基于組件特征與多注意力融合的車輛重識別方法
2022-11-11 10:49:50陳小波梁書榮
計算機研究與發展 2022年11期
胡 煜 陳小波,2 梁 軍 陳 玲 梁書榮
1(江蘇大學汽車工程研究院 江蘇鎮江 212013) 2(山東工商學院計算機科學與技術學院 山東煙臺 264005)
近年來,隨著機動車保有量的持續增加,使用計算機技術輔助人工進行交通管理的需要已十分緊迫,作為一種能夠對城市內車輛進行定位、跟蹤、監管的重要手段,車輛重識別受到學術界的廣泛關注.車輛重識別即給定目標車輛在特定區域內的一張圖像,找出目標車輛被其他攝像頭拍攝的圖像.車輛重識別是一種特殊的圖像檢索問題,只能使用車輛的外觀信息和輔助信息(如車輛編號、拍攝時間和地點等信息),檢索圖像的視角、拍攝時間和天氣等因素都可以和給定的圖像不一致[1].由于不同攝像頭的位置、視角、光照、分辨率等因素,同一輛車的不同圖像可能看上去存在較大差異,而不同的車輛可能由于相同的視角和車輛型號產生相似的圖像,這些都對車輛重識別問題造成了挑戰.
為了解決不同圖像中車輛視角不同的問題,一種直接的方法是在不同的車輛圖像中抽取與視角無關的特征,再利用這些特征度量車輛圖像的相似度.隨著深度神經網絡,尤其是卷積神經網絡的快速發展,一些基于人工設計和提取的視角無關特征[2-5],如顏色、車型、尺寸等的方法已逐漸被基于深度學習的方法所取代.目前,基于深度學習的車輛重識別方法主要分為基于多特征融合的方法和基于度量學習的方法.
在多特征融合方法中,Liu等人[6]將深度學習得到的特征與車輛的顏色信息等多種特征進行加權求和,得到車輛圖像之間的相似性得分,再以此為依據進行車輛重識別排序;He等人[7]將車輛的一些組件作為約束引入了車輛的重識別過程,增強了深度神經網絡對相似車型之間細微差異的辨別能力;Wang等人[8]利用堆疊式沙漏網絡(stacked hourglass network)對車身表面具有辨識性的20個特征點進行預測,并根據這些關鍵點所屬的面對這些關鍵點的特征進行累加,得到用于相似性判斷的特征向量.總的來說,基于特征融合的方法通過合理地選取車輛的關鍵點或關鍵部位與損失函數,使網絡更加關注車輛的辨識性特征,具有較高的準確率.但這些方法選取的車輛部件很多仍需人工指定,不具有較好的魯棒性.
在度量學習方法中,Liu等人[9]提出了深度相關性距離學習,在進行車輛重識別任務的同時對車輛型號進行判別;Guo等人[10]進一步提出一種由粗到精的特征嵌入方法,使網絡能夠學習到敏感的辨識性特征;Zhang等人[11]提取了車輛圖像的關鍵部位,將其輸入到注意力模塊中,提高神經網絡尋找具有辨識性部分的能力,降低非辨識性區域對重識別的負面影響;Zhou等人[12]設計了一個根據單視角特征生成車輛各種視角特征向量的網絡,從而實現對不同視角的車輛圖像進行相同視角的特征向量的對比;Chu等人[13]將圖像對中2張圖像視角之間的關系分為相似視角或不同視角,并分別在不同的特征空間中對這2種關系進行優化.Meng等人[14]提出一種基于語義分割的方法,將車輛圖像劃分為不同組件并對各組件的特征進行對齊(align)以消除視角變化的影響.這些基于度量學習的方法大多較為簡單,具有訓練時間短且解釋性較強的優點.
針對車輛重識別中存在的一些問題,本文提出一種基于組件特征與多注意力融合的車輛重識別方法(parsing-based vehicle part multi-attention adaptive fusion network, PPAAF).首先,利用語義分割網絡,將車輛圖像分割為背景區域和1個或多個車輛組件,包括車輛的正面、背面、頂面和側面,并利用修改后的深度殘差網絡分別從不同的車輛組件中提取不同的特征,比較不同車輛相同組件的特征以消除車輛圖像視角變化對外觀的影響.然后,提出一種基于多注意力的特征融合機制,同時考慮不同組件在圖像中所占的面積及組件特征包含的鑒別信息,實現組件特征的自適應融合.最后,在多任務學習框架下,優化車輛重識別與多個輔助任務的聯合損失函數,對網絡參數進行優化,進一步提升網絡性能.
1 網絡框架
本文提出的車輛重識別網絡由車輛組件語義分割模塊、骨干網絡、特征提取模塊組成,網絡結構如圖1所示:

