面向移動視覺的目標檢測模型級聯優化
2023-01-31 03:36:42余德亮李昌鎬
計算機工程與設計 2023年1期
余德亮,譚 光,李昌鎬
(中山大學 智能工程學院,廣東 廣州 510000)
0 引 言
移動視覺任務在當前大量的移動設備和可穿戴設備中廣泛流行使用,移動視覺任務包括道路車輛檢測和監控、行人數量統計、街道導航等任務。解決移動視覺任務采用目標檢測模型,當前主流的目標檢測模型有著計算準確率高、計算速度快的特點,但移動設備無法支撐目標檢測模型龐大的計算量。當前有3類主流工作從不同角度出發解決這一問題。第一類工作從深度卷積神經網絡模型輕量化的角度出發,例如文獻[1-3]。第二類工作是采用端云協同[4]的方法,例如文獻[5-7]。第三類工作是在本地構建優化系統框架,例如文獻[8-16]提出了DeepCache框架,采用重復區域搜索、模型檢測兩層級聯的方式解決移動視覺任務,并利用連續視頻幀存在重復區域特性減少模型計算量。但現有工作包括DeepCache的主要問題是沒有設計適應場景變化的模型級聯方案。
本文提出面向移動視覺的目標檢測模型級聯優化方案,該方案包含模型級聯框架以及模型配置選擇器。模型級聯框架級聯重復區域搜索、小模型篩選、大模型檢測這3種方式,設計不同的選擇方案應用于變化的移動視覺場景。模型配置選擇器提取場景的變化特征信息,選擇合適的模型級聯框架。目標檢測模型級聯優化方案有兩個創新點:①實現了基于掩碼卷積的模型級聯框架;②設計了模型配置選擇器,模型配置選擇器根據場景特征信息選擇合適的模型級聯框架。
1 基于掩碼卷積的模型級聯框架
在移動視覺場景中,連續視頻幀存在著重復區域的特性,模型級聯框架利用該特性在目標檢測的過程中跳過重復區域的計算,減少模型的運算時間。為實現這一功能,本文改進目標檢測模型的卷積方式。模型級聯框架在重復區域搜索和小模型篩選的方式中會給出重復區域的掩碼信息,掩碼卷積結合這一信息跳過對輸入圖像重復區域的卷積計算。
掩碼卷積在基礎卷積方式上進行改動。卷積的計算公式如式(1)所示,其中f為輸入圖像,h為卷積核參數,g為輸出圖像,*為卷積運算符號
g=f*h
(1)
為了讓卷積只計算本文需要的圖像區域,需要對輸入圖像進行掩碼操作,通過掩碼操作的卷積計算公式如式(2)所示,其中σ為掩碼操作
g=σf*h
(2)
掩碼操作后的卷積計算如圖1所示,左圖為進行過掩碼操作的輸入圖像,圖像中的虛線部分即進行掩碼過的區域。在卷積計算中,卷積核跳過虛線部分區域的計算,同時在其對應輸出區域進行填0保證后續卷積計算的有效性,從而得到右圖結果。掩碼卷積的設計會內嵌到小模型和大模型當中。
