基于交互信息的兩階段特征選擇算法
2023-01-31 03:55:58降愛蓮
計算機工程與設計 2023年1期
劉 強,降愛蓮
(太原理工大學 信息與計算機學院,山西 晉中 030600)
0 引 言
傳統基于相關-冗余性分析的特征選擇算法[1,2]表現出良好性能[3,4],這類算法可以有效選取強相關特征、去除無關特征和冗余特征,但是會遺漏部分與類標簽相關度不高,與其它特征組合后有較強相關性的特征。為提高特征選擇的精度,一些算法同時利用特征相關性、冗余性及互補性。如文獻[5]在搜索過程中考慮互補性,基于自適應損失函數懲罰冗余并獎勵互補,對于小樣本數據,它在三者之間提供最佳的權衡,但會受到所選搜索策略的影響。文獻[6]采用兩階段方式提高特征子集的選擇效率,去除不相關特征和冗余特征的同時,選擇與已選特征集合互補性最大的特征,但忽略了候選互補特征與已選特征集合間的冗余性。
基于上述情況,本文提出一種基于交互信息的兩階段特征選擇算法。該方法能有效消除不相關特征并保留強相關特征,其次兼顧候選冗余特征與已選特征之間的互補性和冗余性,準確選取與已選特征發揮正向協同作用的“冗余”特征。實驗結果表明,該方法能準確選擇重要特征,有效提升數據分類準確率。
1 相關工作
最早使用互信息的方法是互信息最大化(mutual information maximization,MIM)[7],是一種直接的特征選擇策略,利用互信息度量特征與類標簽之間的相關度,選取重要特征。盡管MIM具有較低的時間復雜度,但它忽略了特征之間的冗余性。為了減少冗余信息,Battiti等[8]提出基于互信息的特征選擇算法(mutual information based feature selection,MIFS),該方法通過度量候選特征與類別標簽之間的相關性,以及候選特征與已選特征集合的冗余度,對候選特征打分,選取重要特征。但隨著數據維數的增大,MIFS的冗余項相較于相關項會變的很大,這意味著該方法可能選擇不相關的特征。最大相關-最小冗余算法(maximum relevance minimal redundancy,mRMR)[4],則利用候選特征與已選特征之間的平均冗余度,表示損失函數的冗余項,防止冗余項過大。但是,關于互信息有一個潛在的問題,它傾向于取值較多的特征。為了避免這種情況,一些研究通過將互信息的值縮放到 [0,1], 對互信息進行歸一化處理,例如歸一化互信息特征選擇算法(normalized mutual information feature selection,NMIFS)[9]。上述方法都較為有效地考慮了特征的相關性和冗余性,但都存在一定局限性:①需預設特征個數;②利用貪心搜索策略,計算代價高;③忽略了特征間的交互作用。
