改進YOLOv4的實驗室設備檢測算法
2023-01-31 03:36:06李昊霖徐凌樺
計算機工程與設計 2023年1期
李昊霖,徐凌樺,張 航
(貴州大學 電氣工程學院,貴州 貴陽 550025)
0 引 言
近年來,目標檢測技術與各類監控攝像頭結合實現自動監測的應用研究越來越廣泛[1,2];譚暑秋等[3]基于改進YOLOv3算法對教室監控下學生的異常行為進行檢測,提升精度的同時,滿足實時檢測要求;Lu[4]將深度學習技術應用于交通道路監控視頻中的車輛識別,識別效果提升顯著;李明等[5]提出一類改進YOLO-tiny算法對礦井閘板閥開度進行檢測,避免了傳統傳感器監測布線困難、成本高昂等問題;忻超[6]設計的卷積神經網絡結構對監控下機房設備狀態進行實時監測,提高了工作效率,但網絡層數較低,難以應對復雜場景下對象的檢測。Rashmi等[7]從實驗室的監控視頻中提取靜態圖像,利用改進算法對學生在實驗課程中的行為進行識別和定位,達到監督學習、改善教學環境的目的,但沒有針對實驗設備展開研究。
實驗室設備是高校培養人才的重要教育資源,需要有效的維護監管,結合上述研究發展,考慮將目標檢測算法與監控攝像頭結合,實現實驗室設備的自動實時監測,提高管理效率,保障設備財產安全。本文主要研究實驗室監控下設備的檢測問題,與常規應用中檢測對象尺度分布較為均勻的情況不同,實驗室設備位置及大小均基本固定,尺度分布并不均勻。因此本文以深度學習模型YOLOv4[8]為框架,通過改進先驗框的聚類算法來解決尺度分布不均勻帶來的問題,并在主干網絡中引入了ECA(efficient channel attention)通道注意力模塊[9]和改進FPG(feature pyramid grids)特征融合網格結構[10],提高檢測精度,實現對實驗室設備的有效檢測。
1 YOLOv4目標檢測算法
