改進DBNet與CRNN的面標識別方法
2023-01-31 03:36:00董維振梁海玲
計算機工程與設計 2023年1期
董維振,陳 燕+,梁海玲
(1.廣西大學 計算機與電子信息學院,廣西 南寧 530004; 2.廣西中煙工業有限責任公司,廣西 南寧 530001)
0 引 言
在鋼鐵企業中,板材下線后,噴號設備在板材表面噴鍍標識。依靠人眼識別面標,準確性和生產效率低,系統人機接口信息滯后,不便于信息傳遞與系統交互。
冶金領域人工智能方面,劉玠[1]概述了人工智能理論體系以及在冶金制造領域的應用前景,構建了冶金智能化藍圖。李江昀等[2]重點描述了深度學習在冶金工業圖像分割、預測和分類等方面的理論與應用案例。在冶金文本識別領域,取得了一些研究成果。賀笛[3]采用MobileNet-v2作為骨干網絡,提出了鋼板表面輕量化字符識別模型。張付祥等[4,5]設計了棒材信息檢測系統,提取區域聯通域特征和灰度矩陣特征,構建了模板庫,實現了信息自動識別。相銀堂等[6]采用二值化全部閾值與局部閾值對比方法實現背景與目標分離。錢偉強等[7]提出了支持向量機與Tesseract相結合的字符識別方法。錢偉強等[8]改進了卷積神經網絡結構,以獲取多樣性特征。周嘯[9]提出使用改進的字符模板匹配算法進行鋼板字符識別。楊建等[10]使用SSD網絡構建字符識別器,將字符識別問題轉換為目標檢測問題。李陽[11]提出了邊緣檢測分割方法,解決壓印字符定位問題,對已定位的圖像分割字符。尹子豪[12]優化了BP網絡算法并應用于鋼坯字符識別場景。近年來,基于深度學習的分割法[13-18]研究較廣泛,但是算法模型和研究對象均基于噪聲指數低的場景,而板材生產環境圖像噪聲指數很高,受表面溫度影響,易產生模糊、粘連、變形等,同時由于光照、粉塵等環境約束,使得上述研究方法和模型準確率較低。圖像識別領域面臨的問題、實際應用場景差異較大,須依據實際的應用場景和數據集構建算法模型。
本文設計了文本檢測與識別模型,將改進的可微二值化算法網絡(differentiable binarization net,DBNet)[19]作為文本檢測算法網絡,列出文本候選框,再通過改進的卷積遞歸神經網絡(CRNN)對候選框進行識別,著力提升訓練效率和準確率。通過現場拍攝和數據增強,構建了實際數據集,同時搭建了移動端APP和服務端應用,將模型集成至軟件系統中。
