基于雙注意力時間卷積網絡的人體行為識別
2023-01-31 03:37:00王景林劉泓鑠張建鋒
計算機工程與設計 2023年1期
金 博,王景林,劉泓鑠,張建鋒
(西北農林科技大學 信息工程學院,陜西 楊凌 712100)
0 引 言
目前人體行為識別根據獲取數據的方式不同可以分為5種:基于視覺數據[1]的人體行為識別技術有著較高的識別準確率,但是對于數據集質量要求非常嚴格;基于無線網絡數據[2]的人體行為識別是利用無線信號在傳輸過程中遇到人體的遮擋而產生的信號變化特征來識別各類行為,對設備要求較高,部署成本高昂;基于音頻信號數據[3]的人體行為識別是對采集到的音頻信號編解碼處理來識別人體行為,然而采集到的數據存在大量環境噪聲;基于環境傳感器數據[4]的行為識別是根據各類行為所觸發的傳感器數據事件流來對行為進行識別,但設備需要的部署環境要求較高,應用場景局限大;基于可穿戴傳感器數據[5]的人體行為識別通過利用人體所佩戴的加速度計、磁力計、陀螺儀等傳感器進行數據采集,通過使用識別算法實現各類行為識別。
綜合以上分析,本文提出一種基于可穿戴傳感器數據和雙注意力時間卷積網絡的人體行為識別模型。該模型通過改進時間卷積網絡[6](temporal convolutional network,TCN)來提升人體行為識別準確率。首先在TCN中引入雙模塊注意力以便更有效地提取時序傳感器數據中的深層特征信息。其次使用三元組損失(triplet loss)函數來區分傳感器數據相似的異類行為。最后,該模型在公共行為數據集PAMAP2上獲得了較好的識別效果,優于其它行為識別模型。
1 相關研究
在基于可穿戴傳感器數據的人體行為識別工作中,常用的識別算法有機器學習算法和深度學習算法。這兩者的主要區別在于深度學習算法可以主動從數據中獲得高級的特征,而機器學習算法通過人工進行特征提取。在深度學習還未大規模應用時,主要使用的機器學習算法有支持向量機[7]、決策樹[8]、樸素貝葉斯[9]、隱馬爾科夫[10]和K近鄰[11]等算法,但這些算法對缺失的數據比較敏感,不適用于特征數較多的樣本,且對相似行為的識別效果較差,在識別準確率上還需要進一步的提高。
