基于改進的SKnet 和Bi-GRU 的巖石薄片圖像礦物識別
2023-02-08 12:54:30吳曉紅滕奇志何海波
智能計算機與應用 2023年1期
關(guān)鍵詞:特征
劉 勇,吳曉紅,滕奇志,何海波
(1 四川大學 電子信息學院,成都 610065;2 成都西圖科技有限公司,成都 610065)
0 引言
傳統(tǒng)的巖石薄片圖像分析鑒定依賴于專家在光學顯微鏡下對巖石的目視觀察,存在很多局限性。首先,薄片鑒定需要在多個角度反復觀察單偏光圖像和正交偏光圖像,大量巖石樣本的識別工作需要耗費一定的人力資源和時間成本;其次,人工鑒定因人而異,不能保證準確、量化的結(jié)果;第三,傳統(tǒng)的鑒定依賴實物送樣和人工觀察,但薄片樣品長時間存放可能會變黃、脫膠,影響鑒定結(jié)果,最終導致資產(chǎn)損失。
近年來,在礦物顆粒分類識別方面,國內(nèi)外學者開展了大量的研究工作,也取得了一定的應用成果。2013 年,Mariusz Mlynarczuk[1]等人基于最近鄰算法等4 種模式識別方法,在4 種顏色特征空間中對白云石、石灰?guī)r、花崗巖等礦物進行了顆粒識別;2014年,楊宗瑞[2]結(jié)合礦物顆粒的亮度均值、顏色、紋理特征以及灰度共生矩陣熵信息,采用隨機森林分類器識別多種礦物顆粒;2015 年,Akka? E 等人[3]使用SEM-EDS 光譜儀獲取礦物顆粒的特征,再利用決策樹算法對橄欖石等十種礦物顆粒進行分類;2016年,閔濤[4]針對礦物正交偏光序列圖的顏色、紋理等特征,采用機器學習模型,再結(jié)合復雜的權(quán)值投票機制,完成礦物顆粒識別任務。
隨著計算機硬件能力的迅速提升和深度學習技術(shù)的飛速發(fā)展,基于神經(jīng)網(wǎng)絡的深度學習分類方法也相繼出現(xiàn)。2012 年,Krizhevsky A 等人[5]提出AlexNet,在圖像分類領(lǐng)域取得突破性進展;自此,用于分類的各種卷積神經(jīng)網(wǎng)絡層出不窮,包括VGGNet、ResNet、MobileNet、InceptionResnet 等。2018 年,彭志偉[6]選用CaffeNet 作為識別分類網(wǎng)絡模型,并提出一種基于顏色和紋理的序列圖像篩選算法,實現(xiàn)了礦物顆粒偏光序列圖像下的分類識別;2019 年,T.Nanjo,S.Tanaka[7]等人提出了一種基于深度神經(jīng)網(wǎng)絡的碳酸鹽巖巖性識別圖像分析技術(shù);2020 年Y Xu[8]等人利用卷積神經(jīng)網(wǎng)絡ResNet-18對變質(zhì)巖、火成巖、沉積巖(包括碎屑巖和碳酸鹽)的薄片圖像進行自動分類;2021 年,朱磊[9]提出了一種基于序列圖分類的礦物顆粒識別方法,針對礦物顆粒偏光序列圖像分類效果相對較好,但未充分利用巖石顆粒在不同正交偏光角度下的消光性信息,斜長石礦物顆粒存在一定的誤識別情況。
