基于表情識別技術的電影效果反饋
2022-12-11 09:43:22于初允李闖
智能計算機與應用 2022年11期
于初允,李闖
(吉林師范大學 計算機學院,吉林 四平 136000)
0 引言
伴隨科學技術迅速發展,門禁、手機解鎖和快捷支付等人臉識別技術的應用,給人們生活帶來極大便利,人臉識別逐漸走進了日常生活中。而經濟發展也豐富了人們的精神文化生活,如看電影就已經成為了人們休閑娛樂的重要選擇之一。但互聯網上關于影評褒貶不一,都是憑借人的主觀意志對影片進行評價,人們獲取有效信息的效率降低,挑選合適電影付出的時間代價大。表情識別是人臉識別的重要組成部分,技術日趨成熟且效率較高、跨平臺性能優異。通過對觀影者在觀看電影過程中的表情識別,與預期效果做出對比,達到對電影效果進行客觀反饋的目的。通過多種實驗驗證,基于Dlib 的表情識別技術可以對電影進行有效反饋。
1 Dlib 技術介紹
1.1 ResNet
ResNet(Residual Neural Network),即基于殘差學習思想的深度神經網絡,將人臉數據的訓練集與面部特征數據進行對比,是Dlib 在人臉識別部分的核心[2]。
殘差學習結構如圖1 所示。將學習到的特征記為H(x),由于殘差學習相較于原始特征的學習更加容易,由其學習到的殘差為F(x)= H(x)-x,通過不斷地進行F(x)+x的學習,使系統具有更佳性能[3]。
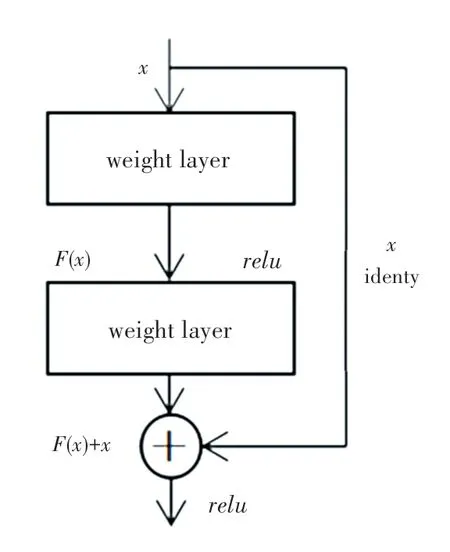
圖1 ResNet 的殘差學習結構[3]Fig.1 Residual learning structure of ResNet[3]
ResNet 有2 種結構:2 層殘差學習單元和3 層殘差學習單元,如圖2 所示。2 種結構分別對應ResNet34 和ResNet50/101/152,后者相較于前者顯著的優點是減少了參數量。所以前者常用于層數更少的網絡,后者常用于更深的網絡[3]。
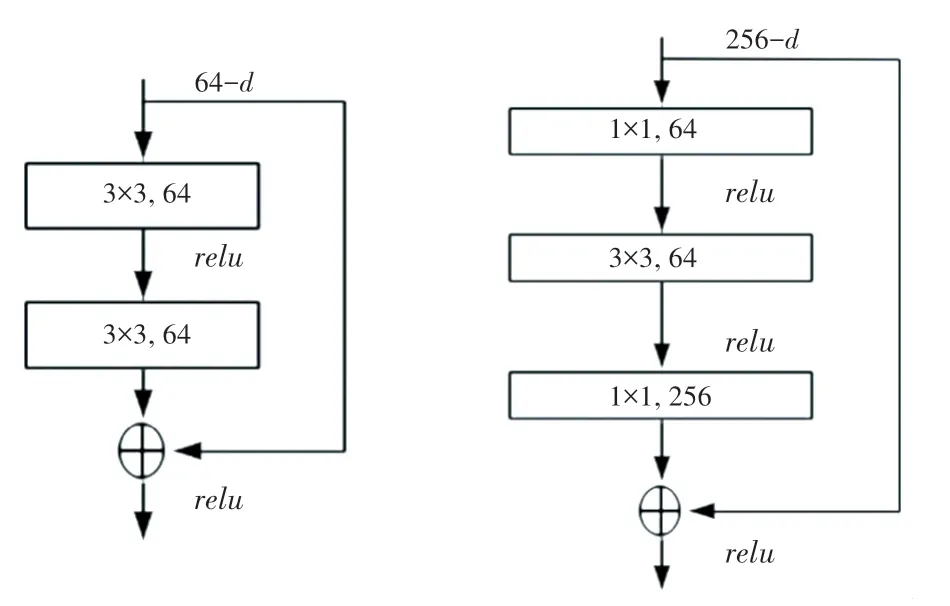
圖2 ResNet 的2 種結構[3]Fig.2 Two structures of ResNet[3]
Dlib 使用的是34 層的網絡,ResNet34 的最后一層是fc 1000,為得到128 維向量,在fc 1000 后面加Dense(128)。通過獲取人臉的Dense(128)與原Dense(128)的歐式距離,與閾值和相似程度的百分比做比較,即可判斷獲得到的人臉圖像信息。
1.2 Dlib68 特征點
本文采用Dlib 的68 特征點檢測模型對人臉進行檢測,特征點位置如圖3 所示。

