車聯網中基于麻雀搜索算法的計算卸載策略
2023-01-31 03:54:56王宗山聶仁燦丁洪偉
計算機工程與設計 2023年1期
楊 超,王宗山,聶仁燦,丁洪偉+,李 波
(1.云南大學 信息學院,云南 昆明 650504; 2.云南大學 云南省高校物聯網技術及應用重點實驗室,云南 昆明 650504)
0 引 言
車聯網技術的快速發展使得車載終端的業務環境更加復雜,出現了大量的計算密集型和時延敏感型業務,例如:自動駕駛、實時路況和語音識別等[1,2]。這些任務不僅數據量較大,而且對處理的實時性具有較高要求,因此完成此類業務的計算需要消耗大量計算資源。然而,車輛有限的計算資源將難以滿足此類計算任務的時延需求[3]。為解決這一問題,邊緣計算(mobile edge computing,MEC)作為一種新興的技術被引入到車聯網中,能有效降低任務執行時延,減少車輛本地計算資源占用,從而極大提升用戶體驗[4]。
計算卸載作為MEC的關鍵技術之一,是有效提升任務處理效率和減少計算時延的重要手段。目前車聯網場景下的MEC系統(MEC-based vehicular network system,VEC)計算卸載主要解決車載應用任務是否需要卸載以及為每個計算任務分配多少資源的問題。現有研究主要從減少MEC系統資源服務費[5]、最小化任務執行時延和設備能耗[6,7]、車輛在動態環境中的任務調度策略[8]、內容驅動的計算卸載策略[9]、基于優先級劃分的任務卸載策略[10]入手解決車載應用的計算卸載問題。但是,上述方案沒有同時考慮VEC系統中計算任務優先級劃分和車聯網動態場景下的計算卸載決策,且算法收斂速度慢。
針對目前研究存在的問題,本文綜合考慮了車聯網動態場景下的計算卸載決策和任務優先級劃分,使得緊急的任務優先得到處理。本文以最小化VEC系統的計算時延和MEC資源服務費為目標,提出一種基于麻雀搜索算法的計算卸載策略,在保證緊急任務優先得到處理的同時均衡系統中MEC服務器負載,提高任務處理效率。
1 系統模型
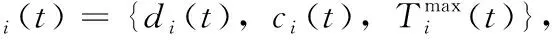
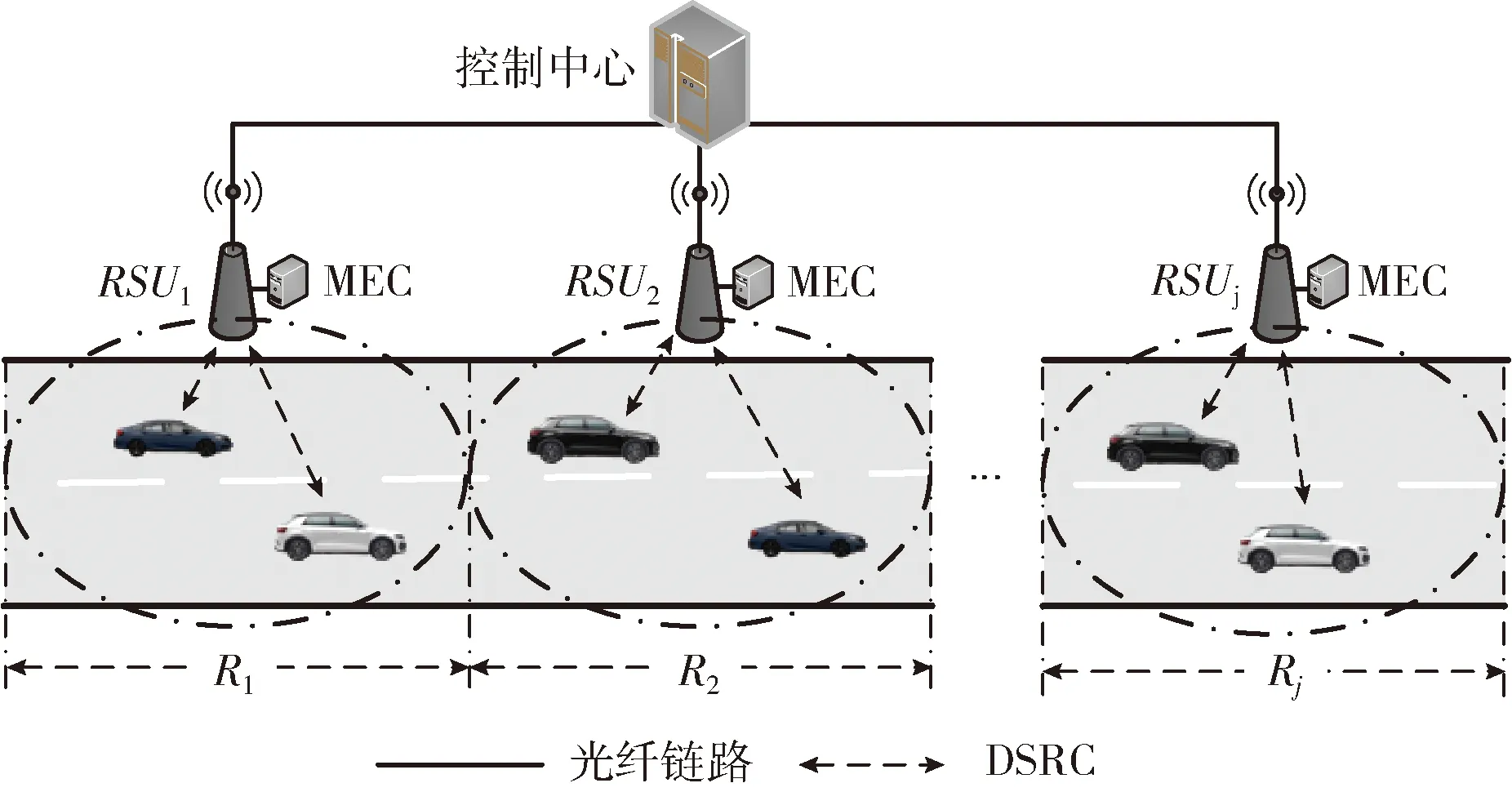
圖1 車聯網計算卸載模型
1.1 計算卸載模型
