基于動(dòng)態(tài)分區(qū)的網(wǎng)格水文模型分布式計(jì)算
2023-01-31 03:35:48王繼民劉賽佳李嘉瑋
計(jì)算機(jī)工程與設(shè)計(jì) 2023年1期
關(guān)鍵詞:模型
王繼民,劉賽佳,李嘉瑋
(河海大學(xué) 計(jì)算機(jī)與信息學(xué)院,江蘇 南京 211100)
0 引 言
網(wǎng)格水文模型屬于分布式水文模型[1]的一種,它將流域劃分為多個(gè)網(wǎng)格單元,每個(gè)網(wǎng)格具有獨(dú)立的參數(shù),能夠更加精細(xì)化考慮流域各種地理要素的空間異質(zhì)性,是解決眾多水文實(shí)際問(wèn)題的有效工具。姚成等[2]提出網(wǎng)格新安江模型并將其應(yīng)用于密賽流域,實(shí)驗(yàn)驗(yàn)證網(wǎng)格新安江模型相比于傳統(tǒng)的新安江模型能取得較高的模擬精度。
目前提高水文模型計(jì)算效率的方法多采用并行化計(jì)算框架[3]。Yue等[4]提出一種將分布式水文模型的計(jì)算流域劃分為大量子流域的并行計(jì)算方案,提高了模型計(jì)算效率。Chu等[5]提出了基于靜態(tài)任務(wù)分解的坡面-河道并行計(jì)算策略,提高了河流演算的并行效率。但并行計(jì)算方式當(dāng)模擬單元單一化時(shí)性能提升效率有限[6],數(shù)據(jù)分區(qū)可以根據(jù)節(jié)點(diǎn)的計(jì)算能力為其分配不同的計(jì)算任務(wù),從而提高并行計(jì)算的效率[7]。陳迪等[8]對(duì)Spark數(shù)據(jù)分區(qū)機(jī)制進(jìn)行優(yōu)化,基于微任務(wù)的思想,減輕了數(shù)據(jù)傾斜對(duì)整體系統(tǒng)性能的影響。朱迅等[9]提出了一種基于異構(gòu)Spark集群的分區(qū)動(dòng)態(tài)負(fù)載的調(diào)度算法,加快了Spark在異構(gòu)集群及集群復(fù)雜負(fù)載情況時(shí)的運(yùn)行速度。
雖然已有的并行化計(jì)算研究取得了一定的成果,但沒(méi)有細(xì)致考慮每個(gè)網(wǎng)格、模型每個(gè)步驟之間的并行關(guān)系。基于此,本文首先根據(jù)網(wǎng)格匯流流向特點(diǎn),提出了動(dòng)態(tài)數(shù)據(jù)分區(qū)方法,并在此基礎(chǔ)上提出了基于Spark的網(wǎng)格化水文模型分布式計(jì)算模型,并通過(guò)實(shí)驗(yàn)驗(yàn)證了所提模型的計(jì)算效果。
1 基于網(wǎng)格匯流的動(dòng)態(tài)數(shù)據(jù)分區(qū)方法
在網(wǎng)格水文模型分布式計(jì)算過(guò)程中,通常網(wǎng)格計(jì)算次序?qū)?yīng)的網(wǎng)格數(shù)量不同且差異較大,直接使用Spark的數(shù)據(jù)分區(qū)器會(huì)因計(jì)算次序選取不當(dāng)出現(xiàn)數(shù)據(jù)分區(qū)不平衡形成的數(shù)據(jù)傾斜現(xiàn)象[10]。這里的數(shù)據(jù)傾斜是指每個(gè)分區(qū)內(nèi)網(wǎng)格數(shù)量差異很大,這使得各分區(qū)任務(wù)執(zhí)行時(shí)間差異較大,網(wǎng)格數(shù)量較少的任務(wù)執(zhí)行完畢后對(duì)應(yīng)的worker節(jié)點(diǎn)將處于空閑狀態(tài),這導(dǎo)致了集群資源的極大浪費(fèi)。
本節(jié)根據(jù)網(wǎng)格匯流流向的參數(shù)特點(diǎn),將多個(gè)網(wǎng)格單元?jiǎng)討B(tài)合并為若干個(gè)大小近似且可同時(shí)計(jì)算的網(wǎng)格集合,有效地解決了數(shù)據(jù)傾斜問(wèn)題,并為分布式模型的計(jì)算提供了有力的支撐。
1.1 網(wǎng)格數(shù)據(jù)分區(qū)總體流程
