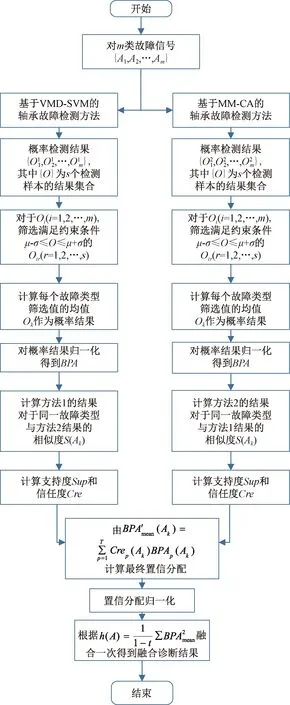
基于改進的數據融合滾動軸承故障診斷
2022-11-08 12:26:22齊詠生高勝利李永亭
鐵道學報 2022年10期
齊詠生,白 宇,高勝利,李永亭
(1.內蒙古工業大學 電力學院,內蒙古 呼和浩特 010080;2.內蒙古北方龍源風力發電有限責任公司,內蒙古 呼和浩特 010050)
車輪設備的滾動軸承是使用最廣泛的零部件之一,也是故障高發部件之一。在旋轉機械設備中,滾動軸承承擔著設備的全部重量,并且長時間的旋轉工作使軸承的磨損程度大幅度增加。據統計,在機械設備故障中,有30%的故障是由滾動軸承引起的。在車輪運轉過程中,軸承一旦發生故障,輕則造成財產損失,重則威脅公共安全,因此實現對滾動軸承的自動故障診斷具有重大意義。
20世紀80年代,振動信號開始被應用到故障診斷中,直到現在對振動信號進行分析與處理仍是當前對滾動軸承進行故障診斷應用最多的一種技術。旋轉機械振動信號往往呈現非線性、非平穩的特性,對這種非平穩信號的局部化信息提取通常采取時頻分析[1-2]方法。在20世紀90年代末,文獻[3] 提出經驗模態分解(EMD)方法,這是目前使用較廣泛的一種將非平穩信號分解為多個模態并轉化為平穩信號的分析方法。在此基礎上,又演變出聚合經驗模態分解(EEMD)[4],變分模態分解(VMD)[5]方法。此外,還產生了諸如小波分析、峭度分析、數學形態學分析等方法。文獻[6] 使用EMD分解原始信號并提取其分量信號自回歸模型參數和能量參數作為信號特征,結合支持向量機(SVM)對軸承故障進行分析,并取得了一定效果。但是,EMD方法存在端點效應、模態混疊、計算量大等問題。EEMD方法是在EMD方法的基礎上對分析信號加入白噪聲的一種改進方法,之前的研究中也曾采用EEMD方法提取故障信號特征,結合核熵成分分析(KECA)對滾動軸承進行故障診斷,并取得了一定的效果[4]。但是EEMD方法迭代次數較多,計算量大,降低了算法的效率。VMD是近幾年新興的一種信號分析方法,該方法計算速度快,不同頻率的信號分量分解準確,文獻[7] 詳細論證了VMD在信號處理領域的優越性。文獻[8] 使用數學形態學(MM)方法在時域中處理信號,提取故障特征,從而完成軸承的故障診斷,并取得了較好的效果。然而,上述方法均為單一故障診斷算法,每種算法都有各自的優缺點,而單一算法不能實現優勢互補,難免會產生受噪聲干擾大、誤診率高、可靠性差等缺陷。