圖3 Dlib 的68 特征點Fig.3 68 feature points of Dlib
此模型的訓練流程為:首先,將訓練圖片和測試圖片放于同一文件目錄下,為保證此模型識別準確率的提升,應使訓練集和測試集圖片包含多種可能,如不同光照、距離的圖片,為擴大兩集合,做鏡像處理。其次,圖像中的人臉尺寸可能存在過大差異,影響結果輸出,所以應設置適當掃描窗口。使用SVM訓練器訓練所提取特征[4],可得到人臉檢測模型。最后,測試人臉檢測模型,若達到預期標準,即可應用。訓練過程如圖4 所示。
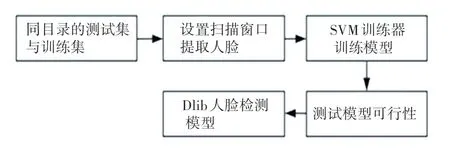
圖4 Dlib68 特征點的訓練過程Fig.4 Training process for Dlib68 feature points
2 具體實現
2.1 系統框架
本文應用的表情識別框架如圖5 所示,模塊應用了人臉圖像的特征點檢測和簡單的表情計算算法,簡單概括為:首先,為獲取人臉圖像使用人臉檢測技術,判斷是否為人類面部;其次,為減少環境帶來的影響,對檢測到的人臉圖像進行預處理;再次,對于面部的特征檢測,需要用到人臉圖像的特征點檢測技術;最后,通過特征點計算進行簡單的表情識別。將表情識別的結果與目標電影片段的預期效果進行對比,實現電影效果反饋。
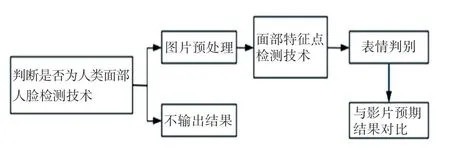
圖5 系統識別框架Fig.5 System identification framework
2.2 實現步驟
論文中重點研究了通過利用Dlib 特征提取器和特征預測器對人臉進行捕獲和特征提取,以達到簡單的表情識別。設計實現步驟具體如下:
(1)利用OpenCv 捕獲圖像[5],并對每幀圖像進行灰度處理。
(2)利用Dlib 的特征提取器檢測人臉,并計算數量。
(3)若存在檢測到的人臉數不為空,顯示每個人臉的68 特征點,并計算人臉識別框的長度。使用特征預測器獲得68 點數據的坐標。
(4)通過步驟(3)獲得有關嘴、眉毛和眼睛的坐標數據,進行簡單的表情計算。需要獲得的坐標有:嘴中心、嘴左角和嘴右角;眉毛的10 個特征點;2 只眼睛的眼角、眼尾、上眼瞼中點及下眼瞼中點。
(5)通過步驟(4)獲得的坐標進行計算,判斷表情。表情判別流程如圖6 所示。
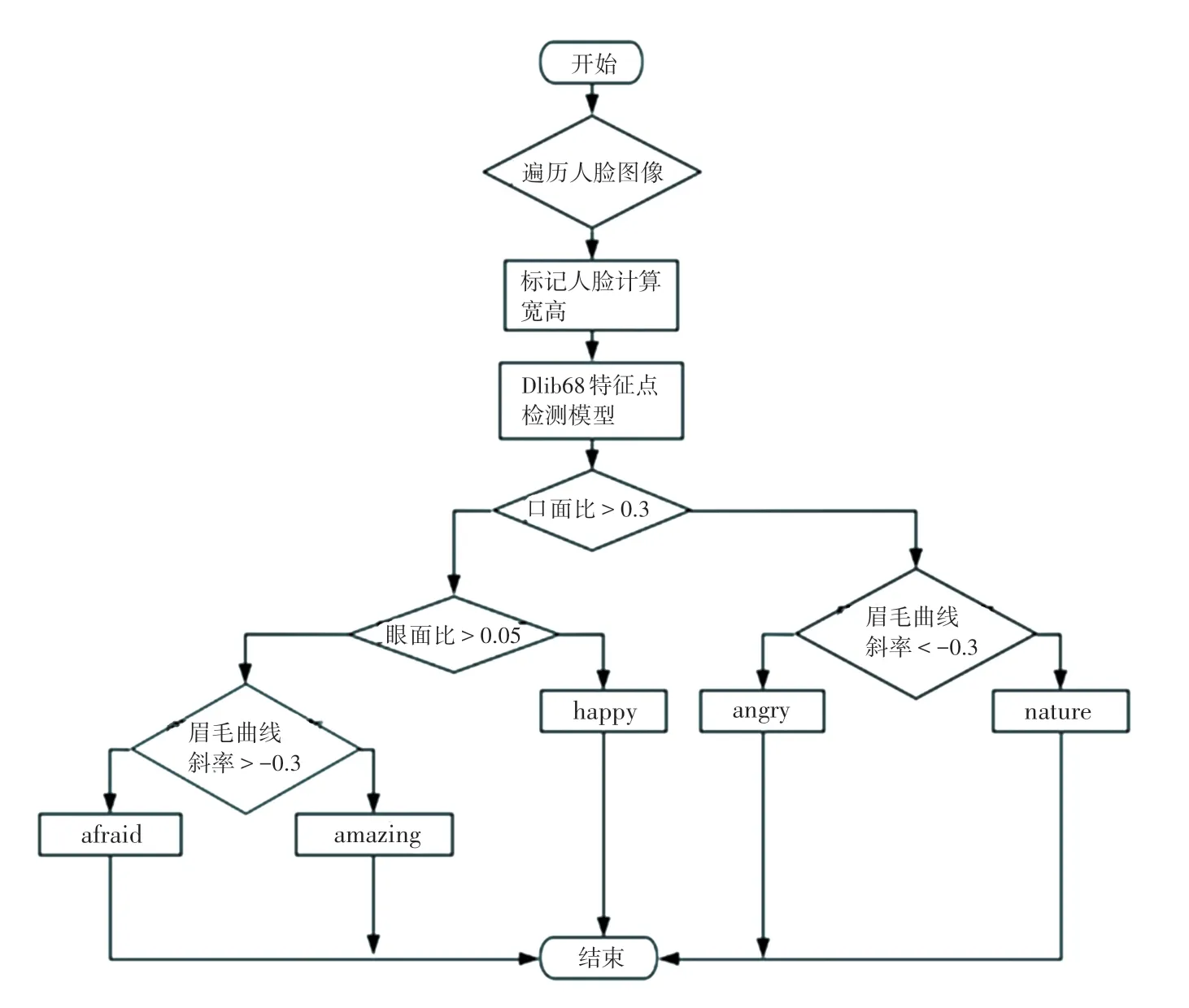
圖6 表情判別流程圖Fig.6 Expression discrimination flowchart
2.3 存在問題