1 文本檢測模型算法
1.1 DBNet概述
文本檢測模型基于DBNet網絡和可微二值化(diffe-rentiable binarization,DB)算法,通過學習閾值圖和使用可微的操作將閾值轉換放入網絡中訓練,預測每個像素點的閾值,而非采用固定值,將背景與前景分離,進而解決梯度不可微的問題。
1.1.1 DBNet網絡模型
DBNet網絡結構如圖1所示。
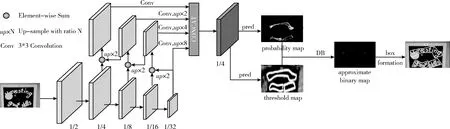
圖1 DBNet網絡模型
首先進行特征提取,特征金字塔(FPN)進行特征級聯得到特征F;然后,特征F用于預測概率圖(probability map P)和閾值圖(threshold map T);最后,通過P和F計算近似二值圖(approximate binary map B)。
在訓練期間對P,T,B進行監督訓練,P和B使用相同的監督信號(label)。在推理時,只需P或B及可獲取文本框。
1.1.2 二值化
標準二值化為,對于一個大小為H×W(圖的高為H,寬為W)的概率圖P,將概率圖中的每個像素進行二值化如下方法
(1)
式中:t表示預設的閾值, (i,j) 表示概率圖中的坐標位置。輸出1表示該像素為正樣本也就是文字區域,輸出0表示該像素為負樣本也就是背景。
為了解決二值化方法不可微的問題,DB提出一個近似的階躍函數,如下方法
(2)
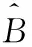
使用二值交叉熵來作為Loss的情況下,計算正樣本的Lossl+和負樣本的Lossl-如下方法
(3)
(4)
Loss對于輸入x的偏導數為如下方法
(5)
(6)
式(5)和式(6)分別表示對于正負樣本的偏導數。k為梯度的增益因子,梯度對于錯誤預測的增益幅度大,反之亦然。
1.1.3 自適應閾值
概率圖P和二值圖B使用相同標簽。將每個標注框縮小一定的偏移量D,偏移量定義如式(7)所示,標簽圖稱為Gs,原始標注文本框為G。偏移量計算如下方法
