基于視覺語義關(guān)聯(lián)的卷煙零售終端文字識(shí)別
2022-10-24 04:48:32韋泰丞譚穎韜
無線電工程 2022年10期
韋泰丞,譚穎韜
(1.廣西中煙工業(yè)有限責(zé)任公司,廣西 南寧 530001;2.中國(guó)科學(xué)院自動(dòng)化研究所,北京 100190)
0 引言
隨著互聯(lián)網(wǎng)技術(shù)的發(fā)展以及具備拍照功能的移動(dòng)終端的普及,各種終端所拍攝自然場(chǎng)景的圖片往往包含一定的文字內(nèi)容。不同于一般的視覺元素,文字直接承載了豐富而準(zhǔn)確的高層語義信息,有著極強(qiáng)的場(chǎng)景表達(dá)力。因此,自動(dòng)檢測(cè)和識(shí)別圖片中的文字具有很廣泛的應(yīng)用場(chǎng)景,例如店招識(shí)別、車牌識(shí)別和單據(jù)閱讀等。光學(xué)字符識(shí)別(Optical Character Recognition,OCR)和場(chǎng)景文字識(shí)別(Scene Text Recognition,STR)技術(shù),即從圖像中檢測(cè)與識(shí)別文字信息,已成為計(jì)算機(jī)視覺、文檔分析等領(lǐng)域的熱點(diǎn)研究方向,得到了來自學(xué)術(shù)界與工業(yè)界的強(qiáng)烈關(guān)注。
在煙草行業(yè),零售終端店招名稱以及煙草專賣零售許可證的文字信息是店鋪信息采集的重要內(nèi)容。傳統(tǒng)的信息采集多以人工為主,耗時(shí)費(fèi)力,并且容易出現(xiàn)差錯(cuò),亟需建立智能化的終端文字信息采集系統(tǒng)。然而,傳統(tǒng)的OCR技術(shù)無法解決復(fù)雜場(chǎng)景下的文字識(shí)別問題。針對(duì)實(shí)際場(chǎng)景中的文字識(shí)別難點(diǎn),本文提出了一種基于視覺語義關(guān)聯(lián)的文字識(shí)別網(wǎng)絡(luò),有效地提高了文字識(shí)別性能。
1 問題分析
零售終端店招文字識(shí)別以及終端許可證識(shí)別分別屬于場(chǎng)景文本[1]和文檔文本[2],如圖1所示。終端店招文字處于真實(shí)的復(fù)雜場(chǎng)景之中,具有目標(biāo)尺度變化大,字體種類、風(fēng)格多樣,背景較為復(fù)雜的主要特點(diǎn)。許可證文字處于紙質(zhì)文檔之中,此類圖片有圖像質(zhì)量較低、文字不清晰、尺度小、文字密度較大的特點(diǎn)。

圖1 圖片樣例Fig.1 Examples of picture
文字檢測(cè)和文字識(shí)別通常以串聯(lián)的結(jié)構(gòu)組成系統(tǒng),文字識(shí)別作用于文字檢測(cè)分支檢測(cè)出的文字區(qū)域。由于本文重點(diǎn)是文字識(shí)別部分,故不對(duì)文字檢測(cè)部分進(jìn)行過多敘述,直接采用文字檢測(cè)器輸出的文字區(qū)域圖像作為文字識(shí)別系統(tǒng)的目標(biāo)圖像,如圖2所示。

(a) 店招文字
近年來,隨著深度學(xué)習(xí)的發(fā)展,基于卷積神經(jīng)網(wǎng)絡(luò)的文字識(shí)別方法以其優(yōu)越的性能逐漸成為文字識(shí)別領(lǐng)域的主導(dǎo)方法。文獻(xiàn)[3-4]使用循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)深入建模像素之間的序列關(guān)系,增強(qiáng)文字上下文之間的理解,經(jīng)過CTC翻譯算法計(jì)算每個(gè)字符的概率,將RNN層的輸出轉(zhuǎn)化為一個(gè)字符串,作為最終結(jié)果。文獻(xiàn)[5-7]使用一種自回歸的方式,利用RNN結(jié)合空間注意力機(jī)制,逐個(gè)識(shí)別每個(gè)字符,獲得了比CTC轉(zhuǎn)譯更好的性能。近年來,表達(dá)能力更強(qiáng)的自注意力模塊[8]逐漸被使用在場(chǎng)景文字識(shí)別任務(wù)上,文獻(xiàn)[9-10]使用自注意力機(jī)制獲得更魯棒的特征表示,取得了目前最佳的識(shí)別性能,并且逐漸將文字的語言模型引入以輔助識(shí)別任務(wù),將其從簡(jiǎn)單的視覺分類建模為更全面的視覺和語言相結(jié)合的模型。由于其結(jié)合了語言的語義關(guān)系,在圖像不清晰、有干擾的情況下仍能取得較好的結(jié)果。