相較于上一個版本YOLOv3[11],YOLOv4最顯著的改進在于引入殘差結構的CSPDarknet53主干網絡和改進PANet[12]的頸部特征金字塔結構,該結構先自頂向下傳遞強語義特征,再由自底向上的特征金字塔傳遞強定位特征,進一步提高了網絡的特征提取與融合能力。CSP結構是將原來殘差塊的堆疊拆分成左右兩個部分:第一部分只經過少量處理;第二部分繼續原來的殘差塊堆疊后,再與第一部分的輸出相加,圖1為其結構示意圖。YOLOv4是目標檢測中最高效的模型之一,融合了系列改進及訓練技巧,在COCO數據集上的mAP相較于YOLOv3有非常顯著的提升,同時保持了優異的速度性能。
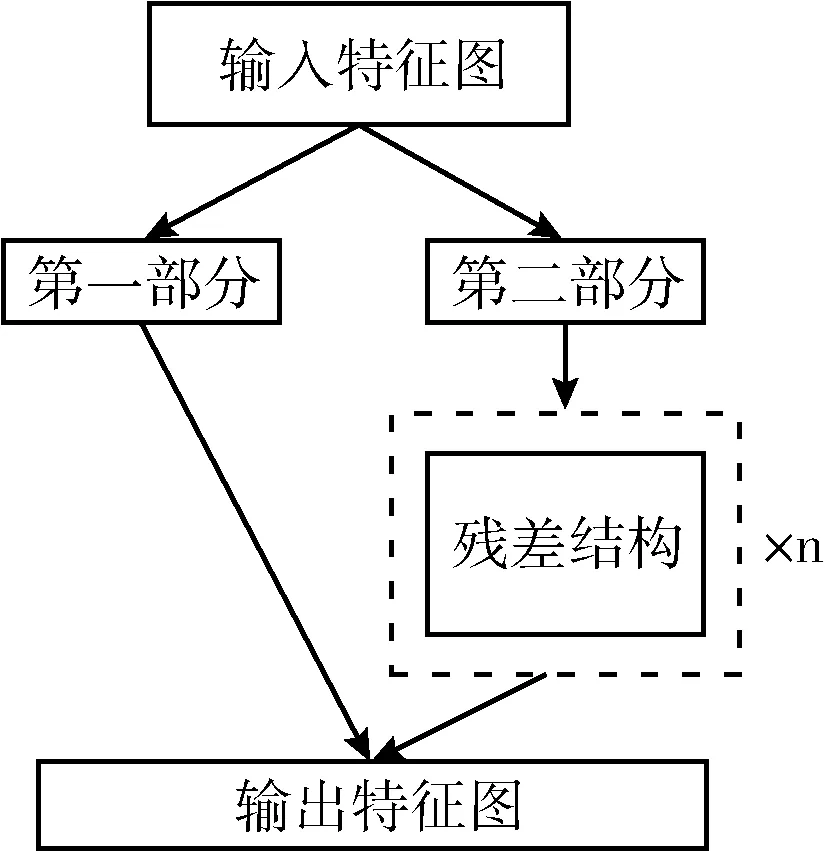
圖1 CSP殘差結構
對于YOLO這一類Anchors based、多輸出層算法,先驗框的選取至關重要,目前各種算法的性能評價一般在COCO數據集上測試,該數據集圖像接近真實生活場景,物體大小整體分布較為均勻,而在實際應用中,部分場景下檢測對象的尺度大小分布并不均勻,使得目前常用的基于K-means聚類算法獲取先驗框的方法有一定局限性,部分網絡分支得不到很好的訓練,浪費網絡,Hurtik等[13]設計的高速路攝像頭檢測車牌的實驗中也驗證了這種情況的存在。
2 模型改進與優化
2.1 數據集先驗框聚類算法改進
K-means聚類算法原理簡單、聚類效果較好,易于實現,因此被應用于YOLO系列算法數據集先驗框的聚類,但該算法存在以下兩點問題:
一是聚類結果受到初始聚類中心的影響較大[14],且初始聚類中心是隨機產生的,因此本文擬使用K-means++算法進行先驗框的聚類。K-means++的特點在其初始聚類中心點的選取上,優先選取距離已有中心點最遠的點作為下一個初始類簇的中心點,確定初始中心點后再進行標準K-means算法聚類。
二是在檢測對象尺度分布不均勻時,K-means聚類的先驗框會使得大小相近的物體被強制分配到不同檢測頭,從而影響檢測精度[13]。在本文實驗室場景下,各類設備的標注框大小只有幾類特定尺度,而K-means算法在聚類樣本滿足以下分布時才有較好的聚類效果
A~u(0,r)
(1)
式中: A={a1,a2,…,an}, 表示一組先驗框,在YOLOv4中,n=9;r為輸入圖像的分辨率;u(0,r) 表示物體大小為0~r之間均勻分布。