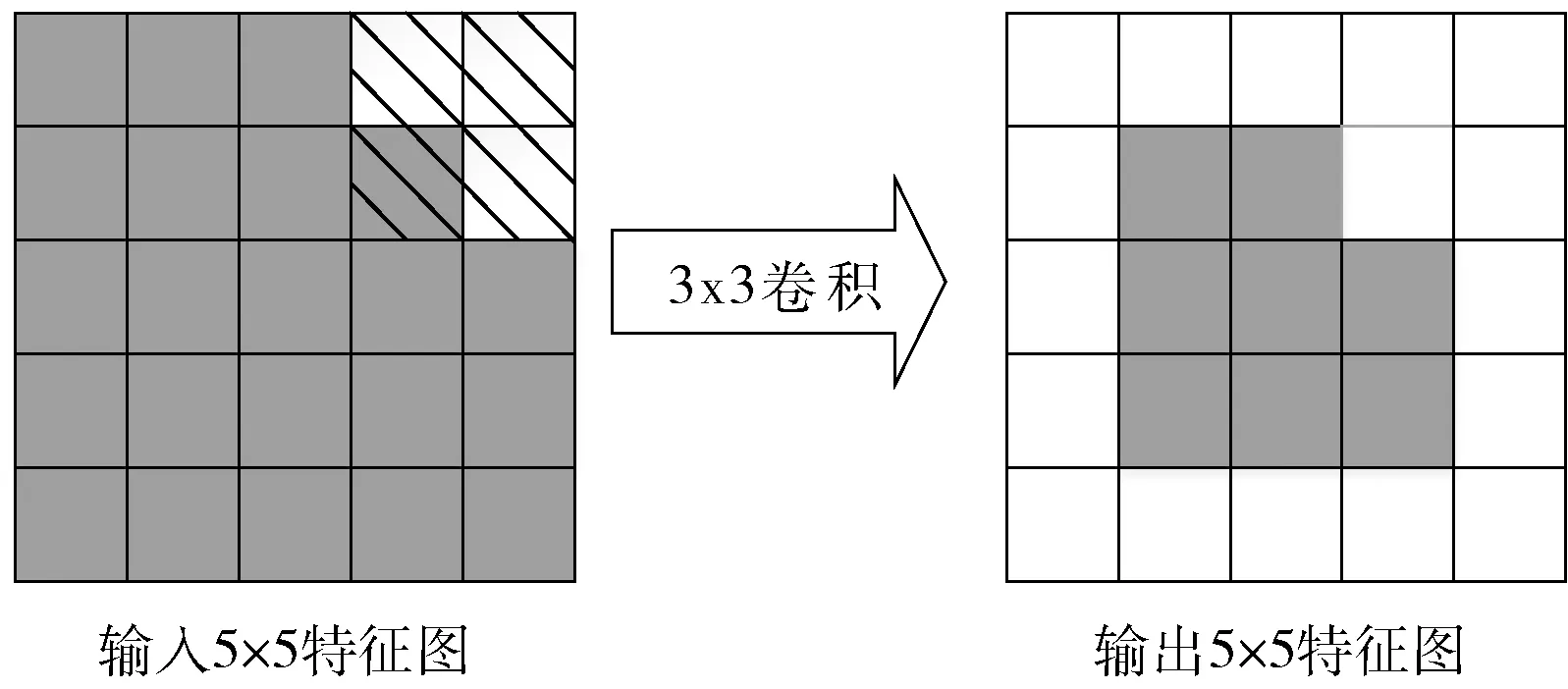
圖1 掩碼卷積細節
模型級聯框架根據搜索算法得到的重復區域生成掩碼信息輸入到小模型當中,小模型根據掩碼信息進行掩碼卷積,得到計算結果。然后模型級聯框架調低小模型的檢測置信度閾值,生成更多可能是目標的區域,根據小模型檢測得到的區域生成掩碼信息輸入到大模型進行計算,此時小模型檢測得到目標的區域為非掩碼區域,而其它區域為掩碼區域。最后大模型對剩余非掩碼區域進行計算得到結果。最終模型級聯框架輸出結果是大模型計算結果以及重復區域在上一幀中出現的計算結果。模型級聯框架如圖2所示。

圖2 模型級聯框架
2 模型配置選擇器
模型級聯框架為場景不同變化狀態提供不同的組合方案,進一步的本文構建以神經網絡為基礎的模型配置選擇器。模型配置選擇器會提取當前場景的變化特征信息,分析并選擇適合當前場景的模型級聯框架。
本文設計的描述場景變化情況提取的特征信息包括:①上一幀圖像的目標數量;②前5幀的平均目標數量;③上一幀圖像中所有目標的平均位移量;④場景的平均位移量。
對于第2個特征信息,連續圖像幀存在重復區域的特性,模型配置選擇器提取上一幀圖像的目標數量可以對當前幀的目標數量分析有幫助,但在對當前圖像幀進行檢測的時候無法預先知道場景出現的目標數量,需要獲取歷史幀目標數量變化的情況,因此本文設計前5幀平均目標數量的特征信息。
在第3個特征信息中,模型配置選擇器計算上一幀圖像中所有目標的平均位移量時,需要結合上一幀和上兩幀圖像的目標坐標信息。對于上一幀圖像中的任一目標,模型配置選擇器會在上兩幀圖像的相同類別目標中計算交并比IOU,尋找得到最大IOU的對應目標,對于最大IOU大于0.7的對應目標,計算這兩個目標中心點的差值,統計上一幀圖像的目標中所有找得到對應目標的差值求平均,得到平均位移量。上一幀圖像中所有目標的平均位移量NMV(x,y) 計算公式如式(3)所示,其中 (xi,yi) 代表滿足條件的待匹配圖像塊坐標, (x′i,y′i) 代表對應的匹配塊在原圖像的坐標,S表示滿足條件的圖像塊集合,N為集合S的元素數量
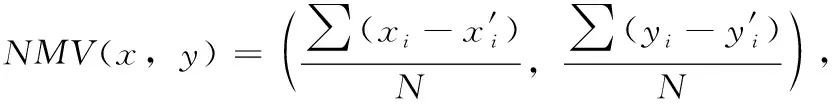
(3)
