基于CUDA 并行優化的矩陣相乘算法研究
2022-12-11 09:43:08趙志建
智能計算機與應用 2022年11期
關鍵詞:優化
趙志建
(江蘇聯合職業技術學院 南京工程分院,南京 211135)
0 引言
矩陣相乘作為數值分析統計學和機器學習中最為常見的數學運算,在FEA 平衡方程、線性回歸、決策樹、樸素貝葉斯等等的求解上都可以分解成系列矩陣相乘或者矩陣乘向量的運算。在深度學習領域,常用的卷積(Convolution)、全連接、批歸一化(Batch-Normalization)、下采樣(MaxPooling)等計算機視覺中常用算子操作也都離不開矩陣相乘運算。常用的編解碼器(Encoder -Decoder)、注意力機制(Multi-Head Attention)等自然語言處理中的基本算子依舊離不開矩陣相乘運算。
隨著矩陣維度的激增,傳統單CPU 矩陣相乘算法的高復雜度帶來了巨大的性能瓶頸,為了緩解單線程大矩陣相乘運算的耗時問題,一種基于共享內存的多線程并發機制應運而生。通過將大矩陣相乘任務劃分給多個子線程,提高計算性能;另一種是將大矩陣劃分成多個子模塊單獨相乘后再相加,以減少內存訪問次數,提高性能。但是就目前而言,深度學習的應用正日趨普及,大矩陣相乘的運算量突增,對于實時性要求很高的人臉識別、無人駕駛、醫療影像分割等應用來說,傳統CPU 平臺實現的矩陣運算已無法滿足需求,亟需一種更加高效的并行計算模式打破該性能瓶頸。
英偉達工智能計算公司首次定義了GPGPU 概念,并提出了CUDA(Compute Unified Device Architecture)并行計算架構,同時支持硬件和軟件。CUDA 可利用圖形處理器中的多顆計算核心進行通用計算處理,計算性能顯著提升,包含CUDA 指令集架構(ISA)以及GPGPU 內部的并行計算引擎,還方便開發人員直接使用C 語言來為CUDA 架構編寫程序,并在支持CUDA 的GPGPU 流處理器(Stream Multiprocessor,SM)上以超高性能實現運行。CUDA 并行計算架構的問世,使得矩陣運算性能得到質的飛躍。本文通過使用CUDA 來做矩陣相乘運算,并充分利用SM 資源對其性能進行優化,且在不同GPGPU 硬件平臺上針對不同優化算法做了充分的實驗對比及性能分析。
1 相關工作
1.1 矩陣乘積定義
矩陣相乘是一種將2 個矩陣乘積運算,得到第3 個矩陣的二元運算。設A為M×K的矩陣,B為K×N的矩陣,那么稱M×N的矩陣C為矩陣A與B的乘積,記作C=AB,其中矩陣C的第i行第j列如公式(1)所示:
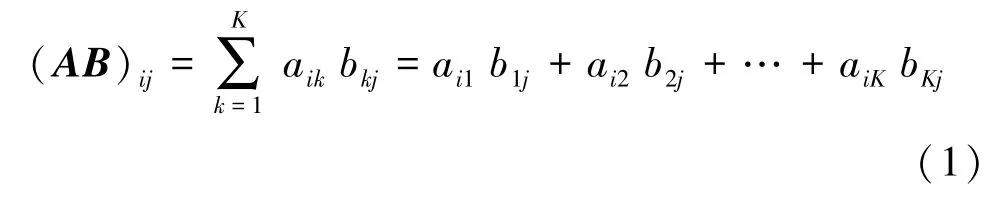