YOLOv4的9個先驗框在檢測頭中分為了3組,分別用于檢測小、中、大物體,而在計算機實驗室場景下,設備先驗框大小并不滿足式(1)的分布,因此在使用時會造成尺度大小非常接近的物體被強制分配到不同層進行檢測,即大物體可能被分配到中等物體檢測頭、小物體也被分配到中等物體檢測頭,使得其余兩個檢測頭得不到有效訓練。
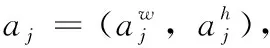
(2)
式中:j=1,2,…,m,m為數據集中所有類標注框的總和;Diag(j) 為所有標注框對應的對角線長度,表示框的大小。
設定3個聚類中心,利用K-means++算法對Diag(j) 聚類,分別得到小、中、大框的聚類中心C0={C1,C2,C3}, 再計算得到閾值Th
(3)
圖2為IK-means++算法流程圖,通過IK-means++聚類算法對實驗室設備圖像數據集的標注框進行聚類,得到先驗框,效果較K-means和K-means++算法均有所提升,對比結果在后續章節給出。
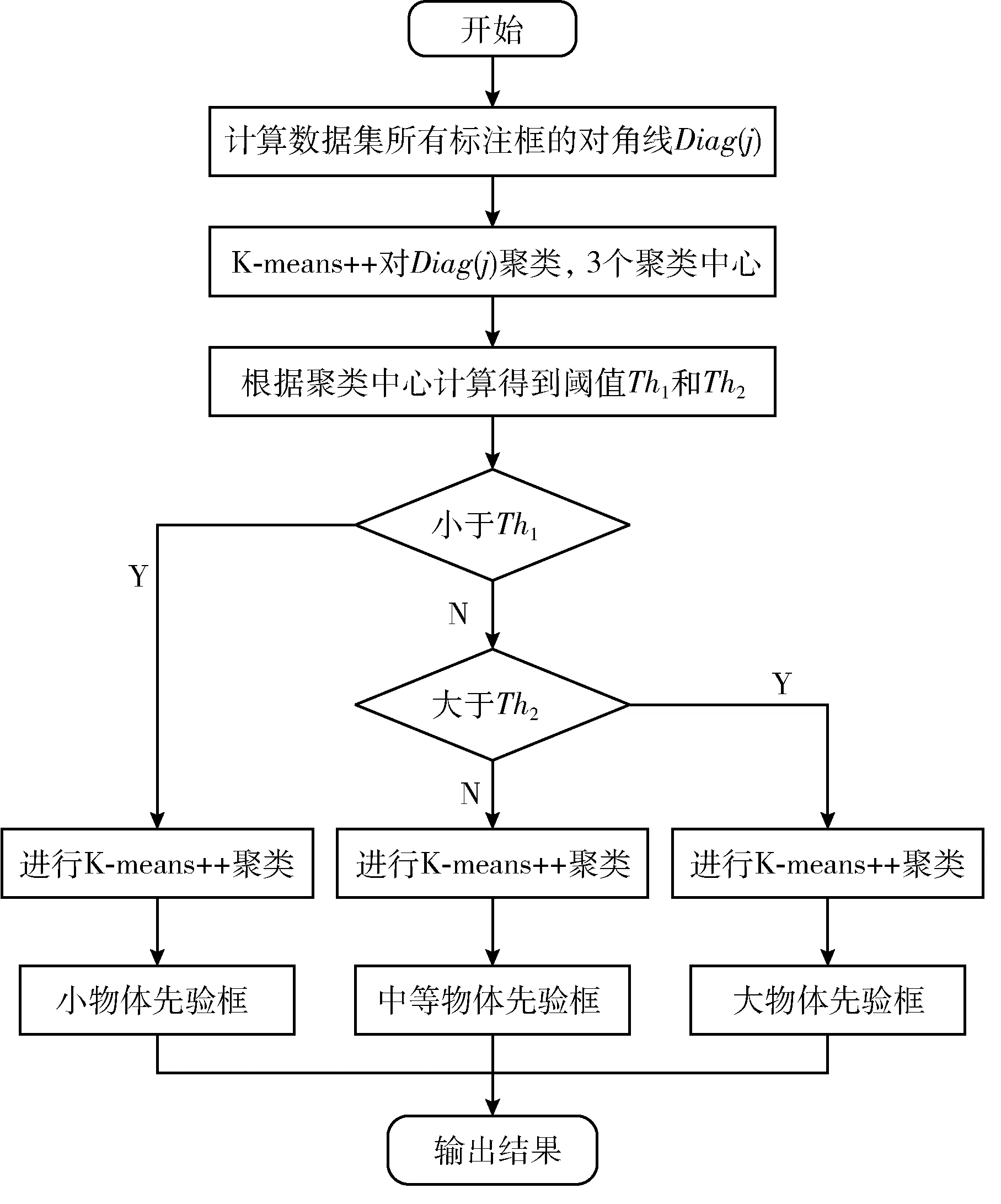
圖2 IK-means++算法聚類流程
2.2 引入ECA通道注意力模塊
為了進一步提高設備檢測模型的精度,在主干網絡中引入通道注意力機制;注意力機制借鑒了人類觀察事物時,會傾向于有選擇性地專注于其中一部分關鍵信息中的機制[15]。注意力機制可以有效提高深度學習模型的感知信息的效率和準確性。
ECA是目前注意力機制方向較新的研究成果,是在SE-Net[16]分組卷積的基礎上,針對其降維操作會給通道注意力預測帶來副作用的問題,提出的一種不需要進行降維、捕獲了跨通道交互且輕量級的高效通道注意力模塊,其結構如圖3所示;ECA模塊用W{k} 來表示學習到的通道注意力
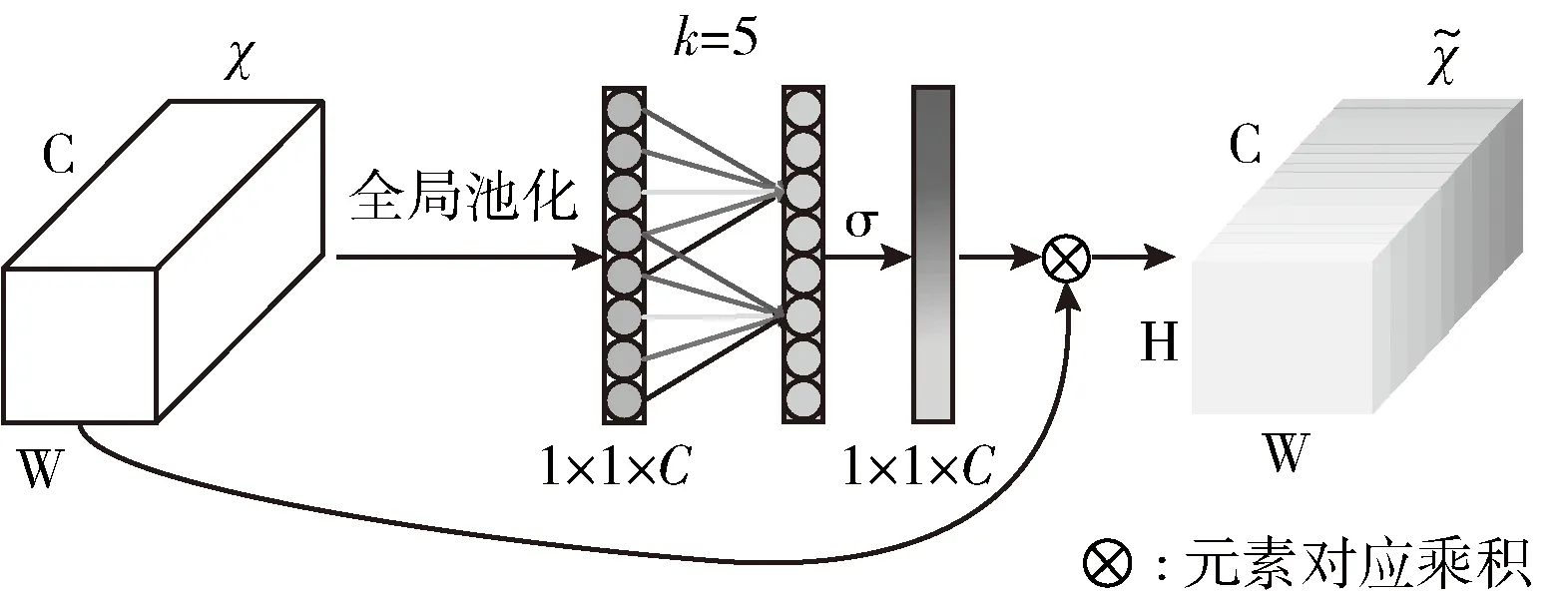
圖3 ECA模塊結構

(4)
W{k} 共涉及k*C個參數,k為卷積核大小,C為輸入特征圖的通道數,對于yi的權重,只考慮yi和它k個鄰居之間的信息交互,且所有通道共享權重信息,即
(5)
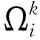
