漆脫落情況等,外觀情況較差則儲罐腐蝕更嚴重[13]。
(4) 基礎完好情況。儲罐基礎無防滲層、表面有粘土、底部滲水、沉降等都會加重儲罐的腐蝕[14]。
(5) 保溫結構。保溫層多為疏松多孔結構,易吸水,且保溫層下的水分冷凝難以蒸發,與雜質形成電解質溶液更易造成儲罐腐蝕[15]。
(6) 材料類別。建造常壓儲罐所用材料多為低碳鋼和合金鋼,低碳鋼S和P的含量較高,而合金鋼添加了Mn,Cr,Ni等耐腐蝕元素,其耐蝕性比低碳鋼耐蝕性更好[16]。
(7) 儲罐結構。浮頂儲罐浮盤支柱與儲罐底板接觸部位的涂層易受到破壞無法再次涂刷,且浮頂儲罐支柱易對底板造成沖擊,更易造成儲罐底板腐蝕[17]。
預處理后的數據宏觀特征和聲發射特征之間的量級相差較大,如果不進行無量綱化處理會對后續計算造成較大影響,因此對數據進行了歸一化處理,公式為
y=(x-xmin)/(xmax-xmin)
(14)
式中:x為樣本值;xmax,xmin分別為樣本的最大值和最小值;y為歸一化后的值,范圍在01之間且無量綱。
儲罐宏觀特征和聲發射預處理后的數據如表2所示(表中宏觀特征均已數據化)。

表2 儲罐外觀和聲發射數據預處理后的數據
2.2 智能評價模型應用
