改進網絡模型的局部骨切片圖像重構
2023-02-15 08:38:04陳繼剛王曉康康永興關亞彬董學剛張子路
電子科技大學學報 2023年1期
陳繼剛,王曉康,康永興,關亞彬,董學剛,張子路
(1. 燕山大學機械工程學院 河北 秦皇島 066004;2. 東北大學機械工程與自動化學院 沈陽 110819)
骨組織是人體重要的組織之一,屬于獨特的多孔結構[1]。在骨組織工程領域,三維骨多孔結構的數字建模是諸多研究的基礎技術[2]。當前,對于具有仿生特征的三維骨多孔結構數字模型,大多還是利用骨切片圖像(以下稱:切片圖像)進行三維重構得到的。
文獻[3-8]提出兩點相關函數法[3]、分形蒙特卡洛法[4]、多點統計法[5]、基于深度學習的方法[6-8]等切片圖像訓練方法,同時基于切片圖像(包括重構生成的圖像)建模得到滿意的三維骨多孔結構數字模型。由于成像設備精度、存儲設備容量等原因,切片圖像在獲取過程中會出現數據丟失、圖像受損或圖像尺寸異常等問題,導致只能得到具有局部特征信息的圖像[9]。另外,雖然計算機斷層掃描技術[10]和掃描電子顯微鏡[11]等成像技術取得了進步,但在實際情況下,獲取大區域、完整的切片圖像還是比較困難的[12]。本文把受損的切片圖像以及小尺寸切片圖像稱為局部骨切片圖像(以下稱:局部切片圖像),即只包含局部骨多孔特征的切片圖像。由于局部切片圖像中的數據是不完整的,所以其無法在統計意義和實際意義上表達三維結構的主要特征。因此,為了得到準確的三維骨多孔結構數字模型,對局部切片圖像進行修復并重構,得到完整且相似的圖像是很關鍵的。
近年來,研究人員對局部切片圖像的修復重構進行了深入研究,其中主要有以下3 種方法:逐像素法[13]、逐區塊法[14]和基于深度學習的方法。逐像素法是基于fast marching method (FMM)的修復算法,逐區塊法則是基于exemplar-based inpainting的算法,這兩種方法都是通過統計單張局部圖像的像素特征來推測全局信息,其重構修復得到的完整圖像與真實切片圖像不具有很好的相似性。