綜上,充分利用礦物顆粒在多個正交偏光角度下的豐富信息是礦物顆粒分類工作中十分值得探究的內(nèi)容。在不同正交偏光角度下,礦物顆粒的干涉、紋理及消光特征表現(xiàn)不同,如圖1 所示。石英顆粒表面整體較為光滑;堿性長石表面紋理特征豐富,沒有規(guī)律,整體表現(xiàn)出一種“不干凈”的狀態(tài);斜長石顆粒在特定角度會呈現(xiàn)聚片雙晶現(xiàn)象;巖屑顆粒在偏光序列圖中幾乎沒有消光變化,表面有零星分布的碎屑,沒有規(guī)律。本文在對巖石礦物顆粒偏光序列圖像進行消光位校正處理的前提下,提出了基于改進的SKnet 和雙向GRU 模型的巖石礦物顆粒分類方法,將進行了消光位校正對齊處理后的礦物顆粒偏光序列圖像送入改進的SKnet 特征提取模塊進行特征提取,再通過雙向GRU 門控單元捕獲序列圖的前后關(guān)聯(lián)特性,最終完成對常見的石英、斜長石、堿性長石、巖屑4 類礦物顆粒的分類識別。該網(wǎng)絡在礦物顆粒偏光序列圖識別分類上取得了較好的效果。

圖1 4 類巖石礦物偏光序列圖Fig.1 Polarization sequence images of four types of rock minerals
1 巖石顆粒偏光序列圖提取及消光位校正
1.1 巖石薄片正交偏光序列圖像采集
在進行巖石礦物顆粒識別工作前需采集一定量的巖石薄片序列圖,便于后續(xù)分割提取巖石顆粒序列圖,制作實驗所用訓練集、測試集。將巖石樣本磨制到足夠“薄”,一般的標準薄片厚度為30 μm,將薄片制作成玻片放置光學顯微鏡下,即可觀察分析巖石薄片中的礦物。本文采用最新的薄片圖像采集系統(tǒng),在載物臺不動的情況下,自動旋轉(zhuǎn)上下偏振片來獲取不同角度的正交偏光圖像,從而實現(xiàn)序列圖像的對齊分析,更有利于后續(xù)圖像的智能識別,圖像采集工作中設(shè)置的正交偏光旋轉(zhuǎn)角度為15°,每一組采集9 張圖片。在正交偏光角度下采集的巖石薄片序列圖像如圖2 所示。

圖2 巖石薄片偏光序列圖像Fig.2 Polarized light sequence images of rock slices
1.2 巖石礦物顆粒提取及消光位校正
在不同角度正交偏光鏡下,由于非均質(zhì)巖石薄片除垂直光軸以外的切片,光率體為橢圓,在偏振片的旋轉(zhuǎn)過程中,光率體橢圓長、短半徑與上偏振片、下偏振片有4 次平行的機會,平行下偏振片的偏光不能透過上偏振片,視域呈黑暗,說明該礦物顆粒處于消光位,并且?guī)r石礦物顆粒的消光性在載物臺旋轉(zhuǎn)的過程中呈現(xiàn)以90°為周期的變化規(guī)律。在實際圖像采集過程中,由于顆粒自身的一些光學特性,實際處于消光位的礦物顆粒表現(xiàn)為周期內(nèi)的亮度最低值,并且不同礦物顆粒的消光位可能處于不同角度,分割提取的巖石顆粒偏光序列圖第一張圖像并不一定處于消光位,為了更好的利用后續(xù)雙向GRU 循環(huán)卷積神經(jīng)網(wǎng)絡的特性,需要保證不同礦物顆粒正交偏光序列圖像相同序號位置處的消光程序盡可能接近,因此需要從巖石薄片偏光序列圖中提取出巖石顆粒序列圖,然后對巖石顆粒序列圖做消光位校正處理,步驟如下:
(1)對采集獲取的巖石薄片偏光序列圖像,一次讀入以15°為間隔的9 張正交偏光序列圖,利用實例分割或者交互式分割方法,提取其中的巖石礦物顆粒偏光序列圖像,如圖3 所示。

圖3 利用分割方法得到的礦物顆粒序列圖Fig.3 Mineral grain sequence map obtained by segmentation method