本文為了針對(duì)性、魯棒性地處理實(shí)際卷煙零售終端中出現(xiàn)的場(chǎng)景復(fù)雜和圖像質(zhì)量低等影響文字識(shí)別準(zhǔn)確率的問題,設(shè)計(jì)了一種基于視覺語義關(guān)聯(lián)的文字識(shí)別網(wǎng)絡(luò),在實(shí)際零售終端的多場(chǎng)景環(huán)境中均得到較好的效果,包括以下特點(diǎn):
① 提升網(wǎng)絡(luò)長(zhǎng)跨度感受野。文本圖像與一般的分類任務(wù)圖像不同,其擁有極大的寬高比并且輸出結(jié)果是不固定長(zhǎng)度的序列。直接沿用分類卷積網(wǎng)絡(luò)的方形卷積操作難以提升有效感受野,無法獲取文本行各個(gè)字符之間的空間長(zhǎng)跨度聯(lián)系。本文使用自注意力機(jī)制增強(qiáng)橫向文本的文字感知性能,有效提升文字識(shí)別準(zhǔn)確率。
② 結(jié)合中文語義,融合圖像和語言雙模態(tài)特征獲取更魯棒的識(shí)別結(jié)果。本文提出了一種全局語義聯(lián)系模塊,利用中文的語義信息,有效地處理實(shí)際拍攝過程中產(chǎn)生的圖像干擾等傳統(tǒng)視覺模型無法解決的問題,降低圖像識(shí)別中字體的多樣性、光照不均勻、顏色變化及尺度不一等干擾。
③ 采用Focal Loss作為最終的損失函數(shù)降低中文樣本不均衡分布的影響。由于實(shí)際場(chǎng)景樣本中文字類別分布極度不均勻,在訓(xùn)練中使用Focal Loss提升網(wǎng)絡(luò)對(duì)于出現(xiàn)頻率較低文字的識(shí)別準(zhǔn)確性,進(jìn)一步提升網(wǎng)絡(luò)的總體識(shí)別性能。
2 算法設(shè)計(jì)
基于視覺語義關(guān)聯(lián)的文字識(shí)別網(wǎng)絡(luò)是一種根據(jù)場(chǎng)景文字中的文字信息具有語言邏輯性的任務(wù)特點(diǎn)來設(shè)計(jì)的文字識(shí)別網(wǎng)絡(luò)結(jié)構(gòu),本節(jié)對(duì)其網(wǎng)絡(luò)細(xì)節(jié)進(jìn)行重點(diǎn)闡述。
2.1 算法概述
提出的基于視覺語義關(guān)聯(lián)的文字識(shí)別網(wǎng)絡(luò)結(jié)構(gòu)如圖3所示。一方面,摒棄現(xiàn)有低效的RNN解碼方式,通過高效并行的注意力模塊定位文字字符的準(zhǔn)確位置,加快多條目文本的識(shí)別速度;另一方面,利用transformer模塊深層次挖掘中文文本的語義內(nèi)容含義,對(duì)識(shí)別結(jié)果進(jìn)行糾正,使識(shí)別結(jié)果具有語言邏輯性。對(duì)由于圖像噪音等圖像低質(zhì)量問題造成的錯(cuò)誤識(shí)別具有一定的糾錯(cuò)能力,實(shí)現(xiàn)高精度的文字定位和識(shí)別。
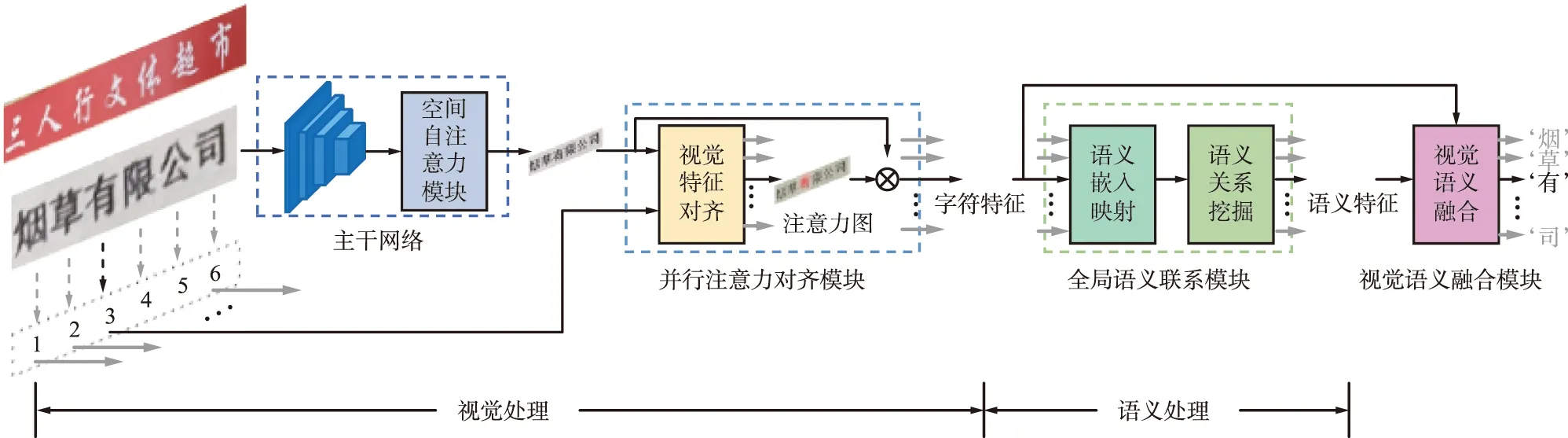
圖3 基于視覺語義關(guān)聯(lián)的文字識(shí)別網(wǎng)絡(luò)結(jié)構(gòu)Fig.3 Configuration of the proposed text recognition network
提出的文字識(shí)別網(wǎng)絡(luò)包含4個(gè)主要模塊:
(1) 主干網(wǎng)絡(luò)
采用卷積神經(jīng)網(wǎng)絡(luò)和自注意力機(jī)制相結(jié)合的主干網(wǎng)絡(luò),卷積神經(jīng)網(wǎng)絡(luò)使用目前性能優(yōu)越的殘差連接網(wǎng)絡(luò)。使用特征金字塔網(wǎng)絡(luò)結(jié)合不同尺寸的特征圖,一方面,為了更好地捕獲中文的筆畫細(xì)節(jié);另一方面,為了增強(qiáng)網(wǎng)絡(luò)對(duì)于不同細(xì)粒度文字特征提取的魯棒性。此外,在特征提取器基礎(chǔ)上,使用基于transformer的長(zhǎng)跨度自注意力進(jìn)一步增強(qiáng)特征的全局聯(lián)系性。