場景的平均位移量是根據當前幀圖像和上一幀圖像進行分析得到。模型配置選擇器采用多方向搜索算法計算連續幀之間的場景位移信息,該算法流程如算法1所示。該方法通過對圖像分塊,計算相鄰兩幀圖像塊的匹配情況,不僅可以尋找連續兩幀圖像之間的重復區域,還可以根據重復區域計算場景的平均移動向量。在搜索算法計算得到相鄰兩幀圖像匹配的圖像塊集合之后,模型配置選擇器根據式(4)計算平均移動向量MV(x,y), 其中 (xi,yi) 代表滿足條件的待匹配圖像塊坐標, (x′i,y′i) 代表對應的匹配塊在原圖像的坐標,S表示滿足條件的圖像塊集合,N為集合S的元素數量
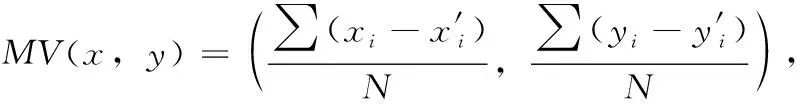
(4)
算法1:多方向搜索算法流程
(1) 初始化imagecurrent, imagepervious, mv_set={}, reuse_set={}, cluster_num=2,T;
(2) for i in N:
(3) for j in N:
(4) blockcurrent, blockpervious=FindMatchBlock(imagecurrent,imagepervious,i,j) //尋找匹配塊
(5) mv=ComputeMoveVector(blockcurrent, blockpervious) //計算位移向量
(6) CollectBlock(mv_set, blockcurrent, mv) //搜集匹配塊
(7) for i in direction:
(8) mv_kmeans(mv_set[i], cluster_num) //采用kmeans聚類方法根據位移向量聚類塊
(9) for i in direction:
(10) for cluster in mv_set[i]:
(11) new_mv=GetMoveVector(cluster) //獲得該聚類簇的平均移動向量
(12) for block in cluster:
(13) matchblock=FindNewMatchBlock(ima-gecurrent, block, new_mv) //根據新的移動向量尋找新的匹配塊
(14) psnr=ComputePSNR(matchblock,block) //計算當前塊和匹配塊的PSNR值
(15) if psnr>T:
(16) blockcurrent∈reuse_set
(17) reuse_set 為可重用區域