而基于深度學習的方法可以利用局部圖像的局部特征,生成與真實切片圖像特征相似的完整圖像,有著更好的重構效果,如文獻[7]應用了條件生成對抗網絡實現了對多種局部多孔圖像的重構,并運用統計相關函數證明了生成圖像的合理性。
本文在條件生成對抗網絡(pix2pix)[15]的基礎上,對生成器進行改進,加入嵌套殘差密集塊(residual-in-residual dense block, RRDB)[16],同 時,在判別器中加入極化自注意力模塊(polarized selfattention, PSA)[17],提出改進條件生成對抗網絡(RRDB-PSA-pix2pix)對局部切片圖像進行完整重構,并通過性能相似性與優異性分析,驗證了重構生成的圖像與真實骨多孔圖像的相似程度。
1 網絡原理與改進方法
1.1 條件生成對抗網絡概述
條件生成對抗網絡(conditional generative adversarial networks, cGAN)是生成對抗網絡[18](generative adversarial network, GAN)的擴展。
cGAN 主要由兩部分構成:一個是生成器(generator network),用來生成數據;另一個是判別器(discriminator network),用來分辨原始數據和生成數據的真偽。生成器和判別器相互訓練對抗,從而使生成的數據越來越接近真實數據。另外,由于cGAN 的生成器輸入的是隨機噪聲和約束條件,因此,判別器需要加上約束條件一起辨別。
近年來,適用于cGAN 的約束條件越來越多,因此誕生出許多cGAN 的變體[19-21],這使得cGAN的應用越來越廣泛。
1.2 改進條件生成對抗網絡