(7)
式中:L為標注框的周長,A為標注框的面積,r為預設的縮放因子,r定義為0.4。
1.1.4 Loss函數
Loss函數公式如下方法
L=Ls+α×Lb+β×Lt
(8)
式中:Ls為概率圖的Loss,Lb為二值圖的Loss,Lt為閾值圖的Loss,α和β分別取值為1.0和10。
對于Ls和Lb采用二值交叉熵(BCE)求解,如下方法
Ls=Lb=∑i∈Siyilogxi+(1-yi)log(1-xi)
(9)
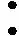
Lt為L1 Loss,如下方法
(10)
式中:Rd為標注框經過D偏移量擴充后得到的Gd里的所有像素,y*為計算出來的閾值圖的label。
1.2 DBNet改進
文本檢測模型基于DBNet構建,特征提取網絡采用ResNet50,通過特征金字塔進行特征融合。本文文本檢測模型為了抑制無效特征,使網絡能夠自動學習不同通道的重要程度和關聯性,引入了高效通道注意力模塊SENet[20];同時為了解決特征金字塔沖突問題,進一步與自適應空間特征融合(ASFF)融合,增強了特征金字塔預測多尺度目標的能力。通過對于DBNet特征提取網絡的改進,有效提升了特征提取的性能與精度。
1.2.1 高效通道注意力機制
為了對于無效特征進行抑制,使網絡能夠自動學習不同通道的重要程度和關聯性,引入高效通道注意力模塊SENet,將SENet模塊加入ResNet50殘差分支中。SENet的結構如圖2所示。
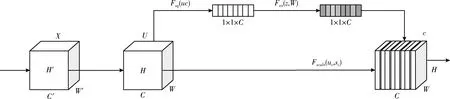
圖2 SENet網絡結構
在SENet模塊中,不再由輸入X直接輸出U,而是根據通道的重要程度進行加權計算。
首先對于每個通道H×W個數據進行全局平均池化,獲得對應標量,稱之為Squeeze,如下方法
(11)
然后經過全連接、激活函數(ReLU)、全連接、激活函數(Sigmoid)后獲得 [0,1] 之間的權重值,及為通道的重要性,稱為Excitation,如下方法
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
