基于用戶和項目的協同過濾算法的比較研究
2023-02-08 12:54:50羅潔,王力
智能計算機與應用 2023年1期
羅 潔,王 力
(1 貴州大學 大數據與信息工程學院,貴陽 550025;2 畢節工業職業技術學院,貴州 畢節 551700;3 貴州工程應用技術學院 信息工程學院,貴州 畢節 551700)
0 引言
隨著時代發展,信息量極大膨脹。用戶在面對海量信息時,不能快速從中獲取自己有用的信息。針對這種現象,智能算法應運而生。近年來有關個性推薦算法的應用越來越廣泛,根據用戶的歷史行為,對用戶的喜好和目標行為,為用戶推送信息,極具商業價值和挖掘價值。協同過濾算法最大的優點在于對推薦的對象沒有特殊要求;能夠有效處理非結構化的復雜的對象,避免了內容的分析不完全性和不精確性,根據用戶的歷史行為推薦個性化的信息。目前有很多學者對協同過濾算法進行改進并應用,孫傳明等[1]針對數據稀疏性和推薦范圍問題,提出了一種混合協同過濾推薦算法;榮以平等[2]針對電力大用戶選擇交易對象的問題,提出了基于用戶協同過濾的購電推薦算法;孟晗等[3]針對對惡意用戶進行區分的問題,提出了一種改進的新型信任關系度量的推薦算法;夏景明等[4]針對數據稀疏導致的推薦不準確問題,提出了一種基于用戶和商品屬性挖掘的協同過濾算法。
本文針對協同過濾算法的兩種不同對象,基于用戶和基于項目,對其進行比較分析,從用戶數大于項目數和用戶數小于項目數兩方面進行實驗,驗證了兩種不同對象的協同過濾算法的特性。
1 相關知識
協同過濾算法由3 個部分組成:通過用戶評分行為得到用戶—項目評分矩陣、計算相似度、根據相似度進行推薦。
1.1 用戶評分行為
用戶評分行為是通過用戶對項目的打分,構成用戶—項目評分矩陣R,式(1)所示,行向量表示用戶對項目的評分,列向量表示某個項目得到用戶的評分。
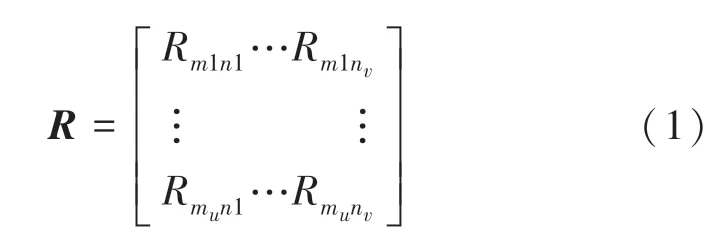
其中m表示用戶;n表示項目;mu表示第u個用戶;nv表示第v個項目;Rmunv表示第u個用戶對第v個項目的評分,其數值的大小表示用戶對項目的興趣程度。
1.2 相似度計算
采用余弦相似度找到與目標用戶興趣相似的用戶集合,利用不同用戶對項目評分數的相似度計算出用戶的興趣相似度。余弦相似度是用戶向量i和用戶向量j之間的向量夾角大小,夾角越小,余弦相似度越大,兩個用戶越相似。余弦相似度公式為
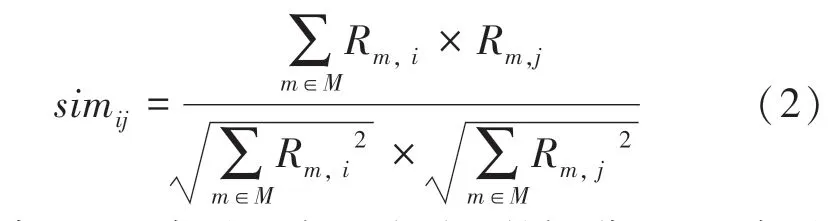
其中,Rm,i表示用戶i對項目的評分,Rm,j表示用戶j對項目的評分。
相似度越高則用戶間的喜好相似性越高。公式(2)中的分子代表評價向量,分母代表評分值。基于項目的協同過濾算法同樣采用余弦算法計算項目間相似度。
1.3 推薦
