基于代理模型進化的履帶車輛動力學參數優化
2023-02-27 13:18:56張發平張書暢武鍇張云賀閻艷
兵工學報 2023年1期
張發平,張書暢,武鍇,張云賀,閻艷
(1.北京理工大學 機械與車輛學院,北京 100081;2.北京電子工程總體研究所,北京 100085)
0 引言
坦克作為現代戰爭的主要路基武器載體,行進間射擊精度和行駛平順性是其重要的設計技術指標[1-3],這些指標要通過對坦克動力學模型的參數優化來保證。基于虛擬樣機技術的多體動力學建模仿真與參數優化是目前研究坦克等高機動履帶車輛動力學性能的重要方法[4]。在進行參數優化時,需要大量重復調用仿真模型以獲取響應計算目標值。然而由于該類車輛總體復雜,動力學仿真模型往往是高度密集計算、求解周期長、難以在有限計算資源內大量求解,成為制約參數優化效率和精度的瓶頸之一[5-6]。
使用代理模型技術構建設計變量和目標函數的近似響應面來提高優化效率,是現有研究的主流方向之一。如借助近似模型對履帶車輛多體動力學模型的參數進行修正來解決模型仿真與試驗結果的匹配問題[7-8],基于全局敏感性分析采用代理模型對復雜非線性機械系統進行參數優化[9]等。然而,這些方法需要大量采樣且優化精度不高,因此如何進一步提高效率和精度仍需研究。
基于代理模型的全局優化(SGO) 可以有效降低“昂貴模型”評估的次數,適用于包含高性能仿真模型的設計優化過程[10-11]。傳統的SGO 方法需大量增加樣本來降低代理模型的全局誤差,很容易產生維度災難問題。為了解決這一問題,近年來衍生出基于代理模型的全局抽樣優化(SGSO) 方法,在SGO方法的基礎上增加代理模型的靜態和動態采樣方法更新策略,在優化過程中選擇樣本點來更新代理模型。
更新抽樣方法采用基于預測最優解的發掘方法[12],將預測最優解作為新增樣本點,通過提高代理模型的精度,來有效避免優化收斂得到非最優解。基于設計空間填充的采樣策略,通過引入規則,將基于預測最優的發掘法和基于誤差的發掘法融合。方法包括由Jones[13]提出的基于改善概率的全局優化(PGO) 算法和Jones 等[14]提出的基于期望改善度的全局優化(EGO) 算法,以及期望改善度(EI) 方法[15]。這些方法雖有較強的全局探索能力,但局部發掘性能較差,當各設計變量維數較高時收斂速度會大幅降低。
另外一類提高效率和精度的研究是基于設計空間縮減的策略方法。主要包括信賴域(TR) 方法和分割平面(CP) 方法。TR 法[16]提出TR 縮放指標,在每次迭代中根據縮放指標的大小判斷設計空間是該收縮還是該擴張。Cheng 等[17]將TR 思想和模式采樣(MPS) 方法結合,顯著提高了MPS 的高維優化效率。TR 法求解局部最優解的效率較高,但在全局探索方面的能力稍顯薄弱。CP 法由Wang 等[18]提出,其思想是通過設計空間中的超平面分割響應面,保留代理模型預測值較小的部分,并在該區域使用DOE 方法采集新的樣本點,CP 的邊界由最優化方法確定。CP 法是單向設計空間縮減法,無法增大尋優子空間,因此很可能陷入局部最優。
針對以上問題,本文以坦克動力學模型參數優化為研究對象,提出一種基于代理模型進化的參數優化方法,旨在確保優化精度的前提下大幅減少仿真模型調用次數,提高優化效率。首先,進行坦克機械系統拓撲關系及約束分析,建立坦克行進間多體動力學仿真模型;其次,以垂向加權加速度均方根與俯仰角加速度均方根組合構建目標函數,并選出對目標函數較敏感的設計變量;隨后,提出基于代理模型進化的參數優化方法,在重點區域持續更新代理模型;最后,使用該方法進行模型參數優化,得到高精度代理模型和最佳參數組合。
1 坦克行進間多體動力學建模
1.1 坦克機械系統拓撲結構及約束建模
