一個并發AI 數據流處理節點內的通信模型
2022-12-11 09:42:30黃東生陳慶奎
智能計算機與應用 2022年11期
黃東生,陳慶奎
(上海理工大學 光電信息與計算機工程學院,上海 200093)
0 引言
隨著物聯網[1]的高速發展、AI 數據流的不斷增加,給物聯網服務器設備對于數據流的處理帶來了極大的挑戰。為了應對這種現狀,大量研究人員和企業人員開始將目光投向了邊緣計算[2],并將其作為云計算的補充和優化,加快數據處理的速率。邊緣計算可以在云的外圍部署集群服務器,集群服務器中的計算節點對于數據流實施不同的處理,可以采用流水線加工的方式并行地對數據流的各個階段進行計算處理,如進行AI 圖像并發數據流的流水線處理,前期由一組流處理節點獲取到數百個圖像的數據流并對數據流進行預處理,然后發送到下一組流處理節點進行圖像信息分析,再將分析結果發送到下一組流處理節點進行信息匯總,這樣每個流處理節點處理并發數據流的一部分,形成一條流水線加工的方式處理數據流既能減輕單個計算節點的工作壓力,又方便各個計算節點功能的維護與擴展。實現邊緣計算的服務器集群的前提是有個高性能的通信方法。有很多種實現邊緣計算服務節點通信的方法,其中一方面是采購專用的網絡通信設備、比如Myrinet、ATM 和ServerNet等[3],但是這些通信設備價格普遍比較高昂,無法進行大規模的普及。另一方面隨著硬件技術的發展,普通的網絡設備價格走低,網卡上的端口數量和通信速度在逐漸提升,CPU 核心數量也在日益增加。但是如何充分利用這些設備資源成為業界研究和討論的問題。伴隨著這些問題,Intel 在2014 年發布了數據平面開發套件DPDK(Data Plane Development Kit)[4]。DPDK 使用DMA 技術和DDIO 技術直接進行內存訪問[5],并利用大頁技術,減少了中斷的發生,將數據的處理從內核態轉移到用戶態[6-7],繞過了傳統系統的內核協議棧,不用進行多次數據的封裝與拆裝,大大地提高了數據的處理效率。DPDK 還能很方便有效地管理計算節點內的網卡端口和CPU 核:實時調度端口與CPU 核資源去執行任務和計算出端口與CPU核的負載程度并及時反饋給系統,為邊緣計算服務集群的實現提供了方法。
為了提升邊緣計算服務集群的通信能力與計算節點內對數據流的處理速度與通信速度,滿足大規模數據流的實時處理需求,本文提出了并發AI 數據流處理節點內的通信模型,并制作相關系統來驗證本文方法。該系統利用DPDK 的綁定機制與線程親和性等技術,根據CPU 核資源的負載情況結合線性規劃算法和排序算法均衡地為資源分配模型的接收過程、計算過程和發送過程綁定CPU核,提高核的利用率;還實現了基于DPDK 的高效數據流接收;根據數據流的id 類型進行分類排序再計算;實時監控集群內網卡端口的負載情況;依據網卡端口的負載情況制定各端口的調度策略,計算出各個端口的數據負載量,以提高系統性能,提高系統資源利用率。
1 相關工作
