高效率采樣的數據關聯融合氣動力建模方法
2022-11-09 04:24:42寧晨伽王文正張偉偉
空氣動力學學報 2022年5期
寧晨伽,王 旭,王文正,張偉偉
(1. 西北工業大學 航空學院,西安 710072;2. 電子科技大學 航空航天學院,成都 611731;3. 飛行器集群智能感知與協同控制四川省重點實驗室,成都 611731)
0 引 言
現代航空航天飛行器設計由多學科響應和大量設計準則共同保障。就飛機設計而言,設計過程需要考慮加載特性、氣動彈性、顫振臨界速度與穩定性等諸多因素,并在飛行力學、空氣動力學、飛行控制原理等多學科耦合下尋求最優方案,因而設計方案需反復迭代以尋求折衷。高保真度(high-fidelity, HF)數據評估飛行器性能指標可有效減少設計迭代循環與修正,大幅提高設計能力。例如20 世紀,空客公司為了實現A310 的研制約進行了18 000 h 的風洞試驗[1],以保證飛行器的設計性能。
高昂的氣動數據獲取成本與高效的飛行器精確設計之間的矛盾迫使研究者尋求更高效的氣動力獲取手段。為加快高保真度數據的獲取時間,縮減設計周期,構建代理模型已然成為一種行之有效的技術途徑。代理模型是一類輸入到輸出的快速響應模型,又稱為響應面模型,具有數據驅動、自上而下的特點。多項式響應面法、支持向量機回歸(SVR)[2]、Kriging模型[3]、徑向基函數(RBF)[4]、人工神經網絡(ANN)等作為常用的代理模型被廣泛應用于計算量大、成本高的黑箱問題,以減輕計算負擔。針對上述問題,可通過直接構建代理模型的方法,使用一定數量的高保真度樣本預測出整個設計空間的高保真度響應面,緩解了數據獲取成本與建模效率之間的矛盾,但該類代理模型所需的高保真度樣本數量仍然很大,計算成本對建模精度的制約仍舊亟待解決。
在氣動領域,飛行、風洞試驗獲取的氣動數據精度高但成本高、周期長。一些CFD 數值方法(雷諾平均的N-S 方法、大渦模擬法等)也是獲取高保真度非線性流動氣動數據的常用手段。除此之外,還有一些高效率的低保真度(low-fidelity, LF)氣動求解方法,例如:速勢方程、Euler 方程等。低保真度數據雖精度不及,但可反映正確的趨勢信息。如何綜合利用多種精度數據,實現“少投入高回報”,以低代價低成本獲得高精度數據,是工程應用中關注的重點話題。2009 年,王文正等[5]針對該痛點已開展探索,提出基于數學模型的氣動力數據融合方法,初步驗證了數據融合的可行性。數據融合關聯方法可為多精度數據建模提供技術途徑。
數據融合關聯方法大致分為兩大類。一是直接交叉使用。該方法在工程問題中使用廣泛,高保真度數據直接使用,其余部分用低保真度數據補齊,但是直接交叉使用導致的間斷不連續問題極為致命。二是構建代理模型。作為預測程序的修正工具是代理模型的又一大用途,引入低保真度樣本輔助代理模型建模,僅需少量高保真度樣本即可實現更高的模型全局精度,從而達到數據融合的效果[6],這類代理模型又被稱之為變可信度模型(VFM)。