針對前兩個問題,基于相關性的快速過濾器(fast correlation-based filter,FCBF)[10]提出近似馬爾可夫毯理論,從而達到快速消除冗余的目的。FCBF無需預設所選特征個數,并且利用對稱不確定性,克服使用互信息帶來的偏置。但該方法在某些情況下存在將強相關特征誤判為冗余特征的問題,意味著該方法可能會漏選重要特征。為了準確選擇強相關特征,基于特征分組的過濾器(filter-based feature selection by feature grouping,FFSG)[11]在近似馬爾可夫毯理論的基礎上提出了強近似馬爾可夫毯理論。對于交互問題,為了識別交互特征,一些方法引入其它標準來選擇特征。例如,聯合互信息最大化方法(joint mutual information maximization,JMIM)[12],通過聯合互信息考慮已選特征與候選特征的交互作用,并利用“最大最小”準則來選擇最相關的特征。基于交互權重的特征選擇算法(interaction-weight-based feature selection,IWFS)[13],則利用交互信息評估候選特征。該方法通過交互權重因子來反映候選特征是交互還是冗余的。
一般情況下,大多數方法都是通過最大化交互信息來考慮互補性,通過評價函數的方式對特征打分,根據分值選取前K個特征。但這些方法需要預設所選特征個數。因此,有必要制定更簡便的方法。
2 相關概念
定義1 互信息[14]。互信息可以用來衡量一個隨機變量中包含另一個隨機變量的信息量。給定兩個離散型隨機變量X={x1,x2…xn} 和Y={y1,y2…ym},X和Y之間的互信息定義為
(1)
其中,p(xi) 表示值xi在X中發生的概率,p(xi,yj) 為xi和yj分別在X和Y中同時發生的概率。
定義2 對稱不確定性[10]。對稱不確定性是歸一化的互信息,其值限制在 [0,1]。X和Y之間的對稱不確定性定義為
(2)
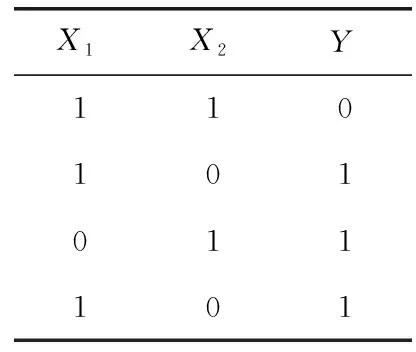
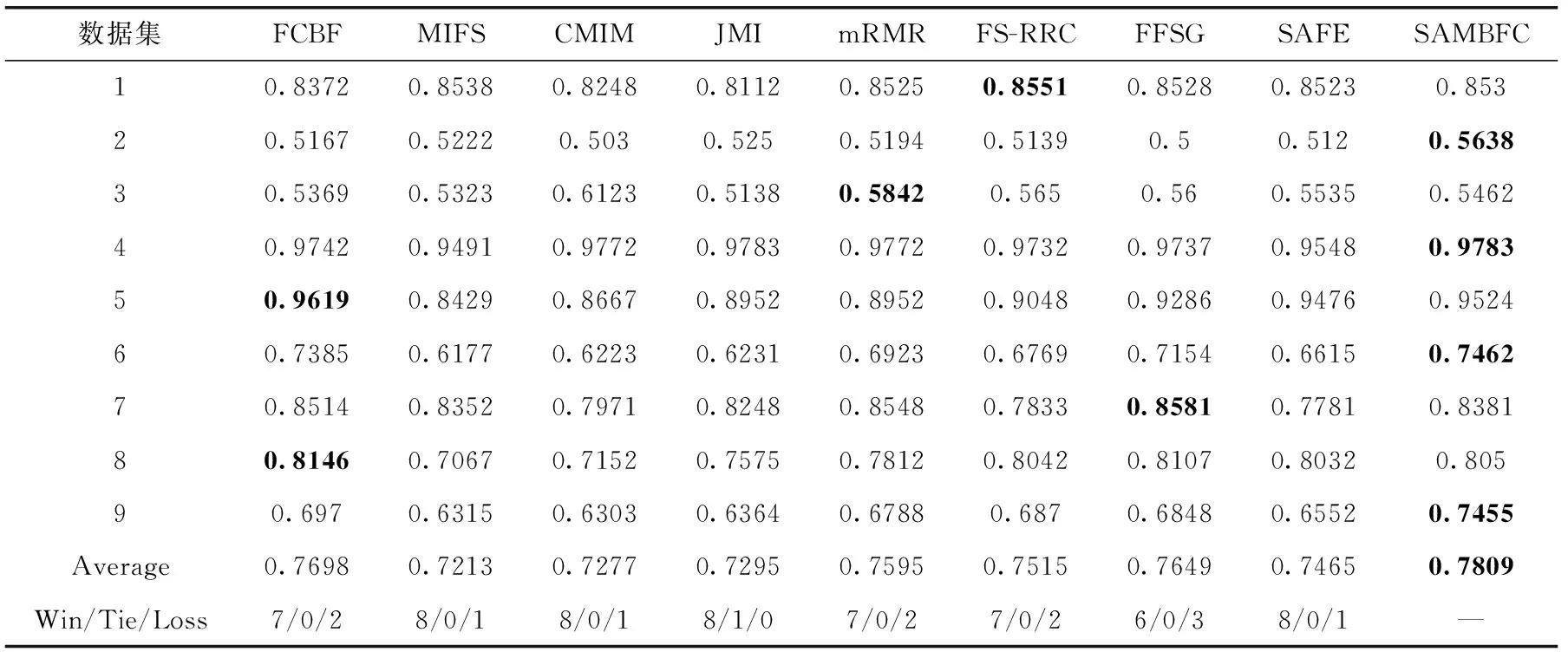
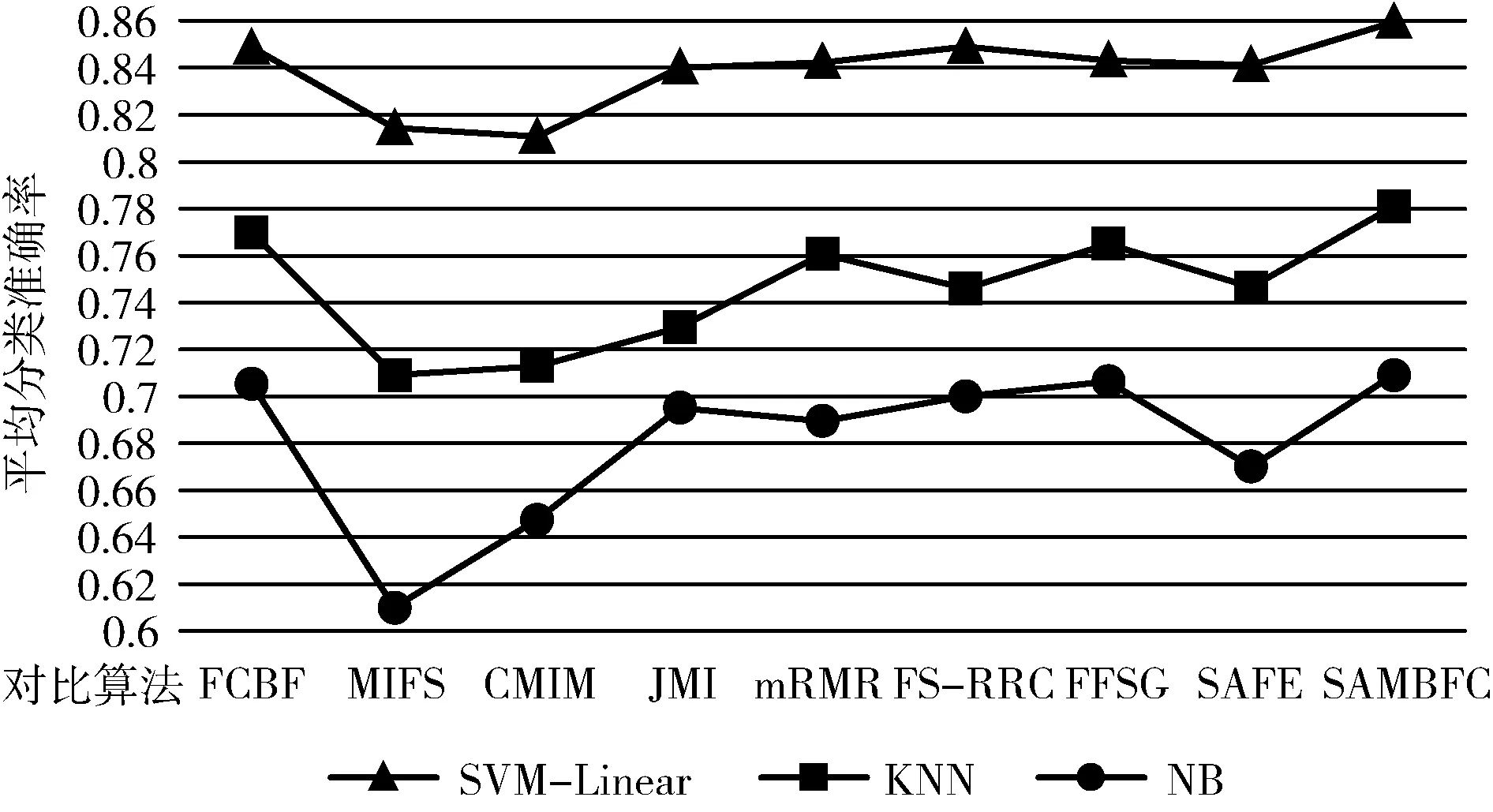
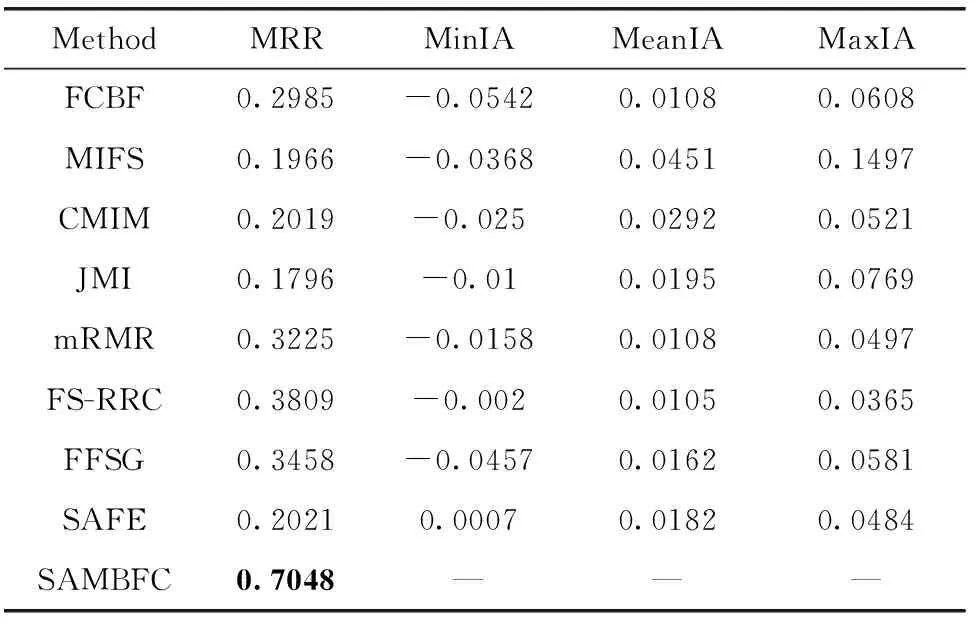
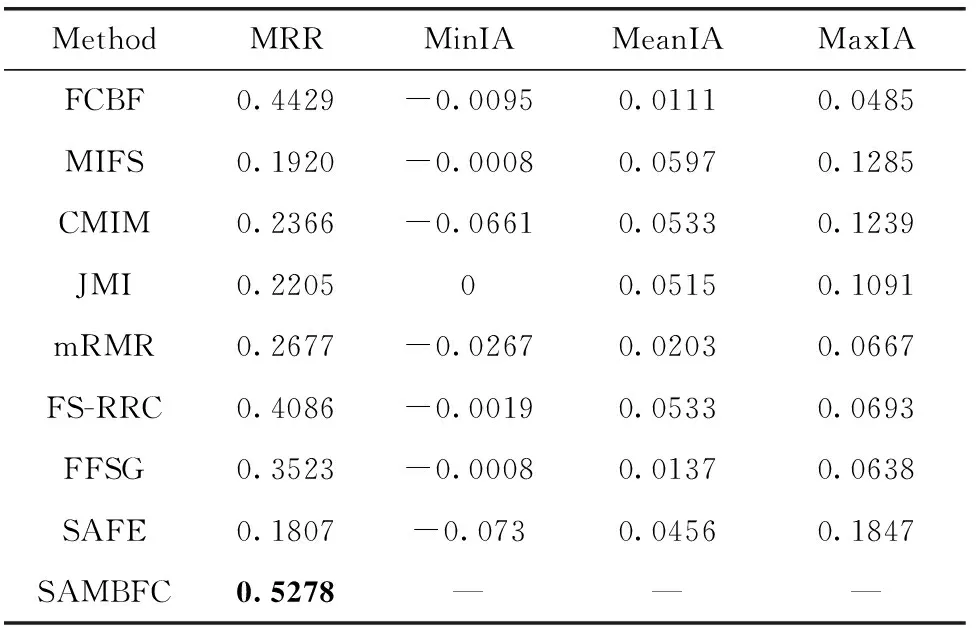
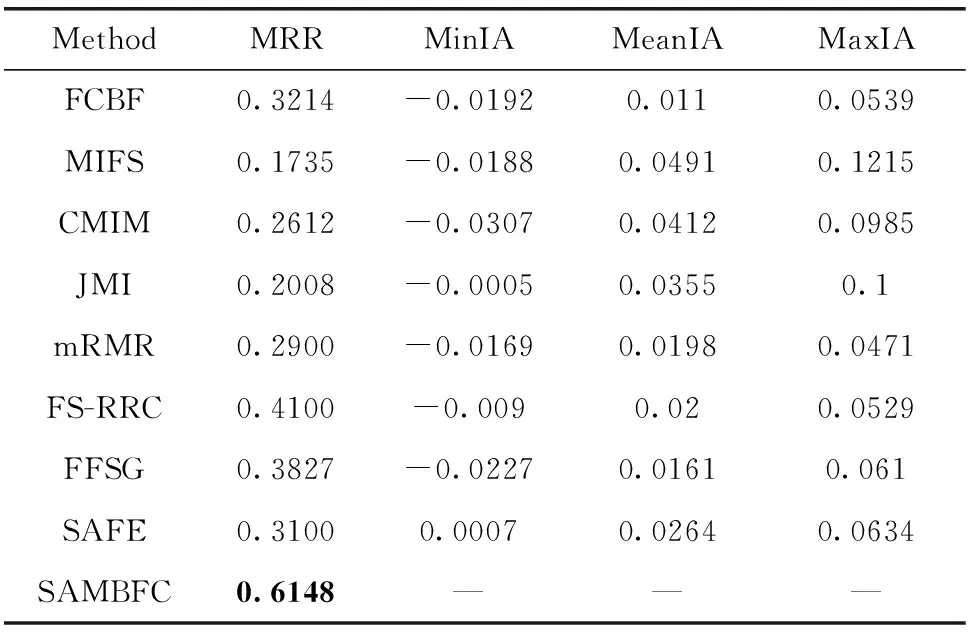
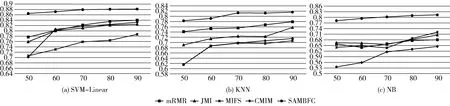
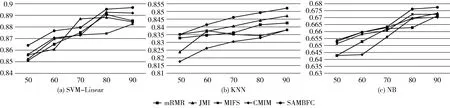