針對邊緣計算服務集群的構建,如何在資源受限的集群計算節點上處理數據流已經成為研究的熱門方向。文獻[8]構建了基于Kafka 的預警數據匯集分發系統架構,說明了Kafka 集群原生負載均衡存在的問題,并提出了一種動態負載均衡算法,利用采集各代理節點運行時的負載指標計算負載值,但Kafka 主要是針對應用層通信進行加速,對于系統的底層通信并不能提供很好的支持。文獻[9]提出一種多網卡帶寬疊加方案,其原理是所定義的端口負載均衡模型來對數據進行收發,達到端口的均衡利用,以實現數據傳輸的穩定性和高效性,但是主要研究的是網卡端口的通信加速,并沒有針對CPU 核的數據處理進行優化研究。傳統網絡通信方案制約著相關行業的發展,經業界行業內人員的不斷研究,目前已出現了如netmap、DPDK 等高性能網絡數據包處理框架。其中,netmap基于共享內存的思想,提供了一套用戶態的庫函數來訪問共享內存,繞過系統內核的數據包處理操作,實現了用戶態和網卡之間的數據包高性能傳遞[10],但是netmap 框架仍然需要依賴中斷機制來進行數據包的發送與接收,未完全解決通信瓶頸。DPDK 結合了netmap 共享內存技術,并采用輪詢模式與混合中斷輪詢模式,在數據包收發時,減少了中斷處理的開銷。近年來,因DPDK 部署起來比較簡單、社區參與人員較多、技術發展快而被廣大業內人員使用。文獻[11]提出一種基于DPDK 的捕獲數據包的方法,使用DPDK 提出的RSS 數據分發算法充分發揮了多端口通信性能。但RSS 的分發是基于五元組,就是數據包必須包含源IP 地址、源端口、目的IP 地址、目的端口和使用的協議才能進行數據包的分發,主要針對網絡層及其以上的協議,若只在同一局域網內通信,RSS則不適用,還有就是若不考慮網卡端口的負載情況而使用RSS 分發算法,容易造成端口的擁塞。文獻[12]則是將DPDK 應用在網絡虛擬化,將SRIVO 與DPDK 結合,利用DPDK 底層的高速數據處理性能,來提升云計算網絡中密集型數據在轉發方面的通信性能,但是這對硬件的要求比較高,部署成本和難度較大。上述研究成果,有的只是針對網卡端口設計了相關的調度策略,但并沒有充分利用CPU 核資源[9-12];還有些是沒有設計任何端口的調度策略,直接利用網卡進行數據的收發[8],沒有針對計算節點中的多核多網卡設計相關并發數據流的調度策略。本文在計算節點內部根據網卡端口與CPU 核的負載情況結合相關算法計算出網卡端口和CPU 核的有效調度策略,均衡各個過程的CPU 核綁定,使計算節點處理并發數據流的速率更優。將計算完成的數據發送給服務器集群中的下一個計算節點進行下一步計算,計算節點之間存在著一對一、一對多和多對多的數據流通信方式,為了提高集群整體的性能,研究了針對計算節點中的計算資源進行均衡利用的劃分方法。
2 基本定義
定義1 流處理節點指為了減輕單個流處理節點(計算節點)處理數據的壓力而采用流水線加工的方式來處理并發AI 數據流。每個流處理節點都會對并發AI 數據流進行接收、存儲、計算和發送處理,這里給出并發AI 數據流的串行處理過程如圖1 所示。圖1中,流處理節點A接收圖像信息數據,進行圖像預處理,如簡單去除圖像、圖像標點和形成AI 數據流的通信單元等操作,然后將預處理完成的數據并發地傳輸到流處理節點B結合CPU 或GPU進行圖像分析計算,將分析結果再傳輸到流處理節點C進行數據匯總等操作,這樣一套流水加工的方式,不用將所有操作交給一個流處理節點處理,減輕了單個流處理節點的壓力,提高效率。