變可信度模型,又稱為“變復雜度模型”,其核心是綜合高保真度與低保真度的優勢,充分利用低保真度數據隱含信息,在有限的計算與時間成本下提供更為精確的預測結果,提高建模效率。目前構建VFM 的常用方法有:空間映射法、基于標度的變可信度法以及co-Kriging 方法。基于空間映射(space mapping, SM)的VFM 方法使用空間映射將高保真度數據的參數空間與低保真度數據的設計空間對應起來,通過改變低保真度的設計空間使不同保真度模型逼近。最早由Bandler 等[7]提出線性映射算法。基于標度的VFM 主要分為三類:乘法標度、加法標度和混合標度。基于乘法標度法的VFM,其高保真度模型和低保真度模型之間的比值可以用標度函數來表示[8]。基于加法標度法的VFM 具有更強的魯棒性和全局逼近性,因而使用更廣泛。基于混合標度法的VFM 融合了加法標度法與乘法標度法的優點,具有更高的預測精度。co-Kriging 模型是在Kriging 模型基礎上發展起來的,起初用于地質學領域,由Kennedy 和O'Hagan[9]提出。該模型能夠提供非試驗樣本點處的預估誤差,使其成為較有前景的VFM 方法。Forrester 等[10]首次將co-Kriging 模型應用于航空航天工程設計。2014 年,Le Gratiet 等[11]提出了co-Kriging 的遞歸公式。國內相關研究也有較多進展。2012 年,韓忠華提出分層Kriging 模型(hierarchical Kriging, HK)[12]。Yamazaki 等[13]將梯度信息引入co-Kriging 的建模過程,提出一種梯度增強的co-Kriging模型(gradient-enhanced co-Kriging, GECK)。黃禮鏗等[14]將co-Kriging 用于氣動優化設計當中,證明了該方法在工程設計優化中的可行性。2019 年,韓忠華等[15]將分層 Kriging 模型進行推廣,發展了一種多層Kriging 模型(multi-level hierarchical Kriging, MHK)從低到高遞歸式建立不同可信度的 Kriging 模型。
在有限計算成本下,VFM 的建模質量與采樣方式有極為密切的關系。通常采樣方法分為兩大類:一次性抽樣法和序貫采樣法[16]。常見的一次性抽樣有拉丁超立方體抽樣[17]、最鄰近抽樣法[18]等,該類方法的缺點是采樣點無法關聯函數自身特性。序貫采樣方法則是使用模型的迭代信息(例如最大預測誤差等)順次選擇樣本點位置。通過上一步模型或自身學習數據獲取樣本點,能更好地迎合目標函數的自身特性,從而用更少的點構建精準的全局模型,降低了建模數據的獲取成本。序貫采樣方法已得到廣泛發展,其中基于貝葉斯抽樣[19]、交叉驗證[20]等理論的貫序采樣方法均取得了較好的建模結果。當低保真度與高保真度數據的計算成本相近的情況下,VFM 序貫采樣建模類似于單保真度建模。
在采用序貫采樣的VFM 中需要依據樣本細化準則獲取新樣本,并迭代更新VFM 直到精度達標。目前已有的樣本細化準則方法有:最小化代理模型預測(MSP)[21]、改善期望(EI)[22]、改善概率(PI)[23]、均方差(MSE)和置信下界(LCB)[24]等。目前針對VFM的代理細化方法較少,通常將單可信度優化的樣本細化準則直接用于VFM 中[25]。Huang 等[26]于2006 年發展了一種適用于多層可信度模型優化的期望改善加點準則(augmented EI, AEI),通過最大化與計算成本相關的增廣期望改進函數,來選擇下一個樣本點的位置和保真度程度。Mehmani 等[27]提出了一種針對不同可信度分析模型的管理策略,其核心利用模型轉換在優化過程中合理地選擇不同的可信度模型。
可將衡量變可信度模型優劣的因素概括為:高可信度樣本數據量、變可信度模型的全局性以及預測精度三大類。由于模型預測的精確性與高精度樣本位置有強相關性,因此初始高保真度樣本的選擇以及序貫采樣中樣本細化準則的搭建尤為重要。
