基于多尺度特征的視盤分割方法
2023-03-09 12:43:16曹婭迪黃文博
吉林大學學報(理學版) 2023年1期
燕 楊, 曹婭迪, 黃文博
(長春師范大學 計算機科學與技術學院, 長春 130032)
精準分割眼底圖像中的視杯和視盤是診斷眼底疾病(如青光眼)的重要因素[1-3].利用眼底圖像中視盤(optic disc, OD)區域和視杯(optic cup, OC)區域的形態學變化是篩查青光眼的早期特征之一, 因此分割OD/OC區域, 并計算杯盤比(cup to dis ratio, CDR)是診斷青光眼的重要因素.OD/OC目前仍需醫生手工分割, 這種方法過于依賴醫生經驗, 不同醫生對同一病例可能有不同的判斷, 不利于醫療水平較差區域的青光眼篩查.同時, 手工分割效率較低, 很難實現大規模篩查.視杯盤自動分割算法輔助青光眼診斷篩查, 相對更客觀、更高效.
視杯盤自動分割算法目前主要有閾值分割方法[4]、超像素分類法[5]、水平集法[6-7]和主動形狀建模法[8-9]等, 這些方法雖然可準確分割OD/OC, 但存在CDR偏小時分割誤差大、需設定恰當參數、過度依賴對比度強的特征及分割效率低等問題.隨著深度學習的廣泛應用, 使用深度學習方法解決OD/OC分割任務的研究已備受關注.如Fu等[10]研究表明, OD/OC分割中的難點在于前背景像素不均衡, 針對該問題, 提出了視盤和視杯聯合分割的深度學習方法, 首先對輸入圖像進行極坐標變換并采用多尺度輸入, 同時對每個尺度的輸入產生相應的輸出, 實現對網絡的深層監督, 最終將多個尺度的輸出特征圖拼接為最終輸出.該方法充分利用了“視杯包含于視盤內”這一先驗知識, 使用多標簽分類, 解決了眼底圖像中屬于“視盤”類像素過少的問題, 實現了視盤和視杯的自動分割, 但該網絡是在極坐標下進行的, 最終結果并非直接分割所得, 而是經過坐標轉換后再進行圓擬合所得, 損失了分割精度;董林等[11]提出了一種端到端的基于區域的深度卷積神經網絡(R-DCNN)用于視盤和視杯的自動分割, R-DCNN由殘差網絡(residual network, ResNet)ResNet34作為主干網絡進行特征提取, 同時, 為提取更密集的特征, 在ResNet34中引入了密集原子卷積.視盤建議網絡(disc proposal network, DPN)根據主干網絡提取的特征, 給出多個可能的視盤區域, 并將其與經過感興趣池化(ROI pooling)處理的特征聯合, 送入分類器, 產生最終的視盤分割結果.該方法利用視盤和視杯的包含關系, 產生視盤分割結果后, 將特征圖中相應區域通過盤注意力模塊進行裁剪, 作為視杯分割的輸入.雖然通過密集原子卷積降低了卷積池化過程中過濾的特征信息導致的影響, 但由于ROI pooling的量化誤差導致了精度損失.
現有算法雖然能實現自動分割視盤、視杯, 達到輔助青光眼診斷的基本目的, 但仍存在很多不足.由于成像條件不同及個體差異會導致視盤、視杯區域顏色、大小、形狀不同, 現有分割方法由于缺少豐富的感受野, 無法利用更多的尺度特征, 很難捕捉尺寸差異大的目標, 在分割時易出現欠分割問題.而多樣的感受野可為網絡引入豐富的上下文信息, 降低其他病變區域對視盤、視杯分割的影響.基于此, 本文提出一種基于多尺度特征的視盤分割方法, 以一種更輕型的U型網絡(U-Net)——輕型U型網絡(UNet-Light)[12]為主干網絡.U型網絡在上采樣過程中將其結果與原特征圖拼接, 融合更多尺度, 同時將UNet-Light與金字塔池化模塊[13]相結合, 以進一步豐富感受野, 充分利用上下文信息, 使網絡更好地捕捉大小不同的目標, 同時兼顧局部特征和全局特征, 增加可利用的空間信息, 從而完成視盤自動精準分割.其結構如圖1所示.