針對這一問題,本文提出一種基于數據融合的機械軸承復合診斷算法。該算法采用雙通道并行診斷,通道1采用VMD對原始振動信號進行模態分解,提取各模態的特征組成特征向量作為SVM的輸入進行故障分類,使用貝葉斯準則[9]將分類結果映射為概率形式完成類型識別;通道2采用數學形態學對原始信號進行濾波處理,將處理后的信號特征轉化為頻域形式,并通過相關性分析對比頻譜完成故障類型的識別。最后使用改進加權證據理論將以上兩通道分類結果進行數據融合,得到更為可靠的故障診斷結果。在眾多數據融合方法中,證據理論是一種能夠突出目標、降低干擾的融合算法。因此,以證據理論為基礎并加以改進,非常適合最后的數據融合工作。融合結果也表明,該方法將VMD-SVM的分類結果準確度高的優點與MM-CA方法具有更強“泛化能力”的優點有效結合,很大程度上提升了旋轉機械滾動軸承故障診斷的準確性和可靠性。
1 數據融合混合診斷算法
1.1 基于VMD-SVM的軸承故障診斷算法
圖1為VMD-SVM故障診斷算法的流程。圖1中左半部分表示待檢測未知類型故障信號;右半部分為對m類故障信號建立分類器的操作流程。
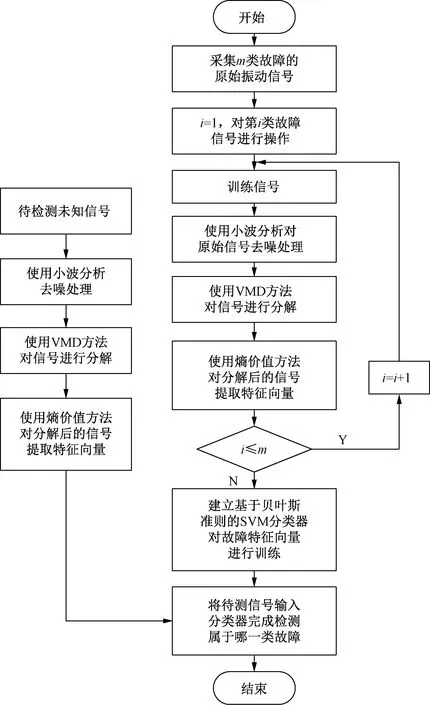
圖1 基于VMD-SVM的診斷方法流程
算法具體步驟如下:
Step1使用振動信號采集裝置采集m類故障軸承的振動信號,每類故障信號包含n個樣本。
Step2用小波變換對原始信號進行去噪,最大限度降低模態分解后的干擾。
Step3將去噪后的信號進行VMD分解,得到一系列模態分量IMFs。對其中各IMF求其能量E(IMF)、能量熵HEN和熵價值V[10]。對IMFs進行篩選,舍去其中熵價值較低且顯著偏離其他熵價值的模態。例如,將0.177 8 mm內圈故障信號按頻率成分可分解為4個IMF,使用熵價值法計算4個模態熵價值分別為-1 822.17、-1 832.41、-1 815.27、-1 940.38。顯然,模態4對應的熵價值最小,且顯著偏離其他熵價值較多,因此舍掉模態4。實際上,熵價值越大,IMF中包含的故障信息就越多;而且從另一個方面分析可知,由于模態4主要代表信號的高頻成分,通常包含較多噪聲,不利于作為特征向量,因此也需要剔除。
Step4求篩選后的IMFs重構信號的能量熵HEN,并與之前計算的各IMF的能量Ei,組合為復合特征向量T=[E1E2…EnHEN]。