本文在co-Kriging 模型的基礎上,提出了一種新的高保真度樣本獲取方案,用于獲取高保真度樣本的設計實驗以及細化樣本。該方法通過從完備的低保真度響應面中提取“信息量”大的樣本作為高保真度的初始樣本,將目標算例的自身特性加入高精度樣本的試驗設計中,從而避免了均勻性隨機采樣帶來的隨機影響,提高了代理模型的全局性以及模型精度收斂效率。針對于高保真度樣本的細化,本文引入了一個距離項d,通過Kriging 基函數構造了一個距離函數D(x),與co-Kriging 模型預測誤差通過線性加和的方法耦合起來構成一個樣本細化的評價函數。評價函數值最大處為下一個新增高保真度樣本點,迭代更新模型。在給定的計算量下,該方法可以構造出一個精確的預測模型。
1 變可信度co-Kriging 融合方法
co-Kriging 融合方法是一種基于Bayesian 貝葉斯理論的自回歸模型,能有效考慮到多種可信度數據之間的關聯作用,利用交叉協方差衡量不同保真度之間的相關程度,融合不同精度的數據。同時co-Kriging 模型繼承Kriging 模型的優勢,可對預測點進行不確定性評估。該方法在小樣本、高非線性問題中具有明顯的優勢和較強的適用性。
該方法假設樣本對應的響應值來自一個隨機過程,將觀測到的響應值表示為一組隨機向量Y(x),其中x為樣本設計參數,y代表樣本響應值。隨機向量中的隨機變量之間的關聯作用由式(1)表示,其中cor代表樣本點之間的相關性,n表 示樣本個數,k表示設計參數維度, θj代 表設計參數x第j個分量的重要程度相關,參數pj與第j個分量的光滑性相關:

若當前樣本數據可分為低保真度(LF)以及高保真度(HF)兩類,則可用Ze(·)和Zc(·)分別表示高保真度和低保真度當地特征的一個高斯隨機過程,Zd(·)代表高低精度之間差量的高斯隨機過程。高保真度、低保真度之間存在如下關系:
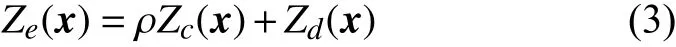


總結來說,式(10)可以看作對低保真度數據的回歸,并使得已知的函數值ye與在高保真度樣本點處的預測值一致。該模型均方誤差估計如式(12)表達,樣本點處的誤差是由d的特性決定的:
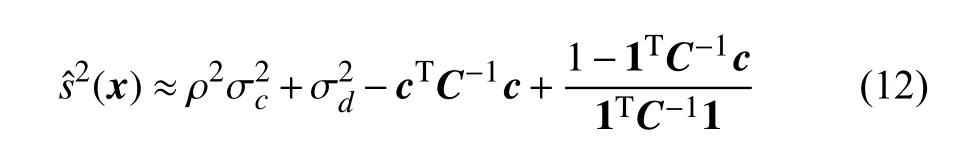
2 高效率建模設計
高可信度樣本數據量、變可信度的全局性與精度為衡量變可信度模型優劣的三大因素。為實現“少投入高回報”,以高效率低成本的方式獲得高精度數據,本文對基于co-Kriging 的變可信度融合模型構建流程進行介紹,并針對變可信度模型初始采樣以及高可信度樣本的序貫采樣提出了兩大方法,用以提升建模效率和精度。
2.1 最優關聯點選取方法
傳統采樣初始化方法難以結合樣本的空間信息,主要存在如下問題:1)空間均勻化為大多數采樣初始化方法的原則,該類方法的均勻性與隨機性會導致采樣點信息浪費。2)響應面強非線性時,局部極值信息不易捕捉,導致模型局部精度降低。因而本文提出了一種變可信度模型初始采樣新方法,通過對低保真度響應面的處理得到高保真度的初始采樣點,將該方法稱為最優關聯點選取方法。
由于各精度響應面之間大致趨勢相同,該方法的核心即用低保真度響應面的極值點逼近高保真度極值點,作為高保真度數據的初始采樣。由于加入自身算例特性,該方法采樣效率遠遠大于空間填充類方法。基于該方法,如何獲取低保真度響應面極值點成為問題的關鍵,本文提出了一種基于多目標優化的極值點獲取方法。使用基函數作為源點項,根據基函數構造響應面,進而用多目標算法尋優確定未知參量。該方法一定程度上也保證了初始采樣點的隨機性。其中,基函數的中心即尋優獲得的響應面的一個極值點:
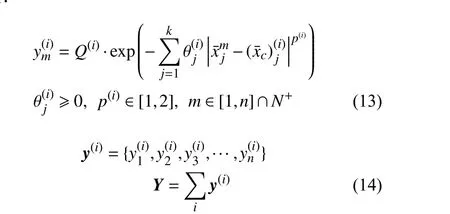
其中n表 示低保真度樣本量;k表示設計空間維度;Q(i)為第i次尋優基函數系數大小,即低保真度響應面的第i個極值大小,Q(i)正負性用來區分極大、極小值;p(i)為基函數光順參數;x為x歸 一化的值,xc表示基函數的中心坐標;Y表示i次優化后逼近的低保真度模型近似值。采用多目標算法尋優,將低保真度模型與基函數逼近模型之間的均方差(MSE)定義為目標函數進行優化。目標函數表達式如下:

2.2 均勻增強的高保真度樣本序貫采樣方法
如何找到“信息量”大的點是決定建模效率的又一大因素。目前最常用的加點準則是改善期望準則(EI)[22]。但是對于全局逼近代理模型而言,EI 準則適用性并不好。co-Kriging 模型可以提供基于均方差(MSE)的預測誤差,但當模型用于全局逼近問題時該做法仍存在一些不足之處:
1)co-Kriging 會出現“早熟”現象,往往該類局部區域周圍沒有高保真度樣本點的加入。
2)直接采用模型預測誤差細化樣本,有時會造成高保真度樣本的聚集而降低建模效率。
“早熟”現象即指該區域預測模型的不確定性較低,導致建模更新過程中沒有高保真度樣本加入,影響模型精度的進一步提高。針對上述問題,本文提出一種空間均勻增強的高保真度序貫采樣方法,通過引入距離項,在優化初采樣不均勻性的同時提高算法的穩定性與建模效率。
該方法改進了僅采用預測誤差作為加點準則的做法,通過構造一個距離函數D(x)表達出高保真度樣本的空間分布。構建距離函數D(x)采用高斯基函數,其表達式如下:
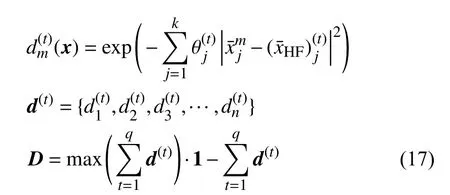
其中,q為 高保真度樣本點的總個數;xHF為高保真度樣本點的坐標; θ(t)是設定的衰減系數,與設計空間各維度尺度差異相關。
定義 Score(s2(x),D(x))為樣本細化方案的評價函數,其中s2(x)為co-Kriging 模型的預測誤差。評價函數將距離項D(x) 與模型預測誤差項s2(x)通過線性加和耦合起來,一般設定a=b=1。每次迭代建模選擇設計空間中最大S core(x)點作為新高保真度樣本點。
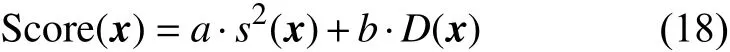
2.3 基于co-Kriging 變可信度融合建模框架流程
該方法通過試驗設計(如LHS)獲得低保真度的初始樣本Ic,并采用Kriging 迭代建模完成低保真度樣本預測,獲得低保真度樣本集Xc。根據低保真度預測響應面獲得高保真度的初始樣本集Ie,聯合低保真度樣本集Xc進行co-Kriging 建模。選擇評價函數Score(s2(x),D(x))最大處作為新的高保真度樣本加入Ie集合中,對模型進行迭代更新,直至模型精度達標。該方法的流程圖如圖1 所示,并給出詳細步驟。
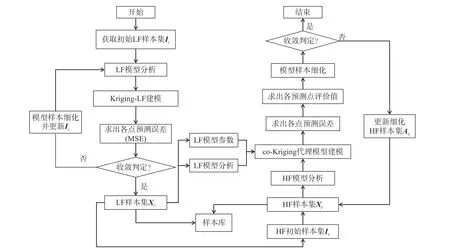
圖1 基于co-Kriging 模型的變可信度建模流程Fig. 1 Flow chat of the VFM framework based on co-Kriging
Step 1:生成初始低保真度樣本集Ic。