1 視盤分割方法設計
1.1 U-Net
由于彩色眼底圖像數據集所包含的圖像數量小, 單張圖像尺寸較大, 因此用原始圖像作為輸入會加大訓練難度.U-Net[14]是全卷積神經網絡(fully convolution net, FCN)的一種, 其采用Overlap-tile策略將輸入圖像分割為多個圖像塊再進行訓練, 處理后再拼接多個圖像塊作為最終輸出結果, 從而在提高分割精度的基礎上加快訓練速度.因此, U-Net在彩色眼底圖像分割中性能優于其他方法.
U-Net主要由兩部分組成: 收縮路徑用于獲取上下文信息; 擴張路徑完成精準分割.收縮路徑和擴張路徑同樣擁有大量的特征通道, 允許網絡將上下文信息傳播到更高分辨率層.因此, 兩條路徑呈對稱狀態.收縮路徑通過池化操作降低特征圖分辨率, 其特征提取由重復卷積完成, 每層卷積結束后對特征圖進行最大池化操作, 使得在提取特征過程中特征圖尺寸不斷減小, 通道數增加.擴張路徑則會將來自對應收縮路徑的高分辨率輸出和擴展路徑輸出進行拼接, 該過程實際上是將多尺度特征進行融合, 使網絡可提取多個尺度的特征.
對于一張輸入特征圖, 要經過兩次卷積核大小為3×3的卷積操作, 為防止出現過擬合現象并提高網絡泛化能力, 在每次卷積后使用退出層, 使一定概率的神經元不再傳播, 再用ReLU激活函數進行激活.對于輸入的X, 若X>0, 則ReLU激活函數將保留其值;若X<0, 則將其賦值為0.計算公式為
ReLU(X)=max{0,X}.
(1)
然后對特征圖進行最大池化操作, 輸出特征圖的寬和高將會減少至輸入圖像的0.5倍, 通道數增加2倍.圖像將通過上述層序列多次, 直到分辨率降為合適大小.在上采樣層添加2×2的上采樣操作, 使其寬和高提升至原來的2倍, 并將其與對應下采樣層的輸出進行融合.
1.2 UNet-Light
為縮短在較大數據庫中對算法進行再訓練所消耗的時間, 本文引入改進的UNet-Light作為主干網絡.與原始U-Net相比, UNet-Light減少了所有卷積層上的濾波器, 但用于降低分辨率的濾波器數目并未減少.從而不會降低任務的識別質量, 在參數數量和訓練時間方面使體系結構變得更輕量級, 使網絡模型性能得以提高.其結構如圖2所示.
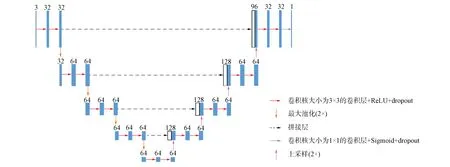
圖2 UNet-Light網絡結構Fig.2 UNet-Light network structure
在視盤分割任務中, 由于視盤僅占眼底圖像的較小區域, 導致了前背景像素嚴重不均衡的問題, 訓練時損失函數易陷入局部最小值, 產生更重視背景部分的網絡, 前景部分常會丟失或僅被部分分割.為解決上述問題, 本文模型損失函數設計為
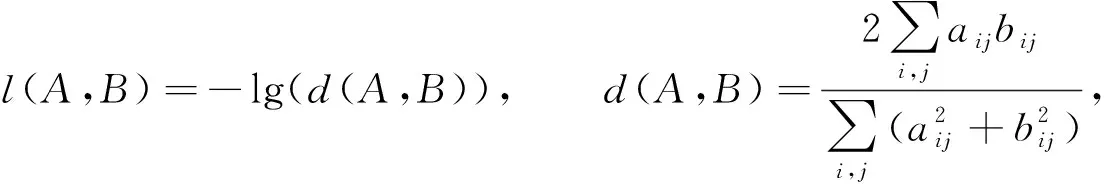
(2)
其中:A為網絡輸出的概率圖;B為專家手工標注的真實標簽, 包含每個像素及其所屬的類;aij和bij分別表示A和B中的某一像素;d(A,B)是Dice損失函數[15], 取值范圍為[0,1].該函數計算概率圖與真實標簽的相似度, 使網絡不會在前景占比較小時, 為追求更小的損失將圖像全部分割為背景像素, 而是更重視對前景的分割.