圖1 并發AI 數據流的串行處理過程Fig.1 Serial processing of concurrent AI data streams
定義2 AI 數據流與通信單元通信單元是流處理節點(計算節點)的接收、存儲、計算和發送的基本單元;經過智能終端的AI 計算得出的中間結果稱為AI 數據流,AI 數據流(AIStream)是由一個或多個通信單元按序組成的一條連續單元序列。
AI 數據流與通信單元如圖2 所示。由圖2 可知,一條AI 數據流可由多個通信單元(U)組成,每個U都是向DPDK 創建的內存池[13-14](mempool)申請而來,U的主要部分結構可表示為U(head,data),其中head為頭部區域,主要包括的字段有des目的地址、src源地址和type通信單元類型,本文主要介紹2 種類型:FT_TYPE類型,用于更新流轉發表端口信息;DATA_TYPE類型,用于存儲AI 數據流信息使各個流節點進行讀取、計算和傳輸,不同的類型所對應的data數據域的結果也不同,當然,head部分的字段格式對所有類型的通信單元是一樣的,詳細情況見數據傳輸協議。

圖2 AI 數據流與通信單元Fig.2 AI data flow and communication unit
定義3 通信速度指計算節點的網卡端口單位時間內發送和接收通信單元的數量。
定義4 處理速度指計算節點的CPU 核單位時間內處理通信單元的數量。
3 系統模型與實現
流處理節點內的并發AI 數據流的通信過程如圖3 所示。圖3中,系統首先通過DPDK 綁定網卡端口以便并行地接收邊緣服務集群中其它流處理節點(計算節點)傳輸來的AI 數據流(AIStream)中的通信單元;接收過程從網卡端口獲取通信單元并根據通信單元的id進行分類,繼而保存至對應的接收環(RR)中;每個RR都有一個與之對應的計算線程(CTP),CTP將RR中的通信單元按序組合成一條單元序列進行計算操作,將計算結果存儲到對應的發送環(SR)中,圖3 中的RR1中的通信單元由CTP1處理,再將處理后的AI數據轉存至SR1;發送過程根據流轉發表(FT)并結合通信單元調度策略將發送環SR中的通信單元并發地傳輸到下一個流處理節點進行下一步AI數據流的處理。端口監控(PM)模塊主要是實時監控集群中各個計算節點的網卡端口的負載情況,將負載情況及時更新到流轉發表中,為通信單元調度策略與AI 數據流的轉發提供數據支持。

圖3 流處理節點內的并發AI 數據流通信過程Fig.3 Concurrent AI data stream communication process within stream processing nodes
3.1 數據傳輸協議
數據傳輸協議的類型由協議頭部(head)中的type字段控制,主要有2 種傳輸協議類型:DATA_TYPE類型和FT_TYPE類型。AI數據流DATA_TYPE類型通信單元格式如圖4 所示。圖4中,type字段為DATA_TYPE的通信單元格式,其中des為接收通信單元的計算節點網卡端口的MAC地址,即為目的MAC,占6 字節;src為發送通信單元的計算節點網卡端口的MAC地址,即為源MAC,占6字節;node為計算節點編號,主要是用于判斷通信單元的來源與轉發,占2 字節;id為通信單元編號,主要用于分類,屬于同一數據流的通信單元id都是一樣的,是用于通信單元分類計算的重要屬性,占2字節;seq為通信單元的序號,序號是連續編排的,方便最終數據按序組合成完整的數據流,占4 字節;size為當前通信單元中實際需要被處理的數據大小,占4 字節;data為需要計算處理的實際數據。

圖4 AI 數據流DATA_TYPE 類型通信單元格式Fig.4 AI data stream DATA_TYPE type communication unit format
AI 數據流FT_TYPE類型通信單元格式如圖5所示。圖5中,type字段為FT_TYPE的通信單元格式,當網卡端口收到此類型的通信單元時,則由端口監控模塊將FT_TYPE類型的通信單元中的數據信息更新到流轉發表中。其中,協議頭部與DATA_TYPE類型的通信單元格式一樣,node字段所表達的內容也為計算節點編號;cnt為該node編號所對應的流處理節點的網卡端口個數;p_mac為網卡端口的MAC地址,編號為0~cnt;p_load為網卡端口所對應的端口負載并與端口MAC地址一一對應。