(12)
式中:W1、W2∈RC×(C/r), 第一個全連接層用于降維,r為降維超參數,然后使用ReLU激活,之后的全連接層用于恢復維度,最后經過Sigmoid函數獲得s。
最后將每個通道初始的H×W個數據與Excitation輸出的權重值分別相乘,獲得加權后特征圖,完成特征重標定,如下方法
(13)
加入SENet模塊后,ResNet50殘差學習分支內部結構如圖3所示。
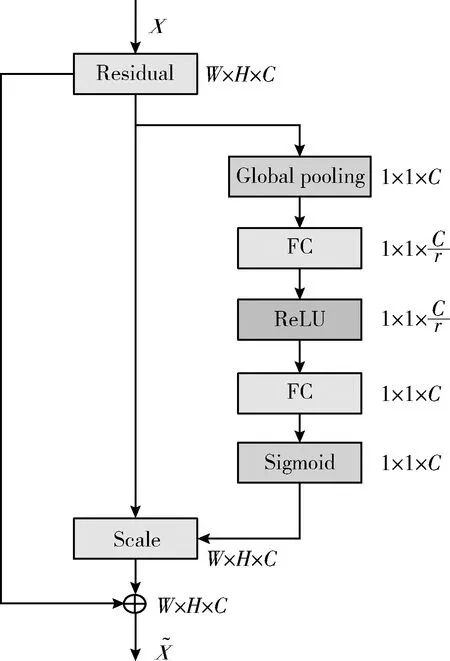
圖3 ResNet50殘差分支內部結構
圖3中,r為超參數,本文r為16,第一個FC層降維為1/r, Sigmoid函數調節各通道特征權重,增強可分辨性。
文本檢測模型將SENet與ResNet50結合,將SENet模塊加入到ResNet50的殘差學習分支中,形成Res50-SE-Net,如圖4所示。

圖4 ResNet50殘差分支加入SENet
1.2.2 自適應空間特征融合
DBNet網絡中使用特征金字塔(feature pyramid networks,FPN[21])進行特征級聯,解決多尺度檢測問題,通過改變網絡連接提升小物體檢測的準確率。ResNet50結合特征金字塔如圖5所示。
如圖5左側,先進行自下至上過程,神經網絡正向傳播,特征圖進行卷積運算尺寸變小;然后自上而下過程將更強語義、抽象的高層特征圖上采樣,然后與前一層特征進行橫向連接,每層融合不同語義強度和分辨率的特征;特征金字塔各層通過上采樣尺寸統一為原尺寸的1/4;最后特征金字塔各層進行concat。
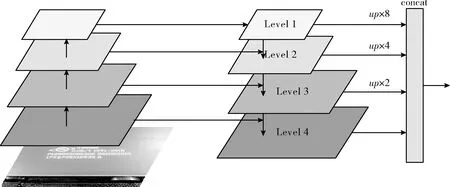
圖5 ResNet50結合特征金字塔
由于特征尺度不同,當某目標在某級別特征圖被認定為正樣本時,該區域在其它級別特征圖中將被認定為背景,如果該區域存在不同尺度的目標時,在特征金字塔中將可能產生沖突,在訓練期間將影響梯度計算,使特征金字塔的有效性降低。為了解決此問題,本文提出將ResNet50與FPN結合后,進一步與自適應空間特征融合(ASFF)融合。ASFF通過學習多尺度特征權重參數、將輸入與權重參數圖逐點相乘、判定像素點的抑制與激活解決特征金字塔沖突問題,增強了特征金字塔預測多尺度目標的能力,整體融合過程如圖6所示。