為了使系統中的計算資源得到充分利用,車輛i產生的計算任務Ti(t) 可以在本地執行(all local process,ALP)也可以卸載到MEC(all offload to mec process,AOMP)服務器執行。本文把t時刻任務Ti(t) 的卸載決策變量定義為xij(t) 且其值只能取0或1,即xij(t)∈{0,1}, 其意義可表示為
(1)
此外,由于計算任務不可分解,因此t時刻任務Ti(t) 只能選擇一種卸載策略,即xij(t) 中的元素只有一個元素為1其余全為0,該約束條件可表述為
(2)
則t時刻所有車輛的卸載決策矩陣可定義為
(3)
為了方便描述,本文把計算任務在本地和MEC服務器處理的集合分別定義為Nl={i∈N|xi0(t)=1} 和No={i∈N|xij(t)=1},j∈M。
1.2 通信模型
假設圖1所述場景中車輛i在道路上以速度vi勻速行駛,車輛i的移動使其與第j個RSU之間的距離dij也時刻在產生變化,則dij可定義為
(4)
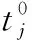
當車輛把計算任務卸載到MEC服務器執行時,車輛需要與RSU進行通信,其上下行鏈路可以建模為頻率平坦型快衰落的瑞利信道[13]。則由香農公式可以把車輛i上傳數據至RSUj的傳輸速率定義為
(5)
其中,B為上行鏈路帶寬;pi為車輛i的發射功率;σ2為背景噪聲方差[14]。hij(t) 為車輛i與RSUj之間的信道增益,其可以通過車輛與RSU之間的直線距離進行計算[15],即
hij(t)=103.8+20.9log10dij(t)
(6)
1.3 計算模型
在此VEC系統中,車輛可以將計算任務卸載到計算資源較為充足的MEC服務器處理或選擇直接在本地處理。當車輛將任務卸載到MEC服務器處理時,對應的MEC服務器將會為其分配計算資源,同時用戶也將根據計算資源的使用情況向運營商繳納費用。因此,本文主要以車輛處理任務的總時延和MEC資源服務費的加權和來衡量整個系統的性能。
1.3.1 MEC卸載模型
當車輛把計算任務Ti卸載到MEC服務器處理時,任務的處理的總時延為任務上傳時延和任務計算時延。此外,由于RSU的發射功率遠大于車輛且計算結果的數據量遠小于任務上傳的數據量,因此計算結果回傳的時延可以忽略[16]。則車輛i在t時刻與RSUj的傳輸時延可定義為
(7)