圖5 AI 數據流FT_TYPE 類型通信單元格式Fig.5 AI data stream FT_TYPE type communication unit format
3.2 接收過程
通過DPDK 的核綁定技術為接收過程綁定若干CPU 核、簡稱Recv核,并通過Recv 核將網卡端口接收的通信單元分類轉存至接收環RR中,這一過程稱為接收過程。此時網卡端口的通信速度與Recv 核的處理速度存在一定限制,若Recv 核過多,總處理速度太快,則可能會造成模型中其它過程因CPU 核的分配不均衡而使任務執行速度慢下來。下面就是系統通信模型結合線性規劃算法為接收過程均衡地綁定CPU 核的理論描述過程。
計算節點中網卡端口總數量為n,通信速度分別為D={u1,u2,…,un},CPU 核總數量為m,處理速度分別為V={v1,v2,…,vm},一般情況下核的處理速度大于端口的通信速度,但是若CPU 核在同時處理多個任務時,分配給單個任務的處理速度可能比通信速度小。此種情況下,在接收過程中,設Recv 核的數量為a,因為網卡端口總的通信速度大于CPU 核總的處理速度會造成Recv 核來不及分類和轉存網卡端口接收的通信單元而導致數據的丟失,所以需要求出a的值以及與其對應Recv 核的處理速度需要滿足如下條件:

滿足式(1)的條件下,目標函數為:

通過規劃論中線性規劃算法,在式(1)的約束下求出式(2)目標函數中Zrv的最小取值,此時可以求出Recv 核的數量a以及在V中選擇的對應Recv核的處理速度此時為接收過程均衡配置的CPU核,既能及時處理網卡端口接收的通信單元,又能提高Recv 核的利用率。
3.3 發送過程
發送過程并發地從各個SR中獲取計算完成后的通信單元,并采用端口調度策略規劃每個網卡端口傳輸通信單元的數量,再將分類后的通信單元序列(數據流)傳輸到下一組對應的流處理節點繼續進行處理。若發送過程傳遞給網卡端口的速度大于網卡端口總的通信速度,則可能會造成網口來不及發送通信單元而丟失數據,所以發送過程綁定的CPU 核有一定的限制,網卡端口的通信速度在3.1節已求出,需要給出發送過程綁定的CPU 核(Send核)的數量f,以及在V中選擇的Send 核的處理速度Vsend=則需要滿足Send 核的處理應該恒定小于網卡端口總的通信速度,即并且Send 核盡可能與CLA 核不重合,即Vcla∩Vsend≈?,求出合適的f以及對應的,設y初始值為無限大,x為-1,循環以下步驟:


3.4 計算過程
計算過程中的每個計算線程(CTP)從對應的接收環RR中獲取通信單元,并會根據字段seq進行按序計算,這一過程稱為計算過程。計算過程中一般會對數據進行大量的復雜計算,如GPU 計算、圖像識別計算和數據故障分析或耗時的系統調度等。系統為計算過程均衡地綁定多個CPU 核、簡稱CALC核,并使用DPDK 技術為每個CALC 核綁定一個或多個計算線程(CTP)。并發AI 數據流的大部分處理時間都在計算過程中,所以這個過程需要配置處理速度較快的CALC 核來加快計算過程。因為并發數據流的大部分處理時間都在CALC 過程中,所以這個過程需要配置處理速度較快的CALC 核來加快計算過程,為CALC 過程綁定的CPU 核的數量為e,以及在V中為計算過程選擇的CPU 核的處理速度此時應將剩余的CPU 核全部分配給CALC 過程,則e=m -a -b -f,其中m為CPU 核總數,a為Recv 核數,b為CLA 核數,f為Send 核數,與之對應的Vcalc為Vcalc?V且Vcalc∩Vrv≈?,Vcalc∩Vcla≈?,Vcalc∩Vsend≈?,表示Vcalc所包含的計算核盡量不與其它過程所取的核有交集。
在CPU 核數量不足的情況下,如某系統只有2個CPU 核可用,應盡可能使計算過程有一個獨立的核可用,其它過程共用另一個CPU核,因為一般情況下計算數據所花費的時間較多,耗能較大,所以應多分配CPU 核到計算過程中,但是具體情況則視實際情況而定。
3.5 緩沖環
緩沖環是利用DPDK 技術創建的Ring 來緩存通信單元,其具有先進先出,可以設置最大空間,指針存儲在表中,多消費者或單消費者(這里,消費者是指數據對象出隊機制),多生產者或單生產者入隊(這里,生產者是指數據對象入隊機制)等特點,優點是數據交換速度快,使用簡單,還可用于巨型數據的入隊和出隊操作。本文將緩沖環分為2 種。一種是用于接收初始通信單元分類的接收緩沖環RR,另一種是緩存計算后等待發送的通信單元的發送緩沖環SR。
3.6 端口監控與流轉發表
端口監控(PM)模塊綁定一個空閑的或有空余負載的CPU 核、簡稱PM核,用于監控服務器集群中計算節點的端口通信負載情況并及時更新到流轉發表(FT)中,PM 模塊還需要將其所在計算節點的網卡端口負載情況每隔一個時間段就發布給服務器集群內的其它計算節點,以便服務器集群中的計算節點能實時掌控全局網卡端口負載情況,有助于轉發數據時填充目的MAC。
FT 主要作為一個流id與流處理節點的映射表,指引AI 數據流轉發到下一個流處理節點。
流轉發表的結構FT(id,node(mac,load))見表1。表1中,展示了當前流處理節點中第i條AI數據流在計算后應轉發到下一跳節點nodei,其中mac為nodei的MAC地址,用于通信單元目的地址填充;load為nodei所對應流處理節點的各個端口負載,主要用于端口調度策略的計算。在整個計算資源均衡分配模型中PM 核的工作負載較小,因此可利用Recv 核、CLA 核或Send 核的空余負載并發地執行PM 模塊的功能,若還有剩余的CPU 核則可以分配給PM 模塊或計算過程。

表1 流轉發表結構Tab.1 Flow forwarding table structure
3.7 端口調度策略
將SR中的通信單元序列(計算完成的AI 數據流)通過網卡端口并行地傳輸給下一組計算節點,均衡各個網卡端口的通信負載需要進一步考慮每個網卡端口發送通信單元的數量,制定端口的調度策略,均衡網卡端口的通信負載。當前網卡端口總發送的通信單元數量為N,需要求出為各網卡端口分配的通信單元的數量{s1,s2,…,sn},則調度分配策略如下:


當Zt取最小值時,可達到最優的端口調度,此時可求出每個端口的通信單元發送量{s1,s2,…,sn}。
在計算出各端口的調度策略后,發送過程需要根據發送網卡端口先填充每個待發送的通信單元U的U.src,U.src為發送該通信單元的網卡端口地址,再根據每個通信單元的U.id到流轉發表中找到對應計算節點的目的網卡端口信息,U.des填充如圖6所示。若對應計算節點的FT.node.load還有空余負載,可以將FT.node.load對應的FT.node.mac填入U.des,若FT.node.load沒有空余負載,則繼續掃描下一個FT.node.load。

圖6 U.des 填充Fig.6 U.des filling
4 實驗分析
4.1 實驗環境
為了驗證所設計的計算資源均衡分配模型的性能,研究使用了5 臺服務器作為邊緣服務集群中的計算節點來模擬將avi 格式的視頻數據轉換成mp4格式的視頻數據。其中,2 臺服務器設備產生視頻數據,1 臺服務器對視頻數據進行預處理,1 臺服務器對視頻數據流進行avi 到mp4 格式的轉碼操作,一臺服務器對最后的視頻數據進行整合匯總。
本次實驗中的各個服務器的布局情況如圖7 所示。圖7中,每個計算節點(服務器、流處理節點)會先安裝DPDK 進行網卡端口的綁定和系統的初始化操作,接著由2 個計算節點A和B生成視頻數據,再并發地將視頻數據傳輸給計算節點C進行預處理:將每個視頻進行id編號和切分等操作,形成視頻數據流后發送給計算節點D進行avi 格式到mp4 視頻格式的轉碼操作,再將轉碼后的視頻數據流發送給計算節點E進行視頻數據單元的組合,匯總形成完整的mp4 格式的視頻。