網(wǎng)格數(shù)據(jù)分區(qū)主要包括網(wǎng)格數(shù)據(jù)分區(qū)單次計(jì)算過(guò)程以及網(wǎng)格單元更新操作。單次的數(shù)據(jù)分區(qū)計(jì)算過(guò)程包括計(jì)算集群的可用資源、根據(jù)網(wǎng)格流向計(jì)算上游網(wǎng)格坐標(biāo)、根據(jù)網(wǎng)格計(jì)算次序計(jì)算每個(gè)次序?qū)?yīng)的網(wǎng)格個(gè)數(shù),根據(jù)上述3個(gè)步驟計(jì)算結(jié)果對(duì)流域網(wǎng)格進(jìn)行動(dòng)態(tài)分區(qū);網(wǎng)格單元更新操作是對(duì)上一輪數(shù)據(jù)分區(qū)的上游網(wǎng)格參數(shù)進(jìn)行更新,剔除已完成計(jì)算的網(wǎng)格,重新進(jìn)行動(dòng)態(tài)數(shù)據(jù)分區(qū)操作。根據(jù)單次數(shù)據(jù)分區(qū)計(jì)算結(jié)果對(duì)網(wǎng)格單元信息進(jìn)行更新并再次進(jìn)行數(shù)據(jù)分區(qū)的過(guò)程稱為網(wǎng)格數(shù)據(jù)分區(qū)循環(huán)計(jì)算流程。
1.2 網(wǎng)格數(shù)據(jù)分區(qū)單次計(jì)算流程
網(wǎng)格數(shù)據(jù)分區(qū)單次計(jì)算方法可以將滿足分區(qū)要求的計(jì)算次序?qū)?yīng)的網(wǎng)格及其所有的上游網(wǎng)格根據(jù)分區(qū)數(shù)進(jìn)行均等劃分,減輕在集群計(jì)算的過(guò)程中出現(xiàn)數(shù)據(jù)傾斜現(xiàn)象,并且在之后的計(jì)算過(guò)程中對(duì)參與分區(qū)的所有網(wǎng)格同時(shí)計(jì)算,不再需要大量的數(shù)據(jù)聚合操作,減少了數(shù)據(jù)交互的次數(shù)。網(wǎng)格數(shù)據(jù)分區(qū)單次計(jì)算流程如圖1所示。
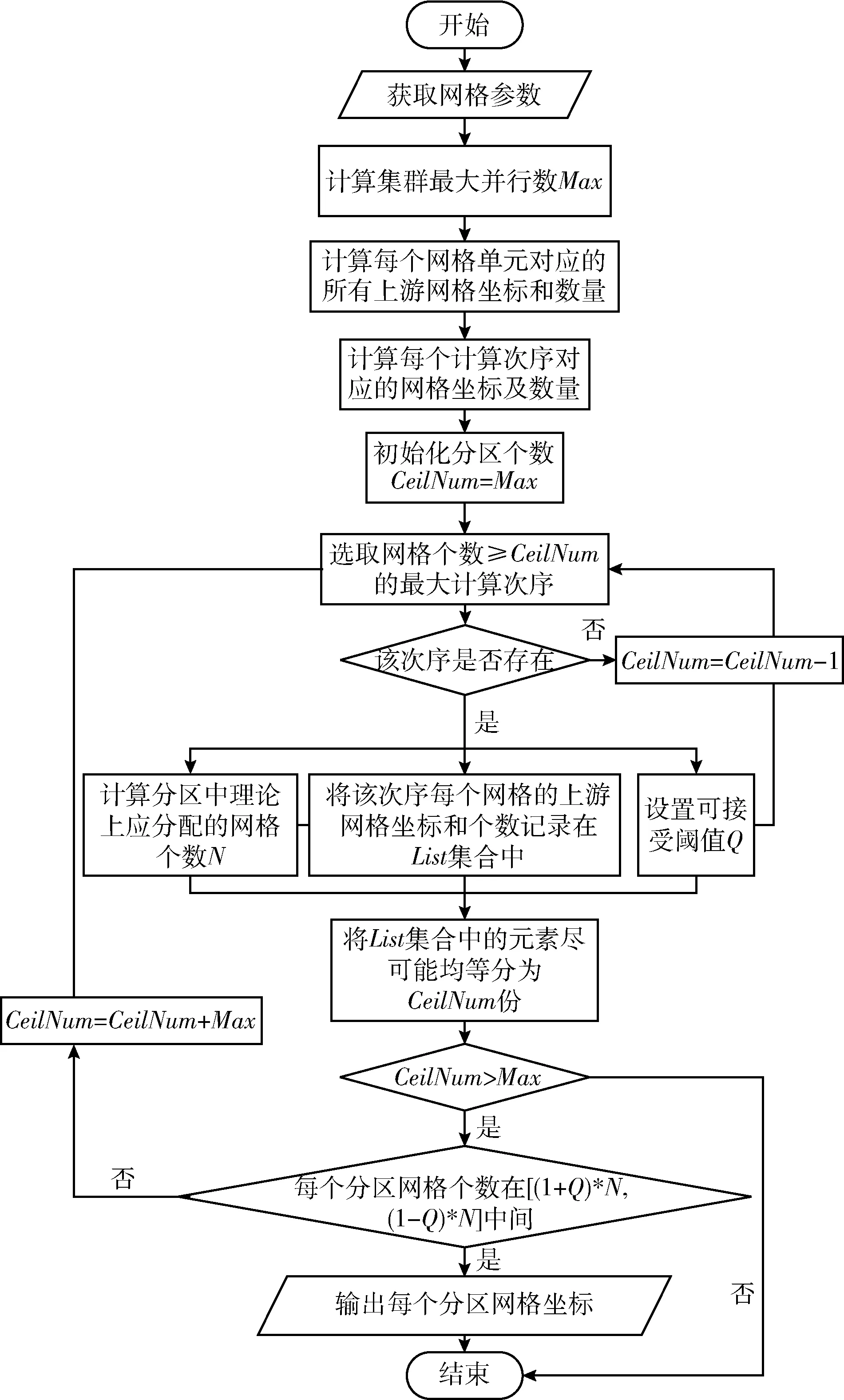
圖1 網(wǎng)格數(shù)據(jù)分區(qū)單次計(jì)算流程
網(wǎng)格數(shù)據(jù)分區(qū)單次計(jì)算的具體過(guò)程如下所示:
(1)計(jì)算集群的最大并行數(shù)Max。記集群中共有N個(gè)同構(gòu)的計(jì)算機(jī)作為Worker節(jié)點(diǎn),第CeilNum個(gè)節(jié)點(diǎn)中有Ei個(gè)Executor執(zhí)行器,每個(gè)執(zhí)行器有Ci個(gè)Core。集群的最大并行數(shù)由式(1)決定
(1)
(2)計(jì)算每個(gè)網(wǎng)格單元對(duì)應(yīng)的所有上游網(wǎng)格坐標(biāo)和數(shù)量。根據(jù)網(wǎng)格匯流流向參數(shù)計(jì)算出每個(gè)網(wǎng)格對(duì)應(yīng)的所有上游網(wǎng)格坐標(biāo)并以 “x1,y1,x2,y2…” 的格式存儲(chǔ)在字符串?dāng)?shù)組UpCeil中。遍歷UpCeil數(shù)組,其長(zhǎng)度記為L(zhǎng)en, 則該上游網(wǎng)格的個(gè)數(shù)為L(zhǎng)en/2, 并用數(shù)組UpCeilLen存儲(chǔ),即UpCeilLen[x][y]=k表示坐標(biāo)為 (x,y) 的網(wǎng)格單元的上游網(wǎng)格為k個(gè)。
(3)計(jì)算每個(gè)網(wǎng)格計(jì)算次序?qū)?yīng)的網(wǎng)格坐標(biāo)及數(shù)量。令無(wú)上游網(wǎng)格的網(wǎng)格單元計(jì)算次序?yàn)?,其余網(wǎng)格的計(jì)算次序由上游網(wǎng)格的最大計(jì)算次序加1。每個(gè)計(jì)算次序?qū)?yīng)的網(wǎng)格坐標(biāo)以 “x1,y1,x2,y2…” 的格式存儲(chǔ)在字符串?dāng)?shù)組Order-Ceil中。計(jì)算每個(gè)網(wǎng)格計(jì)算次序?qū)?yīng)的網(wǎng)格數(shù)量,用整型數(shù)組OrderCeilNum存儲(chǔ)。即OrderCeilNum[p]=q表示計(jì)算次序p對(duì)應(yīng)網(wǎng)格個(gè)數(shù)為q個(gè)。
(4)初始化分區(qū)數(shù)。劃分的分區(qū)數(shù)用CeilNum表示,在模型計(jì)算初始化時(shí)令分區(qū)數(shù)為Max。
(5)從大到小選擇網(wǎng)格個(gè)數(shù)大于等于CeilNum的計(jì)算次序。如果該次序不存在,執(zhí)行CeilNum遞減操作,最大程度的利用集群資源。假設(shè)滿足條件的最大計(jì)算次序?yàn)镻,對(duì)應(yīng)的網(wǎng)格單元個(gè)數(shù)有K個(gè),其中K≥CeilNum。 這K個(gè)網(wǎng)格單元對(duì)應(yīng)的上游網(wǎng)格數(shù)量用集合T表示,如式(2)所示
T={c1,c2,c3,…,ck}
