基于兩點法的醫療化驗單傾斜校正算法*
2023-01-06 05:43:02賈智彬呂學強何健董志安
計算機與數字工程 2022年10期
關鍵詞:方法
賈智彬呂學強何 健董志安
(1.北京信息科技大學網絡文化與數字傳播重點實驗室 北京 100101)(2.北京洛奇智慧醫療科技有限公司 北京 100015)(3.清華大學互聯網產業研究院 北京 100084)
1 引言
隨著深度學習[1~2]的廣泛應用,醫療OCR[3~4](Optical Character Recognition,光學字符識別)已經成為醫療領域重要的研究話題。在醫療化驗單識別的過程中,由于拍照的角度不同往往會導致圖像內容產生一定的傾斜,而內容的傾斜對圖像的文字識別影響非常大,所以在一個化驗單識別系統的預處理階段,圖像內容的傾斜校正往往是非常重要的部分。
目前對于醫療化驗單圖像的校正并沒有專門提出或改進的算法,大多數還是使用一些通用的校正方法,例如基于Hough變換的方法[5~7],基于投影的方法[8],基于K-最近鄰簇方法[9~10]。基于Hough變換是一種快速的形狀匹配技術,經過Ballard D.H[11]的推廣,雖然其可以檢測任意形狀,很好地擴展了該算法的應用[12~13],但該方法的計算量還是比較大。基于投影的方法是通過投影圖像的某些統計特性來求得其傾斜角,但由于需要對整個圖像統計特征值,因此計算量和復雜度都比較高。而K-最近鄰簇方法是找出所有聯通中心的K個最鄰近點,計算每對近鄰的矢量方向并統計生成直方圖,其峰值對應著整幅圖像的傾角,但因整幅圖像中聯通成分較多,比較耗時。
由于醫療化驗單版面復雜,例如化驗單中文字的字體和字號多樣性且文字分布可能密集或零散,使得以上的方法對于醫療化驗單的傾斜校正效果不明顯。本文在曾凡鋒[14]等所提出的在文本子區域上進行檢測以及李慶峰[15]所使用的兩點法的基礎上,提出了一種快速的化驗單圖像傾斜校正算法,通過找到其圖像中的某一條直線的左右端點,然后計算其直線的傾斜角度,大大提高了校正的速度和準確性。
2 算法思想
提出的方法運用兩點法的基本思想,即已知直線上不同兩點的坐標,那么就可以求得這條直線的斜率,進而即可確定直線的傾斜角度。本文算法是基于兩個前提和一個假設下完成的。
前提1:化驗單中至少含有一條貫徹版面的線段,該線段可以是化驗單中表格的邊;
前提2:化驗單的整體形狀為矩形。
假設1:斜線被切分成無窮多份后,每一份可以看成是一條直線,即斜線是由局部的直線組成的。
以往的方法一般是通過在圖像的整體上進行傾斜角度的計算,例如計算整體邊框的傾斜度,但現實中往往會存在一些圖像邊框傾斜,但其內容并沒傾斜,由于化驗單傾斜校正的主要目的是校正內容,若要按照之前提出的算法來校正,肯定會出現錯誤校正的情況,而本文提出的方法將直接在化驗單內容部分中進行校正。
通過對大量傾斜圖像的研究分析發現,如果能夠確定斜線左側起點坐標L(x,y)以及斜線右側結束點坐標R(x,y),就可以求出兩點之間的位移差a=imgR.y-imgL.y,偏移量b=|imgRx-imgLx|,再利用勾股定理,a2+b2=c2,計算直角三角形斜邊長度,之后即可通過求角式(1)可計算出傾斜的角度。
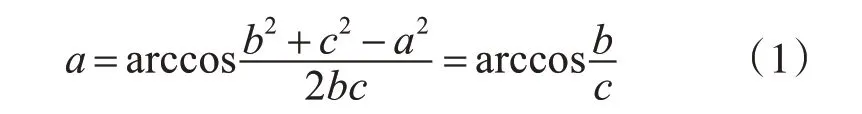
通過對大量的二值化后的化驗單圖片研究分析發現,可以利用像素最小求和的方法來確定圖片中的內容區域,從而檢測到圖片中斜線的位置信息及坐標,然后根據勾股定理及求角公式完成傾斜角度的求解。
3 算法實現
為了盡量使每份近似于直線,需要將二值化圖像按固定像素等份切分為img={img1,img2,…,imgn},而這個固定的像素將在很大的程度上決定該算法的好壞。切分之后,原圖中的“斜線”片段變成了子圖中的“直線”,然后利用選擇子圖的位置i(1≤i≤n)以及切分的寬度,找到子圖的直線橫坐標。可以利用行像素點最小求和方法,找到子圖中縱坐標。取img左側某個子圖imgL坐標為(x,y),取右側某個子圖imgR坐標為(x,y),根據imgL,imgR的坐標即可計算出傾斜的角度,再根據求出角度的正負值進行偏移校對,即可完成校驗,具體實現步驟如圖1所示。