其中,H(X) 為X的信息熵,表示X中包含的信息量。SU(X,Y)=0時,表示兩個變量之間相互獨立。 0 定義3 馬爾可夫毯[15]。給定一個特征Xi∈F, 其中類標簽為Y,若特征子集Mi?F(Xi?Mi) 為Xi的馬爾可夫毯,當且僅當Xi⊥{F-Mi-{Xi},Y}|Mi。 其中⊥表示獨立, |Mi表示在給定Mi的條件下。即在給定Mi的條件下,Xi獨立于特征集合F-Mi-{Xi} 和類標簽Y。 說明Mi中包含了Xi對類標簽Y和其它特征集合F-Mi-{Xi} 的所有相關信息,則Xi相對于Mi為冗余特征。 定義4 強近似馬爾可夫毯[11]。給定兩個相關特征Xi,Xj≠i∈F, 若Xi構成Xj的一個強近似馬爾可夫毯,當且僅當滿足 (3) 定義5 交互信息[16]。給定兩個特征Xi和Xj,Xi和Xj之間的交互信息定義為 I(Xi;Xj;Y)=I({Xi,Xj};Y)-I(Xi;Y)-I(Xj;Y)= (4) I(Xi;Xj;Y)>0, 表示Xi和Xj組合后發揮正向協同作用,提供Xi或者Xj單獨存在時不能夠提供的信息;I(Xi;Xj;Y)=0, 表示Xi和Xj包含相同的信息;I(Xi;Xj;Y)<0時,表示Xi和Xj組合后會帶來更多冗余信息。 定義6 冗余特征。Xj為特征集合F中任意一個特征。若Xj為冗余特征,當且僅當存在Xi≠j∈F構成Xj的一個強近似馬爾可夫毯。 定義7 強相關特征。Xi為特征集合F中任意一個特征。若Xi為強相關特征,當且僅當F中沒有任何特征是該特征的強近似馬爾可夫毯。 定義8 基于相關性特征選擇算法[17]。基于相關性算法(correlation based feature selection,CFS)通過評估特征間以及特征與類別標簽之間的相關性來評估特征子集。該算法保留與類標簽高度相關,但與其它特征無關的特征,可以有效去除對類預測不起作用的特征變量,評價函數為 (5) 為防止漏選重要特征,而導致有用信息的丟失。本文提出基于交互信息的兩階段特征選擇算法,主要分為以下兩個階段:①相關-冗余性分析。首先去除無關特征,然后利用強近似馬爾可夫毯原理選取強相關特征,得到一個高相關、低冗余的次特優子集。②互補-冗余性分析。首先分析冗余特征,從中選取主互補特征,然后利用CFS算法分析該特征的優劣,確定是否將該特征加入已選特征集合中。最終得到一個兼顧特征相關性和互補性的最優特征子集。 為準確去除無關特征,并保留強相關特征,本文利用對稱不確定性和強近似馬爾可夫毯理論分別對特征進行相關性和冗余性分析,具體過程如下: (1)相關性分析。對于特征集合F={X1,X2…Xn}, 根據式(2)計算F中所有特征與類標簽的相關度,并從F中去除所有與類標簽相關度為0的無關特征,保留與類標簽具有一定相關度的特征。 (2)特征排序。計算F中每一個特征與其它特征間的冗余度,如式(6)所示,并按照特征間冗余度對F中特征降序排序 (6) 由所有強相關特征組成的特征子集為次特優子集,該集合中特征與類標簽相關度高,并且特征間冗余度低。基于強近似馬爾可夫毯原理,可以有效防止強相關特征被誤判為冗余特征;而且所有被刪除的特征都能從該集合中找到相應的強近似馬爾可夫毯。 現有的大多數特征選擇算法都通過最大化特征與類標簽之間的相關性、最小化特征間冗余來選擇重要特征。