搜索算法采用圖像差分法時,會采用多方向搜索算法計算場景的平均移動向量,這種算法在計算場景平均移動向量時所需耗費時間很少,相對于模型計算所需用到的時間耗費可忽略不計。對于視頻數據集來說,每一幀圖像都是一個數據點,模型配置選擇器除了對每個數據點提取上述的特征信息之外,還會分配一個模型級聯框架作為標簽代表當前場景下的選擇方案。為了給每個數據點確定合適的目標檢測框架,本文通過提取的特征信息和目標檢測框架測試結果來選擇最優框架,對于提取的特征信息,本文按場景變化復雜情況分成高中低3類,對應3組不同的模型組合集,每組模型組合集分別包含3種模型組合,在每個數據點分配到對應的模型組合集之后,本文選擇模型組合集里面的所有模型組合對數據點進行測試,再根據目標數量和場景變化快慢再分成3組,相當于每類3組一共9組情況。數據點選擇模型組合的準則在于,數據點在不同的模型組合表現的精度計算會有所不同,這與模型組合的表現力相關,當數據點包含的目標比較少的時候,模型組合表現力即使不用過高也能滿足精度要求,這時候模型配置選擇器會傾向選擇減少模型計算力的方案,而對于數據點包含目標比較多的情況,模型配置選擇器會著重采用表現力較強的方案,而減少模型計算力的方案應放在其次。基于以上準則,雖然模型配置選擇器不能保證每個數據點確定的模型組合最優的,但每個數據點確定的模型組合都是較為合適的。
圖3為模型級聯框架和模型配置選擇器在模型級聯優化方案中的組合關系,在該優化方案中,前5幀圖像會直接采用大模型進行檢測,在之后的圖像幀處理中,圖像緩存器會緩存歷史采集的圖像信息,模型配置選擇器會根據當前采集的圖像和圖像緩存器的信息提取當前場景的特征信息,并根據特征信息選擇合適的模型級聯框架配置,模型級聯框架根據模型配置選擇器提供的配置信息選擇搜索算法和模型組合,并對當前幀圖像進行檢測,得到最終輸出結果。
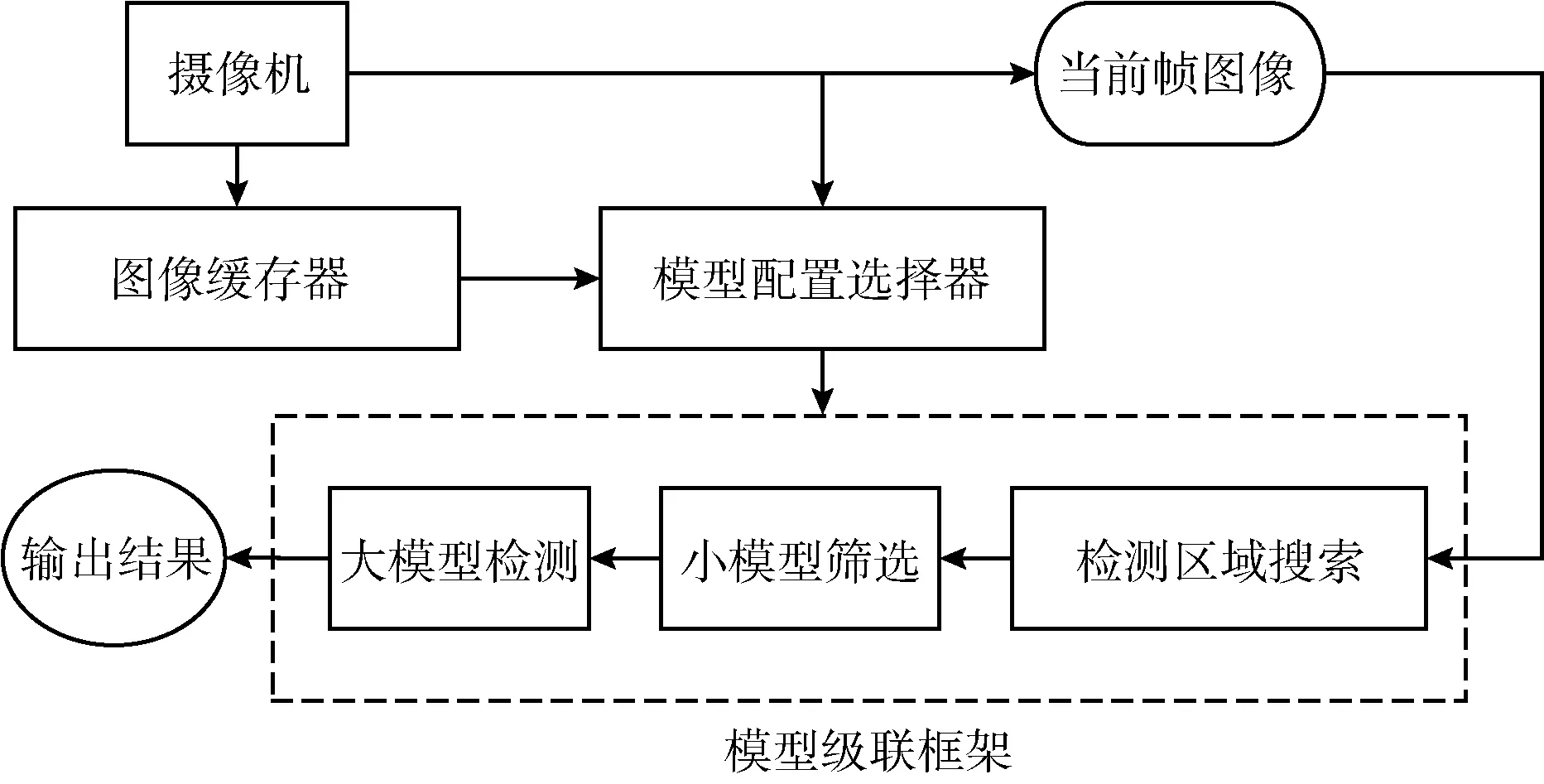
圖3 模型級聯框架和模型配置選擇器的組合關系
3 實驗結果展示
本文實驗在電腦上進行,CPU型號是i7-8700,操作系統是ubuntu18.04。實驗代碼以C++語言基礎,借助ncnn框架設計實現,ncnn框架是面向移動視覺應用部署深度學習的框架。本文實驗為模擬移動設備的實際運行情況,因此主要在CPU上運行實驗。實驗數據采用了KITTI、UA-DETRAC、MOT16、OTB這4種數據集進行挑選組合。其中挑選的數據集先按場景數量和變化情況分成三大類,第一類數據集包含KITTI訓練數據集中的序號12、17,測試數據集的序號15的片段499-644,UA-DETRAC數據集中的序號MVI_40992和OTB數據集的subway;第二類數據集包含KITTI訓練數據集中的序號5、8、10、16、18,以及測試數據集中的序號14的片段428-595和684-849、15的片段279-532和645-700、16;第三類數據集包含KITTI訓練數據集中的序號11、13,MOT16數據中的序號7、14,UA-DETRAC數據集中的序號MVI_40131。
