基于降噪自編碼器和彈性網絡的入侵檢測模型
2023-02-08 12:54:50常會鑫楊麗敏陳麗芳
智能計算機與應用 2023年1期
常會鑫,楊麗敏,陳麗芳
(華北理工大學 理學院,河北 唐山 063210)
0 引言
近年來,計算機網絡發展迅速,對信息化生活產生了重大影響,然而計算機網絡的廣泛應用使其面臨各種嚴重的威脅,如惡意活動、網絡入侵和網絡犯罪[1]。入侵檢測系統是目前最有前景的網絡安全防御機制之一,在網絡安全領域引起了大量的關注與研究[2]。盡管入侵檢測系統已經發展到一個高度成熟的水平,但由于當今互聯網的廣泛應用,迅猛增長的網絡流量和復雜的網絡結構為入侵檢測帶來新的挑戰。如何從海量網絡數據中學習最魯棒的特征表示,提高入侵檢測精度是目前的研究熱點。
機器學習算法應用,在入侵檢測領域使其具有更高的魯棒性和適應性[3]。許多機器學習算法,如SVM[4]、logistic 回歸[5]、XGBoost[6]等,已被用于開發入侵檢測模型。然而,網絡流量數據的高維性和復雜性,使網絡入侵檢測成為一項具有挑戰性的任務。深度學習作為一種機器學習方法,因其對高維大規模數據的挖掘能力而受到廣泛關注,成功地解決了文本分類、目標識別、圖像分類等研究領域所面臨的許多問題,也逐漸應用于網絡入侵檢測系統中。雖然深度學習算法RNN[7]、DNN[8]在入侵檢測方面取得了良好的效果,但通過研究發現在其算法中還存在數據不完整對模型訓練結果影響過大、訓練過程中存在數據過擬合、模型對未知攻擊流量缺少判斷依據等問題。
為解決上述問題,本文提出了一種基于降噪自編碼器(Denoising Autoencoders,DAE)和彈性網絡(Elastic Net,EN)的入侵檢測模型—DAE-EN。該模型可以高效準確地對網絡流量中的攻擊流量部分進行識別,達到保證網絡安全的目的。為了方便閱讀本文以DAE-EN 代替降噪自編碼器-彈性網絡模型。
1 理論基礎
1.1 自編碼器概念