在深度學習算法中,常用于處理可穿戴傳感器時序數據的網絡有循環神經網絡[12](recurrent neural network,RNN)、長短時記憶神經網絡[13](long short-term network,LSTM)及其各類改進網絡模型,但RNN無法捕捉時間序列的長期依賴性,LSTM無法并行處理,這些都影響了行為識別的準確率。如文獻[14]提出了一種基于深度卷積的LSTM網絡模型(DeepConvLSTM),通過卷積層對數據進行特征提取,之后利用LSTM層對提取的特征建立行為識別模型,但對于本文實驗,該網絡較為復雜,容易過擬合。文獻[15]提出了基于殘差網絡的雙向LSTM(Res-BiLSTM)網絡模型,該網絡使用雙向LSTM保證輸出不僅與當前時刻之前的序列數據有關,也與后續的序列數據有一定的結合,引入殘差模塊來解決網絡模型復雜的問題,相較于本研究,該模型在人體行為識別上的準確率還有待提高。文獻[6]首次提出時間卷積網絡模型TCN,該模型相較于RNN和LSTM能夠擁有更快的訓練速度,更好地捕捉時序數據的依賴關系,通過使用因果卷積和膨脹卷積,可以利用靈活的感受野捕捉到更長的時間序列信息特征。文獻[16]首次使用TCN模型進行人體行為識別,實驗結果表明相較于其它網絡模型,該模型具有接收可變長序列的能力,且時間復雜度低,運算速度比較快,可以更好地捕捉時序數據長期依賴關系,在人體行為識別研究中有較好的表現。但該模型在傳感器數據高相似的異類行為中的識別準確率仍有待提高。
注意力機制是根據模仿人類大腦感知行為進行的一種仿生研究。當網絡模型處理時序數據時會出現長距離的信息被弱化的情況,導致模型對特征提取不足。通過加入注意力機制之后,可以快速提取數據中的重要特征,為各類特征分配不同的權重,減少其對外部信息的依賴,因此在處理時序數據時,注意力機制可以發揮更好的性能[17]。故本文引入注意力機制,解決模型提取行為識別深層特征不足的問題。
三元組損失(triplet loss)函數是在人臉識別領域應用較為廣泛的一種損失函數[18],其目的是做到非同類極相似圖片樣本的區分,但尚未應用于基于可穿戴傳感器序列數據的人體行為識別。Triplet Loss函數的主要優勢在于可以很好地進行高相似度樣本區分,當兩個輸入相似時,Triplet Loss函數能夠更好地對細節進行建模,相當于為模型加入了兩個輸入差異性的度量,學習到輸入的更精確表示。故本文引入Triplet Loss函數作為模型的損失函數,解決模型在非同類極相似傳感器數據的行為識別準確率不高的問題。
2 模型設計
2.1 模型結構