1.3 金字塔池化模塊
眼底圖像中視杯尺寸在不同患病階段有較大差異, 針對這種變化, 本文引入如圖3所示的金字塔池化模塊(pyramid pooling module, PPM), 通過設計多個不同大小的感受野檢測不同大小的目標, 以減少視杯大小變化導致的分割錯誤.同時, 金字塔池化模塊也使網絡獲得了更豐富的多尺度特征, 這些極具區分度的多尺度特征對OD/OC精準分割至關重要.
金字塔池化模塊中采用最大池化操作, 本文通過1×1,2×2,4×4和8×8四個不同大小的感受野收集特征圖的上下文信息并對其編碼, 池化后得到4個不同大小的特征圖.對每個特征圖進行1×1的卷積操作, 將其通道數降為一維, 以減少計算權重產生的消耗.為將池化結果聚合, 先使用雙線性差值方法對其進行上采樣操作, 池化后大小不一的特征圖被擴張至原始特征圖大小, 并與原始特征圖進行拼接.最后, 對拼接的特征圖采用1×1卷積操作, 將通道數恢復至原特征圖大小, 最終的輸出特征圖尺寸與輸入特征圖尺寸相同.
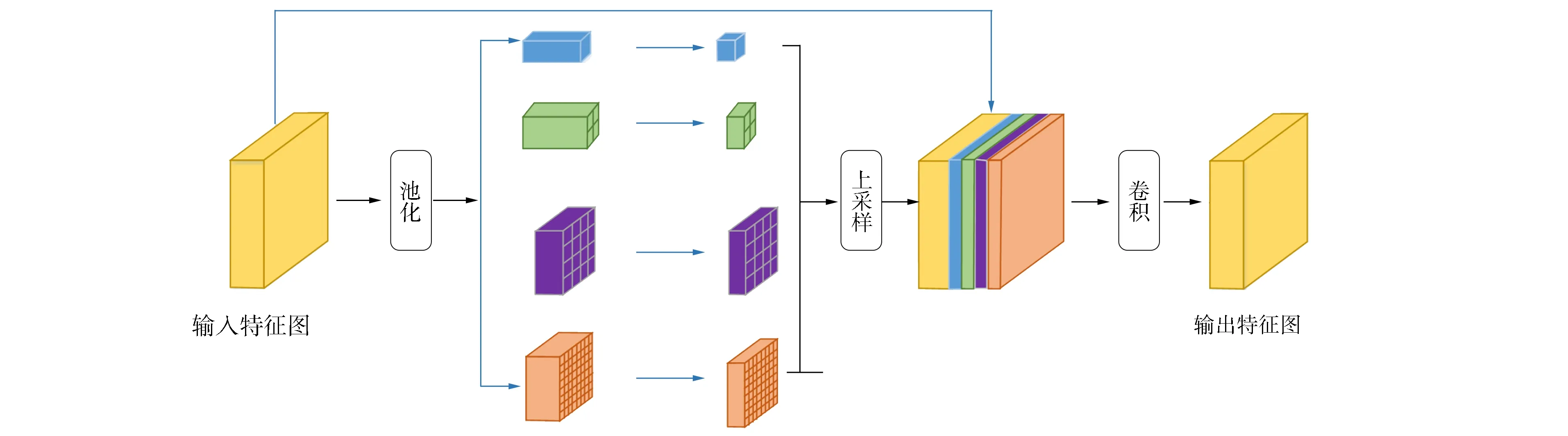
圖3 本文金字塔池化模塊Fig.3 Proposed pyramid pooling module
若輸入特征圖F, 則產生最終特征圖的過程如下:
其中MaxPooln×n表示卷積核大小為n×n的最大池化操作, Conv1×1表示卷積核大小為1×1的卷積操作, UpSamble表示上采樣操作, ⊕表示對不同尺度的特征圖進行鏈接,P為最終輸出的特征圖.