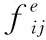
(8)
此外,運營商還將根據用戶使用MEC資源的多少來收取服務費[17]。若把MEC服務器計算資源的單價定義為ρ,則車輛i的計算開銷φij(t) 可寫為
(9)
綜上,車輛i在MEC服務器j處理任務的效用函數可定義為
(10)
其中,μi∈[0,1] 為車輛i對時延和資源服務費的偏好。
1.3.2 本地處理模型
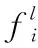
(11)
因此,t時刻車輛i本地計算的效用函數為
(12)
此外,為保證車輛計算任務的連續性及在限定時間內完成任務卸載,則任務卸載的總時延不應超過該任務的最大容忍時延Tmax,且要求任務計算卸載在車輛離開RSU的覆蓋范圍前完成,這兩個約束條件可表示為
(13)
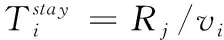
1.4 任務優先級處理
當車輛需要將計算任務卸載時,由于每個任務的數據量大小,最大時延容忍度和任務類型不同,導致需要分配的計算資源和處理順序也不同。因此本系統將對卸載的任務進行優先級劃分,保證緊急的任務優先處理[18]。本文采用層次分析法(analytic hierarchy process,AHP)來劃分任務的優先級,通過AHP算法給每個任務分配處理的優先級,使得緊急的任務得到優先處理,進而實現更合理的卸載決策。
(14)
采用特征向量法計算,每個任務中影響因素的權重即
Aβ=λmaxβ
(15)
其中,β為權重向量,λmax為矩陣A最大的特征值。
由β及各影響因素即可算出任務Ti在t時刻的分數Ci(t)
(16)
最后,對所有任務的分數進行歸一化處理即為對應任務的優先級,把執行任務的優先級向量定義為W=[w1,w2,…,wN], 則任務執行優先級的計算方式為
(17)
1.5 目標函數
本文主要以車輛處理任務的總時延和MEC服務器計算資源服務費來衡量整個系統的性能,因此系統的目標函數為可定義為任務處理時延和MEC服務器計算資源服務費的加權和,如式(18)所示

(18)
在式(18)中,Fmax為單個MEC服務器最大計算能力。約束條件C1~C2表示卸載決策只有0和1兩種取值且同一時刻只能取0或1;C3~C4表示MEC服務器為對應車輛分配的計算資源需大于0且不能超過服務器的最大計算能力;C5表示車輛自身也擁有一定的計算資源;C6表示車輛計算任務的卸載需要保證服務質量和任務執行的連續性。