本文所提出的網絡模型結構如圖1所示。該網絡結構主要由SMA(sensor-modality attention)模塊、TCN(temporal convolutional networks)模塊、LGA(local-global attention)模塊、全連接層和softmax激活函數組成。
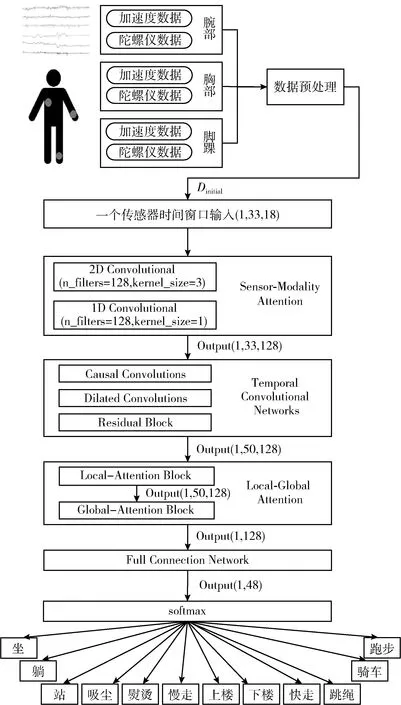
圖1 本文所提模型結構
本文以公共行為數據集PAMAP2[19]的多傳感器時序數據為研究對象,該數據由佩戴在腳踝、胸部和手腕3個身體部位的MPU-6050傳感器獲取。首先,SMA模塊基于傳感器數據與行為之間的關聯性為不同部位的傳感器分配注意力權重值;其次,TCN模塊進一步提取傳感器數據的深層時域特征;再次,LGA模塊對不同時間節點的傳感器特征信息進行加權計算,進而獲得相應的注意力權重值;最后,全連接層和softmax激活函數對特征信息進行分類,從而實現人體各類行為識別。
2.2 SMA模塊
在基于多傳感數據的行為識別任務中,不同部位的傳感器對不同行為的識別結果有著重要的影響,如跑步時,腳踝上的傳感器對行為識別有更大的作用;在熨燙時,腕部的傳感器數據對行為識別的影響更大。因此,本文利用SMA模塊為采集于身體不同部位的傳感器數據分配注意力分數值。
該模塊首先將初始的傳感器數據調整為Dinitial∈T×6N, 其中T=33表示為傳感器時序數據的時間窗口大小,N=3為傳感器的數目以及6表示加速度計的X、Y和Z軸和陀螺儀的X、Y和Z軸的數目之和,共計6軸。其次使用128個3×3大小的卷積核對輸入數據進行二維卷積操作,該操作完成之后使用一維卷積核將特征信息調整為一維數據;再次使用式(1)計算不同傳感器數據的權重值。在本研究中,根據不同身體部位傳感器數據對行為分類的貢獻程度,SMA模塊為腕部、胸部和腳踝處的傳感器數據自適應地分配注意力權重值,其輸出的特征向量定義為S=[s1,s2,s3,…st]
(1)
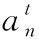
2.3 TCN模塊
TCN通過因果卷積、膨脹卷積和殘差結構在保持梯度穩定傳播的同時捕獲最優的局部特征信息以及數據間的長期依賴性,其結構如圖2所示。
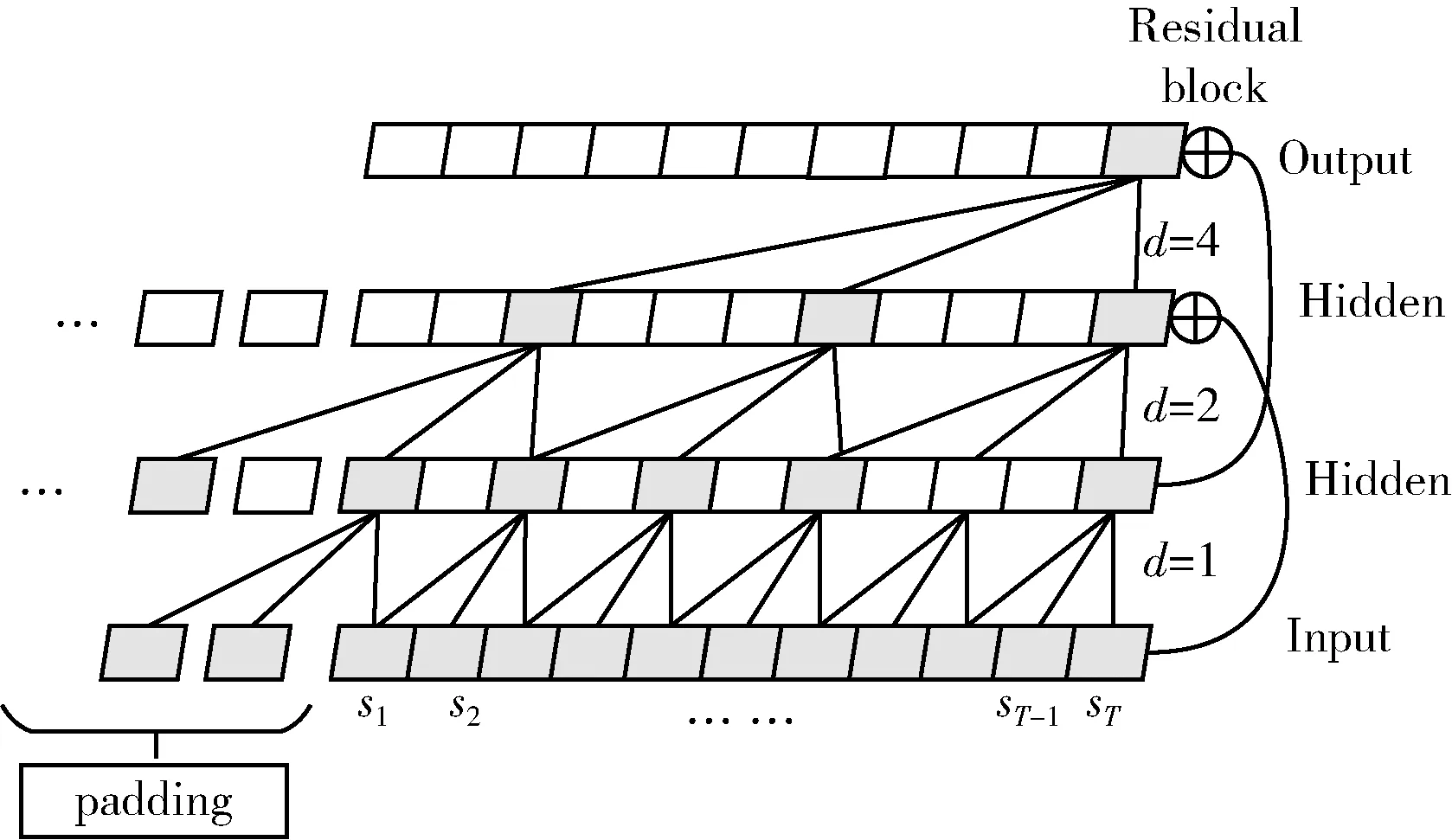
圖2 TCN結構模型