3.1 模型組合
在本文實驗中,采用了一共9種目標檢測模型級聯框架,采用了f1-score的計算方法,模型級聯框架的測試精度和計算時間是在KITTI數據集上測試得到,這里測試的KITTI數據集是所有視頻連續幀組成的圖像集合,計算結果見表1。
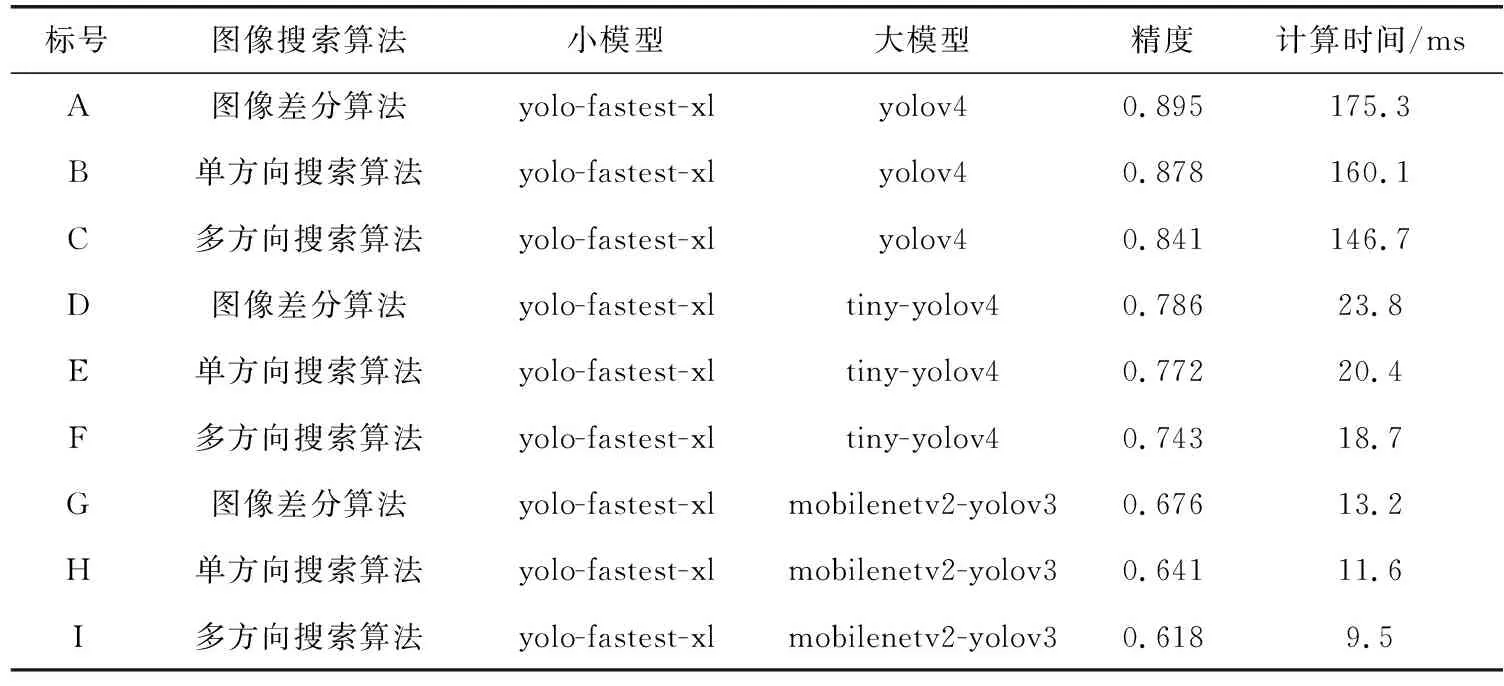
表1 不同模型級聯框架在KITTI數據集中的計算精度和計算時間
圖像搜索算法采用了3種方法,圖像差分算法、單方向搜索算法[13]和多方向搜索算法。圖像差分算法搜索重復區域數量最少,單方向搜索算法搜索重復區域數量其次,多方向搜索算法搜索重復區域數量最多。當搜索重復區域較多時,模型級聯框架花費的計算時間就會越少,但與此同時模型精度會較低,而搜索重復區域較少的時候,模型精度會比較高,但需要花費的計算時間較多。
小模型只選擇了輕量化模型yolo-fastest-xl這一種方案,這是因為小模型的作用在于選擇搜索算法篩選下來的非重復區域中是否有感興趣區域,小模型盡可能選擇目標,而目標檢測結果可以由大模型來保證。在本文的實驗過程中發現選擇滿足條件的不同的小模型去搭配不同的模型組合是對于整體的框架精度和計算時間沒有過多影響。
大模型選擇了3種不同精度和計算時間的模型,其中yolov4精度最高,但在模型計算中耗費時間最長,tiny-yolov4和mobilenetv2-yolov3相比于yolov4雖達不到那么高的精度,但在計算時間上花費遠小于yolov4,tiny-yolov4相比mobilenetv2-yolov3需要花費多一些計算時間,但精度比mobilenetv2-yolov3高一些。大模型判斷小模型篩選出來的目標是否準確,需要有一定的精度要求,但由于需要應用的場景不同,所以在大模型上會有不同的模型選擇。表2是yolov4、tiny-yolov4和mobilenetv2-yolov3在KITTI數據集上的計算精度和計算時間,模型組合C和yolov4比較得到精度減少6.3%,時間減少45%;模型組合F和tiny-yolov4比較得到精度減少6.9%,時間減少52%;模型組合I和mobilenetv2-yolov3比較得到精度減少7.7%,時間減少54%。對比實驗結果可以發現無論是哪種模型應用于模型級聯框架,都可以實現精度損失較少的情況下計算時間大幅度減少的優化方案。本文設計的模型級聯框架在精度上會有些許差距,這是因為在搜索算法的時候會帶來一些精度減少,用小模型進行篩選的時候也會有些許的誤差,但總的來說,在精度減少少量的情況下模型級聯框架可以減少大量的計算時間和模型計算量。