圖1 圖像校正流程圖
1)在進行二值化之前需要將圖片中的背景去除,然后在去完背景的圖像上進行二值化處理,本文使用的是全局閾值法[16]。將圖像由3通道轉化為2通道,像素點的灰度值設置為0或255,其中0代表黑色像素點,255代表白色像素點。可以根據0和255提取圖像中的信息,二值圖像在進行圖像處理時增加提高處理的效率。
2)為了盡可能地將傾斜的橫線切分成多份直線,需要根據不同的化驗單種類,確定其合適的切割寬度,切分整個化驗單圖像的固定寬度在很大程度上決定了算法的優越性。從理論上講,其寬度越小,切分出的線段越接近直線,效果應該越好,但如果切割寬度和化驗單中的文字大小一樣,反而降低校正效果。在本類化驗單中,一個文字的像素為20像素,通過實驗得,寬度在22像素左右時分割效果最佳。在確定好切割寬度后,就可以將化驗單按照每小份22像素進行切割,共分為n份,然后根據img的寬度將圖片平均分成兩個集合,即imgL、imgR,其中mid=img.width/2;根據式(2)對imgn進行集合劃分。劃分之后,從imgL、imgR集合中分別取出子圖imgL(i),imgR(j),通過計算imgL(i),imgR(j)的偏移量以及位移差,由此即可計算出對應的img的傾斜角度。

3)通過使用最小求和公式計算imgL矩陣中每一行像素之和,之后通過位置信息進行排序,即根據式(3)可以找到第一條直線的位置,能夠找到imgL圖像中直線的y坐標信息。根據所選取imgL的位置信息計算imgL中的x坐標信息,即imgLx=i*22。利用上述方法同樣可以計算出imgR的(x,y)坐標。

4)通過步驟3可以計算出imgL、imgR的坐標,再通過計算偏移量、位移差即可計算img傾斜角度。如果img存在傾斜,則偏移量不等于0,即imgR.x-imgL.x≠0。已知imgL、imgR兩點坐標,即可求出偏移量和位移差,再利用三角形勾股定理可計算出斜邊c的長度,如圖2所示,再根據式(1),即可計算傾斜角度。之后根據a的取值判斷傾斜角度旋轉的方向,如果a大于0,則向圖片上旋轉;如果a小于0,則向下旋轉;如果a=0,則圖片不旋轉。
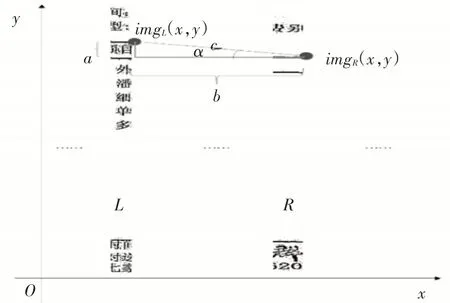
圖2 求角示例圖
5)為使img傾斜角度計算的更精確,從imgL集合中取一個子圖,imgR集合中取5個子圖合并組成五組數據,如圖3所示。利用式(1),計算每一組傾斜角度,再根據式(4)計算img的平均傾斜角度,其中n=5。
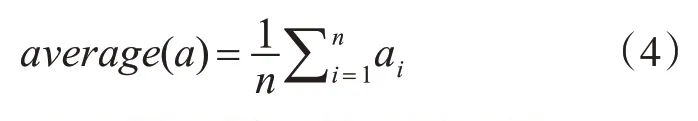