因果卷積只利用上一層t時刻以及t時刻之前的時序性歷史信息作為當前層t時刻的特征表示,而時刻t之后的數據不影響當前時刻的特征提取;膨脹卷積通過增大膨脹因子使卷積核的感受野涵蓋較大范圍的特征信息。TCN模塊的輸入序列,經過TCN模塊處理之后,輸出到LGA模塊。TCN的第i+1層的第n元素處膨脹卷積計算公式如下
(2)
式中:k為卷積核的尺寸,d表示為膨脹因子,其一般按指數變化 (d=O(2i) 其中i為層數)。當膨脹因子增大時,其輸出數據的長度更長,從而保證數據的長時有效性。在本研究中,膨脹卷積可以嵌入較長時間范圍的時序傳感器數據,進而提升特征信息的可靠性。
卷積神經網絡的穩定性隨著時序數據的長度和網絡的深度增加而衰減,TCN通過引入殘差結構[20]來解決網絡的梯度消失問題從而增強其穩定性。由于殘差結構中的縱向歸一化函數WN(weight normalization)受Batch-Size的影響較大而LN(layer normalization)橫向歸一化函數可以綜合衡量每一層中所有維度的數據,計算該層的輸入方差和平均輸入值以及將每個維度的樣本數據都歸一化到相同的分布上,因此本研究對殘差結構進行改進,使用LN替換原始的WN。
本研究使用TCN模塊可以有效地捕捉到時間序列數據的長期依賴性,進而可以充分提取時間序列數據中的特征。與此同時,TCN具有良好的并行計算能力,有助于提升模型訓練速度。
2.4 LGA模塊
為了提升網絡模型學習高維的深層特征的能力,進而提升模型的識別準確率,本研究在TCN模塊的輸出之后引入LGA模塊。該模塊由Local-Attention子模塊和Global-Attention子模塊組合而成。
Local-Attention子模塊通過對比當前時刻的特征與序列中其余所有時刻的特征之間的相似性,進一步獲得特征序列(一個時間窗口時序數據的特征)中每個時刻的相對注意力分數。如圖3所示,該模塊使用多頭注意力機制來捕捉輸入數據的深層信息,圖中的FV表示TCN模塊輸出的特征向量。具體流程如下:
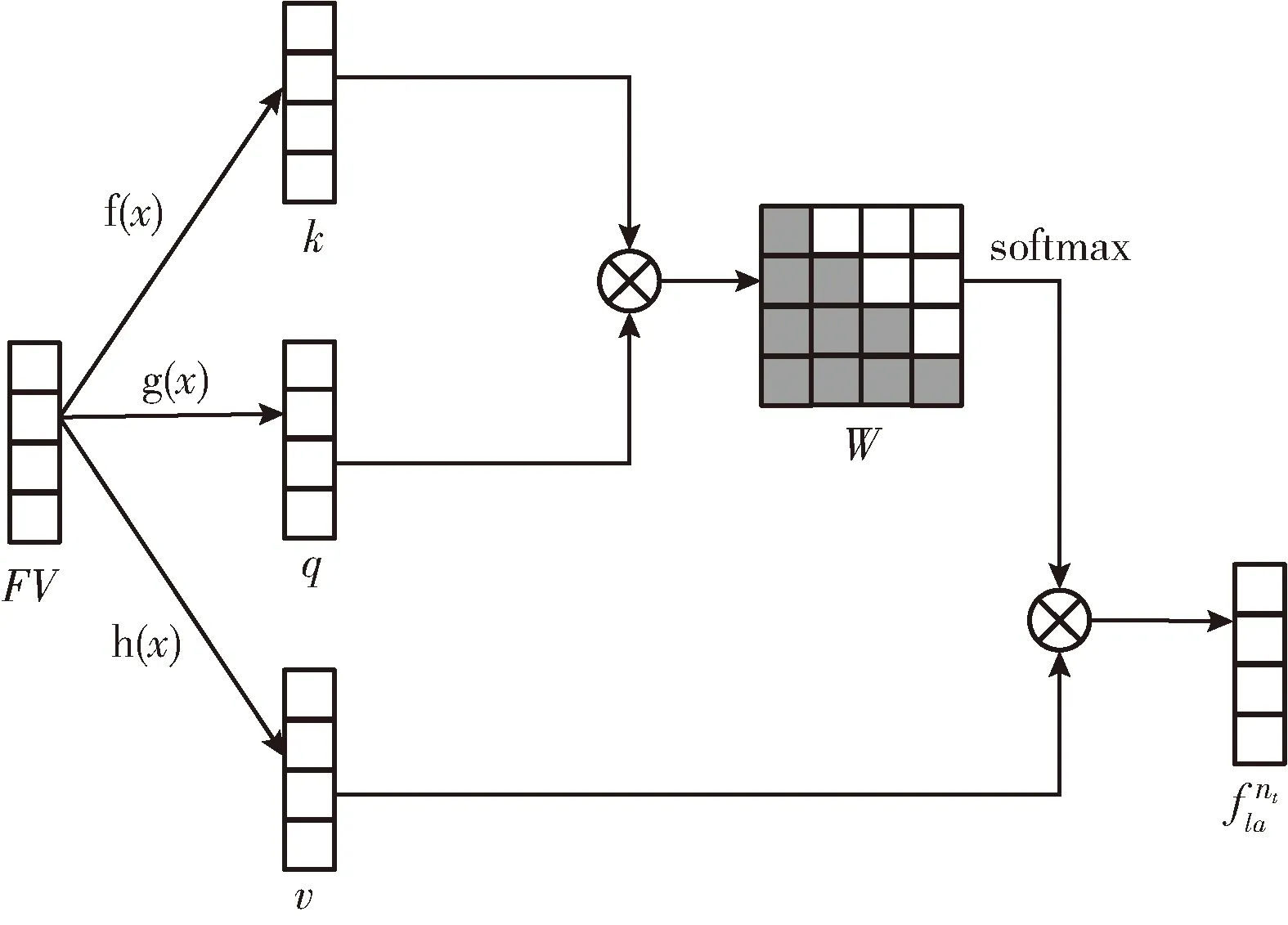
圖3 注意力機制
首先,本文通過3個線性變換f(x)、g(x)和h(x)將特征向量轉化為鍵值向量k、查詢向量q和值向量v,之后利用式(3)計算時間窗口域的每個時刻下采集于不同傳感器的數據的權重值
(3)
式中:n代表多頭注意力機制的頭數,在本次實驗中被設置為4。t代表在時間窗口的某個時刻,t∈(1,2,…T)。 因此每個傳感器數據在時間窗口上的權重值的計算方式如式(4)所示