pix2pix 是cGAN 的變體之一,它可以進行圖像對圖像的風格變換,由于該網絡有強大的變現能力,使其在圖像修復中得到了廣泛應用。pix2pix的生成器是跳躍連接形成的U 型結構,維度從高到低又從低到高,且左右兩邊對應維度通道相拼接。跳躍連接可以有效保留輸入數據的潛在信息,因此,對于局部切片圖像的局部特征信息,可以得到很好的保留和傳遞,這有利于局部切片圖像的完整重構。
為了更好地獲得圖像中的細節,網絡需要搭建到一定的深度才能重構出優質的圖像。然而,一味地增加網絡的深度會造成深度模型退化,這樣的網絡是很難訓練的。本文在pix2pix 網絡的生成器上加入嵌套殘差密集塊RRDB 來減弱網絡模型的退化,RRDB 的殘差塊里有殘差組合的密集塊,因此其擁有殘差塊[22]和密集塊[23]各自的優勢。
另外,極化自注意力(PSA)模塊是能耗盡通道注意力和空間注意力表現能力的自注意力模塊,將其應用到網絡中,可以幫助提高網絡的辨別能力,因此,本文把PSA 模塊加入到pix2pix 網絡的判別器中。
最后,將網絡中的各個模塊進行搭建和調試,得到了改進條件生成對抗網絡(RRDB-PSA-pix2pix)。圖1 為該網絡的生成器和判別器的架構,其中一個方塊代表一個網絡塊,塊中傳遞順序從左往右,一個字母表示一個網絡層,如C 為卷積層,L 為LeakyReLU 激活函數層,R 為RRDB 模塊層,B為批歸一化層,U 為上采樣層,D 為Dropout 層,Re 為ReLU 激活函數層,T 為Tanh 激活函數層,P 為PSA 注意力層,F 為Flatten 層。
如圖1a 所示,生成器的左半邊(編碼作用)的主線輸出為out1,跳躍連接上輸出的是out2。生成器的右半邊(解碼作用)整合局部圖像信息和左半邊傳遞過來的out2 信息,其RRDB 不輸出out2,只輸出out1。另外,RRDB 中的殘差尺度參數在密集模塊的支線上,這會阻礙密集模塊數據的傳遞,并使局部切片圖像中的噪聲信息傳遞到下層,進而影響生成圖像的質量。因此,本文將RRDB 架構進行了改進,即將殘差尺度參數放置在“短路連接”上,這樣局部切片圖像的信息可以得到保留,并且密集模塊可以學習局部切片圖像中剩余的細節。同時,考慮到資源分配的問題,改進后的架構使用2 個密集殘差和2 層密集模塊。如圖2 所示,改進的RRDB 架構有兩個輸出,分別為out1 和out2,out1 比out2 包含更多的局部圖像信息。
