基于稀疏化訓練和聚類降低IR-Drop 影響的方法
2022-12-11 09:42:54王子杰
智能計算機與應用 2022年11期
關鍵詞:影響
王子杰
(合肥工業大學 計算機與信息學院,合肥 230601)
0 引言
目前,卷積神經網絡已經廣泛應用于深度學習中。研究表明,在卷積神經網絡中乘法和累加運算占整個操作的90%以上[1]。但隨著神經網絡不斷加深,利用傳統CMOS 器件組成的神經網絡由于存在著計算時間過長和能耗過大的問題[2],規模已經很難增大。新型器件憶阻器為實現矩陣乘法提供了一種更高效的方式[3],能夠以O(1)的時間復雜度實現矩陣乘法,且具有極低的能耗[4]。基于憶阻器[5-7]構建的神經網絡[8]可以加速神經網絡的計算,加快神經網絡對于大規模數據的處理速度。
通過憶阻器陣列[9]加速神經網絡計算,首先需要在軟件上訓練神經網絡得到權值矩陣,然后通過施加電壓改變憶阻器的阻值將權值矩陣映射為憶阻器電導矩陣。但由于IR-Drop 的存在,在運算的過程中,實際施加在憶阻器上的電壓和預期的電壓不同,計算結果和理想中預期的結果存在偏差,造成計算精度低的情況出現。
在憶阻器陣列中距輸入端越遠的憶阻器受到IR-Drop 的影響越大,因為隨著導線長度增加、導線電阻也會變大,而距施加電壓的輸入端越近的憶阻器受到的影響越小,所以憶阻器陣列規模越大,受到的IR-Drop 影響就越大。隨著神經網絡的規模增加,相應的憶阻器陣列規模增大,計算精度也會下降。例如當憶阻器陣列規模從16×16 增大到128×128時,在IR-Drop 的影響下,憶阻器陣列的計算精度降低了35%[10]。為了解決這一問題,在硬件和軟件方面上,研究人員都提出了一些有效的解決方案。
硬件方面,Huang 等人[11]提出補償輸出電流的方法來提高計算精度。該方法首先求出在理想情況下憶阻器陣列中每一列輸出的電流大小,然后在憶阻器陣列中新增行,對新增行施加電壓來補償電流輸出,使得每一列的輸出電流達到理想的電流大小。但是這種方式會增加過多的硬件開銷。為了減少硬件開銷,Zhu 等人[12]提出了一種新的補償電流的方法來提高計算精度。該方法在憶阻器陣列每一列的輸出端新增讀出放大器(sense amplififier),并對每一列的輸出電流調整放大的倍數使得電流輸出達到理想的電流大小。文獻[11-12]中的方法都會額外增加硬件的開銷,而軟件的解決方式則不會額外增加硬件開銷。