(2)
其中,ci表示第i個(gè)網(wǎng)格單元對(duì)應(yīng)的上游網(wǎng)格數(shù)量。
(6)計(jì)算分區(qū)理想情況下的網(wǎng)格個(gè)數(shù)GNumequals并定義數(shù)據(jù)傾斜可接受范圍Q。數(shù)據(jù)傾斜即為分區(qū)之間數(shù)據(jù)量大小不同,Q越大表示分區(qū)之間數(shù)據(jù)大小差值的接受度越高。為了防止因Q過(guò)小出現(xiàn)無(wú)滿足條件的計(jì)算次序的問(wèn)題,Q隨著循環(huán)計(jì)算次數(shù)的增加而增大,即每循環(huán)一次Q為原來(lái)的二倍。理想情況下各個(gè)分區(qū)網(wǎng)格個(gè)數(shù)GNumequals的計(jì)算方法如式(3)所示
(3)
(7)對(duì)于滿足條件的K個(gè)網(wǎng)格單元,將每個(gè)網(wǎng)格坐標(biāo)及其對(duì)應(yīng)上游網(wǎng)格坐標(biāo)作為一個(gè)整體進(jìn)行數(shù)據(jù)劃分,根據(jù)數(shù)組UpCeilLen中K個(gè)網(wǎng)格的上游網(wǎng)格長(zhǎng)度將這K份網(wǎng)格盡可能均等劃分為CeilNum份,得到的分區(qū)網(wǎng)格數(shù)量可以用集合Nums表示,如式(4)所示
Nums{num1,num2,num3,…,numCeilNum}
(4)
其中,Numi表示第i個(gè)分區(qū)劃分得到的網(wǎng)格單元數(shù)量。
(8)若最終的分區(qū)個(gè)數(shù)小于等于集群最大并行數(shù)Max, 不再進(jìn)行分區(qū)條件判斷,直接結(jié)束數(shù)據(jù)分區(qū)過(guò)程。否則需要對(duì)集合Nums中的網(wǎng)格個(gè)數(shù)進(jìn)行判斷,若對(duì)于集合Nums中任意的numi, 都滿足式(5),則此次分區(qū)操作結(jié)束。否則意味著出現(xiàn)了不可接受的數(shù)據(jù)傾斜現(xiàn)象,需要重新進(jìn)行網(wǎng)格數(shù)據(jù)分區(qū)操作,直到滿足條件為止。為了快速尋找到下一個(gè)滿足條件的計(jì)算次序,本方法將CeilNum的增量設(shè)置為Max, 即下次的分區(qū)操作的分區(qū)個(gè)數(shù)CeilNum=CeilNum+Max
GNumequals*(1-Q)≤numi≤GNumequals*(1+Q)
(5)
1.3 網(wǎng)格數(shù)據(jù)分區(qū)循環(huán)計(jì)算流程
1.2節(jié)詳細(xì)的介紹了網(wǎng)格數(shù)據(jù)分區(qū)方法的單次計(jì)算流程,該方法在保證水文模擬過(guò)程正確的情況下,盡可能將網(wǎng)格動(dòng)態(tài)劃分為多個(gè)大小相近、可以同時(shí)計(jì)算的網(wǎng)格集合。但是一次的網(wǎng)格分區(qū)操作并不能完成整個(gè)流域的水文模擬過(guò)程,因此,本小節(jié)設(shè)計(jì)了網(wǎng)格數(shù)據(jù)分區(qū)循環(huán)計(jì)算方法。該方法對(duì)上次分區(qū)結(jié)果對(duì)存儲(chǔ)網(wǎng)格信息變量進(jìn)行更新并重新進(jìn)行數(shù)據(jù)分區(qū)操作。網(wǎng)格數(shù)據(jù)分區(qū)循環(huán)計(jì)算具體的過(guò)程如下:
(1)初始化網(wǎng)格單元標(biāo)志位參數(shù)flag[][]。 若flag[i][j]=0則表示坐標(biāo)為 (i,j) 的網(wǎng)格未進(jìn)行分區(qū)計(jì)算,若flag[i][j]=1則表示坐標(biāo)為 (i,j) 的網(wǎng)格已經(jīng)完成分區(qū)計(jì)算。
(2)調(diào)用網(wǎng)格數(shù)據(jù)分區(qū)單次計(jì)算方法。由于上游網(wǎng)格信息更新取決于上次的數(shù)據(jù)分區(qū)涉及的網(wǎng)格,所以需要先進(jìn)行一次數(shù)據(jù)分區(qū)操作。
(3)獲取網(wǎng)格數(shù)據(jù)分區(qū)操作中選擇的計(jì)算次序K。若K等于當(dāng)前流域網(wǎng)格的最大計(jì)算次序,則說(shuō)明所有網(wǎng)格計(jì)算完畢,結(jié)束數(shù)據(jù)分區(qū)循環(huán)操作。否則進(jìn)入步驟(4)。