綜合前文提及的表情識別中基于面部幾何的識別方法[7]可知,利用檢測獲得的68 特征點,通過數學計算,對人在恐懼、驚訝、高興、憤怒和自然狀態下進行表情的識別。進而可以通過獲得的表情數據,與預期觀眾的觀影效果進行對比,達到電影效果反饋的目的。研究發現在此過程中存在的主要問題有:
(1)電影中呈現的內容復雜繁多,不同的人所感受到的情緒不同,所展現的表情各異。期望情緒集的數量偏大,會導致不符合預期的表情也被計入預期結果中,導致反饋不準確;數量偏小,則符合預期的表情會有大部分不計入預期結果中,導致反饋不準確。所以期望情緒集的創建不具備便捷、準確的優點。
(2)由于人的個體個性、身體發育等方面存在差異,對于同種情緒的表現也有所不同,表現程度也并不一樣。且存在調動的肌肉、組織變化細微,多數呈現復合表情,約超過21 種。本文探討的表情識別,需要在表情變化幅度較大時才能準確識別,缺少微表情的識別。且僅對嘴、眼睛和眉毛的部分變化作為表情識別的依據,缺少準確性且識別模式單一,并且僅能識別5 種普通表情。
2.4 實驗步驟及結果分析
為驗證上述系統是否能對觀影人的表情及時、準確地進行識別,對正在觀影的人的表情進行簡單識別。測試此系統的可行性,并將結果輸出在屏幕中。對該過程可做闡釋分述如下。
(1)選擇3 類短片:喜劇、恐怖和懸疑。
(2)開啟系統,調用pc 攝像頭捕獲測試者面部。
(3)記錄輸出在屏幕上的檢測結果。
(4)測試非人類的面部。
(5)記錄結果。實驗結果如圖7 所示。

圖7 表情識別結果圖Fig.7 Expression recognition results graph
研究可知,在喜劇時可以檢測到實驗者有較頻繁的“happy” 表情,懸疑時有“amazing” 表情和“angry”表情,恐怖時可以檢測到實驗者的“afraid”表情和部分“angry” 表情,大多時候人們都是“nature”表情。基于Dlib 的表情識別技術可以較為準確和迅速地識別觀影者的表情變化,令數據更加客觀,說明將其應用于電影效果反饋上是可行的。
3 結束語
將表情識別應用于電影反饋中,是一項具有良好發展前景的研究課題。本文實現了基于Dlib表情識別技術在電影效果反饋中的應用,該應用具有跨平臺性優異、響應速度快和結果準確等優點,達到了對電影效果反饋的客觀性和準確性。
猜你喜歡
作文中學版(2022年1期)2022-04-14 08:00:34
中老年保健(2021年12期)2021-11-30 02:58:01
學生天地(2020年31期)2020-06-01 02:32:06
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年8期)2016-10-09 02:11:50
計算機工程(2015年8期)2015-07-03 12:19:07