(2) 并行注意力對(duì)齊模塊
提出一種高效的并行視覺注意力策略。傳統(tǒng)的字符串識(shí)別方法執(zhí)行網(wǎng)絡(luò)前向過程僅識(shí)別一個(gè)字符,識(shí)別整串需要執(zhí)行多次前向,處理許可證版面的長(zhǎng)文本十分費(fèi)時(shí)。因此,提出并行注意力機(jī)制,一次前向過程識(shí)別文本行中所有字符,速度提升10倍以上。另外,由于店招文字以及許可證文本每行文字分布均勻,網(wǎng)絡(luò)可以輕易學(xué)習(xí)出字符的位置信息,高效準(zhǔn)確地對(duì)文字進(jìn)行捕捉。
(3) 全局語義聯(lián)系模塊
中文文字具有強(qiáng)烈的語義特征,通常的文字識(shí)別方法中將語義分析作為后處理操作,無法與識(shí)別網(wǎng)絡(luò)進(jìn)行端到端訓(xùn)練。本文提出全局語義聯(lián)系模塊,單獨(dú)挖掘語義信息并隨網(wǎng)絡(luò)端到端訓(xùn)練。使用長(zhǎng)跨度序列注意力模型,將識(shí)別出的文字結(jié)果進(jìn)行語義級(jí)別的矯正,使輸出結(jié)果具備語言邏輯性。
(4) 視覺—語義融合模塊
綜合并行注意力對(duì)齊模塊以及全局語義聯(lián)系模塊的視覺和語義識(shí)別結(jié)果,進(jìn)行文字逐位比較,使用注意力機(jī)制權(quán)衡視覺以及語義識(shí)別結(jié)果的置信度獲得最終視覺—語義關(guān)聯(lián)的識(shí)別結(jié)果。
2.2 算法模塊分析
(1) 主干網(wǎng)絡(luò)
本文采用了殘差神經(jīng)網(wǎng)絡(luò)[11]結(jié)合自注意力機(jī)制的主干網(wǎng)絡(luò),其中,殘差神經(jīng)網(wǎng)絡(luò)參考文獻(xiàn)[3]提出的45層輕量級(jí)網(wǎng)絡(luò)的結(jié)構(gòu)設(shè)計(jì)。每個(gè)殘差模塊單元包含一個(gè)空間尺寸為3的卷積層用于收集上下文信息,擴(kuò)大網(wǎng)絡(luò)的感受野;一個(gè)尺寸為1的卷積核減少參數(shù)量并且增強(qiáng)特征表達(dá),具體的主干網(wǎng)絡(luò)配置如表1所示。由于文字圖像長(zhǎng)寬比例的特殊性,更改了原始等比例下采樣的策略,在第3階段之后采用縱向下采樣、特征圖寬度不變的策略以保持文字的橫向排列特性。
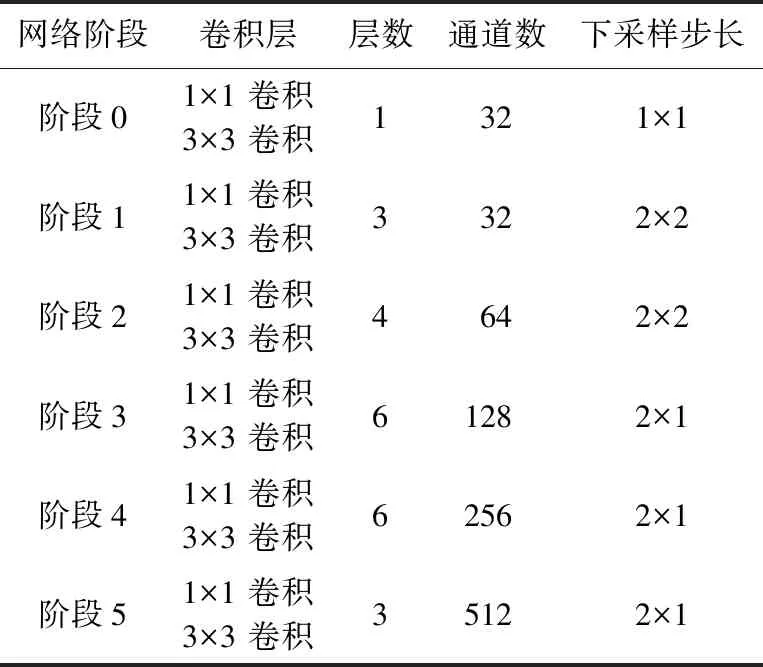
表1 主干網(wǎng)絡(luò)配置Tab.1 Backbone network configuration
近年來,基于自注意力機(jī)制的主干網(wǎng)絡(luò)在計(jì)算機(jī)視覺領(lǐng)域取得了很大的成功[12-13]。自注意力模塊和卷積神經(jīng)網(wǎng)絡(luò)相結(jié)合的混合模型[14-16]更是取得了優(yōu)異的效果。卷積神經(jīng)網(wǎng)絡(luò)擁有出色的歸納偏置,對(duì)通用特征的提取起到了極大的幫助,而自注意力模塊以數(shù)據(jù)為驅(qū)動(dòng)深度挖掘特征之間的關(guān)聯(lián),并且改進(jìn)卷積操作感受野的局限性,二者相得益彰。transformer結(jié)構(gòu)如圖4所示。本文將基于標(biāo)準(zhǔn)transformer的空間長(zhǎng)跨度自注意力模塊置于卷積網(wǎng)絡(luò)之后,其具體結(jié)構(gòu)如圖4(a)所示。
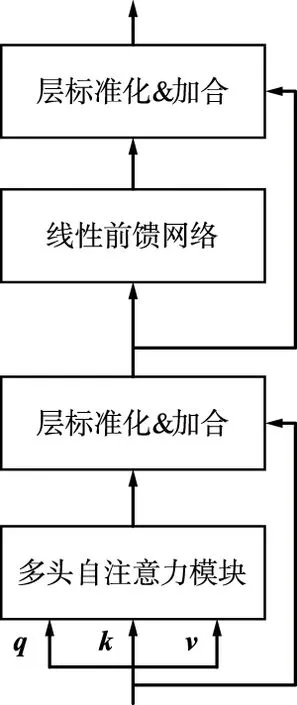
(a) transformer模塊組成結(jié)構(gòu)
在自注意力模塊[8]中,查詢向量q為輸入序列中某個(gè)元素,鍵向量k和值向量v構(gòu)成
