基于支持向量機的輸氣管道泄漏壓降信號智能識別方法
2022-10-13 10:36:44賈文龍孫溢彬湯丁陳家文雷思羅李長俊
化工進展 2022年9期
賈文龍,孫溢彬,湯丁,陳家文,雷思羅,李長俊
(1 西南石油大學石油與天然氣工程學院,四川 成都 610500;2 重慶相國寺儲氣庫有限公司,重慶 401121)
為保證輸氣管道安全運行,根據標準GB 50251《輸氣管道工程設計規范》的要求,需要在管道沿線設置截斷閥室。目前國內大多數管線采用美國Shafer氣液聯動閥,當氣液聯動閥檢測到的管道壓降速率和持續時間同時超過設定值時,截斷閥將自動關斷。如表1所示,國內不同管線的截斷閥參數設定值存在一定差異,大部分設置壓降速率為0.15MPa/min,持續時間為120s。

表1 截斷閥參數設定值
然而,在實際情況中采用上述設定值后,截斷閥仍會出現無法在管道泄漏時正常關斷的情況。例如,2012年西部某天然氣管道發生約20mm的小孔泄漏,檢測的壓降速率約0.03MPa/min,截斷閥沒有自動關斷;2015 年中石油天然氣管網發生多起泄漏事故,由于泄漏量和檢測的壓降速率較小,所有事故中截斷閥均未自動關斷。
國內外學者針對如何合理設置閥門壓降速率和持續時間的問題開展了大量的研究。Zuo 等分析了持續時間為120s時泄漏工況對壓降速率的影響,表明管道的最大壓降速率與管道運行壓力成正比,與氣體流速成反比。楊毅等模擬了不同泄漏工況對截斷閥壓降速率和持續時間的影響,發現小于300mm的泄漏孔徑幾乎不會引起截斷閥自動關斷。赫德明等針對安徽省某輸氣管道提出了氣液聯動閥的壓降速率與持續時間的推薦值,但僅能截斷泄漏孔徑為200mm以上的泄漏情況。賈文龍等基于仿真將壓縮機抽吸工況和泄漏工況的壓降信號進行對比,研究發現這兩種工況的壓降速率有重復,容易引起截斷閥的不關斷或誤關斷。因此,氣液聯動閥檢測管道泄漏目前存在兩方面的問題:首先是管道發生小孔徑泄漏時的壓降速率遠小于設定值,致使截斷閥無法自動關斷;其次是壓縮機的抽吸等正常運行工況也會導致管道的壓力下降和波動,如果試圖降低設定值以識別出更小的泄漏工況,就會引起截斷閥在管道正常運行時的誤關斷。為此,研發新的泄漏壓降速率信號識別方法有助于提升氣液聯動閥對泄漏工況以及其他工況的判斷能力與執行能力,確保管道平穩供氣。