為提高模型的訓練效果,使用SMOTE算法進行少數類樣本擴容,將每個等級各20個原數據集樣本作為測試集,其余樣本和擴充樣本作為訓練集,同時,采用GWO優化算法對SVM算法的懲罰因子C和和核數參數g進行優化,以獲得最佳模型,經試驗,最終尋參結果為C=3.97,g=1.79,圖4為SVM參數尋優過程示意。
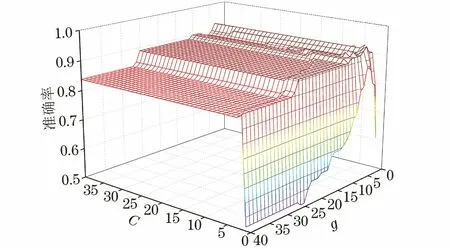
圖4 SVM參數尋優過程示意
為驗證SMOTE-GWO-SVM模型用于儲罐底板腐蝕等級評價的有效性,將未進行SMOTE處理和SMOTE處理后數據的分類結果進行對照,其中未經過SMOTE處理的數據中1級、4級各10個,2級、3級各20個原數據集樣本作為測試集,其余作為訓練集。同時與BP神經網絡和隨機森林(RF)算法進行分類準確性對比,結果如表3所示,各個模型的混淆矩陣如圖5所示。
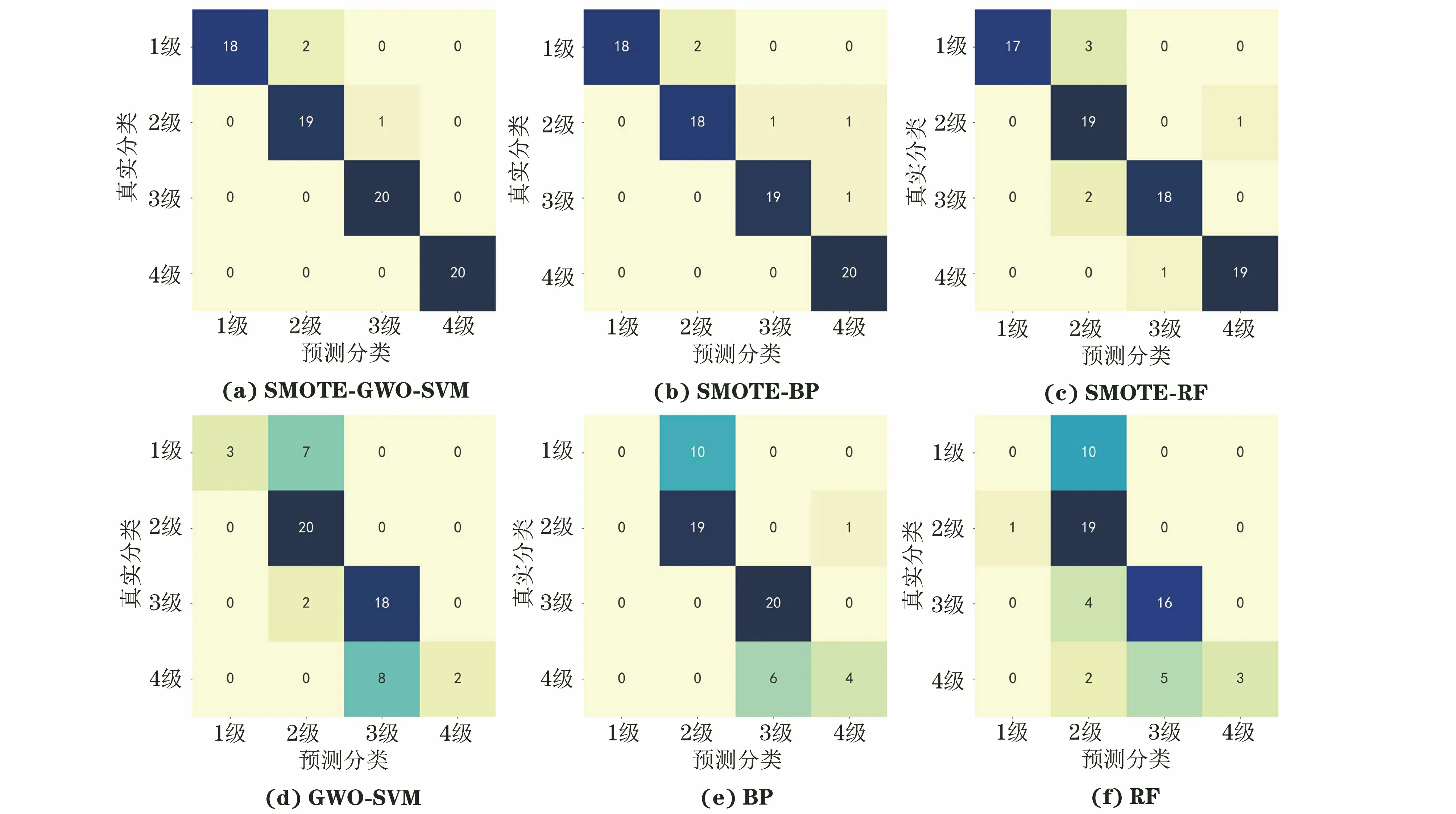
圖5 各預測模型的混淆矩陣

表3 各模型準確率對比
由分析結果可知,在進行SMOTE處理之前,儲罐底板腐蝕1級和4級的樣本數量較少,模型得不到充分訓練,導致這兩類數據的分類準確率極低。對數據集進行SMOTE處理后,針對不平衡小樣本數據的分類準確率有較明顯提升,準確率從71.67%提升至96.25%。