(1)
式中,Q∈Rn×dk;K∈Rn×dk;V∈Rn×dv。本文中自注意力模塊的輸入q=k=v=F。F∈Rn×C為卷積神經(jīng)網(wǎng)絡(luò)的輸出特征,n=H×W為序列長(zhǎng)度,C,dv,dk為特征通道數(shù)。
由于transformer模塊結(jié)構(gòu)無法感應(yīng)輸入數(shù)據(jù)的相對(duì)次序,通常為輸入特征額外復(fù)合代表位置關(guān)系的位置編碼[12-13],為了適應(yīng)圖像特征的2維位置關(guān)系,使用了自學(xué)習(xí)2維位置編碼提升圖像的自注意力機(jī)制識(shí)別效果。表達(dá)如下:
(2)
式中,PEi,j∈Rn×dk為自學(xué)習(xí)位置編碼向量,i,j分別代表空間的行列位置,以使transformer模塊感知空間的特征關(guān)系。位置編碼只作用于查詢向量q以及鍵向量k,建立自注意力空間位置關(guān)系,而不改變值向量v,以保證圖像判別性特征不被改變。
自注意力是一種關(guān)注輸入序列內(nèi)部元素間關(guān)系的注意力機(jī)制。自注意力機(jī)制的中心思想是計(jì)算輸入序列中每個(gè)元素與其他所有元素間的相互關(guān)系權(quán)重,自主學(xué)習(xí)序列中元素的編碼表示,該編碼表示同時(shí)包含元素本身的信息和輸入序列中其他元素與該元素的關(guān)系,即所有的文字信息。如圖4(a)所示,加入了殘差連接和層歸一化計(jì)算方式,處理深度學(xué)習(xí)模型的退化難題。增加全連接層構(gòu)成的前饋網(wǎng)絡(luò),增強(qiáng)每個(gè)元素的特征表示。
終端店招文字識(shí)別具有內(nèi)容長(zhǎng)的特點(diǎn),使用空間長(zhǎng)跨度自注意力模塊可以高效、準(zhǔn)確地解析所有字符。
(2) 并行注意力對(duì)齊模塊
基于空間注意力的文字識(shí)別解碼[4,17]通常通過自回歸的方式從左至右依次定位圖像中各個(gè)文字的位置,并且識(shí)別為相應(yīng)字符。其最大弊端是每次解碼字符均需要執(zhí)行一次前向過程,當(dāng)文字序列過長(zhǎng)時(shí)計(jì)算效率過于低下。為此,使用了并行注意力解碼方式,一次前向過程解碼所有字符。計(jì)算如下:
(3)
式中,K=V=G為圖像視覺特征;Qd為次序編碼,形式上為一個(gè)自學(xué)習(xí)矩陣Qd∈Rn×dk。最終,得到Fv為各個(gè)字符的視覺特征。
(3) 全局語義聯(lián)系模塊
全局語義聯(lián)系模塊由語義嵌入映射和語義關(guān)系挖掘2個(gè)子模塊構(gòu)成。語義嵌入映射模塊利用詞嵌入 (Embedding)操作,將視覺特征Fv的字符分類結(jié)果映射至高維語義特征,這些特征通過語義關(guān)系挖掘模塊深入探索語言的語義關(guān)聯(lián)性。
全局語義關(guān)系模塊如圖5所示,其基本結(jié)構(gòu)為4層相連的transformer模塊。利用transformer中自注意力模塊的全局交互,文字序列中的每一個(gè)文字之間深層語言信息被挖掘,建立文本串的語言邏輯知識(shí)。
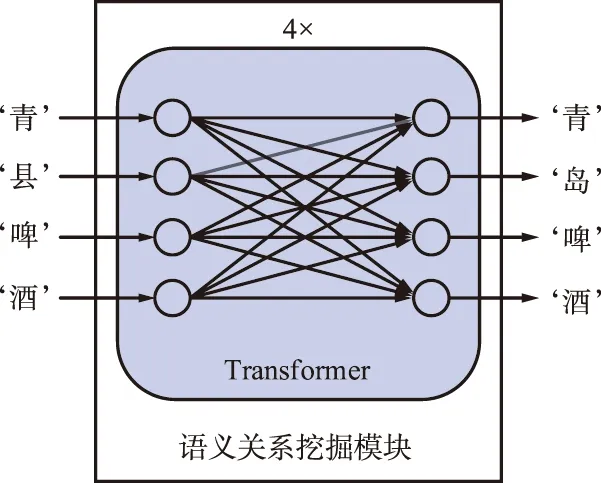
圖5 全局語義關(guān)系模塊Fig.5 Global semantic association module
采用圖4(a)的transformer結(jié)構(gòu),輸入q=k=v是視覺并行注意力對(duì)齊模塊的解碼結(jié)果相應(yīng)的嵌入結(jié)果并且復(fù)合位置編碼以表明文字的相對(duì)前后關(guān)系[8]。利用自注意力模塊的計(jì)算能力深度挖掘各個(gè)文字之間的關(guān)系,建模文本行的語義知識(shí)。對(duì)于模糊、檢測(cè)缺失和遮擋污漬等視覺干擾,純粹利用卷積神經(jīng)網(wǎng)絡(luò)的視覺建模無法解碼正確字符,但是利用上下文的整體語義信息可以對(duì)結(jié)果進(jìn)行彌補(bǔ)。遮擋圖像示例如圖6所示,其視覺識(shí)別結(jié)果為“青縣啤酒”,使用語義上下文建模,理解中文語言語境,糾正結(jié)果為“青島啤酒”。