在軟件方面,主要是采取縮減憶阻器陣列規模來降低IR-Drop 的影響,憶阻器陣列規模越小,受到的IR-Drop 影響就越小,計算精度就越高。Wang 等人[13]提出通過PCA 分解矩陣的方式來提高計算精度。通過將一個大的憶阻器陣列分解成若干個小的憶阻器陣列的方式來減少憶阻器陣列規模[14]。但分解過后的憶阻器陣列計算精度較低,所以需要對神經網絡進行重新訓練來提高計算精度。而Liu 等人[10]提出通過SVD 分解矩陣的方式[15]來提高計算精度,這種方式不需要對神經網絡進行重新訓練,相對于PCA 分解矩陣的方式計算精度較高。文獻[10,14]中采用分解矩陣的方法得到的憶阻器陣列規模較大,仍然會受到較大的IR-Drop 影響,憶阻器陣列的計算精度較低。
為了解決IR-Drop 對計算精度的影響,本文提出基于對權值矩陣稀疏化以及對權值矩陣的行向量進行聚類的方案(Sparse Training Clustering,STC)來提高計算精度,為了描述方便,本文余下部分對所提方案簡稱STC 方案。首先,對神經網絡進行稀疏化訓練,將神經網絡的權值矩陣上行號、列號之和較大的權值置零且保證計算精度大于閾值p。然后對矩陣的行向量進行聚類,將全零行向量和近似全零行向量聚集在一起,將其權值置零并且在保證零權值不變和神經網絡的計算精度大于閾值γ 的前提下重新訓練神經網絡得到新的權值矩陣,接著刪除權值矩陣的全零行向量和全零列向量減少矩陣規模。最后在IR-Drop 下計算行向量的權值損失,將行向量按照損失大小降序排列得到新的權值矩陣并且映射到憶阻器陣列上。STC 方案可以有效地降低憶阻器陣列的規模,同時仍然保持較高的計算精度。
1 憶阻器陣列
利用憶阻器陣列實現矩陣乘法,首先需要將訓練好的神經網絡的權值矩陣Wn×m映射到憶阻器陣列上,憶阻器陣列如圖1 所示。用憶阻器陣列上的憶阻器電導值gij來代表權值矩陣上的權值wij,對每一行施加電壓V={V1,V2,…,Vn},第j列的輸出電流的計算公式可表示為:
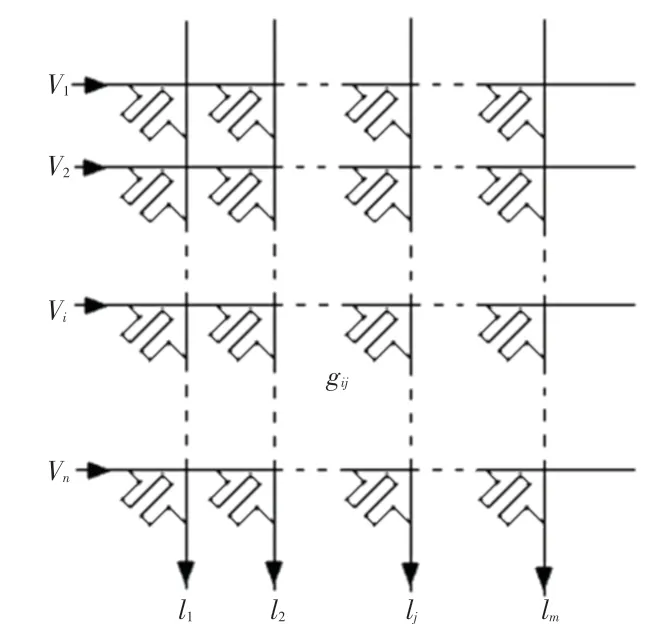
圖1 憶阻器陣列Fig.1 Memristor based Crossbar
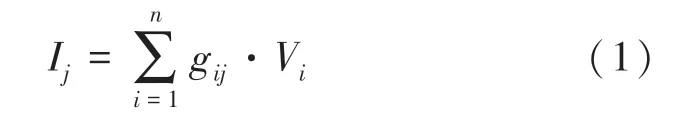
其中,Vi為第i行的輸入,Ij為第j列輸出。因為施加電壓在電阻上可以得到一個電流,并且在導線上輸出端會輸出電流之和,這個速度比起傳統的計算要快,所以憶阻器陣列可以加速神經網絡的計算速度。為了描述方便,本文余下部分對于憶阻器陣列上的電導值統稱為憶阻器陣列的權值。
2 STC 方案流程