YOLOv4的主干網絡由多個不同深度的CSP殘差結構組成,在其中引入ECA通道注意力模塊,可以有效提高主干網絡的特征提取及信息感知能力,圖4為改進的ICSP-Darknet53的殘差塊堆疊部分結構圖。
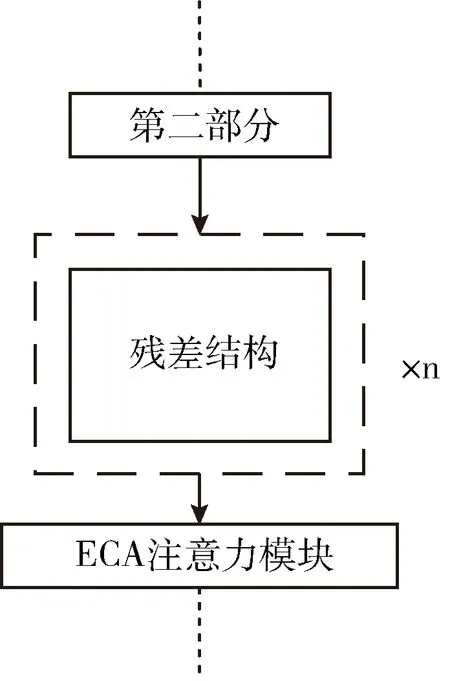
圖4 引入ECA模塊的ICSP殘差堆疊部分結構
2.3 改進的L-FPG特征融合網格結構
不同尺度特征的融合是目標檢測中提高模型性能的一個重要手段。不同尺度的特征圖對原始圖像特征的表達能力不同,淺層特征經過的卷積較少,噪聲較多,語義信息低,但特征分辨率高,包含的位置、細節信息更多;而深層特征有更強的語義信息,但是特征分辨率低,對細節信息的表征能力較差,因此如何將兩者有機融合,取長補短,是改善模型性能的關鍵。特征融合結構的發展從FPN特征金字塔[17]的提出到PANet創建自下而上的路徑增強,再到ASFF[18]提出的自適應特征融合策略和Bi-FPN[19]在可學習參數的自適應加權融合基礎上,增加跨層連接,使多個特征融合模塊重復堆疊,進一步增強信息的融合,都逐步突出了深度特征金字塔的優異性能。
FPG是2020年4月提出的一種深層多路徑特征金字塔,它將特征尺度空間表示為平行的多向橫向連接的網格,實驗結果表明了這種平行網格有效性,在提升速度和精度的基礎上,也降低了模型的復雜度,其網格結構如圖5所示;但過于深層的結構對模型性能的提升并不明顯,因此本文在FPG的基礎上,對網格結構進行簡化,并結合YOLOv4的主干網絡和檢測頭,提出了一種階梯狀特征融合網格結構L-FPG (Ladder-FPG, L-FPG),以加強檢測模型對實驗室設備特征的融合能力。
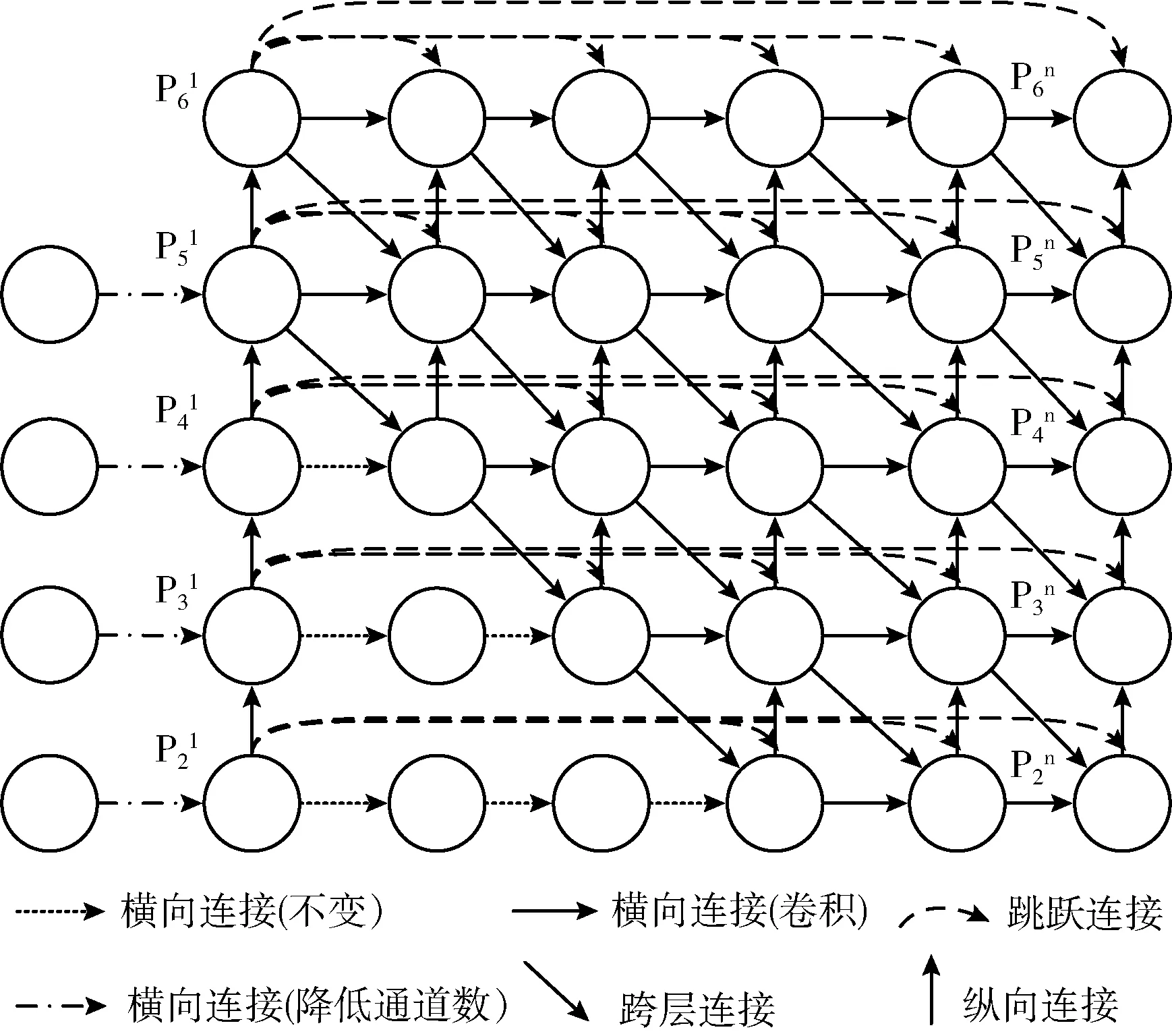
圖5 原FPG網絡結構
原網格結構中有9層,5個特征輸出,較為復雜,不利于與YOLOv4檢測頭結合及后續模型的輕量化研究;因此改進簡化后的L-FPG網絡結構如圖6所示,保留了原結構中的橫向、向上、向下和不同層間的跳躍連接,中間層特征都由臨近的4個特征相加得到,使得不同尺度的特征得到了有效融合,最終3個特征輸出直接連接到YOLO檢測頭,整體呈階梯狀。