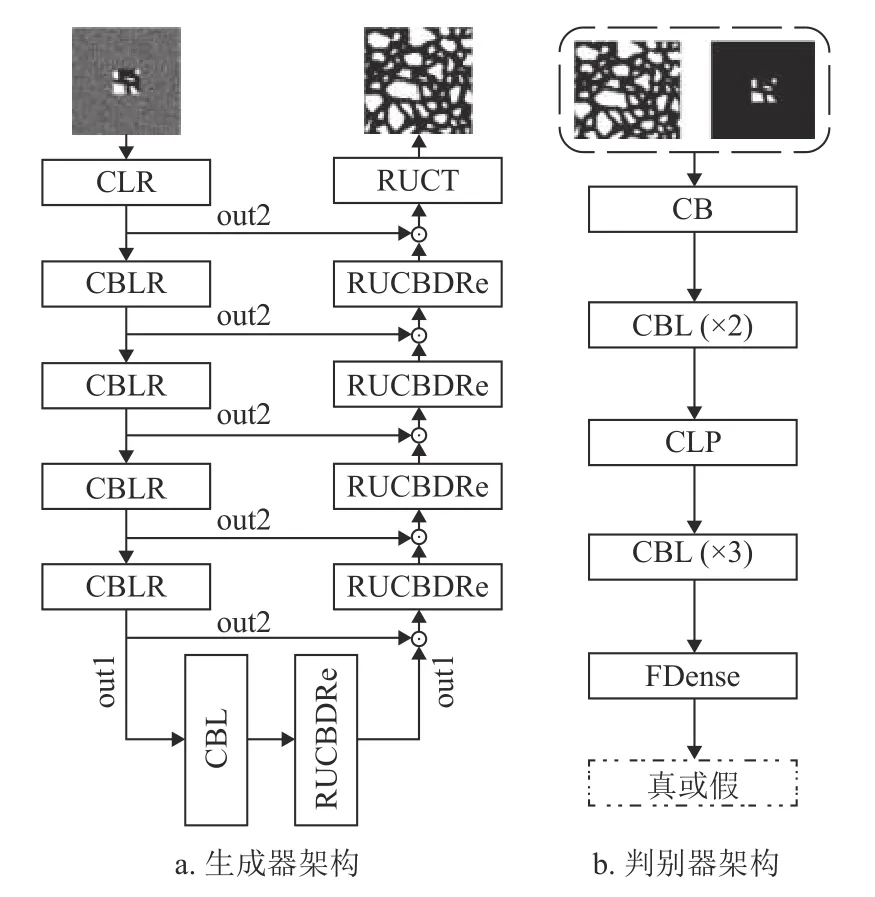
圖1 RRDB-PSA-pix2pix 網絡架構
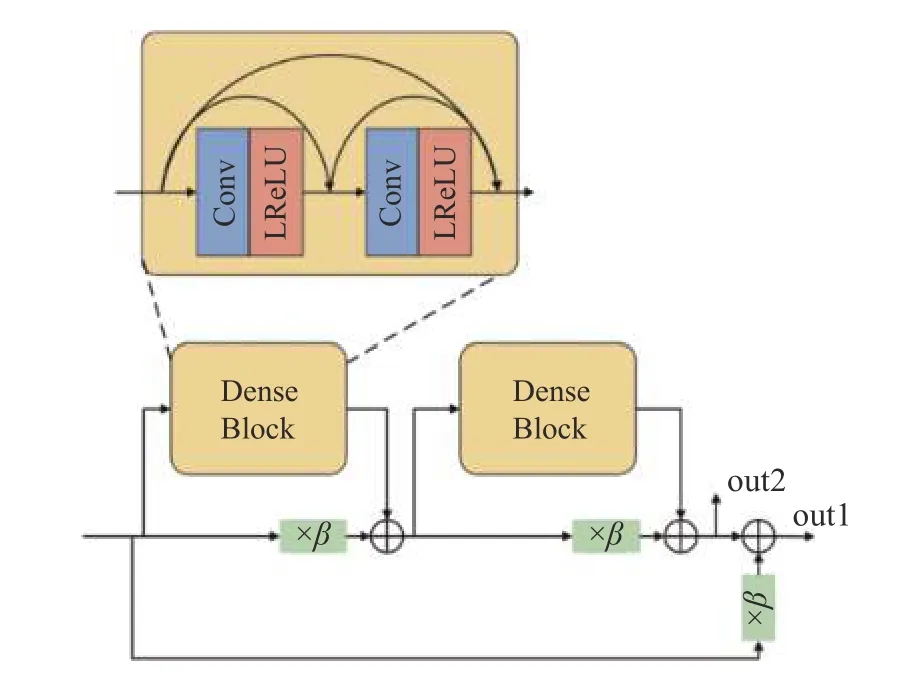
圖2 本文改進的RRDB 架構
對于條件生成對抗網絡,判別器損失采用Wasserstein 距離[24]和梯度懲罰[25]進行目標優化,同時需要加上其條件概率,可以表示為:
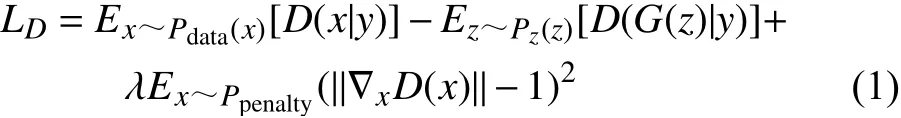
同時,為了讓生成器生成更高質量的圖像,在生成器損失中加入感知損失,計算過程表示為:
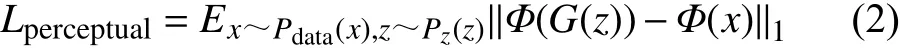
式中, Φ (G(x))表示利用VGG19 網絡[26]從生成圖像中提取的特征映射(不通過最后激活層); Φ (x)表示從真實圖像中提取的特征。
孔隙率是多孔結構最重要的結構參數。為了得到與真實圖像孔隙率相似的生成圖像,將生成圖像孔隙率和真實圖像孔隙率的曼哈頓距離作為孔隙率損失,如下所示:

式中, φporosity為 孔隙率;Avoid為孔隙(即空相)的面積;Avoid+Asolid為總面積。
另外,為了更準確地描述生成圖像和真實圖像的相似情況,本文在生成器損失中加入L1損失。根據式(1)~式(3),可以得到網絡的生成器損失表達:
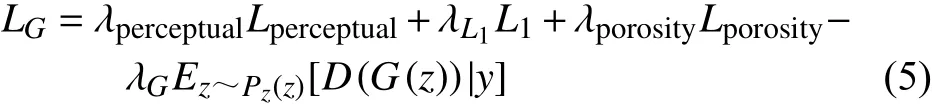
式中,y是約束條件;L1損失表示真實圖像數據分布x與 生成器生成圖像分布G(x)的L1范數,可寫為:
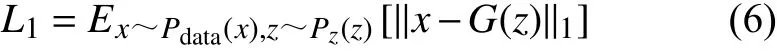
2 局部切片圖像重構
2.1 局部切片圖像的獲取