1.2 并行計算架構簡介
CPU 實現的并行計算大多依據多處理器共享內存機制進行多線程并行編程,典型的框架包括MPI(Message Passing Interface),OpenMP(Open Multi-Processing),TBB(Intel Threading Building Blocks),OpenCL(Open Computing Language)等。
目前,主流的GPGPU 實現的并行計算架構有CUDA 架構、ROCM、OpenCL 等。NVIDIA 提出的GPGPU 作為現如今最為流行的并行框架,其整體結構主要由大量的SM 和DRAM 存儲等構成,每個SM又由大量計算核(又稱CUDA 核)、LDU(Load-Store Units)、SFU(Special-Function Units)、寄存器、共享內存等構成。GPGPU 具有高并行度計算能力的基礎,每個SM 支持數百線程并發執行,每個GPGPU通常有多個SM,所以一個GPGPU 可以并發執行數千線程。CUDA 采用和CPU 編程中常見的單指令多數據(SIMD)架構類似的單指令多線程(SIMT)架構來管理和執行線程,每32 個線程為一組,被稱為線程束。一個線程塊只能在一個SM 上被調度,而且一旦線程塊在一個SM 上被調度,就會保存在該SM 上直到執行完成。需要注意的是,這2 種層級并不是完全一一對應的,比如在同一時間,一個SM 可以容納多個線程塊。
在SM中,共享內存和寄存器是非常重要的資源。共享內存被分配在SM 上的常駐線程塊中,寄存器在線程中被分配。線程塊中的線程通過這些資源可以進行相互的合作和通信。盡管線程塊里的所有線程都可以邏輯地并行運行,但并不是所有線程都可以同時在物理層面執行。因此線程塊中的不同線程可能會有不同的運行速度,且在需要時可以使用CUDA 語句進行線程的同步。
1.3 內存優化算法
在大多數GPGPU 應用程序中,性能優化的關鍵點在于如何高效訪問內存,尤其共享內存的合理分配使用。
典型的GPGPU 內存優化算法包括共享內存優化、內存合并優化、內存沖突優化等。共享內存相較于全局內存而言,延遲要低上大約20~30倍,而帶寬要高出約10倍,因此合理分配共享內存是性能優化的關鍵。矩陣分塊思想與CPU 矩陣分塊思想相同。對齊訪問含義就是如果“內存事務”(32 和128字節兩種)的訪問首地址是緩存粒度(L1 的128 字節或L2 緩存的32 字節)的偶數倍,即實現了對齊訪問。在L1 緩存的情況下,由“128 字節內存事務”進行訪問,如果一個線程束訪問的地址是連續的128 字節,且首地址又是128 的倍數,那么這種訪問就稱為合并訪問,內存合并對齊訪問對性能提升起著關鍵作用。