STC 方案的流程圖如圖2 所示。STC 方案首先需要輸入模擬憶阻器陣列上IR-Drop 影響的矩陣In×m和神經網絡的權值矩陣Sn×m,In×m·Sn×m代表In×m和Sn×m對應位置相乘得到的矩陣。用神經網絡的權值矩陣In×m·Sn×m的計算精度來代表在IRDrop 下矩陣Sn×m映射到憶阻器陣列上的計算精度。然后稀疏化訓練將Sn×m上行號、列號之和較大的權值置零,因為行號、列號之和較大的權值在憶阻器陣列上距離輸入端較遠,受到的IR-Drop 影響較大。緊接著得到在IR-Drop 影響下計算精度高于閾值p的神經網絡權值矩陣Cn×m。接下來,對Cn×m的行向量進行聚類,將全零行向量和近似全零行向量聚集在一組,將近似全零行向量的權值置零、并且在保證零權值不變的前提下重新訓練神經網絡得到計算精度高于閾值γ的神經網絡權值矩陣Dn×m。同時,刪除矩陣Dn×m的全零行向量和全零列向量得到矩陣Kl×h。最后,在IR-Drop 影響下計算矩陣Kl×h行向量的權值損失,將行向量按照損失大小降序排列得到新的權值矩陣Fl×h,并將權值矩陣Fl×h映射到憶阻器陣列上。對STC 方案流程,本文擬展開研究分述如下。
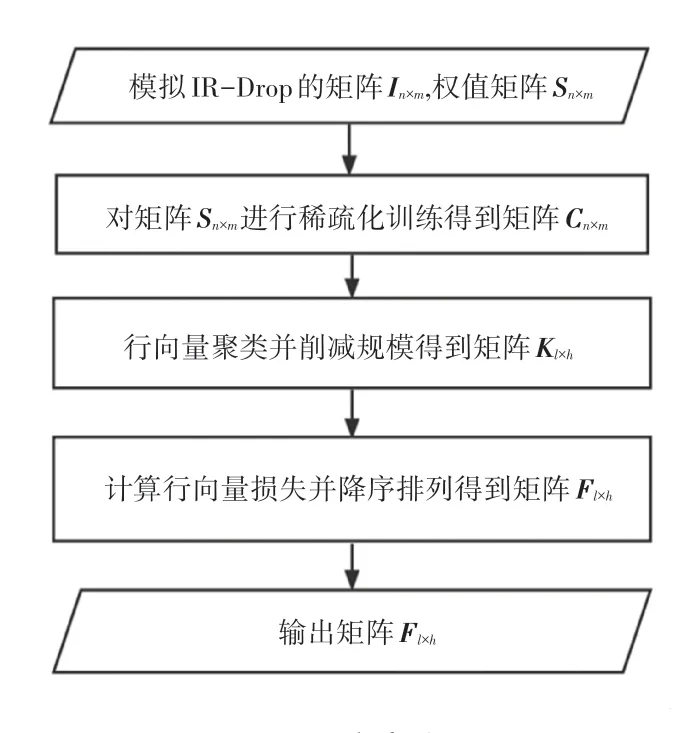
圖2 STC 方案流程圖Fig.2 Flow chart of STC scheme
2.1 稀疏化訓練
IR-Drop 影響大小是由憶阻器阻值以及導線電阻決定的[10],隨著憶阻器規模的增大,導線電阻增加,IR-Drop 影響也會增加。如果憶阻器的電阻設置為最大、即權值為零,此時導線電阻分壓的影響就會降低,IR-Drop 影響就會降低,計算精度也隨之提高。在STC 方案中,經過稀疏化訓練的權值矩陣有大量的零權值,映射在憶阻器陣列上受到的IRDrop 影響較小,計算精度顯著提升。關于稀疏化的訓練過程,其代碼表述具體如下。
輸入權值矩陣Sn×m,模擬憶阻器陣列上IR -Drop 影響的矩陣In×m,閾值q,閾值p
輸出稀疏化后的矩陣Cn×m


綜上可知,輸入為神經網絡的權值矩陣Sn×m,模擬憶阻器陣列上IR-Drop 影響的矩陣In×m,閾值q和p。第1 行給閾值q和p賦值,權值的行號、列號之和超過q代表在憶阻器陣列上此權值與輸入端相距較遠,受到的IR-Drop 影響較大,p為神經網絡計算精度閾值。第2行將Sn×m賦值給Cn×m,第3行In×m·Cn×m代表In×m和Cn×m對應位置相乘得到的矩陣,神經網絡的權值矩陣In×m·Cn×m的計算精度代表在IR-Drop 下矩陣Sn×m映射到憶阻器陣列上的計算精度,計算精度超過p則停止訓練。第4 行重新將Sn×m賦值給Cn×m用于稀疏化訓練。第5~10 行當矩陣Cn× m上的權值行號、列號之和大于q時置零,第11 行在保證零權值不變的情況下重新訓練神經網絡。第12 行縮小稀疏化范圍,因為神經網絡的計算精度還未超過p,通過改變稀疏化范圍使得神經網絡計算精度超過p。第14行輸出計算精度高于p的神經網絡權值矩陣Cn×m。