現代履帶坦克部件眾多,組成結構復雜,性能指標多。根據經驗,在此選擇影響性能的技術指標:車輛行駛的平順性為主要成分[19-20]。忽略動力和傳動系統,某型號坦克主要由上裝系統和底盤行動系統兩部分組成。上裝系統通過上、下座圈與底盤系統連接。所構建的被動懸掛坦克行進間多體動力學模型共包含619 個部件、660 個約束。部件和約束明細見表1 和表2。根據部件之間的連接關系以及部件之間的約束狀況,簡化后的坦克機械系統拓撲結構圖如圖1 所示。這些零部間的約束共包含普通接觸約束24 個,間隙碰撞接觸約束12 個,接觸摩擦184 個,剛度阻尼力矩18 個。其多體動力學模型的構建可通過理論方法描述約束力與狀態變量間的關系。具體可用多體動力學仿真軟件RecurDyn 進行建模仿真,通過添加直線彈簧阻尼器和扭轉彈簧阻尼器實現各約束,其中直線彈簧阻尼器和扭轉彈簧阻尼器的非線性剛度和阻尼特性數據設置為樣條曲線。
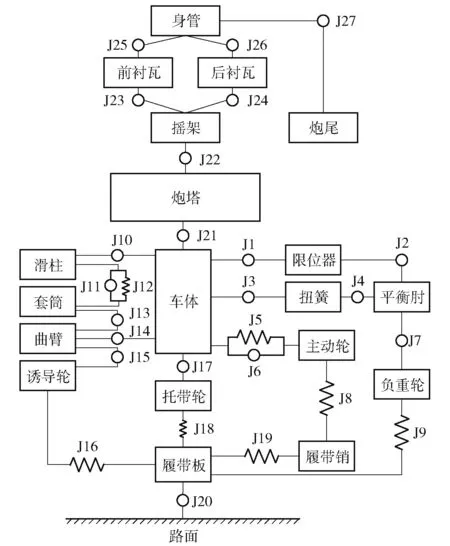
圖1 坦克多體動力學模型拓撲結構圖Fig.1 Topological structure of the multi-body dynamics model
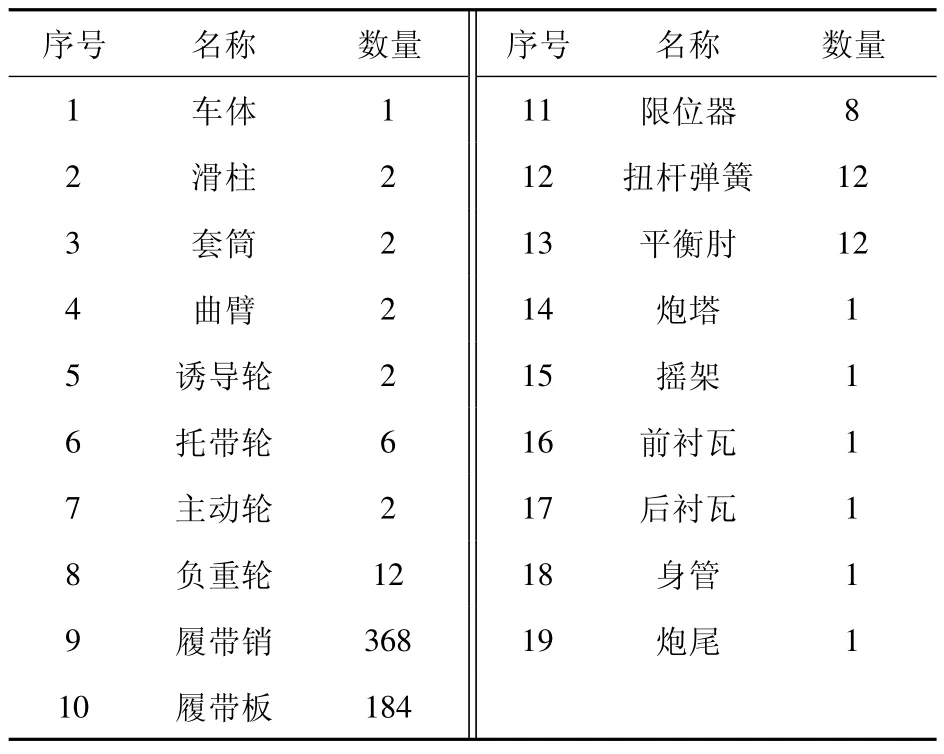
表1 坦克多體動力學模型部件明細Table 1 Details of tank multi-body dynamics model cemponents
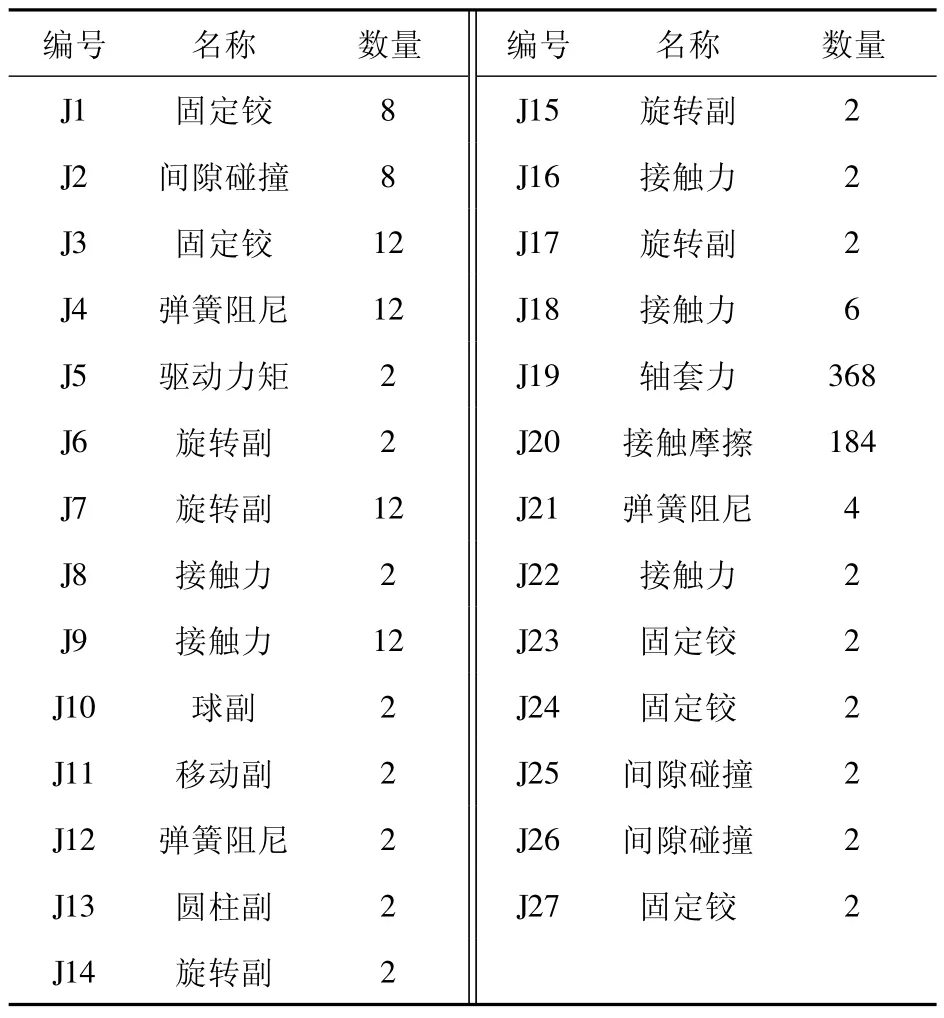
表2 坦克多體動力學模型約束明細Table 2 Constraint details of tank multi-body dynamics model
1.2 路面譜的三維不平度建模及包絡效應處理
1.2.1 路面譜的三維不平度建模
坦克等履帶車輛行駛過程中路面激勵影響車輛的性能。根據國家標準GB7031—1986 車輛振動輸入路面平度表示方法規定的路面不平度公式量化如下:
式中:Gq(n) 和Gq(n0) 分別為路面不平度功率譜密度和標準功率譜密度;n 為路面不平度空間頻率;n0為其對應的標準空間頻率;w 為路面功率譜密度的頻率指數。一般采用諧波疊加法[10]建立如下三級路譜。左右相干路面不平度表達式如下:
式中:ql(x) 和qr(x) 分別為左、右路面不平度表達式;ni為將空間頻率nmin<n <nmax平均劃分為N 個區間中第i 個區間的中心頻率;αl為[0,1]區間內的隨機數,表示左側相位系數;αr為右側相位系數,決定了左右兩側的相干性,其計算由相位角擬合,見文獻[21];d 為負重輪輪距;αn為[0,1]區間內的隨機數;Ai表示諧波振動幅值,
Gq(ni) 為功率譜密度,可以由國家標準GB7031 進行計算得到,Δn 為空間頻率間隔。
GB7031 根據功率譜密度將路面劃分為A~H 8 個等級,H 級的平度系數的幾何平均值最大,為262 144,代表等級中最嚴苛的路面。因此,本文建立D、F、H 三個等級路譜,分別代表不同路面不平度的等級進行仿真,如圖2 所示。
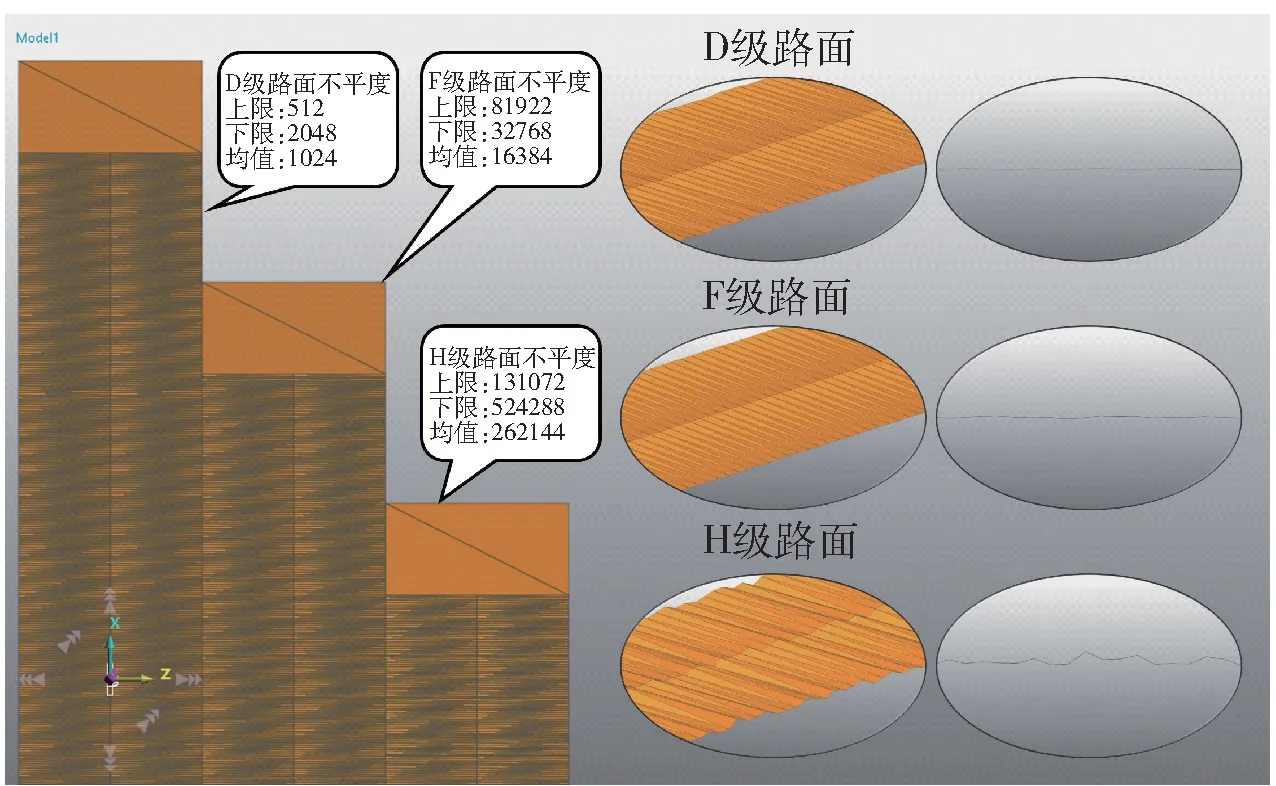
圖2 D、F、H 級路面左右相干三維不平度模型Fig.2 Left-right coherent three-dimensional roughness model of class D,F and H pavements
1.2.2 履帶板包絡效應的路面譜濾波建模
履帶裝甲車輛在路面行駛時,因履帶板對地面具有包絡效應,作用在負重輪上的高程激勵發生變化。可以將履帶對地面的濾波作用等效成1 階低通濾波器對路面譜的作用,標準形式為
式中:G(ω) 為濾波器幅頻特性,ω 為路面激勵頻率;G0為零頻增益;ωc為濾波器截止角頻率;G(n) 為履帶濾波函數;S0為靜態靈敏度;nc為空間截止頻率。履帶對地面的濾波函數與自身結構和車速有關。通過相應等級的路面不平度和對應車速下濾波函數對位移譜進行濾波,得到時域信號作為去履帶后的路面激勵輸入,對履帶車輛懸掛系統做動態特性分析。
1.3 坦克整車多體動力學仿真模型
基于機械系統部件拓撲關系及約束模型,采用多體動力學仿真軟件RecurDyn 建立坦克行進間多體動力學模型。所構建的整車RecurDyn 模型如圖3 所示。
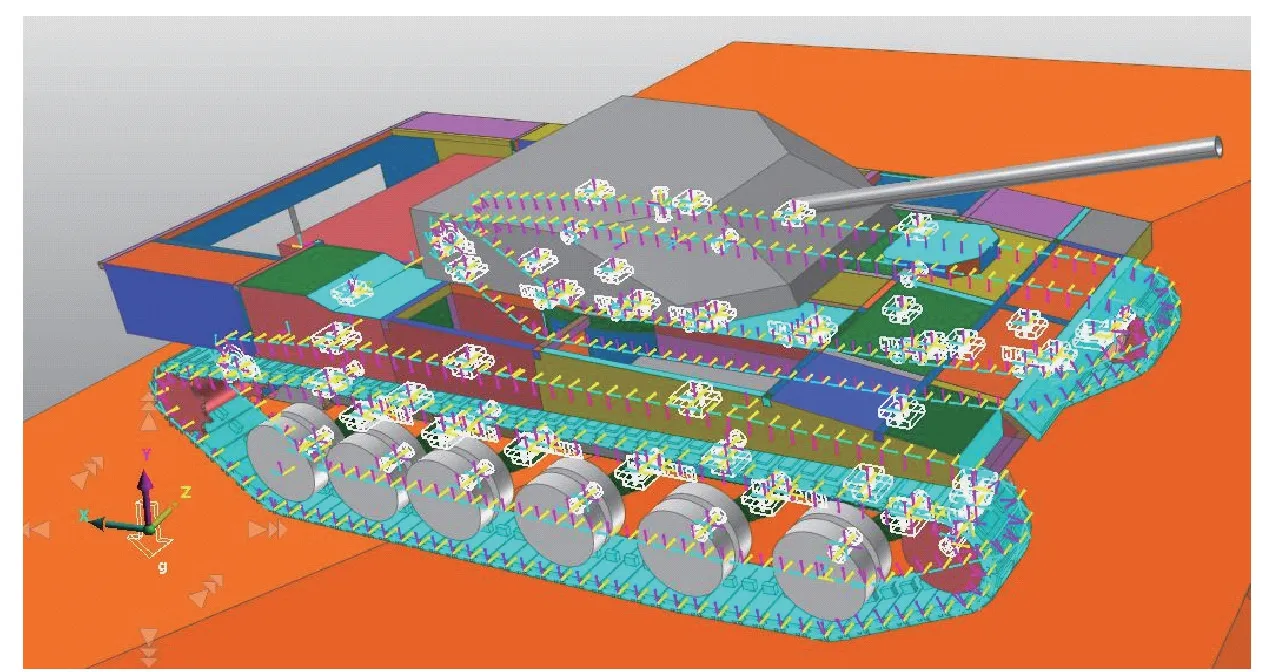