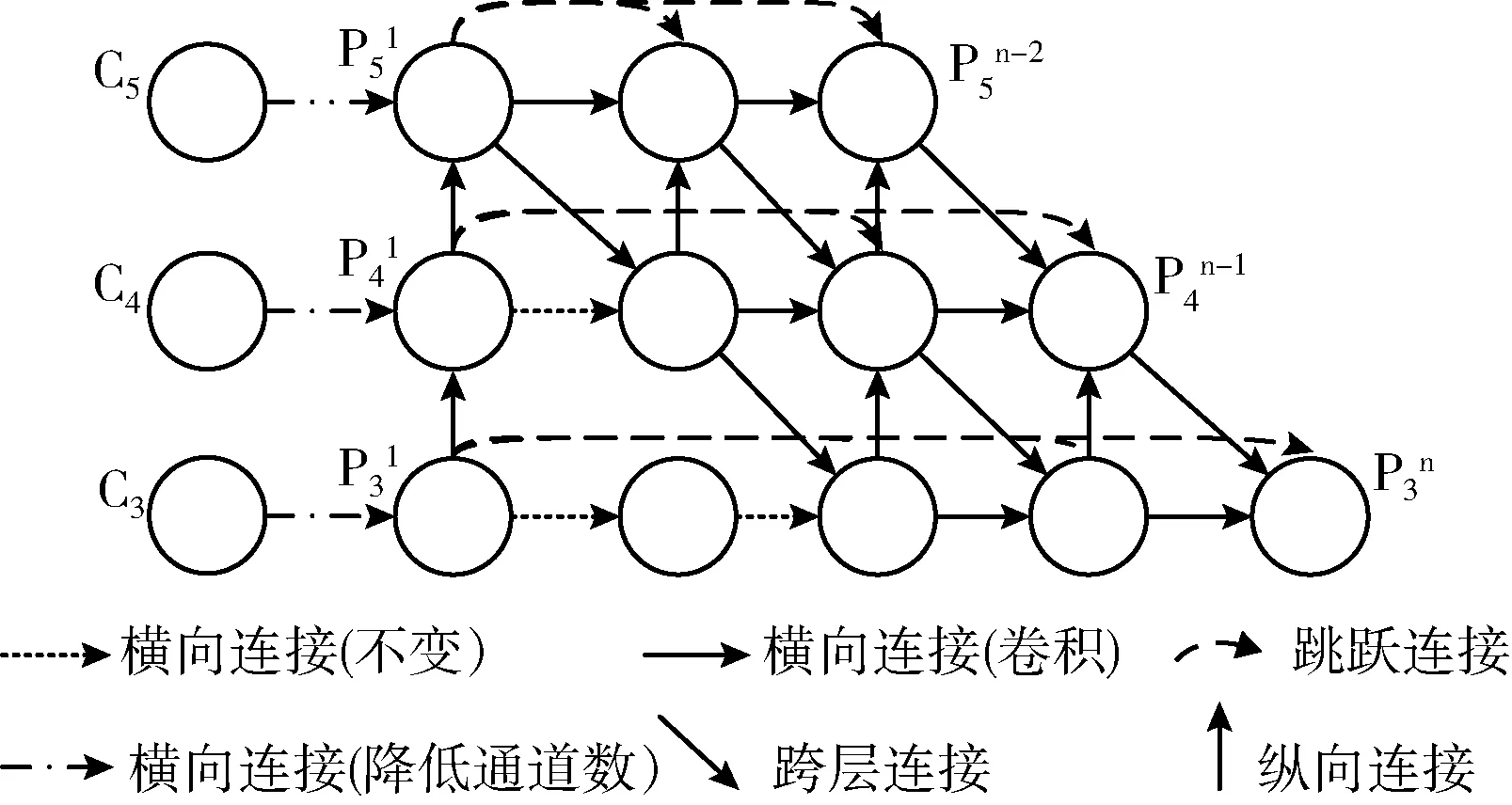
圖6 改進的L-FPG網絡結構
圖6中各向連接具體操作如下:



3 實驗與結果分析
3.1 數據集準備
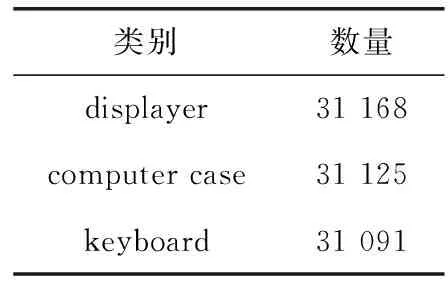
表1 訓練集中各類別數量統計結果
3.2 IK-means聚類算法實驗
在訓練網絡模型前,需對數據集按圖2流程聚類得到9個先驗框,根據式(2)對數據集標注框大小的定義,計算得到式(3)的閾值,將數據集按標注框大小劃分為小、中、大框3個區間,如圖7所示,圖(a)為數據集標注框整體的分布散點圖,可以看到整體分布并不均勻,且呈現非球狀分布,這也是K-means算法聚類效果不佳的主要原因;圖(b)~圖(d)分別為數據集標注框按大小劃分區間的尺寸分布散點圖。
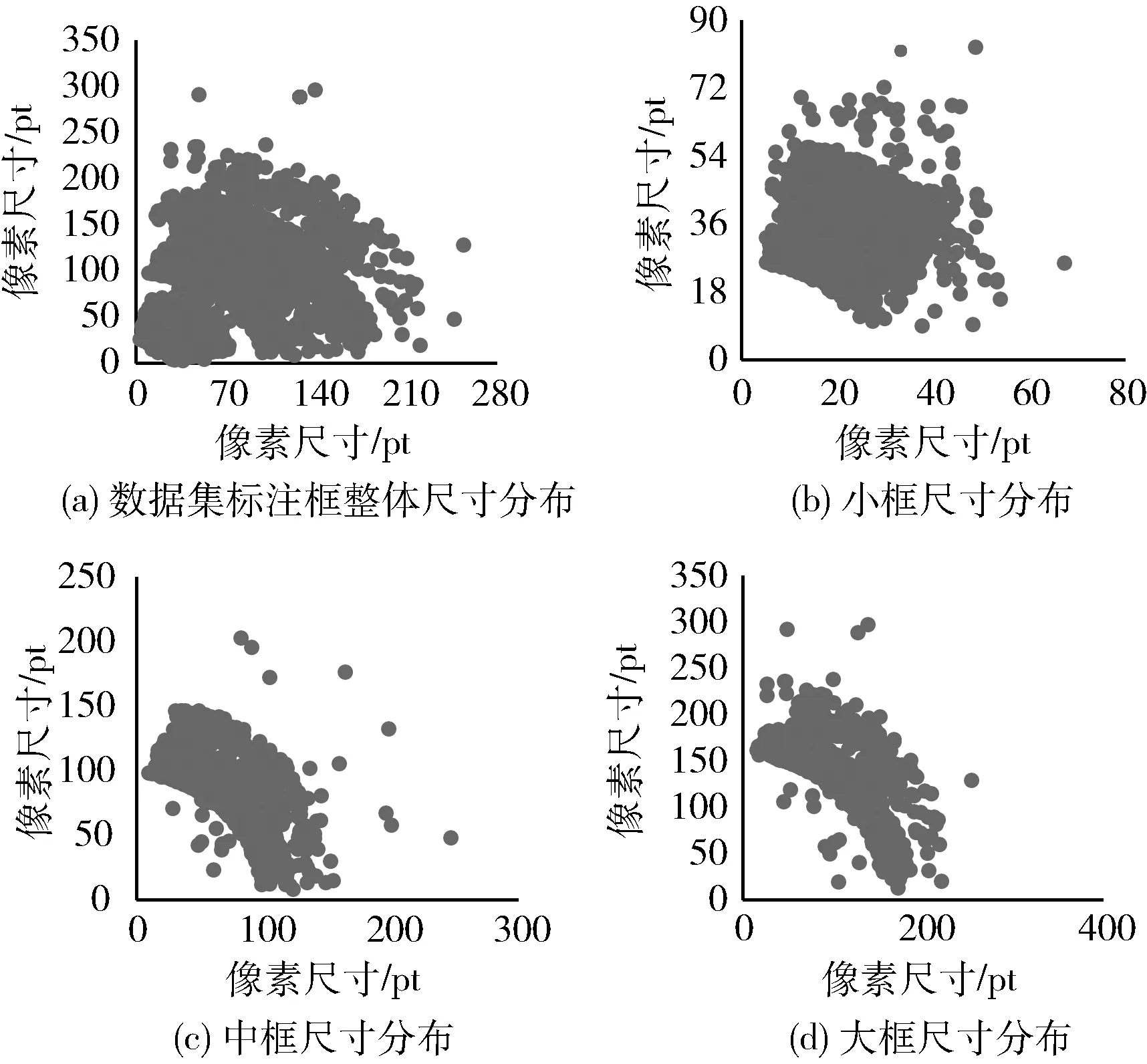
圖7 數據集標注框按大小劃分區間結果
根據區間劃分結果,再分別進行K-mean++聚類,各得到3個聚類中心,以小框區間的聚類過程為例進行說明,迭代過程可視化如圖8所示。
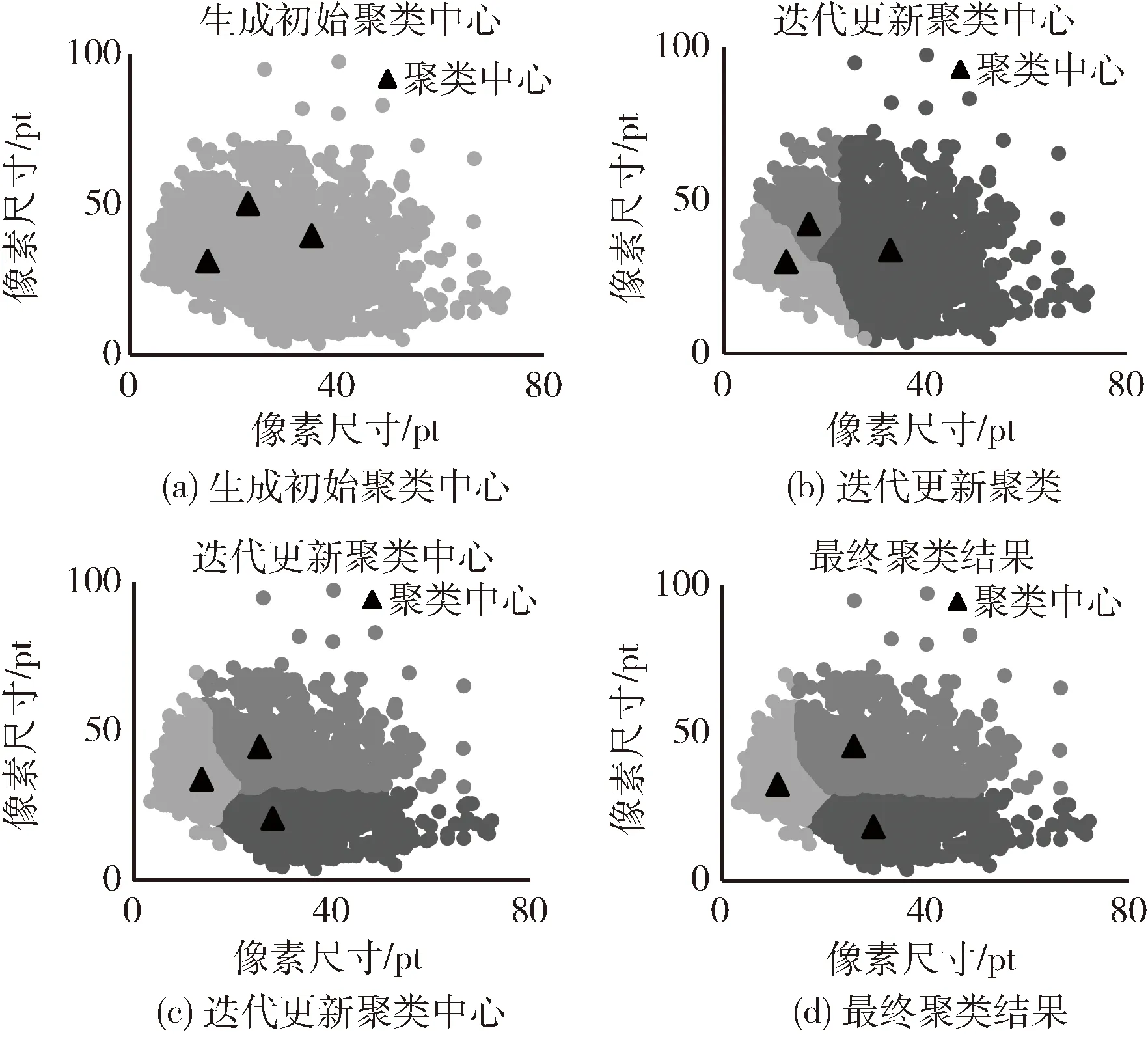
圖8 先驗框聚類過程可視化
首先,根據初始聚類中心之間距離越遠被選擇概率越高的思想,選擇3個初始聚類中心,如圖8(a)所示;然后計算所有點與聚類中心的距離,每個點將歸屬到距離最近的中心類簇,再計算每個類簇下的中位數,以更新聚類中心,并循環迭代直至中心點與上一次中心點一致,圖8(b)、圖8(c)為部分迭代過程;最后,當聚類中心不再發生變化時,得到最終聚類結果,如圖8(d)所示。
中框和大框的聚類過程與此類似,由此可得到最終9組先驗框聚類結果為:[13,29]、[20,44]、[33,29];[103,37]、[40,101]、[82,79];[55,161]、[91,146]、[141,105],兩道閾值分別為90.3、224.2。