(4)獲取已分區(qū)網(wǎng)格坐標(biāo)。對(duì)于步驟(2)計(jì)算過(guò)程中已進(jìn)行分區(qū)的網(wǎng)格坐標(biāo)使用字符串?dāng)?shù)組進(jìn)行存儲(chǔ),網(wǎng)格坐標(biāo)形式依然為 “x,y”。 令flag[x][y]=1, 表示這些網(wǎng)格不再進(jìn)行分區(qū)計(jì)算。
(5)遍歷計(jì)算次序大于K的網(wǎng)格對(duì)應(yīng)的上游網(wǎng)格坐標(biāo),從中剔除flag為1的網(wǎng)格單元。根據(jù)更新之后的上游網(wǎng)格坐標(biāo)數(shù)組UpCeil, 計(jì)算上游網(wǎng)格個(gè)數(shù)并對(duì)上游網(wǎng)格數(shù)量數(shù)組UpCeilLen進(jìn)行更新。更新完之后再次調(diào)用網(wǎng)格數(shù)據(jù)劃分單次計(jì)算方法,直至步驟(3)中的計(jì)算次序等于流域網(wǎng)格的最大計(jì)算次序。
2 基于Spark的網(wǎng)格水文模型分布式計(jì)算模型
模型的總體結(jié)構(gòu)如圖2所示,共包括四大部分:模型參數(shù)描述規(guī)范、模型構(gòu)建及依賴描述規(guī)范、構(gòu)件任務(wù)調(diào)度及計(jì)算、計(jì)算結(jié)果整合。模型參數(shù)描述采用了NetCDF(network common data form)規(guī)范對(duì)網(wǎng)格水文模型參數(shù)進(jìn)行統(tǒng)一的描述[11,12];模型構(gòu)件及依賴關(guān)系描述采用XML(extensible markup language)規(guī)范進(jìn)行描述;構(gòu)件任務(wù)調(diào)度及計(jì)算指的是通過(guò)解析NetCDF的網(wǎng)格水文模型參數(shù)文件以及模型構(gòu)件及依賴關(guān)系描述文件,獲取參數(shù)與構(gòu)件信息,在分布式計(jì)算過(guò)程中采用不同的數(shù)據(jù)分區(qū)方法進(jìn)行網(wǎng)格分區(qū),調(diào)用構(gòu)件計(jì)算文件進(jìn)行計(jì)算;計(jì)算結(jié)果的整合以NetCDF的形式進(jìn)行保存。
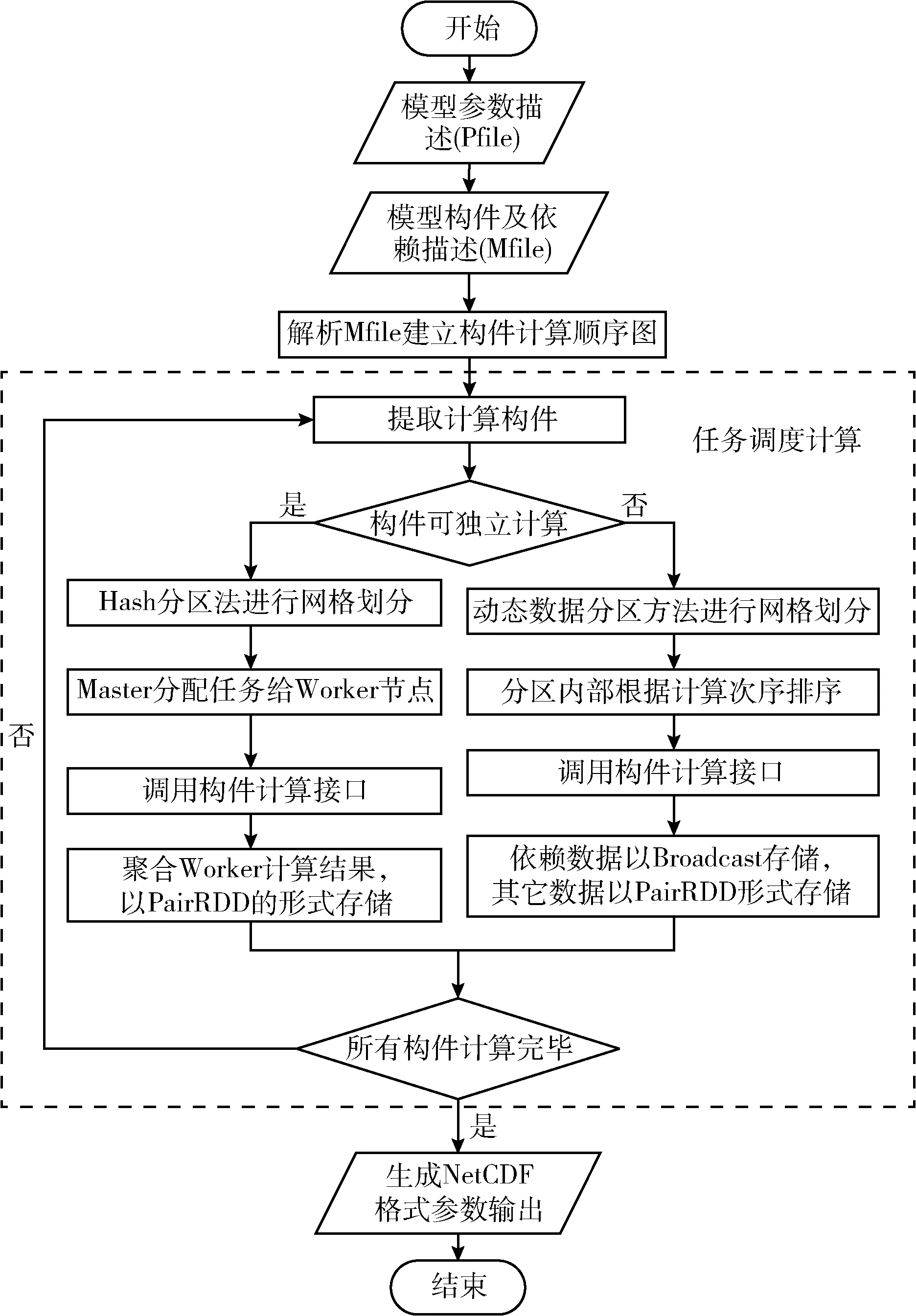
圖2 模型總體結(jié)構(gòu)
2.1 基于NetCDF的網(wǎng)格水文模型參數(shù)描述
網(wǎng)格水文模型參數(shù)包括三大類型:模型參數(shù)、流域基本信息參數(shù)和流域?qū)崟r(shí)信息參數(shù)。
(1)模型參數(shù)
模型參數(shù)在程序設(shè)計(jì)中對(duì)應(yīng)的是數(shù)值型變量。對(duì)標(biāo)量參數(shù)的描述從變量標(biāo)準(zhǔn)名稱(standard_name)、單位(units)和取值范圍(valid_range)這3個(gè)方面進(jìn)行描述。其中standard_name在參數(shù)描述中為必要屬性,valid屬性和units屬性為非必要屬性。
(2)流域基本信息參數(shù)
流域基本信息參數(shù)的存儲(chǔ)形式為二維數(shù)組。在上述信息描述的基礎(chǔ)上,從標(biāo)準(zhǔn)名稱(standard_name)、取值范圍(valid_range)、無(wú)效值(_FillValue)和單位(units)這4個(gè)方面對(duì)流域基本信息參數(shù)進(jìn)行描述。
(3)流域?qū)崟r(shí)信息參數(shù)
流域?qū)崟r(shí)信息參數(shù)比流域基本信息參數(shù)多一維時(shí)間維度為三維數(shù)組。因此在流域基本信息描述的基礎(chǔ)上增加對(duì)時(shí)間序列的描述即為流域?qū)崟r(shí)信息參數(shù)的描述方法。流域?qū)崟r(shí)信息參數(shù)的時(shí)間序列分為兩種類型,一類由連續(xù)的時(shí)間序列構(gòu)成,這類數(shù)據(jù)的時(shí)間維度變量值可以為空,參數(shù)值的時(shí)間點(diǎn)個(gè)數(shù)根據(jù)模型參數(shù)中的開始時(shí)間、結(jié)束時(shí)間和時(shí)間間隔計(jì)算得出;第二類為包含間隔點(diǎn)的時(shí)間序列,當(dāng)時(shí)間出現(xiàn)斷點(diǎn)的時(shí)候,需要用數(shù)組的形式對(duì)有記錄的時(shí)間點(diǎn)進(jìn)行存儲(chǔ)。
2.2 基于XML的網(wǎng)格水文模型構(gòu)件及關(guān)系描述