2 實 驗
2.1 數據集圖像預處理
在公開彩色眼底視盤、視杯分割數據集RIM-ONE v.3[16]中, 利用本文方法在視盤、視杯分割任務中進行多組對比實驗, 以驗證本文方法的性能及泛化能力.數據集RIM-ONE v.3由159張彩色視網膜圖像組成, 分為健康眼、青光眼和疑似青光眼兩類.每張圖像的視盤和視杯均由眼科專家進行分割, 作為分割標準.
在進行網絡模型訓練前, 先對輸入圖像做預處理.預處理采用對比度受限自適應直方圖均衡化(contrast limited adaptive histogram equalization, CLAHE)方法以增強對比度, 避免放大噪聲及圖像失真.CLAHE方法將眼底圖像分為多個子域, 對每個子域分別進行直方圖均衡化, 同時限制每個子域的對比度.設對比度閾值為T, 對原始直方圖高度超過T的部分從頂部開始裁剪, 為保證整個直方圖最終面積不變, 將裁剪掉的部分均勻地分布在整個像素范圍內, 使整個直方圖上升L, 最大值為T+L, 重復該過程直到L可忽略不計.CLAHE方法表達式為
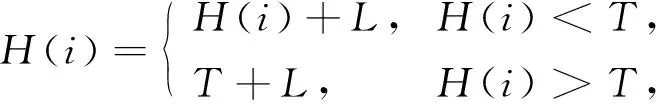
(4)
其中H(i)表示直方圖在i處的高度.
均衡后采用雙線性插值法消除子域邊界產生的偽影.設均衡后的圖像為f(x,y), (xi,yi)為其中某像素點, (xi,yi)在原圖像中最鄰近的4個像素點為Q11=(xi,yi),Q12=(x1,y2),Q21=(x2,y1),Q22=(x2,y2),f(x,y)在這些像素點的值已知, 則雙線性插值結果為
為防止過擬合, 還需對圖像進行隨機縮放、隨機水平偏移、隨機垂直偏移和隨機旋轉等預處理操作.
2.2 評估標準
本文采用Dice系數、平均交并比(mean intersection over union, MIoU)和均方誤差(mean square error, MSE)作為算法評估標準.
Dice系數用于計算預測結果與真實標簽的相似度, 公式為
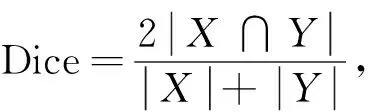
(6)
其中X是真實標簽圖像,Y是預測結果圖像.平均交并比MIoU用于計算預測結果與真實標簽的交并比, 公式為
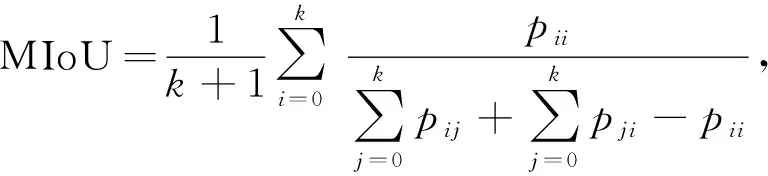
(7)
其中k為類別數量, 本文k=1,i表示前景類,j表示背景類,pij為將前景分割為背景的概率.均方誤差MSE用于計算預測結果與真實標簽的偏差程度, 其值越小, 分割性能越好, 公式為
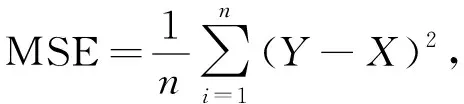
(8)
其中X為真實標簽圖像,Y為預測結果圖像,n為圖像包含像素的數量.
2.3 實驗結果與分析
本文方法與其他方法對比實驗結果列表1.由表1可見, 本文方法的平均交并比MIoU由0.896提升至0.908, Dice系數由0.951提升至0.958, 均方誤差MSE則降低了0.001, 證明了本文方法的有效性.