Step5分別對m類故障的振動信號進行Step1~Step4得到m類型的故障特征向量。將得到的故障特征向量作為SVM分類器的輸入訓練數據,構建“一種類型與其他類型”的一對多分類器,構建數量與故障類型個數相同。
Step6采集待檢測的振動信號,將振動信號采用Step1~Step5相同的技術處理后得到特征向量T1。
Step7將特征向量T1作為SVM分類器的檢測數據輸入,得到分類結果。將分類結果使用貝葉斯估計[9]映射為概率模型,給出判別結果。
這種方法本質上是在頻域中提取信號特征,其優點是檢測速度快、計算量小,能夠較好檢測出已訓練過的故障類型,分類清晰且干擾性小。但是該方法存在泛化能力弱的缺點,即對于同類型不同損傷等級的故障樣本如果沒有參加訓練,檢測結果可能會失效。
1.2 基于MM-CA的軸承故障診斷算法
圖2所示為MM-CA算法[11]的流程,算法包含兩部分,左半部分為訓練建模過程,對已知m類故障數據進行訓練和建模;右半部分為算法應用過程,對待測信號進行故障識別和診斷。
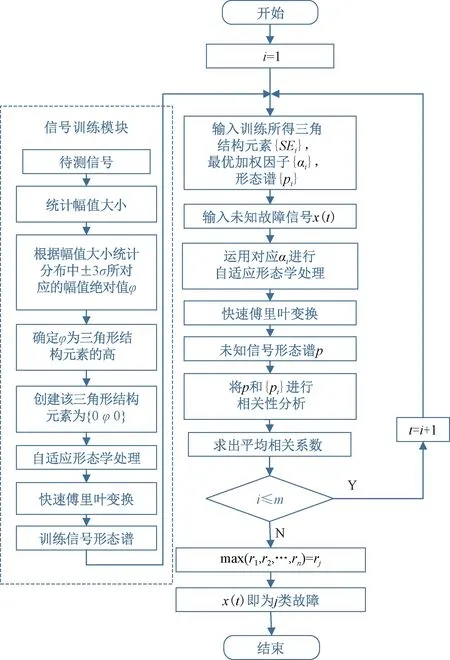
圖2 基于MM-CA的診斷方法流程
該算法具體實施步驟如下:
Step1根據目前已知的軸承故障類型將訓練信號分成m類,每一類包含n個訓練樣本信號。分別組成信號集合{xi,j}(i=1,2,…,m;j=1,2,…,n)。計算每個信號的標準差σ,根據設高為±3σ的三角形結構元素創建方法,計算出各類已知信號所對應的三角形結構元素SEi(i=1,2,…,m)。
Step2確定相對應故障信號自適應加權{αi}(i=1,2,…,m),采用自適應開閉運算和結構元素SEi對信號集合{xi}進行處理,以提取信號集合{xi}的特征信息。
Step3釆用快速傅里葉變換對處理后的信號集合{xi}(i=1,2,…,m)進行變換得到與之對應的自適應形態頻譜集{pi}(i=1,2,…,m)。
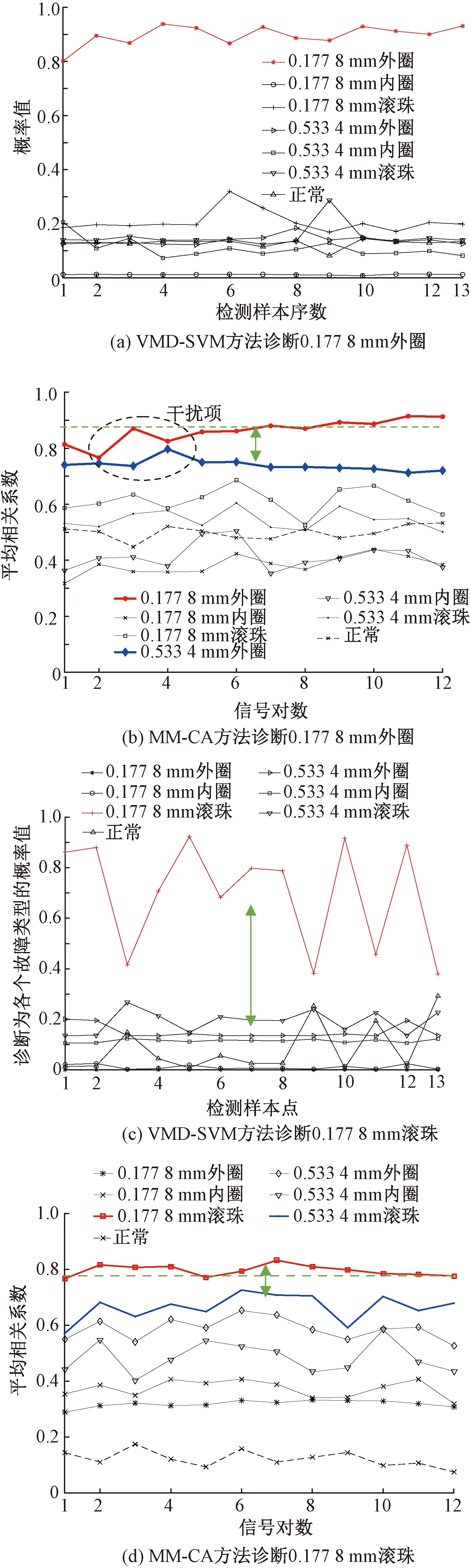
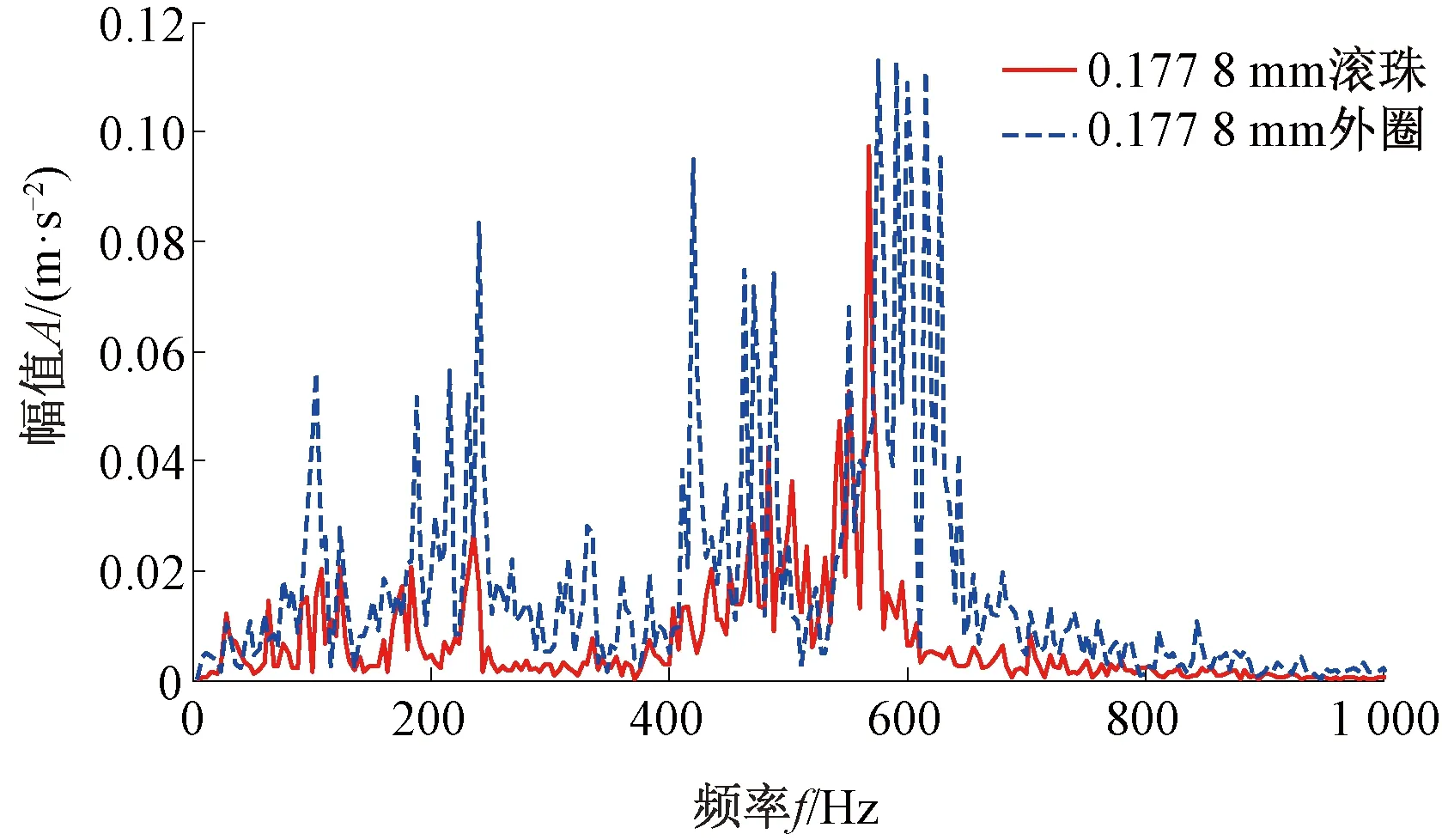
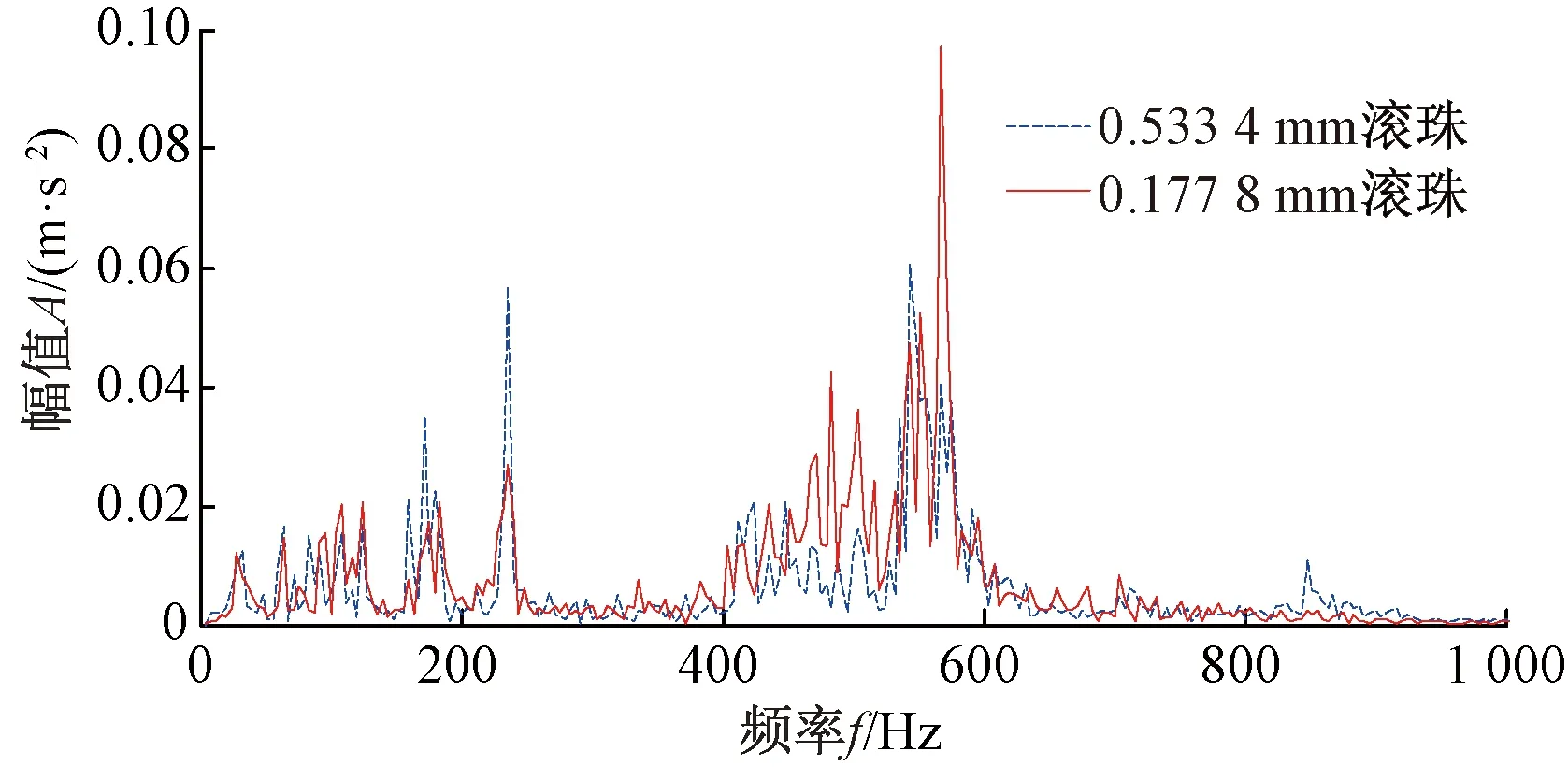
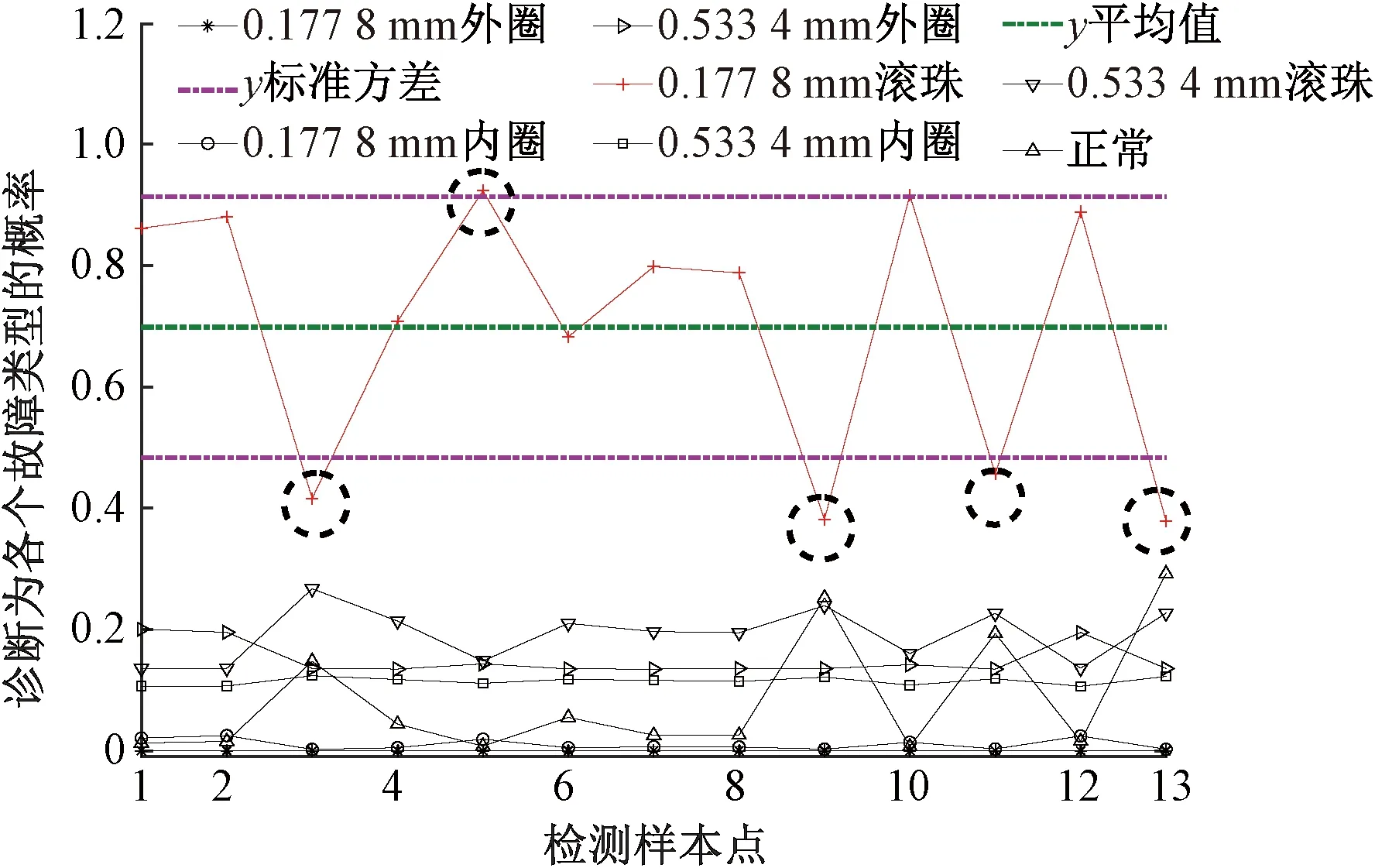
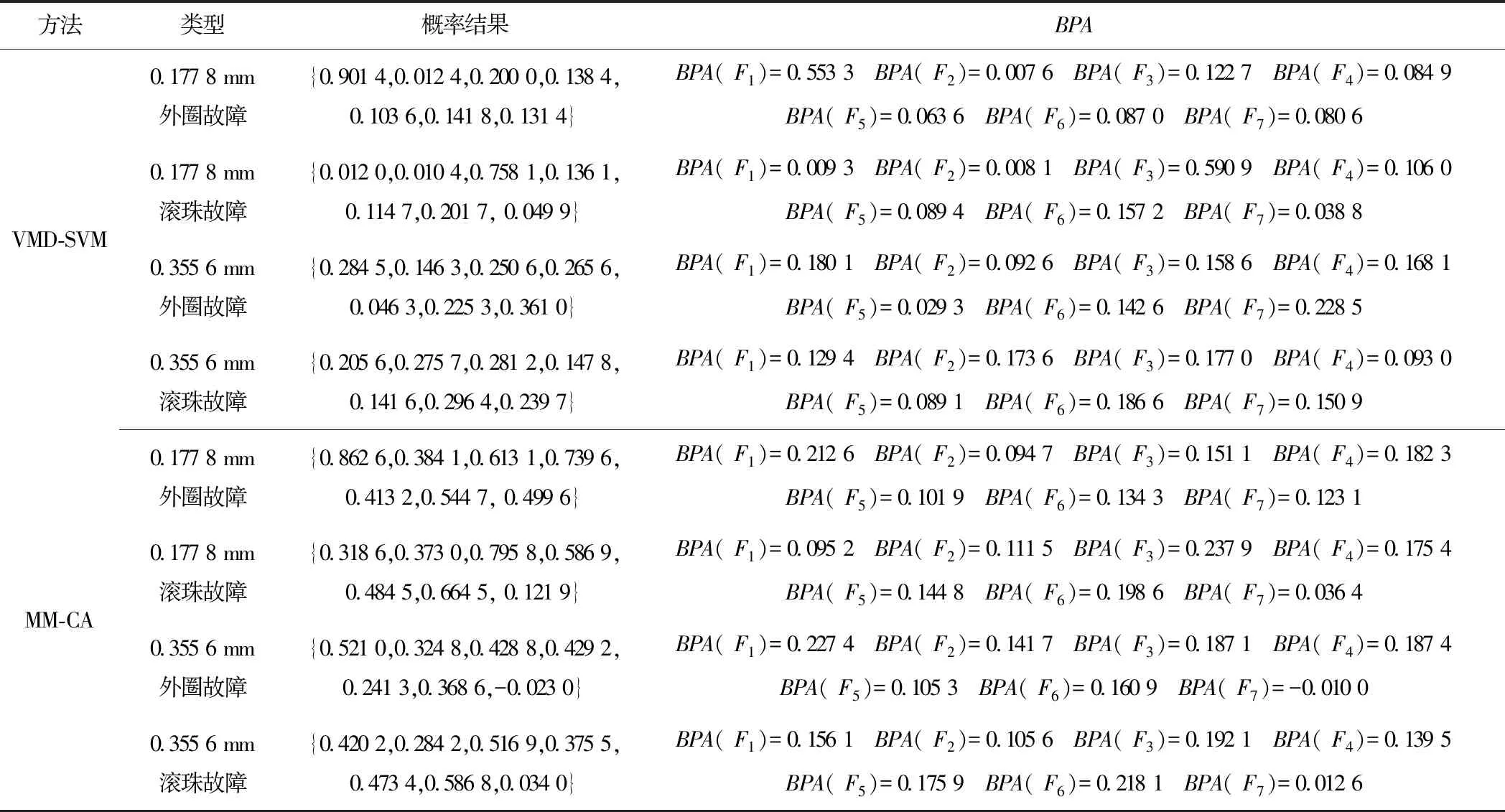
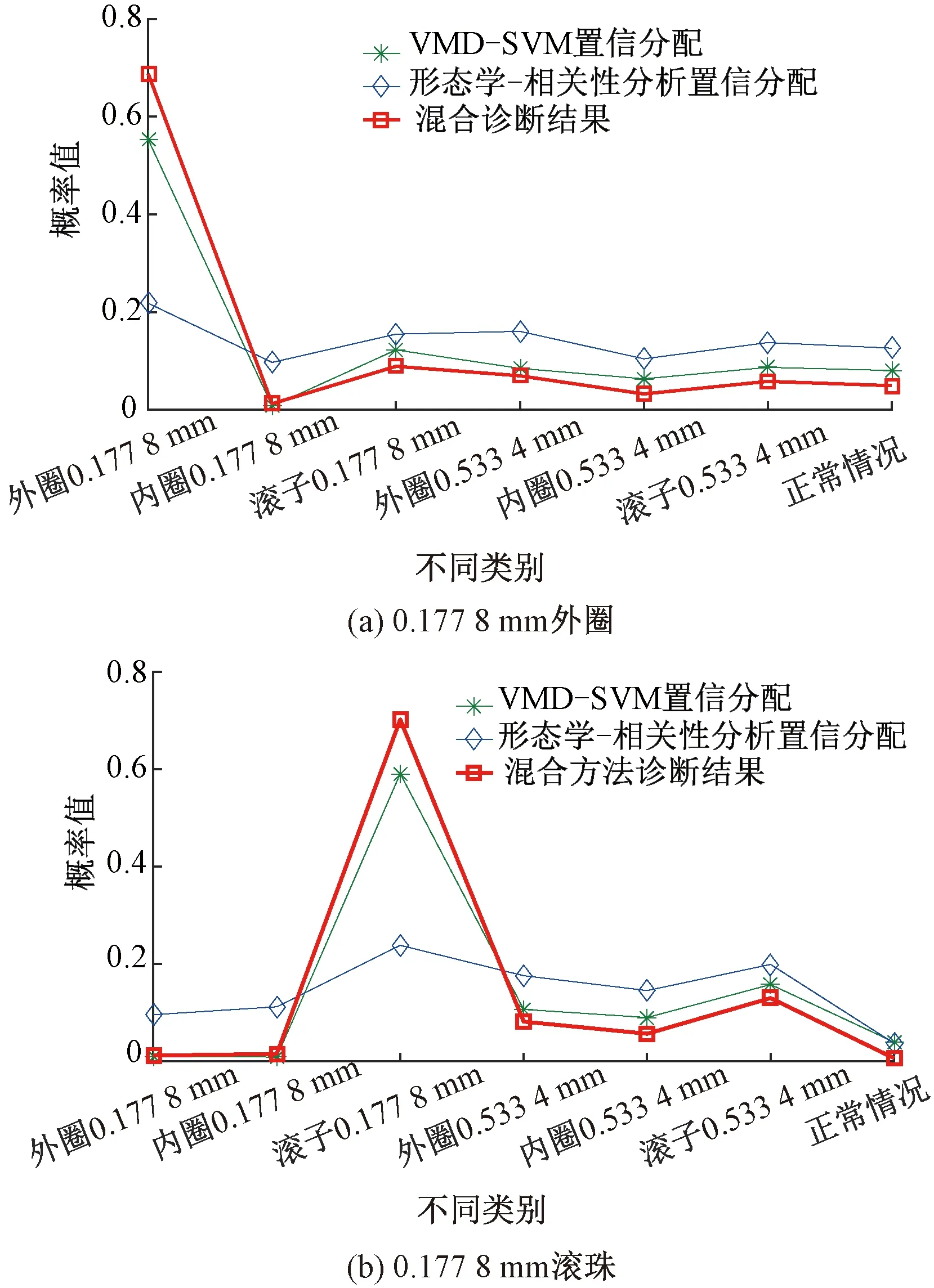