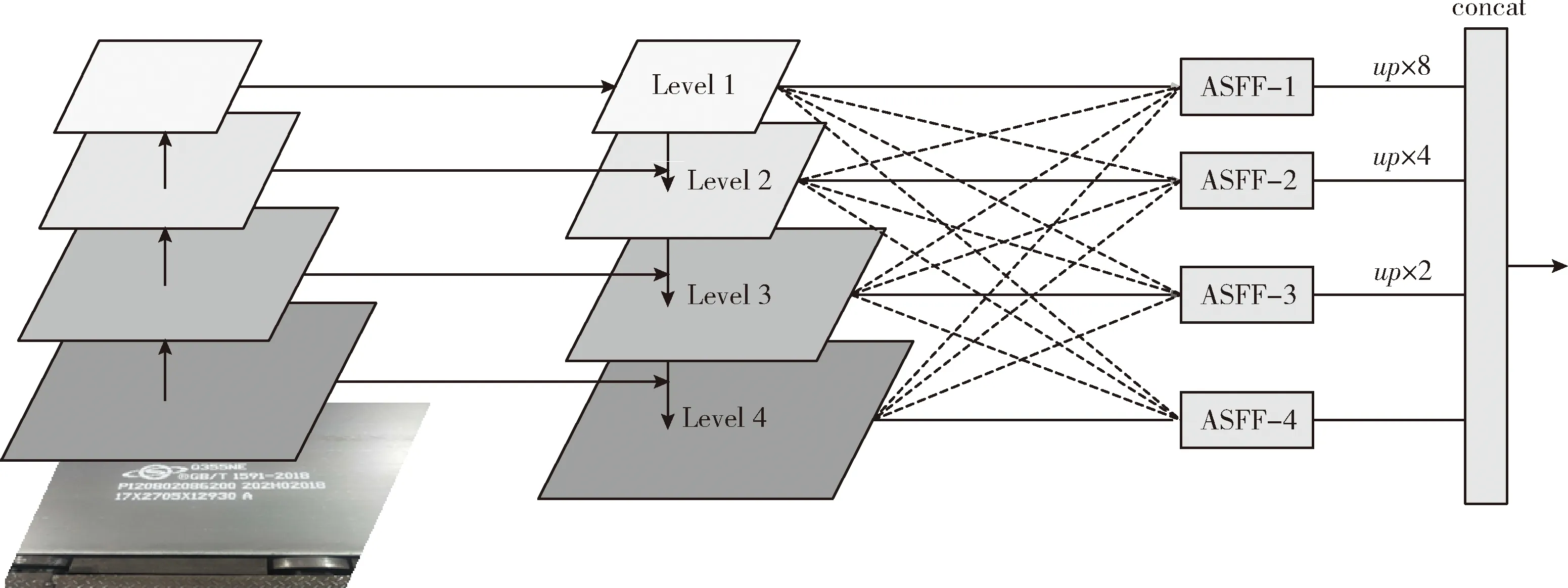
圖6 融合ASFF過程
進一步與ASFF融合的網絡結構如圖7所示。
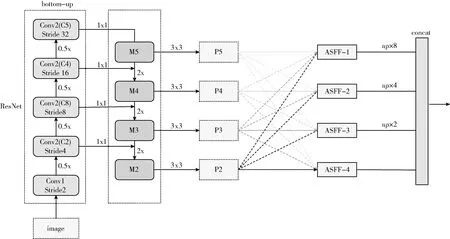
圖7 與ASFF融合后的網絡結構
ASFF特征融合如下方法
(14)
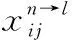
將Res50-SE-Net網絡與ASFF相結合后形成了Res50-SE-ASFF-Net。
2 文本識別模型算法
文本識別模型基于CRNN[22]網絡構建,接收文本檢測模型輸出的文本檢測框,將檢測結果與識別結果對應,生成信息提取圖。
2.1 模型結構
CRNN網絡結構如圖8所示。
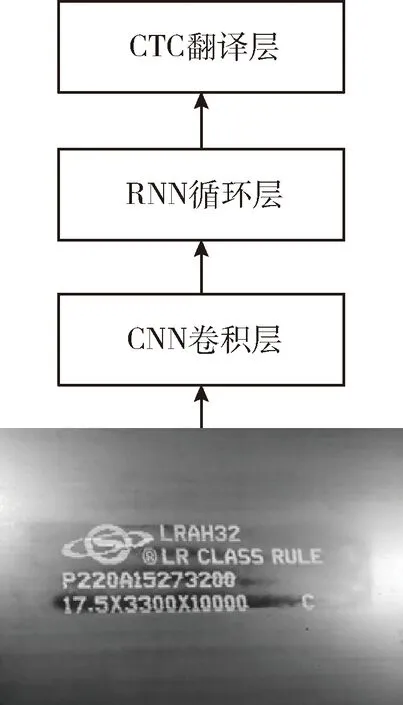
圖8 CRNN網絡結構
CRNN網絡由3部分組成,CNN(卷積神經網絡)將圖片轉換為特征序列;RNN(循環神經網絡)循環層進行解碼識別,文本被認為一種序列;CTC(聯接時間分類)算法將識別結果進行轉錄,并通過占位符添加機制處理重復字符在文本中丟失的問題。
2.2 CNN卷積層
CNN采用VGG結構,首先將分割后的數據集圖片按比例縮放為寬度W,然后通過CNN卷積網絡生成數量為W/4的512通道的特征序列。
本文對于VGG網絡進行如下改進:為了提升訓練精度和加快網絡的訓練收斂速度,在第5和第6卷積層后加入BN層;為將VGG提取的特征輸入至RNN,將第3、4個最大池化層的卷積核尺寸由2×2改進為1×2;由于RNN可將誤差反向傳播,使CNN與RNN聯合訓練,進一步提升網絡訓練的準確率。改進后的CNN網絡結構見表1。

表1 改進后的VGG網絡結構
2.3 RNN循環層
CNN網絡提取的特征序列輸入至RNN網絡進行文本預測,輸出對應的特征分布。文本識別模型采用stack型深層雙向RNN網絡,如圖9所示。
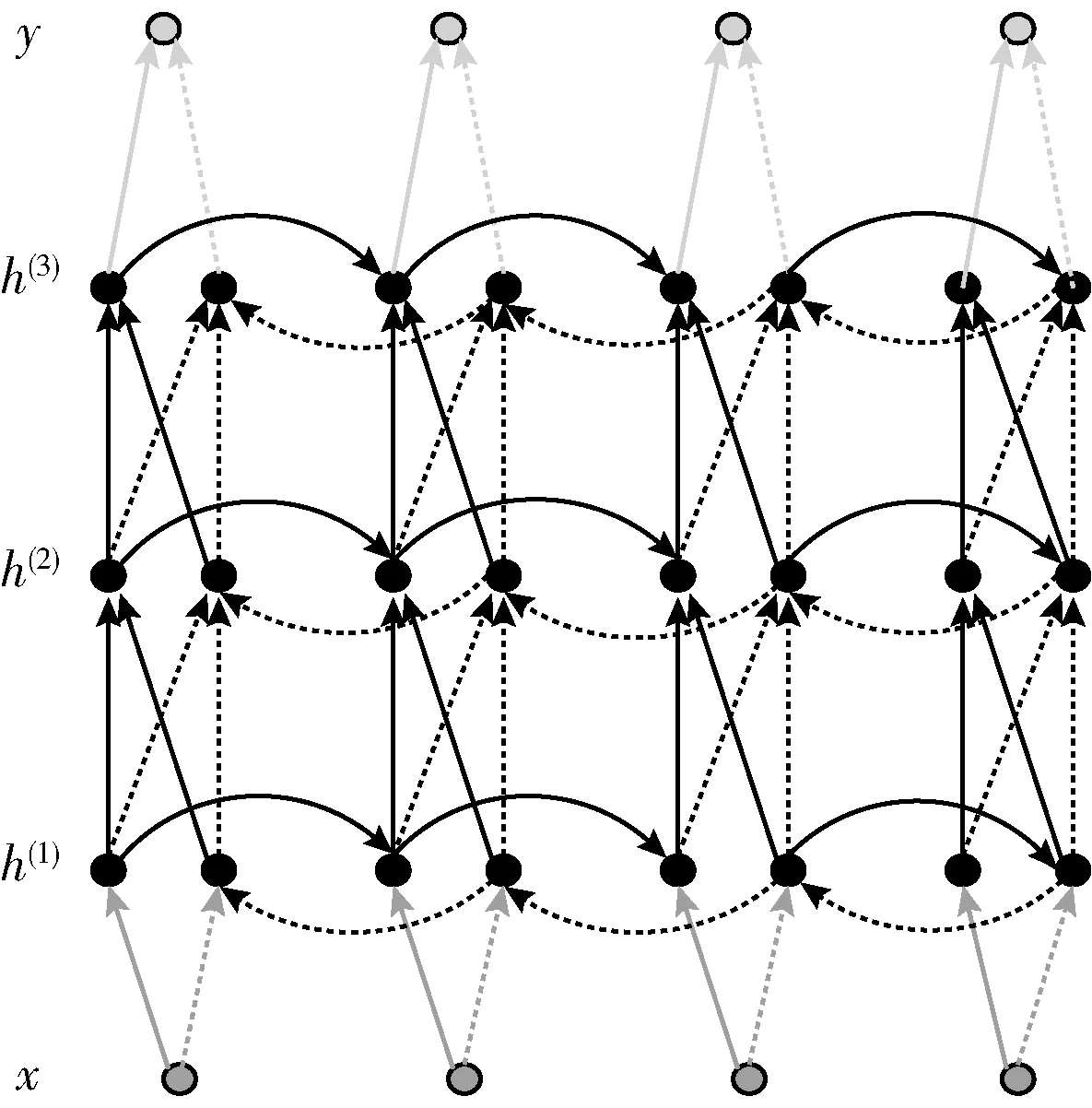
圖9 stack型深層雙向RNN網絡結構