2 基于麻雀搜索算法的計算卸載策略
問題Q1為混合整數非線性規劃(mixed-integer nonli-near programming,MINLP)問題[19],應用窮舉法可以獲得此問題的最優解,但是窮舉法將遍歷所有可能結果,因此計算量較大會造成較高的延時,并不適合用于對實時性要求較高的車聯網場景中。因此,本文提出一種基于麻雀搜索算法的計算卸載算法(computing offloading based on sparrow search algorithm,COSSA)來解決該問題。麻雀搜索算法(sparrow search algorithm,SSA)算法是模擬麻雀的覓食和反捕食行為的一種生物啟發式算法,與灰狼算法(grey wolf optimizer,GWO)、粒子群算法(particle swarm optimization,PSO)等啟發式算法相比,SSA具有良好的全局搜索能力,且收斂速度較快,可以有效的避免陷入局部最優值等優點[20]。
2.1 編 碼
在式(3)中,卸載決策矩陣X (t) 被定義為只有0或1兩種取值的離散變量,為了適應SSA的更新策略,本文對X (t) 進行整數編碼。具體方式為:把X (t) 中的每一行看成二進制數然后轉換成十進制整數,則t時刻車輛i的卸載決策由一個二進制向量編碼為一個整數xi, 則編碼后的卸載決策向量可定義為
X(t)=[x1(t),…,xi(t),…,xN(t)],i∈N
(19)
其中, xi是根據卸載決策矩陣X (t) 中的行向量計算而來,計算方式為
(20)
以M=2,N=3的場景中卸載決策的編碼為例來說明上述編碼過程,假設卸載決策矩陣見表1。

表1 卸載決策矩陣
表1所示的卸載決策矩陣的含義為:第1輛車卸載至編號為1的MEC服務器;第2輛車卸載至編號為2的MEC服務器;第3輛車為本地處理。則根據式(21),該卸載決策矩陣可編碼為:X(t)=[2,1,4]。
2.2 適應度函數
系統的優化目標是最小化車輛處理任務的總時延和MEC服務器計算資源費用,則麻雀種群的適應度值可表示為
(21)
2.3 COSSA算法流程