從模型準確率的角度分析,SOMTE-GWO-SVM模型的準確率最高,從模型安全性的角度分析SOMTE-GWO-SVM模型將低腐蝕等級預測為高腐蝕等級,雖然可能會提高后續儲罐的維護成本,但是更好地滿足了石化行業對安全性的高要求,因此采用SOMTE-GWO-SVM模型對儲罐底板腐蝕等級進行預測,可滿足企業安全生產和維護要求。
2.3 智能評價結果分析
儲罐典型聲發射特征參數分布如圖6所示(IQR為四分位距),可見,儲罐腐蝕情況越嚴重,聲發射參數中的定位事件密度、撞擊平均值、能量標準差和振鈴計數標準差就越大,這與儲罐聲發射檢測評價標準一致。標準將評定區域內每小時出現的定位數和每個通道每小時出現的撞擊數作為儲罐底板腐蝕等級的評價依據。從圖6也可以看出,不同腐蝕等級的聲發射數據存在一定程度的重合區域,對于某一腐蝕等級,儲罐個體數據之間可能存在差異,而智能評價模型對多維度數據(聲發射特征和宏觀特征)進行學習和訓練,避免了某個維度數據偏差給整體評價帶來影響。
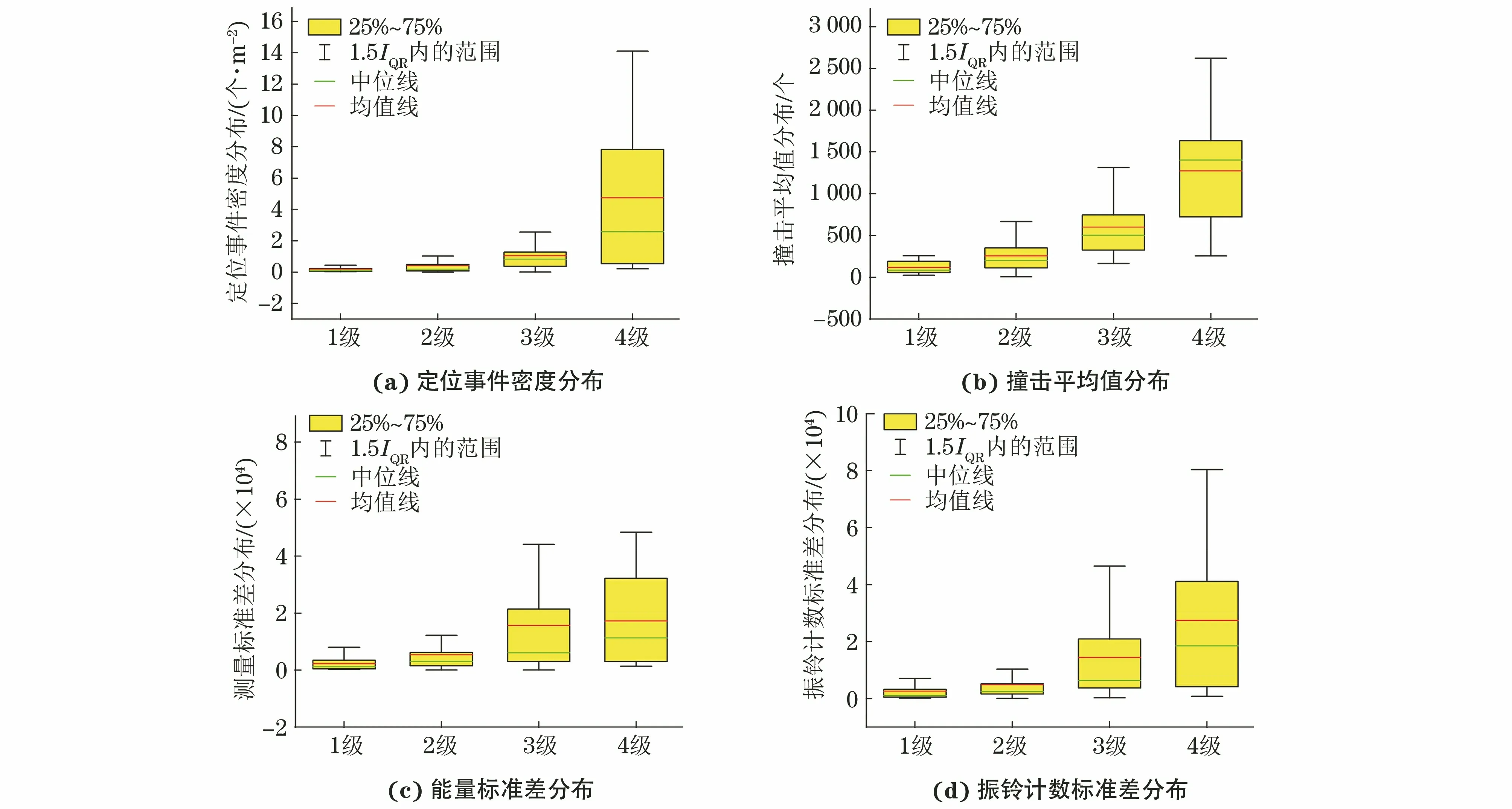
圖6 儲罐典型聲發射特征參數分布
儲罐樣本不同特征的分布如圖7所示,圖中儲罐的腐蝕等級與儲罐的使用年限、運行溫度、外觀腐蝕情況和儲罐基礎沉降情況呈正相關。不難理解,儲罐服役年限越長,儲罐底板累積腐蝕產物越多,服役狀態越差,而溫度越高,存儲介質越容易與底板材料發生化學反應。外觀腐蝕情況和儲罐沉降則體現了企業對儲罐的日常維護和維修情況,若外觀疏于維護,罐內底板的腐蝕狀態也不會太好。