為了防止訓練過程中梯度消失,選用LSTM(長短時記憶單元)作為RNN的單元,LSTM包括遺忘門、存儲單元、輸入和輸出,雙向RNN通過存儲單元存儲雙向上下文信息。
2.4 CTC翻譯層
經過RNN網絡輸出的預測文本序列將經過翻譯層轉換為字符標簽,采用基于詞典的CTC算法進行字符轉換。
CTC翻譯層分別使用符號序列X=[x1,x2,…,xT]、Y=[y1,y2,…,yU] 表示輸入和輸出(對應的標注文本)。對于一對輸入輸出 (X,Y) 來說,CTC的目標是將下式概率最大化,如下方法
(15)
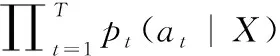
CTC采用多對一的方式對齊輸入輸出,例如Q3ε4ε5Bε與Q3εε4ε5B均對應“Q345B”,此為其中的兩條路徑,將所有路徑相加為輸出的條件概率。
2.5 損失函數
CTC損失函數定義如下方法
loss=-∑Wi,Ii∈Xln(p(Ii,yi))
(16)

(17)
式(16)為正確標注條件概率似然數的負對數,其中p(Ii,yi) 為預測值yi對應標簽Ii的條件概率,π為y的全部可能,及對應字符的概率不為零的全部線性可能。
2.6 應用集成
同步構建了移動端APP和服務端應用,面標檢測與識別模型部署于服務端應用。移動端APP與服務器端使用Http協議進行交互,移動端APP拍攝圖像上傳至服務端,服務端調用鋼卷噴涂面標識別模型進行識別,并將識別結果傳輸至移動終端APP展示,系統架構如圖10所示。
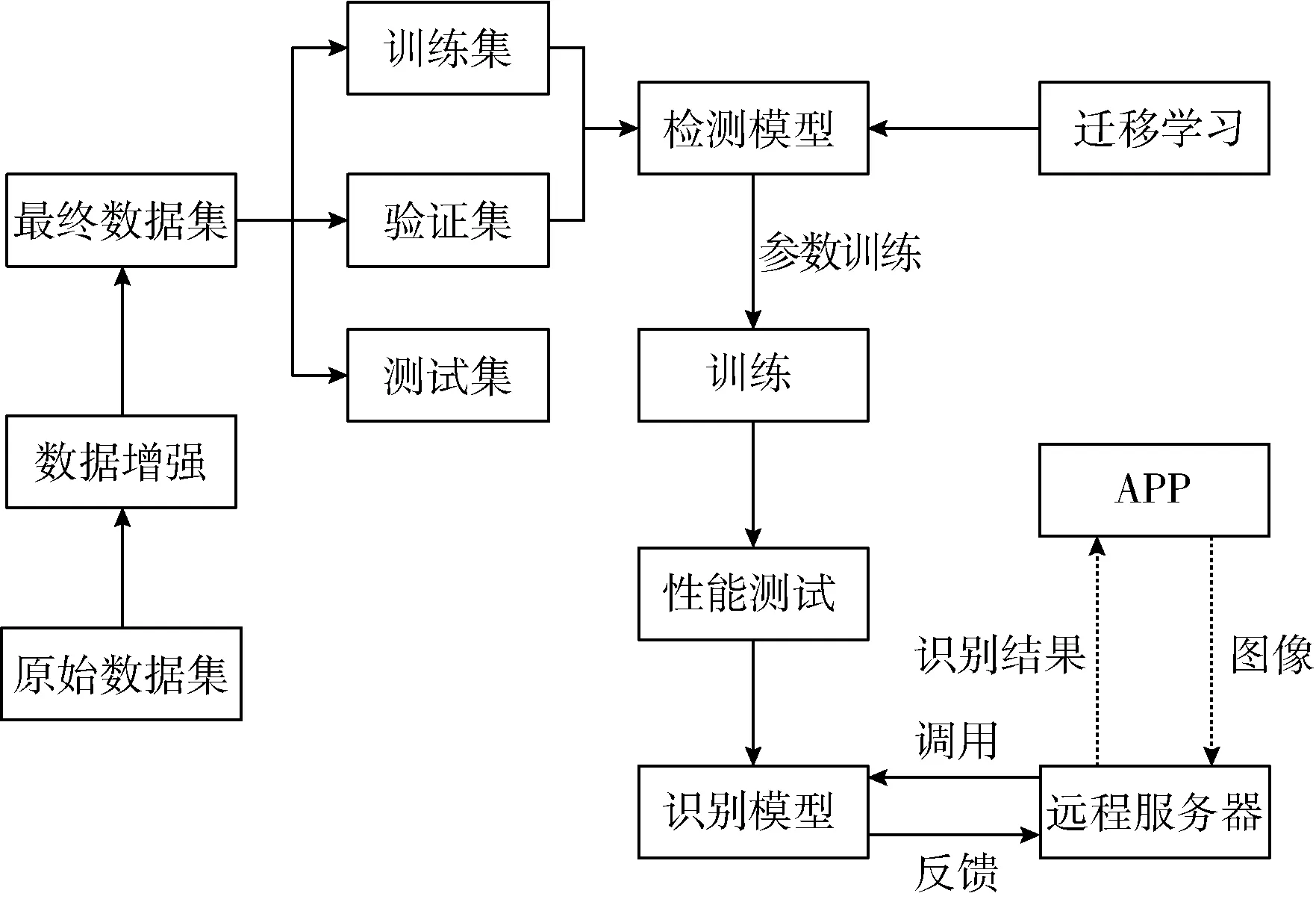
圖10 系統架構
3 模型訓練
3.1 數據集獲取
文本檢測和識別模型訓練分別使用獨立的數據集,文本檢測模型模型數據集通過拍攝和數據增強獲取,文本識別模型訓練數據集通過Text Recognition Data Generator分割生成。
3.1.1 文本檢測數據集
共搜集了板坯噴涂圖像741張,通過數據增強后共計4752張,標注為VOC數據格式。圖像樣本如圖11所示。

圖11 樣本圖像示例
3.1.2 文本識別數據集