(4)
其次,如式(5)所示,利用學習參數Wl將多頭注意力的輸出聚合并調整為單注意頭的尺寸,從而得到時間窗口的注意力加權特征矩陣SLA
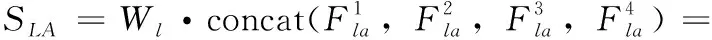
(5)
最后,Global-Attention子模塊以SLA作為輸入,如式(6)所示,利用學習參數Wg、bg和si進行變換后使用非線性激活函數tanh得到gi; 根據式(7)計算注意力權重值向量ai, 并傳入式(8)中,其中gs表示為當前時刻與前后時刻的關聯參數;利用式(8)獲得各個時刻特征向量的加權平均值,隨后將這些具有權重值的特征向量傳入全連接層和softmax激活函數以獲取各類行為的識別結果
gi=tanh(Wg·si+bg)
(6)
(7)
(8)
2.5 三元組損失函數
本文所研究的部分人體行為在傳感器的數據表示上具有極高的相似度,以坐和站這兩類動作為例,志愿者在靜坐時,其上半身處于挺直狀態,上半身姿態與站立時的姿態無明顯差異,加速度儀和陀螺儀無法判斷當前所處高度,因此這兩類行為在數據特征表示上具有極高的相似性。然而,現有算法模型無法有效解決這一問題,從而行為識別的準確率還有進一步提高的空間。
Triplet Loss函數的優勢在于能夠很好地區分細節信息,當輸入的兩類數據具有較高的相似度時,Triplet Loss函數利用困難三元組(hard-batch)對相似的行為進行有效區分。因此,本文使用Triplet Loss函數對模型進行訓練。與其它損失函數相比,該損失函數可以學習到更加豐富的特征。在訓練過程中,根據模型訓練的需要對Triplet Loss函數設置相關閾值,本次實驗中將閾值設置為0.2,其公式為
(9)
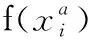
在本研究中,以站和坐為例,Triplet Loss函數的示意圖如圖4所示,anchor樣本和positive樣本是不同志愿者的坐行為,negative樣本是志愿者的站立行為。Triplet Loss函數將本研究中從行為數據中所提取的深層特征作為度量指標信息,縮小同類行為的高維空間距離及增大不同行為的高維空間距離,從而進一步實現高相似度傳感器數據的異類行為識別。
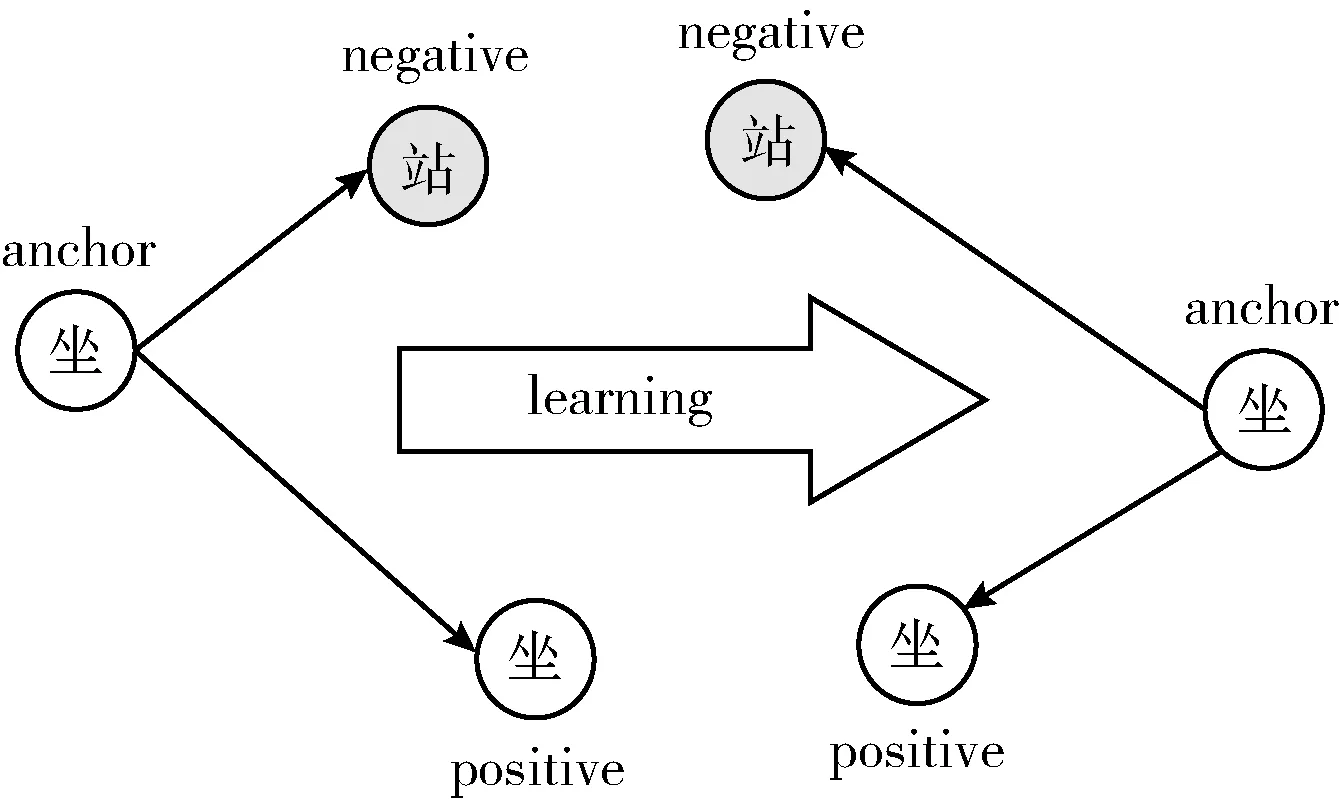