2.2 聚類并削減矩陣規模
經過了神經網絡的稀疏化訓練后,STC 方案對矩陣Cn×m上的行向量進行聚類,找到全零行向量和近似全零行向量的集合。首先定義一個閾值γ,在神經網絡的計算精度高于γ 的前提下,將權值矩陣的近似全零行向量的權值置零,然后保證零權值不變并重新訓練神經網絡,使得權值矩陣有更多的全零行向量,最后刪除矩陣的全零行向量和全零列向量,降低權值矩陣的規模。對聚類并削減矩陣規模過程,可給出設計描述如下。
輸入稀疏化后的矩陣Cn×m,憶阻器陣列IRDrop 分布信息矩陣In×m,半徑h,閾值γ
輸出經過刪減的新矩陣Kl×h


綜上可知,輸入為經過稀疏化的矩陣Cn×m,模擬憶阻器陣列上IR-Drop 影響的矩陣In×m,半徑h,閾值γ。第1 行給h和γ賦值,若行向量與全零行向量距離h以內的則為近似全零行向量,γ為神經網絡計算精度閾值。例如:

第2 行是將矩陣Cn×m賦值給Rown×m。第3 行的In×m·Rown×m為In×m和Rown×m對應位置相乘得到的矩陣,神經網絡的權值矩陣In×m·Rown×m的計算精度代表在IR -Drop 下矩陣Rown×m映射到憶阻器陣列上的計算精度,當計算精度超過γ時停止訓練。第4 行重新將Cn×m賦值給Rown×m,第5 行對Row采用mean-shift 算法聚類并得到result分類集合。mean -shift 算法的聚類中心處于最高密度處,由于矩陣Cn×m經過稀疏化訓練,所以全零行向量這一類型必定最多,所以得到的聚類中心相對來說比較準確。mean -shift 算法中的h表示如果2 個向量距離h以內則為同一類,將h設為0.1 可得:
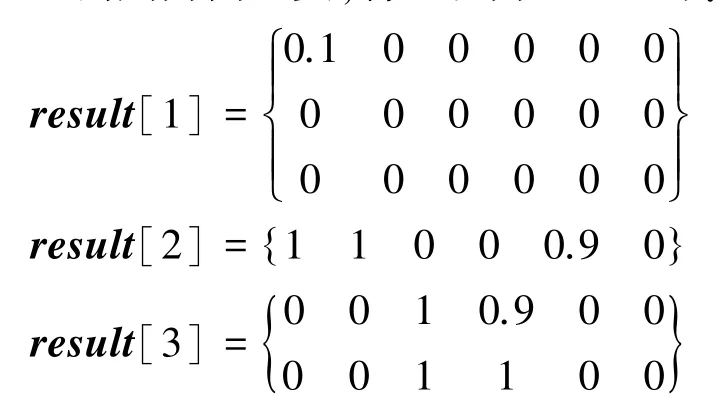
第6~16 行尋找result內擁有全零行向量和近似全零行向量的集合,并將集合編號賦值給flag,再將result編號為flag的集合內所有行向量權值置零,result[i]代表第i個集合,result[i][j]代表第i個集合的第j個行向量。第17~18 行將result賦值給Rown×m,同時保證零權值不變的前提下重新訓練神經網絡。第19 行減少h,因為神經網絡計算精度還沒超過γ,h越小、近似全零行向量越少,則進行重訓練后的神經網絡計算精度越高,不斷改變h的大小,直到神經網絡的計算精度超過γ。第21 行得到計算精度高于γ的神經網絡權值矩陣Rown×m,并將其賦值給矩陣Dn×m,推導后得到的運算結果如下:
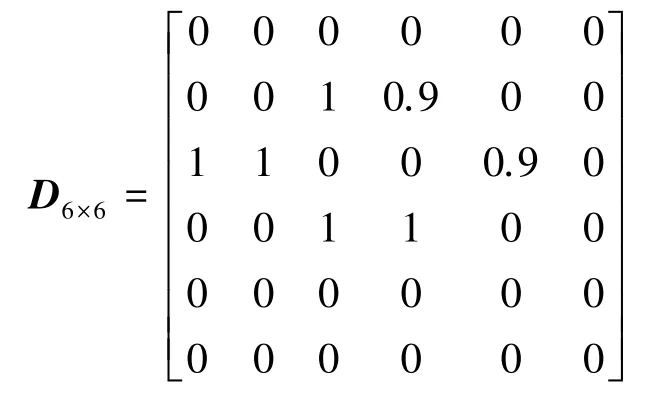
在22~29 行刪除矩陣Dn×m的全零行向量和全零列向量得到新矩陣Kl×h并輸出,并可表示為:
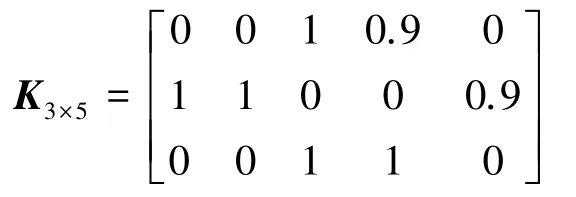
2.3 行向量排序
對于刪減后的權值矩陣Kl×h,STC 方案通過對其行向量采用排序的方式來提高計算精度。采用如下步驟:
(1)設定一個向量b,利用b來代表IR-Drop 的影響下權值矩陣上行向量的每個權值損失比例。
(2)利用b計算權值矩陣行向量的權值損失大小,將行向量按照損失大小降序排列得到新的矩陣。
這樣將容易受到IR-Drop 影響的行向量放到在憶阻器陣列上受IR-Drop 影響小的位置,而將不易受到IR-Drop 影響的行向量放到在憶阻器陣列上受IR-Drop 影響大的位置上,使得整體受到的IR-Drop影響降低。行向量排序過程可做完整描述如下。
輸入經過刪減的矩陣Kl×h,向量b
輸出經過排序的新矩陣Fl×h

分析可知,輸入為經過刪減的矩陣Kl×h和向量b。例如:

第1~3行,用b計算矩陣Kl×h的行向量的權值損失,并且和行向量建立匹配關系map,對map的行向量的權值損失進行降序排序。K[i]為矩陣Kl×h的第i個行向量,K[i]·b為第i個行向量和向量b的內積結果,map.first存放行向量的權值損失,map.second存放對應的行向量。為此,可以得到:

第4~5行,將map上的行向量賦值給矩陣Fl×h并輸出,求得的結果可寫為:

3 實驗結果以及分析
3.1 實驗參數設置
本實驗在Pytorch 上構建了一個3 層卷積神經網絡,采用MINST 數據集對其進行仿真測試。卷積神經網絡主要包括2 個卷積層、2 個池化層和1 個全連接層。輸入圖像的大小為28×28。憶阻器的電阻范圍為10 kΩ~1 MΩ,憶阻器陣列中憶阻單元之間的導線電阻為2.5 Ω,憶阻器陣列規模分別為64×64、96×96 和128×128,參數配置見表1。在IRDrop 的影響下,施加到憶阻器兩端的電壓受到憶阻器處于憶阻器陣列的位置的影響,根據文獻[10]中的憶阻器陣列的實際退化情況得到模擬結果,按照模擬結果來表示IR-Drop 的影響。
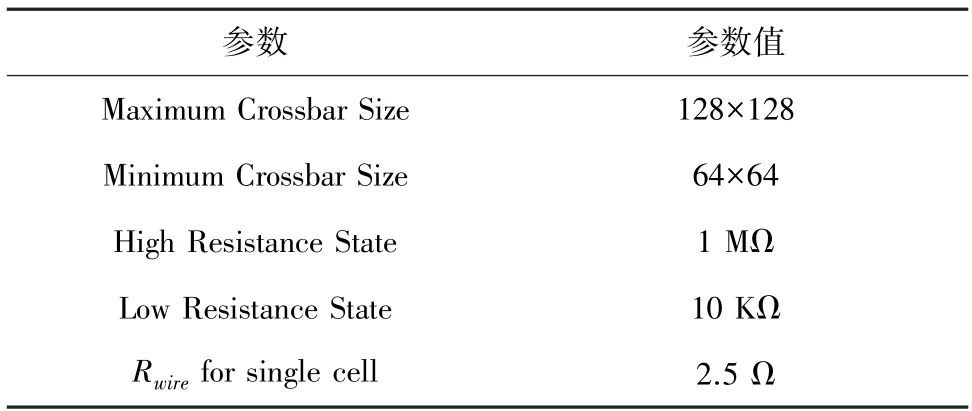
表1 實驗參數設置Tab.1 Experimental parameters setting
3.2 實驗結果分析