往往為了獲得較高的內存帶寬,共享內存被劃分成了多個大小相等的存儲器模塊,稱為bank。內存bank 沖突表示當一個線程束中的不同線程訪問一個bank 中的不同的字地址時,就會發生bank 沖突。如若沒有bank 沖突,共享內存的訪存速度將會非常快,而如果在使用共享內存時發生了bank 沖突的話,性能將會降低很多,所以避免內存bank 沖突尤為重要。不同于內存優化,循環延展是一種以編程復雜為代價來提升并行代碼性能的高級的編程方式,是一種指令集優化,其性能較內存優化提升更為明顯。
2 CPU 并行優化算法
CPU 實現的矩陣相乘偽代碼,具體見算法1。通過3 個for 循環即可完成公式(1)中表達的矩陣相乘運算。
算法1 矩陣相乘串行實現

2.1 OpenMP 并行優化
OpenMP 是基于共享內存模型的多線程并行模式,適合于應用在單機多核心平臺上。程序開始時只有一個主線程,程序中的串行部分都由主線程執行,并行的部分是通過派生其他線程來執行。目前主流編譯器默認都已支持OpenMP,只需要在第一個for 循環之前加上“#pragma omp” 語句,表示動態分配線程數,且保證每個CPU 線程單獨并行地完成矩陣點乘任務。算法實現偽代碼具體見算法2。
算法2 矩陣相乘并行實現

2.2 訪存優化
無論對于串行、還是OpenMP 并行實現都未經過任何優化,訪存延遲和通信開銷會隨著維度M,N,K的增加而增大。例如:對于M=N=K的大型方陣,矩陣乘積運算次數為N3、即時間復雜度為O(N3),所需的數據量為O(N2),從而產生N階的計算強度。而該算法又依賴于訪存中保存的一個大工作集,這就使得隨著M、N和K增長時,CPU 需要來回傳送數據,顯然不符合減小訪存的思想。
C/C++中,默認會按行優先儲存數據(一維數組),ijk枚舉順序將會使得內層k循環中B[k,j]=B[k?K+j]在內存中的枚舉出現不連續、即按列讀取,顯然降低效率。若此時采用ikj的枚舉順序將提高訪存效率,偽代碼具體見算法3。
算法3 矩陣相乘訪存優化實現

算法3中,在k循環中先讀取A[i,k]保存到寄存器變量S中,在內層j循環計算時直接讀取S,而B[k,j]和C[i,j]在j循環中是連續訪問的。需要指出的是,在外層k循環中,omp并行后去掉了最外層i循環,A[i,k]也是連續讀取的,這樣就極大提高了訪存效率。
2.3 矩陣分塊優化
將矩陣乘法的計算轉化為其各自分塊矩陣相乘后相加,能夠有效減少乘數矩陣和被乘數矩陣調入內存的次數,可加快程序運行速度。矩陣分塊優化思想如圖1 所示,通過將原始矩陣進行分塊,并將每個分塊看作另一個矩陣的元素參與矩陣乘運算,接著將相乘結果進行累加,從而完成一個矩陣分塊的矩陣乘,其他塊的處理流程也和這個一樣。