以Avg IOU[20]為評價指標評估IK-means++算法,假設先驗框a=(aw,ah),box=(bw,bh), 則有
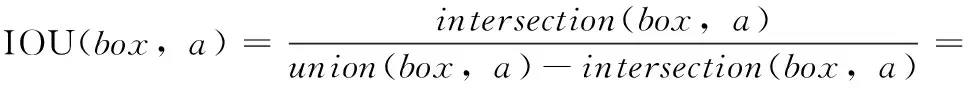
(6)
按式(6)計算每個先驗框與對應區間內所有標注框的IOU,再得到Avg IOU的同時與K-means和K-means++算法聚類結果對比,結果見表2。
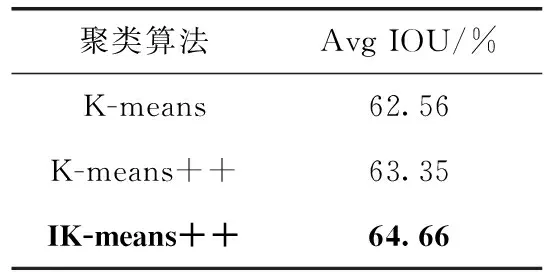
表2 先驗框聚類算法結果對比
其中IK-means++算法在劃分的小、中、大框區間內的聚類結果見表3。結果表明,改進的IK-means++算法在檢測目標尺度分布不均勻的數據集中,相較于常用的K-means以及K-means++的聚類結果均有明顯的提升。

表3 IK-means++各區間聚類結果
3.3 網絡模型訓練
本文在主干網絡的CSP殘差結構中引入了ECA通道注意力模塊,提出改進的L-FPG特征融合網格,替換原PANet,同時去掉了原網絡中的SPP結構,輸入圖像分辨率為416×416;圖9為完整網絡結構圖。
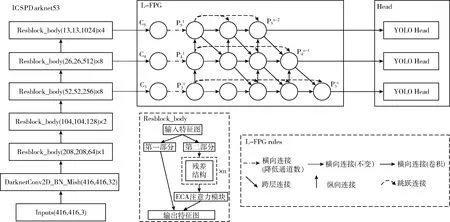
圖9 改進YOLOv4的整體網絡結構
本文實驗平臺為并行超算云平臺的GPU服務器,主機配置為Gold 61系列v5@2.5 GHz,GPU為32 GB的NVIDIA?Tesla?V100,操作系統為CentOS7;采用Python平臺的PyTorch深度學習庫構建網絡模型,訓練時超參數設置如下:訓練的epochs設置為100;batch size設置為64,初始學習率為0.001。
3.4 實驗結果分析
在訓練集上訓練圖9網絡結構,訓練的損失函數值如圖10所示,模型從20 epoch開始逐漸收斂。結果表明:在同樣預訓練模型基礎上,本文改進的YOLOv4收斂速度更快,最終的損失值更低,穩定在2.1左右。

圖10 損失函數值隨迭代次數的變化曲線
模型訓練完成后,在測試集上與原YOLOv4算法進行對比,采用目標檢測領域常用的mAP作為評價指標,計算公式如式(7)所示
(7)
式中:N表示N類檢測目標,本文中共3類,即N=3;APi為3類檢測目標對應的AP值。