近年來,隨著智慧管道的發展,人工智能的檢測方法越來越受到關注,它主要通過對采集的壓力信號、流量信號或聲信號進行實時特征值提取與分析來實現管道泄漏的檢測。焦敬品等基于聲信號的特征參數構建了BP 神經網絡管道泄漏識別系統,實現了不同泄漏信號的交叉識別。張瑞程等基于聲信號的特征參數,基于一維卷積神經網絡提出了一種泄漏識別模型,優化了輸氣管道泄漏識別中的數據預處和特征提取過程,提高了識別的準確率。郝永梅等對總體局域均值分解與多尺度熵進行改進,提出了一種管道泄漏識別方法,減少了分解后的誤差,提高了泄漏信號的識別率。逯雯雯將布谷鳥和粒子群算法進行融合并優化了支持向量機的參數,根據負壓波信號的特征建立了二叉樹多分類支持向量機模型,實現了對泄漏點的定位。Ning等將頻譜增強和卷積神經網絡相結合,提出了一種天然氣管道泄漏檢測方法,該方法可以增強泄漏信號并降低背景噪聲。Zadkarami 等使用統計技術和小波分析的方法,提取了泄漏管道的進口壓力和出口流量等信號特征,使用多層感知器神經網絡進行分類,實現了對泄漏位置和泄漏尺寸的識別。Li等提出了一種基于核主成分分析和支持向量機的聲信號泄漏檢測方法。Liu 等采用濾波法對聲信號進行處理,提出了信號去噪系統和泄漏點定位方法,提出的系統能夠有效地從實測信號中提取泄漏信號且泄漏檢測結果的精度也較高。Diao等結合粒子群算法和最大熵原理對聲波信號進行重構,基于變分模態分解提取了聲波信號的特征,通過支持向量機對管道泄漏進行檢測。
然而,國內外研究大多以聲波信號為研究對象,目前還缺乏壓降速率信號對管道泄漏識別的研究與驗證。因此,考慮氣液聯動閥的檢測特點并結合實際工程中截斷閥遇到的問題,基于相國寺儲氣庫輸氣干線數據,建立并驗證管道壓降速率仿真模型。通過模型獲得管道泄漏、壓縮機抽吸以及截斷閥緊急截斷工況的壓降速率信號然后進行特征分析。改進教與學優化算法并用其優化支持向量機內的參數,建立多分類的支持向量機泄漏信號識別模型,以期提供一個快速且準確的管道泄漏智能識別方法。
1 壓降速率信號的采集
1.1 壓降速率的計算
Shafer 氣液聯動閥的對點檢測壓降速率計算如式(1)~式(3)所示。