利用k 最近鄰算法思想,找到相似度最高的前k個用戶,通過這些用戶的相似度權重以及其對項目的偏好,計算得到一個項目排序列表進行預測推薦。用戶u對項目i的預測評分,為式(3)
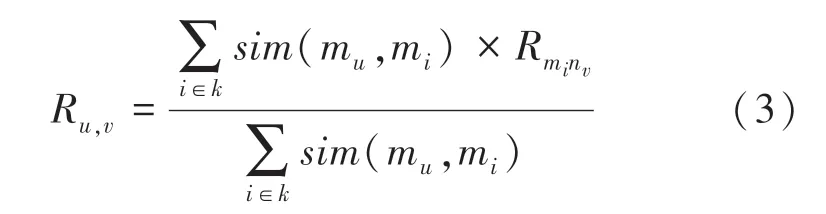
其中,k是相似度最接近的向量的集合;i是任意一個用戶;sim(mu,mi)表示最近鄰i和用戶u的相似度乘上最近鄰i對項目v的評分。
與基于用戶的協同過濾算法相似,基于項目的協同過濾算法是通過項目的相似度矩陣乘上評分矩陣得到推薦列表,來為用戶推薦其有興趣但還未涉及的項目。
2 基于用戶的協同過濾
采用不同用戶對項目的評分作為用戶-項目評分矩陣,以此計算用戶的相似度,根據相似度給用戶推薦和其興趣一致的用戶的其他項目。其過程如圖1 所示。
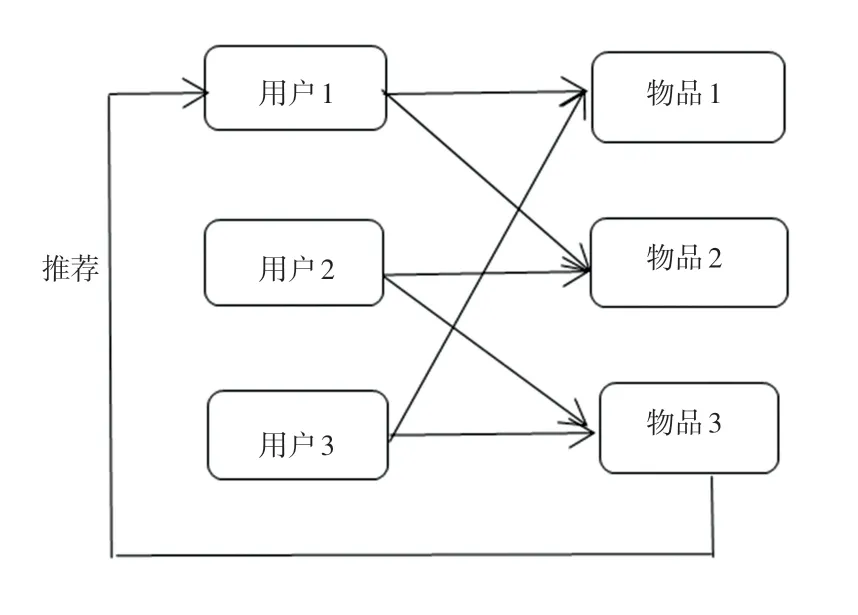
圖1 基于用戶的協同過濾過程Fig.1 The process of user-based collaborative filtering
該算法利用了用戶和用戶間的相似性來為用戶推薦其感興趣的信息,通過評分達到篩選信息的目的,但是這個算法存在兩個難解決的問題:
(1)稀疏性,即:用戶評價信息量少,很難發現用戶行為的相似性;
(2)隨著項目和用戶數量的增多,可擴展性變差。針對這兩個問題,一方面可以通過改進相似度計算方法來改善數據稀疏性;另一方面,可以采用分布式編程來提高算法的可擴展性。
3 基于項目的協同過濾
將用戶對不同項目的評分行為用矩陣來表示,以此計算項目之間的相似度,根據相似度排序為用戶推薦與用戶偏好相似度高的項目。每個用戶操作獨立,有獨立的特征向量,不受相鄰用戶的偏好影響,可以為目標用戶推薦其感興趣的、新的、冷門的項目,使算法不受冷啟動和稀疏性問題的影響,過程如圖2 所示。
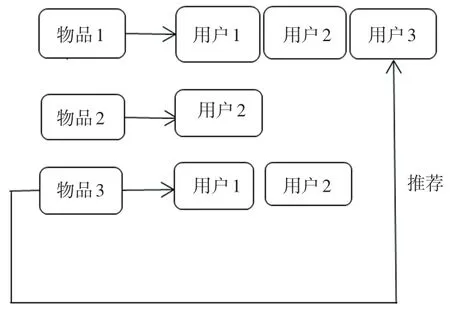
圖2 基于項目的協同過濾過程Fig.2 Project-based collaborative filtering process
4 實 驗
4.1 實驗環境
實驗環境為:Inter(R)Core(TM)i5-2410M CPU@ 2.30 GHz;8 GB 內存;操作系統是Winsdow10 64 位,利用Jupyter Notebook 進行編程。實驗數據集從MovieLens(https://grouplens.org/datasets/movielens/)中抽取。電影的評分范圍為[1,5]區間所有整數值,用戶對電影的喜好程度由1 到5 逐漸遞增,數值越大,喜歡程度越深。實驗數據集包含了用戶信息,評分信息,電影信息。
4.2 評價指標
4.2.1 召回率(Recall)
召回率(Recall)又稱為查全率,表示樣本中正例被預測正確的比例,召回率為