圖6 遮擋圖像示例Fig.6 Occlusion image example
由于全局語義聯(lián)系模塊基于視覺識(shí)別網(wǎng)絡(luò)的識(shí)別結(jié)果,僅作用于中文語言空間而與圖像特征無直接關(guān)系,故此模塊可以獨(dú)立于文字識(shí)別模型進(jìn)行中文語義的預(yù)訓(xùn)練。參考文獻(xiàn)[18]的預(yù)訓(xùn)練方式,本文在大量中文語料中預(yù)訓(xùn)練,并在終端店招和零售許可證圖像中分別微調(diào)此模塊。預(yù)訓(xùn)練策略為隨機(jī)掩碼,對(duì)于輸入的中文文字嵌入信息,隨機(jī)掩碼輸入序列中的若干文字,并最終預(yù)測(cè)這些被替換的文字,以此學(xué)習(xí)文字間的語言關(guān)系。其中,EM∈RC為所述掩碼,其本身無意義,在訓(xùn)練中隨機(jī)替換文字的嵌入信息。
在微調(diào)階段,對(duì)于視覺模型的輸出結(jié)果,其識(shí)別置信度往往和其字符識(shí)別準(zhǔn)確率高度正相關(guān)。對(duì)于錯(cuò)誤識(shí)別的字符,其識(shí)別準(zhǔn)確率p往往較低,為了不使錯(cuò)誤的識(shí)別結(jié)果干擾語義聯(lián)系模塊的識(shí)別,本文以字符識(shí)別準(zhǔn)確率p作為置信度權(quán)值復(fù)合文字嵌入代表最終的輸入:
Ein=p×E+PE,
(4)
式中,E為中文文字的嵌入信息;PE為可學(xué)習(xí)位置編碼。隨著置信度p的作用,錯(cuò)誤的文字信息不會(huì)被帶入全局語義聯(lián)系模塊干擾上下文的學(xué)習(xí);另一方面,其輸入文字信息被掩碼后信息缺失,只能通過上下文的文字語言知識(shí)進(jìn)行推斷,與預(yù)訓(xùn)練的動(dòng)機(jī)更加貼合。
(4) 視覺—語義融合模塊
如上所述,視覺處理中的視覺識(shí)別特征Fv以及語言建模后的語義特征Fs分別代表各個(gè)字符的視覺信息和語言信息,使用一個(gè)門控機(jī)制進(jìn)行視覺—語義方面的權(quán)衡,最終的特征D表達(dá)為:
D=σFv+(1-σ)Fs,
(5)
σ=Wg([Fv;Fs]),
(6)
式中,門控單元σ自適應(yīng)地由視覺和語義特征得到;Wg為自學(xué)習(xí)向量用于調(diào)控視覺和語言特征的比重。對(duì)于視覺信息較弱的受干擾文字,語言特征Fs的作用尤為突出,而對(duì)于純數(shù)字等無意義文字,視覺特征Fv更加關(guān)鍵。門控機(jī)制針對(duì)這一問題進(jìn)行了建模,自適應(yīng)地權(quán)衡融合特征比重。
最終網(wǎng)絡(luò)的優(yōu)化目標(biāo)包含3個(gè)部分:視覺識(shí)別結(jié)果的損失、語言糾正結(jié)果的損失以及視覺—語義相關(guān)聯(lián)的結(jié)果損失。三者的損失函數(shù)均使用Focal Loss[19]并且有相同的標(biāo)簽。由于中文文字識(shí)別具有分布不均勻的特性,尤其在終端場(chǎng)景中,“煙草”“超市”等文字出現(xiàn)更為頻繁,故使用處理分布不均勻的Focal Loss對(duì)視覺特征Fv、語義特征Fs以及融合特征D進(jìn)行多損失聯(lián)合優(yōu)化:
L=λvLv+λsLs+λDLD,
(7)
式中,Lv,Ls,LD為Focal Loss:
l=-α(1-pt)γln(pt)。
(8)
3 應(yīng)用效果
3.1 實(shí)驗(yàn)設(shè)計(jì)