但特征間關系較為復雜,部分特征之間可能存在交互作用。即單個特征與類標簽的相關性較小,但與其它特征組合后卻與類標簽有較強相關性。表1中的示例說明了這一現象。 表1 互補性示例 表1中特征X1和X2都不能提供較多的分類信息:I(X1;Y)=0.085、I(X2;Y)=0.216。 若不考慮特征間的交互作用,X1和X2有可能被誤判為冗余特征。但X1和X2組合后I({X1,X2};Y)=0.477>I(X1;Y)+I(X2;Y), 卻可以提供更多分類信息,說明X1和X2不是真正的冗余特征。因此,在選出強相關特征的基礎上,冗余特征的分析決定了最終所選特征子集的優劣。為準確、簡便地分析特征間的交互信息,本文提出一種分析候選冗余特征與已選特征間交互作用的方法。該方法將互補-冗余性分析相分離,分別對冗余特征進行互補性分析和冗余性分析。具體方法為: C(Xi,Xj,Y)=SU(Xi,Y|Xj)-(1+λ)SU(Xi,Y) (7) (8) (3)冗余性分析。對于主互補特征Xc, 與Xi組合后發揮正向協同作用,但與Xlist中其它已選特征組合后可能發揮負向協同作用,因此有必要分析加入Xc后給整個已選特征集合帶來的影響。首先,根據式(5)計算Xlist的整體價值;然后將Xc加入Xlist中,并計算此時Xlist的整體價值。若加入Xc后Xlist的整體價值有所提升,則保留該特征,否則不加入該特征。 (4)以此類推,直至分析完Xlist中所有已選特征的主互補特征,得到最優特征子集Xbest。 根據SAMBFC的兩階段選取過程,給出下面相應的兩部分算法。其中,階段1為選取強相關特征,階段2為分析冗余特征。 第一階段:選取強相關特征 輸入:數據集D,特征集合F={X1,X2…Xn} 其中Xi={x1,x2…xm}, 標簽集合為Y={y1,y2…ym} (1)Xlist←?SC←?Xbest←?F*←? (2)for eachXi∈Fdo (3) ifSU(Xi;Y)=0 (4)F←F (5)end for (6)for eachXi∈Fdo (8)end for (9)F←sort(F) whereRi>Rj (10)for eachXi∈Fdo (11)Xlist←Xlist∪{Xi} (12) for eachXj≠i∈Fdo (13) IfSU(Xi,Xj)>δandSU(Xi,Xj)≥SU(Xj,Y) andSU(Xi,Y)≥SU(Xj,Y) (15) end for (16)end for 階段1中主要是利用強近似馬爾可夫毯原理,將原始特征空間,劃分為強相關、無關以及冗余子集,其中(2)~(5)行篩選無關特征,第(11)行選取強相關特征,(13)、(14)行識別冗余特征。 