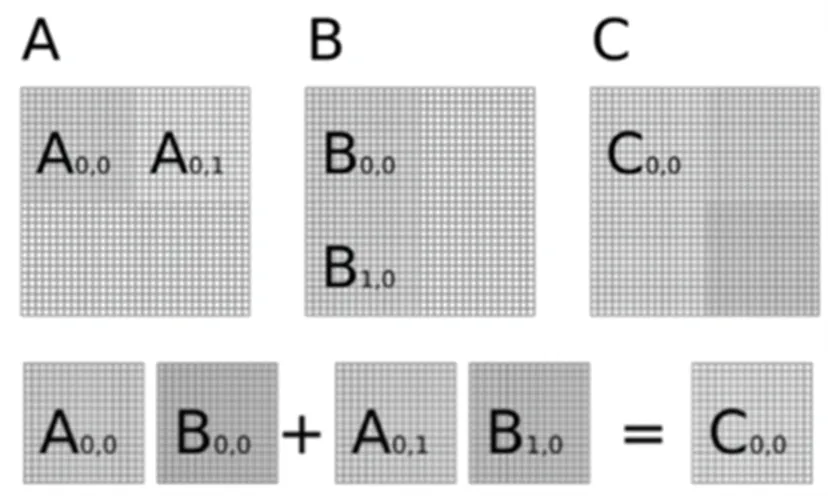
圖1 矩陣分塊優化思想Fig.1 Matrix block optimization
3 CUDA 并行優化算法
CUDA 允許用戶定義被稱為內核(kernel)的C語言函數,在調用此類函數時,將由N個不同的CUDA 線程并行執行N次,這與普通C 語言函數只執行一次的方式有所不同。在定義內核時,需要使用global 聲明限定符并使用一種全新的<<<…>>>語法啟動內核,同時還要指定每次調用的CUDA 線程數。通過讓每個線程對應矩陣C中一個元素來進行計算,每個線程從矩陣A中讀取一行向量,從矩陣B中讀取一列向量,對這2 個向量做相乘累加運算,再將結果寫回矩陣C。
A、B、C三個矩陣都保存在GPGPU 的全局內存中,每個線程都進行了大量重復的全局內存訪問操作,雖然線程束機制優化了全局內存的訪問效率,最大程度實現了合并訪問,但GPGPU 全局內存的讀取速度仍然不高、即帶寬有限。
3.1 共享內存優化
CUDA 中每個線程都有自己的私有的全局內存和寄存器,用來保存在核函數內不加修飾的聲明的局部變量;線程塊有自己的共享內存(Shared Memory),并對塊內所有的線程可見。相較于全局內存400~600 個時鐘周期的訪問延遲,共享內存只有20~30 時鐘周期訪問延遲,且帶寬也比全局內存高10倍,極大程度上提高了訪存效率。
共享內存優化算法的核心思想借鑒了矩陣分塊優化思想,通過充分利用數據的局部性,讓一個線程塊內的子線程先從全局內存中讀取分塊矩陣數據,并寫入到共享內存中,在計算時,直接從共享內存中讀取分塊數據進行矩陣乘和累加操作,從而大大降低了訪問延遲。接下來,讓子矩陣塊分別在矩陣A的行向以及矩陣B的列向上滑動,直到計算過所有N個元素的相乘累加為止。
3.2 合并內存優化
內存優化的目標在于通過更少的內存事務獲得更多的內存請求,因此需要盡量進行對齊合并訪問。內存合并訪問是指所有線程訪問連續且對齊的內存塊,內存塊大小支持32 字節、64 字節以及128 字節,分別表示線程束中每個線程以一個字節(1×32=32)、16 位(2×32=64)、32 位(4×32=128)為單位讀取數據。
以合并內存訪問128 字節為例,每個線程讀取一個浮點變量,那么一個線程束(32 個線程)將會執行32×4=128 字節的合并訪存指令,通過一次訪存操作完成所有線程的讀取請求,其緩存有效利用率達到128/128=100%,如圖2 所示。
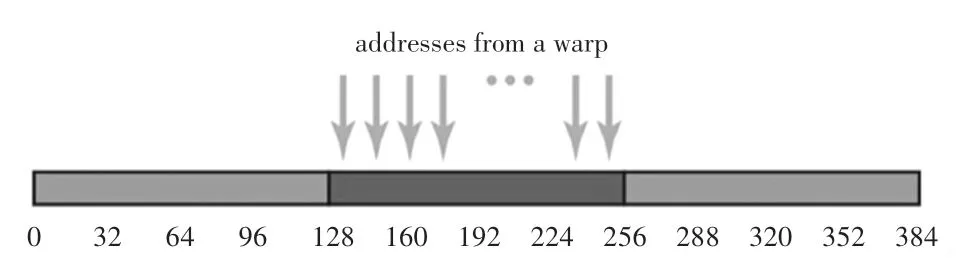
圖2 合并內存訪問Fig.2 Coalesced memory access