圖7 實驗中服務器的布局Fig.7 The layout of the server in the experiment
實驗環境中每個服務器節點上都有一個4 口千兆網卡,用來進行并發數據流的接收和發送,還有16 個CPU核,并通過上述各個過程的算法為各過程均衡綁定CPU核,服務器詳細配置信息見表2。

表2 服務器配置信息Tab.2 Server configuration information
4.2 性能評估指標
在對計算資源均衡分配模型進行評估時,選取網卡端口帶寬利用率、丟包率來對整個系統的性能進行評估、并發數據流的流量大小對模型中各個過程CPU 核綁定的情況進行分析和計算任務復雜度的變化對CALC 過程的核綁定的影響,因本文還未實現可靠傳輸,所以采用傳統UDP 通信來與本文方案做對比實驗。網卡端口帶寬利用率Rpt(t)計算公式如下:

其中,Fpt(t) 表示當前時間端口通過的通信單元數量;Fpt(t -1)表示上次采集的值;Δt表示2 次收集的數據量的時間差;BW表示網卡端口的帶寬、即端口的通信速度。
端口丟包率Rloss(t)計算公式如下:
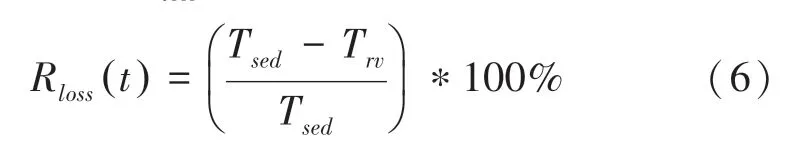
其中,Tsed表示當前網卡端口輸入的通信單元數量,Trv表示當前網卡端口輸出的通信單元數量。
4.3 實驗過程與分析
4.3.1 通信性能和丟包率
實驗中的計算節點都在同一局域網下,在計算節點C上將每個通信單元的大小從64 字節到1 024字節進行調整,并傳輸給計算機節點D,數據流數量為240 條。通信性能測試,主要在計算機節點D上測試本文單個端口的帶寬與不采用本文模型的系統內核UDP 通信做對比實驗,在同樣的數據包和數據量情況下,通信性能與丟包率如圖8 所示。

圖8 通信性能和丟包率測試Fig.8 Communication performance and packet loss rate testing
由圖7 可知,通信單元的大小對通信帶寬的影響不大,而對于丟包率會有影響。柱狀圖為通信速率,由此可知,本文方案明顯優于傳統UDP 通信速率;由折線圖可以看出傳統UDP 的丟包率在0.01%到0.05%之間,而本文方案的丟包率在0.001%到0.01%之間,比傳統UDP 通信的丟包率低10 倍左右。這2 個結果得益于DPDK 的高性能數據包處理機制,加速了數據包的處理,提高了通信帶寬,降低了丟包率。
4.3.2 計算核數量與通信核數量的變化
隨著并發數據流的增大,對各個通信過程(接收過程和發送過程)與計算過程綁定核的數量變化,與此同時在進行視頻轉碼時,會使用到GPU 來參與計算,所以在實驗過程中也記錄了GPU 負載的變化,如圖9 所示。
由圖9 可以看出,隨著并發數據流的增加,通信核的個數也逐漸增加,在總核數不變的情況下,分配給計算部分的計算核有所下降,但是一起參與計算的GPU 使用率逐漸增加,來彌補CPU 核計算能力不足的問題。