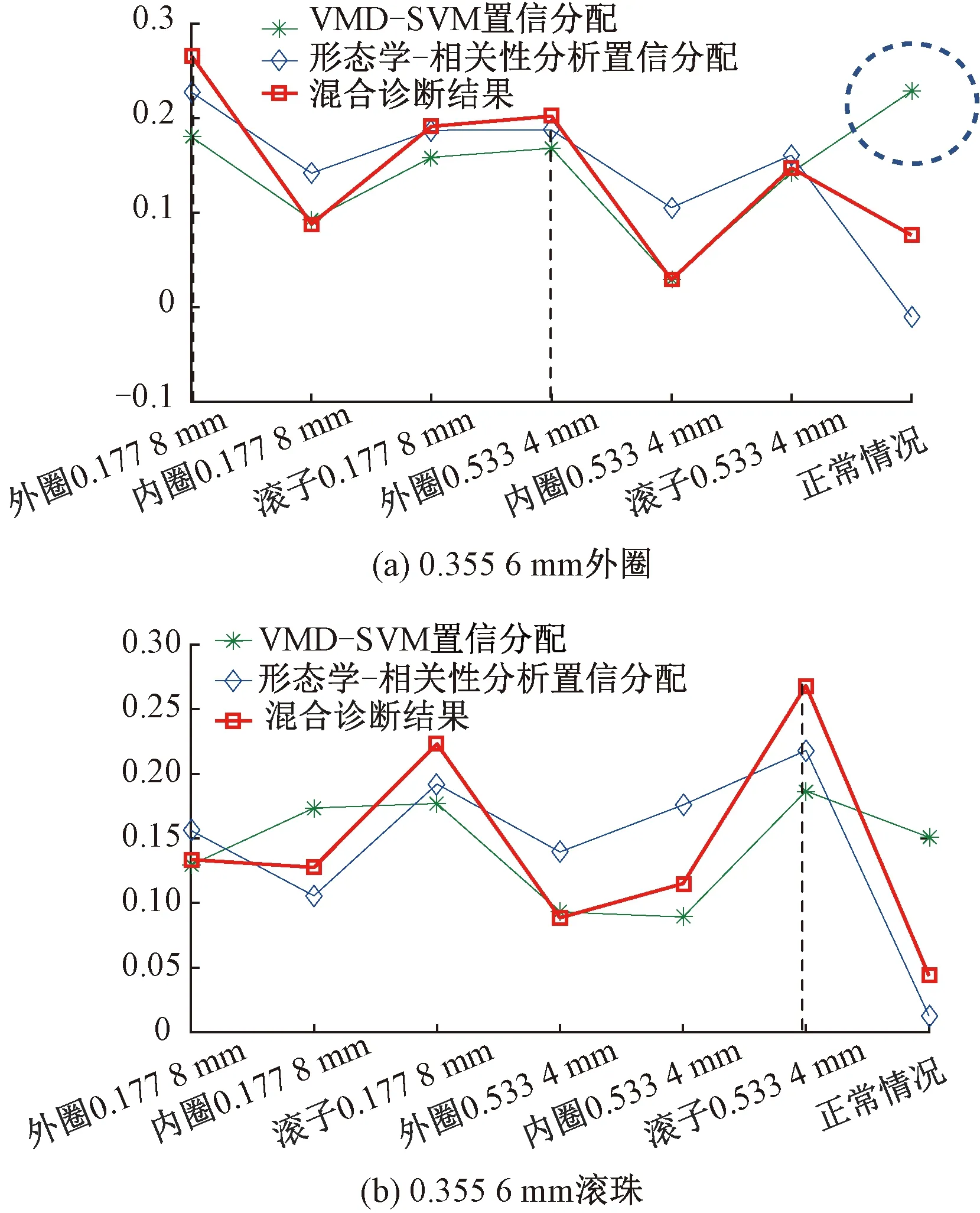
Step4對于未知故障狀態的軸承信號x(t),分別采用由訓練預處理得到的三角形結構元素SEi(i=1,2,…,m)和對應故障信號自適應加權系數{αi}(i=1,2,…,m),對其進行形態學處理以提取該信號的特征,通過傅里葉變換得到該信號的自適應形態頻譜p。分別計算待測信號的自適應形態頻譜p和訓練預處理的自適應形態頻譜集{pi}之間的平均相關系數ri。假設r1到rm中最大的一個為rs(0 MM-CA算法本質上是在時域中提取信號特征,在檢測故障效果上該方法計算量較小,運行速度較快,檢測效果較好。這種方法還具有一個明顯的優點,即具有較強的泛化能力。當同種類型不同損傷等級的故障樣本未參加訓練時,該方法也能準確檢測出其故障類型。但是其優點也是影響其檢測效果的缺點,由于其泛化能力強,造成檢測的精確度不夠高,受噪聲影響較大,檢測結果中往往存在干擾項。 證據理論(DS)[12-14]作為一種信息融合的方法在各行各業已經進行了廣泛的研究并得到了一定的應用,但是如果樣本本身存在較大問題時,DS證據理論在處理沖突時也會出現失效的情況。當一個證據的置信分配為0時,融合的結果會發生徹底否定該證據的可能。當證據的置信分配發生微小變化時,DS證據理論的融合結果會出現較大變動。為了克服DS證據理論的這些缺點,近年來很多專家都致力于改進DS證據理論方法的研究,其中對所有證據的置信分配進行加權平均是一種效果較好又應用廣泛的處理方法[15-17],這種方法可以很好的處理證據的沖突問題。在數據融合之前,為了得到更可靠的證據輸入,與常規加權證據理論相比,本文在證據理論的輸入端加以改進,首先用標準差法篩選證據結果,計算篩選結果的平均值作為證據輸入,通過這種改進可以剔除極端證據情況的發生,得到更穩定的輸入。其次,為了避免由于一個0分配置信證據導致融合結果全盤否定的現象發生,本文提出當出現0置信分配時,為該置信分配賦值0.01,同時將最大的置信分配減去0.01。 具體實施方法如下: Step1對兩種算法分別選取s個檢測信號進行檢測,并計算兩種方法檢測概率結果的均值與標準差{μ1,σ1,μ2,σ2},按照約束條件μ-σ≤Or≤μ+σ,r=1,2,…,s,篩選每個檢測信號的診斷結果,剔除極端值。計算滿足條件值的均值Ok作為算法概率形式的故障診斷結果。 