采用LHS 方法獲得初始低保真度樣本集Ic,并通過低保真度模型分析獲得響應值。低保真度模型分析一般采用簡化模型的數值仿真。針對初始樣本的數目的確定沒有具體定論。由于低保真度數據計算與時間成本低,且初始低保真度樣本少會導致Kriging建模的局部特性差,所以選用Jones 等[28]給出的經驗公式,其中,k為設計空間的維度,n為初始樣本數量:

Step 2:建模得到低保真度預測響應面。
獲得準確的低保真度預測響應面有兩個目的,一是生成均勻散布的低保真度樣本集Xc;二是使低保真度預測模型完備,為高保真度的初始采樣提供信息支撐。將Ic進行Kriging 建模。根據預測誤差式(7)得到細化的低保真度樣本點加入Ic中,通過如此循環迭代更新模型,構建一個完備的低保真度預測模型。
Step 3:生成低保真度樣本集Xc。
構建變精度模型需要Xc建 模得到相關參數 θc和pc等 。Xc即可通過上述低保真度預測模型獲得。不同的低保真度樣本集對建模穩定性以及模型收斂效率有一定影響,但該影響可忽略不計。
Step 4:獲得高保真度初始樣本集Ie。
根據最優關聯點選取方法,使用多目標優化算法對完備的低保真度預測響應面逼近,以低保真度預測響應面的極值處作為高保真度初始樣本。
Step 5:建立基于co-Kriging 的變精度模型。
對獲得的Xc以 及高保真度樣本集Xe進行基于co-Kriging 的VFM 建模,得出狀態空間各點的預測值與預測誤差。其中,Xe為 高保真度初始樣本集Ie和細化高保真度樣本集Ae的并集。
Step 6:求出變精度模型細化的高保真度樣本。
根據式(18)選擇設計空間中 Score(x)最大處作為下一個高保真度樣本點,并加入細化高保真度樣本集Ae中。隨著高保真度樣本的增加,可通過式(18)對a、b常數項進行調整。
Step 7:判斷模型的收斂性。
代理模型優化和數據融合的收斂判定往往沒有固定方案。依照經驗,模型的收斂可劃分為三個階段:第一階段,模型的收斂速率大,收斂精度呈指數下降;第二階段,模型收斂速率逐漸降低,收斂精度可能會出現振蕩下降;第三階段,模型已基本收斂,該階段模型精度變化不大,無法換來大于模型迭代成本的收斂增益。第一、第二階段可能會混淆,之間沒有清晰的分界線。
該模型的預測誤差無法跨算例對比。收斂條件可綜合當前迭代步的最大預測誤差以及模型更新過程最大的平均預測誤差得出。若模型滿足收斂判定,則可輸出最終預測模型。若模型此時不滿足收斂判定,則用高保真度分析獲得新細化的高保真度樣本的真實響應,并返回Step 5 循環,直至滿足收斂判定條件。
3 算例驗證與討論
本節使用數值算例來驗證該方法的有效性,將該方法與單精度序列元建模進行對比,并給出了基于采樣的高效率建模設計相對于傳統初采樣方法的優勢。最后將基于co-Kriging 模型的高效變可信度模型算法成功應用于實際氣動算例當中。算例采用均方根誤差(root mean square error, RMSE)作為度量精度的指標。RMSE 的表達式如下:


3.1 一維數值算例
一維算例選用Forrester 函數數[10],是Forrester 等在2007 年重構得來,常用于多精度模型與單精度模型的對比。高保真度函數fh(x)與 低保真度函數fl(x)的數學表達式為:
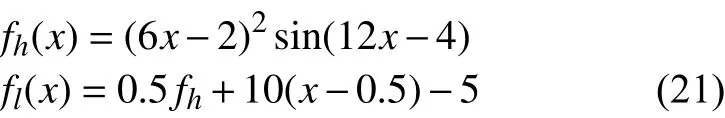
其中x∈[0,1]、 NumHF=3、a=b=1。低保真度樣本點與Forrester(2007)[10]中設置相同為:
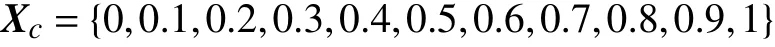