在SSA算法中,麻雀初始種群位置定義為Sn=(sn1,sn2,…,snd), 其中n表示種群中麻雀的數量,d表示變量的維度其值為X(t) 的維度即:d=N。 則第n只麻雀的適應度值為fn=f(sn1,sn2,…,snd)。 根據麻雀的捕食習性,具有較高適應度值的麻雀(發現者)在搜索過程中會優先獲得食物并且還會負責尋找食物和引導這個麻雀種群的移動方向,此外捕食者也將影響麻雀種群的移動方向[21]。則每次迭代期間,發現者的位置更新方式為
(22)
其中,g=[1,Itermax] 表示當前迭代次數,Itermax表示最大迭代次數。α∈(0,1] 是一個隨機數,Alarm∈[0,1] 和Safe∈[0.5,1] 分別表示報警值和安全閾值。G是服從正態分布的隨機數,V為1×d的單位向量。
對于加入者,他們會時刻監視發現者。當他們觀察到發現者找到更好的食物,則加入者會立即朝著發現者的位置移動去獲得食物,即加入者的位置更新方式為
(23)
其中,sopt和sworst分別表示發現者的最佳和最差的位置,A為一個1×d矩陣,且A+=AT(AAT)-1,NP表示麻雀總的種群數量。
對于整個麻雀種群,種群邊緣的麻雀在意識到危險時迅速向安全區域移動以獲得更好的位置,而處于群體中間的麻雀為了縮小危險范圍而靠近其它麻雀進行隨機游走。因此,麻雀種群位置更新方式為
(24)
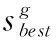
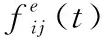
算法1:基于麻雀搜索算法的計算卸載算法(COSSA)
輸出:最優卸載決策X*(t), 適應度值fglobal
(1) 隨機初始化Np個卸載決策矩陣X(t);
(2) 把每個X (t)根據式(20)編碼為卸載決策向量X(t) 組成麻雀種群Sn;
(3) 用式(21)計算適應度值fn, 并找出最小的適應度值fmin;
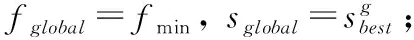
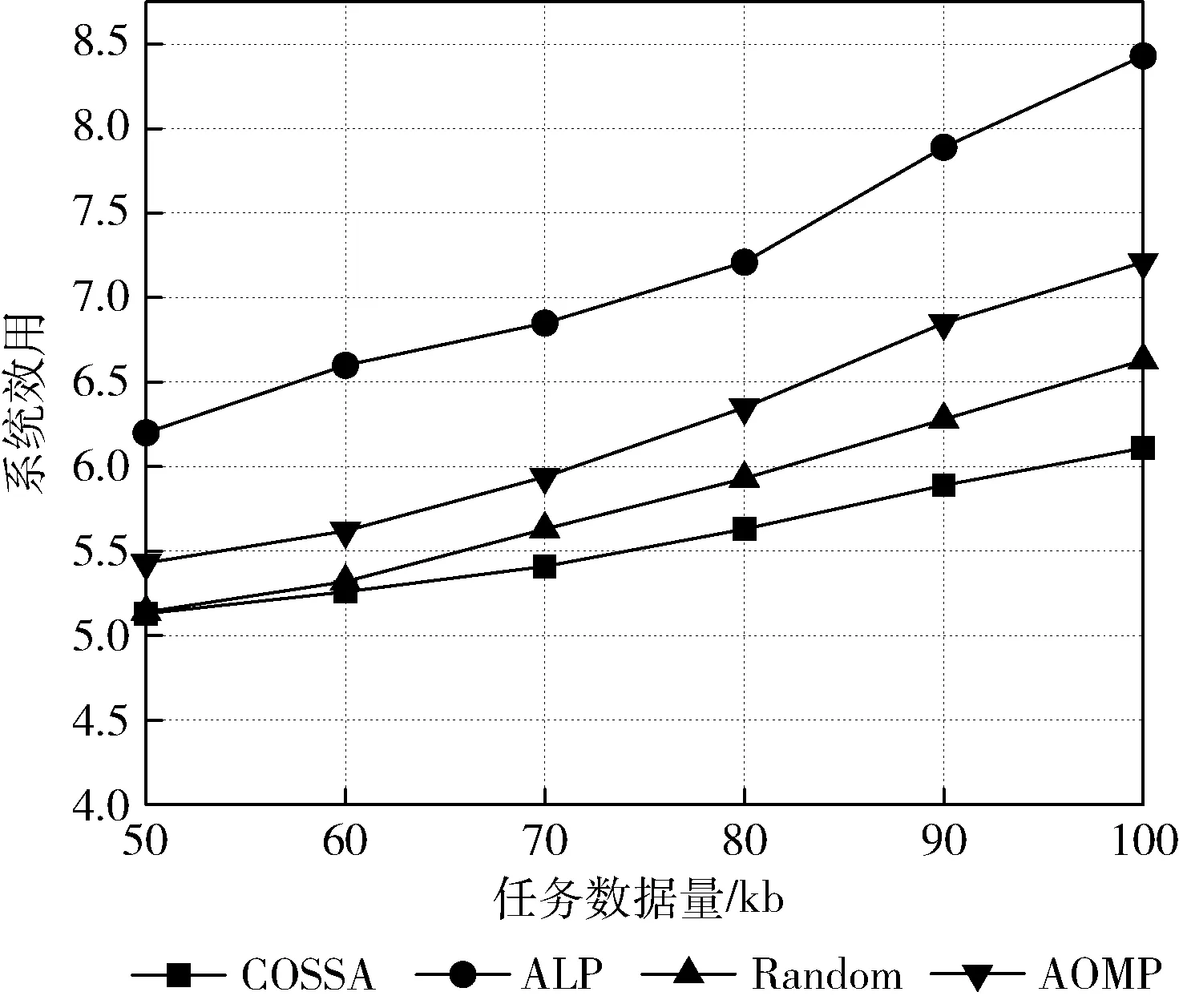