自編碼器是神經網絡算法的一種,用于在無監督的情況下學習有效的數據編碼[9]。自編碼器為了學習一組數據編碼,需要訓練網絡去除信號中的“噪聲”,其主要功能是降低數據特征的維數。自編碼器包含編碼器和解碼器,分別用于將輸入映射到隱藏層以及從隱藏層映射到輸出。
最簡單的自編碼器形式是前饋非遞歸神經網絡,其類似于單層感知器,自編碼器輸入層和輸出層需要一個或多個隱藏層進行處理。輸入層和輸出層必須具有相同數量的節點(神經元)才能保證重構輸入,重構的結果是得到一個輸入和輸出之間的最小化差異,而不是預測給定輸入X情況下的目標值Y。
將自編碼器中的編碼器定義?,解碼器定義為ψ,則表達式為:
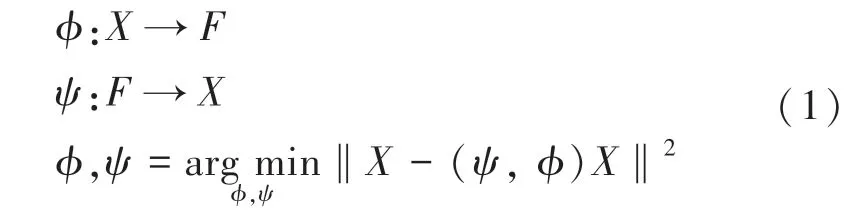
自編碼器架構如圖1 所示。通常情況下,自編碼只會使用一個隱藏層來連接輸入與輸出,編碼器接收輸入x∈Rd =X,并將其映射到h∈Rp =F:
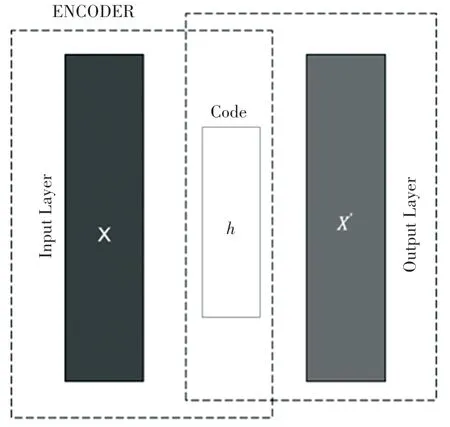
圖1 自編碼器架構Fig.1 Autoencoder architecture
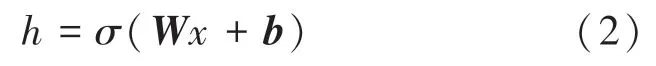
式中,h通常被稱為潛在變量;σ為激活函數,例如sigmoid 函數或修正線性單元;W為權重矩陣;b為偏置向量。權重矩陣和偏置向量的初始化過程是隨機的,這兩個參數在訓練過程中通過反向傳播迭代更新。自編碼器的解碼階段將h映射到與x具有相同維度的x′為
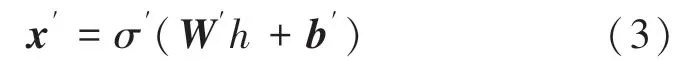
解碼器中的變量σ′ W′ b′與編碼器中的變量σWb沒有強關聯性。自編碼器經過訓練最小化重建誤差(例如:平方誤差),通常稱為“損失”:
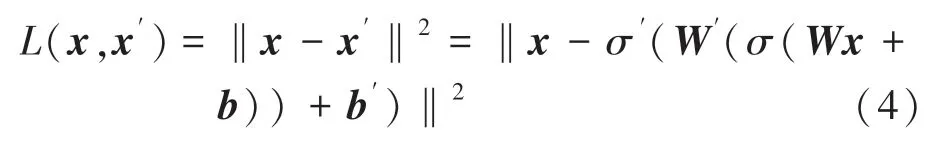
X通常是訓練集的平均值。自編碼器訓練與其它前饋神經網絡一樣,均是通過誤差的反向傳播進行。