(2)對每一組提取出來偏光序列圖像,找到序列圖中處于消光位的顆粒圖像,并以該圖像為基準對序列圖重新排序。
①把原來的9 張礦物顆粒RGB 序列圖記為rgb={r1,r2,r3,r4,r5,r6,r7,r8,r9},根據(jù)RGB 值與灰度值之間的轉(zhuǎn)換關(guān)系,將其轉(zhuǎn)換為9 張灰度序列圖,記為gray ={g1,g2,g3,g4,g5,g6,g7,g8,g9};
②在9 張灰度序列圖中,計算每張圖像的灰度值總和,并記錄灰度值總和最低的圖像序號,如第四張圖g4;
③將原礦物顆粒RGB 序列圖中第四張(序號r4)之前的圖添加到序列圖末端,結(jié)果為rgb ={r4,r5,r6,r7,r8,r9,r1,r2,r3},此時偏光序列圖消光位校正工作已完成。
2 結(jié)合改進的SKnet 與Bi-GRU 的礦物顆粒識別算法
針對采集處理后的巖石礦物顆粒偏光序列圖像,巖石顆粒成分的識別不僅需要考慮單個圖像中的紋理、亮度等特征,還需要結(jié)合不同正交偏光角度下的圖像之間的關(guān)聯(lián)信息。本文將二維序列圖像類比于視頻分類的方式進行巖石礦物顆粒成分識別,提出一種基于卷積神經(jīng)網(wǎng)絡(Convolutional Neural Network,CNN)和循環(huán)神經(jīng)網(wǎng)絡(Recurrent Neural Network,RNN)的巖石礦物顆粒識別網(wǎng)絡,CNN 采用改進的SKnet 進行特征提取,同時利用雙向門控循環(huán)單元(Bidirectional Gated Recurrent Unit,Bi-GRU)提取巖石礦物顆粒偏光序列圖像的前后關(guān)聯(lián)特征,完成識別任務,其框架如圖4 所示。
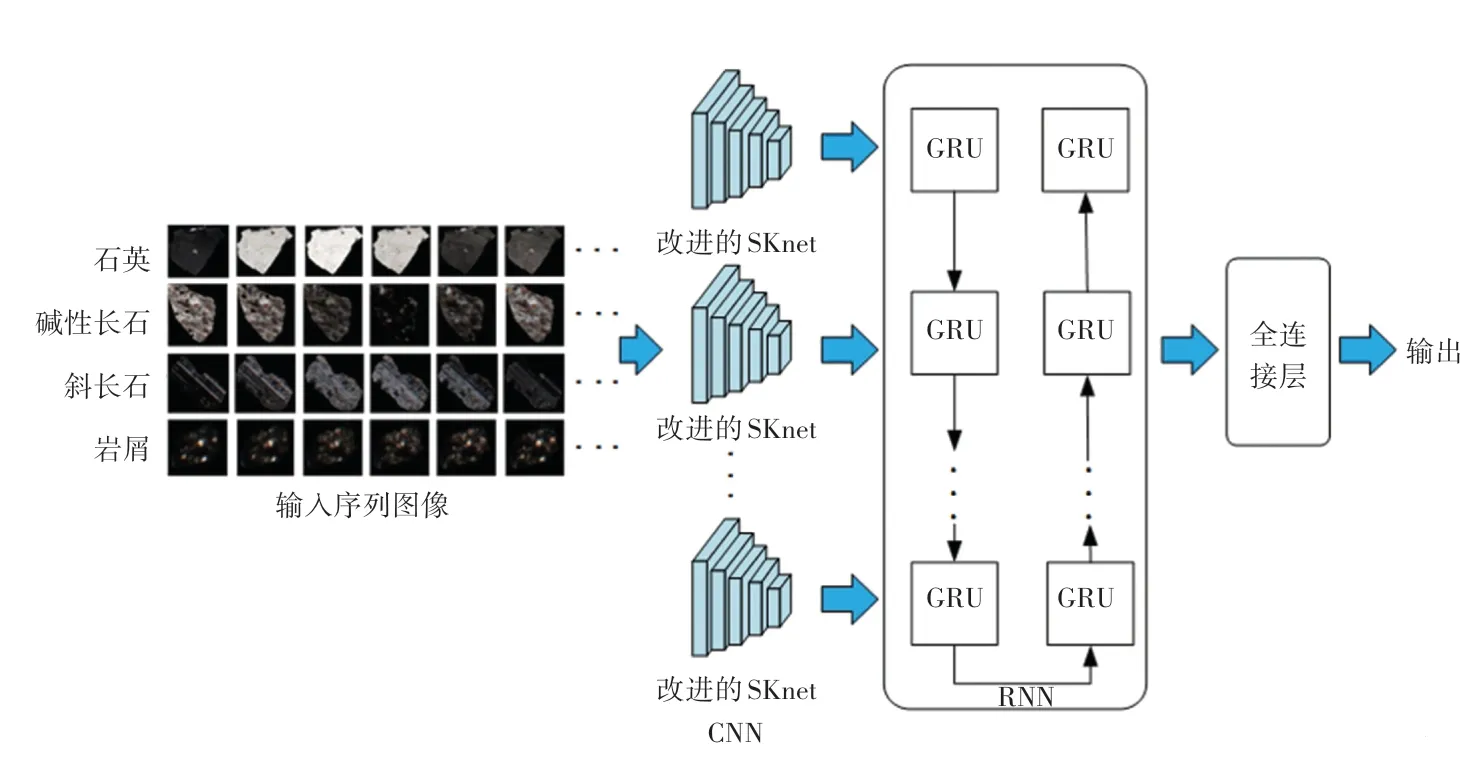
圖4 結(jié)合改進的SKnet 與Bi-GRU 的礦物顆粒識別框架Fig.4 Combining improved SKnet with Bi-GRU for mineral particle identification framework
整體輸入為巖石礦物顆粒正交偏光序列圖像,通過改進的SKnet 特征提取模塊對每一張偏光序列圖像提取特征;將提取出來的特征送入后續(xù)雙向GRU 循環(huán)神經(jīng)網(wǎng)絡模塊進行序列維度的信息建模;最后,利用全連接層得到最終的分類識別結(jié)果。本文采用交叉熵作為損失函數(shù),計算公式為
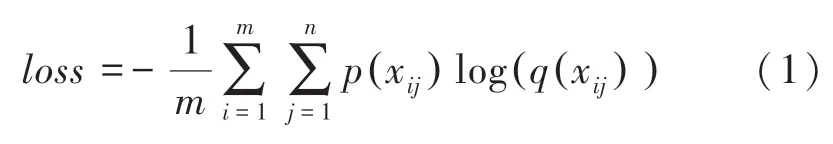
其中,p(xij)表示第i個樣本的真實標簽為j,q(xij) 表示第i個樣本預測為第j個標簽值的概率,共有n個標簽值,m個樣本。
2.1 加入空間特征融合的SKnet 特征提取模塊