輸入圖像的高度歸一化至32 pixel,寬度通過保持長(zhǎng)寬比的方式動(dòng)態(tài)調(diào)節(jié)。先等比例縮放圖像,保證圖像高度為32 pixel,寬度不足32 pixel的部分補(bǔ)0,超過的部分寬度縮放至32 pixel。對(duì)于并行注意力對(duì)齊模塊,其次序編碼個(gè)數(shù)對(duì)于店招文字和許可證文字分別為20,50,以針對(duì)圖中最大長(zhǎng)度的文字限制,在前向測(cè)試中根據(jù)圖像的長(zhǎng)寬比進(jìn)行動(dòng)態(tài)調(diào)整以提升計(jì)算效率。網(wǎng)絡(luò)中的每個(gè)卷積層默認(rèn)緊跟一個(gè)批歸一化層和一個(gè)非線性整流激活函數(shù)(ReLU)。使用的網(wǎng)絡(luò)自注意力模塊和并行注意力對(duì)齊模塊維度均為512,其中,多頭注意力的頭部數(shù)量為8。使用Adam[20]優(yōu)化器進(jìn)行訓(xùn)練,默認(rèn)學(xué)習(xí)率為10-3,損失函數(shù)中λv=λs=λD=1,Focal Loss超參數(shù)α=0.25,γ=2 。
使用預(yù)訓(xùn)練和微調(diào)的整體訓(xùn)練策略。對(duì)于視覺識(shí)別模型,采用大量真實(shí)樣本和生成樣本訓(xùn)練本文提出的模型。使用公開真實(shí)文字識(shí)別數(shù)據(jù)集,例如LSVT,RCTW-17,MTWI2018和CCPD以及生成文字圖像等總計(jì)4 000 000的文本數(shù)據(jù),大量的文本圖像預(yù)訓(xùn)練提升網(wǎng)絡(luò)的通用識(shí)別性能。對(duì)于全局語義關(guān)聯(lián)模塊,使用中文維基百科EXT等500 000 000個(gè)中文文本數(shù)據(jù)預(yù)訓(xùn)練。
在微調(diào)的過程中使用實(shí)際場(chǎng)景的數(shù)據(jù)訓(xùn)練整體網(wǎng)絡(luò),其中,視覺識(shí)別模型和全局語義關(guān)聯(lián)模塊經(jīng)由預(yù)訓(xùn)練得到,二者微調(diào)時(shí)學(xué)習(xí)率為10-4。店招圖像的圖像數(shù)9 285,許可證條目圖像數(shù)92 200。測(cè)試集中,店招條目圖像數(shù)1 034,許可證條目圖像數(shù)10 213。遵循場(chǎng)景文字識(shí)別的標(biāo)準(zhǔn)評(píng)判準(zhǔn)則,圖像正確的依據(jù)為字符串中所有文字全部正確。網(wǎng)絡(luò)使用4塊12 GB 顯存的NVIDIA TITAN Xp GPU進(jìn)行訓(xùn)練,總共訓(xùn)練250個(gè)epoch。
在性能評(píng)測(cè)時(shí),遵循行內(nèi)全部文字正確識(shí)別代表該文本圖像正確識(shí)別,準(zhǔn)確率指標(biāo)計(jì)算如下:
準(zhǔn)確率=(正確識(shí)別文本圖像數(shù)目/文本圖像數(shù)目)×
100%。
(9)
3.2 實(shí)驗(yàn)結(jié)果
(1) 準(zhǔn)確率分析
使用本文提出的結(jié)構(gòu)訓(xùn)練神經(jīng)網(wǎng)絡(luò),店招文字的識(shí)別準(zhǔn)確率達(dá)到86.4%,許可證文字的識(shí)別準(zhǔn)確率為94.1%。平均的GPU前向推理時(shí)間為0.073 4 s,即13.62幀/秒。訓(xùn)練準(zhǔn)確率曲線如圖7所示。
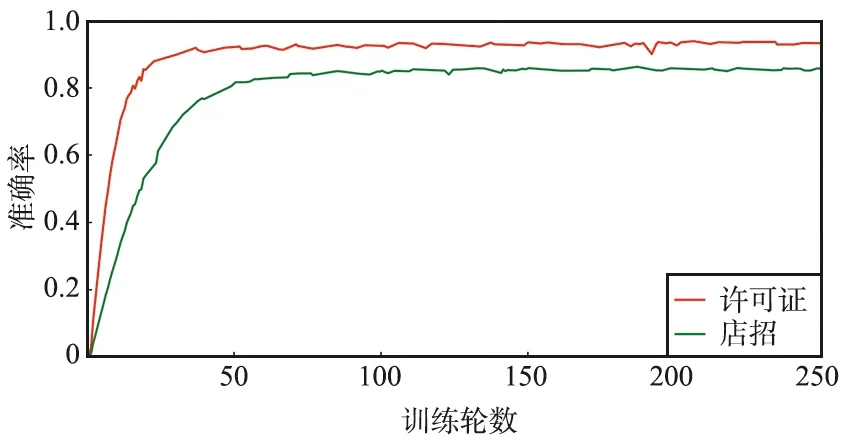
圖7 訓(xùn)練準(zhǔn)確率曲線Fig.7 Illustration of training accuracy
由圖7可以看出,訓(xùn)練在50個(gè)epoch之后呈現(xiàn)穩(wěn)定趨勢(shì),在50~150個(gè)epoch上由于數(shù)據(jù)增強(qiáng)的存在,準(zhǔn)確率微弱上升。由于許可證文字多為白底黑字,排列規(guī)整,其準(zhǔn)確率更高、收斂速度更快。店招文字由于其多變的字體和復(fù)雜的背景,識(shí)別準(zhǔn)確率稍低。
(2) 模型結(jié)構(gòu)對(duì)比分析
為了證明所使用方法的有效性,分別對(duì)視覺模型和語言模型的性能進(jìn)行詳細(xì)比較。在視覺模型中,使用了基于自注意力模塊transformer的上下文建模和基于并行注意力機(jī)制的解碼方式作為視覺模型基準(zhǔn)線的設(shè)置。相比于傳統(tǒng)方法中同等作用的CTC解碼和基于雙向LSTM的上下文建模,本文采用的方法具有最佳的識(shí)別準(zhǔn)確率,結(jié)果如表2所示。