式中,p為時刻的平均壓力,MPa;為時刻的壓力,MPa;為-5s 時的壓力,MPa;為-10s 時 的 壓 力,MPa;為-15s 時 的 壓 力,MPa;為-20s時的壓力,MPa。
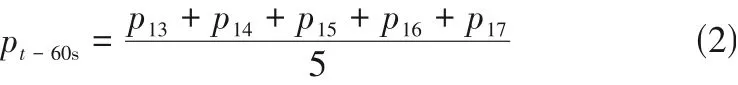
式中,p為-60s 時的平均壓力,MPa;為-60s 時的壓力,MPa;為-65s 時的壓力,MPa;為-70s 時的壓力,MPa;為-75s 時的壓力,MPa;為-80s時的壓力,MPa。

式中,ROD為時刻的壓降速率,MPa/min。壓力曲線見圖1。
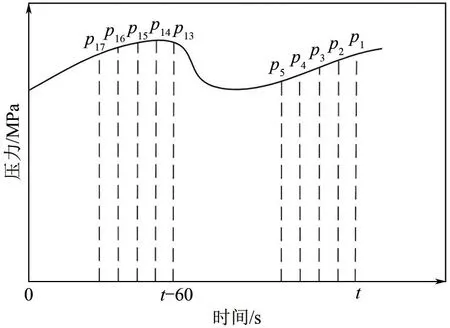
圖1 壓力曲線
1.2 壓降速率信號的模擬
如圖2所示,相國寺儲氣庫銅相線全長84.2km,設計輸量2100×10m/d,設計壓力10MPa,沿線有5座閥室,集注站內設有壓縮機組,在注氣階段時啟動。采用PipelineStudio 仿真軟件建立了銅相線的管道仿真模型,通過現場實測數據對模型進行驗證,平均相對偏差為0.38%,驗證了模型的可靠性。

圖2 相國寺儲氣庫銅相線
基于仿真模型,結合銅相線的實際情況,模擬了管道泄漏、壓縮機抽吸和截斷閥緊急截斷3種工況下集注干線上各閥室的壓力變化情況。為了使數據更具多樣性,模擬了不同邊界條件在任意組合下對閥室壓降速率的影響,其中管徑為660~1016mm、輸量為(300~2100)×10m/d、壓力為5~10MPa、泄漏孔徑為25~125mm、泄漏位置為兩閥室間10%~70%的位置、壓縮比為1.5~3.0。
以土場閥室為例,圖3 為該閥室在相同輸量、壓力等邊界條件下對應3 種不同工況時的壓力曲線。其中泄漏工況的泄漏孔徑為80mm,泄漏位置為兩閥室間70%位置;壓縮機抽吸工況的壓縮比為2.5;截斷閥截斷工況為靜觀閥室突然截斷后土場閥室的壓力變化情況。以上所有動態工況均發生在第3分鐘,共持續30min。
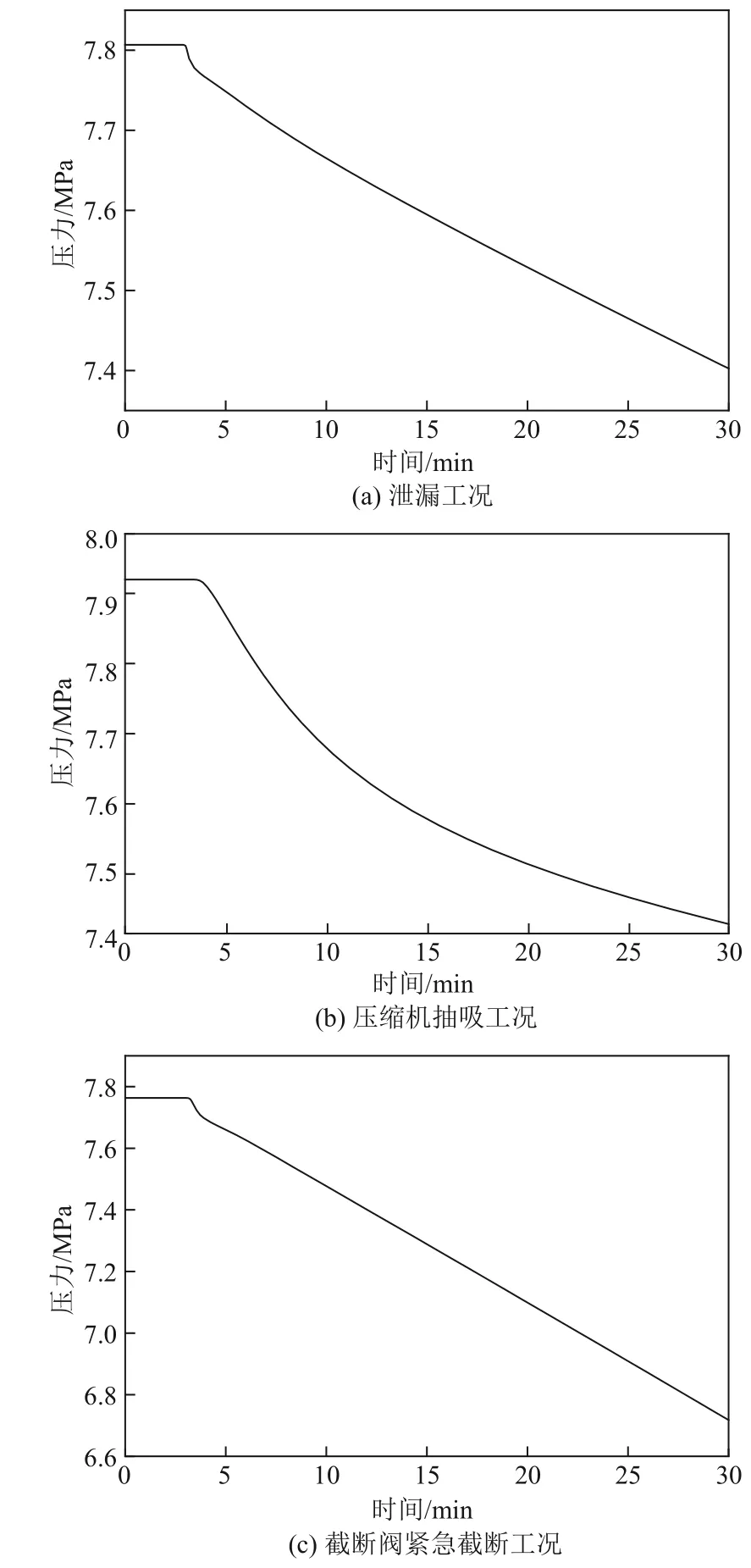
圖3 不同工況下閥室壓力曲線