特征空間F的維度應低于輸入特征X的維度,特征向量?(X)可以看做是輸入x壓縮而來的。在使用欠完備自編碼器情況下,如果隱藏層節點數量大于等于輸入層的節點數量,自編碼器會一直學習同一個函數,導致整個訓練過程是無效的。然而通過實驗發現,欠完備的自編碼仍然可能學習到有用的特性[10],模型代碼維度和模型容量可以根據所需建模的數據分布情況來設定,這種方法稱為正則化自編碼器。
1.2 降噪自編碼器
降噪自編碼器(DAE)是在自編碼器的基礎上增強了健壯性[11],DAE 使用部分“損壞”的輸入并經過訓練以恢復原始未失真的輸入。在實踐中,自編碼器去噪的目標是清除“損壞”的輸入,為實現這個目的通常采用兩種方法[12]:一是使用更高級別的輸入特征,提高相對穩定性和健壯性;二是為了更好的對特征進行去噪,模型需要提取特征來分析輸入中的有效結構。DAE 主要是為了從噪聲輸入數據中學習更一般化的特征,其訓練過程如下:

Step 3在隱藏層中對該模型進行重構z =gθ′(h)。
模型中的參數θ和θ′是為了最小化訓練集的平均重構誤差,特別是最小化數據z和原始未輸入數據x之間的差異。基于,每個隨機示例X輸入到模型中,都會隨機產生一個新的“損壞” 版本。
1.3 彈性網絡
在統計學中,特別是在線性或邏輯回歸模型的擬合中,彈性網絡線性組合了Lasso 和Ridge 方法的L1和L2懲罰[13]。彈性網絡可以向Lasso 學習輸入少量參數非零的稀疏模型,同時能保持Ridge 的正則性質。該方法基于公式(5):
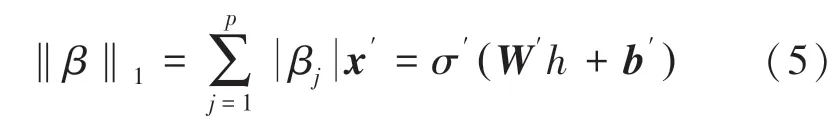
在高維數據、樣本數量不多的情況下,Lasso 在飽和之前最多選擇n(樣本個數)個變量[14]。此外,若樣本是一組高度相關的變量時,Lasso 會優先選擇變量中的一個變量而忽略其它變量。為了克服這些限制,彈性網絡增加了一個懲罰‖β‖2,單獨使用時就是一個Ridge 回歸[15]。彈性網絡的定義為

二次懲罰項使損失函數具有很強的凸函數性質,因此具有唯一的最小值[16]。
1.4 DEA-EN 模型構建與實現流程
DEA-EN 模型的構建主要是由兩部分組成:一是由輸入層、隱藏層、輸出層組成的降噪自編碼器(DEA);二是在DEA 的隱藏層中增加的彈性網絡。