以檢測數據集為基礎,通過Text Recognition Data Generator生成共計28 512張圖像,文本長度為20,線程數為32。示例如圖12所示。

圖12 文本識別數據
3.2 模型訓練
利用pycharm開發環境、Pytorch框架和Python語言訓練和測試模型。計算機內存為16 G,顯卡為NVIDIA Tesla T4。
3.2.1 文本檢測模型
特征提取網絡分別選用MobileNetV3、ResNet18、ResNet50以及本文提出的Res50-SE-ASFF-Net,訓練迭代次數為1000、2000、5000,基于遷移學習進行訓練,采用precision(精確率)、recall(召回率)、hmean(調和平均值)3項指標對模型進行評估。
3.2.2 文本識別模型
訓練場景為:訓練迭代次數為1000、2000、5000,基于遷移學習進行訓練,區分CNN與RNN是否聯合訓練,比較本文改進CNN中VGG網絡前后的模型性能,采用avg accuracy(平均準確率)為指標對模型進行評估。
4 結果與分析
4.1 文本檢測模型
表2對比了本文提出的Res50-SE-ASFF-Net與MobileNetV3、ResNet18、ResNet50在不同訓練迭代次數下的精確率、召回率和調和平均值,Res50-SE-ASFF-Net均為最優,訓練迭代次數為5000時,Res50-SE-ASFF-Net的精確率、召回率和調和平均值分別為93.30%、86.45%、89.85%,比MobileNetV3分別提高16.03%、13.44%、14.74%,比ResNet18分別提高9.01%、11.78%、10.65%,比ResNet50分別提高7.09%、7.92%、7.67%,表明本文算法魯棒性優秀。
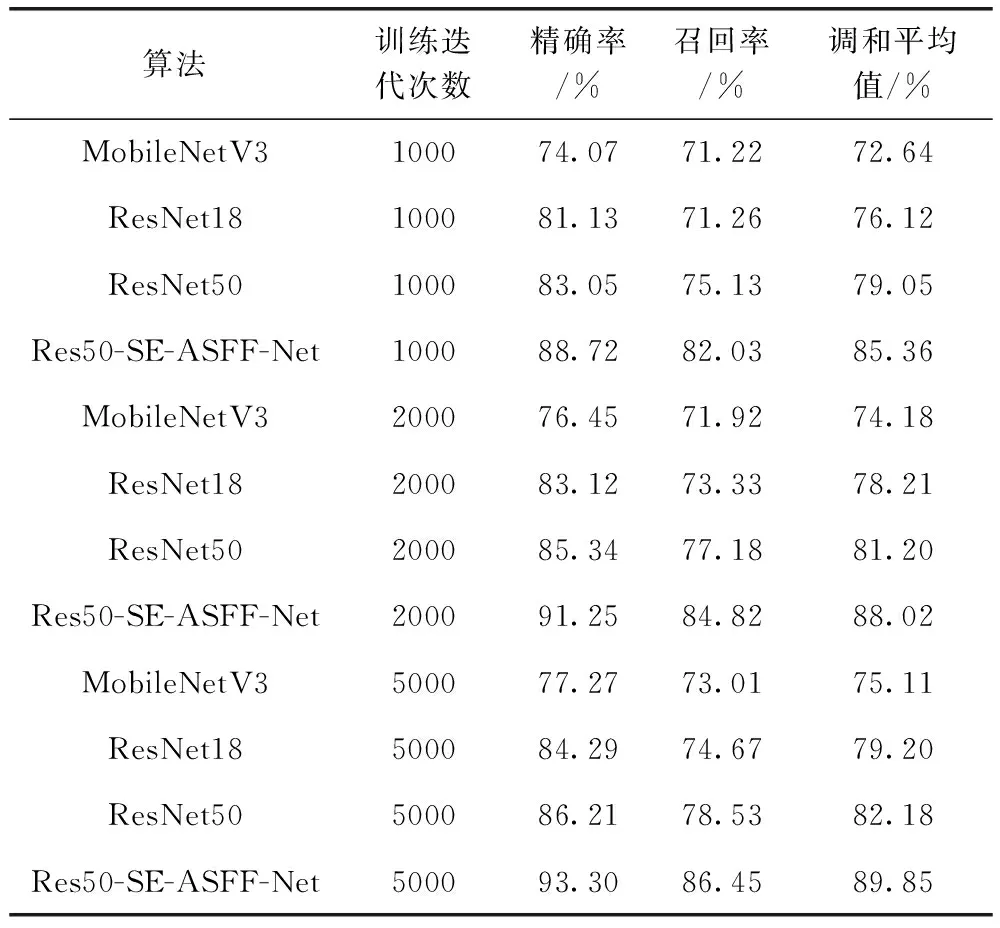
表2 文本檢測模型測試結果
4.2 文本識別模型
表3對比了不同實驗場景(VGG改進前后、CNN與RNN是否聯合訓練、不同訓練迭代次數)的平均準確率。結果表明,使用改進VGG網絡并且聯合訓練的場景,平均準確率指標最優,訓練迭代次數為5000時,平均準確率達到86.01%,比改進前的實驗指標提升了4.99%。