圖3 坦克整車多體動力學RecurDyn 模型Fig.3 Tank multi-body dynamics RecurDyn model
2 懸掛系統參數優化目標函數及變量確定
2.1 懸掛系統參數優化目標函數
坦克等履帶車輛行駛過程中,駕駛艙地板位置的垂向加速度和坦克車體的俯仰角加速度是重要的評價指標[20,22-23],因此將坦克在不同路面上行駛過程中車體駕駛艙位置的垂向加速度均方根aya和俯仰角加速度均方根值azw加權,作為車輛性能綜合指標,共同組成如下優化目標函數:
式中:wya和wzw分別為兩者的權重,用來平衡兩目標項的數量級。該目標函數沒有具體物理意義,只是保證兩者之和的最小化。目標函數的取值越小,車輛行進間的綜合性能越好。
垂向加速度均方根aya和俯仰角加速度均方根值azw的計算根據國際標準ISO 2631-1:1997 人體承受全身振動評價進行,此標準認為人體對0.5~80 Hz區間的不同頻率振動的敏感程度不同。因此采用加權加速度均方根值對舒適性進行量化,通過快速傅里葉變換(FFT) 將仿真得到的駕駛艙位置垂向加速度時域譜變換為功率譜
式中:Ga(f) 為垂向加速度頻率譜;aya(t) 為垂向加速度時域譜。在此基礎上,通過ISO2631-1 規定的0.5~80 Hz 區間頻率加權函數對頻譜加權,計算均方根值如下:
式中:F 為總頻率尺度;ω(f) 為頻率分段加權函數:
聯合式(7)~式(8),可以得到垂向加權加速度功率譜密度。
坦克車體的俯仰角加速度時域均方根值量化計算方法如下:
式中:azw(t) 為車體俯仰角加速度時域譜;T 為總時間歷程。
工程上這些參數均通過坦克車輛主動懸掛系統的設計參數或控制參數來控制,因此選擇懸掛系統參數作為優化變量來進行優化。
2.2 懸掛系統參數優化設計變量
坦克等履帶車輛的參數優化效率受設計變量的維度和設計空間的影響,高維度的設計變量和大尺寸的設計空間常常導致計算成本驟升。因此為了提高優化效率,根據車輛動力學相關理論,選擇6 個對目標函數敏感的懸掛系統參數作為設計變量來控制設計變量維度,分別為:左右兩側1、6 號扭桿彈簧剛度系數,左右兩側2、5 號扭桿彈簧剛度系數,左右兩側3、4 號扭桿彈簧剛度系數,左右兩側1、6 號扭桿彈簧阻尼系數,左右兩側2、5 號扭桿彈簧阻尼系數;左右兩側3、4 號扭桿彈簧阻尼系數。另一方面,通過基于代理模型進化的參數優化方法在參數優化過程種持續縮小設計空間尺寸,節約計算資源,提高優化效率。6 個設計變量的位置示意圖如圖4 所示。圖4 中,a1~a6分別為相應車輪間的水平距離,mb為車體質量,zb為車體的垂向位移,zw1~zw6分別為相應車輪相的垂向位移,zt1~zt6分別為相應車輪位置處路面的激勵位移。
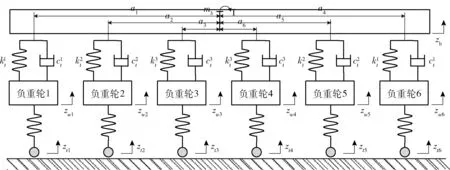
圖4 優化變量位置示意圖Fig.4 Schematic diagram of optimized variable location
王欽龍等[8]在履帶車輛模型修正工作中通過極差法確定了對目標函數較敏感的設計變量分別是車體俯仰轉動慣量Izz、懸掛系統剛度k 和懸掛系統阻尼c。車體轉動慣量Izz受整車各部件質量、質心等多因素影響,不具備優化價值。
2.3 懸掛系統參數優化聯合仿真過程
基于代理模型進化優化算法的履帶車輛參數優化過程由算法程序、控制程序和坦克行進間多體動力學模型聯合仿真環節所組成。其中,算法程序為采用MATLAB 軟件自研的代理模型進化優化算法,控制程序依托Simulink 由RecurDyn 聯合仿真模塊和其他基礎組件構成,實現坦克行進間多體動力學模型的參數傳入和響應采集功能,以動力學仿真軟件RecurDyn 為基礎平臺,根據第1 節提供的機械系統拓撲及約束信息實現坦克行進間多體動力學模型建模,以及3 種三維路面譜建模和行進動力學仿真。具體結構如圖5 所示。
3 初始代理模型構建
坦克行進間多體動力學仿真模型部件及約束眾多,單次仿真求解效率極低(本文仿真配置計算機下一次仿真約20 min) 。為解決該問題,本節將構建初始代理模型表征設計參數和目標函數之間的響應關系,為基于代理模型進化的參數優化方法確定優化搜索方向。