此外,儲罐腐蝕狀態與儲罐體積呈負相關,即儲罐體積越大,底板腐蝕狀態越好。數據研究發現,大型儲罐建造年限都比較短,同時由于建造費用高,企業對大型儲罐的維護投入也較高,所以儲罐容積越大,儲罐底板越不容易腐蝕。
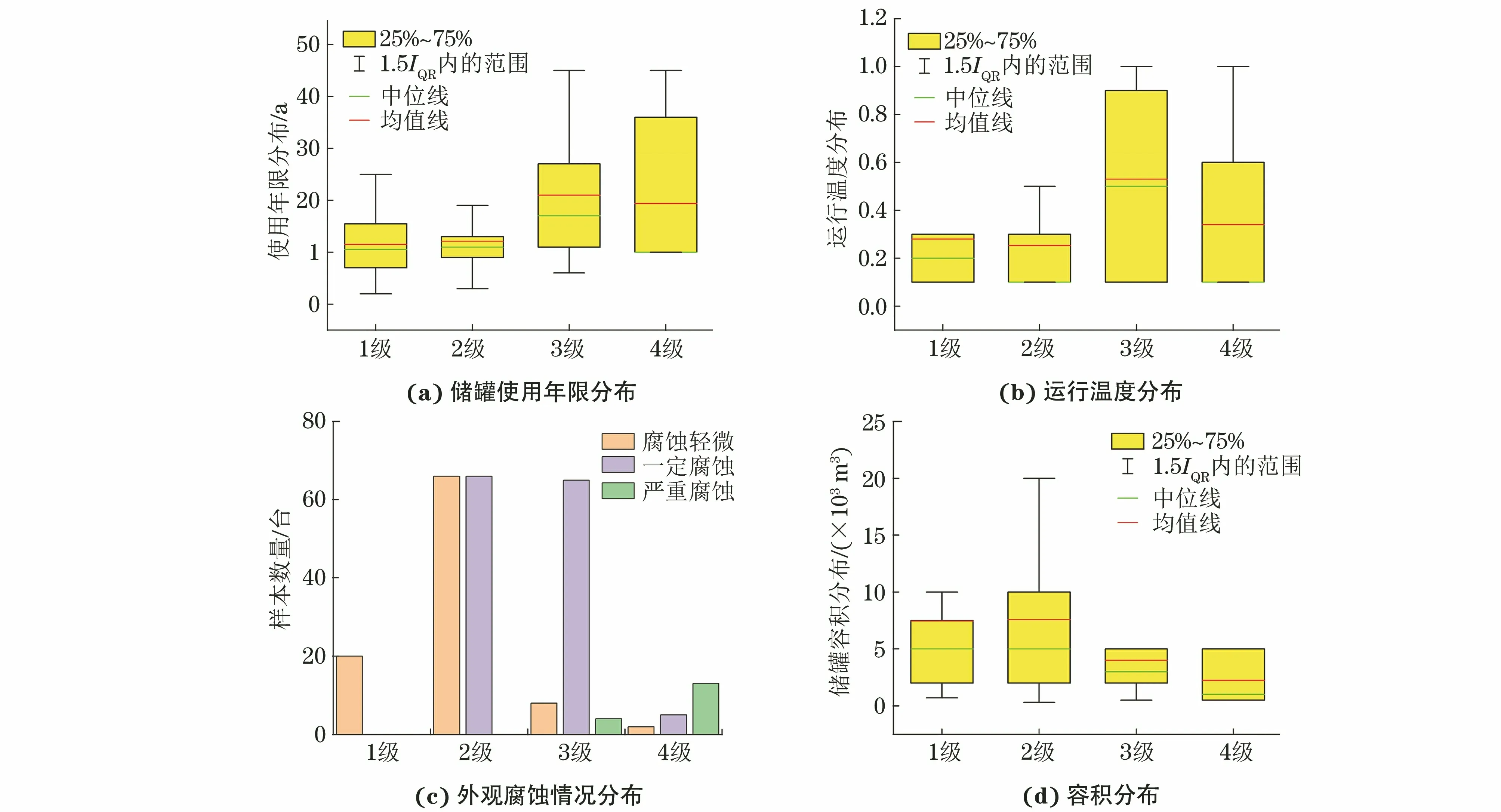
圖7 儲罐樣本不同特征分布
3 結語
(1) 將儲罐宏觀信息和聲發射數據相結合,并以可能的腐蝕狀況導向對儲罐宏觀信息進行預處理,提高了數據的合理性。
(2) SMOTE-GWO-SVM智能評價模型能夠通過擴充少數類數據集樣本,實現各類樣本空間的平衡,相對未采用SMOTE算法的智能評價模型,準確率從71.67%提升至96.25%。
(3) 智能評價結果表明,儲罐腐蝕與聲發射參數中的定位事件密度、撞擊平均值、能量標準差和振鈴計數標準差呈正相關,與外觀參數中的儲罐使用年限、運行溫度和外觀腐蝕情況呈現正相關。
(4) 利用同時考慮聲發射特征和宏觀特征的智能評價模型對多維度數據進行分析,實現了對儲罐底板腐蝕狀態評價分級,避免了某個維度數據偏差給整體評價帶來影響。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
河南科技(2014年23期)2014-02-27 14:19:15