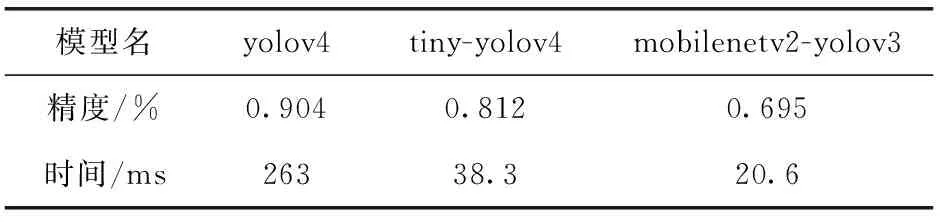
表2 不同模型在KITTI上的測試精度和計算時間
表3給出了主流模型和對應配置的模型級聯框架占用內存量的對比,其中yolov4為大模型的級聯模型框架采用組合C作對比,tiny-yolov4為大模型的級聯模型框架采用模型F作對比,mobilenetv2-yolov3為大模型的級聯模型框架采用模型I作對比。可以看到模型級聯的方式搭建的框架對比同等主流模型消耗的內存量并不多,而當前本文所選擇的主流模型都是可借助ncnn部署在移動端上進行實際運行的,本文設計的模型級聯框架也是借助ncnn框架實現的,也可方便部署在移動端上實現相應功能。
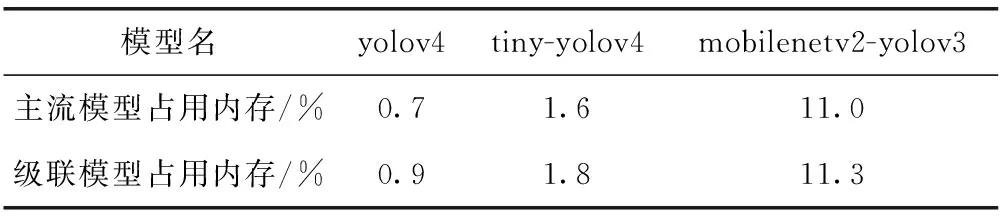
表3 主流模型和級聯模型占用內存量對比
3.2 模型配置選擇器
本文實驗搭建一個模型配置選擇器,在實時檢測的時候可以提取當前視頻圖像幀信息選擇合適的模型級聯框架。用于框架選擇器訓練的訓練數據包含近5000張圖像,每個圖像提取4種特征信息,即①上一幀圖像的目標數量N;②前5幀的平均目標數量EN;③上一幀圖像中所有目標的平均位移量NMV(x,y); ④場景的平均位移量MV(x,y), 由于位移量由向量表示所以一共提取的特征點數量為6個,輸出類別有9種,對應9個模型級聯框架,數據集劃分為9份訓練集和一份測試集,并進行交叉驗證。模型配置選擇器需滿足計算速度快,內存占用少,易于訓練等特點,因此本文選擇神經網絡構建模型配置選擇器,模型配置選擇器構建兩層線性層,每層包含50個神經元,每層輸出之后采用relu作為激活層,學習器采用adam學習器,學習率為0.01,采用20個epoch,每個epoch抽取500個數據點進行訓練,訓練和測試的精度結果如圖4所示,其中x代表epoch,y代表精度,沒有采用更大的epoch是因為模型訓練已經收斂,防止過擬合情況出現。
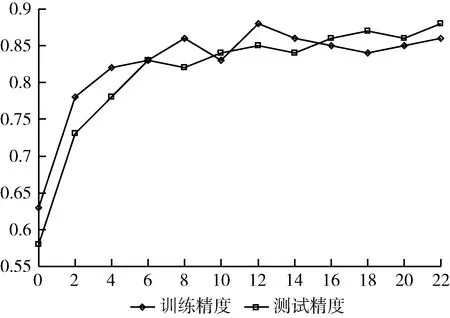
圖4 模型配置選擇器訓練和測試結果
訓練得到的模型配置選擇器在訓練集的精度為0.95,測試集的精度為0.85,由圖4的結果可以看到模型沒有出現過擬合現象,說明這種方法訓練得到的模型配置選擇器具有一定的選擇能力。