第二階段:分析冗余特征 輸出:最優特征子集Xbest (1)SC←?Xbest←?Xc←? (2)for eachXi∈Xlistdo:Xj?SC (4) ifC(Xi,Xj,Y)>0 (5)XC←Xj∪{XC} (6) end for (8)SC←SC∪{XC} (9)end for (10)for eachXc∈SCdo (11)Xbest←Xlist∪{Xc} (12) ifJ(Xbest)>J(Xlist) (13)Xlist=Xbest,J(Xlist)=J(Xbest) (14)end for 階段2主要是分析冗余特征,選擇出能增強已選特征集合與類標簽相關性的互補冗余特征,其中(2)~(9)行選出主互補特征,(12)、(13)行分析該特征的優劣。 第一階段中計算特征與類標簽間相關性的時間復雜度為O(n), 計算特征間冗余度的時間復雜度為O(mn2), 特征排序的時間復雜度為O(nlogn), 刪除冗余特征的時間復雜度為O(n2), 因此第一階段的時間復雜度為O((m+1)n2+nlogn+n)=O(mn2)。 由于在第一階段已經去除大量無關和冗余特征,會減小第二階段的特征計算規模,所以第二階段所需時間復雜度遠小于第一階段。因此,SAMBFC算法的總時間復雜度為O(mn2)。 本文在UCI和ASU上的多個公開數據集進行對比實驗,數據集涉及醫學、生物信息學、圖像等領域,具體參數見表2。實驗前利用類別屬性依賴最大化方法[18](class-attribute interdependence maximization,CAIM)將連續型數據離散化。 表2 實驗所用數據集 為了驗證本文所提SAMBFC算法的有效性,實驗過程中將與以下3類算法進行對比: (1)MIFS[8]、mRMR[4]以及條件互信息最大化(conditional mutual information maximization criterion,CMIM)[13],這3種算法是傳統的基于相關-冗余性分析的。 (2)FCBF[10]和FFSG[11]分別基于近似馬爾可夫毯理論和強近似馬爾可夫毯理論進行相關-冗余性分析。 (3)自適應特征評估(self-adaptive feature evaluation,SAFE)[5]算法、基于特征相關性、冗余性和互補性(feature selection based on relevance、redundancy and complementarity,FS-RRC)[6]算法以及基于聯合互信息(joint mutual information,JMI)[12]算法在特征選擇的過程中考慮特征互補性。 實驗中分別使用支持向量機(support vector machines,SVM)、樸素貝葉斯(Naive Bayesian, NB)和k-最近鄰(K-nearest neighbor,KNN)分類器評估SAMBFC算法的性能。其中SVM來自LIBSVM工具包,內核選擇線性核函數,該工具包中利用網格搜索確定懲罰因子等具體參數。