根據式(3)將壓力信號轉化為壓降速率信號。圖4(a)顯示,同一閥室在不同泄漏孔徑下,壓降速率信號趨勢保持一致,但泄漏孔徑越小,信號的波動越不明顯。由于壓力波動會隨著傳播距離增大而減弱,所以在圖4(b)、(c)可以看到,這兩種工況下距離集注站或靜觀閥室(緊急截斷的閥室)越遠的閥室,壓降速率越小且信號越加平緩。縱觀圖4,這3種工況的某些壓降速率信號在數值上相近,這也是截斷閥誤關斷或不關斷的主要原因,因為氣液聯動閥單一地根據壓降速率數值無法準確區分出這些工況。但觀察發現,不同工況下壓降速率信號曲線的趨勢各有不同,而機器學習就可以根據這些曲線的特征來反向判別該信號所屬的工況類別,進而指導截斷閥是否動作。
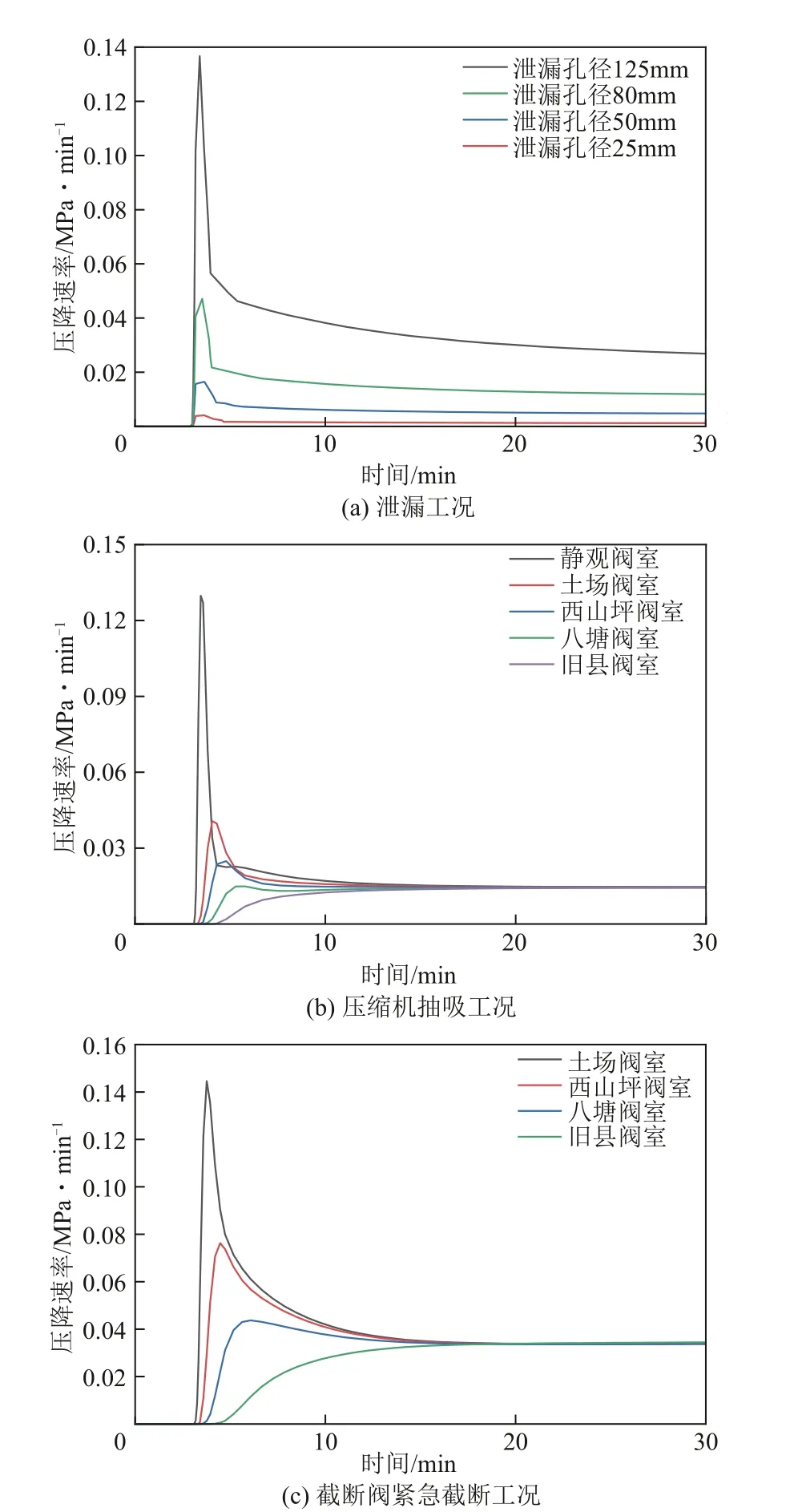
圖4 不同工況下閥室的壓降速率曲線
2 泄漏信號的智能識別模型
2.1 支持向量機模型
支持向量機(support vector machine,SVM)屬于機器學習模型的一種,近年來被廣泛應用于模式識別領域中的數據分類問題。SVM的目標是找到一個分類超平面,使訓練集中的點盡可能遠離它。實際情況中大部分的分類問題為線性不可分問題,在解決這類問題時SVM 中的核函數可以將樣本數據從原始空間映射到高維空間,使原始的樣本數據在高維空間中轉變為線性可分的情況。實際情況中,管道泄漏屬于小概率事件,能夠采集到的壓降速率信號樣本有限。而支持向量機恰好適用于解決小樣本、非線性的分類問題,在管道泄漏識別領域具有一定的優勢。非線性分類問題的分類超平面的表達式如式(4)所示。
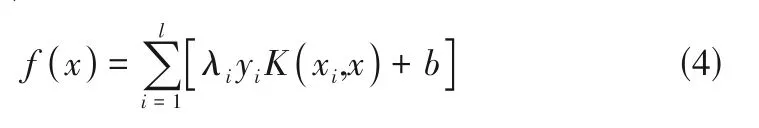
2.2 TLBO算法的優化
支持向量機在處理分類問題時,通常要對其內部的懲罰因子和核函數參數進行優化。相比于粒子群算法和遺傳算法,教與學優化算法(teaching-learning-based optimization,TLBO)因其具有更高的尋優精度、收斂速度和參數設置簡單等優點而被廣泛關注。TLBO 算法模擬了課堂中學生從老師和其余學生處獲取知識的過程,學生的成績(適應度值)在學習過程中不斷提高,最終使學生在目標函數處的表現不斷接近全局最優值。該算法由教師階段和學生階段兩個階段組成。
教師階段是將每次迭代中成績最高的學生作為老師,其他同學不斷向老師學習進而提高班級平均成績的過程。該過程的數學表達式如式(5)、式(6)所示。