網(wǎng)格水文模型一般是由多個(gè)構(gòu)件組成,根據(jù)各構(gòu)件的計(jì)算特點(diǎn),將網(wǎng)格水文模型構(gòu)件分為獨(dú)立計(jì)算構(gòu)件、數(shù)據(jù)依賴構(gòu)件和參數(shù)聚合構(gòu)件。
獨(dú)立計(jì)算構(gòu)件是在單個(gè)網(wǎng)格單元中的計(jì)算過(guò)程并不涉及其它網(wǎng)格單元的參數(shù)信息的一類構(gòu)件,數(shù)據(jù)依賴構(gòu)件指的是在計(jì)算過(guò)程中需要依賴網(wǎng)格的上游網(wǎng)格的參數(shù)信息的一類構(gòu)件,參數(shù)聚合構(gòu)件用于各個(gè)構(gòu)件計(jì)算結(jié)果的聚合以及結(jié)果保存操作,負(fù)責(zé)將各個(gè)模塊的計(jì)算結(jié)果以NetCDF的形式保存到指定路徑中,不屬于按照水文模擬過(guò)程劃分的構(gòu)件。
網(wǎng)格水文模型的構(gòu)件(components)描述屬性一般包括構(gòu)件名稱(componentName)、構(gòu)件編號(hào)(conponentId)、構(gòu)件存儲(chǔ)路徑(componentPath)、構(gòu)件函數(shù)入口(componentFuction)、參數(shù)路徑(paramPath)、前置構(gòu)件標(biāo)識(shí)(precoms)、結(jié)果輸出路徑(resultOutPath)、依賴參數(shù)標(biāo)識(shí)(relParamId)、構(gòu)件計(jì)算類型(componentType)和構(gòu)件保存類型(saveType)這10個(gè)方面的基本信息,其中依賴參數(shù)標(biāo)識(shí)為數(shù)據(jù)依賴構(gòu)件特有的子元素,用來(lái)存儲(chǔ)依賴參數(shù)的標(biāo)識(shí),便于依賴數(shù)據(jù)交互操作。構(gòu)件描述的結(jié)構(gòu)如圖3所示,其中componentType屬性取值有0、1和2這3種,0代表該構(gòu)件為獨(dú)立計(jì)算構(gòu)件,1代表該構(gòu)件為數(shù)據(jù)依賴構(gòu)件,2代表該構(gòu)件為參數(shù)聚合構(gòu)件;saveType屬性取值為0和1兩種,0代表exe存儲(chǔ)方式,1代表Jar包存儲(chǔ)方式。
2.3 構(gòu)件調(diào)度及計(jì)算
2.3.1 獨(dú)立計(jì)算構(gòu)件分布式計(jì)算過(guò)程
獨(dú)立計(jì)算構(gòu)件的分布式計(jì)算相對(duì)簡(jiǎn)單,不需要考慮網(wǎng)格單元之間的數(shù)據(jù)依賴問(wèn)題。關(guān)于獨(dú)立計(jì)算構(gòu)件分布式計(jì)算流程具體步驟如下:
(1)獲取構(gòu)件計(jì)算所需參數(shù)。首先解析NetCDF文檔得到構(gòu)件計(jì)算所需參數(shù)。將解析到的流域基本和實(shí)時(shí)參數(shù)以網(wǎng)格為單位使用字符串?dāng)?shù)組的形式進(jìn)行存儲(chǔ)。
(2)參數(shù)格式轉(zhuǎn)換。獲取網(wǎng)格參數(shù)信息之后,將其轉(zhuǎn)化為Spark的RDD的形式。解析網(wǎng)格參數(shù)字符串信息,獲取網(wǎng)格單元的計(jì)算次序作為Key,將整個(gè)參數(shù)字符串作為Value,將RDD轉(zhuǎn)換為PairRDD形式[13-15]。
(3)根據(jù)網(wǎng)格計(jì)算次序進(jìn)行排序操作。該步驟主要是根據(jù)Key值對(duì)PairRDD進(jìn)行排序,便于數(shù)據(jù)依賴構(gòu)件的計(jì)算。
(4)網(wǎng)格參數(shù)分區(qū)操作。獨(dú)立計(jì)算構(gòu)件使用Spark中自帶的HashPartitioner分區(qū)器進(jìn)行分區(qū),因?yàn)樵摌?gòu)件計(jì)算與網(wǎng)格單元的計(jì)算次序無(wú)關(guān),所以不需要根據(jù)網(wǎng)格流向進(jìn)行數(shù)據(jù)劃分。
(5)構(gòu)件計(jì)算。該步驟主要是執(zhí)行構(gòu)件算法的代碼,將解析之后的網(wǎng)格參數(shù)傳遞到構(gòu)件函數(shù)中。
(6)結(jié)果處理。完成步驟(5)之后就可以得到構(gòu)件的計(jì)算結(jié)果,計(jì)算結(jié)果一般為與時(shí)間相關(guān)的一組參數(shù)。構(gòu)件的計(jì)算結(jié)果以NetCDF的形式進(jìn)行存儲(chǔ)。