SKnet 網(wǎng)絡由多個SK(Selective Kernel)單元堆疊而成,通過SK 卷積以非線性的方法聚合來自不同卷積核大小的特征,進而實現(xiàn)動態(tài)調(diào)整感受野的尺寸,便于對巖石顆粒多尺度信息的提取[10]。基礎(chǔ)的SK 卷積由分離、融合和選擇等操作組成。本文在基礎(chǔ)的SK 卷積中添加了空間維度上的特征融合和選擇,利用軟注意力機制使模型關(guān)注到更多重要的區(qū)域,從而提升巖石薄片圖像礦物識別分類的性能。本文改進的SK 卷積的內(nèi)部結(jié)構(gòu)圖如圖5 所示。

圖5 改進的SK 卷積內(nèi)部結(jié)構(gòu)圖Fig.5 Improved SK convolution internal structure diagram
首先是分離操作,對于輸入的特征圖,默認情況下進行兩次轉(zhuǎn)換兩個變換對應的卷積核的尺寸分別為3×3和5×5,并且都是由卷積、Relu 激活函數(shù)、BatchNorm批處理等操作組成。通道特征融合操作,融合的基本思路是設(shè)計一個門控裝置控制流入下一個卷積層中不同分支的信息流。sc表示s的第c個元素內(nèi)容,通過在U的H × W維度上進行壓縮計算得到,其計算過程為
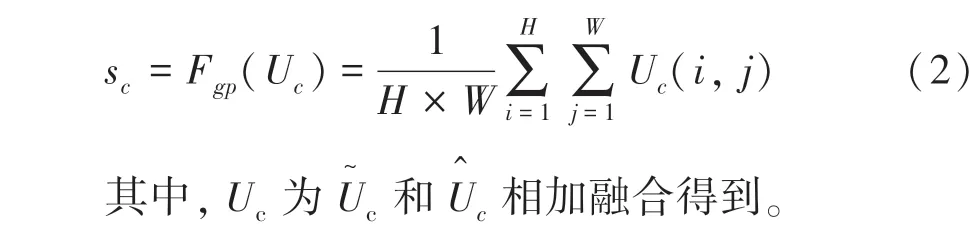
通過全連接層產(chǎn)生一個緊湊的特征圖像用于精確及調(diào)整的選擇,這部分也進行了降維處理,式(3):
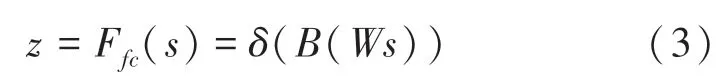
其中,δ表示ReLU 激活函數(shù);B表示批規(guī)范化;W∈RdxC。
為了驗證W中d的作用,采用了一個衰減比r控制d的值,來探究d對于模型效率的影響為
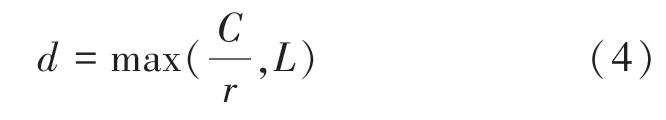
其中,C表示通道數(shù),L為d的最小值。
在壓縮特征描述符z的引導下,采用跨通道的軟注意機制自適應選擇不同空間尺度的信息,ac和bc分別為軟注意力矢量,通過對各個核的注意權(quán)值分別得到,式(5):
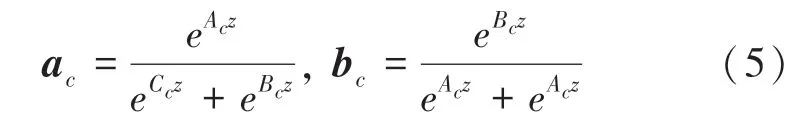
其中,A,B∈RC×d,Ac∈R1×d表示A的第c行,Bc∈R1×d表示B的第c行。
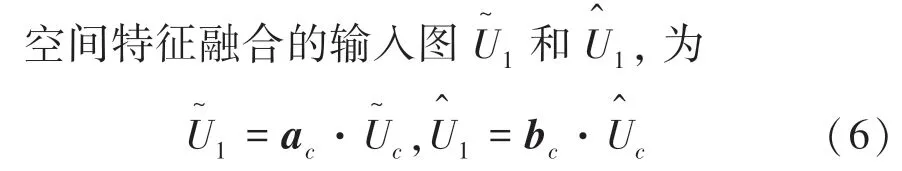
使用空間注意力融合操作來關(guān)注圖像哪些區(qū)域特征更有意義。不同于簡單的像素級相加來整合多分支特征,引入自適應分支特征融合,實現(xiàn)不同特征的高效融合,具體為不同分支的特征乘上相應的可學習權(quán)重并相加得到新的融合特征。自適應權(quán)重的學習過程為通過連接不同分支的特征圖進行1×1 大小的卷積操作,改變特征圖的通道數(shù),得到與分支特征圖相同尺寸、通道數(shù)為2 的特征圖,2 個通道上的特征圖分別表示為Aij和Bij,然后通過softmax 函數(shù)對其進行處理,分別得到不同分支特征的融合比例矩陣為
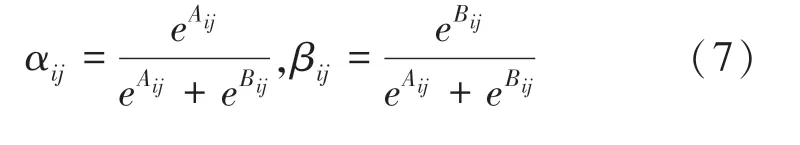
針對于兩個分支特征圖中同一位置的像素點,經(jīng)過特征融合策略得到最終輸出特征圖像V,為