圖9 通信核數量與計算核數量和GPU 負載的變化Fig.9 Changes in the number of communication cores,the number of computing cores and GPU load
4.3.3 網卡端口均衡帶寬利用率測試
為測試端口調度策略的可行性,數據流源源不斷地從計算節點A和B傳輸給計算節點C、D和E,需要觀測計算節點C、D、E的網卡端口是否處在均衡使用狀態。各計算節點端口均衡使用情況如圖10 所示。
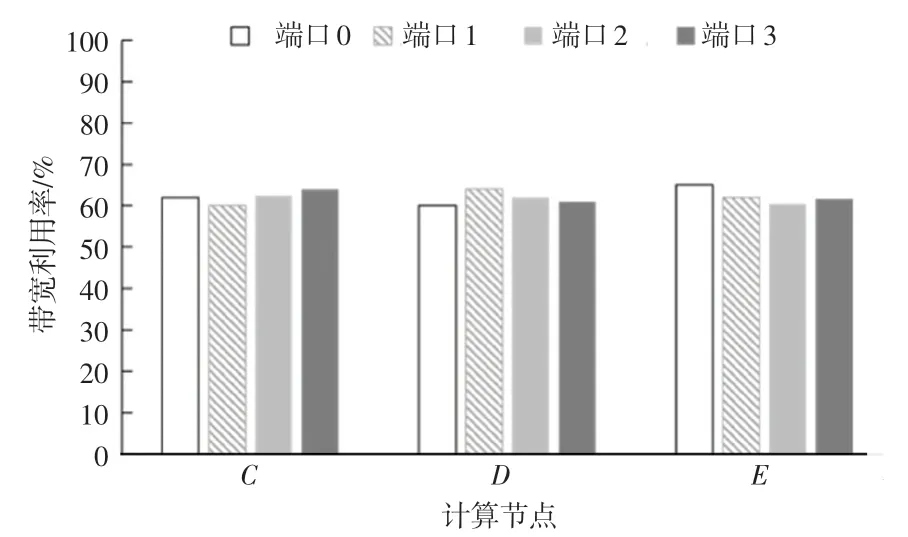
圖10 各計算節點端口均衡使用情況Fig.10 Balanced usage of ports on each computing node
此次測試是在120 條數據流的情況下進行的,通過圖10 可以發現,計算節點對網卡端口的使用相對均衡,各個端口帶寬利用率穩定在60%左右,證明端口調度策略是可行的。
下面測試數據流大小對計算節點內網卡端口利用率的影響。
數據流大小對帶寬利用率的影響如圖11 所示。由圖11 可知,隨著并發數據流逐漸增大,計算節點的平均帶寬利用率也在上升,最終穩定在90%左右。

圖11 數據流大小對帶寬利用率的影響Fig.11 The effect of data stream size on bandwidth utilization
5 結束語
本文研究與分析了并行通信、DPDK 和計算節點內的通信資源與計算資源,在邊緣服務集群中以流水加工串行的方式處理并發AI 數據流,以減輕各個計算節點的計算壓力與通信壓力,設計實現了一個并發AI 數據流處理節點內的通信模型;然后對資源分配模型中的各個過程進行資源分析,并為每個過程均衡地分配CPU核,以提高CPU 核的利用率,同時還設計了端口調度策略用來均衡各端口的帶寬利用率,還加入了端口監控模塊和流轉發表實時監控服務器集群中的端口負載情況,將緩沖隊列中的數據轉發給下一個計算節點;最后,通過實驗驗證了計算資源均衡分配算法和端口調度算法的可行性,實現了計算資源的均衡分配,有效降低了邊緣服務集群中計算節點的部署成本,提高了計算節點的計算效率與通信速率。接下來為完善邊緣服務集群整體性能,將對模型的可靠性、能耗、CPU 核的并發處理能力進一步優化降低通信核的數量等方面做更深入系統的探索與研究。