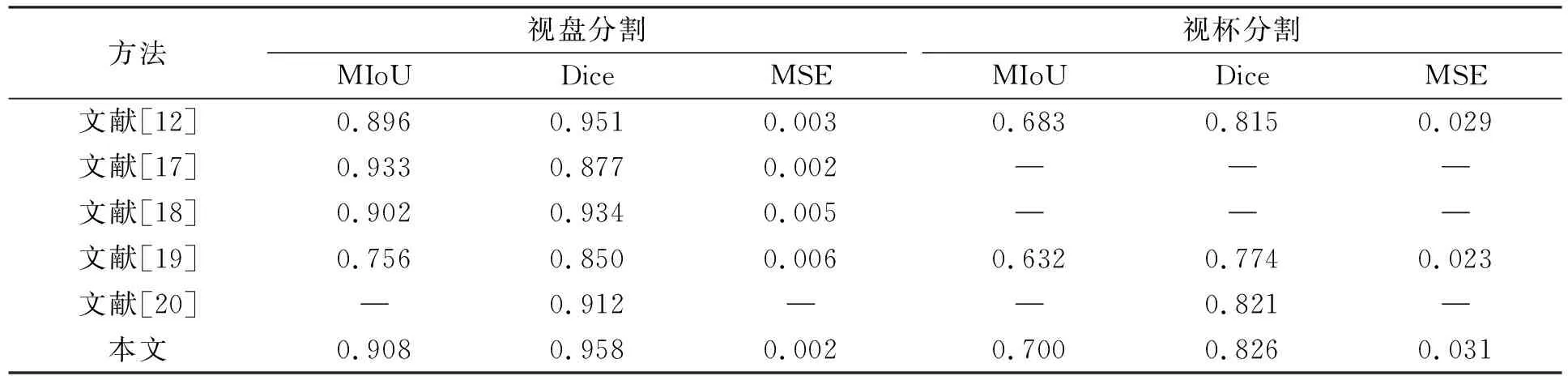
表1 不同方法在數據集RIM-ONE v.3上的對比結果
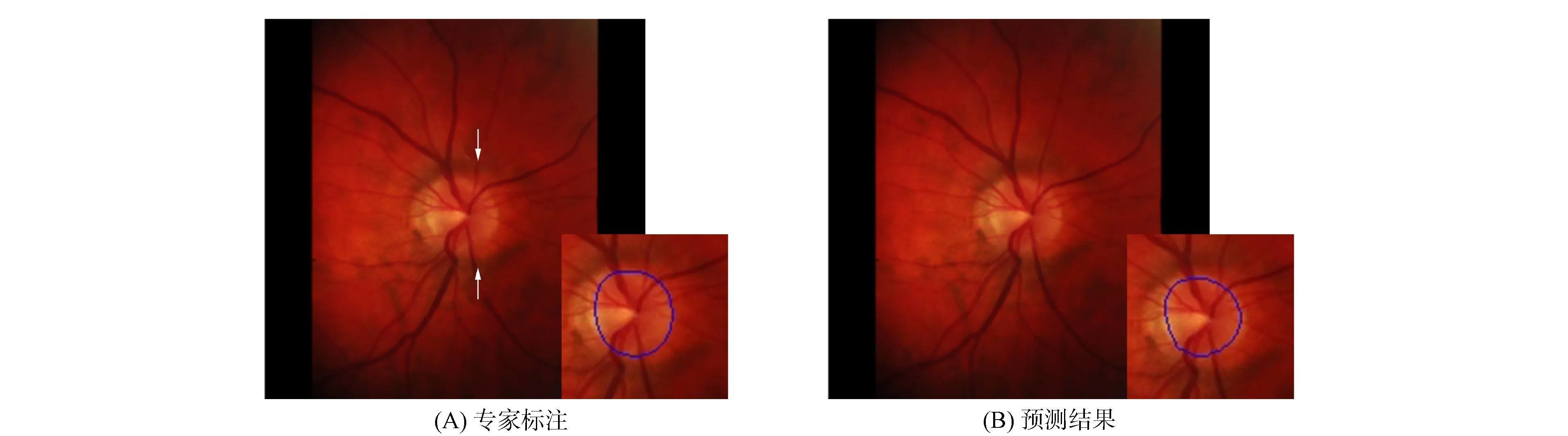
圖4 視盤分割示例Fig.4 Examples of OD segmentation
眼底圖像采集光照不均及眼底病變和滲出物的干擾都會加大視盤分割難度, 圖4為視盤分割示例.由圖4可見, 視盤左側邊界不清晰, 且箭頭所指處存在陰影, 被陰影包圍區域與陰影產生明暗對比.若算法僅關注局部特征, 則很容易誤認為陰影中全是視盤, 導致誤分割.由于本文方法兼顧了全局與局部特征信息, 因此在邊界模糊且有陰影干擾的情況下, 仍實現了視盤區域精準分割.