本文使用的特征提取模塊總體結(jié)構(gòu)如圖6 所示,包含多個層級,每個層級內(nèi)部由多個SK 單元連接而成,每個層級內(nèi)包含的SK 單元的數(shù)量分別為3、4、6、3。通常情況下,在每一個層級中多個SK 單元的連接方式是簡單的相加組合,不同的SK 單元之間并沒有共享信息,簡單堆疊的方式無法有效地提取想要的特征。因此,本文借鑒Xu Ma[11]等人在2021 年提出的深度連接注意力網(wǎng)絡模式,在堆疊的相鄰SK 單元之間建立連接關(guān)系,使多個單元間能夠進行信息交流,提高了網(wǎng)絡的學習能力。具體的多個SK 單元的連接結(jié)構(gòu)如圖7 所示,由于相互連接的兩個特征在空間、通道等方面維度有所不同,所以分別采用最大池化層和全連接層來實現(xiàn)特征間空間維度和通道維度的匹配。

圖6 特征提取模塊整體架構(gòu)Fig.6 The overall architecture of the feature extraction module
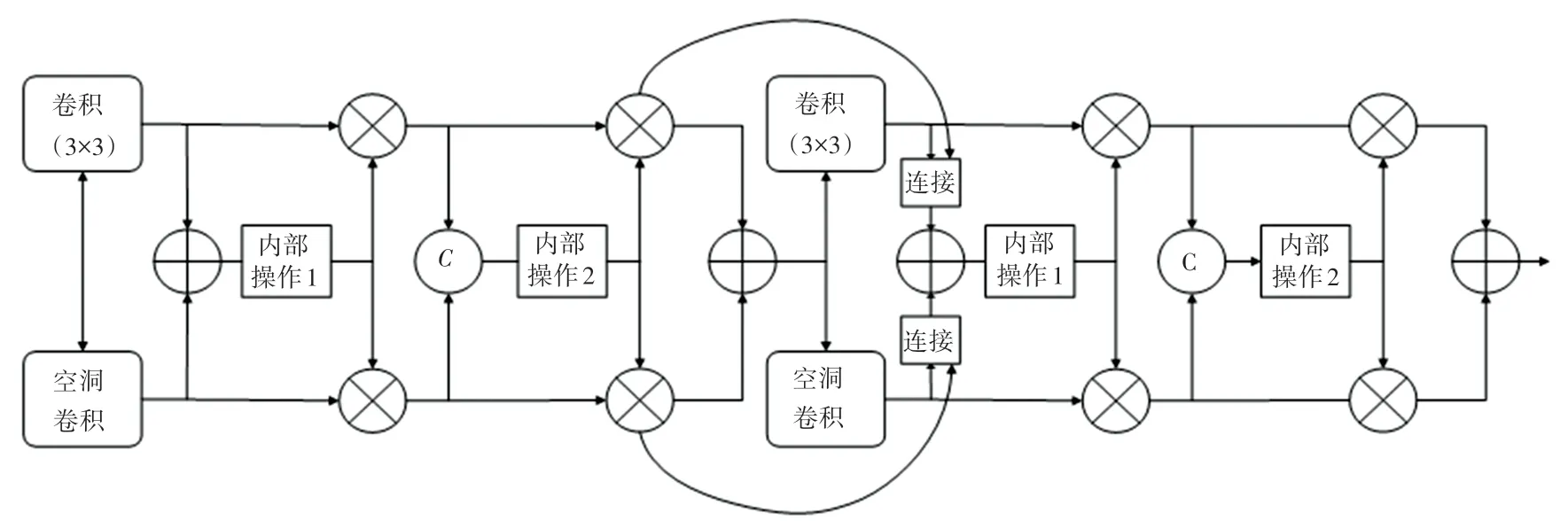
圖7 改進的SK 單元互連結(jié)構(gòu)圖Fig.7 Improved SK cell interconnect structure diagram
2.2 用于時間序列預測的雙向GRU 門控循環(huán)單元
巖石礦物顆粒成分的識別需要結(jié)合正交偏光序列圖像中每一張圖像的特征以及序列圖像的變化信息才能準確的識別礦物顆粒種類。本文采用雙向門控循環(huán)單元(Gated Recurrent Unit,GRU),利用SKnet 提取的序列圖特征信息送入GRU 循環(huán)卷積神經(jīng)網(wǎng)絡,充分的利用巖石礦物顆粒序列圖像的相關(guān)信息。GRU 是基于門機制的,原理類似于長短期記憶(LSTM),依靠歷史信息在當前點做出相應的預測。LSTM 的門機制主要通過輸入門、遺忘門、輸出門來控制記憶單元的信息,解決信息的長依賴問題。GRU 模型改進了LSTM 的門機制結(jié)構(gòu),比LSTM 更加簡潔,訓練效率相對較高。GRU 也是典型的RNN 架構(gòu),通過結(jié)合序列樣本中當前樣本的信息和上一個樣本的隱狀態(tài),計算當前樣本的隱狀態(tài)并向下繼續(xù)傳遞。GRU 的內(nèi)部結(jié)構(gòu)如圖8 所示。

圖8 GRU 內(nèi)部結(jié)構(gòu)圖Fig.8 GRU internal structure diagram
GRU 有兩個門,一個是重置門,另一個是更新門。更新門控的計算公式為
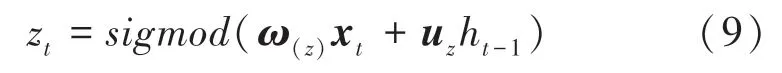
其中,ω(z)和uz為權(quán)重矩陣;xt是經(jīng)過線性變換后時間步長的向量輸入;ht-1保存了上一個經(jīng)過線性變換后時間步長的信息。
將變換后的信息匯總并輸入激活函數(shù),最終的結(jié)果在0 到1 之間變換。更新門決定了歷史信息在傳遞時的比例,復制過去的信息,以減少梯度消失的風險。重置門控的計算公式為

重置門的計算方法與更新門相同,只是改變了用于線性變換的參數(shù)ω(r)和ur。復位門計算非聚焦信息的比例,這些信息稍后會被過濾掉。GRU 結(jié)構(gòu)中還包含一個候選的隱藏層ht,計算公式為