圖4 坐和站—Triplet Loss函數
3 實驗設計與結果分析
實驗首先針對TCN進行優化策略進行對比實驗,其次對TCN損失函數與標準化層進行對比實驗,再對TCN添加不同模塊注意力進行對比實驗,最后將本文所提模型與現有模型進行對比實驗。
3.1 數據集描述
本實驗所采用的數據集來源于加州大學機器學習人工智能實驗室所公布的人體行為數據集PAMAP2[19]。該數據集由9名年齡在24歲~30歲的志愿者在身體的腕部、胸部和腳踝這3個不同的部位佩戴內置加速度計、陀螺儀和磁力計等傳感器進行數據的采集。該數據集包含躺、坐、站、熨衣服、吸塵、上樓梯、下樓梯、慢走、快走、騎車、跑步和跳繩這12種行為數據。原始數據以100 Hz的頻率采集,共采集2 872 352條數據。為了減少非同源數據的量綱和單位的影響,在實驗前對數據進行歸一化處理,保證所有數據點處于相同的數量級,便于后續數據的分析。數據被分為70%的訓練集和30%的測試集。
3.2 評價指標
為了驗證基于注意力機制的時間卷積網絡模型的識別效果,本實驗采用總體分類精度(Accuracy)、召回率(Recall)和精確率(Precision)作為行為識別的評價指標。評價指標的公式如下
(10)
(11)
(12)
式中:TP表示正確預測到正分類結果,即正類被正確地預測為正類;FP表示錯誤預測到正分類結果,即反類被錯誤預測為正類;TN表示正確到預測負分類結果,即反類被正確預測為反類;FN表示錯誤預測到負分類結果,即正類被錯誤地預測為反類。
3.3 TCN模型優化策略實驗對比
基于PAMAP2人體行為數據集,本研究分別使用SGD、RMSprop和Adam策略對TCN進行優化。實驗結果見表1,當使用Adam作為優化策略時,其最高識別準確率為89.64%。相較于RMSprop和SGD這兩種優化算法,有效地提高了1.71%~3.55%。實驗結果表明,結合了多種優化算法的Adam算法可以有效提高模型的識別準確率,但對TCN模型提升能力有限,還需要進一步改進。

表1 不同優化策略方式對準確率的影響
3.4 損失函數與標準化層實驗對比
為了驗證三元組損失函數對TCN識別準確率的影響,使用該損失函數與交叉熵損失函數(cross entropy loss,CE Loss)、指數損失函數(exponential loss,Exp Loss)、二進制交叉熵損失函數(binary cross entropy loss,BCE Loss)和負對數似然損失函數(negative log likelihood loss,NLL Loss)進行對比實驗。