Fig. 1 Architecture of the proposed network圖1 網絡結構圖

2 骨干網絡與特征抽取模塊
首先對深度殘差網絡進行修改作為本文方法的骨干網絡.深度殘差網絡是計算機視覺中用于圖像分類的經典網絡之一,對于給定的輸入圖像,網絡輸出該圖像所屬的類別.由于圖像中物體的分類任務對車輛重識別并無明顯幫助,移除了深度殘差網絡最末端的圖像分類器,即殘差網絡中最末端的全局平均池化層與全連接層,而將其應用于提取圖像的特征.同時,為了提高輸出特征圖的分辨率,本文移除了深度殘差網絡頂端的步長為2的3×3最大池化層,這使得骨干網絡最終輸出的特征圖寬和高均為原始殘差網絡輸出特征圖的2倍,從而包含更豐富的信息.
通常情況下,可將車輛分為5個面,分別是正面、背面、頂面、左側面及右側面.考慮到車輛的對稱性及車輛的左右2個側面往往不能在一張車輛圖像中同時出現,因此將車輛定義為4個組件:正面、背面、頂面和側面.利用Meng等人[14]提供的車輛組件語義分割模塊,對車輛圖像P進行語義分割,輸出車輛的語義分割圖M,其尺寸與車輛圖像一致.具體而言,對一張高為H、寬為W的車輛圖像P上的一點Phw(1≤h≤H,1≤w≤W)有B(Phw)∈{0,1,2,3,4},其中,B(Phw)表示Phw所屬的類別,0表示該點為圖像背景(不屬于車輛),1,2,3,4分別表示該點屬于車輛的正面、背面、頂面或側面.本文所提出方法中,車輛組件的劃分實例如圖2所示:

Fig. 2 Examples of vehicle parts partition圖2 車輛組件劃分示例


(1)
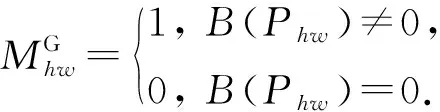
(2)

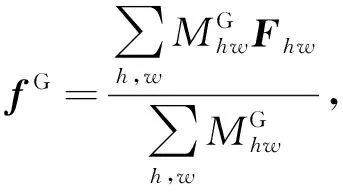
(3)
(4)
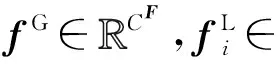
3 組件注意力模塊
3.1 面積注意力
在一張車輛圖像中,構成車輛的4個組件在圖像中所占的面積一般是各不相同的.通常來說,某個組件的面積越大,該組件更可能包含更多鑒別信息,從而在車輛重識別時應該更受關注.因此,首先定義車輛組件i的面積注意力Hi:

(5)
其中ai為圖像中車輛組件i∈{1,2,3,4}所占的面積,Area為圖像中車輛整體所占的面積,這里以組件所包含的像素個數作為面積度量,即

(6)
(7)
3.2 特征注意力
雖然車輛各個組件所占面積的大小在一定程度上能反映該組件在重識別任務中的重要程度,但組件對重識別任務的重要性并不能完全依賴于其在圖像中所占的面積大小.例如,大部分車輛的車頂缺少圖案和裝飾,除顏色外幾乎相同;而大部分車輛的正面,尤其是前擋風玻璃處,則因為車主的個人喜好等因素,會有較為明顯的差異.對從俯視角度獲取的車輛圖像,車頂與車輛正面所占面積大小可能幾乎相同,而車輛正面更可能包含豐富的鑒別特征.因此,為反映車輛各組件的特征向量對其在車輛重識別任務中的重要程度,本文引入一個可學習的車輛組件注意力編碼向量E∈C(C為組件特征的通道數)對各組件的特征向量進行編碼.組件i的特征注意力Ui可以表示為
(8)
其中
(9)