初始訓練樣本集的空間均布性決定了初始代理模型能否有效地表征設計變量和目標值在整個設計空間的響應面關系。針對2.2 節給出的坦克優化設計變量及對應的可行空間,使用基于隨機進化算法的最優拉丁立方(ESEA-OLHD) 法進行試驗設計,獲得6D(D 為設計變量維度) 個樣本,通過2.3 節聯合仿真計算得到響應,生成初始訓練集。使用擴展徑向基函數(RBF) 代理模型[24]構建6 維設計變量與目標之間的初始響應面。擴展RBF 代理模型詳細過程見文獻[11]。
在D、F、H 三個等級路面條件下,ESEA-OLHD試驗設計法采樣獲得訓練樣本集,據此構建三級路面6 維設計變量和目標函數間的初始代理模型,如圖6 所示為以圖形方式表示的初始代理模型,因篇幅原因只列出D 級路面。圖6 中,K1為設計變量中的剛度,C1為設計變量中的阻尼。初始代理模型將在優化過程中持續更新,不斷提高擬合精度。
4 基于代理模型進化的參數優化方法
為了解決傳統工程設計優化問題大量調用仿真模型導致的優化效率低問題,本文提出設計空間的三層分解方案、基于代理模型進化的參數優化方法,以及在可能最優解的重點區域的代理模型動態更新,從而提高優化精度,降低樣本使用量。
4.1 多層設計空間縮減策略
在工程設計優化初始階段,設計變量范圍設定往往較大,以便能覆蓋所有可能的設計結果,但帶來的后果是大設計范圍導致空間搜索成本過高。本節將設計變量所構成的空間劃分為三層空間,分別為初始設計空間(OA)、局部過渡子空間(MA) 和重要子空間(IA) 。各子空間關系示意圖如圖7 所示。
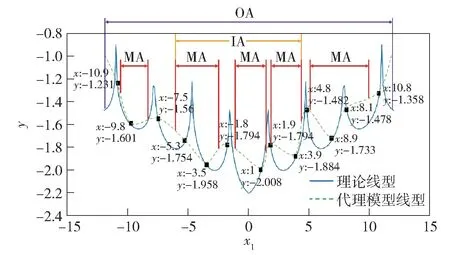
圖7 某次迭代過程中三層子空間示意圖Fig.7 Schematic diagram of three-layer subspaces in an iterative process
4.1.1 初始設計空間(OA)
OA 是優化變量的初始范圍,也是首次迭代的基準空間,覆蓋變量所有可能取值。在OA 空間中通過極值法和高斯誤差法的動態采樣策略,可以改善代理模型在整個初始設計空間的精度,通過基于ADAM 梯度下降的局部尋優法和松弛判別式尋找可能被遺漏的極小值,為算法提供跳出局部最優解的能力。
4.1.2 局部過渡子空間(MA)
MA 是過渡子空間,可由圖8 所示的二次聚類法把OA 劃分為多個子MA 空間。每一個MA 空間包含優化問題的一個或多個局部極小值。在各MA空間中,采用ADAM 梯度下降法尋找MA 空間中的局部極小值并更新代理模型,確定本次迭代的預測最優解。
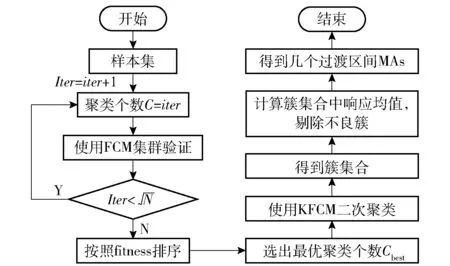
圖8 基于二次聚類確定過渡區間流程圖Fig.8 Flow chart of determining transition intervals based on quadratic clustering
使用確定MA 子空間的步驟如下:
1) 首次聚類種群驗證。通過基準空間樣本點數量確定聚類數量區間,以區間中的每一個取值為先驗值,執行模糊C 均值(FCM) 聚類,計算每一次聚類結果的評價指標,衡量聚類種群的有效性。將評價指標最優的聚類數量值作為最佳聚類數量,并保存最佳聚類中心坐標。
2) 二次聚類劃分種群。以最佳聚類數量和最佳聚類中心坐標為先驗條件,對樣本集進行基于核函數的模糊C 均值(KFCM) 聚類,得到cbest個簇,每個簇都包含局部極小值。選擇平均響應較低的前50%(根據經驗取值) 簇作為各MA 子空間,根據各簇包含樣本各維坐標的最大、最小值確定子空間范圍。文獻[25 -26]提供了FCM 和KFCM 的詳細執行過程。
4.1.3 重要子空間(IA)
IA 是最可能包含全局最優解的區域,是設計空間的進一步收縮。通過ADAM 梯度下降法在IA 子空間中開展優化搜索工作,使用基于極值法和高斯誤差聯合采樣策略在IA 子空間中重點采樣,在可能存在全局最優解的鄰域深入探索并持續精化代理模型。確定IA 的具體操作步驟如下:
1) 通過二次聚類法確定若干過渡空間MA;
2) 對所有MA 空間中的局部最小值排序,得到最佳預測值作為IA 子空間的中心;
3) 以IA 空間隸屬的MA 子空間邊界和最佳預測值的各維度坐標為依據,計算IA 子空間各維度邊界。MA 數量大于1 或等于1 兩種情況下IA 區間邊界IA_range 的計算方法如下:
式中:prebest為當前最優預測值所在點的各維度坐標向量;MAurapnge和MAlroawnge分別為MA 空間各維度上界和下界;size(MA) 為MA 空間的數量。通過在IA 子空間中進行多種形式,更多數量的采樣,提高代理模型在該區域的精度,進而促進全局最優解的捕獲,且IA 區間的范圍相對于MA 區間得到了進一步縮減。多層空間縮減的算法偽代碼見附錄1。
4) 根據搜索效率和精度的綜合考慮,每3 次迭代后進行IA 空間確定,防止過早收斂。
4.2 多起點局部尋優及代理模型動態更新
4.2.1 基于ADAM 梯度下降法的局部尋優
優化迭代過程中,需要在MA 和IA 子空間進行局部尋優,獲得局部極小值、確定新增樣本點,更新代理模型。使用用于深度學習的ADAM 梯度下降法[27],從多個起點進行搜索來捕獲空間中的多個局部極小值。
在MA 空間和IA 空間執行基于ADAM 的局部尋優算法,流程見附錄2。需將尋優搜索限制在MA或IA 空間范圍中,在搜索過程中接近上下邊界的變量維度將停留在邊界,其他維度依然保持向負梯度方向搜索,直至到達預設最大迭代次數stepnum或滿足收斂條件‖deltaX‖2<ε,ε 為一個足夠小的值,一般取ε×10-8。
4.2.2 基于動態采樣策略的代理模型更新
新增樣本點是優化迭代進程中代理模型更新的重要來源,本節提出基于極值法和高斯誤差法聯合的動態采樣策略。
4.2.2.1 基于極值法的新增樣本點
該方法將獲得子空間中可能是全局最優點的候選點,執行步驟如下:
步驟1確定各空間(如MA) 包含的觀測樣本點集以及邊界。
步驟2在空間邊界內從多起點進行ADAM 梯度下降搜索,得到各子空間內所有局部極小值,將其按預測響應從小到大排序后取各子空間前p 個局部極小值,p 的取值如下:
式中:s 為本次迭代生成的子空間數量。需要說明的是,p 和s 的取值是考慮到效率精度的平衡。
步驟3剔除新增樣本點集中的兩類冗余:1) 從多起始點搜索得到的局部極小值可能收斂到同一位置;2) 得到的新增樣本點可能與原有樣本集中的點重合。對此,計算新增樣本點集中各點歐式距離,剔除距離相近的新增樣本點;逐一計算新增樣本集和原始觀測樣本集的歐氏距離,剔除冗余點。歐式距離評價公式如下:
式中:x1、x2為兩個樣本點;‖*‖2為向量L2 范數;LHSrange(1,:) 和LHSrange(2,:) 分別為初始設計空間各維度的上界和下界。
4.2.2.2 基于高斯誤差法加點
該方法將獲得該次迭代關注區域內代理模型誤差較大位置的樣本點。高斯誤差的計算包含三部分:1) 利用空間(如IA) 樣本集訓練該區域的高斯過程回歸模型(GRF),得出IA 空間各處高斯過程預測值IA_GRF_pre 和方差σ;2) 計算IA 子空間各處GRF 和RBF 預測響應偏差Δpre=|IA_GRF_pre-IA_RBF_pre|;3) 分別將高斯過程方差和預測響應偏差進行標準化:
式中:σnor為標準化方差;Δprenor為預測響應偏差。以上兩個參數加權,得到總誤差值SE=0.2Δprenor+0.8σnor,選擇總誤差值最小的3 個點作為新增樣本集。
高斯過程方差和高斯過程回歸模型的理論內容見文獻[28]。優化迭代中動態采樣策略在MA 和IA 子空間采樣流程見附錄1 的多層空間縮減策略算法和附錄2 的基于ADAM 梯度下降的局部尋優法算法。
4.3 基于動態采樣的局部最優解跳出
在滿足判別標準下在OA 空間中使用動態采樣法更新代理模型避免算法陷入局部最優解,偽代碼如附錄3,分為以下4 個步驟:
步驟1執行判斷:若某次迭代新增樣本點為0或觀測最優值連續3 次迭代中沒有發生變化,則判定當前迭代過程是否陷入局部最優。