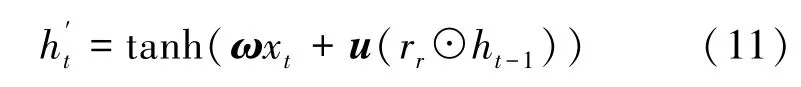
其中,ω和u為權(quán)重矩陣。
候選隱藏層可以理解為當前的記憶內(nèi)容。控制過濾后的信息在隱藏層的比例,將這個信息與隱藏層當前時刻的信息相加,得到隱藏層的最終輸出信息ht,也是當前時刻的最終記憶狀態(tài),計算公式為
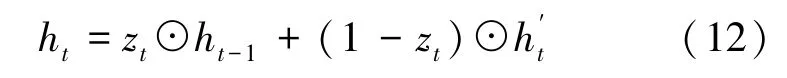
可以發(fā)現(xiàn),該模塊通過應用注意力機制使得zt與1-zt是互相制約與影響的,對于前一個序列樣本的輸出遺忘的越多,當前得到的候選狀態(tài)過濾掉的信息就越少,反之同理。直接丟棄與模型分類無關(guān)的信息,可以在一定程度上解決模型接收到的信息過多的問題,提高模型分類的效率。
單向GRU 的狀態(tài)是從前到后單向傳輸?shù)模簿褪切蛄袌D前面的樣本無法考慮后面樣本序列對前面樣本的影響,很容易忽略后面的序列圖的影響,雙向GRU 是單向GRU 的一種變體,其輸出依賴于向前和向后狀態(tài)的雙重作用,克服了單向GRU 的局限,從而提升基于正交偏光序列圖像的巖石薄片礦物識別網(wǎng)絡的性能。
3 實驗結(jié)果與分析
3.1 數(shù)據(jù)集
本文利用課題組鑄體粒度圖像處理軟件中的交互式分割方法,從大量巖石薄片正交偏光序列圖像中提取出不同類別礦物顆粒偏光序列圖像,以一組偏光序列圖像對應一類礦物顆粒標簽的方式,構(gòu)建礦物顆粒分類識別的原始數(shù)據(jù)集。該數(shù)據(jù)集包含4類礦物顆粒偏光序列圖,分別為石英、堿性長石、斜長石、巖屑。在實際數(shù)據(jù)采集過程中,通常情況下,巖石薄片圖像中斜長石顆粒含量相對較少,其余3種礦物顆粒數(shù)量相對較多。為了防止樣本數(shù)量的不均衡影響最終識別效果,本文根據(jù)4 種巖石礦物顆粒樣本數(shù)量占比,使用圖像幾何變換、仿射變換等方法對數(shù)據(jù)集進行了進一步的擴充,建立最終數(shù)據(jù)集。通過數(shù)據(jù)增廣,石英、堿性長石、斜長石、巖屑4 類礦物顆粒的偏光序列圖像的數(shù)量均達到每類2 000組,按照8 ∶1 ∶1 的比例劃分為訓練集、驗證集和測試集,最終構(gòu)成的數(shù)據(jù)集分布情況見表1。
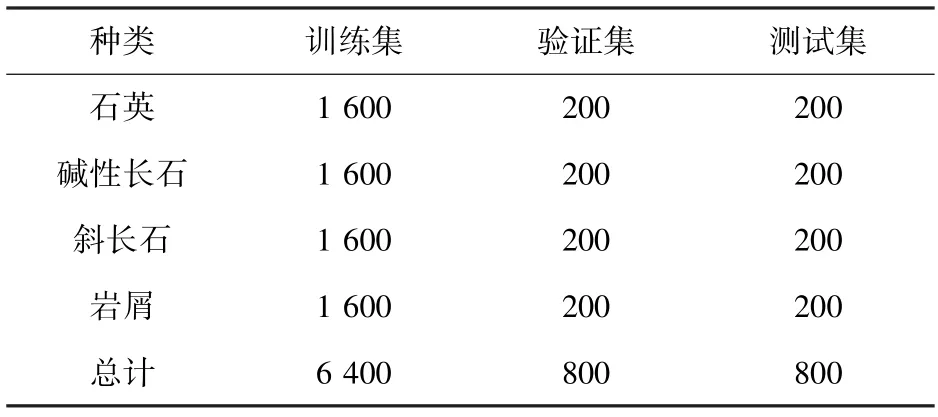
表1 礦物顆粒識別數(shù)據(jù)集Tab.1 Mineral particle identification dataset 個
3.2 實驗環(huán)境
實驗中模型訓練使用NVIDIA RTX2080Ti GPU,顯存為32 G,CPU 為Intel(R)Core(TM)i7-9700。實驗環(huán)境基于Ubuntu20.04 系統(tǒng),使用CUDA 9.0 加速運算平臺,深度學習的框架使用Pytorch-1.2.0。
在送入網(wǎng)絡訓練之前對巖石礦物顆粒正交偏光序列圖像進行消光位校正處理,然后將圖像數(shù)據(jù)調(diào)整為224×224,再進行歸一化操作,批處理大小設(shè)置為8,初始學習率設(shè)置為0.001,訓練迭代次數(shù)為400,使用隨機梯度下降優(yōu)化器,并且采用poly 策略調(diào)整學習率。