注意力編碼向量的初始化為EO=(1/C,…,1/C),不包含特定的語義信息,但經過學習后,該編碼向量呈現出相當豐富的語義信息.圖3為一個通過網絡優化后的編碼向量的可視化示例,圖4為該編碼向量各通道的數值分布.
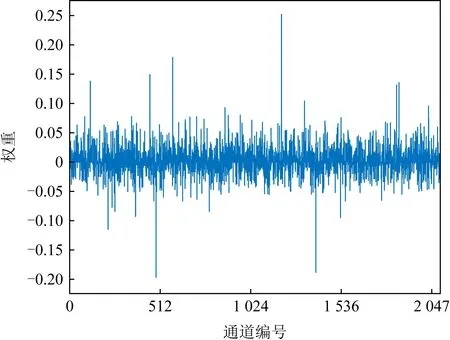
Fig. 3 Weights of attention embedding vector圖3 注意力編碼向量的權重

Fig. 4 Distribution of weights in attention embedding vector圖4 注意力編碼向量的權重分布
3.3 多注意力融合
最終的車輛組件注意力為面積注意力H和特征注意力U的加權之和:
A=λHH+λUU.
(10)
為了更好地確定2種注意力各自的權重,本文引入了一種門控機制Q,使2種注意力在融合時的權重λH與λU由網絡學習得到:
λH,λU=Q(LH(H)+bH,LU(U)+bU),
(11)
其中,LH與LU均為全連接層,bH與bU為可學習的偏差,Q為softmax函數.
4 網絡訓練
針對車輛重識別問題,本文應用三元組損失函數對網絡進行優化;同時,為提高重識別性能,還分別設計了使用車輛整體特征與組件特征的分類任務,用于輔助車輛重識別網絡的訓練.實驗結果表明采用分類任務確實有助于提升網絡的性能.
4.1 損失函數
針對車輛重識別問題,本文采用三元組損失函數[16].首先,對于車輛整體特征fG,應用三元組損失函數,即
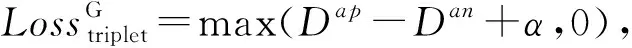
(12)
其中,Dap=dis(fG,a,fG,p)表示車輛圖像a與相應的正樣本p的整體特征fG,a與fG,p之間的歐氏距離;Dan=dis(fG,a,fG,n)表示車輛圖像a與相應的負樣本n的整體特征fG,a與fG,n之間的歐氏距離;α表示正負樣本間的最小距離.

(13)
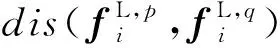

(14)

(15)
在此基礎上應用三元組損失,即

(16)