圖2(a)為僅用4 個高保真度樣本時,Forrester 等建模結果[10]與本文建模結果的對比圖。圖2(b)則是兩者的預測誤差對比圖。在其他條件不變的情況下,二者均加入了4 個高保真度樣本作為修正,其中黑色正方形為文獻中所給出的點,藍色三角形為本文采樣方法獲取的高保真度樣本。可對比看出,本文方法所得的高保真度樣本可以使VFM 建模預測誤差下降1~2 個數量級,大大提高了VFM 的建模精度。

圖2 Forrester 函數建模結果對比Fig. 2 Comparison of the modeling results for Forrester function
3.2 二維數值算例
3.2.1 算例介紹

高保真度與低保真度函數響應面圖3(a)所示。
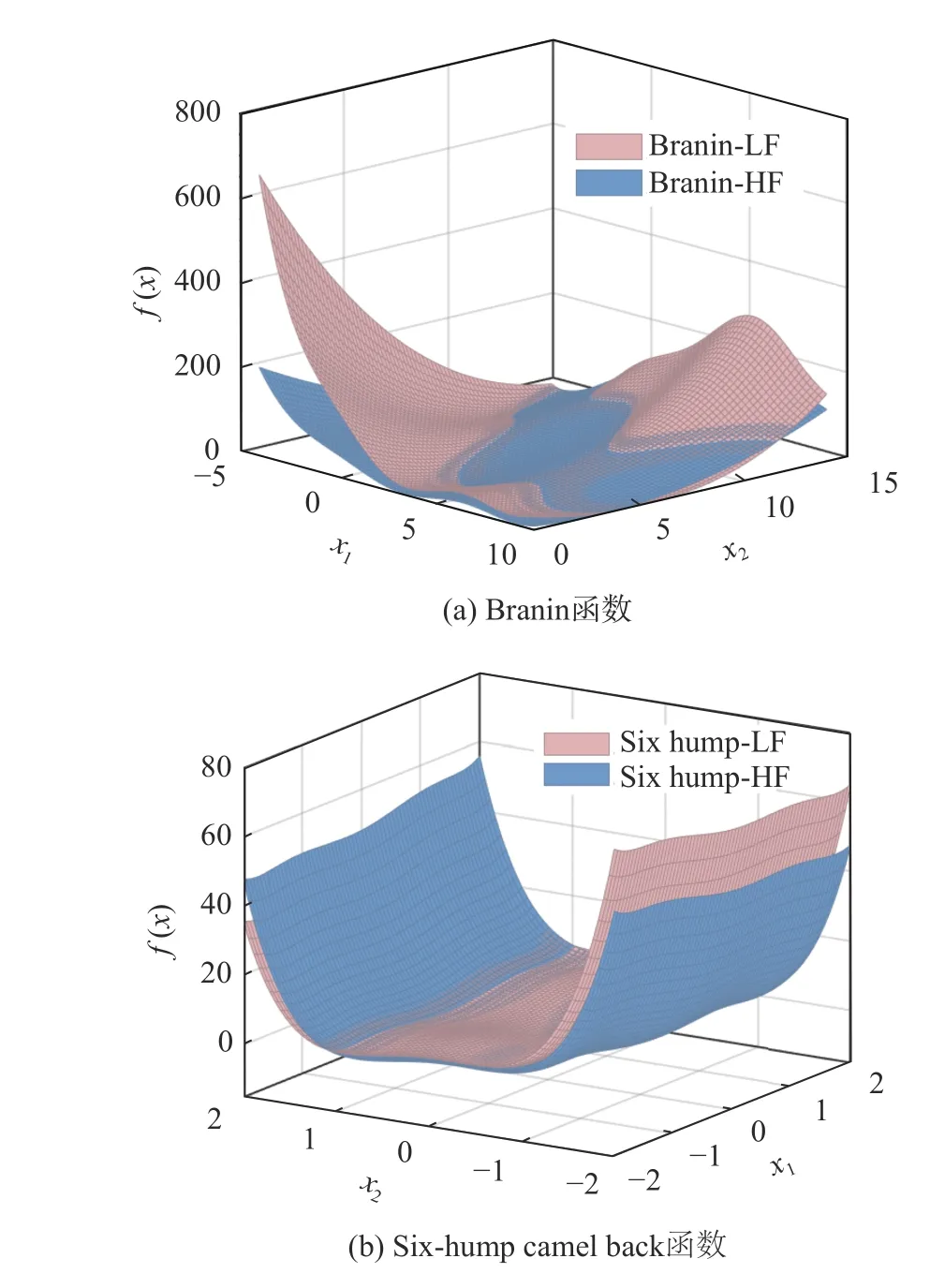
圖3 二維數值算例不同保真度數據差異對比Fig. 3 Comparison of two-dimensional numerical cases with different fidelity data
2) Six-hump camel back 函 數。Six-hump camel back 函數又稱為六駝峰背函數,其非線性程度相較于Branin 函數有所提高。該函數在有界區域內共有6 個局部極小值,其中2 個為全局極小值。其高保真度函數fh(x1,x2)與 低保真度函數fl(x1,x2)的數學表達式如下給出,其中up (x2) 和low (x2) 分別為設計變量x2的上下界:
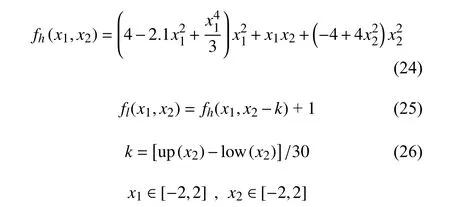
3.2.2 建模結果與分析
上述兩個數值算例的低保真度樣本數相同。根據式(16),co-Kriging 建模高保真度數據初始采樣個數為 N umHF=7 , 且設置參數a=b=1。
Branins 函數和Six-hump camel back 函數算例分別使用25 個、17 個高保真度樣本即可滿足收斂精度要求,所提出VFM 的預測值與函數真值的平均相對誤差均小于2%。從圖4 看出,在本文提出的高效VFM 算法始終遠優于DACE 工具箱的Kriging 方法[29]。由于DACE 工具箱的尋優不太徹底,故將本文所提的高效VFM 算法與自研的單精度序列元建模的Kriging 也進行了對比,VFM 迭代前期的建模精度遠大于其余兩種,且優勢隨著高保真度樣本點數的增多而逐漸消退,該點也符合VFM 建模的特點。對于Six-hump camel back 函數算例,單精度序列元建模至少需要比該算法多一倍以上的高保真度樣本數,才能達到相同的建模精度效果。
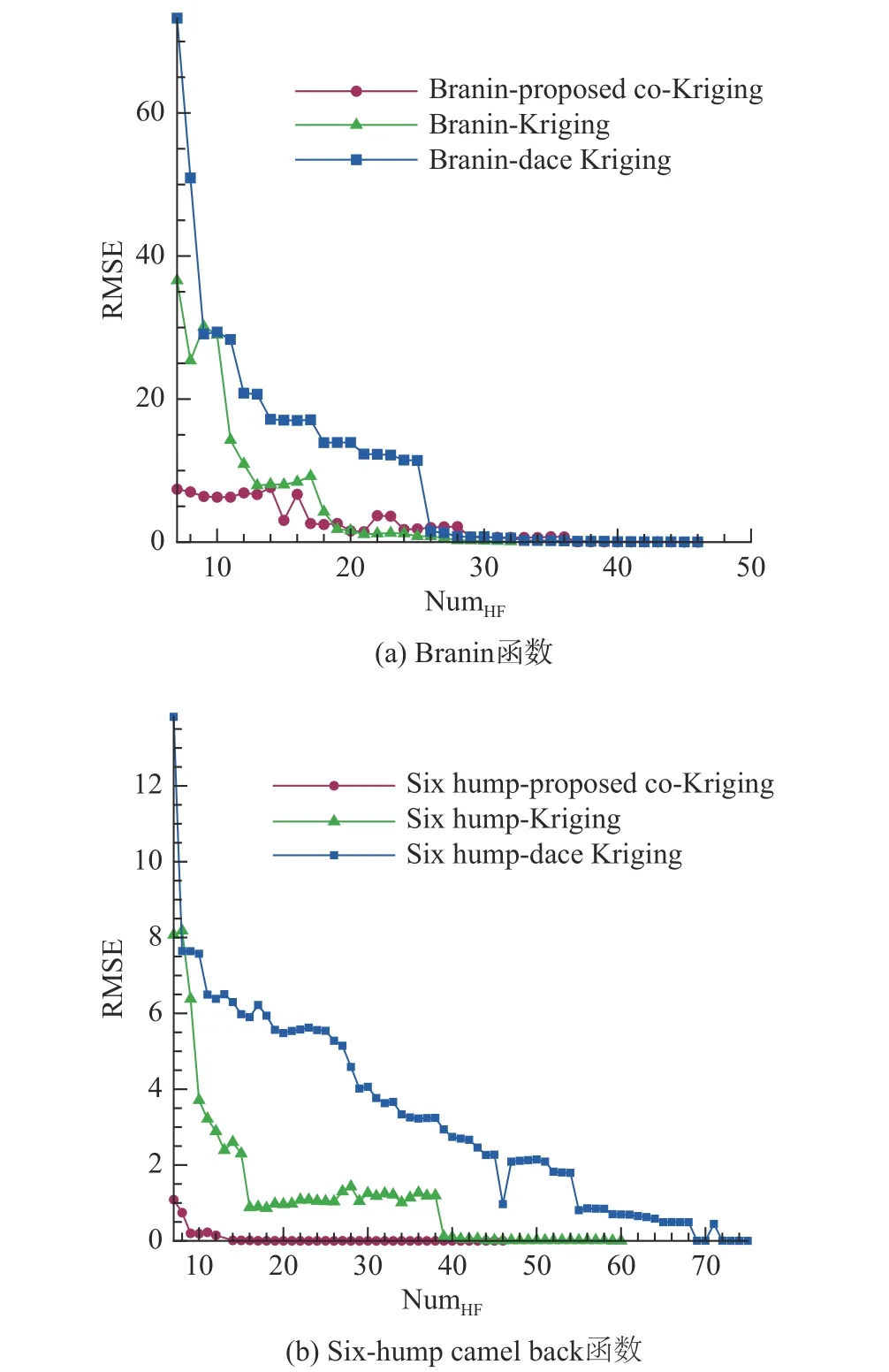
圖4 二維數值算例不同建模方法RMSE 對比Fig. 4 RMSE comparison among different modeling methods for two-dimensional numerical cases
3.2.3 最優關聯選點方法優勢性與適用性
在兩個數值算例中,分別采用最優關聯選點方法與拉丁超立方采樣(LHS)獲取初始高精度樣本進行融合建模,并使用RMSE 指標進行對比。由于LHS 具有隨機性,所以根據式(16)確定初始樣本數后,用LHS 生成100 個初始樣本集,并分別求解變可信度融合模型建模結果。變可信度融合模型的初始低精度樣本集保持相同,以控制變量。用箱線圖來表示出該統計性結果,如圖5 所示。其中,曲線表示100 次LHS 所得初始樣本集建模RMSE 的正態分布。將最優關聯選點方法變可信度融合模型建模得到的RMSE 用黑色星號標出。可對比看出,兩個算例最優關聯選點方法RMSE 均遠低于LHS 方法RMSE的均值和中位數,明顯體現出該方法的優勢。