如圖2 所示,DAE-EN 模型的實現步驟如下。
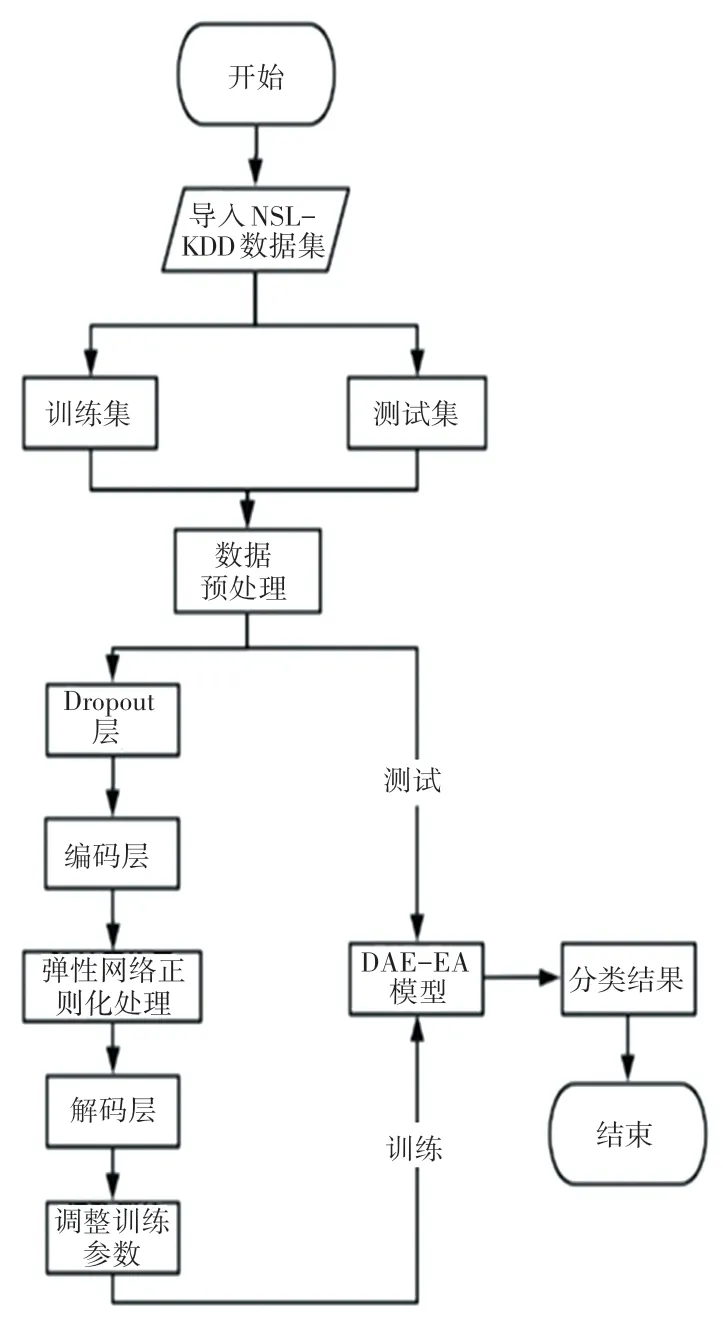
圖2 DAE-EN 模型實現流程Fig.2 DAE-EN model implementation process
Step 1導入NSL-KDD 數據集,按照8:2 的比例將該數據集劃分訓練集和測試集。為方便模型使用,訓練集和測試集均需要對數據進行預處理。
Step 2將訓練集數據輸入Dropout 層,其可以隨機的臨時屏蔽掉一半的隱藏神經元,達到防止模型過擬合,提升模型泛化能力。
Step 3經過一個具有8 個神經元的編碼層進入降噪自編碼器的隱藏層。在隱藏層采用彈性網絡,避免數據的過擬合,最后再從解碼層輸出,最終構建好整個模型。
Step 4調整模型參數。
Step 5通過訓練集數據對模型進行訓練,使用測試集評估模型效果,得到最終分類結果。
2 仿真實驗
2.1 數據集來源
NSL-KDD 數據集基于KDD99 進行改進,解決了KDD99 數據集數據的重復性和冗余性問題,避免了訓練模型優先使用出現頻率較高數據的情況,該數據集被廣泛應用于入侵檢測系統中。NSLKDD 數據集中共有148 517 條數據,訓練集和測試集占比為84.8%和15.2%,分別存放在NSL_Trian.csv 和NSL_Test.csv 文件中。整個數據集包含41個特征值和一個標志位(見表1),同時NSL-KDD數據集包含39 種攻擊類型,按照其性質劃分為4 種一般的攻擊類型:DoS、R2L、U2R 和Probe。具體分類情況見表2。

表1 NSL-KDD 數據集的部分數據Tab.1 Partial data of NSL-KDD dataset

表2 NSL-KDD 數據集中的攻擊分類Tab.2 Attack classification in NSL-KDD dataset
2.2 數據集預處理