模型的mAP對比結果見表4,結果表明,本文改進的網絡模型與原YOLOv4相比mAP提高了3.65個百分點,同時由于改進YOLOv4算法的L-FPG網格中大量使用的是1*1卷積核,使得浮點運算數減少了25.1%,參數量下降了43.1%,FPS也提升了6.8幀。
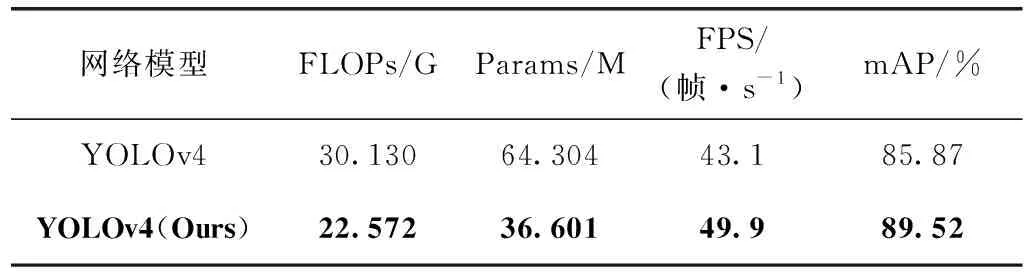
表4 實驗對比數據
3.5 光線環境對比實驗
由于實驗室內不同時段光線不同,拍攝的圖片亮度也不同,為了比較網絡模型在不同光線環境下的檢測性能,設計光線環境對比實驗,分別取白天和傍晚拍攝的圖片作實際檢測對比,如圖11所示,用不同顏色的矩形框表示不同設備類別;圖11(a)為明亮場景原YOLOv4算法的檢測結果,圖11(b)為明亮場景改進YOLOv4算法的檢測結果;圖11(c)和圖11(d)分為傍晚昏暗場景對應的檢測結果;通過統計各個類別的準確率和誤檢率,可以更直觀地比較網絡模型性能,統計結果見表5、表6。

圖11 不同光線環境下檢測效果對比
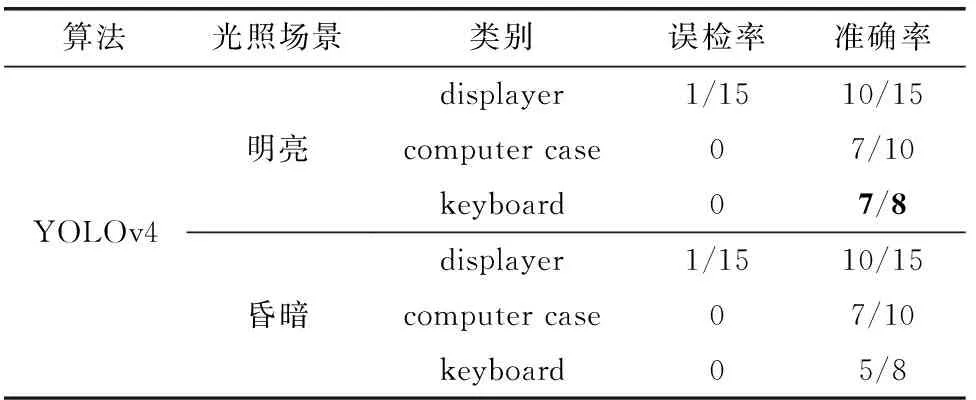
表5 原YOLOv4不同光照場景下檢測結果對比
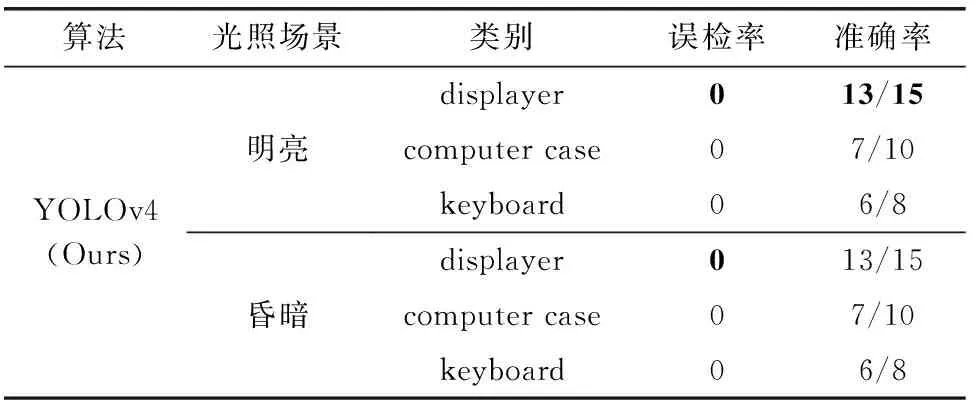
表6 改進YOLOv4不同光照場景下檢測結果對比
由表5、表6對比結果可以發現,整體而言,共33個設備中,本文改進的YOLOv4算法在明亮和昏暗場景下的準確率都要更高,誤檢率更低,在昏暗環境下,整體檢測結果與明亮環境相差不大,但置信度有所降低;而原YOLOv4算法在昏暗環境下檢測效果下降明顯,主要體現在對keyboard的識別率降低,并且將左上方的筆記本電腦檢測為displayer,存在誤檢。對比結果表明本文改進后的網絡結構面對不同光照環境條件的表現更穩定。
3.6 消融實驗
消融實驗是深度學習領域常用的實驗方法,用來分析不同的網絡分支對整個模型的影響[21]。為了進一步分析本文提出的IK-means++先驗框聚類算法和ECA通道注意力模塊以及改進的L-FPG特征融合網格對網絡模型檢測性能的影響,設計了消融實驗,實驗結果對比見表7。