(5)whileg (7)Safe=1; (9) 用式(22)更新麻雀的位置; (10)endfor (12) 用式(23)更新麻雀的位置; (13)endfor (14)forn=1:Ns (15) 用式(24)更新麻雀的位置; (16)endfor (17)iffglobal>fmin (19)endif (20)g=g+1; (21)endwhile (22) 把sglobal解碼為最優卸載決策X*(t); 為驗證COSSA算法的優越性能,本文采用與文獻[13]和文獻[23]相同的方式做驗證。此外,為驗證COSSA算法良好的收斂性能,還將其與粒子群優化算法和灰狼優化算法進行對比。因此本文將COSSA算法與如下策略做比較: (1)ALP:所有計算任務在車輛本地處理; (2)AOMP:所有計算任務都卸載到同一個MEC服務器處理; (3)Random:所有車輛的計算任務隨機選擇卸載至MEC服務器或在本地處理; (4) COPSO:基于麻雀搜索算法的計算卸載策略,目標函數及編碼方式與COSSA相同; (5) COGWO:基于灰狼優化算法的計算卸載策略,目標函數及編碼方式與COSSA相同。 參數設置主要參考文獻[13]和文獻[23],見表2。 表2 仿真參數 圖2把COSSA與COPSO和COGWO算法相比較,3種算法均用相同的適應度函數和編碼方式,最大迭代次數Itermax=1000。 從圖2中可以看出,在有限的迭代次數內COSSA算法經過180次迭代后找出了全局最優值,而COGWO和COPSO算法要分別經過400和220次迭代才能收斂。此外,COPSO算法易陷入局部最優值,其相較于COSSA算法目標函數值較大,使得系統開銷也較大;COGWO的目標函數值與COSSA算法最為接近,但其收斂較慢。因此,COSSA算法的收斂性能優于COPSO和COGWO算法,在收斂速度方面分別提升了18%和45%。 圖2 算法收斂性分析 圖3為車輛數在[10,50]范圍內變化時,車輛數與系統效用值之間的關系。隨著車輛數的增加,系統效用值也在不斷增長,這是因為車輛數目的增加必然導致任務處理總時延和資源服務費增加,從而使得系統效用變大。從圖3中可以看出,當車輛數小于30時,4種卸載策略無明顯差別,當車輛數大于30時,ALP、AOMP和Random策略的效用值急劇增長,而COSSA策略在車輛數較多時仍能保持較低的系統效用,實現了最優的效果。 圖3 車輛數與系統效用的關系 圖4為車輛數與系統中車輛任務處理總時延之間的關系。