數據集預處理是模型訓練前的必要步驟,其中包括兩部分處理內容:針對連續數據進行歸一化處理;針對字符串數據進行一位有效編碼處理。
采用最小-最大歸一化方法,將連續值縮放到數值范圍[0,1],如公式(7):
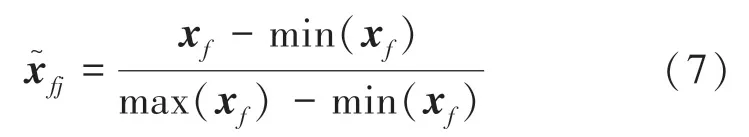
其中,max(xf)和min(xf)分別代表特征值xfj的最大值和最小值。歸一化的結果取值范圍為[0,1]。一位有效編碼將協議類型、服務和標志3 個特征轉換為數值,每個類別屬性都由二進制值表示。例如:protocol_type 字段有tcp、udp 和icmp 3 個值,一位有效編碼將其分別轉換為二進制向量[1,0,0]、[0,1,0]、[0,0,1],同時把服務和標志兩個字段處理成向量。經過預處理后,數據集的特征值由原來的41 個變成了122 個。其中,連續特征38 個,協議類型、服務和標志3 個特征相關的向量特征為84 個。
2.3 訓練方法及參數調整
為了避免訓練數據中每種攻擊類型樣本不平衡以及無法通過訓練分析未知攻擊類型的問題,本文提出利用自編碼器和彈性網絡來檢測異常的方法。該方法使用一個帶有dropout 的降噪自編碼器。由于輸入樣本的特征數是122,所以輸入層由122 個神經元組成,緊接著是一個dropout 層和一個由8 個神經元組成的隱藏層,最后是一個有122 個神經單元的輸出層,隱藏層和輸出層的激活函數為relu 函數。
降噪自編碼器通過訓練,將輸入進行重構。模型只針對訓練集中標志位為正常的數據訓練,進一步得到輸入和輸出之間的均方誤差,最終目的是通過訓練使均方誤差最小化。自編碼器強制在訓練階段結合彈性網絡正則化處理,防止訓練時出現簡單地將輸入復制到輸出的情況。為防止過擬合問題,需要對Lasso、Ridge 的L1和L2懲罰參數進行調整,均設為0.001時效果最好。此外,這種自編碼器被訓練成從自身的一個“損壞”版本來重構輸入,迫使自編碼器學習更多的數據屬性。該模型使用大小為100 的Adam優化器訓練10 個epoch,使用訓練集90%的數據對模型進行訓練,預留10%的數據驗證模型。