步驟2執行動態采樣:在OA 中執行高斯誤差采樣和極值采樣,得到預測響應誤差較大和局部最優位置的新增樣本點。
步驟3更新基準空間:若OA 中最小的局部極小值OAbest與當前全局最優解prebest(iter) (iter 為迭代次數) 滿足松弛判別式(11),則更新全局最優解,合并基準空間OAbest的坐標作為下次迭代基準空間邊界。
4.4 優化流程
基于代理模型進化的參數優化方法流程如圖9所示。流程包含4 個部分:1) 循環迭代前,初始化參數并訓練初始代理模型;2) 進入迭代后,使用多層空間縮減策略確定三類子空間,并從三類子空間中交替局部尋優并獲取新增樣本點;3) 執行跳出局部最優解的措施,確定新增樣本集;4) 更新基準空間和代理模型,計算目標值并判斷是否終止。
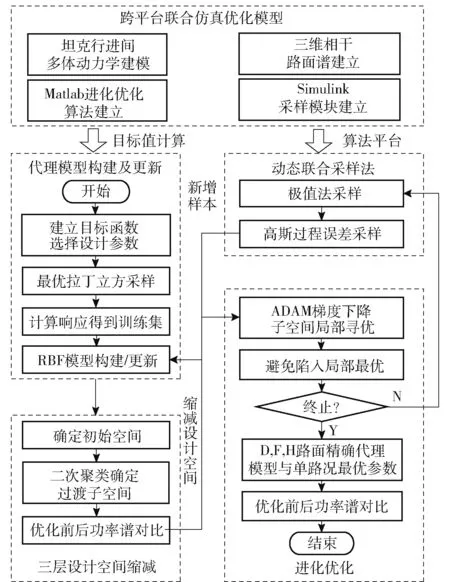
圖9 坦克參數優化總體技術流程Fig.9 Overall technical process of tank parameter optimization
5 基于進化優化算法的懸掛系統參數優化
5.1 坦克懸掛系統設計參數優化過程
分別針對D 級、F 級和H 級3 種道路環境進行基于代理模型進化的參數優化,以盡可能少的樣本得到單路面情況下的最佳設計變量組合以及單路面情況下設計變量和目標值的高精度響應面。其中,D 級路面優化問題的數學表達式如下:
在本文優化問題中,多層設計空間縮減策略、基于代理模型進化的參數優化方法各子方法參數以及RecurDyn 行進間多體模型仿真參數設置如表1 所示。

表1 優化過程中算法及仿真模型參數設置Table 1 Algorithm and simulation model parameter setting
5.2 3 種路面條件的優化結果分析
圖10 為D 級路面10 次優化中最小全局最優解的收斂曲線。由圖10 可知,每3 次迭代目標值有較大幅度下降,第8~13 次迭代中陷入局部最優,算法采取相應策略跳出局部最優,于14 次迭代中得到更小的目標值。表2 所示為10 次優化中坦克在D 級、F 級和H 級路面下優化前后懸掛系統參數優化的目標值,變化率分別為[27.2%,34.8%]、[23.3%,26.6%]、[19.6%,21.3%],樣本使用量分別為[91,108]、[91,110]、[93,109]。表3 為優化前后的參數值。表2 表明,該方法的優化參數可使得3 種路面下行進間車輛性能綜合指標平均提升分別為32.4%、24.5%和20.4%,且可綜合將傳統方法平均樣本使用量的約500~1 000 次降低到80~150 次,在同等算力下節省時間100 h 以上(以本文所用計算機配置單次仿真周期20 min 計算) 。
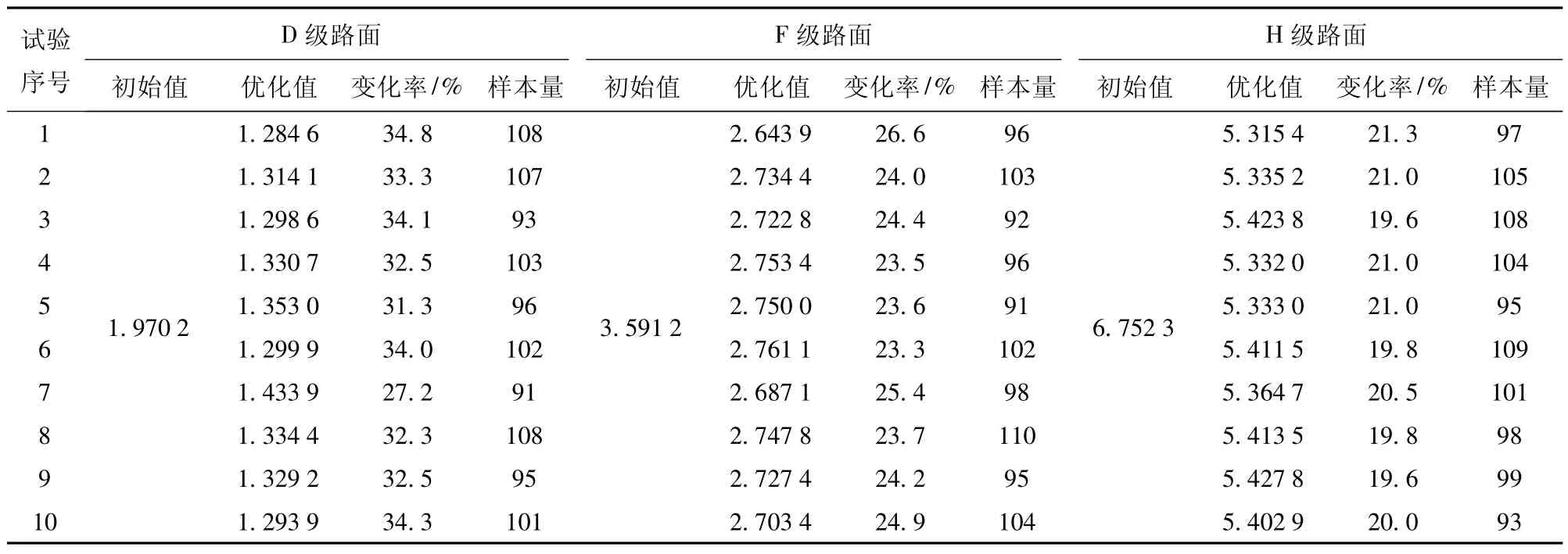
表2 基于代理模型進化優化算法的10 次單路面優化(懸掛系統參數優化目標函數值)Table 2 10 times single road optimization based on agent model evolutionary optimization algorithm(objective function value of suspension parameter optimization)

表3 3 種路面下的最優參數組合Table 3 Optimal parameter combination for each grade of pavement
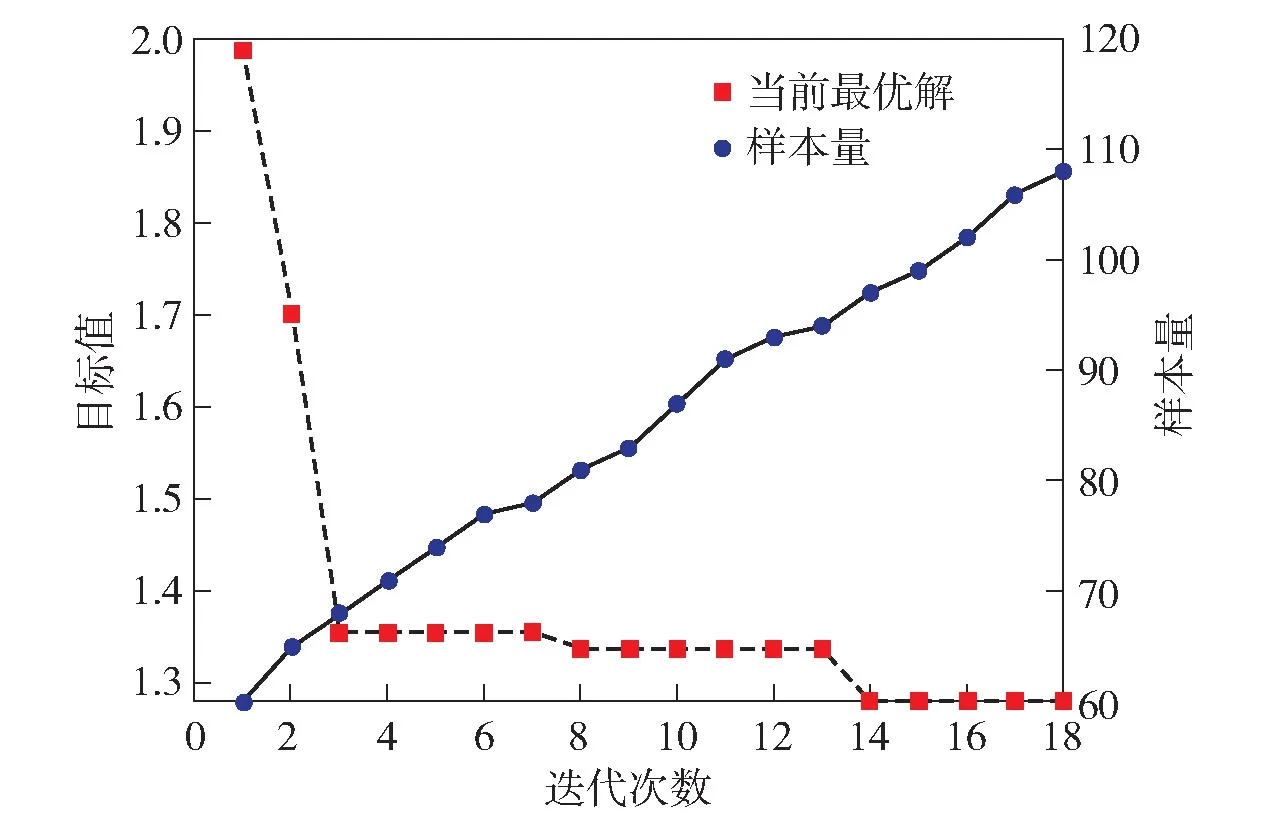
圖10 D 級路面譜優化收斂曲線Fig.10 Convergence curve of spectrum optimization of grade D pavement
使用H 級路面下的最優參數組合和初始參數組合進行仿真,得到坦克行進間加速度功率譜對比曲線如圖11 所示,從中可以看出優化后0~50 Hz振動頻率區間內功率譜密度均值和極值都有了顯著降低。