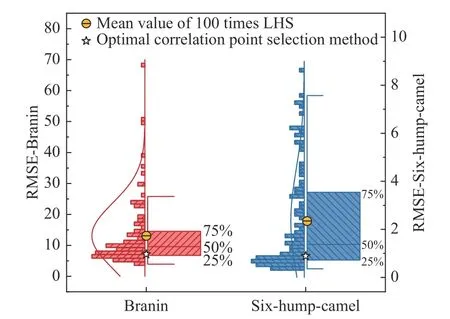
圖5 不同算例LHS 與最優關聯選法RMSE 箱線圖對比Fig. 5 Comparison of RMSE in boxplot between LHS and optimal correlation selection method for different cases
3.3 NACA0012 跨聲速氣動力系數建模
將高效采樣的變可信度數據融合建模方法應用于NACA0012 翼型變馬赫數變攻角的跨聲速氣動力系數建模。采用精度不同的CFD 數值計算方法,計算二維翼型的氣動力系數:升力系數(CL)、阻力系數(CD)以 及 俯 仰 力 矩 系 數(Cm) 。在Ma∈[0.5,0.8],α∈[0,5]設計空間內,使用盡可能少的高保真度樣本,得到高精度的氣動模型。
3.3.1 CFD 計算方法與求解器驗證
CFD 為計算流體力學的簡稱,是一種利用計算機求解得到流場數值模擬的技術。Euler 法能夠捕捉CL的非線性特點和CD相對于攻角的多項式行為等,揭示許多現象的本質特征。N-S 方程是迄今為止描述連續介質最完備的控制方程組。在本研究中,Euler 法將提供氣動力系數的趨勢信息,即提供“廉價數據”,而N-S 法將作為修正數據。求解N-S 方程采用雙時間推進法,實時間采用二階精度向后差分,偽時間則采用隱式Gauss-Seidel 迭代。因為本文針對的主要是跨聲速下翼型在非定常流場中的運動,因此選擇了能夠較好描述流動分離的S-A 模型[30]。CFD求解所用的網格如圖6 所示。
圖6 不同CFD 求解器所用的網格Fig. 6 Meshes for different CFD solvers
3.3.2 變可信度融合模型的建立
NACA0012 翼型在設計空間內存在抖振邊界[31],如圖7 所示,本算例中設置模型每個預測點都位于抖振邊界以內。確定低保真度模型的設計實驗樣本數為20,建模時需要對三種氣動力系數分別建模。由于CD、Cm的非線性程度較高,即低保真度模型收斂時Ic集 合樣本較多,因此可用構建CD(或Cm)低保真度模型時的低保真度樣本點構建其余兩個氣動力系數的低精度模型并進行收斂判定,若不滿足可繼續細化更新模型。該做法可有效減少建模所需的計算成本。
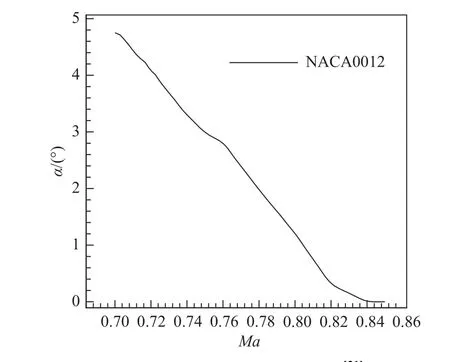
圖7 NACA0012 翼型抖振邊界[31]Fig. 7 Buffet boundary of the NACA0012 airfoil[31]
低保真度樣本集Xc為設計空間抖振邊界內的均勻網格點。初始采樣個數 NumHF=7。圖8(a~c)給出CL、CD、Cm的低保真度預測響應面以及最優關聯點選取方法獲取的樣本信息。圖8(d)給出三種氣動力系數分別建模時初始高精度樣本點的對比,其中虛線代表抖振邊界。
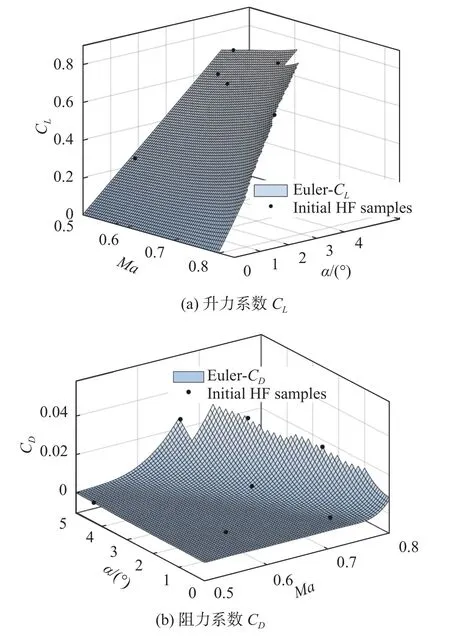
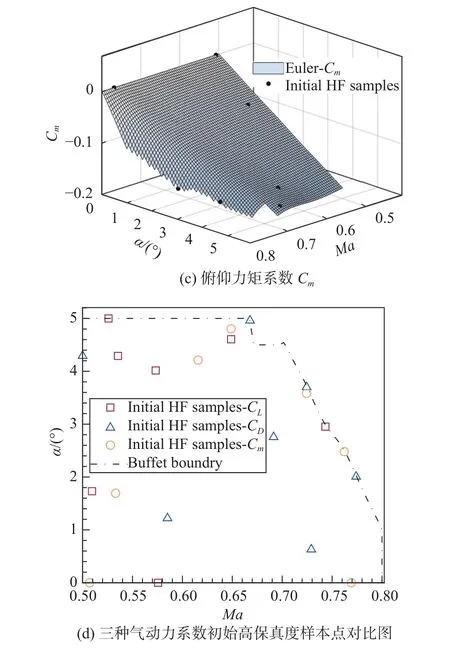