KNN中的K值設為10,MIFS的β設置為0.5,FCBF的δ設置為0,SAMBFC的λ設置為0.1。實驗采用5折交叉驗證的方式,為保證公平,每個數據集都進行50次實驗,通過計算50次結果的平均值來求得算法的分類表現。 由于SAMBFC算法無需預設選擇的特征個數。為保證對比實驗的有效性。所以,實驗將分兩部分算法進行對比。一部分為FCBF、FS-RRC、FFSG以及SAFE,4種無需預設特征個數的算法,另一部分為MIFS、mRMR、JMI、CMIM,4種需預設特征個數的算法。 4.4.1 分類性能 本節實驗主要與4種無需預設特征個數的算法進行對比。此處將MIFS、mRMR、JMI、CMIM,4種特征選擇算法選擇的特征個數設置為SAMBFC選擇的特征個數。表3給出了FCBF、FS-RRC、FFSG、SAFE和SAMBFC算法在9組數據集上選擇的特征個數。 表3 5種算法選擇特征個數 圖1是9種算法在3種分類器上的分類表現。表4和表5分別是9種算法在SVM和KNN分類器上的具體分類準確率。Win/Tie/Loss,其中Win表示SAMBFC表現優于當前算法,Tie表示與SAMBFC算法表現一致,Loss表示當前方法優于SAMBFC算法。 表4 SVM-Linear分類器的分類準確率 表5 KNN分類器的分類準確率 圖1 9個算法在不同分類器上的分類效果 (1)FFSG與SAMBFC算法對比 SAMBFC相較于FFSG,在SVM-linear上提升1.63%,KNN上提升1.6%。在SVM-Linear分類器上,FFSG方法除了在Colon、WarpPIE10P數據集上的表現優于SAMBFC方法,其余數據集上表現較差,在KNN分類器上,在Colon、Madelon和Lung discrete數據集上表現優于SAMBFC方法。SAMBFC相較于FFSG方法平均多選擇了24個特征,多出的特征一部分是具有互補信息的特征,另一部分是FFSG篩選次特優子集后刪除的特征,由于次特優子集中絕大部是相關性較強的特征,刪除部分特征后導致分類效果下降。SAMBFC雖然選擇更多的特征,但總體表現優于FFSG方法。 (2)FS-RRC與SAMBFC算法對比 在SVM-Linear分類器上,SAMBFC算法相較FS-RRC算法提升了1.05%,在KNN上高出2.94%。表4中SAMBFC僅在Optdigist和Isolet數據集上低于FS-RRC算法。表5中在Colon、Optdigist數據集上低于FS-RRC算法,但在其它7個數據集上均高于FS-RRC算法。SAMBFC較于FS-RRC平均少選28個特征,但在9個數據集上表現優于FS-RRC算法或與其相近。因此SAMBFC相較于FS-RRC對于互補信息的評價更為準確,并且充分考慮到候選特征和已選特征集合間的冗余性,獲得更優的特征子集。 (3)FS-RRC、FCBF與SAMBFC算法對比 FS-RRC是在FCBF的基礎上加入了特征互補性。