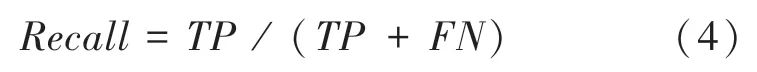
其中,TP表示預測結果為正,實際結果為正;FN表示預測結果為負,實際結果為正;TP +FN表示實際結果為正的樣例。
4.2.2 精確率(Precision)
精確率(Precision)又稱為查準率。表示預測為正的樣本中正樣本的比例,精確率為
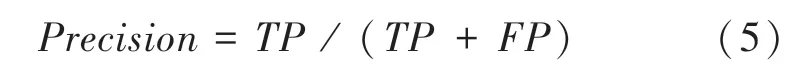
其中,TP表示預測結果為正,實際結果為正;FP表示預測結果為正,實際結果為負;TP +FP表示預測結果為正的樣例。
4.2.3 覆蓋率(coverage)
覆蓋率(coverage)是度量測試完整性的手段,覆蓋率為
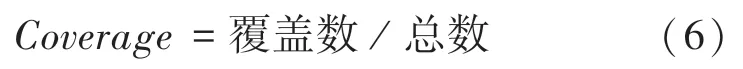
4.3 實驗結果
實驗1用戶數大于項目數
將兩種算法對同一數據集,6 040 個用戶對3 925部電影共1 000 209條評論信息進行實驗,實驗結果見表1。實驗證明基于項目的協同過濾算法準確率更高,而基于用戶的算法召回率、覆蓋率更高,從時間上看基于用戶的算法效率更高。
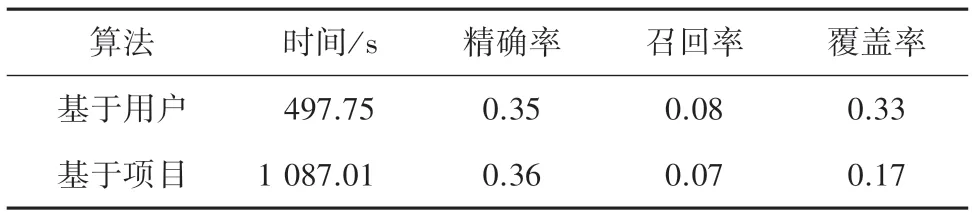
表1 用戶數大于項目數Tab.1 The number of users is greater than the number of items
實驗2用戶數小于項目數
將兩種算法對同一數據集,610 個用戶對9 742部電影的評論信息進行實驗,結果見表2。實驗證明基于項目的協同過濾算法精準率、覆蓋率更高,而基于用戶的算法召回率更高,從時間上看基于用戶的算法效率更高。
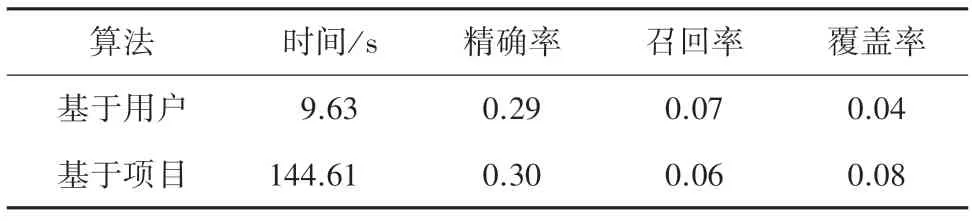
表2 用戶數小于項目數Tab.2 The number of users is less than the number of items
結論:
(1)從精確率來說,基于項目的協同過濾算法質量更高。
(2)從時間成本來說,基于用戶的協同過濾算法效率更高。
5 結束語
信息大爆炸時代,面對如此龐大數量的信息,如何有效篩選有用信息是個性化推薦算法的主要目的,也極具商業價值。本文就協同過濾算法的選擇對象不同,對基于項目和基于用戶的協同過濾算法進行了比較分析研究,實驗表明兩種算法各具其特色,從精確率角度,基于項目的協同過濾算法質量更高;從時間成本角度,基于用戶的協同過濾算法效率更高,應該在適宜的情況下,用相應的算法。當考慮精確率時,就使用基于項目的協同過濾算法,當考慮時間成本時,就使用基于用戶的協同過濾算法。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