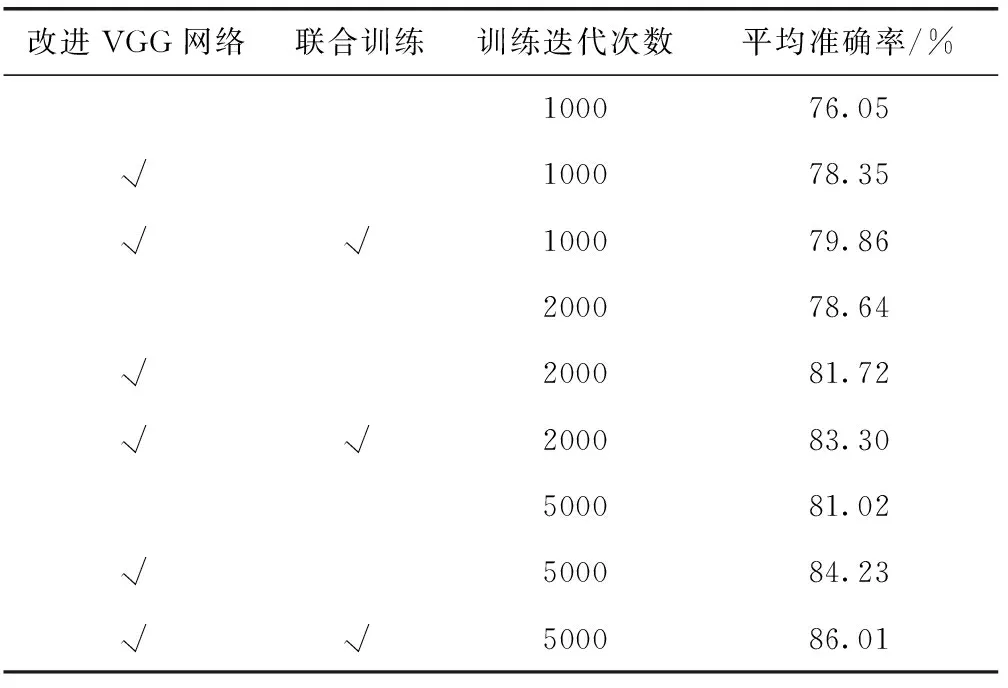
表3 文本識別模型測試結果
4.3 模型推理結果
對于文本檢測模型和文本識別模型改進后,進行了模型訓練和推理測試,如圖13所示,文本檢測模型準確列出文本候選框,文本識別模型準確對于檢測框中的文本進行了識別,模型推理效果好,檢測和識別準確度均較高。

圖13 模型檢測與識別結果
4.4 移動APP終端測試
移動端APP與服務器端使用Http協議進行交互,移動端APP拍攝圖像上傳至服務端,服務端調用噴涂面標識別模型進行識別,并將識別結果傳輸至移動終端APP。
基于4G網絡進行交互調試,從上傳圖像至展示識別數據,平均時長僅為2.1 s,數據識別準確率高,測試結果如圖14所示。
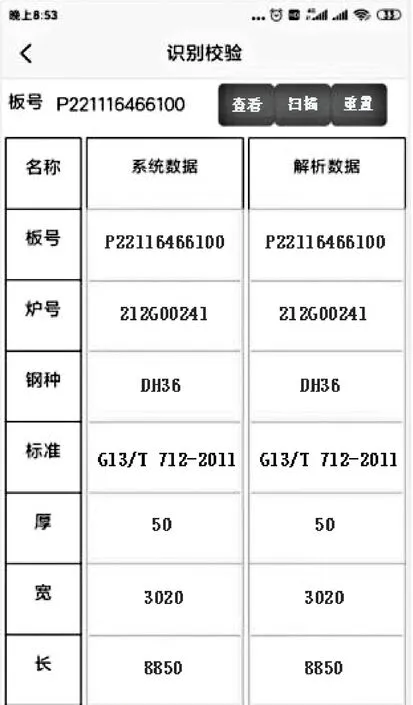
圖14 移動APP測試結果
5 結束語
(1)板坯面標文本檢測模型改進了DBNet網絡,引入了高效通道注意力模塊SENet,特征金字塔特征融合后進一步與自適應空間特征融合(ASFF)融合,解決了特征金字塔沖突問題,增強了特征金字塔預測多尺度目標的能力。測試結果表明,改進后檢測模型的精確率、召回率和調和平均值達到93.30%、86.45%、89.85%,比改進前網絡的最優測試結果分別提高了7.09%、7.92%、7.67%,檢測效果提升顯著。
(2)文本識別模型改進了CNN中的VGG網絡結構,使VGG中加入了BN層,將第3、4個最大池化層的卷積核尺寸由2×2改進為1×2,并將CNN與RNN進行聯合訓練,提升了訓練精度和網絡收斂速度。測試結果表明,改進后的CRNN識別模型平均準確率達到86.01%,較原算法精度提高4.99%,識別效果得到顯著提升。
(3)通過搭建移動端APP和服務端應用,將模型集成至軟件系統中,實現了模型算法推廣使用,測試結果表明,移動端APP識別過程僅2.1 s,識別準確度高,滿足實時與準確性要求。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
小學教學參考(2015年20期)2016-01-15 08:44:38