本實驗將STC 方案和SVD 方案在不同規模的憶阻器陣列上的計算精度和硬件規模開銷上做了對比。STC 方案和SVD 方案在計算精度的對比如圖3所示,圖3 展示了不同規模的憶阻器陣列在4 種情況下的計算精度,分別是權值矩陣在有IR-Drop 影響下和無IR-Drop 影響下的計算精度,采用SVD 方案和STC 方案的計算精度。在IR-Drop 的影響下,隨著憶阻器陣列規模的增加,計算精度會不斷下降,STC 方案和SVD 方案有效地提升了在IR-Drop 影響下憶阻器陣列的計算精度,并且STC 方案與SVD方案相比計算精度較高。這主要是因為采用STC方案得到的矩陣有大量零權值,零權值受到IRDrop 的影響很小,所以憶阻器整體受到的IR-Drop影響較小。而SVD 方案得到的矩陣規模較大,所以仍然會受到較大的IR-Drop 影響。可以看出STC方案在憶阻器規模較小的時候計算精度的提升較小,而對于較大規模的憶阻器陣列計算精度提升較大。
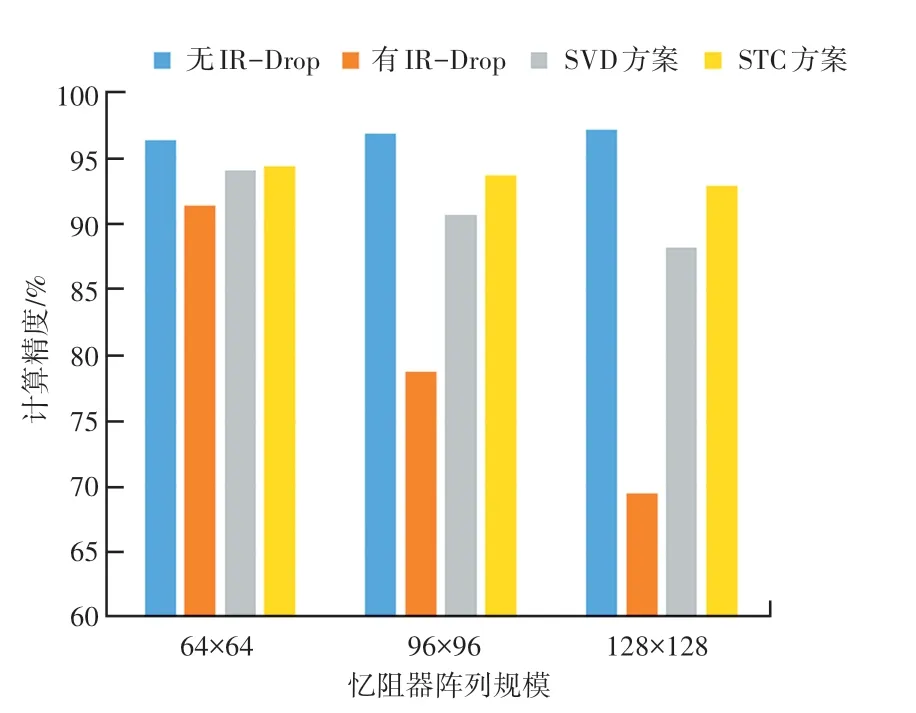
圖3 不同規模的憶阻器陣列的計算精度Fig.3 Calculation accuracy of Memristor based Crossbar of different sizes
STC 方案和SVD 方案在硬件規模開銷對比見表2。表2 展示了不同規模的憶阻器陣列,采用STC 方案和SVD 方案所使用硬件規模的比較。SVD 方案會把矩陣分解成2 個小矩陣,STC 方案則直接將一個大矩陣縮減成小矩陣。STC 方案在硬件規模的縮減大小上比SVD 方案要高。這主要是因為STC 方案采用稀疏化訓練的方式使得零權值大量分布于神經網絡的權值矩陣上,因此權值矩陣上可以刪除許多全零行向量和全零列向量來減少矩陣規模,而SVD 方案為了提高計算精度,得到的矩陣規模較大。STC 方案對于較大規模憶阻器陣列的硬件規模削減效果更好,例如對于128×128 大小的憶阻器陣列縮減了77.29%,而對于64×64 大小的憶阻器陣列只減少了23.44%。

表2 不同規模的憶阻器陣列的硬件規模Tab.2 Hardware scale of Memristor based Crossbar of different sizes
在STC 方案中,通過調整稀疏化范圍來得到不同規模的憶阻器陣列的計算精度和硬件規模的開銷,針對不同規模的憶阻器陣列的計算精度如圖4所示。圖4中,橫坐標表示憶阻器陣列上的權值的行號、列號之和大于該值則需要置零。隨著神經網絡稀疏化范圍的減小,憶阻器陣列的計算精度提高。因為在40~60 的范圍內,憶阻器陣列上的大權值受到的IR-Drop 影響較小。隨著權值矩陣稀疏化訓練范圍的減小,在神經網絡訓練的過程中可以進行調整的權值數量增加,神經網絡的計算精度就會提高,權值矩陣映射到憶阻器陣列上的計算精度也會增加。因此在一定范圍內減少神經網絡稀疏化訓練的范圍可以提高憶阻器陣列的計算精度,但是如果神經網絡稀疏化范圍太小,憶阻器陣列就會受到較大的IR-Drop 的影響,計算精度反而會下降。