視杯包含在視盤內部, 基于該先驗知識, 本文在進行視杯分割前先根據視盤分割結果對眼底圖像進行裁剪.圖5為一個視杯分割示例.圖5(A)為數據集中的原始圖像和經過裁剪后的輸入圖像, 由圖5(A)可見, 視杯和視盤擁有極相似的特征, 很難區分.同時, 視盤中心匯聚的大量血管結構也對視杯分割產生干擾, 增加了分割難度.由圖5(B),(C)可見, 本文方法實現了視杯區域精準分割, 驗證了本文網絡模型的特征提取能力.圖6和圖7展示了更多的可視化結果, 驗證了本文方法準確率不受目標大小變化的影響.
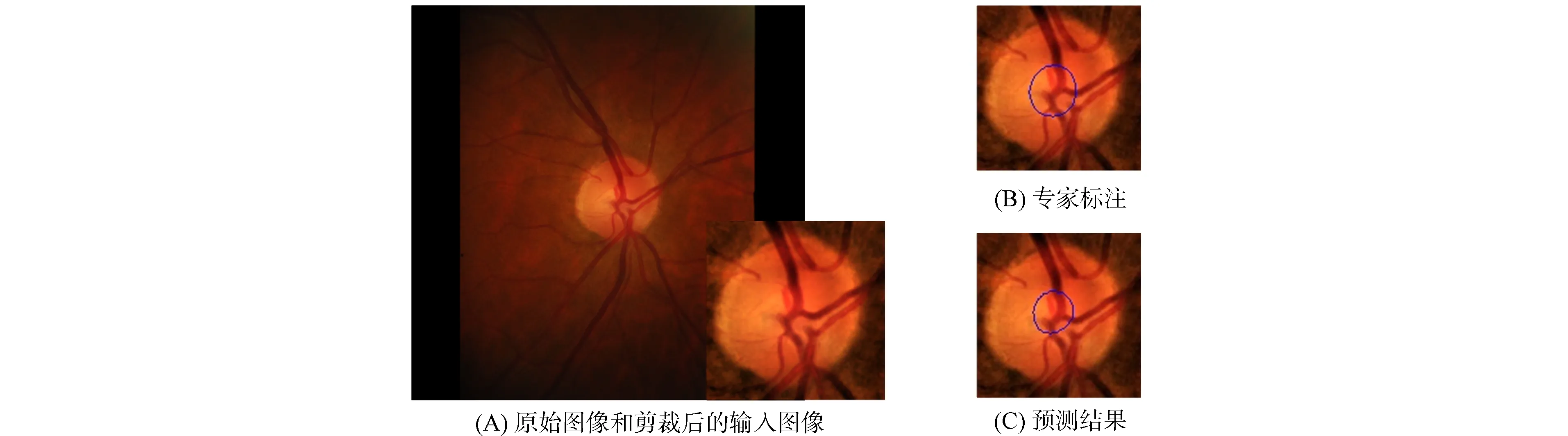