Step2將兩種算法概率形式的故障診斷結果,按照式( 1 )歸一化。 ( 1 ) 式中:Ok表示診斷為各類故障類型的概率輸出;BPA(k)為各類故障的置信分配,k代表總數為m個故障類型中的一個。初步得到各類故障的置信分配(BPA值)。 Step3設所有故障類型集合為{A1,A2,…,Am},對于同一種故障類型兩種算法的判斷結果h1(Ak)和h2(Ak),相似度計算式為 ( 2 ) 式中:hp(Ak)、hq(Ak)為不同算法診斷同一故障時的BPA值;p、q為不同種方法,pq。 Step4利用相似度分別計算兩種算法對應同一類故障Ep(Ak)的支持度Supp(Ak)和信任度Crep(Ak)。 ( 3 ) ( 4 ) Step5以信任度Crep(A)為權值對兩種算法針對同一類故障的證據的置信分配進行加權,并應用到所有故障類型當中。歸一化之后得到最終的置信分配,計算式為 ( 5 ) ( 6 ) 式( 5 )用于權值修正,式( 6 )用于歸一化。將得到的新的置信分配BPAmean按照DS證據理論的規則自身融合T-1次得到最終診斷結果。本文選取T=2,即新的置信分配自身融合一次得到最終結果。原DS證據理論融合規則計算式為 ( 7 ) ( 8 ) 圖3為本文提出的基于數據融合診斷算法的總體流程。該數據融合算法首先將m類故障的原始振動信號劃分為等長的數據段,將同類型的所有數據段組成一個故障樣本Ak,k=1,2,…,m,所有樣本構成樣本集{A1,A2,…,Am}。將該樣本集分為兩部分,訓練集和檢測集。使用1.1節和1.2節兩種算法,并依據訓練集和檢測集得到各自的m類故障類型的概率形式診斷結果。最后使用加權證據理論完成數據融合,得到最終的融合診斷結果。 圖3 基于數據融合的混合診斷算法流程 該融合算法依據自身特點,弱化沖突證據,增強相容證據,使互補的兩種算法診斷結果相互融合,提高了軸承故障診斷結果的準確性和可靠性。 為了驗證本文所提出方法的有效性,本文采用美國Case Western Reserve University(CWRU)軸承數據中心數據,該實驗中心通過電火花技術在軸承上加工單點故障,軸承類型為SKF6205,用加速度傳感器測量軸承振動信號,數據中包含了不同條件的多組數據,這里選擇負載為3 HP(約2 200 W)、轉速為1 730 r/min、采樣頻率為12 000 Hz的軸承驅動端振動信號進行仿真驗證。