2.3.2 數(shù)據(jù)依賴構(gòu)件分布式計(jì)算過(guò)程
數(shù)據(jù)依賴構(gòu)件的計(jì)算過(guò)程并不完全是網(wǎng)格獨(dú)立的,在計(jì)算過(guò)程中涉及到上游網(wǎng)格單元的計(jì)算結(jié)果,需要使用基于網(wǎng)格流向的Spark動(dòng)態(tài)數(shù)據(jù)分區(qū)算法,可以減少各分區(qū)網(wǎng)格數(shù)量的差異,同一計(jì)算次序?qū)?yīng)的網(wǎng)格及其上游網(wǎng)格也可以同時(shí)計(jì)算,從而提高模型的計(jì)算效率。數(shù)據(jù)依賴構(gòu)件分布式計(jì)算流程如圖4所示。
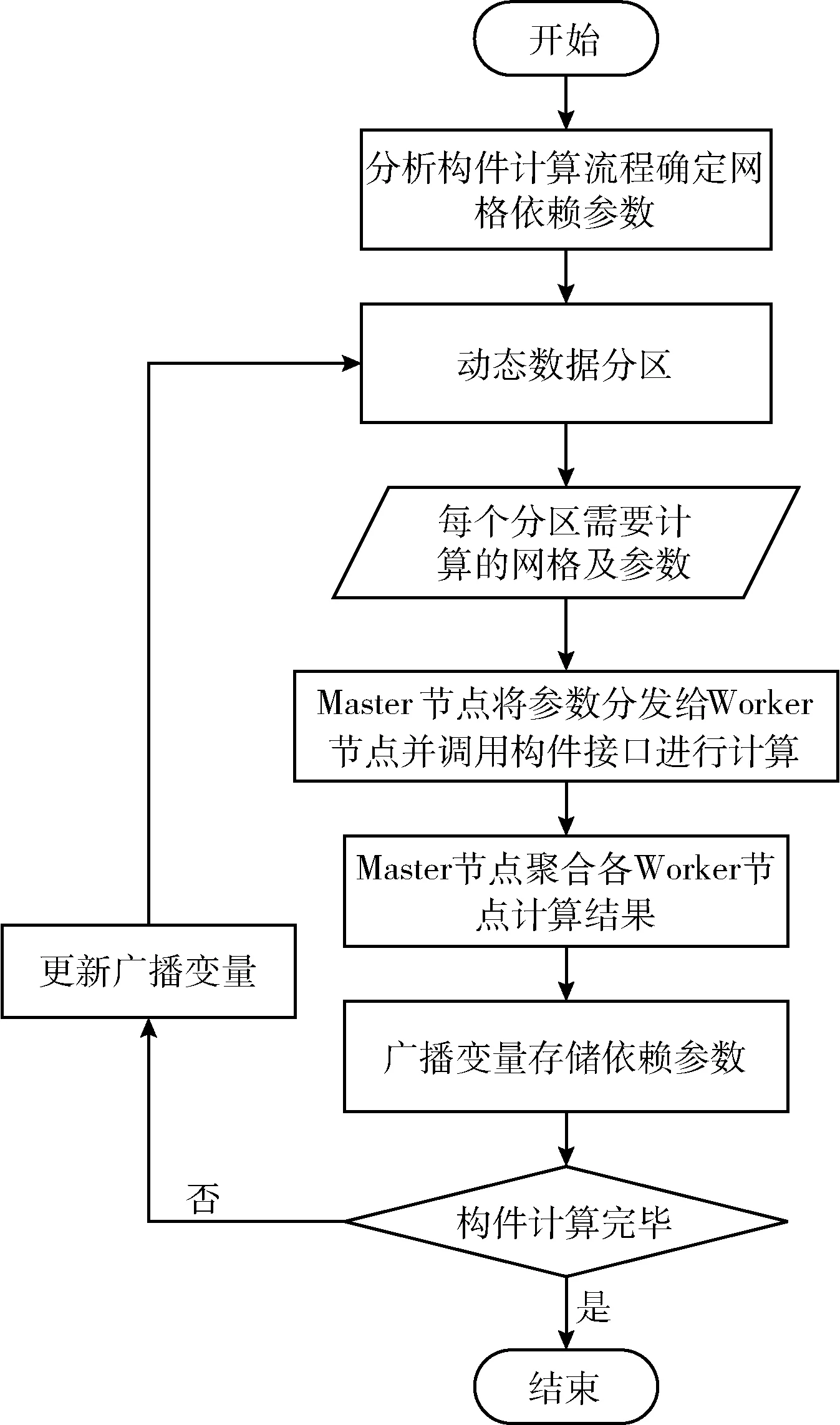
圖4 數(shù)據(jù)依賴構(gòu)件分布式計(jì)算流程
數(shù)據(jù)依賴構(gòu)件計(jì)算的具體過(guò)程如下:
(1)參數(shù)預(yù)處理。通過(guò)分析構(gòu)件計(jì)算流程,確定網(wǎng)格依賴參數(shù)。將讀取的參數(shù)轉(zhuǎn)化為Spark計(jì)算需要的PariRDD格式,其中Key為網(wǎng)格坐標(biāo),Value為參數(shù)值。
(2)動(dòng)態(tài)數(shù)據(jù)分區(qū)方法進(jìn)行分區(qū)操作。通過(guò)動(dòng)態(tài)數(shù)據(jù)分區(qū)方法,確定每個(gè)Worker節(jié)點(diǎn)需要計(jì)算的網(wǎng)格,將對(duì)應(yīng)的網(wǎng)格參數(shù)傳輸?shù)较鄳?yīng)的節(jié)點(diǎn)上,Worker節(jié)點(diǎn)調(diào)用構(gòu)件計(jì)算接口,進(jìn)行構(gòu)件計(jì)算,執(zhí)行完成之后將該網(wǎng)格的flag[x][y] 置為1。
(3)計(jì)算結(jié)果聚合。Master節(jié)點(diǎn)聚合各個(gè)Worker節(jié)點(diǎn)的計(jì)算結(jié)果,并將網(wǎng)格依賴的參數(shù)存儲(chǔ)到廣播變量中。
(4)更新廣播變量。步驟(3)所計(jì)算的網(wǎng)格單元的部分計(jì)算結(jié)果需要作為下一批網(wǎng)格的輸入?yún)?shù),對(duì)計(jì)算結(jié)果進(jìn)行解析,獲取共享變量對(duì)應(yīng)的計(jì)算結(jié)果并進(jìn)行更新,將更新的結(jié)果重新分發(fā)出去。
(5)判斷網(wǎng)格是否計(jì)算完畢,若沒(méi)有計(jì)算完畢,則進(jìn)行步驟(2)再次進(jìn)行分布式計(jì)算操作,直至所有網(wǎng)格計(jì)算完成。
3 分布式計(jì)算模型驗(yàn)證
本節(jié)以網(wǎng)格新安江模型為實(shí)驗(yàn)?zāi)P停酝拖饔驗(yàn)閷?shí)驗(yàn)流域,實(shí)驗(yàn)分為兩部分,第一部分驗(yàn)證動(dòng)態(tài)數(shù)據(jù)分區(qū)的有效性。第二部分驗(yàn)證本文模型在Spark本地模式和Standalone模式下計(jì)算效率的提高。
第一部分實(shí)驗(yàn)采用Java編寫的網(wǎng)格新安江水文模型對(duì)屯溪流域水文模擬的匯流過(guò)程數(shù)據(jù)分區(qū)進(jìn)行對(duì)比,實(shí)驗(yàn)數(shù)據(jù)為屯溪流域網(wǎng)格劃分?jǐn)?shù)據(jù)、網(wǎng)格流向參數(shù)和網(wǎng)格單元計(jì)算次序參數(shù)。
實(shí)驗(yàn)分別使用本文提出的基于網(wǎng)格匯流的Spark動(dòng)態(tài)數(shù)據(jù)分區(qū)方法與基于集群最大并行數(shù)的Spark靜態(tài)數(shù)據(jù)分區(qū)方法對(duì)屯溪流域進(jìn)行網(wǎng)格單元?jiǎng)澐郑?duì)使用這兩種方法劃分得到的分區(qū)網(wǎng)格數(shù)量差異進(jìn)行對(duì)比,設(shè)置分區(qū)數(shù)分別為4和6,Q為0.1。
4分區(qū)當(dāng)且僅當(dāng)計(jì)算次序?yàn)?1時(shí)候滿足動(dòng)態(tài)分區(qū)的閾值要求且并行數(shù)為4,將本次實(shí)驗(yàn)的結(jié)果與Spark靜態(tài)分區(qū)方法進(jìn)行對(duì)比,4分區(qū)結(jié)果對(duì)比如圖5所示。