利用工業級CT 掃描機(型號:Y.CT modular,3.5 mA, 200 kV)對生物骨(豬肋骨)進行掃描,得到40 張切片圖像。對切片圖像進行二值化處理和形態處理,得到更高質量的圖像。然后對處理過的切片圖像進行裁剪,每張切片圖像可裁剪出4~5 張骨多孔圖像。考慮到圖像質量和計算成本,本文對裁剪后的骨多孔圖像進行縮放,縮放至512×512 大小,則得到190 張圖像,如圖3 所示。實際上,190 張圖像作為深度學習的數據集是遠遠不夠的,本文通過對骨多孔圖像進行旋轉和翻轉來實現增強數據的目的,最終得到1 140 張圖像作為數據集。
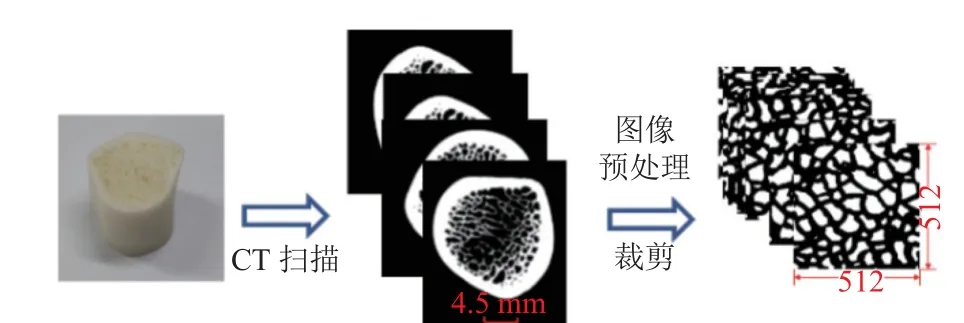
圖3 數據集獲取過程
將上述獲得的骨多孔圖像與掩膜矩陣相乘得到局部切片圖像,如下所示:
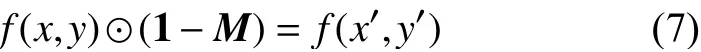
式中,f(x,y)為 骨多孔圖像;f(x′,y′)為局部切片圖像;掩膜矩陣M中缺失區域信息為1,背景區域為0,如圖4 所示。
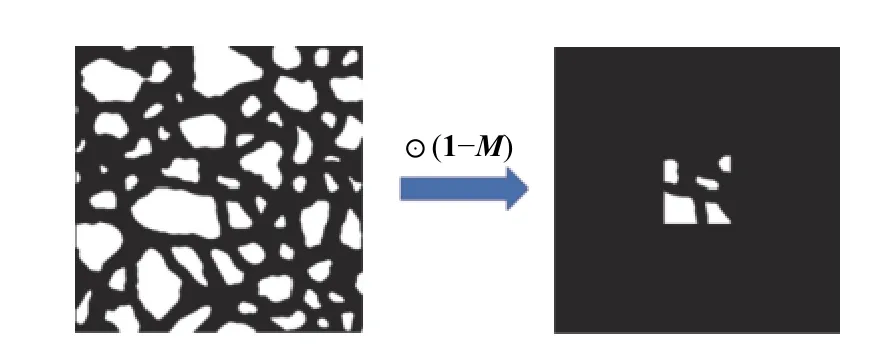
圖4 局部骨切片圖像的生成
2.2 網絡的輸入
本文采用在掩膜矩陣的背景圖像上加隨機噪聲作為網絡生成器的輸入,如圖5 所示。
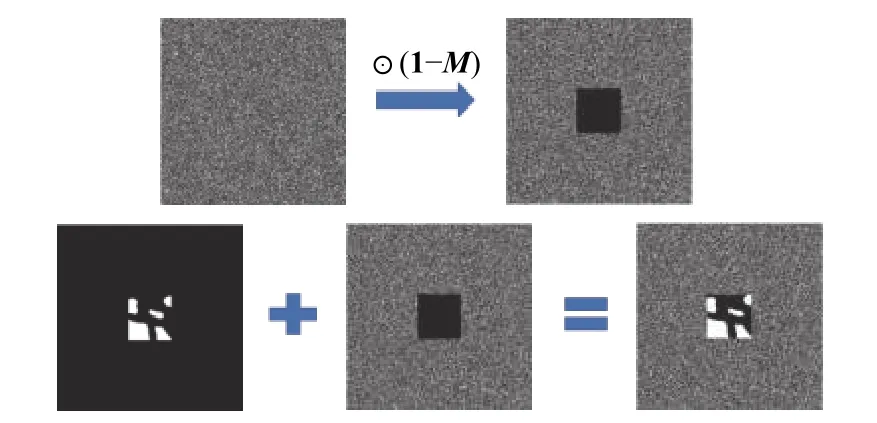
圖5 生成器輸入形式
將局部切片圖像設置為網絡的約束條件,同時,對局部切片圖像進行重構,需要構建局部切片圖像與重構生成圖像之間的關系,否則當生成器生成出與輸入不對應但又清晰的圖像時,判別器仍然會給高分,影響重構結果。將不帶噪聲的局部切片圖像與重構生成圖像拼接在一起,輸入到判別器中進行判斷,如圖6 所示。
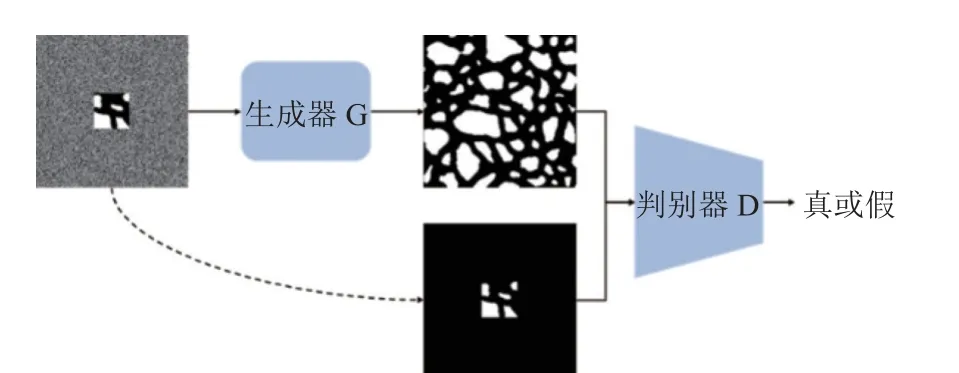
圖6 判別器輸入形式
2.3 網絡模型訓練