針對不同規模的憶阻器陣列縮減后的硬件規模如圖5 所示。圖5中,橫坐標表示憶阻器陣列上的權值行號、列號之和大于該值則需要置零。隨著神經網絡稀疏化范圍的減小,硬件規模的大小增加。因為隨著稀疏化范圍的減小,權值矩陣上全零行向量和全零列向量的數量就會變少,權值矩陣的規模增加,所以映射到憶阻器陣列上后的硬件開銷就會增加。
從圖4 和圖5 可以看出,通過設置不同的稀疏化范圍會導致不同的計算精度和硬件規模的開銷,這里STC 方案以最高計算精度為選取方案。
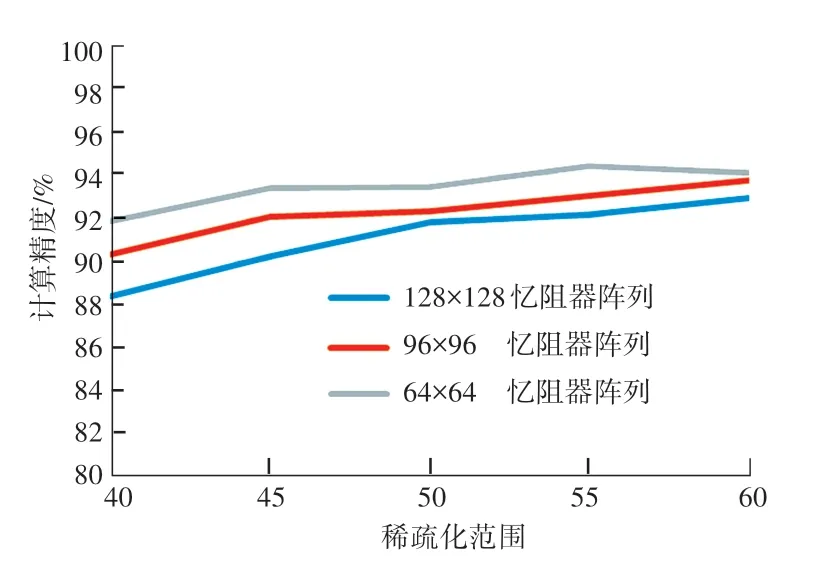
圖4 不同規模的憶阻器陣列計算精度Fig.4 Calculation accuracy of Memristor based Crossbar of different sizes

圖5 不同規模的憶阻器陣列硬件規模Fig.5 Hardware scale of Memristor based Crossbar with different sizes
4 結束語
憶阻器陣列在神經網絡計算加速上有著很好的效果,但是會受到IR-Drop 的影響,從而造成計算精度的下降。本文提出了STC 方案用于降低IR-Drop的影響,提高計算精度。該方案基于對權值矩陣進行稀疏化以及對權值矩陣的行向量進行聚類來實現,可以有效提高計算精度,并且減少了硬件規模的開銷。根據實驗結果表明,經過STC 方案處理的憶阻器陣列在IR-Drop 的影響下,計算精度顯著提高,硬件規模大大降低。
猜你喜歡
中學生數理化·八年級物理人教版(2022年3期)2022-03-16 05:55:08
當代陜西(2021年2期)2021-03-29 07:41:24
家庭影院技術(2020年10期)2020-12-14 07:54:18
媽媽寶寶(2017年3期)2017-02-21 01:22:28
中國塑料(2016年3期)2016-06-15 20:30:00
通信電源技術(2016年3期)2016-03-26 07:13:38
知識經濟·中國直銷(2016年3期)2016-02-27 16:15:49
現代檢驗醫學雜志(2014年6期)2014-02-02 03:02:04
閱讀與作文(小學低年級版)(2011年3期)2011-01-01 00:00:00