3.3 模型組合選擇測試表現情況
為了體現模型選擇的合理性和優勢性,本文從測試集取出3類場景數據集,并根據模型配置選擇器所選的模型在提取的數據的測試精度和所需計算時間進行分析。
第一個連續視頻幀數據集是KITTI測試數據集15中的片段499-644(后面簡稱kitti_test15),包含145張圖片,每張圖片包含4~6個目標,采集該數據集的攝像頭處于靜止狀態,場景中目標移動緩慢。對于該數據集,模型配置選擇器選擇模型組合G進行檢測,本文同時取模型組合A-F對數據集進行檢測,得到的模型精度和模型計算時間如圖5和圖6所示。
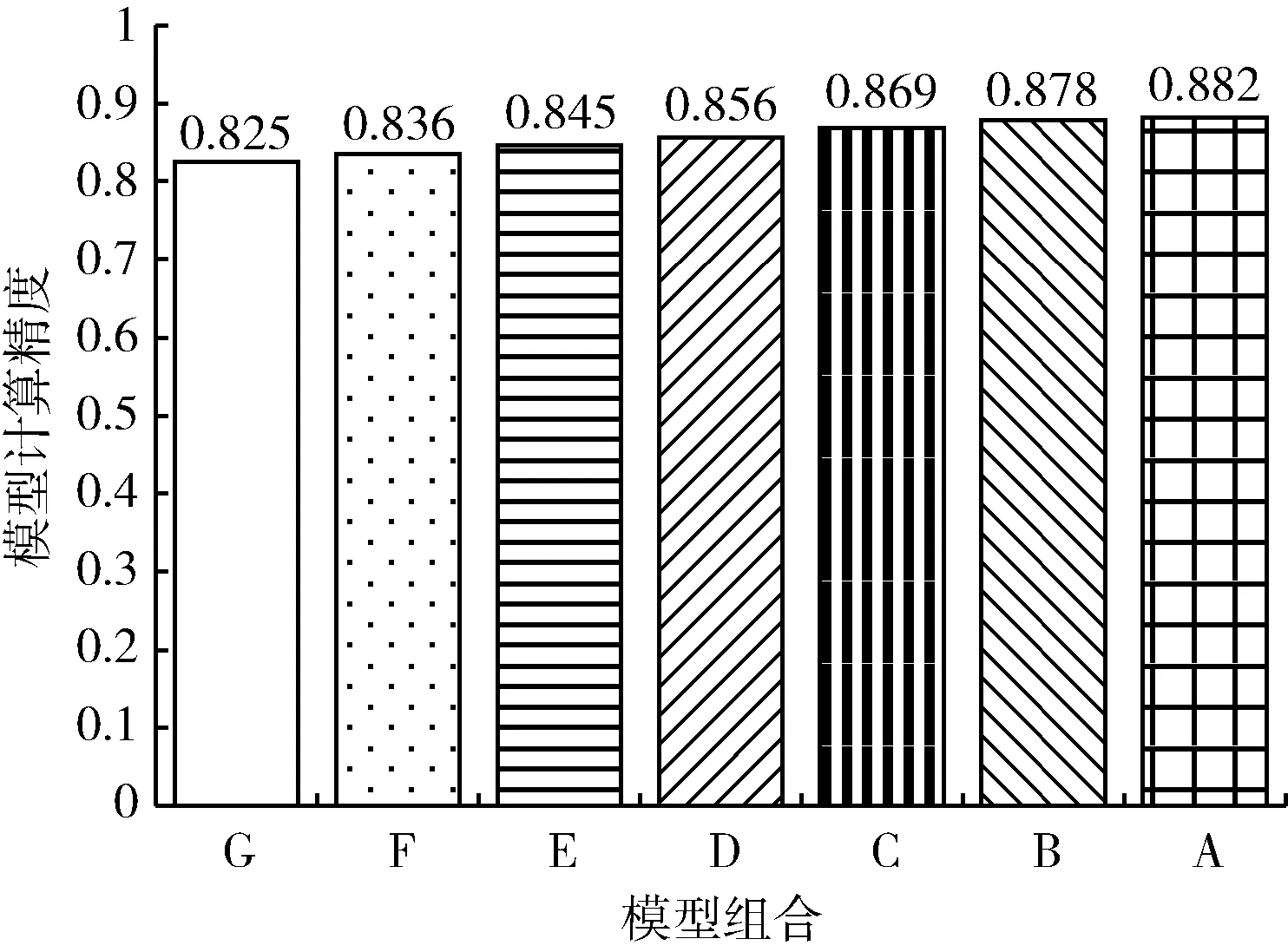
圖5 模型組合A-G在數據集kitti_test15上的測試精度
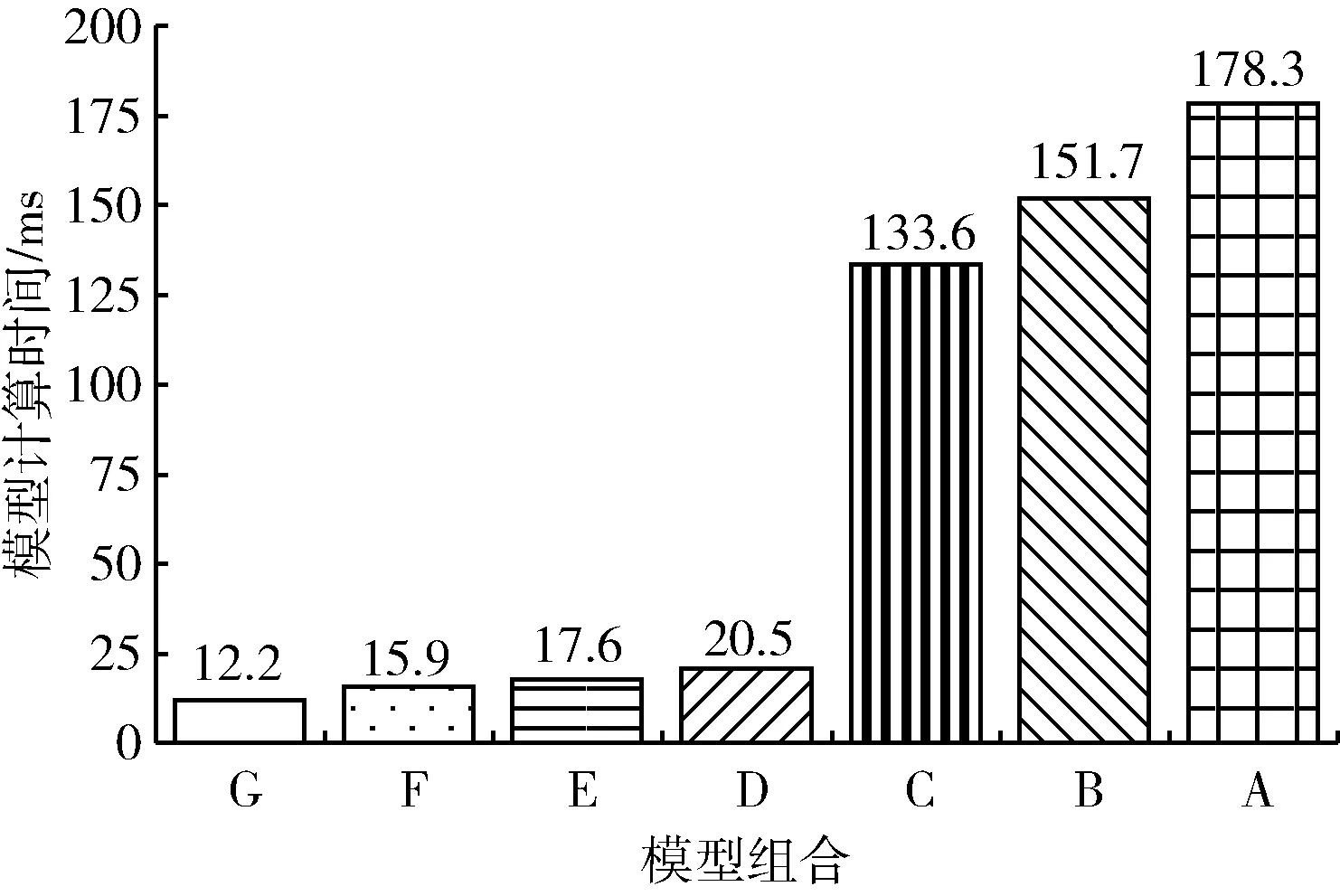
圖6 模型組合A-G在數據集kitti_test15上的計算時間
從圖5和圖6中可以看到,選擇模型組合G和模型組合A-F進行檢測該數據集得到的精度差別不大,最大的差別即模型組合G和模型組合A的精度差為6%,而模型計算時間節省了166 ms。模型組合G在KITTI數據集上測試的精度僅有0.68是因為KITTI包含目標數量多,場景變化大的數據,在這種情況下模型組合G是不具備優勢的,而在數據集kitti_test15中目標數量少,場景變化緩慢,這個時候模型組合G能在花費較少計算時間的情況下獲得較高精度。圖7為當前幀圖像即待檢測圖像,標注即模型組合最終的檢測結果,結合圖7可以看到場景變化緩慢,移動數量也較少,這時候采用模型組合G同樣可以得到較高的精度。

圖7 數據集kitti_test15的例子中當前幀圖像檢測情況
第二個連續視頻幀數據集是KITTI測試數據集14的428-595片段(后面簡稱kitti_test14),包含168張圖片,每張圖片包含8~10個目標,采集該數據集的攝像頭處于緩慢移動狀態,場景中目標移動平緩。對于該數據集,模型配置選擇器選擇模型組合E進行檢測,本文取模型組合A-D對數據集進行檢測,得到的模型精度和模型計算時間如圖8和圖9所示。
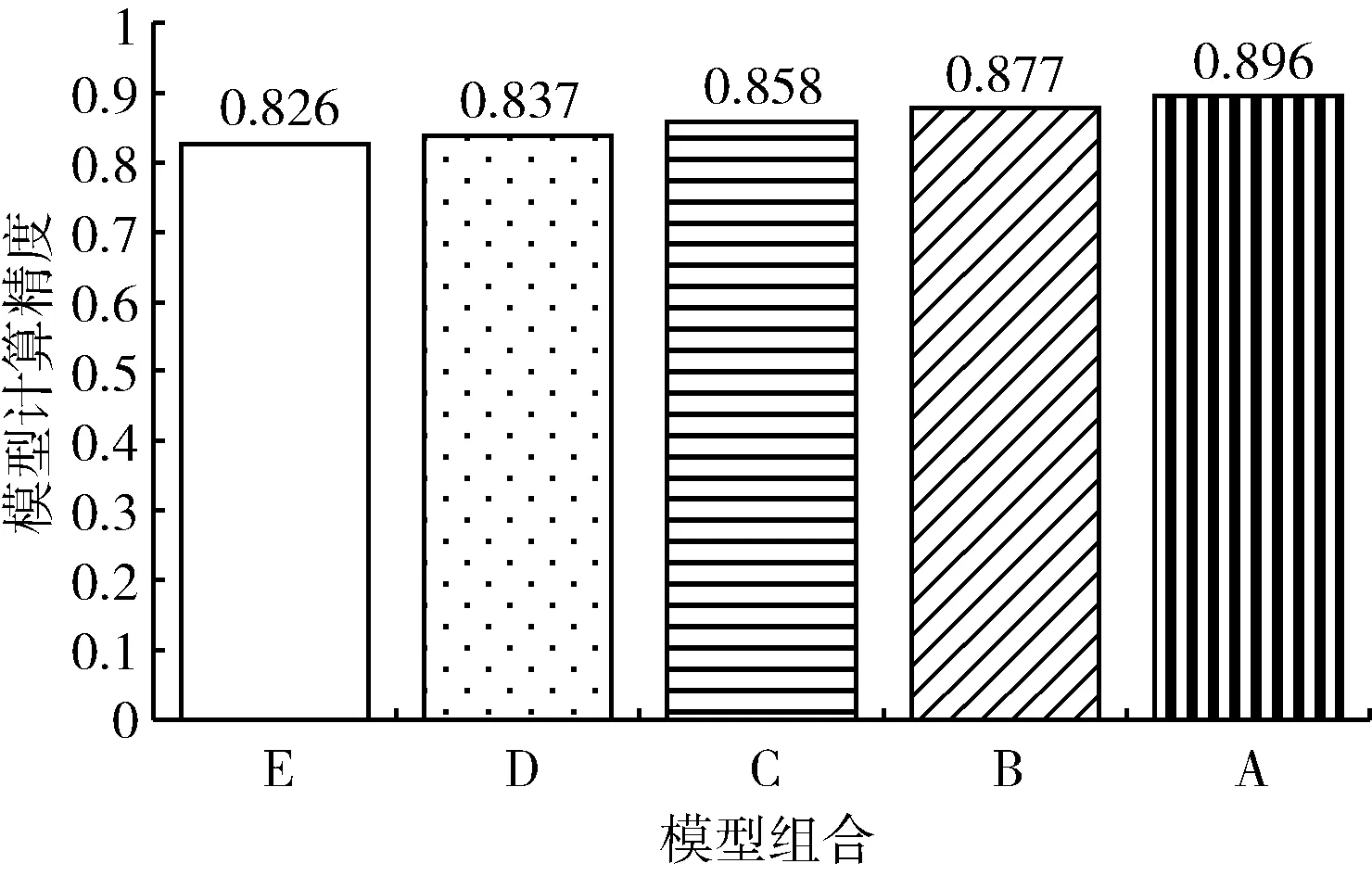
圖8 模型組合A-E在數據集kitti_test14上的測試精度
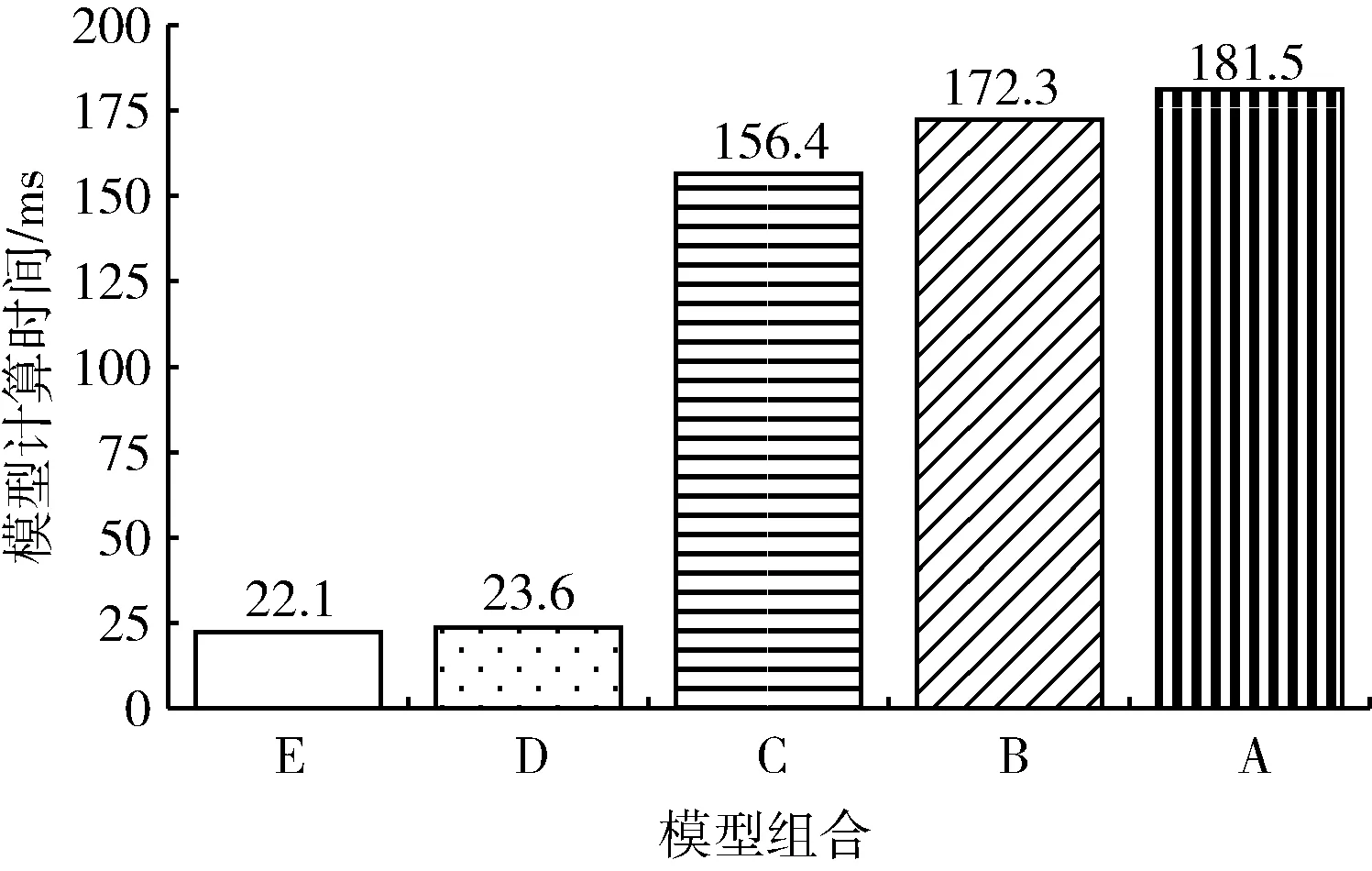
圖9 模型組合A-E在數據集kitti_test14上的計算時間