3.3 評價指標
本文使用混淆矩陣展示所提出的基于改進的SKnet 和Bi-GRU 的巖石薄片圖像礦物識別方法對4 類巖石礦物顆粒的預測結(jié)果,同時反映影響模型預測準確性的樣本分布情況。此外,為了評估本文提出的方法面向不同巖石礦物偏光序列圖像在識別性能上的差異,采用識別率作為分類網(wǎng)絡的評價指標。識別率反映了每一類礦物顆粒正確分類的數(shù)量占該類礦物顆粒實際總數(shù)量的比例,識別率越高,表明正確分類的數(shù)量越多,公式為

其中,ni為第i類礦物中正確分類的數(shù)量,Ni為第i類礦物顆粒實際總數(shù)量。
3.4 結(jié)果分析
根據(jù)本文提出的方法,利用礦物顆粒序列圖像預測和真實類別的識別結(jié)果,建立混淆矩陣見表2。表2 中每一行代表該類別的判別結(jié)果的數(shù)量,識別正確的數(shù)量除以該類別實際總數(shù)即為該類別的召回率。每一列為其他類別識別為當前類別的數(shù)量,識別正確的數(shù)量除以列內(nèi)數(shù)量總和即為該類別的精確率。可以看出本文提出的分類模型準確率和召回率都達到90%以上,說明利用本文提出的分類方法,石英、堿性長石、斜長石、巖屑這4 類礦物可以被有效的區(qū)分開。
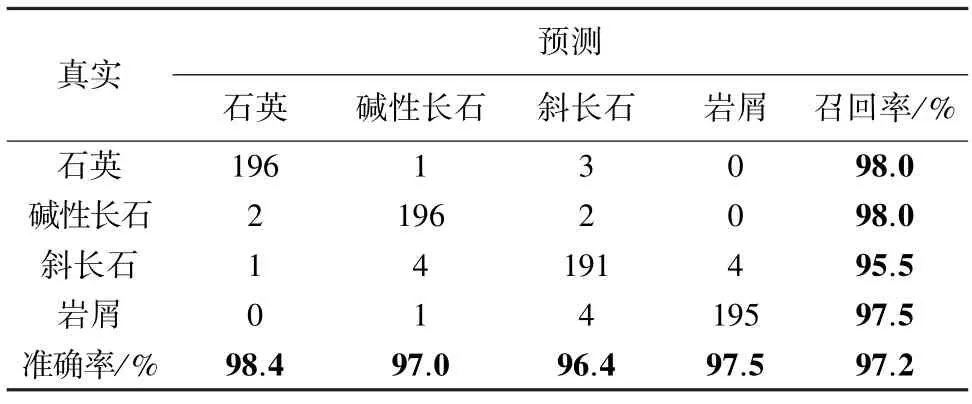
表2 基于本文分類方法的混淆矩陣Tab.2 Confusion matrix based on the classification method in this paper
為表明本文所采用的巖石礦物顆粒識別方法的有效性,將本文提出的方法與現(xiàn)有的一些礦物顆粒識別算法進行了對比,對比結(jié)果見表3。
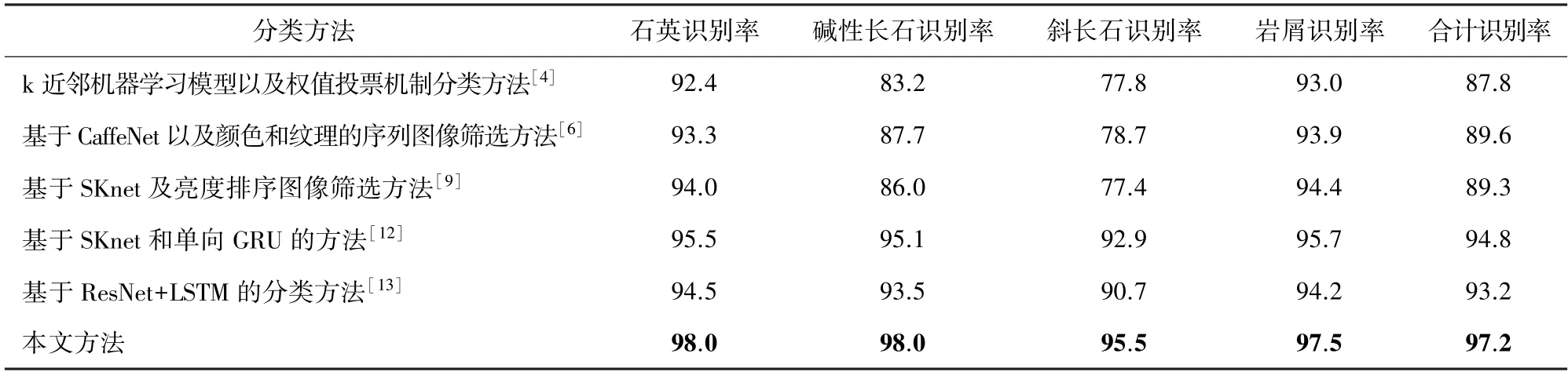
表3 本文提出的方法與其他方法的實驗結(jié)果對比Tab.3 The method proposed in this paper is compared with the experimental results of other methods %
由表3 可以發(fā)現(xiàn),利用傳統(tǒng)機器學習方法實現(xiàn)礦物顆粒分類,總體識別率較低;使用CaffeNet 或SKnet 再結(jié)合一定的圖像篩選方法進行識別分類,針對石英、堿性長石、巖屑顆粒識別率相對較好,但是斜長石顆粒識別率較低,由于礦物顆粒自身特征的復雜性,單張圖像很難將礦物顆粒特征完全表征出來,在某些情況下斜長石顆粒容易被誤識別為堿性長石或者巖屑顆粒;基于SKnet 結(jié)合單向GRU 的分類方法總體來說識別率較前幾種方法已有明顯提升;本文提出的分類方法,更充分的利用了巖石礦物顆粒正交偏光圖像的消光特征,改進的SKnet 以及雙向GRU 門控單元更好的利用了序列圖像的前后關(guān)聯(lián)信息,對于4 種巖石礦物顆粒的識別率都達到了95%以上,相比于已有的算法有明顯的提升。