本文提出的網絡模型在搭載單張RTX 2070super GPU 及Intel-i5 10600KF 主機的前提下,使用pytorch框架進行訓練和推理,訓練過程采用如下超參數。
對于LeakyReLU 激活函數,參數a設置為0.2,式(5)中 λG設 為0.1, λperceptual設 為1, λL1設為0.02, λporosity取0.3;對 于 所 有 模 型,均 使 用Adam 優化器(β1=0, β2=0.9)進行訓練;使用雙時間尺度更新規則,即判別器的學習速率設為0.000 4,生成器的學習速率設為0.000 1;式(1)中判別器梯度懲罰的參數λ 設為10。
骨多孔圖像數據集被按照3:1 比例劃分為訓練集和測試集。將訓練集中的圖像數據進行處理,得到局部切片圖像數據集。為了完整地描述骨多孔結構的特征,本文以閔可夫斯基泛函(minkowski functionals, MF)[27]作為測試集測試網絡的判據。對于二維骨切片圖像,它們的 M F 由 總表面積S、總周長C和2D 歐拉示性數組成,表示為 MF=[S,C,χ]。同時,設置測試集T={t1,t2,···,tN}, 生成圖像G(T)={G(t1),G(t2),···,G(tN)}, 判據 ?MF可以表示為式(8),其值越小說明網絡越好:
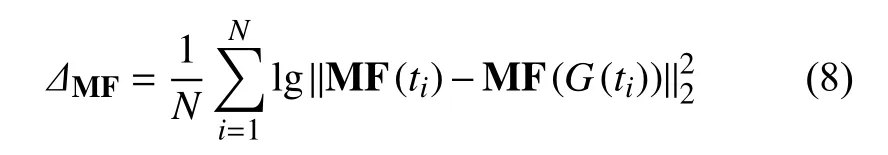
網絡訓練的周期為500 輪,每一輪訓練后的生成器模型對測試集圖像進行重構,用閔可夫斯基泛函判據來確定最好的模型,整個訓練過程如圖7 所示。
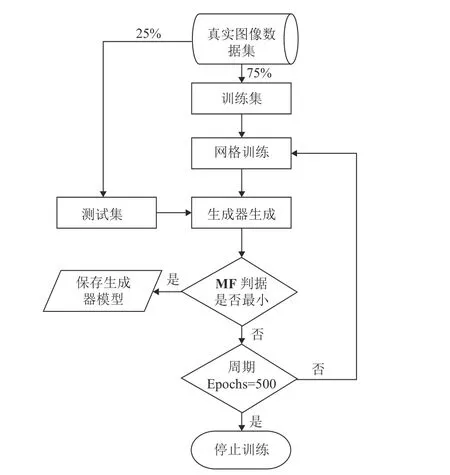
圖7 RRDB-PSA-pix2pix 網絡訓練過程
2.4 不同網絡的對比分析
近年來,文獻[7-8]提出U-NetGAN 網絡和Dense-W-pix2pix 網絡對多孔結構圖像進行重構。本文分別對U-NetGAN 網絡和Dense-W-pix2pix 網絡進行修改使其能夠訓練本文數據集,并使用MF 判據,將二者與本文提出的RRDB-PSA-pix2pix網絡進行對比。骨多孔圖像(圖8a)與掩膜矩陣相乘得到了如圖8b 所示的局部骨切片圖像。3 種網絡分別對局部骨切片圖像進行重構,得到了圖8c~8e 所示的生成圖像。