從圖8和圖9中可以看到,選擇模型組合E和模型組合A-D進行檢測該數據集中得到的精度差別較少,最大的差別即模型組合E和模型組合A的精度差為7%,而模型計算時間節省了159 ms。模型組合E在KITTI數據集上測試的精度為0.77,但它比模型組合G-I相比優勢在變動的場景和目標數量較多的情況有一定的適應性。圖10為當前幀圖像也即待檢測圖像,標注即模型組合最終的檢測結果,結合圖10可以看到場景變化對比第一組數據較快,大部分目標在移動,場景處于不斷變化的狀態,這時候采用模型組合E能夠保證精度較少的情況下節省更多計算時間。

圖10 數據集kitti_test14的例子中當前幀圖像信息
第3個連續視頻幀數據集是第3類數據集UA-DETRAC中序號為MVI_40131的數據集,包含323張圖片,每張圖片包含至少15個目標,采集該數據集的攝像頭處于較快的移動狀態,場景中目標移動較快,場景變化復雜。對于該數據集,模型配置選擇器選擇模型組合C進行檢測,本文同時取模型組合D-I對數據集進行檢測,得到的模型精度如圖11所示。
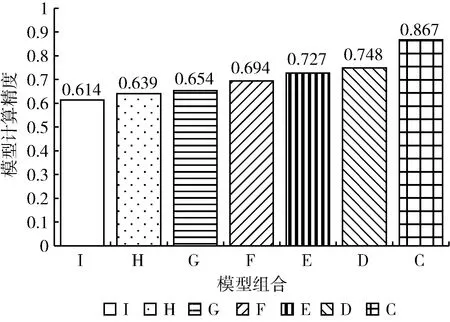
圖11 模型組合C-I在數據集MVI_40131上的測試精度
從圖11可以看到,選擇模型組合E和模型組合D-I進行檢測該數據集中得到的精度差別較大,從D開始精度差別達到了12%,而最高精度差在對比E和I得到為22%。圖12為當前幀圖像也即待檢測圖像,標注即模型組合最終的檢測結果,對于這組數據集,場景中的物體數量多,移動速度快,處于較為復雜的情況,低精度的模型組合會產生較大的精度損失,因此模型配置選擇器更關注高精度模型以滿足需求而非減少計算時間。

圖12 數據集MVI_40131的例子中當前幀圖像信息
4 結束語
本文設計的模型級聯優化方案解決了目標檢測模型如何適應不同場景變化情況。模型級聯框架對比通用的目標檢測模型可以在精度損失減少6%~8%的情況下,計算時間減少40%~55%,而通過模型配置選擇器的設計本文可以適應不同變化情況的場景并針對性的選擇合適的模型組合,在場景變化較平緩的情況模型配置選擇器可以選擇模型精度損失不大,但計算時間較快的模型組合,在場景變化較快的情況下模型配置選擇器可以選擇能夠滿足精度要求的模型。本文的設計仍存在一定局限性,一是假設內存足夠使用,沒有進一步考慮實際內存使用情況,二是本文的模型配置選擇器沒有實現在線學習的策略,可加入在線學習的方式適應更多的場景變化情況,使得模型配置選擇器更具魯棒性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