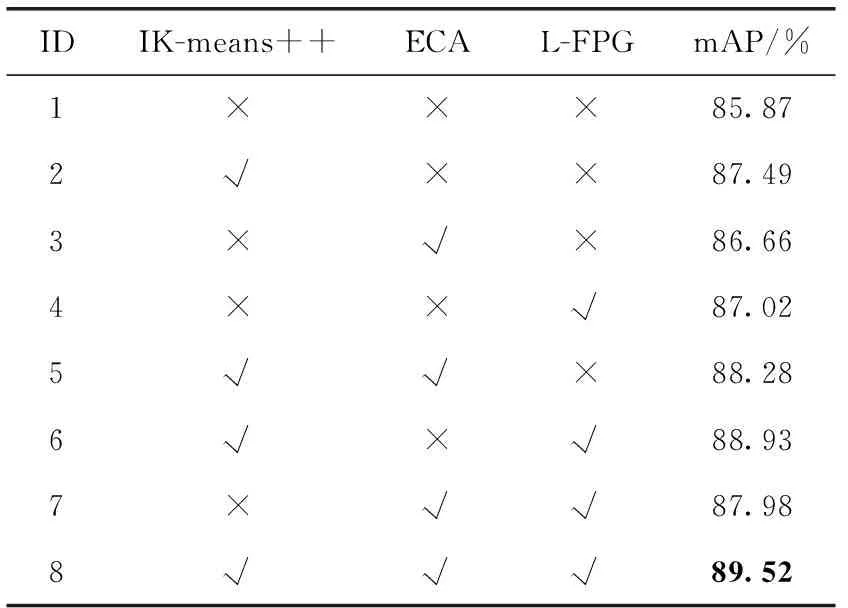
表7 消融實驗中mAP結果對比
第1組為原YOLOv4算法檢測結果,第2、第3、第4組分別為單獨使用其中一種改進方法,相較于第一組,mAP分別提升了1.62、0.79、1.15個百分點,提升最大的是IK-means++先驗框聚類算法,這是由于K-means算法適用于聚類對象分布均勻的情況,而本文計算機實驗室場景下,電腦設備尺度分布并不均勻;IK-means++算法在K-means++優化了初始聚類中心選擇的基礎上,強制劃分區間再進行聚類,減小了初始聚類中心選擇的隨機性和大小接近的物體被強制分配到不同檢測頭的情況,因此先驗框聚類的結果表現更好,對模型檢測精度的貢獻也最大,這也說明先驗框的選擇對于模型的影響較為顯著。
第5組~第7組分別為3種改進點的兩兩組合,均在一定程度上提升了檢測精度,第8組為本文3種改進思路的結合,也是檢測效果最好的一組,相較于第1組原算法,mAP提升了3.65個百分點。
4 結束語
針對實驗室場景的設備檢測,本文提出一種改進的YOLOv4算法,并以本校計算機實驗室為研究對象,首先,提出了一種將數據集標注框按大小分布強制劃分區間,再分別進行先驗框聚類的IK-means++算法;其次,在主干網絡的CSP殘差結構中引入了ECA通道注意力模塊,并提出了一種改進的階梯狀特征融合網格L-FPG。實驗結果表明,本文提出的IK-means++算法對先驗框的聚類效果要優于K-means和K-means++;同時ECA模塊與L-FPG特征融合網格的引入,在降低了模型復雜度的基礎上,FPS和mAP均得到提升,顯著提高了YOLOv4算法在計算機實驗室設備檢測上的綜合性能。在后續工作中,將主要研究如何進一步提高檢測精度,且在不損失精度的同時對模型進行枝剪、輕量化,將模型實際部署到移動設備或嵌入式設備,同時分別以其它各類實驗室為研究對象,增強適用性研究。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