圖8 3 種網絡的生成圖像比較
如圖8 所示,U-NetGAN 網絡生成的圖像質量最差,圖中噪聲多,孔隙邊緣輪廓不清晰,出現偽影,且生成的圖像輪廓與真實圖像相同。而另外兩種網絡生成的圖像表現較好。同時,由表1 可以看出, RRDB-PSA-pix2pix 網絡 ?MF判據值比Dense-W-pix2pix 網絡更小,由此可知,本文提出的RRDB-PSA-pix2pix 網絡重構出的圖像質量最好。

表1 3 種網絡MF 判據比較
2.5 重構圖像與真實骨多孔圖像相似性分析
本文通過3 種形態學函數分析和局部孔隙率分布研究[28],評價了RRDB-PSA-pix2pix 網絡重構生成的圖像與真實圖像的相似程度。這3 種形態學函數分別為兩點相關函數[29]、線性路徑函數[30]和弦長分布函數[31]。兩點統計函數S2(r)用來表示空間中兩點的關系。線性路徑函數L(r) 統 計給定長度為r的線段完全位于同一相的概率,包含了多孔結構的連通性信息。弦長分布函數C LD(r)計算位于同一相位相同弦長的概率,可以較為準確地捕獲多孔圖像內部的空間信息,用來描述孔洞大小、形狀和空間排布等特征。局部孔隙率分布通常用于表征數字化模型中不同長度下的孔隙率和連通性的波動。與孔隙率不同,局部孔隙率? (r,L) 是在位于r為中心且長度為L的二維測量單元K(r,L)內測得。圖9 為3 種形態學函數和局部孔隙率分布的定義示意圖。
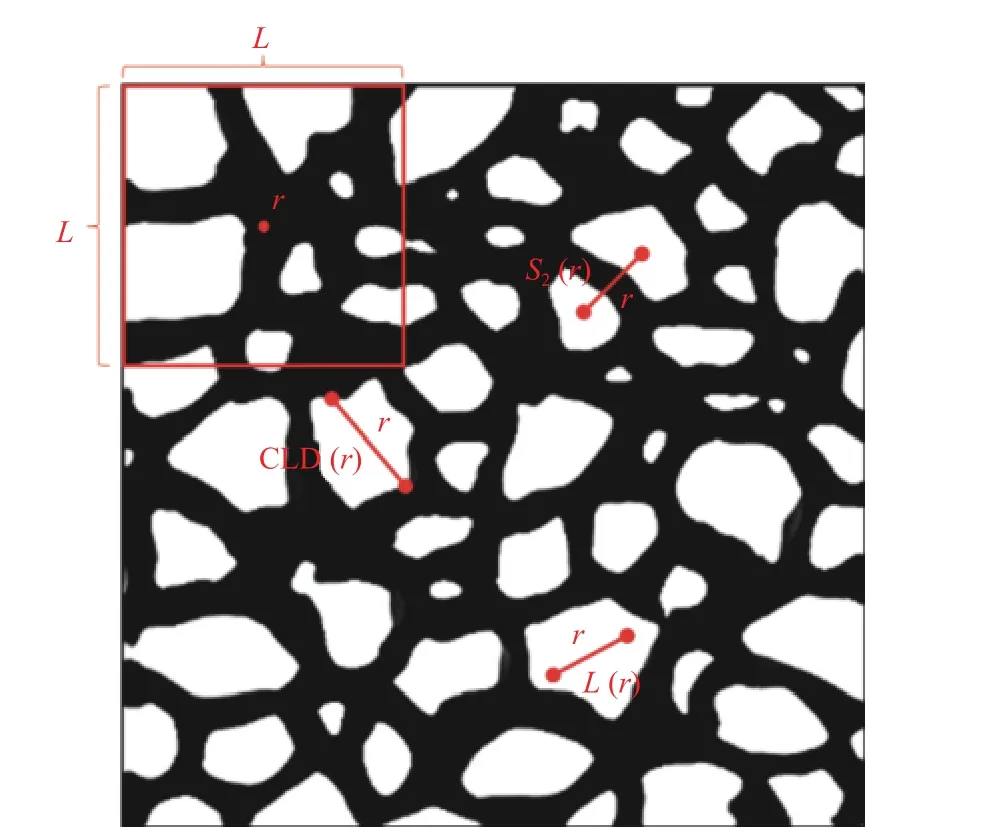
圖9 3 種形態學函數和局部孔隙率分布的定義示意圖
本文以Dense-W-pix2pix 網絡重構生成的圖像作為對比,來評價分析RRDB-PSA-pix2pix 網絡生成的圖像與真實圖像的相似程度。圖10 為兩種網絡生成圖像的形態學函數和局部孔隙率分布統計圖,其中局部孔隙率分布中的測量單元取大小為320×320。