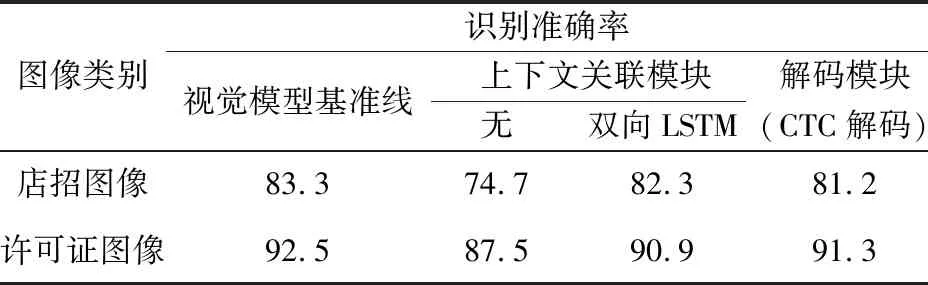
表2 視覺模型模塊對(duì)比實(shí)驗(yàn)Tab.2 Ablation study of visual model 單位:%
上下文關(guān)聯(lián)模塊和解碼模塊分別為transformer和并行注意力解碼,在各實(shí)驗(yàn)中僅替換相應(yīng)模塊以達(dá)到公平比較。可以看到,使用的視覺模型相比其他算法有一定優(yōu)勢(shì),相比于傳統(tǒng)的雙層雙向LSTM的上下文關(guān)聯(lián)算法,使用的transformer模塊分別在店招圖像和許可證圖像識(shí)別準(zhǔn)確率上有1.0%和1.6%的提升,說明了自注意力模塊的優(yōu)越性;另一方面,使用的基于注意力的解碼模塊相比CTC解碼模塊有著2.1%和1.2%的性能增長(zhǎng)。CTC模塊因其簡(jiǎn)單、高速的特點(diǎn),廣泛使用于文字識(shí)別的解碼中,但是由于其訓(xùn)練指導(dǎo)性較弱,近年來逐步被訓(xùn)練區(qū)域定位更精確的空間注意力機(jī)制超越。在許可證文字識(shí)別中,CTC解碼的性能相對(duì)較高,這是由于許可證文字是打印文字,其排列規(guī)律均勻,有利于CTC的解碼,但是在店招的復(fù)雜場(chǎng)景中,本文采用的解碼方式更能體現(xiàn)出優(yōu)勢(shì)。
為了進(jìn)一步探究語義聯(lián)系模塊在中文文字識(shí)別中起到的補(bǔ)充輔助作用,進(jìn)行模型在沒有該模塊時(shí)的性能對(duì)比,結(jié)果如表3所示。在去除語義聯(lián)系模塊的模型中,店招文字和許可證文字識(shí)別準(zhǔn)確率分別有3.1%,1.6%的下降,體現(xiàn)語義聯(lián)系模塊的重要性。其中,店招文字存在遮擋和藝術(shù)字體等原因?qū)е录兇獾囊曈X模型難以十分準(zhǔn)確地識(shí)別,利用中文語言語境的關(guān)系進(jìn)行識(shí)別結(jié)果的修正顯得更加重要。

表3 語義聯(lián)系模塊的比對(duì)實(shí)驗(yàn)Tab.3 Ablation study of semantic association module 單位:%
(3) 與其他方法比較
在同樣的訓(xùn)練條件下和目前在中文文字識(shí)別中廣泛使用的CRNN算法進(jìn)行比較,結(jié)果如表4所示。由表4可以看出,提出的網(wǎng)絡(luò)有更優(yōu)越的性能。相比于CRNN算法,提出的方法分別有6.6%,3.6%的性能提升。由于店招圖像場(chǎng)景更為復(fù)雜,該方法取得了更大的提升。在規(guī)則的水平文字場(chǎng)景,即許可證圖像文字識(shí)別中,該方法仍然遠(yuǎn)優(yōu)于CRNN,證明了所提方法的魯棒性。

表4 和其他方法性能對(duì)比Tab.4 Comparison of performance with other methods 單位:%
部分可視化識(shí)別結(jié)果如圖8所示。圖片第一列是圖像區(qū)域的文字檢測(cè)結(jié)果,不同的文字條目檢測(cè)結(jié)果由不同的顏色區(qū)分。為了公平對(duì)比提出的方法和CRNN的差異,使用相同的文字檢測(cè)結(jié)果。文字區(qū)域執(zhí)行不同的文字識(shí)別算法,其中第二列是CRNN的文字識(shí)別結(jié)果,第三列為提出的方法的識(shí)別結(jié)果,其中錯(cuò)誤識(shí)別的文字用紅色字體標(biāo)出。
店招文字識(shí)別結(jié)果如圖8(a)所示,可以看到店招文字由于字體的多樣性和復(fù)雜場(chǎng)景的干擾,對(duì)識(shí)別結(jié)果產(chǎn)生了較大的干擾。“嶽”在大規(guī)模訓(xùn)練中是出現(xiàn)很少的文字,單純的圖像視覺難以正確識(shí)別,但是提出的語義關(guān)聯(lián)模型針對(duì)該場(chǎng)景的中文語料將其糾正為正確的識(shí)別結(jié)果。同樣,在圖中“煙”字被復(fù)雜場(chǎng)景遮蓋,純粹的識(shí)別模型無法直接識(shí)別,但是受到上下文的語義糾正捕捉到“煙酒商行”這一短語。