(17)
針對輔助網絡訓練的分類問題,分為基于車輛整體特征的分類與基于車輛組件特征的分類.對于車輛各組件特征的分類,首先由組件注意力模塊得到車輛各組件的權重A∈N,N=4,對車輛各組件特征進行加權求和,得到
(18)
將加權后得到的特征fL與車輛整體特征fG分別輸入全連接分類器,激活函數采用softmax,預測車輛圖像所屬的類別,然后對車輛整體特征fG的預測應用交叉熵損失LossCE,對特征fL的預測應用focal損失[17]Lossfocal,其調節因子α=0.25,γ=2.
最終用于訓練網絡的損失函數為以上各部分之和,即
Loss=LossCE+Lossfocal+Losstriplet.
(19)
4.2 網絡訓練與推理
本文方法基于Pytorch[18]實現,對在ImageNet上進行預訓練的ResNet-50[15]進行修改作為車輛重識別的骨干網絡,利用Adam[19]優化器對網絡進行優化,批大小(batch size)為72,設置權重衰減(weight decay)為4×10-5,網絡的最大學習率為4×10-4,并且進行學習率預熱(warm-up)[15],在初始的10個訓練輪次中學習率從4×10-5逐漸線性增大至最大.網絡共訓練120輪,且在第40,70輪連續對學習率乘以0.1.對輸入的圖像,首先在圖像邊緣增加10個像素的空白,同時還對訓練圖片使用隨機擦除(random erasing)[20]、水平翻轉(horizonal flipping)[21]等數據增強手段以豐富訓練數據.
在推理階段,本文所設計的網絡對所有輸入的圖像提取全局特征向量與各組件特征向量,分別根據車輛的全局特征向量與各組件特征向量計算出車輛圖像間的全局特征距離DG和組件特征距離DL,最終進行車輛重識別計算的圖像間距離D=DG+λDL,其中λ為平衡參數,λ=1.
5 實驗與分析
5.1 實驗環境
本文所有代碼均基于Pytorch1.7.1,CUDA10.2,Python3.7,實驗平臺的硬件配置為i7-6950x+3×GTX1080ti,內存為64 GB,操作系統為Ubuntu 18.04 LTS.在該平臺上,訓練本文所提出的網絡(120輪)需要大約13 h進行推理時,每批樣本耗時約618 ms,平均每樣本耗時85.8 ms.
5.2 數據集與評價指標
為評估所提出網絡的性能,在Veri-776[22]數據集與VehicleID[9]數據集上進行實驗.Veri-776數據集包括了由20個監控攝像頭拍攝到的776輛車的圖像,共計50 000張,并被劃分為包含來自576輛車的37 778張圖像作為訓練集和來自200輛車的11 579張圖像作為測試集.在Veri-776數據集中,保證檢索圖像與正確的被檢索圖像必須是由不同攝像頭拍攝的,在進行重識別性能評價時,計算全類平均正確率(mean average precision,mAP)與累積匹配曲線(cumulative matching characteristics,CMC).VehicleID數據集使用來自13 134輛車的110 178張圖像與來自13 113輛車的111 585張圖像分別作為訓練集與測試集.對于每輛不同的車,隨機選擇其中的1張圖像作為檢索圖像,其余作為被檢索圖像,且重復測試10次,取這10次測試中的平均性能指標作為最終的性能評價指標,在測試重識別性能時僅計算CMC.下文及表中CMC@k表示CMC曲線在第k位的值.
5.3 實驗結果
為驗證本文提出的PPAAF網絡的有效性,與近年來的部分優秀重識別算法進行了性能比較.比較的方法包括:1)OIFE[8].該方法提取了車輛的20種關鍵點的特征并隨后將特征對齊進行比較,該方法還利用了時空信息.2)VAMI[12].該方法通過視角感知的注意力模型,獲取多個視角的注意力映射,并利用生成對抗機制,通過單視角的特征和注意力映射生成多視角特征.3)EALN[23].該方法通過在指定的嵌入空間內生成難樣本而不是從訓練集中選擇難樣本來提高重識別任務的性能.4)AAVER[24].該方法利用一個2分支網絡分別捕捉車輛的整體特征與車輛各關鍵點的局部特征,并結合車輛的朝向特征來進行重識別任務.5)RAM[25].該方法在抽取了車輛全局特征的基礎上,將車輛圖像水平均分為3部分,并分別在這3部分中抽取車輛的局部特征用于重識別任務.6)VANet[13].該方法針對方向相同的車輛圖像對與方向不同的車輛圖像對,將視角關系不同的圖像對分別在不同的特征空間中進行度量學習.7)DFLNet[26].該方法利用生成對抗網絡的思想,分別抽取出與視角有關和與視角無關的圖像特征,并根據圖像對的視角關系選取對應的特征進行比較.8)PRN[7].該方法主要利用車輛的車窗、車燈與車牌的特征對車輛進行區分.9)PVEN[14].該方法將車輛劃分為正面、背面、頂面和側面4部分,結合車輛的整體特征與4部分的特征進行重識別計算.在VehicleID數據集與Veri-776數據集的比較結果分別如表1、表2所示:

Table 1 Performance Comparison of Different Methods on VehicleID Dataset

Table 2 Performance Comparison of Different Methods on Veri-776 Dataset

Fig. 5 Ranking results obtained by baseline and our method for some hard samples圖5 基準與本文方法對一些難樣本的排序結果
5.4 消融實驗