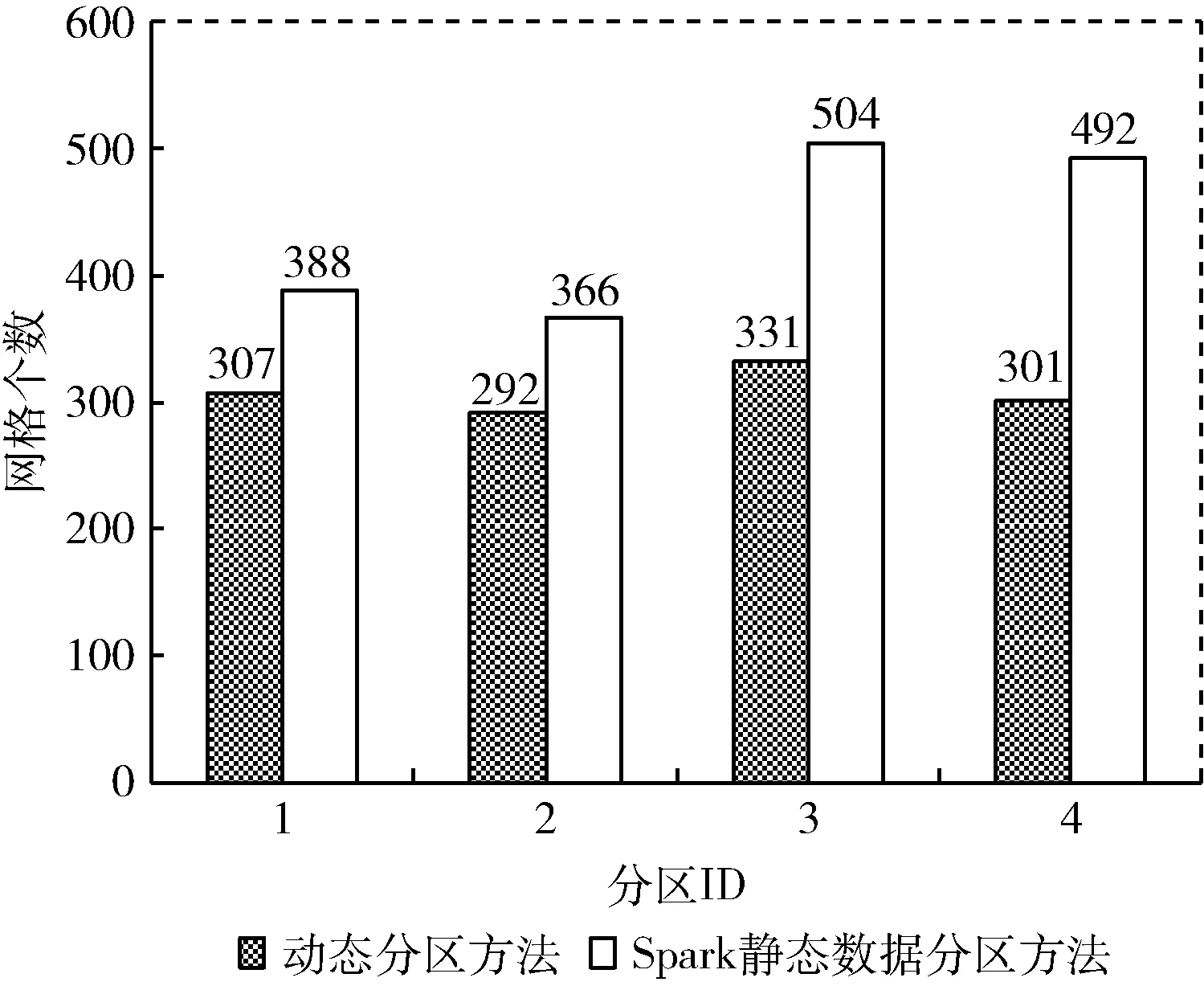
圖5 4分區(qū)結(jié)果對(duì)比
如圖5所示,網(wǎng)格計(jì)算次序21對(duì)應(yīng)的動(dòng)態(tài)數(shù)據(jù)分區(qū)方法得到的分區(qū)結(jié)果的最大值331與最小值292的差值在平均值的10%以內(nèi),但是Spark靜態(tài)數(shù)據(jù)分區(qū)方法對(duì)應(yīng)的分區(qū)網(wǎng)格個(gè)數(shù)的最大值504與最小值366的差值超過(guò)了平均值的20%。
6分區(qū)時(shí)需要8次分區(qū)即可完成屯溪流域網(wǎng)格的劃分操作。將前兩次分區(qū)數(shù)為6的分區(qū)結(jié)果合并與Spark靜態(tài)分區(qū)方法得到的分區(qū)結(jié)果進(jìn)行對(duì)比,6分區(qū)結(jié)果對(duì)比如圖6所示。
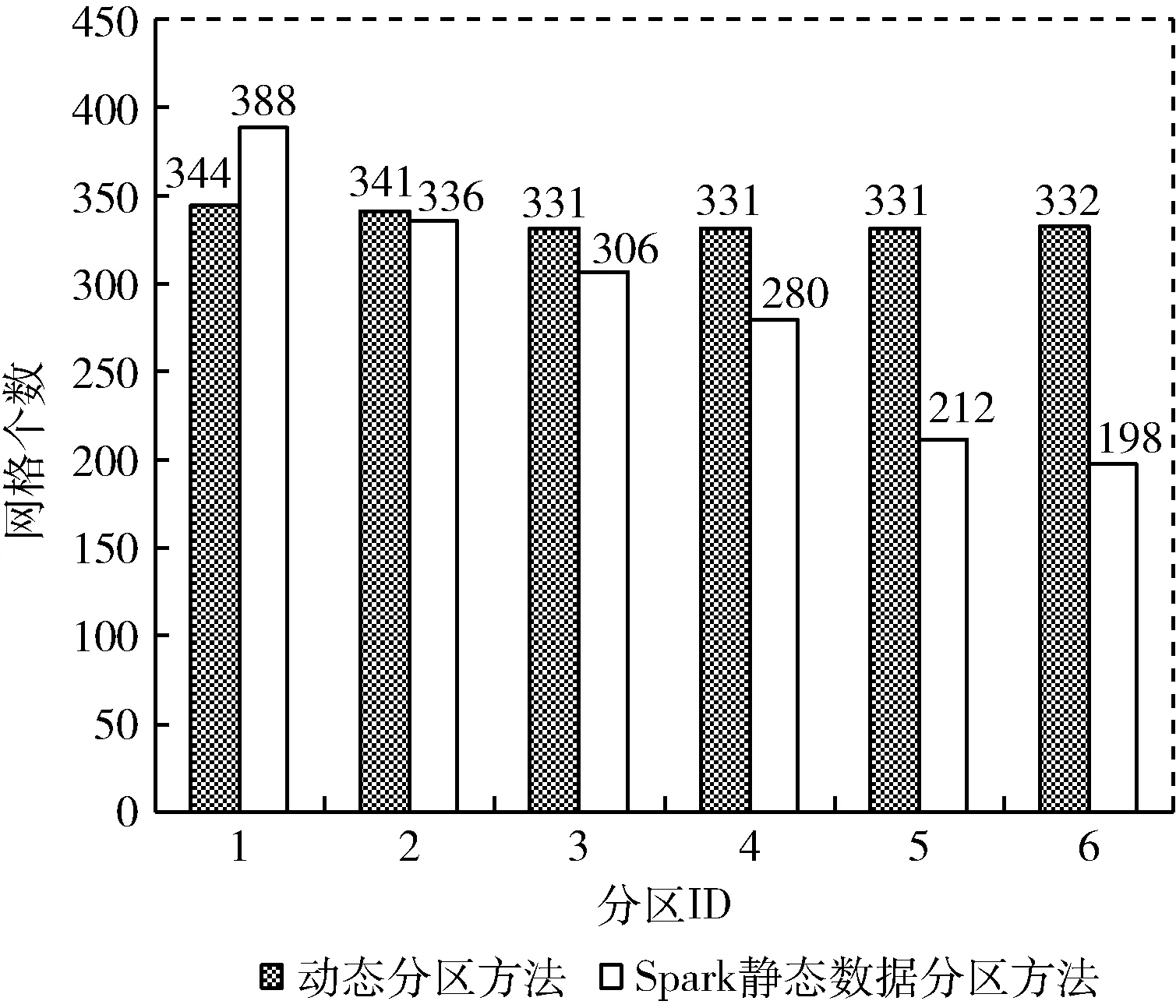
圖6 6分區(qū)結(jié)果對(duì)比
圖6中的動(dòng)態(tài)分區(qū)方法的結(jié)果各個(gè)分區(qū)的最大值與最小值的差值均小于平均值的10%;使用Spark靜態(tài)分區(qū)方法得到的分區(qū)結(jié)果的最大分區(qū)網(wǎng)格個(gè)數(shù)為388,最小分區(qū)網(wǎng)格個(gè)數(shù)為198,兩者之間的差值遠(yuǎn)高于平均值的10%。
由第一部分實(shí)驗(yàn)可以得到本文提出的動(dòng)態(tài)數(shù)據(jù)分區(qū)方法能保持較好的分區(qū)數(shù)據(jù)平衡性,且適應(yīng)于不同的分區(qū)數(shù)情況。通過(guò)與Spark靜態(tài)分區(qū)結(jié)果進(jìn)行對(duì)比,驗(yàn)證了本文方法在解決網(wǎng)格水文模型數(shù)據(jù)分區(qū)中的數(shù)據(jù)傾斜問(wèn)題的有效性。
第二部分實(shí)驗(yàn)分為兩組,第一組使用一臺(tái)PC機(jī),內(nèi)存大小為24 G,CPU型號(hào)為i5-7900HQ。第二組集群由3臺(tái)1核CPU、4 G內(nèi)存虛擬機(jī)構(gòu)成,兩組實(shí)驗(yàn)的分布式計(jì)算模型的分區(qū)數(shù)均為4。
(1)Spark本地模式本文方法與網(wǎng)格新安江模型串行計(jì)算方法對(duì)比。
對(duì)于第一組實(shí)驗(yàn)中3天~27天的預(yù)熱期(從實(shí)測(cè)開始時(shí)間到預(yù)報(bào)開始時(shí)間的時(shí)間間隔),分別使用上述兩種模型對(duì)網(wǎng)格新安江模型進(jìn)行計(jì)算,網(wǎng)格新安江模型計(jì)算時(shí)間結(jié)果對(duì)比如圖7所示。每一次計(jì)算的具體時(shí)間見表1。
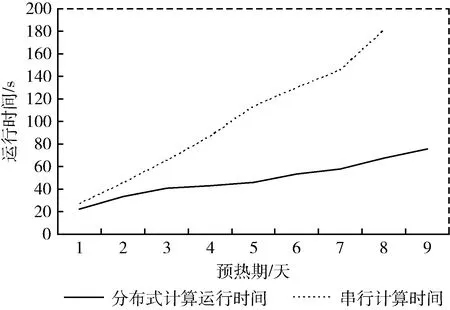
圖7 網(wǎng)格新安江模型計(jì)算時(shí)間結(jié)果對(duì)比
由圖7和表1可知,隨著水文計(jì)算時(shí)間的延長(zhǎng),本文提出的網(wǎng)格水文模型分布式計(jì)算模型的優(yōu)勢(shì)逐步顯示出來(lái)。在預(yù)熱期小于24天的時(shí)候,與已有的網(wǎng)格新安江模型串行計(jì)算方法相比,分布式計(jì)算模型的加速比逐步增加。水文模擬時(shí)間為15天時(shí),分布式計(jì)算模型的運(yùn)行效率是串行計(jì)算模型計(jì)算效率的2.46倍,水文模擬時(shí)間達(dá)到24天時(shí),計(jì)算效率提升至2.68倍。水文模擬時(shí)間為27天時(shí),已有網(wǎng)格新安江模型串行計(jì)算方法出現(xiàn)了內(nèi)存溢出的情況,無(wú)法再進(jìn)行模型計(jì)算,而分布式依然保持著較好的運(yùn)行速率。
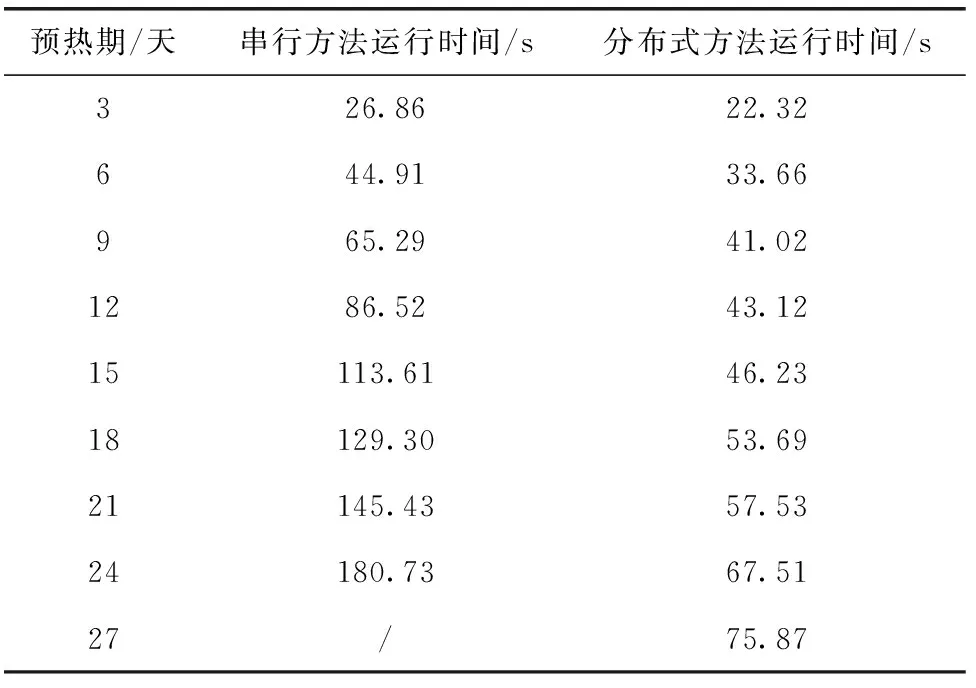
表1 串行計(jì)算與分布式計(jì)算方法結(jié)果