隨著車輛數的增加,4種策略的任務處理總時延差距越來越大,這說明不同的策略將對VEC系統的任務執行時延產生影響。其中,Random策略是隨機選擇將計算任務卸載至MEC服務器或本地處理,因此其效果最差;而COSSA策略同時考慮了任務執行時延、MEC服務器負載均衡以及任務執行的連續性,因此COSSA策略始終保持最低的任務處理時延,有效地提升了用戶體驗,實現了最佳性能。 圖4 任務完成時延對比 圖5展示了車輛數為20,任務數據量在[50,100]kb范圍內變化時,任務數據量與系統效用值之間的關系。如圖5所示,隨著任務數據量的增加,系統效用也在不斷增加。這是因為車輛和MEC服務器的計算資源一定時,任務數據量增加直接導致任務處理、傳輸時延以及資源使用費的增加,從而使得系統效用變大。其中,由于車輛計算能力較弱,任務數據量增多導致處理時延較長,因此ALP策略效果較差,而COSSA策略始終保持較低的系統效用,實現了車載終端與MEC服務器的負載均衡。 圖5 任務數據量與系統效用的關系 針對車聯網場景下的邊緣計算系統中MEC服務器負載不均衡,緊急任務無法得到優先處理的問題,提出一種COSSA策略。首先利用層次分析法根據任務的屬性為每個需要卸載任務分配優先級,然后利用麻雀搜索算法根據目標函數找出最優的卸載決策,以最小化系統效用,實現服務器負載均衡。實驗結果表明,COSSA與COPSO和COGWO策略相比具有更好的收斂性能。與Random、ALP和OMP策略相比,COSSA策略可以有效地降低系統開銷、均衡MEC服務器負載。下一步將對VEC系統中車輛移動性管理以及車輛計算任務的部分卸載問題進行深入研究。
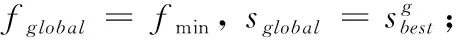
3 仿真分析

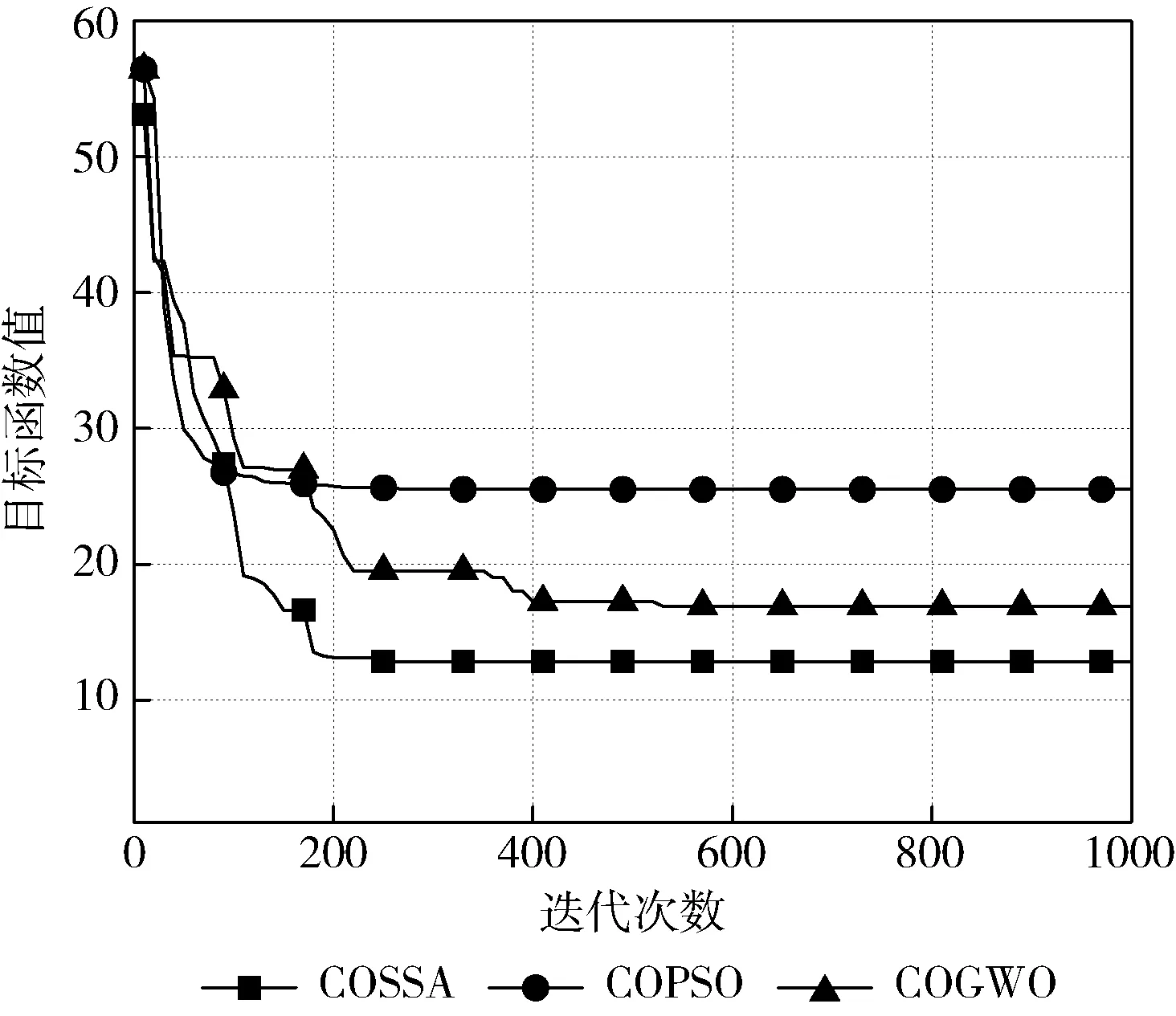
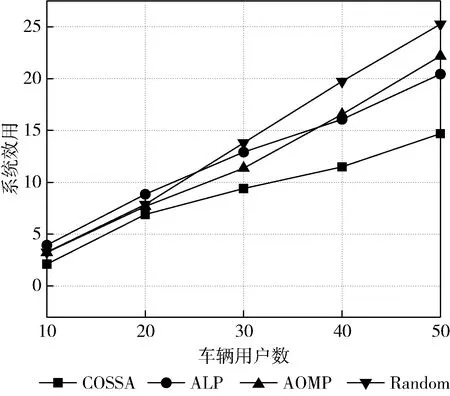
4 結束語
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
裝備制造技術(2019年12期)2019-12-25 03:06:46
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
數學大世界(2018年1期)2018-04-12 05:39:14