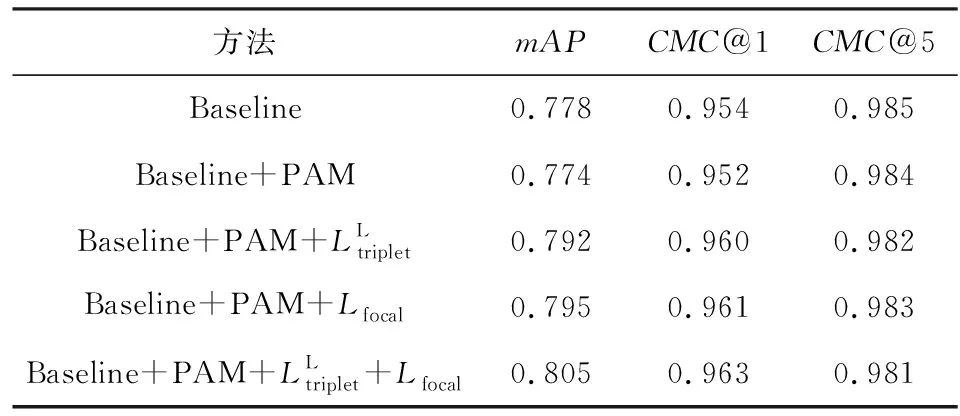
Table 3 Effects of PAM and Multi-task Loss表3 PAM與多任務損失的影響

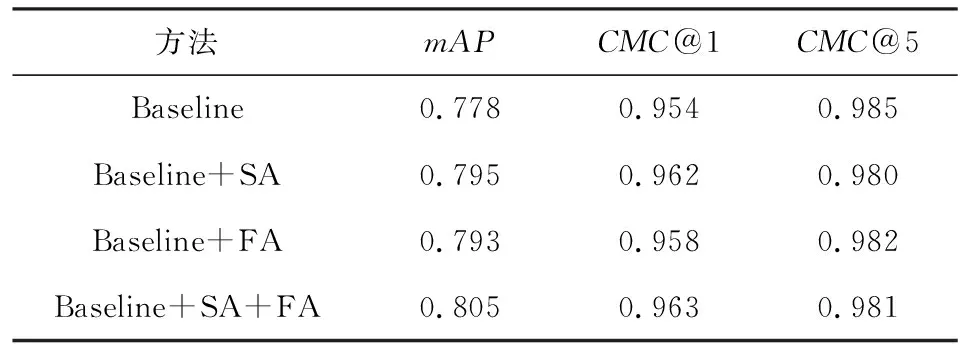
Table 4 Effects of SA, FA and Their Combinations表4 SA,FA及其融合的影響
針對利用車輛特征進行的2項分類任務,本文同樣進行了實驗以驗證其有效性,Veri-776數據集上的實驗結果如表5所示.結果表明,如果不進行分類任務(無LossCE,無Lossfocal),網絡的性能受到大幅度削弱,相比基準,mAP降低了8.4%,CMC@1降低了約6.0%;不利用車輛的整體特征進行分類任務(無LCE),使網絡的性能受到了較大的影響,相比基準,mAP降低了2.1%,CMC@1降低了約0.2%;不利用車輛的組件特征進行分類任務(無Lfocal),也使得網絡的性能受到了一定程度的影響,相比本文方法,mAP降低了1.3%,CMC@1降低了約0.3%.