在SVM-Linear分類器上,FS-RRC除了在Colon和Warp-AR10P數據集上差于FCBF,其它7個數據集上表現均優于FCBF,表明互補特征能夠帶來更多信息,但也可能帶來更多冗余。選擇的特征個數增多但降低了分類準確率,表明FS-RRC算法中通過特征互補性加入的部分特征帶來的冗余信息超過了互補信息,從而造成分類準確率的下降。而SAMBFC算法所提的度量方法能夠較為有效衡量特征間的互補信息,從而提升分類效果。 (4)SAFE和SAMBFC算法對比 在兩個分類器上,SAMBFC表現均優于SAFE,而且相較于SAFE方法平均少選擇兩個特征。SAFE以啟發式的方式,從整個特征集合的角度來衡量特征之間的關系,雖然從整體衡量特征空間的相關、冗余及互補性更為準確,但SAFE算法在高維數據上表現較差,而且該方法會受到搜索策略的影響。 (5)MIFS、CMIM、JMI、mRMR和SAMBFC算法對比 從表4~表5中可以看到將MIFS、CMIM、JMI、mRMR算法選擇的特征個數設置為SAMBFC選擇出的特征個數時,SAMBFC整體表現優于其它算法。但將這幾種算法選擇的特征個數直接預設為SAMBFC選擇的特征個數不能很好地對比幾種方法的差異。在實驗的最后部分本文對這幾種算法選擇特征的能力進行了更詳細的對比。 由實驗結果可知,SAMBFC算法總體優于這4種算法。從相關、冗余性的角度而言,SAMBFC算法利用強近似馬爾可夫毯選出與類別高度相關、更有區分能力的特征,并且防止了強相關特征的誤判。從互補性的角度來看,SAMBFC利用對稱不確定性度量特征間的互補性,利用CFS算法度量候選特征與已選特征集合間的冗余度,能夠更為公平、準確選擇互補特征,獲得更好的分類效果。 4.4.2 單獨分類性能的統計表現 為了更加直觀地描述特征選擇算法的優劣程度,表6、表7是對表4、表5數據的統計分析,其中MRR是平均倒數秩[19],用來衡量一個方法的綜合排名。例如SAMBFC在SVM上的表現排名為:7,1,1,5,2,1,1,2,1。則SAMBFC的MRR為 (1/7+1+1+1/5+1/2+1+1+1/2+1)/9=0.7048。 MinIA、MeanIA和MaxIA是SAMBFC的分類準確率減去每個方法的分類準確率后的最小值、平均值和最大值。表5、表6中的數據表示,SAMBFC在兩個分類器上的綜合表現均為最優。 表6 9種方法在SVM-Linear上的統計表現 表7 9種方法在KNN上的統計表現 4.4.3 平均分類性能的統計表現 由于每種方法都有它各自的特點或優勢,因此單個分類模型上的性能好壞,并不足以說明選擇算法的性能優劣。為了能從整體上描述不同選擇方法的性能,將在表4和表5中的分類表現求和后取平均值,對其統計表現進行分析,其具體數值見表8。表8中結果表明SAMBFC的平均分類表現在幾個方法中也是最優。 