所用數據對應的軸承運行狀態包括正常、內圈故障、外圈故障以及滾動體故障4種類型,每種故障類型又包含3種不同損傷程度的故障,即損傷直徑為0.177 8、0.355 6、0.533 4 mm。本文所選故障數據與大多數文獻中所選數據基本相同。這樣選擇有兩個目的:①易于算法比較;②這些數據相對診斷難度較大,能夠更好地體現出算法的有效性。 圖4 不同方法故障結果 兩種單一方法均使用0.177 8 mm軸承故障數據與采用0.533 4 mm軸承故障數據作為訓練數據,構建故障特征庫。不同方法診斷故障結果見圖4。由圖4(a)、圖4(c)可知,使用VMD-SVM方法對機械軸承進行故障診斷效果良好,診斷結果無交叉點,即不存在誤診斷結果。由圖4(b)、圖4(d)可知,使用MM-CA方法對機械軸承進行故障診斷,診斷結果存在干擾項,診斷結果并不理想。通過對比圖4(a)、圖4(b),圖4(c)、圖4(d)可知,VMD-SVM方法的目標樣本與其他樣本的間隔較大,即干擾較小。MM-CA方法的目標樣本與其他樣本的間隔較小,存在干擾項。 下面采用未經過訓練的樣本0.355 6 mm外圈故障和0.355 6 mm滾珠故障對兩種單一診斷算法進行測試。 如圖5所示,VMD-SVM方法對于未參與訓練的0.355 6 mm外圈故障(圖5(a))和0.355 6 mm滾珠故障(圖5(b))沒有識別能力,均給出了錯誤結果。表明該方法雖然對訓練過的故障類型數據抗干擾能力強、準確度高,但對未參與訓練的同種故障不同損傷程度數據無法實現有效檢測。 圖5 VMD-SVM方法診斷故障結果 如圖6所示,MM-CA方法對于未參與訓練的0.355 6 mm外圈故障和0.355 6 mm滾珠故障樣本雖然不能檢測出具體的損傷等級,但均能正確識別出發生的故障類型。圖6(a)最高和次高的檢測概率曲線顯示,該方法可以檢測出0.355 6 mm外圈故障類型屬于外圈故障,并且該損傷等級更接近0.177 8 mm。同理,圖6(b)最高和次高的檢測概率曲線顯示,該方法可以檢測出0.355 6 mm滾珠故障類型為滾珠故障,并且該損傷等級更接近0.533 4 mm。分析可知,當匹配樣本中沒有與測試樣本同種類型同種損傷程度的樣本時,算法就會匹配最相似的樣本,即匹配同類型不同損傷程度的樣本,實現故障類型的有效檢測。上述實驗表明MM-CA方法具有較強的泛化能力。 圖6 MM-CA方法診斷故障結果 進一步分析原因,使用數學形態學處理0.177 8 mm滾珠故障和0.177 8 mm外圈故障后,對比其頻譜,如圖7所示。