非合并內存訪問的對比如圖3 所示,128 字節的數據沒有進行內存對齊,首地址位于96~128 字節之間,為了訪問128 字節之前的數據,必須訪問從0~127 字節的整段內存,其緩存的有效利用率僅有一半,128/256=50%。
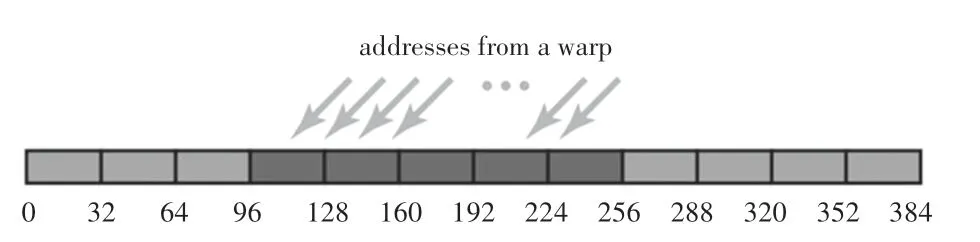
圖3 非合并內存訪問Fig.3 Non-coalesced memory access
3.3 內存沖突優化
往往為了獲得較高的內存帶寬,共享內存被劃分成了多個大小相等的存儲器模塊,稱為bank。一個bank 內對多個地址進行讀取和寫入的操作可以同時進行,大大提高了整體帶寬。當每個線程訪問一個32 位大小的數據類型的數據(如int,float)時,就不會發生bank 沖突,例如圖4 呈現了一種非內存bank 沖突的場景。
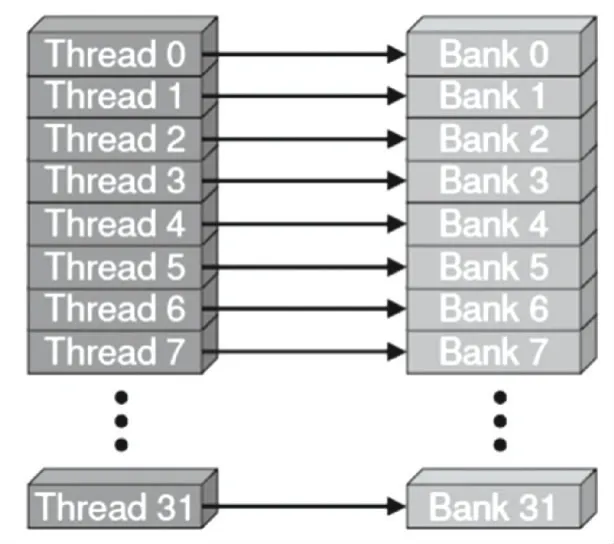
圖4 非內存bank 沖突Fig.4 Non-memory bank conflict
但是很多情況下,無法充分發揮bank 的作用,以致于共享內存的帶寬受阻,這可能是因為遇到了bank 沖突。例如,當同一個線程束中不同線程去訪問共享內存中同一個bank 的不同字地址時,就會發生bank 沖突,例如圖5 中同一個線程束中多個線程訪問了Bank 0 的數據。
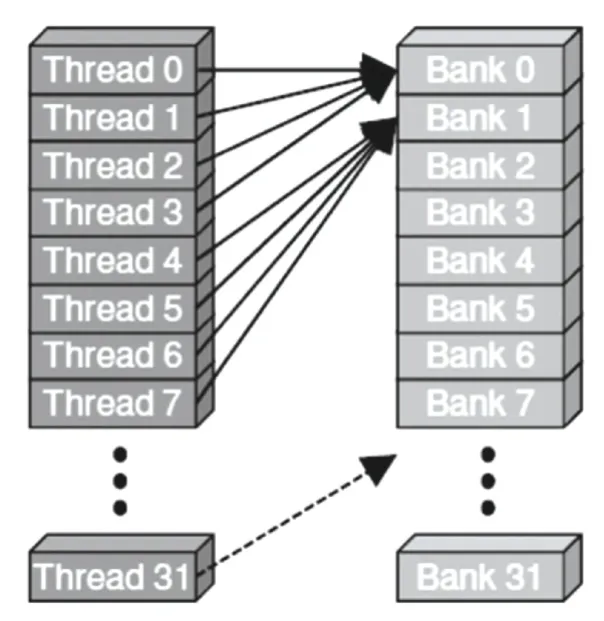
圖5 內存bank 沖突Fig.5 Memory bank conflict
避免內存bank 沖突常用的優化思路有2 個:
(1)典型的線程訪問方式:每個線程束的線程和每個bank 的ID 一一對應或者每個線程對應唯一的bank。
(2)多播機制:當一個線程束中的多個線程同時訪問一個bank 的相同字地址時,會將該字廣播給這些線程,從而也不會產生bank 沖突。
3.4 循環延展優化
循環延展(Loop Unrolling)不同于內存優化,是一種指令級優化。前面提到的所有優化算法實現都離不開for 循環的運用,而實際上for 循環是一種以犧牲計算性能為代價的編程思路。
循環延展優化思想的提出,主要是為了降低循環開銷,為具有多個功能單元的處理器提供指令集并行,同時也有利于指令流水線的調度。目前基于CUDA 編程的編譯器默認都已支持循環延展化,其實現方式和OpenMP 并行優化算法類似,只需在for循環前添加“#pragma unroll”語句,編譯器將會識別該語句,自動對其進行展開,而后并發去執行。具體偽代碼見算法4。
算法4 矩陣相乘循環延展優化

4 性能分析