本實驗的結果見表2,在相同的標準化層中,當使用Triplet Loss函數作為損失函數時,模型準確率有一定的提升;在相同的損失函數下,使用LN層優化時,準確率高區其它標準化層。實驗結果表明,調整損失函數為三元組損失函數并使用LN層優化可以有效地提升模型的識別準確率,提升了1.11%~3.91%。
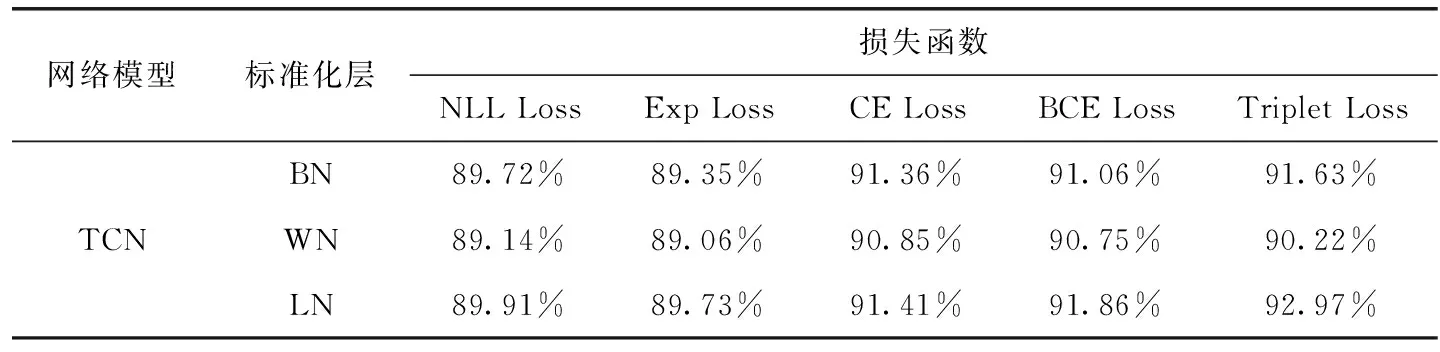
表2 不同損失函數與不同標準化層對準確率影響
3.5 注意力機制實驗對比
為了驗證注意力機制對TCN識別準確率的影響,使用TCN、引入單模塊注意力的TCN模型以及引入雙模塊注意力的TCN模型進行實驗。實驗結果見表3,當TCN加入SMA模塊時,準確率提升了1.46%,加入LGA子模塊時,準確率提升了2.77%。實驗結果表明,當引入雙注意力模塊時,TCN模型的準確率得到顯著性提升,提高了5.98%。

表3 不同注意力模塊對注意力影響
3.6 所提模型與其它模型實驗結果對比
為了驗證所提模型的有效性和先進性,本文將所提出的模型與現有模型如RNN[12]、LSTM[13]、Res-BiLSTM[15]、GRU-RNN[21]、BiLSTM[22]和LSTM-DeepRNN[23]進行對比,對每個模型進行10次實驗,并使用其平均值為最終結果。
本文所提出的模型在訓練集和測試集上的Loss值和Accuracy值如圖5和圖6所示。首先,在50個Epoch內,圖5顯示模型的Loss值呈下降趨勢,降至0.02以內;其次,50個Epoch內,圖6顯示模型的Accuracy值在不斷提升,上升至95%以上;最后,模型的Loss值降至平穩的趨勢且Accuracy值也上升至平緩,穩定在98%附近。與此同時,訓練集和測試集之間的差值較小,表明了本文所提出的模型不僅有較高的識別準確率,且具有良好的穩定性。
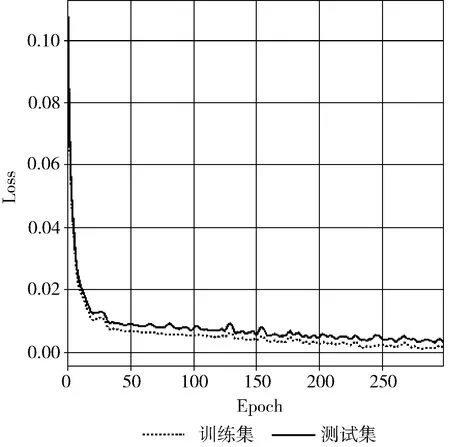
圖5 訓練集和測試集損失值
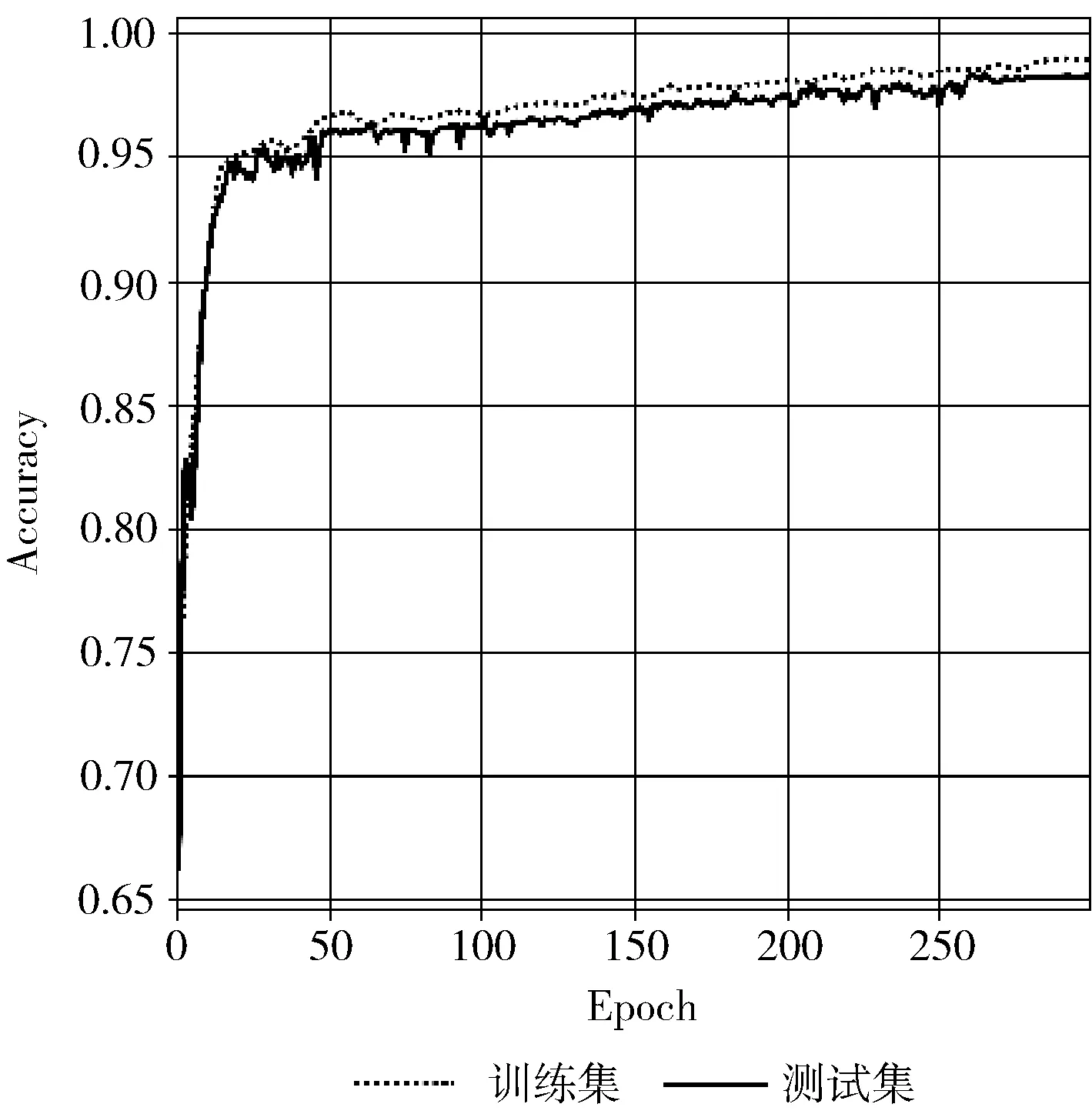
圖6 訓練集和測試集準確率值