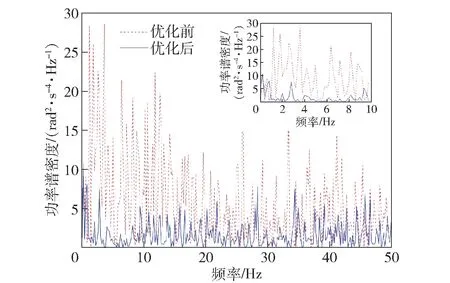
圖11 H 級路面下優化前后功率譜密度對比Fig.11 Comparison of power spectral densities before and after optimization for H grades of pavement
6 結論
本文以履帶車輛多體動力學模型參數優化為研究對象,提出了基于代理模型進化算法的參數優化方法,以提高復雜多體動力學系統優化的效率,并用懸掛系統的參數優化進行了驗證。得出主要結論如下:
1) 提出了復雜結構履帶車輛動力學參數優化的代理模型進化優化方法,可實現異構模型間信息無縫傳遞,以及代理模型進化和參數優化的有效融合,提高了參數優化的精度和優化過程的效率。
2) 在3 種路面下對坦克動力學數值仿真的結果表明,本文提出的基于代理模型進化的參數優化方法與傳統優化方法相比,優化精度提高21.3%,降低樣本使用量31.5%。同時,該方法的優化參數可使得3 種路面下行進間車輛性能綜合指標平均提升分別為32.4%、24.5%和20.4%。
3) 本文優化方法本質上是一種單目標優化法,在求解多目標優化問題時,需要通過權重分配系數建出單目標代理模型后再求解。下一步研究中將引入多目標概率期望改善等方法,使算法具有本質多目標優化能力,并結合具體的工程實際驗證。
附錄1
多層空間縮減策略算法
Begin
初始化:初始采樣個數m 和維度D,其中樣本個數m 推薦的數量為二維問題[20,40],當維度2 <n <10 時,推薦采樣數量為[6n,8n];n >10 時推薦[50,70];RBF 代理模型及訓練迭代次數為80,初始各個維度可行設計空間為LHSrange;
得到昂貴初始樣本集:
Xolh 優化拉丁超立方采樣在LHSrange 中得到樣本點矩陣mxD
Yexp 通過復雜模型計算初始樣本集Xolh 的目標值,即響應值,矩陣大小為m×1
Sexp 將初始樣本點坐標和其對應的響應值合并為初始昂貴樣本集矩陣,大小為m×(D+1)劃分訓練集和測試集:
Sexp_train 和Sexp_test 通過留一交叉驗證法將初始昂貴樣本集劃分為訓練集和驗證集,用來更高精度地訓練代理模型
訓練代理模型:
RBF(Sexp_train,Sexp_test) 訓練RBF 神經網絡作為代理模型,并通過交叉驗證提高代理模型精度
save NET_RBF_iter1.mat-mat net 保存該次迭代過程中訓練好的代理模型
End
空間縮減:
Input: Sexp,NET_RBF_iter1.mat,iter
初始化: FCM 和KFCM 最大迭代次數為100,終止條件為1 ×10-5,KFCM 使用高斯核函數,參數sigma 設置為150;
MA——首先進行二次聚類,劃分種群過后進行一定篩選工作,得到s 個MA
Two-stage clustering:
Cbest——最佳聚類個數
Para_miu_best——種群驗證后得到的與最佳聚類個數對應的聚類中心
Label_KFCM——得到種群劃分矩陣,存儲類表標識,數據點坐標以及觀測響應
The determination of MA——將二階段聚類得到的種群通過響應值的大小進行排序,根據最小響應值從小到大的順序將所有種群排序,取前20%的s 個種群作為s 個過渡區間。如果種群數量小于5,則只選出1 個種群作為MA。
MA_plt——得到每個過渡區間包含的樣本點
MA_range——得到每個過渡區間對應的可行空間范圍
IA——在確定MA 的基礎上,通過分層尋優法判斷哪個空間是IA 空間
The determination of MA——確定s 個過渡區間以及響應的樣本點和空間范圍
分層尋優法——通過分層尋優法尋找局部極小值
Local_min_MA——得到每個過渡區間內的局部極小值
The determination of IA
IA_plt——得到重要空間包含的所有樣本點
IA_best——得到重要空間的最佳預測值
ImpAre_range——得到重要空間的區間范圍