圖5 視杯分割示例Fig.5 Examples of OC segmentation
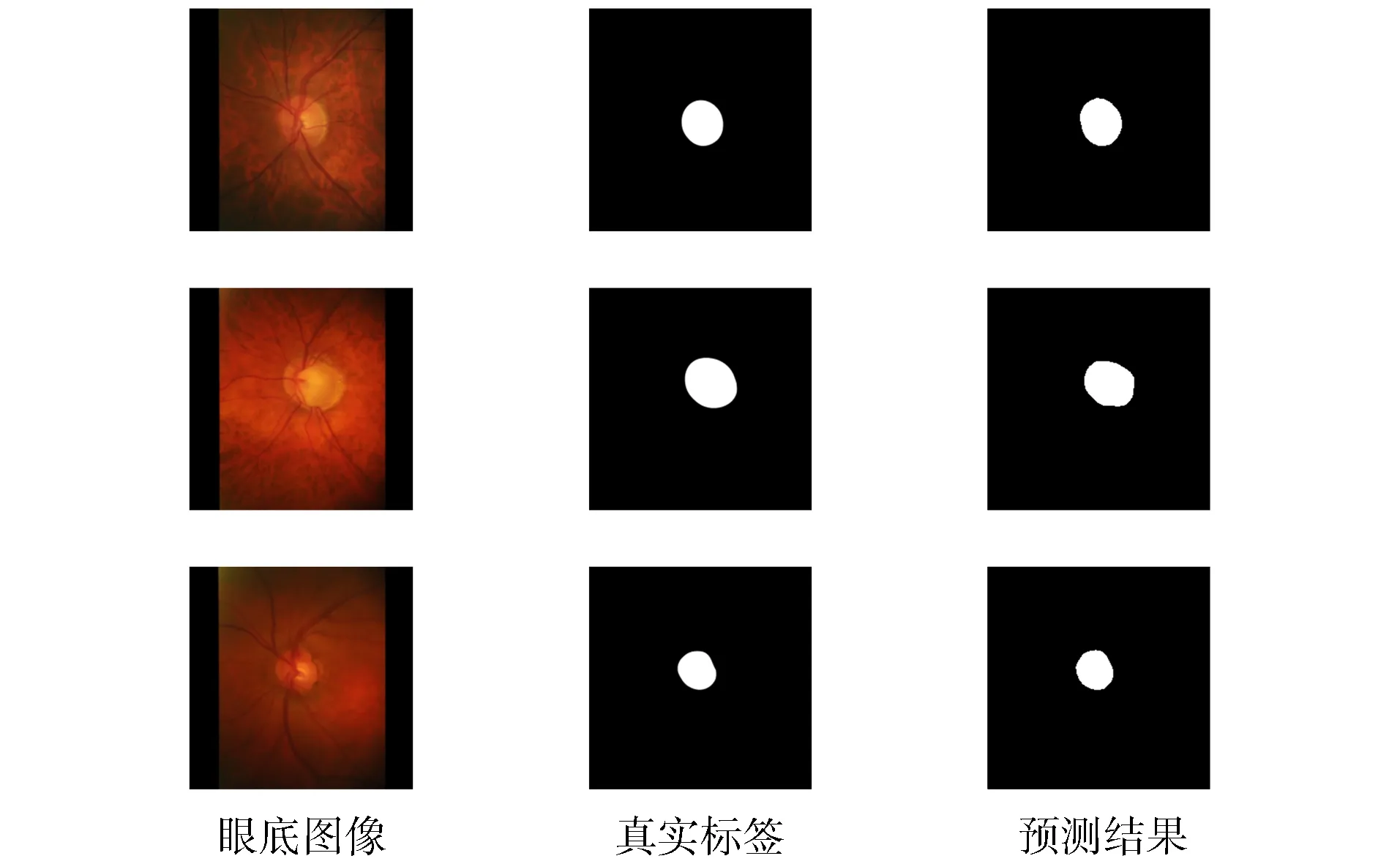
圖6 視盤分割在數據集RIM-ONE v.3上的結果Fig.6 Results of OD segmentation on RIM-ONE v.3 dataset
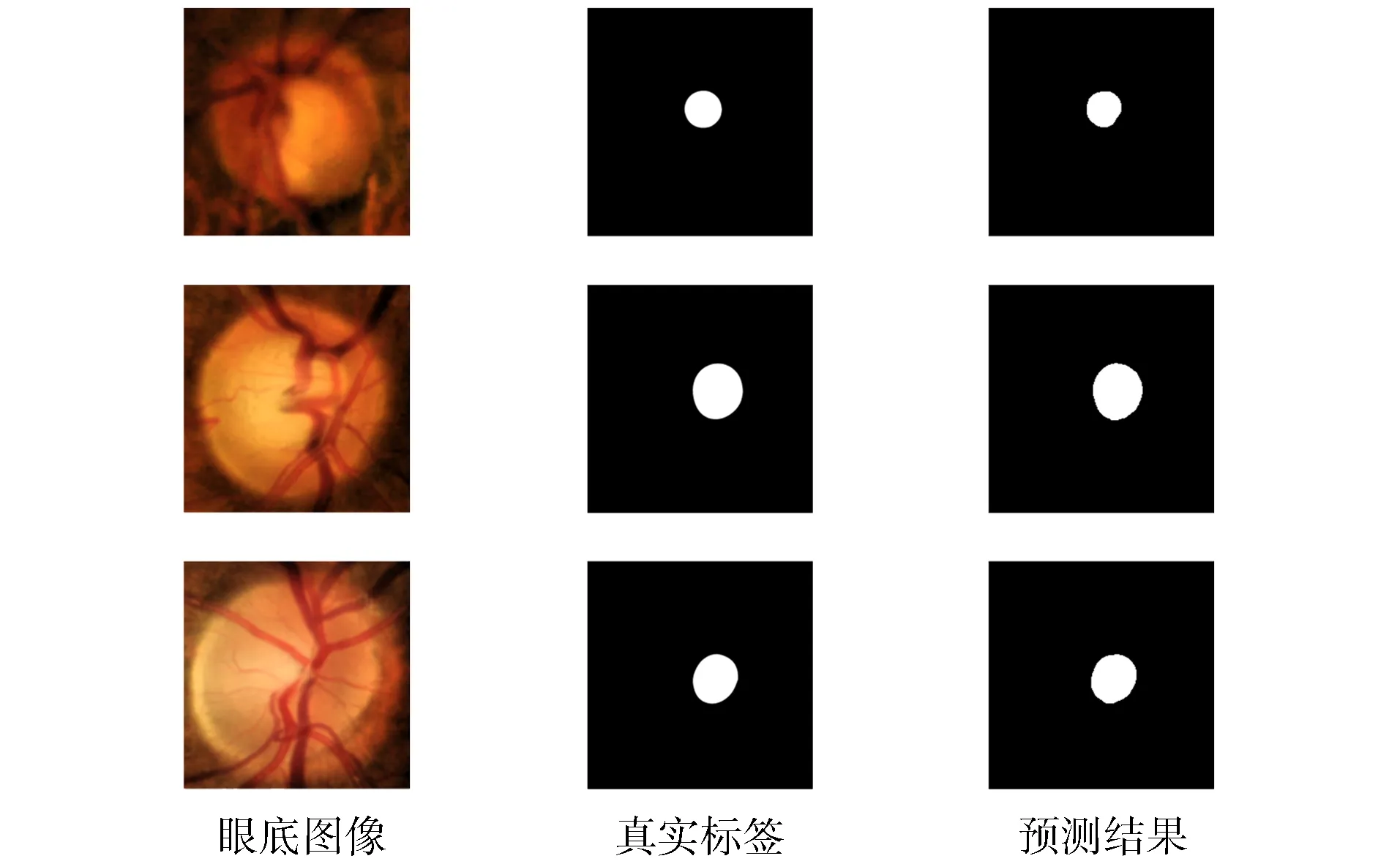
圖7 視杯分割在數據集RIM-ONE v.3上的結果Fig.7 Results of OC segmentation on RIM-ONE v.3 dataset
綜上所述, 本文以UNet-Light作為主干網絡, 通過在其中加入金字塔池化模塊, 降低病變等噪聲對視盤和視杯分割的干擾, 豐富多尺度特征, 有效提高了網絡特征的提取能力, 使網絡在分割時不受目標大小形狀變化的影響.針對視盤和視杯分割兩個任務, 在公開數據集RIM-ONE v.3上進行了多組對比實驗, 結果表明, 本文方法在兩個任務中的分割精度均優于原始網絡, 且在處理病變區域、視杯特征不明顯等分割困難區域, 比現有算法各項指標均有顯著提高.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