圖7表示在測試過程中各類行為組成的混淆矩陣,該混淆矩陣能夠顯示各類行為的識別準確率。由圖7可知,模型對各類行為的識別精度均較高,尤其對坐和站這兩類具有高相似度傳感器數據的行為,識別準確率均高于98%,這反映了三元組損失函數能夠提升模型的學習能力,進而提升各類行為的識別準確率。
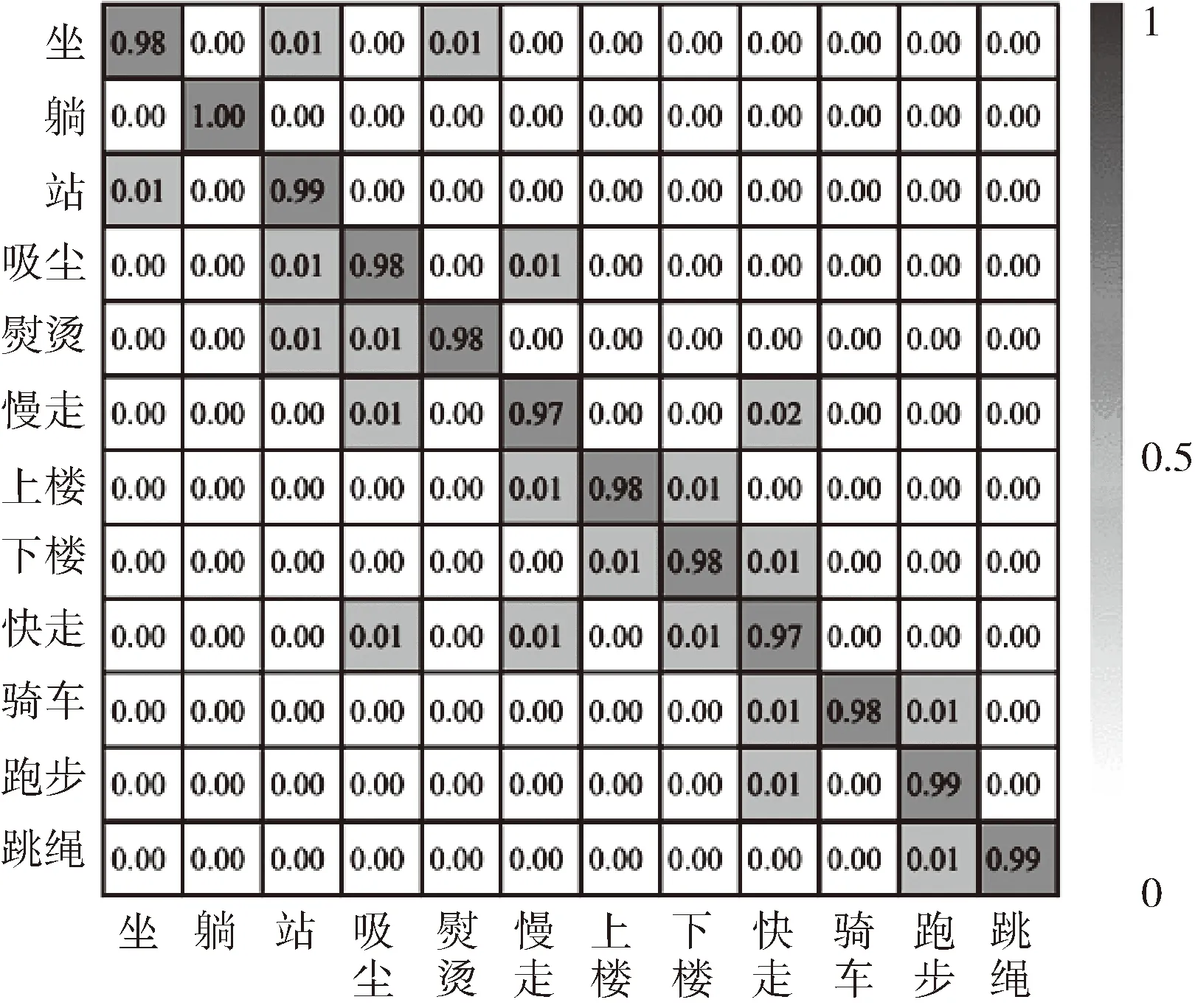
圖7 各類行為準確率的混淆矩陣
本文所提出的模型與其它模型在PAMAP2數據集上的準確率對比結果見表4,其中RNN和LSTM這兩類非混合算法模型的識別準確率最低,其它混合算法模型的準確率相對于二者雖有一定程度的提升,但仍有進一步提升的潛力。實驗結果表明,本文的模型相較于表中的非混合算法模型,識別準確率提升了6.48%~8.65%,與表中的混合算法模型相比,識別準確率提高了2.56%~4.83%。
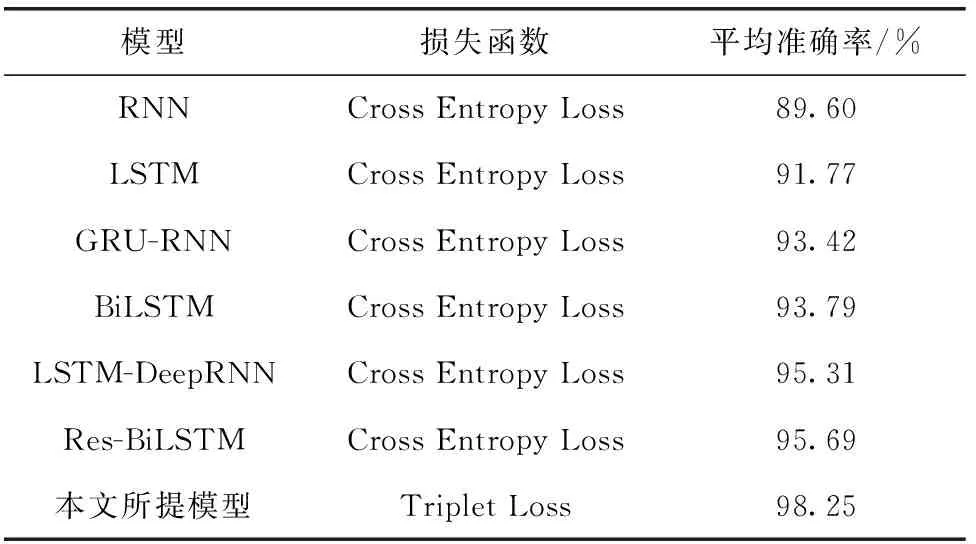
表4 不同算法模型準確率對比
3.7 傳感器注意力分配圖
為了觀察各類行為和穿戴于不同身體部位上的傳感器之間的關系,本文利用SMA模塊中的輸出權重來繪制注意力權重圖。如圖8所示,不同部位的傳感器對行為的貢獻度不同。如熨燙和吸塵這兩類行為,腕部的傳感器權重得分較高,驗證腕部操作對該類行為的貢獻較大。騎車、跑步和跳繩這幾種行為的腳踝部位傳感器權重得分較高,驗證該類行為與腳踝部位關聯性較大。實驗結果表明,本文所提出的模型可以自適應地為不同部位傳感器分配注意力權重值。
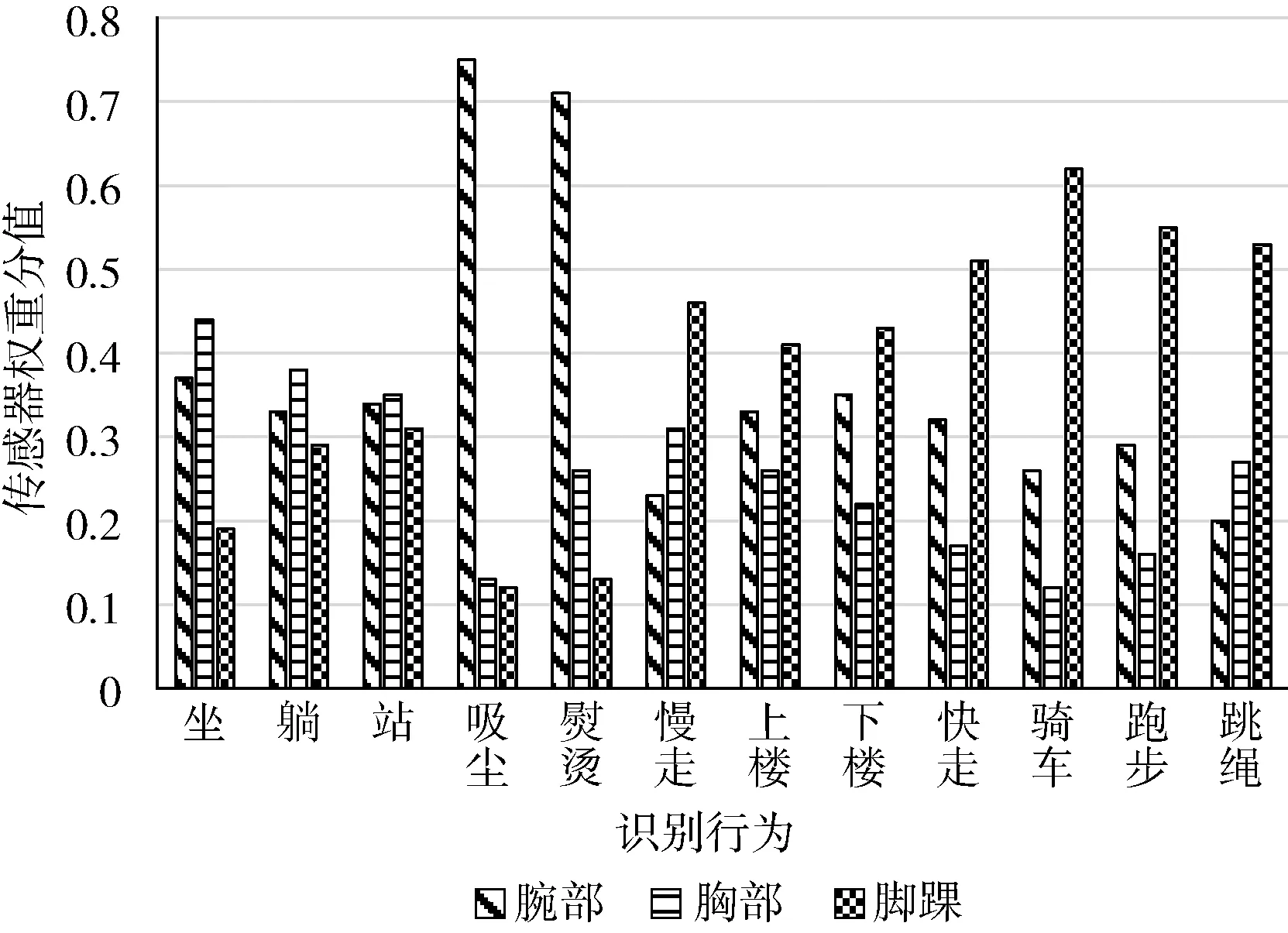
圖8 各傳感器在不同行為中的權重分值
4 結束語
本文從TCN模型在使用可穿戴傳感器數據進行人體行為識別的準確率低的角度出發,針對不同身體部位的可穿戴傳感器數據提出了基于雙注意力機制的時間卷積網絡人體行為識別模型。首先通過引入SMA和LGA這兩類注意力模塊改進原始TCN的網絡結構;隨后創新性地將三元組損失函數應用于傳感器數據行為識別研究中,促使網絡模型提高了對具有高相似度傳感器數據的異類行為識別準確率;最后將該模型應用于公共數據集PAMAP2上,識別結果優于原始TCN及其它現有模型,取得了高達98.25%的平均識別準確率。未來研究中,擬將圖卷積神經網絡應用到多傳感器的人體姿態估計,進而實現更細粒度的行為識別。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