2.4 結果分析
本模型的訓練方法只使用正常樣本數據,將正常數據與攻擊數據分別輸入到訓練好的模型中。具有攻擊的數據所得到的重構誤差相對偏高,因此可以通過設置重構誤差的閾值檢測攻擊,假設一個數據樣本的重構誤差高于預設的閾值,該樣本則被歸為攻擊,否則歸為正常流量。
對于閾值的選擇,采用訓練數據上的模型損失和驗證數據上的模型損失,本實驗中使用訓練數據生成的模型損失作為一個閾值。
本次實驗的目的是為了進行異常檢測,檢測網絡數據中的攻擊數據,本模型只涉及二分類。為了更好的評估模型的性能,根據輸入特征與預測特征的特性,使用了一個損失函數式(8)計算每個輸入的重構損失,通過對比重構誤差和預設閾值的大小來進行分類。
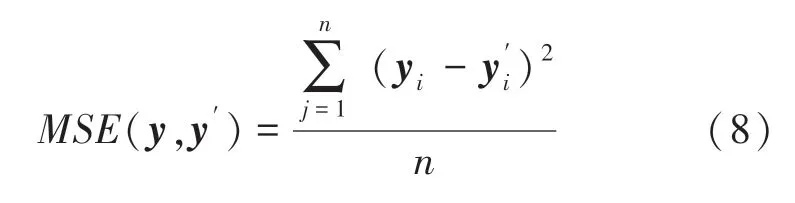
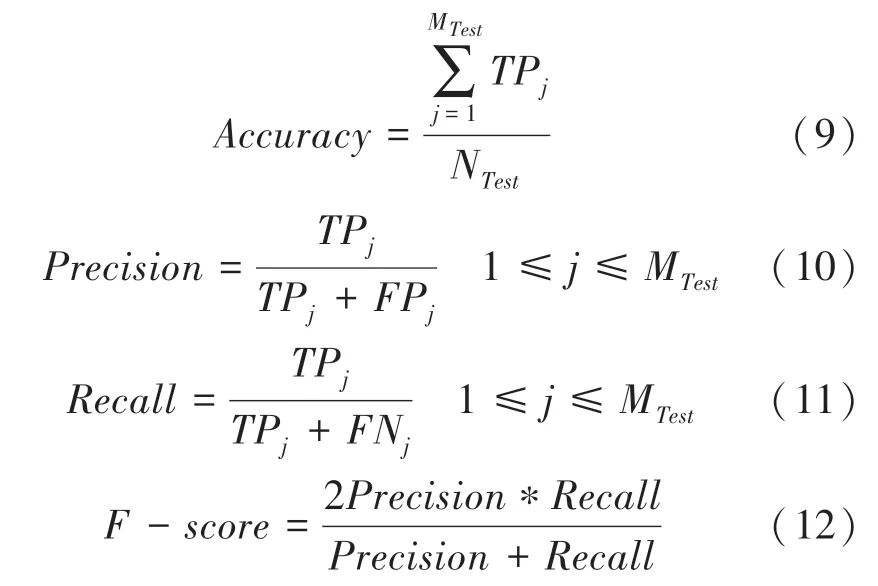
為了評估該模型,準確率(Accuracy)、精確率(Precision)、召回率(Recall)、F分數(F -score)等計算性能指標。其計算公式分別為:
通過實驗得出準確率為90.3,召回率為95.3,精確率為88.5,F1分數為91.8。為了使數據更加直觀,繪制了正常流量和攻擊流量的混淆矩陣[14],如圖3 所示。其中,橫軸是預測值,縱軸是實際值。
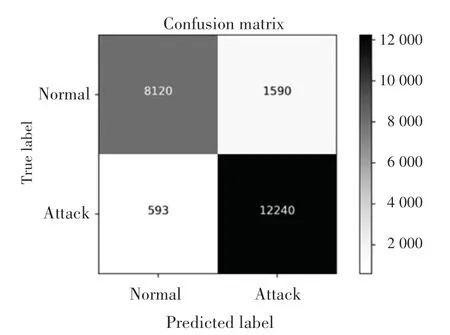
圖3 正常流量與攻擊流量的混淆矩陣Fig.3 Confusion matrix of normal traffic and attack traffic
針對模型的測試結果,計算出4 種攻擊的檢測率見表3,以及如圖4 所示的小提琴圖。由圖中可以清楚的看出測試集中所有數據樣本重構損失值的分布。其中,攻擊的損失值大多高于閾值,正常流量的值則大部分小于閾值。
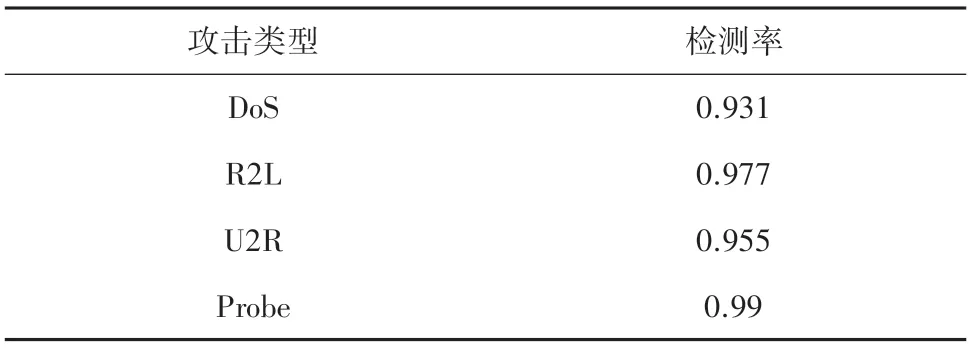
表3 4 種攻擊類型檢測率Tab.3 Detection rates of four attack types