圖中的統計分布均進行了兩組獨立樣本的Kolmogorov-Smirnov 檢驗(K-S 檢驗),且p值皆大于0.05。由圖10 可以看出, RRDB-PSA-pix2pix網絡生成的圖像分布曲線更接近于真實圖像的分布曲線,因此可以得出,本文提出的網絡能夠重構出高質量的完整骨多孔切片圖像,并且其兩相位置分布關系和連通性更符合真實情況。
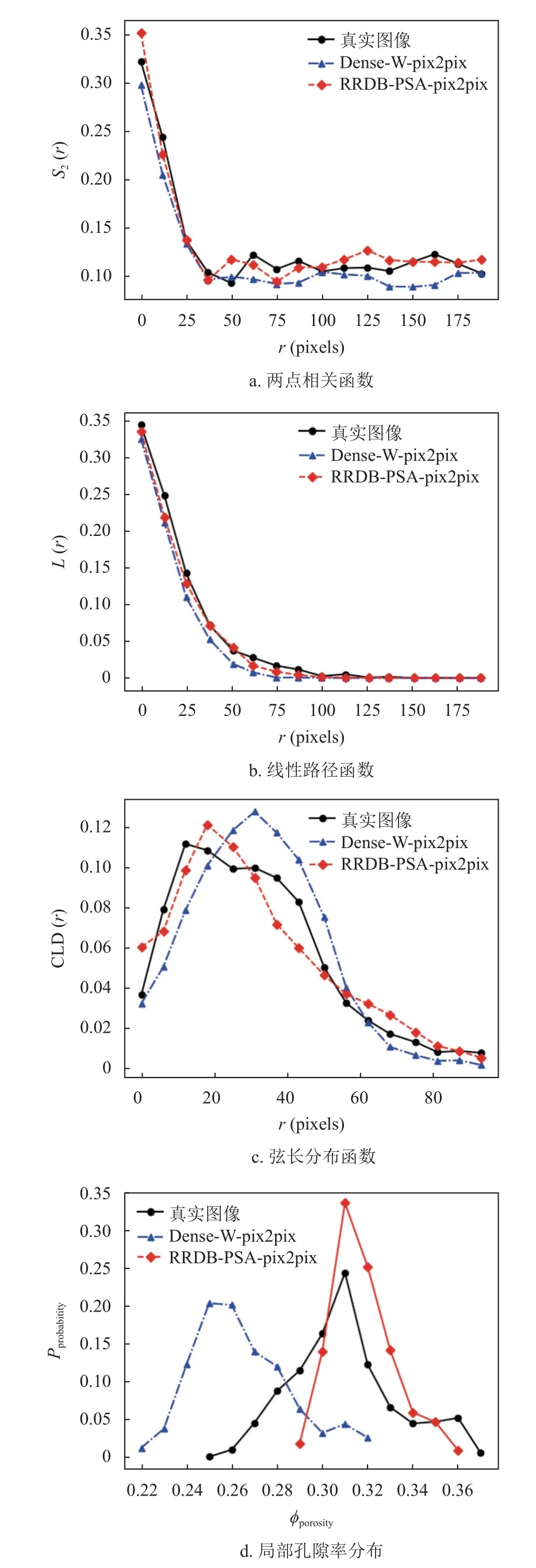
圖10 形態學函數與局部孔隙率分布統計圖
3 結 束 語
孔隙率是骨多孔結構最重要的結構參數之一,孔隙率的不同,直接影響著骨多孔結構的質量、滲透性能、機械性能以及相關生物性能,實際上,除孔隙率外,還有一些參數可用來評價骨多孔結構,但是,不同參數的評價方法,所采用的網絡算法與數學模型也各不相同,因此,考慮到篇幅問題,本文重點考慮通過孔隙率來評價骨多孔結構。
1) 本文在pix2pix 基礎上,對生成器進行改進,加入嵌套殘差密集塊(RRDB),在判別器中加入PSA 模塊,提出對局部骨切片圖像進行完整修復重構的RRDB-PSA-pix2pix 網絡。
2) 研究并分析了閔可夫斯基泛函對骨多孔結構唯一性的表征,建立了閔可夫斯基泛函判據,為快速篩選網絡提供了方法。
3) 利用3 種形態學函數與局部孔隙率分布對本文提出的RRDB-PSA-pix2pix 網絡進行分析評價。研究表明,該網絡重構生成的骨切片圖像中的多孔結構特征,更加接近于真實圖像,并且生成的圖像質量更高。
4) 本文所提出的網絡框架可以很容易地擴展到其他應用,如2D-to-3D 或3D-to-3D 的重構。理論上,它可以將任意數量的任何類型的對象函數以及任何用戶定義的條件數據合并到重構中。當通知某一區域存在特定結構時,這在實踐中可能特別有用。此外,它還可以通過與其他方法相結合來降低計算成本。