圖8 三種氣動力系數低保真度預測響應面以及高保真度初始樣本的位置信息Fig. 8 Response surface predicted by LF model and the position information of the HF initial samples for the three aerodynamic force coefficients
3.3.3 建模結果與分析
三種氣動力系數的預測響應面以及建模所用的高保真度樣本點位置如圖9 所示。
通過LHS 采樣獲得30 個高保真度樣本作為測試集來進行co-Kriging 變可信度融合模型精度驗證。圖9(d)給出測試集在設計空間內的分布情況。將測試集的樣本點的高保真度響應值與求出的預測值進行對比。為減小氣動力接近零值對誤差統計帶來的影響,定義相對平均誤差為:
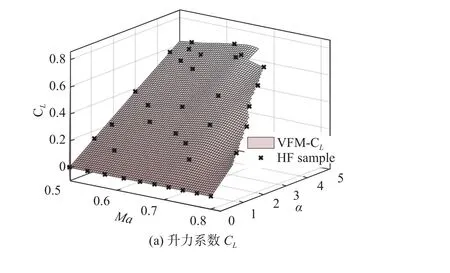
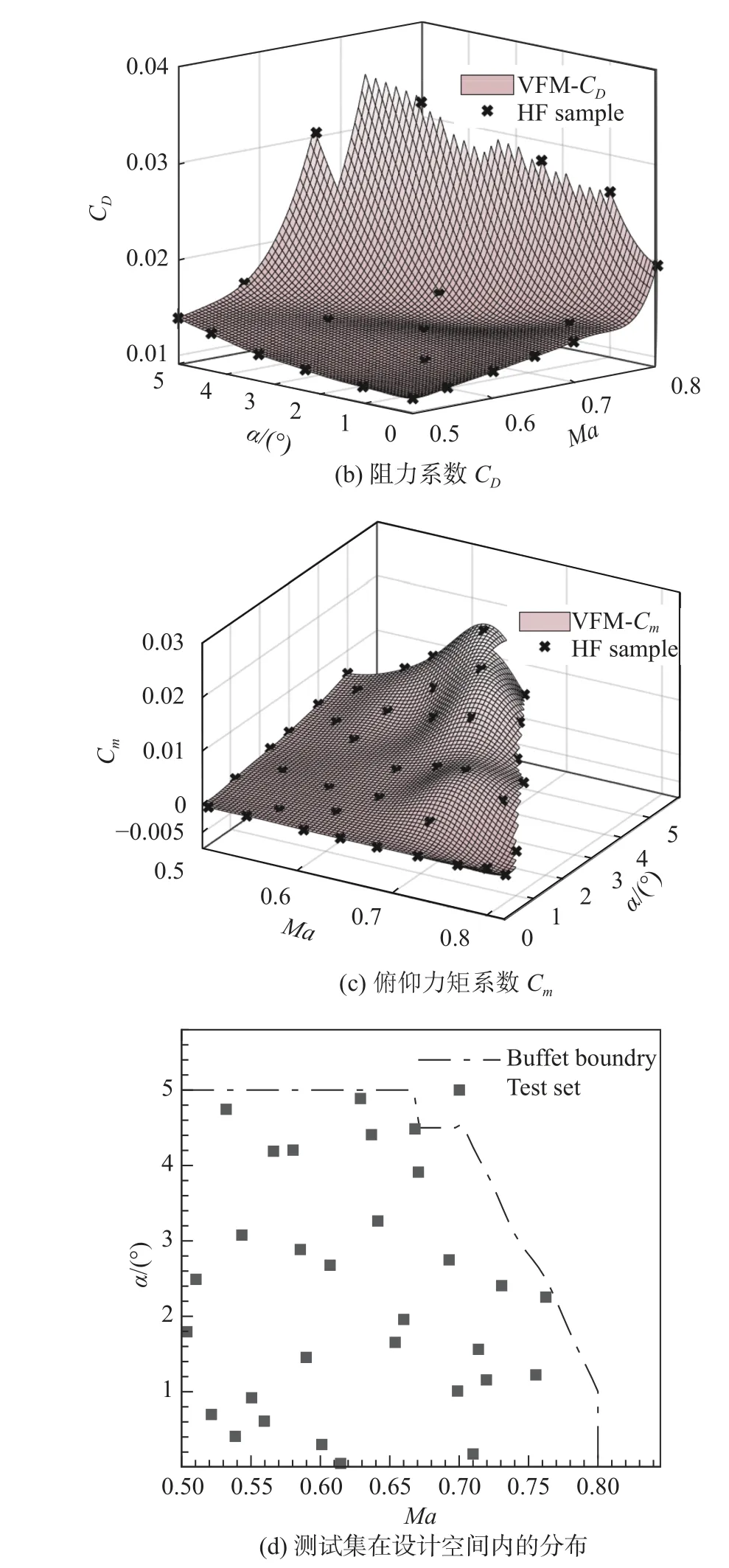
圖9 氣動力系數變可信度數據融合后的預測響應面以及高保真度樣本點位置Fig. 9 Response surface and HF samples after the variablefidelity data fusion
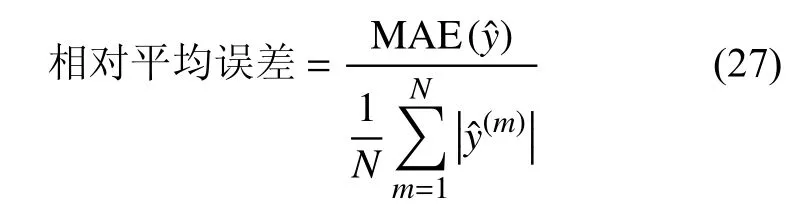
其中,y?(m)為 第m個預測點的預測值,N代表驗證集樣本數量, M AE(y?)為驗證集樣本的平均絕對誤差。
表1 給出了測試集真實值與預測值之間均方差(RMSE)、平均絕對誤差(MAE)以及相對平均誤差的對比。由表1 可以看出,三種氣動力均達到很好的融合效果,其中CL、CD預測值與真實值之間的相對平均誤差均小于3%。基于高效采樣的變可信度關聯融合氣動力建模在實際工程問題中可以達到很好的建模效果。
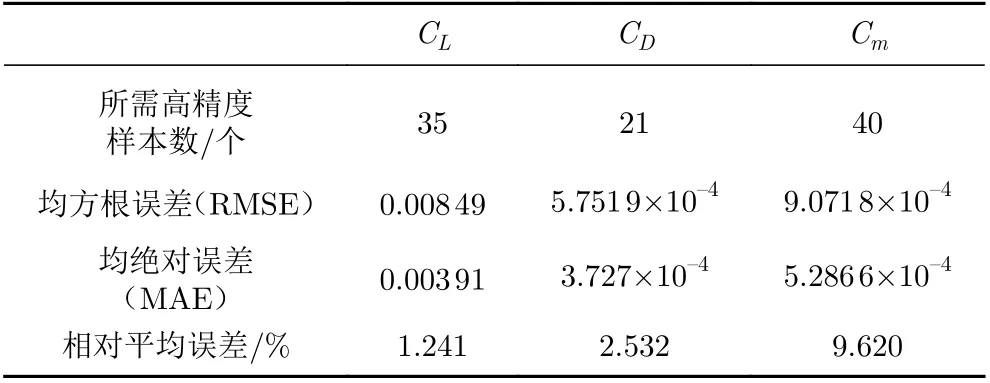
表1 測試集真實值與預測值之間誤差對比Table 1 Comparison between the true and predicted values of the test set
4 結 論
本文提出了一種用于變可信度模型的最優關聯點選取方法,并對變可信度模型的加點準則進行了討論與改進,解決了下述兩個問題: 1)如何確定變可信度模型高精度初始樣本點,使其建模精度與模型收斂速度優于通常采用的LHS? 2)如何確定每次迭代更新的模型細化樣本?在所提出的樣本初始化方法中,基于最優關聯采樣方法約束了高精度初始樣本的分布,在保證VFM 建模效率下降低了空間均勻化采樣帶來的強隨機性,增強了融合模型的融合效率。本文還對VFM 樣本細化方法進行了分析,加入距離項D(x), 通過線性加和的方法與模型預測誤差項s2(x)耦合,構建新的評價函數,提升了模型的全局性。通過三個數值算例說明了模型的優勢,同時給出最優關聯點選取方法與LHS 初采樣對比的統計結果。主要結論如下:
1)最優關聯點選取方法對于一般非線性強的響應面建模(強周期性的響應面除外),優勢性明顯;
2)基于co-Kriging 的VFM 的建模精度與高保真度與低保真度樣本的相關程度有關,關聯度越高,VFM 建模效率越高;
3)VFM 的建模優勢在高保真度樣本很少時體現明顯,隨著高保真度樣本數的增加,VFM 相對于單精度序列元建模的優勢逐漸變弱。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