在不同設備上進行M=N=K=2 048 階矩陣相乘及優化算法的性能對比,矩陣相乘CPU 并行算法的性能對比見表1。明顯看出基于OpenMP 并行優化實現算法稍優于串行算法;矩陣相乘分塊優化算法明顯優于未分塊算法;最優的仍是訪存優化算法帶來的性能提升。因此,內存優化一直是性能瓶頸的難點、也是挑戰。

表1 矩陣相乘CPU 并行優化算法性能對比Tab.1 Performance comparison of matrix multiplication CPU parallel optimization algorithm ms
從表1 明顯看出,雖然基于CPU 的并行優化算法較串行算法有了很大提升,但運行時間仍然較長,最優矩陣相乘訪存優化算法也需18.4 s,這個時間明顯無法滿足實時性應用需求。
基于CUDA 并行優化矩陣相乘算法的運行時間,見表2。
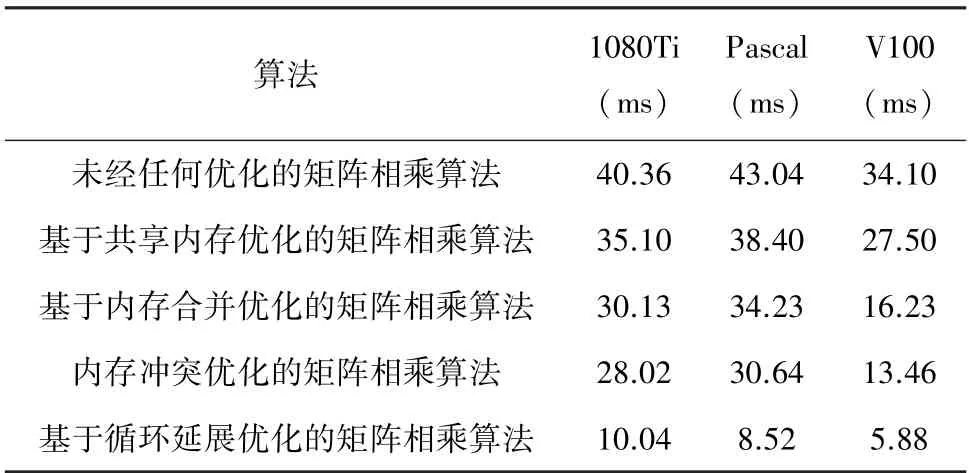
表2 矩陣相乘CUDA 并行優化算法性能對比Tab.2 Performance comparison of matrix multiplication CUDA parallel optimization algorithm
由表2 明顯看出,未經任何優化的CUDA 并行算法比CPU 實現的最快訪存優化算法提升了400倍之余。盡管原生CUDA 矩陣相乘實現算法得到了性能上的飛躍,但原生實現并沒有真正充分利用GPGPU 硬件資源,利用率往往達不到100%。通過使用共享內存優化的矩陣分塊優化算法,性能得到了明顯提高,這是因為共享內存訪問帶寬明顯高于全局內存。其次,在CUDA 內存使用中,經常會遇到內存并非對齊、內存bank 沖突等現象,通過使用NVIDIA 提供的nvprof 和nvvp 性能分析工具可以發現內存使用中存在的問題。通過內存合并對齊優化之后的性能較未優化實現有很大提升,解決了內存bank 沖突后也得到了部分性能提升。除此之外,還發現通過指令集優化的循環延展方法性能最為出色,這點得益于編譯器優化。
5 結束語
隨著GPGPU 的普及,陸續推出了CUDA、ROCM、OpenCL 等并行計算架構,不僅解決了CPU低算力帶來的高延時,同時還為高實時性要求的人工智能應用提供了強有力的支撐。本文借用CPU平臺和當今主流的CUDA 并行計算架構實現了數學領域常用的矩陣相乘并行計算,并對其進行了有效的性能優化,提高了利用率,從而能夠充分利用GPGPU 硬件資源。實驗結果表明,合理使用共享內存優化、指令集編譯器優化能帶來明顯的性能提升。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