圖8為網(wǎng)格新安江模型長(zhǎng)歷時(shí)水文模擬分布式計(jì)算方法運(yùn)行結(jié)果圖,分別對(duì)1個(gè)月、2個(gè)月、3個(gè)月時(shí)長(zhǎng)水文模擬進(jìn)行計(jì)算。為了延長(zhǎng)模型可計(jì)算的水文模擬時(shí)間,本模型根據(jù)計(jì)算的水文模擬時(shí)長(zhǎng)度,每增長(zhǎng)一個(gè)月的預(yù)熱期,就增加分區(qū)數(shù),即一個(gè)月水文模擬計(jì)算的分區(qū)數(shù)為4,兩個(gè)月水文模擬計(jì)算分區(qū)數(shù)為8,3個(gè)月水文模擬計(jì)算的分區(qū)數(shù)為12,防止單個(gè)任務(wù)過(guò)大引起的內(nèi)存溢出問(wèn)題。
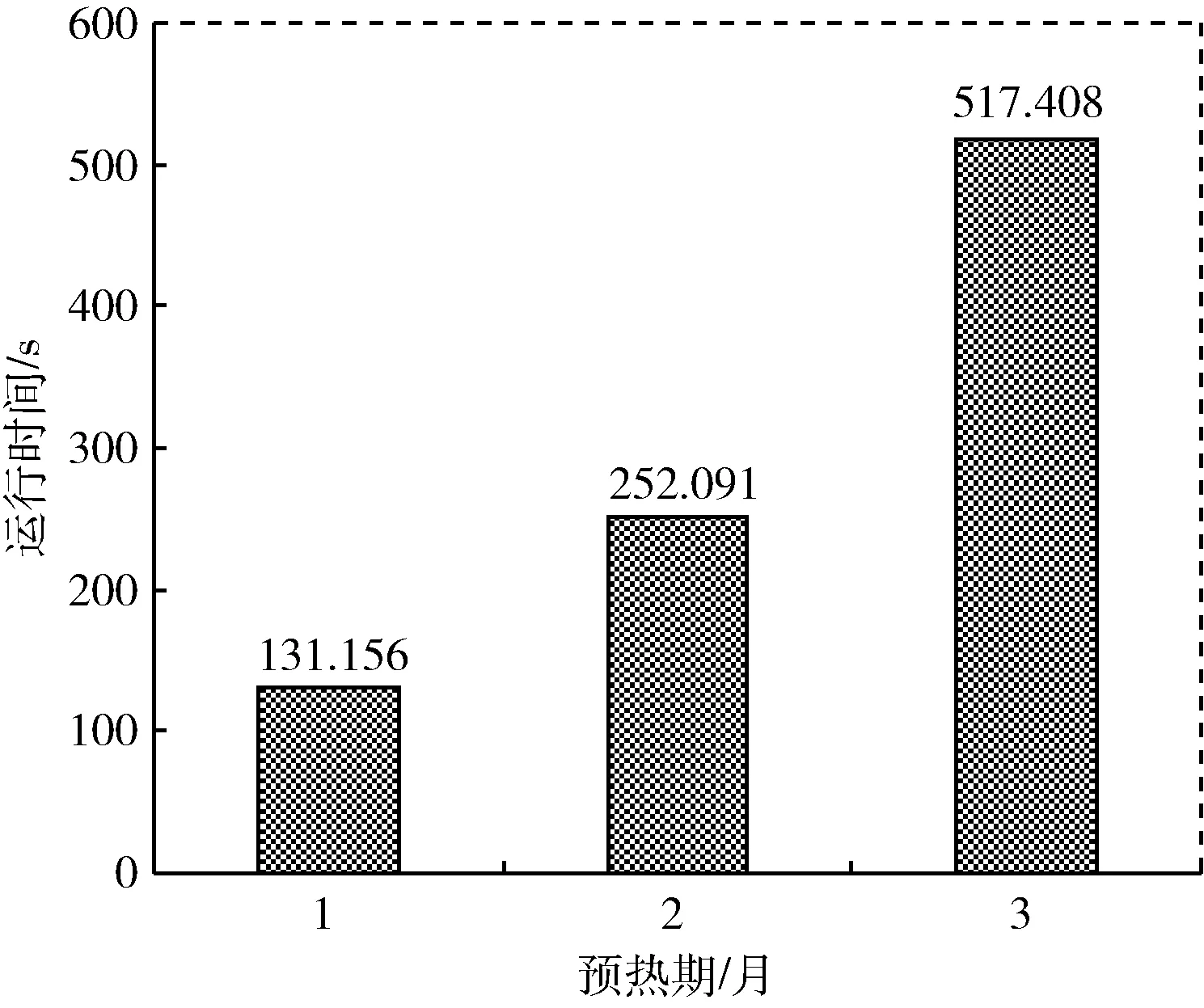
圖8 網(wǎng)格新安江模型長(zhǎng)歷時(shí)水文模擬分布式計(jì)算運(yùn)行時(shí)間結(jié)果
(2)Spark的Standalone模式下本文模型與基于網(wǎng)格計(jì)算次序并行化的計(jì)算思想實(shí)現(xiàn)的分布式計(jì)算模型對(duì)比。
由于實(shí)驗(yàn)環(huán)境的限制,無(wú)法在Standalone模式下進(jìn)行長(zhǎng)時(shí)間的水文模擬計(jì)算。分別在Standalone集群模式下對(duì)3天水文模擬時(shí)長(zhǎng)至27天水文模擬時(shí)長(zhǎng)中的8組時(shí)長(zhǎng)進(jìn)行實(shí)驗(yàn)。圖9為兩種方法在Standalone集群模式下的運(yùn)行時(shí)間結(jié)果,每次計(jì)算的具體時(shí)間見表2。
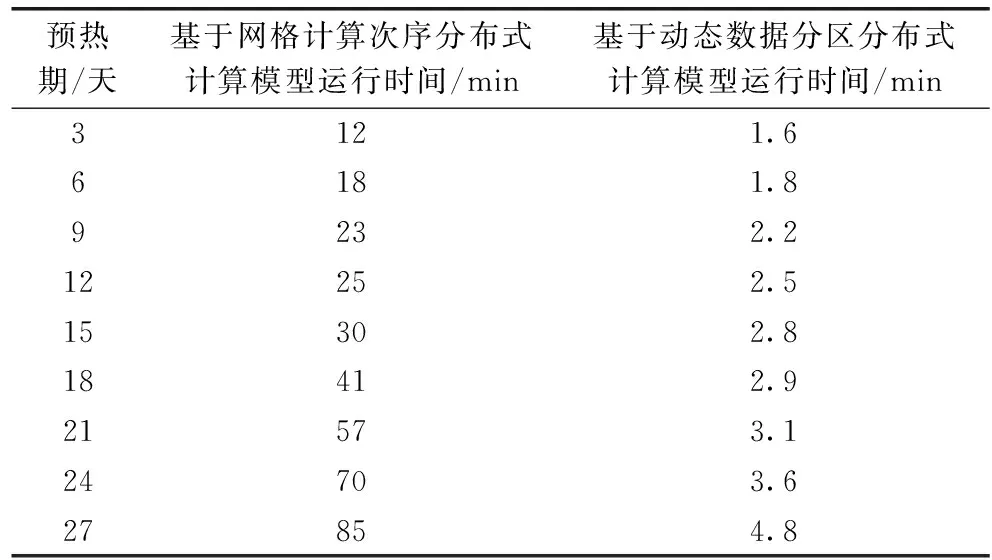
表2 Standalone模式下模型計(jì)算時(shí)間結(jié)果
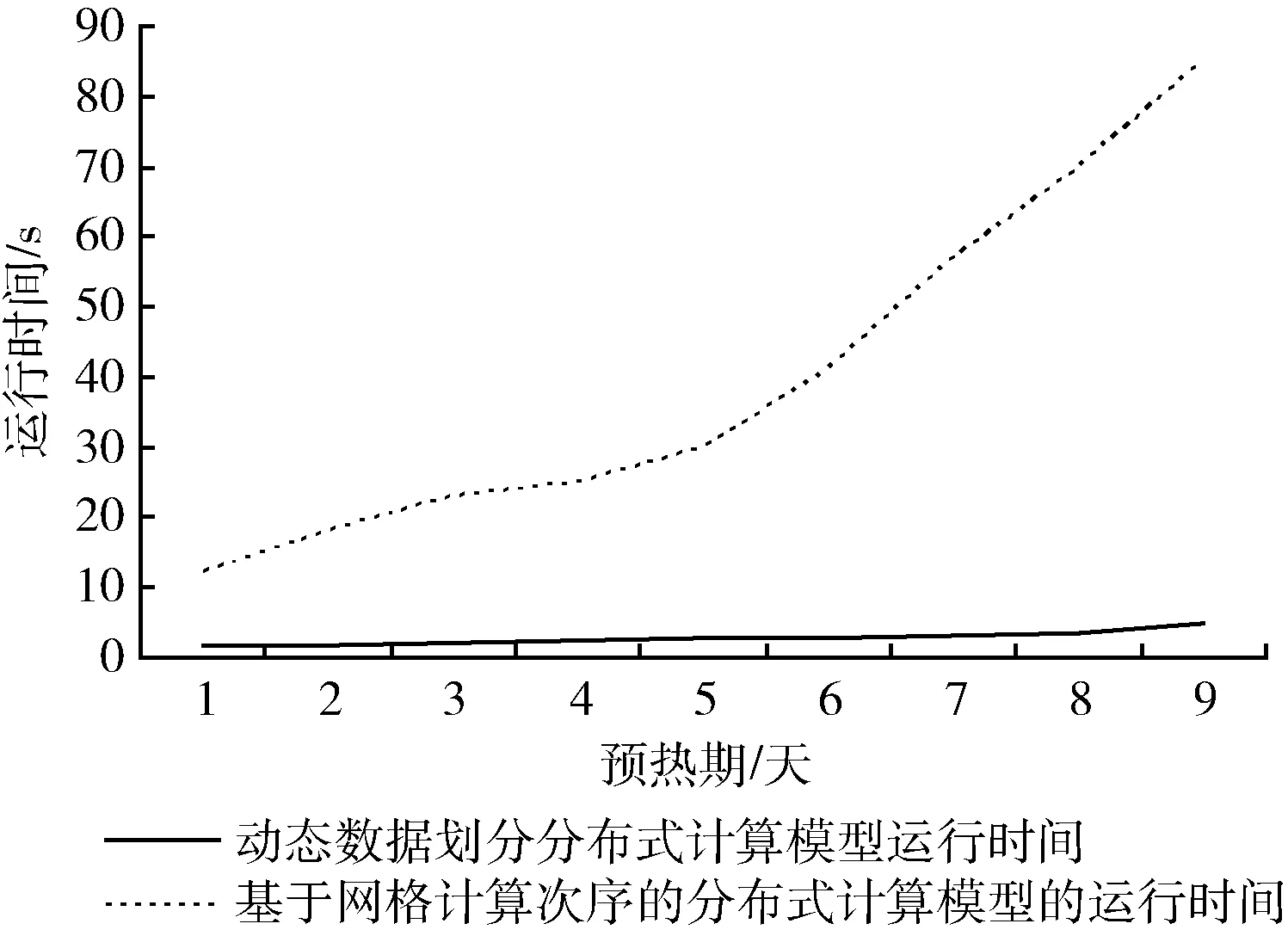
圖9 Standalone模式下模型計(jì)算時(shí)間結(jié)果
屯溪流域網(wǎng)格新安江模型的網(wǎng)格單元計(jì)算次序最大為100,在基于網(wǎng)格計(jì)算次序分布式計(jì)算模型中,對(duì)于相同計(jì)算次序的網(wǎng)格單元計(jì)算完成之后進(jìn)行數(shù)據(jù)聚合操作,再進(jìn)行
下一步的計(jì)算。因此,該模型在匯流構(gòu)件至少有100次數(shù)據(jù)聚合操作。而本文的分布式計(jì)算模型根據(jù)網(wǎng)格流向?qū)⒘饔蚓W(wǎng)格劃分為多個(gè)網(wǎng)格集合,在整個(gè)分布式計(jì)算過(guò)程中只需要4次的數(shù)據(jù)聚合操作,解決了因?yàn)轭l繁的數(shù)據(jù)交互操作造成計(jì)算時(shí)間過(guò)長(zhǎng)的現(xiàn)象。從表2可以看出,使用動(dòng)態(tài)數(shù)據(jù)分區(qū)方法構(gòu)建的分布式計(jì)算模型,在Standalone集群模式下計(jì)算效率有大幅度的提升。
從上述兩組實(shí)驗(yàn)可知,無(wú)論是在一臺(tái)計(jì)算機(jī)中使用Spark的本地模式還是由多臺(tái)計(jì)算機(jī)構(gòu)成的Standalone模式,本文提出的網(wǎng)格水文模型分布式計(jì)算模型均能夠明顯提高模型計(jì)算效率,且能夠有效延長(zhǎng)水文模擬總體時(shí)長(zhǎng)。在第二組實(shí)驗(yàn)中,將網(wǎng)格新安江模型的數(shù)據(jù)交互次數(shù)從100降至4次,再次驗(yàn)證了本文提出的基于網(wǎng)格流向的Spark動(dòng)態(tài)數(shù)據(jù)分區(qū)方法在減少數(shù)據(jù)聚合操作方面的有效性。
4 結(jié)束語(yǔ)
為了提高網(wǎng)格水文模型的計(jì)算效率,本文致力于研究基于多臺(tái)性能有限的計(jì)算機(jī)集群環(huán)境下的網(wǎng)格水文模型高效計(jì)算方法,根據(jù)網(wǎng)格流向參數(shù)特點(diǎn),提出了基于網(wǎng)格流向參數(shù)特點(diǎn)的動(dòng)態(tài)數(shù)據(jù)分區(qū)方法,有效解決了網(wǎng)格水文模型分布式計(jì)算過(guò)程中出現(xiàn)的數(shù)據(jù)傾斜問(wèn)題,并在此基礎(chǔ)上提出了基于Spark的網(wǎng)格水文模型分布式計(jì)算模型,并通過(guò)實(shí)驗(yàn)驗(yàn)證了該模型帶來(lái)的計(jì)算效果的提升。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