圖3 對子圖進行分組
經過以上五步校正之后,可以將化驗單內容傾斜的圖像校正成功,圖4為原始圖片,圖5為校正過的圖片。

圖4 未校正的圖像

圖5 校正后圖像
4 算法測試結果與分析
為驗證本文算法的效果,在此與傳統的Hough變換和投影法進行比較。實驗數據采用了50張類似于圖5的化驗單進行了實驗,將這些圖像以一定的角度為間隔進行旋轉。
每張圖像生成6種不同的傾斜樣本圖像,共生成300張測試圖像。將三個方法分別對這些化驗單進行傾斜校正,然后對這些結果進行比較,校正結果如圖6所示。
圖6(a)展示的是運用上述的一張化驗單的原圖,而這張原圖有個很大的特點就是化驗單里的內容是傾斜的,而圖片本身水平,而這樣的化驗單在實際中并不是少數。圖6(b)展示的是旋轉10°后得到的化驗單,圖6(c)、圖6(d)分別是通過Hough變換法、投影法得到的校正后的圖像。通過這三幅圖像可知,Hough變換法和投影法可以很好地將化驗單的邊框由傾斜校正水平,但這并沒有將內容校正水平,而圖6(e)展示的是通過本文算法得到的校正后圖像,可以看出其化驗單里的內容得到了明顯的校正,并不在是化驗單本身進行校正。

圖6 校正結果
表1對Hough變換法、投影法與本文方法進行了對比分析,從每張的處理時間上來看,本文的處理時間最短,與其他兩種方法的速度相比得到了提高。而從平均誤差來看,本文算法的平均誤差在這三類算法中是最大的,這是因為本文算法檢測是表單里的直線,而有的直線在原化驗單中是傾斜的,雖然旋轉一定角度得到測試圖像,但其實這些直線并沒有真正旋轉到該角度,這會導致本文算法的平均誤差較大。準確率是指經過算法傾斜校正后文字內容沒有傾斜的圖像與參與測試的所有樣本數之比,從表中可以看出,本文提出的方法的準確率最高,達到了94.6%。這是因為Hough變換和投影法對化驗單這種比較復雜圖像的適應度比較差,而本文算法直接針對化驗單的內容進行傾斜校正,從而排除了圖像中非內容部分的干擾,所以準確率較高。可見,本文所提出的算法與傳統的Hough變換法和投影法來說,在對化驗單進行傾斜校正的情況下,既提高了校正的精度,又減少了算法的執行時間。

表1 各方法對比分析
5 算法推廣
本文提出的算法可以進一步應用于其圖像中至少有一條易于檢測到的直線,首先需要確定合適的固定寬度,然后根據本文所提出的算法,得到直線的左右端點的坐標,再求出其傾斜度,即可通過旋轉得到其校正后的圖像。
如圖7所示,這是一張來自其他醫院去完背景的化驗單圖像,通過圖像可以看出其原圖存在一定程度的傾斜,通過觀察可以得出圖像滿足上述提到的前提條件1、2,根據上述算法思想,先求出其平均傾斜角度值,最后再對原圖進行旋轉即可得到校正后的圖像,結果如圖8所示。

圖7 未校正的圖像

圖8 校正后的圖像
6 結語
對于化驗單這種比較復雜的圖像來說,該類圖像通常由表頭,檢驗項內容和表尾三部分組成,所以對其文本行進行分析往往會受到表格或多或少的影響。本文結合化驗單的基本特征,利用兩點法的基本思想,從而計算出其圖像的傾斜角度,達到校正圖像的效果。實驗表明,本文提出的方法提高了校正的速度和對化驗單這種比較復雜圖像校正的正確率,達到項目使用要求。
但目前本文提出的算法還需要對不同種類的化驗單進行不同的特征分析,需要確定合適的分割寬度,這是本算法需要改進的地方。另外,對于傾斜角過大的圖像,其算法的正確率也會大大降低,仍然需要結合其他方法進行綜合處理。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