在相同損傷等級,不同類型故障條件下,兩種故障信號的頻譜幾乎完全不同。圖8所示為損傷等級為0.177 8 mm和0.533 4 mm的滾珠故障頻譜對比。由圖8可知,二者屬于同種故障類型,故障特征頻率理論值是相同的,因此在頻譜圖中大部分頻率是重疊的,尤其是中頻和低頻段,其頻譜相似性保證了MM-CA方法具有較強的泛化能力。這也是MM-CA方法能夠區分不同故障與相同故障不同損傷程度的主要原因。 圖7 0.177 8 mm滾珠與0.177 8 mm外圈故障頻譜對比 圖8 0.177 8 mm與0.533 4 mm滾珠故障頻譜對比 在數據融合算法中,采用并行通道對故障進行初步診斷。對于通道1(AVMD-SVM故障診斷方法)和通道2(MM-CA故障診斷方法)的初步診斷結果,首先采用標準差法對診斷結果進行篩選。以AVMD-SVM診斷0.177 8 mm滾珠故障為例,如圖9所示。首先計算最高判別線0.177 8 mm滾珠故障判別結果的標準差,在均值μ±標準差σ范圍外的點為極端判別點,為了避免極端情況對概率結果產生影響,將這些點舍去,計算剩下點的平均概率值作為判別0.177 8 mm滾珠故障的最終概率結果。其他判別線均使用這種方法,得到全部概率判別結果。將兩種方法的故障診斷概率結果歸一化,得到初步置信分配。表1所示為VMD-SVM、MM-CA方法的概率平均值診斷結果以及置信分配。表1概率診斷結果均按照 “0.177 8 mm外圈(F1)”、“0.177 8 mm內圈(F2)”、“0.177 8 mm滾珠(F3)”、“0.533 4 mm外圈(F4)”、“0.533 4 mm內圈(F5)”、“0.533 4 mm滾珠(F6)”、“正常情況(F7)”順序排序。 圖9 標準差法篩選0.177 8 mm滾珠故障判別結果的點 表1 不同方法診斷結果及基本概率置信分配 如圖10所示,將MM-CA方法的診斷結果歸一化后,其存在干擾項的缺點很明顯表現出來,診斷的目標類型結果并沒有非常突出的高于其他類型診斷結果。結合VMD-SVM診斷結果抗干擾強的優點,經過加權證據理論融合后的診斷結果可知,目標故障的診斷概率明顯上升,高于任何一種單一診斷方法的概率結果,而其他故障類型診斷概率被降低。充分體現了VMD-SVM方法能夠彌補MM-CA方法準確度不夠高的問題,表明了融合算法的優勢。從復合診斷效果圖中可以看到該方法對參與訓練的樣本,具有突出故障目標、降低干擾、增強故障診斷結果可靠性的優點。 