Table 5 Effects of Two Auxiliary Tasks表5 2種輔助任務的影響
5.5 參數影響分析
在推理過程中,計算車輛重識別排序需要指定超參數λ.為研究λ的取值對重識別性能的影響,分別在不使用PAM和使用PAM的情況下,調整λ的取值,并記錄對應的mAP與CMC@k的值.使用PAM前后λ的取值對網絡性能的影響如表6和表7所示:
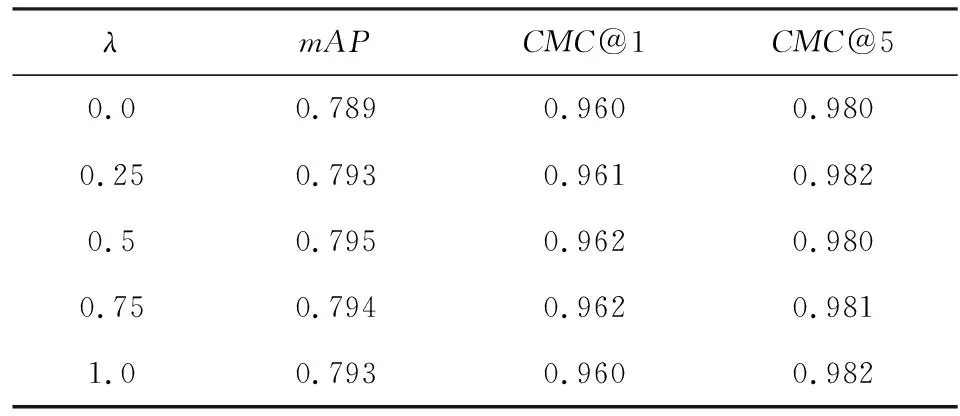
Table 6 Effect of λ Without PAM on the Performance表6 不使用PAM時λ對性能的影響
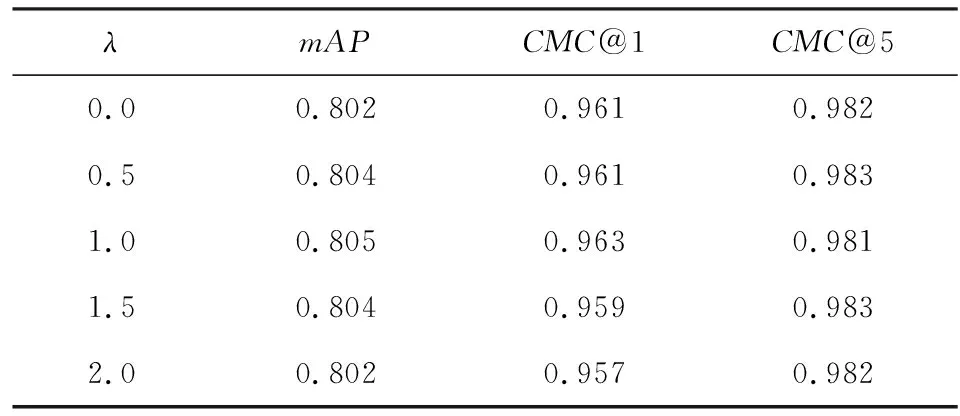
Table 7 Effect of λ with PAM on the Performance表7 使用PAM時λ對性能的影響
結果表明,不使用PAM時,當λ=0.5,網絡的性能達到最優,此時mAP=0.795;使用PAM時,當λ=1.0,網絡的性能達到最優,此時mAP=0.805.使用PAM使網絡性能在mAP上提升了約0.01.
λ表示車輛組件特征距離在最終計算車輛重識別時對各車輛圖像對間總特征距離的貢獻程度,λ越大,則車輛的組件特征距離越有效.因此,本文所提出的PAM不僅提升了網絡的性能,還提升了網絡提取各組件特征的有效性.
6 結論與展望
本文利用修改后的深度殘差網絡與帶掩膜的全局平均池化分別抽取了車輛的整體特征與各組件的特征,并將多種注意力機制進行融合,使得網絡可以精確地計算圖像對之間的總特征距離,從而給出更加準確的車輛重識別結果.實驗表明,融合了多種注意力機制的方法不但能夠在多個車輛重識別數據集上取得更優的性能表現,而且能夠提高所抽取的車輛組件特征的有效性.然而,本文研究仍未完全擺脫依賴于獨立檢測器的桎梏,所采用的車輛組件語義分割模塊獨立于整個網絡,且車輛組件的語義分割結果對重識別模塊的性能表現存在一定影響.在后續的研究中將嘗試解決這些問題.
作者貢獻聲明:胡煜負責文獻調研、方法與實驗設計、論文撰寫和全文修訂;陳小波負責提出指導意見、框架設計和全文修訂;梁軍負責提出指導意見和全文修訂;陳玲負責內容設計和實驗結果分析;梁書榮負責論文撰寫和全文修訂.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