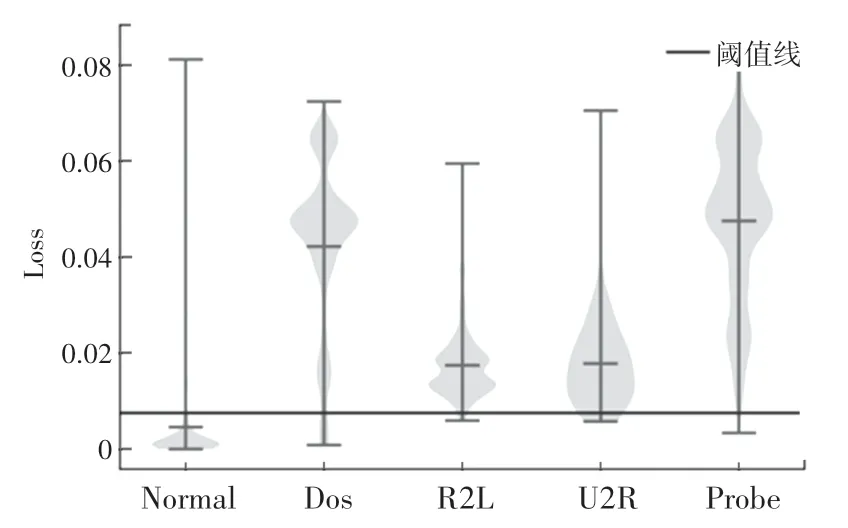
圖4 測試集的損失分布Fig.4 Loss distribution of the test set
2.5 算法性能對比分析
為了進一步驗證本模型針對入侵檢測的性能,將其與決策樹(DT)、K 鄰近算法(KNN)、梯度提升決策樹(GBDT)、隨機森林(RF)以及變分自編碼器(VAE)算法[15-16]的準確率進行對比,其結果見表4。
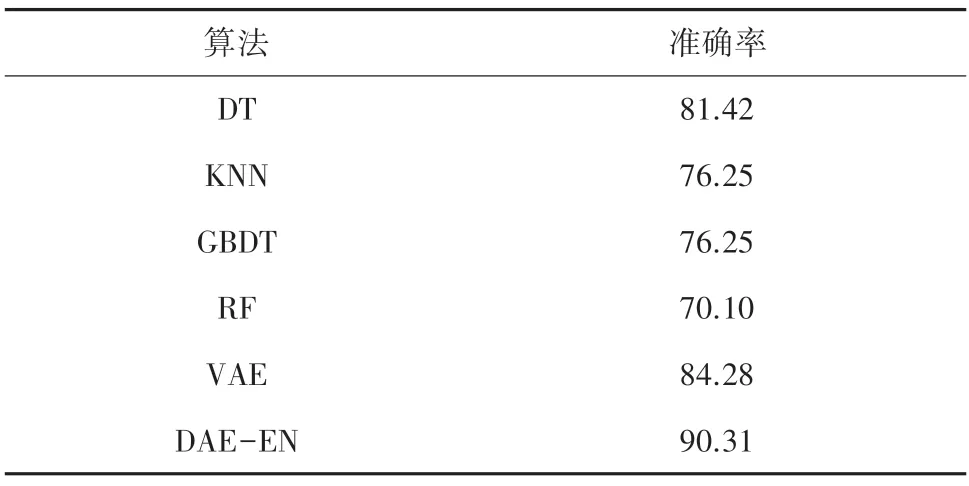
表4 與傳統機器學習算法對比Tab.4 Comparison with traditional machine learning algorithms
由表4 中可以看出,決策樹、K 鄰近算法、梯度提升決策樹、隨機森林4 種傳統機器學習算法中,準確率最高的為決策樹算法,其值為81.42%;變分自編碼器深度學習模型的準確率為84.28%;而DAEEN 模型對于區分正常流量與攻擊流量的能力都優于其它算法,準確率為90.31%。
3 結束語
入侵檢測系統面對大量的網絡流量,其中大部分流量是正常流量,只有小部分流量是具有攻擊的流量,所以本文設計DAE-EN 模型通過訓練正常流量計算損失值,根據重構誤差的大小,通過設置合理的閾值來區分正常數據和攻擊數據。DAE-EN 模型中降噪自編碼器將輸入數據經編碼器和解碼器映射后,生成重構數據,在訓練過程中增加了彈性網絡正則方法避免訓練過程的過擬合問題。通過實驗結果對比表明,本文提出的DAE-EN 模型檢測準確性達到90.31%,高于決策樹等傳統機器學習算法以及變分自編碼器模型,對網絡入侵檢測具有更優的檢測效果。目前,DAE-EN 模型只能區分正常流量和攻擊流量,計劃在未來工作中將模型擴展到多個類別,并且可以完成對特定攻擊類型的識別。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