表8 平均分類性能的統計表現 為了更好對比MIFS、CMIM、JMI、mRMR與SAMBFC算法之間的性能。通過約束SAMBFC方法選擇的特征個數,將這幾種方法選擇的特征個數預設為50、60、70、80、90。由于SAMBFC算法在Lung discrete、Isolet以及Yale數據集上選擇特征個數較多,所以此處在這3個數據集上進行對比實驗。 圖2~圖4則是幾個方法在選擇不同特征個數時的表現。從圖2中可以看出,在Isolet數據集上SAMBCF算法的分類效果明顯優于其它MIFS、CMIM、JMI、mRMR算法。圖3(c)中,SAMBFC算法在分析Lung discrete數據集時,在NB分類器上選擇較少特征個數時表現與其它方法相近,隨著所選特征個數的增多,分類表現逐漸優于其它算法。圖4(b)中,SAMBFC除了在KNN分類器上,選擇特征個數為50和60時表現不佳,其余情況下表現均優于其它方法。因此,SAMBFC算法選擇特征能力總體優于其余4種特征選擇算法。 圖2 5種方法在Isolet數據集上的分類效果對比 圖3 5種方法在Lung discrete數據集上的分類效果對比 圖4 5種方法在Yale數據集上的分類效果對比 針對傳統特征選擇中,因忽略特征間協同作用而漏選部分重要特征的問題,本文提出了一種基于交互信息的兩階段特征選擇算法。該方法對特征進行兩階段選取,在選取強相關特征后,對冗余特征進行互補-冗余性分析,選取具有交互作用的冗余特征。在9個公共數據集上將本文算法與FCBF等8種特征選擇算法進行對比實驗。實驗結果表明,相較其它算法SAMBFC選擇了更優的特征子集,提高了分類準確率,然而本文算法僅考慮了兩兩特征間的交互作用。未來將對候選特征與整個已選特征集合間互補性的度量進行研究。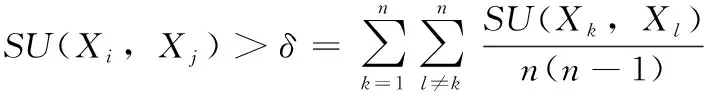
I(Xi;Y|Xj)-I(Xi;Y)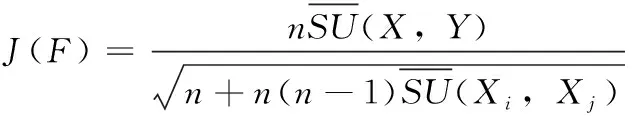
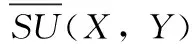
3 本文算法
3.1 相關-冗余性分析
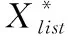
3.2 互補-冗余性分析
3.3 算法偽代碼
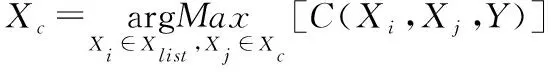
4 實驗與結果分析
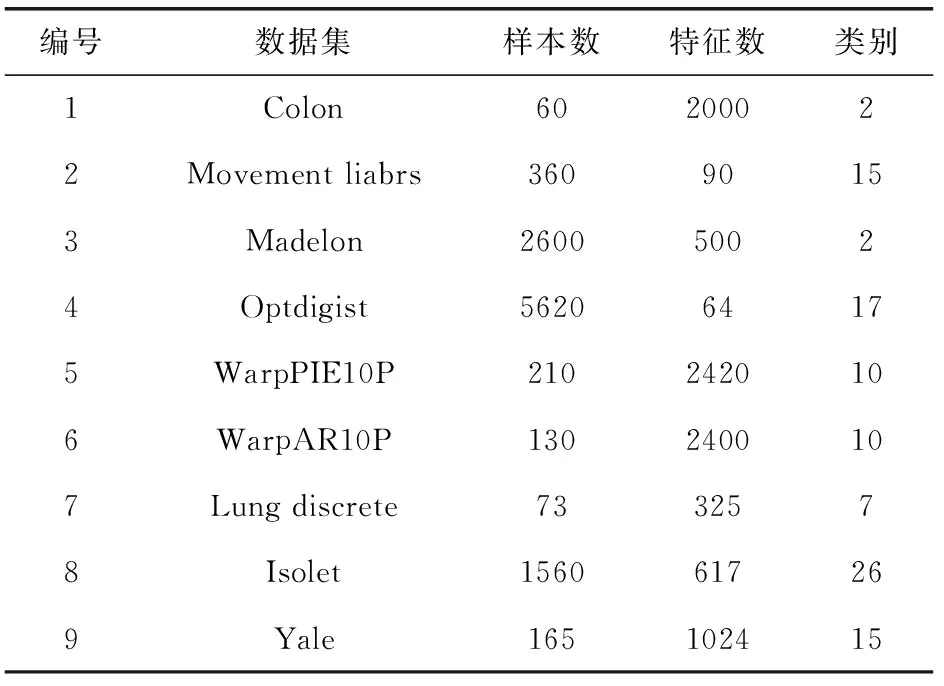
4.1 實驗數據
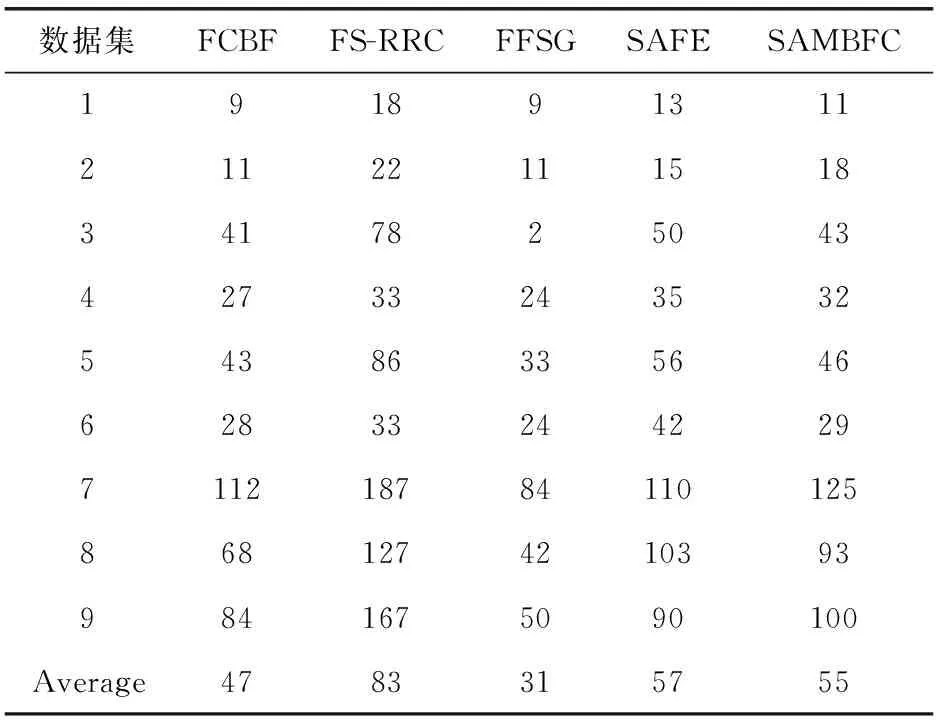
4.2 實驗對比算法
4.3 實驗設置
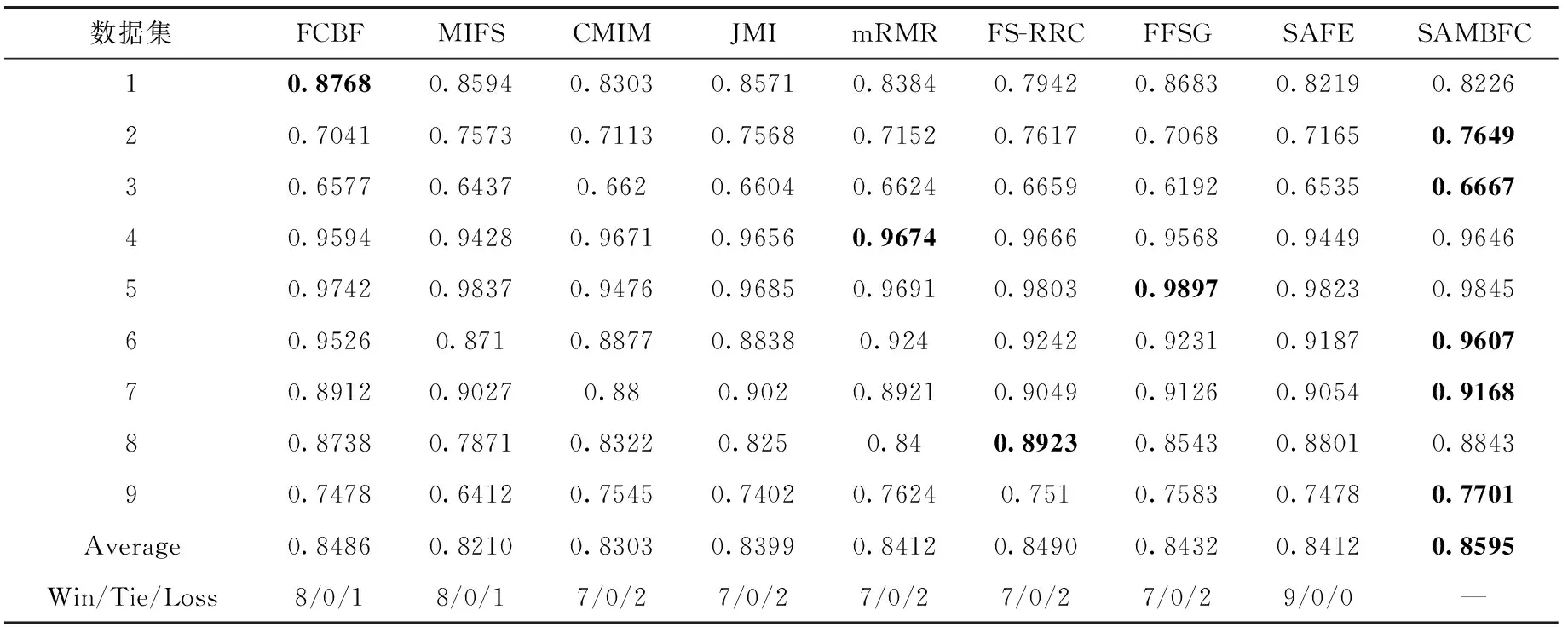
4.4 結果分析
5 結束語
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