(a) 店招圖像區(qū)域識(shí)別結(jié)果展示
許可證文字的識(shí)別結(jié)果如圖8(b)所示,相比于店招文字,許可證文字排列簡(jiǎn)單而且字體單一,但是其由于文字較小常常分辨率較低,模糊的文字干擾識(shí)別,通過語義補(bǔ)充可以一定程度上彌補(bǔ)這一不足。如圖中“雪茄”識(shí)別為“雪范”,雖然圖像的模糊對(duì)視覺識(shí)別造成困難,但是在該場(chǎng)景的上下文語料中能夠輕易糾正為“雪茄煙零售”。圖中“擂”字同樣很少出現(xiàn)在訓(xùn)練的圖像中,故CRNN識(shí)別錯(cuò)誤為“播”,通過結(jié)合上下文的“擂鼓”仍能給予糾正,由此體現(xiàn)了提出的語義信息補(bǔ)充在文字識(shí)別中起到了關(guān)鍵性的作用。
(4) 在公開數(shù)據(jù)集中的比對(duì)
為了證明本文提出的方法具有魯棒性,在中文公開數(shù)據(jù)集中進(jìn)行對(duì)照實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如表5所示。由表5可以看出,提出的方法相比于CRNN[3],SRN[9]具有更高的識(shí)別準(zhǔn)確率。收集RCTW,ReCTS和LSVT等中文公開數(shù)據(jù)集作為本節(jié)實(shí)驗(yàn)數(shù)據(jù),其中訓(xùn)練數(shù)據(jù)集包括500 000個(gè)中文字符串訓(xùn)練數(shù)據(jù),測(cè)試數(shù)據(jù)集包括60 000個(gè)。
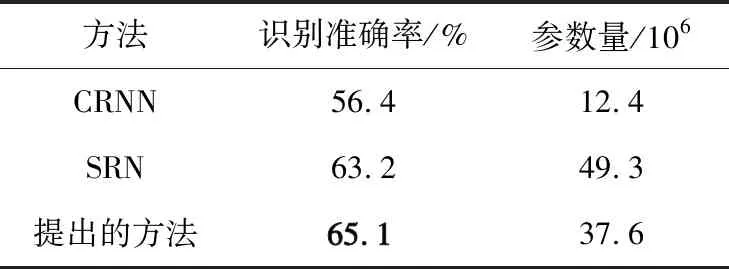
表5 在公開數(shù)據(jù)集中和其他方法性能對(duì)比Tab.5 Comparison of performance with other methods on benchmarks
相比于傳統(tǒng)的純視覺模型CRNN,本文提出的方法考慮了文字的語義關(guān)系有明顯的性能提升;相較于語義關(guān)聯(lián)網(wǎng)絡(luò)SRN,本文使用的模塊設(shè)計(jì)以及新的損失函數(shù)等策略改變帶來了很大收益,能夠在中文數(shù)據(jù)上展示出更強(qiáng)的識(shí)別性能。全局語義關(guān)聯(lián)模塊采用基于雙向感知的結(jié)構(gòu),相比于SRN中使用的前向語義以及反向語義2個(gè)網(wǎng)絡(luò)的實(shí)現(xiàn),本文提出的結(jié)構(gòu)具有更少的參數(shù)量以及計(jì)算消耗。
4 結(jié)束語
本文將中文語言的語義關(guān)系融合至卷煙零售終端店招文字和許可證文字識(shí)別的模型當(dāng)中,取得了良好的識(shí)別效果。其中,利用自注意力機(jī)制在視覺模型和語言模型中均取得了較大的成功:一方面,提升了識(shí)別的準(zhǔn)確率;另一方面,減少了由于RNN帶來的耗時(shí)以及注意力機(jī)制偏差。語言模型的加入很大程度上解決了真實(shí)終端拍攝圖片存在的問題,緩解純視覺模型的固有缺陷。在未來的工作中,將著重關(guān)注模型的預(yù)訓(xùn)練方式,因?yàn)閷?duì)于文字識(shí)別,通用的文字識(shí)別是最終的目標(biāo),不應(yīng)該有場(chǎng)景的區(qū)分。場(chǎng)景的真實(shí)樣本數(shù)量相比于公開的通用識(shí)別數(shù)據(jù)和生成圖像數(shù)據(jù)少之又少,因此,在預(yù)訓(xùn)練模型的基礎(chǔ)上,利用少量真實(shí)場(chǎng)景圖像進(jìn)行微調(diào),即可提升模型在各個(gè)場(chǎng)景的通用性和泛化性。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
當(dāng)代修辭學(xué)(2011年6期)2011-01-29 02:49:50
外語學(xué)刊(2011年1期)2011-01-22 03:38:33