為了測試本文分類方法中巖石礦物顆粒偏光圖像消光位校正處理以及網(wǎng)絡模型各模塊對最終的識別效果產(chǎn)生的影響,基于本文提出的網(wǎng)絡結(jié)構(gòu),分別進行了使用消光位校正和不使用消光位校正操作的對比實驗測試,使用改進的SKnet 網(wǎng)絡模型和基礎(chǔ)SKnet 網(wǎng)絡模型的對比實驗測試以及使用單向GRU門控單元和雙向GRU 門控單元對比實驗測試,測試結(jié)果見表4。

表4 是否進行礦物顆粒偏光序列圖像消光位校正實驗結(jié)果對比Tab.4 Whether to carry out the comparison of the experimental results of the extinction position correction of the polarized sequence images of mineral particles %
由表4 可以發(fā)現(xiàn),對礦物顆粒偏光序列圖像進行消光位校正,4 類巖石礦物顆粒的最終識別率都得到了一定的提升,經(jīng)過消光位校正后,輸入到雙向GRU 門控單元的序列圖像特征保持了很好的一致性,更有利于網(wǎng)絡學習序列前后圖像的自身特征信息以及關(guān)聯(lián)信息。
使用基礎(chǔ)的SKnet 替換本文提出的改進的SKnet 后,對4 種巖石礦物顆粒的識別率都產(chǎn)生了一定的影響,說明本文利用特征融合優(yōu)化后的SKnet 特征提取模塊,更有效地提取出想要的特征信息,進一步降低了誤識別的概率。雙向GRU 門控單元可以更好的學習巖石礦物顆粒偏光序列圖的序列信息,堿性長石、斜長石、巖屑礦物顆粒的識別率都得到了提升。
4 結(jié)束語
為了更有效地完成巖石薄片偏光序列圖的顆粒成分的分析工作,本文提出了一種結(jié)合改進的SKnet 和雙向GRU 的巖石薄片正交偏光序列圖像礦物顆粒分類方法。首先,利用已有分割方法,從巖石薄片正交偏光序列圖像中提取出石英、堿性長石、斜長石、巖屑4 類巖石礦物顆粒圖像,對提取出的礦物顆粒序列圖做消光位校正處理,將消光位校正后的序列圖作為輸入數(shù)據(jù)進行訓練;其次,利用改進的SKnet 網(wǎng)絡結(jié)合具有記憶的雙向GRU 循環(huán)神經(jīng)網(wǎng)絡,加強對礦物顆粒序列圖中序列特征的提取。本文的方法在已有的數(shù)據(jù)集上表現(xiàn)良好,最終4 類巖石礦物顆粒的識別率都達到95%以上,總體的識別率為97.25%,優(yōu)于已有的巖石礦物顆粒識別分類方法。但本文只針對巖石薄片中相對較多的4 種巖石礦物顆粒進行了分類識別,在實際石油地質(zhì)開采工作中,巖石礦物顆粒的種類十分豐富,在后續(xù)的工作中可以繼續(xù)探索更多巖石礦物顆粒類別下的識別分類方法。
猜你喜歡
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數(shù)理化(高中版.高考數(shù)學)(2022年3期)2022-04-26 14:04:16
數(shù)學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數(shù)學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