Output: MA_plt and MA_range/IA_plt,IA_best and ImpAre_range
End
附錄2
基于ADAM 梯度下降的局部尋優法算法
初始化:學習率,最大迭代步長,初始參數,衰減速率
Input:
MA_plt and MA_range/ IA_plt and ImpAre_range——MA
空間或IA 空間包含的樣本點以及對應的空間范圍,假設某一空間中包含樣本點S 個
NET_RBF_iter.mat——本次迭代訓練的RBF 模型
Whileiter_opt <step_num——設置最大循環次數為step_num
grad——計算數值梯度
Square gradient——累積平方梯度
更新參數
deltaX=-grad* 學習率——計算該次迭代的樣本點各維坐標增量
Xiter_opt+1=xiter_opt +deltaX() ——更新尋優樣本點的坐標
If ‖deltaX‖2<1 ×10-8——所有維度增量都小于1 -e8,終止循環
Break;
End if
End while
Output: Local_min——得到大小為S×(D+1) 的局部極小值矩陣
End
附錄3
優化流程及跳出局部最優策略算法總體迭代流程
While iter <itermax——進入循環體,itermax 為最大迭代次數
Iter=Iter++——迭代次數+1
If mod (iter,3)==0——如果當前迭代次數iter 是3 的整數倍
IA_plt,IA_best,BS_range——執行多層空間縮減算法,得到重要空間IA,下次迭代基準空間以及包含的觀測樣本點
Sample_best——執行基于極值的加點方法,得到包含可能全局最優點的新增樣本點
Sample_gua——執行高斯誤差加點,得到IA 空間誤差較大區域的新增樣本點
Sample_new——合并Sample_best 和Sample_gua 后,執行樣本點篩選方法,剔除內外部距離過近的樣本,得到最終新增樣本集
Else
MA_plt,BS_range——執行多層空間縮減算法,得到過渡空間MA
Sample_best——執行基于極值的加點方法
Sample_new——執行樣本點篩選方法
判斷并執行未知區域探索部分
If iter >5——5 次迭代后,計算當前最優預測值和前5 次最優預測值的差CRT
CRT=Pre_best(iter) -Pre_best(iter-5)
Else
CRT=1 ×1010
End if
If size(Sample_new)=0 or CRT <1 ×10-6——如果本次迭代過生成新增樣本點個數為0 或CRT 小于閾值
執行稀疏采樣方法在OA 中采樣
Sample_OA——OA 空間中執行高斯誤差采樣,生成新增樣本點
OA_best——OA 空間中部分觀測點為起始點使用尋優方法確定OA 最優預測值
Sample_new=[Sample_new;Sample_OA]——合并新增樣本點
If OA_best-pre_best(iter) <pre_best(iter)/pre_best(1)
Pre_best(iter)=OA_best——更新最優預測值
BS_range——擴大并更新下次迭代基準空間
Sample_new=[Sample_new;Sample_OA;OA_best]——合并新增樣本點
End if
End if
Sample_new_rdc——對新增樣本點集執行去冗余操作,生成無冗余樣本矩陣
Ysample_new——使用復雜模型計算新增樣本點的觀測值
Sexp——[Sexp;[Sample_new_rdc,Ysample_new]]將新增樣本坐標和響應合并到整體樣本集中
NET_RBF_iter+1.mat 更新RBF 代理模型
End While
Out put:pre_best,RBF——最終輸出最優解以及最終RBF 代理模型
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