圖10 數據融合算法故障的診斷結果 數據融合算法故障的診斷結果如圖11所示。由圖11(a)可見,單一VMD-SVM方法無法判斷0.355 6 mm外圈故障的正確故障類型,并且將該類型判斷為正常數據的概率最高。而MM-CA方法可以正確診斷故障,其泛化能力可以彌補VMD-SVM方法的不足,數據融合方法判斷0.355 6 mm外圈故障最接近于0.177 8 mm外圈故障,次接近于0.533 4 mm外圈故障。綜合看融合算法的判別結果,突出了判別為0.177 8 mm外圈的概率結果,平滑了診斷為其他故障類型的概率結果。實現優勢互補,完成了軸承故障類型的判別,增強了診斷可靠性。 圖11 數據融合算法故障的診斷結果 由圖11(b)可見,數據融合算法的判斷結果表明0.355 6 mm滾珠故障更接近于0.533 4 mm滾珠故障,次接近于0.177 8 mm滾珠故障,給出了正確的故障類型判別結果。除此之外,兩種滾珠故障的概率均得到了突出,其他干擾故障類型的可能性被降低和平滑。綜合來看,當診斷未參與訓練的不同損傷程度故障數據時,數據融合算法實現了正確診斷故障類型的目的,體現出了較強的泛化能力和突出故障目標、降低干擾的能力。 針對機械滾動軸承中的單一故障診斷方法存在干擾大、訓練樣本不完備而導致誤診率較高、可靠性較差等問題,提出一種基于數據融合的復合故障診斷算法。該方法使用改進加權證據理論融合兩種不同特點的單一算法的診斷結果,綜合了VMD-SVM方法對于已訓練樣本診斷準確度高、抗干擾強的優點和MM-CA方法具有較強泛化能力的優勢,實現了復合算法優勢互補,從而提高診斷算法可靠性的目的,具有一定的工程應用價值。1.3 加權平均證據理論以及融合診斷算法
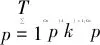
2 實驗驗證
2.1 單一方法診斷效果
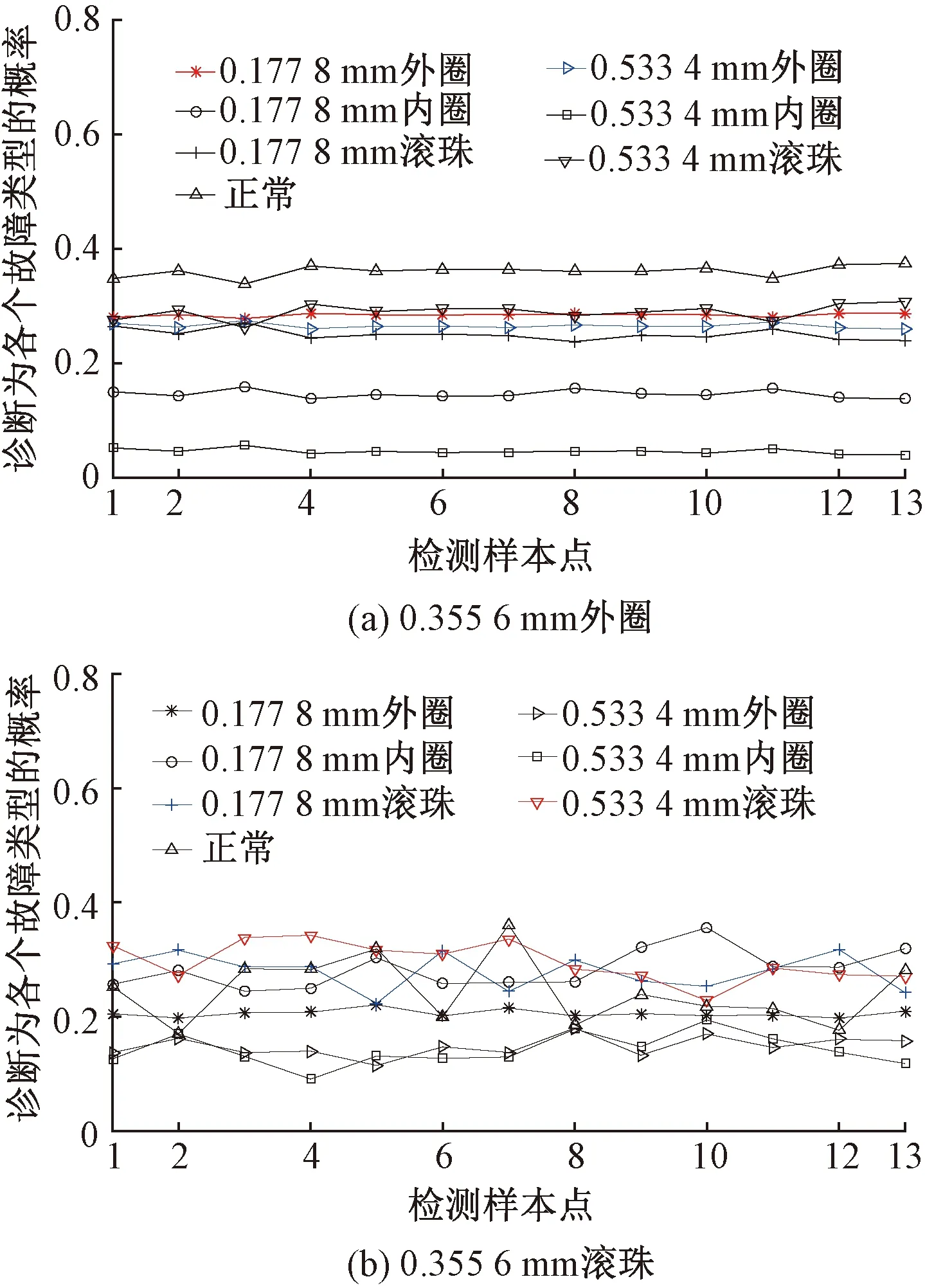
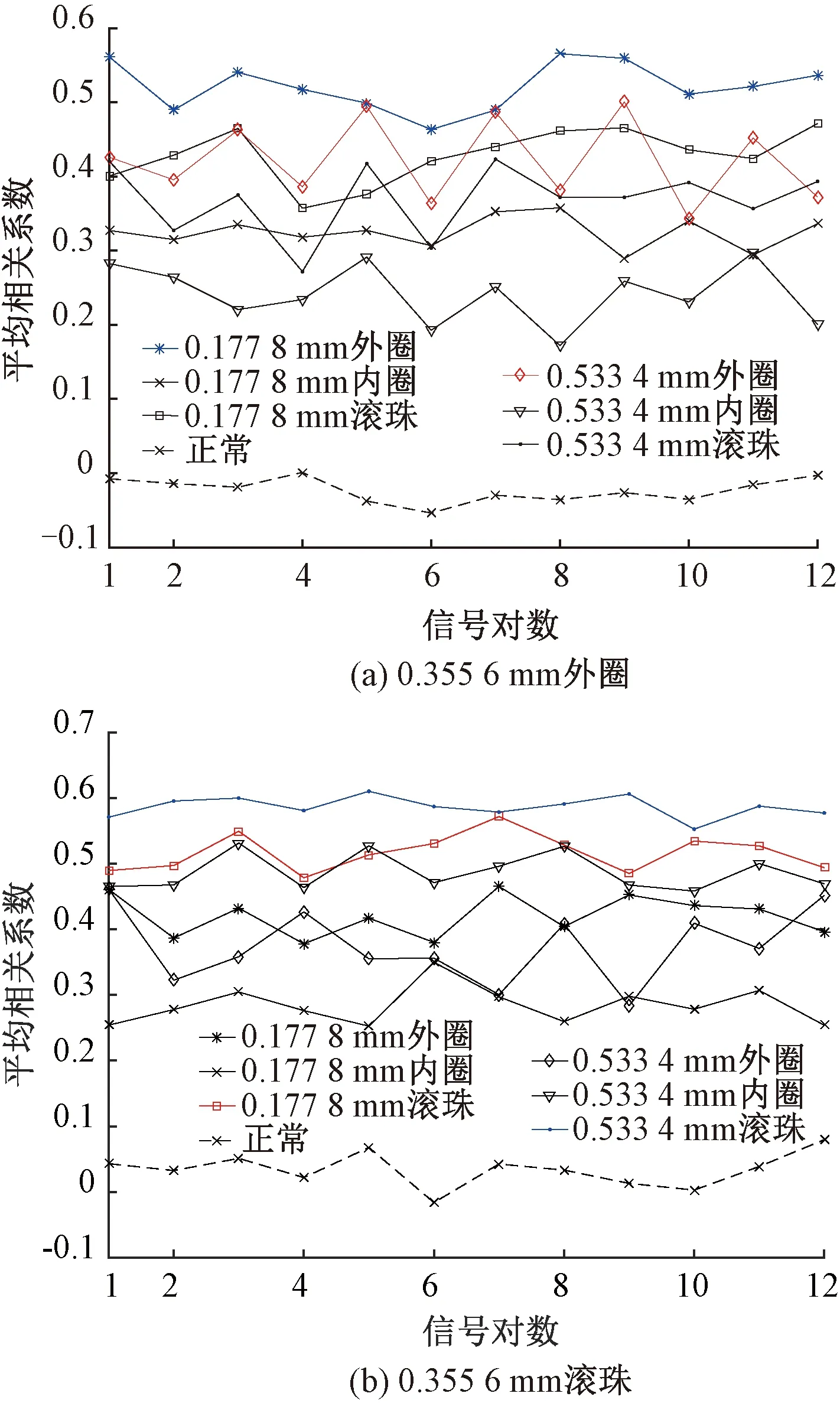
2.2 基于數據融合的復合方法診斷效果
3 結論
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
汽車維修與保養(2019年7期)2020-01-06 03:30:42
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