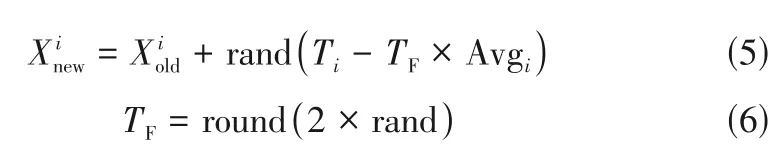
式中,Xn和Xo分別為向老師學習后和學習前的學生個體,為[0,1]間的隨機數;為學習因子,取1或2。
學生階段是兩個隨機的學生X和X間相互學習的過程,每個學生都能從比自己成績更好的學生處獲得新知識。該過程的數學表達式如式(7)所示。

雖然TLBO算法具有參數少、計算精度高等優點,但是在求解時容易陷入全局最優解。因為TLBO 算法使用隨機初始化的方法產生種群個體,使粒子分布不均勻,如果初始種群沒覆蓋到全局最優解且在有限的迭代次數內沒有搜索到最優解,就會導致算法過早收斂、求解精度低等問題。而且TLBO 算法平衡全局搜索和局部搜索的能力較差,容易使算法陷入局部最優解。因此,為進一步提高壓降速率信號識別模型分類的準確率,從種群初始化和平衡局部與全局尋優能力兩個方面對TLBO算法進行改進。
2.2.1 改進的Tent混沌映射
研究顯示,利用混沌映射對種群進行初始化會影響算法的整個過程,而且產生的變量具有較強的遍歷性,常常能取得比偽隨機數更好的效果。標準的Tent混沌映射如式(8)所示。

式中,Z為第個混沌變量,取值范圍為[0,1];為(0,1)之間的隨機數,取0.4。
然而,標準Tent 混沌映射產生的混沌粒子在[0,1]區間內分布仍不夠均勻,遍歷性還有待提升。因此,對標準Tent 混沌映射進行了改進以提高初始種群粒子的均勻性,如式(9)、式(10)所示。

式中,為粒子轉移范圍的下界;rand為[0,1]之間的隨機數。
如圖5所示,對比了標準Tent混沌映射和改進的Tent混沌映射,均產生100個混沌變量,將區間按[0,0.1),(0.1,0.2],…,(0.9,1]分為10個區間,統計了粒子在各區間分布的個數。
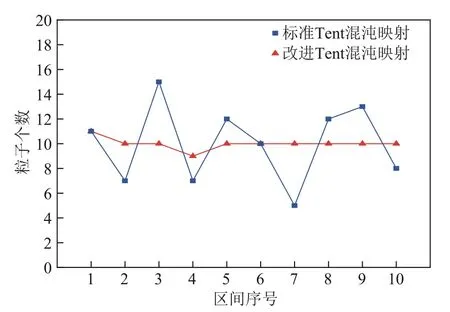
圖5 粒子在各區間分布情況
由圖5可以看到,使用改進的Tent混沌映射產生的變量在各區間的分布較改進前的更加均勻,具有更好的遍歷性。基于改進的Tent 混沌映射對種群進行初始化的公式如式(11)所示。

式中,為變量的最小值;為變量的最大值。
2.2.2 自適應慣性權重函數
慣性權重的概念在首次提出時就引入了PSO算法中,隨后大量研究證明,慣性權重能夠很好地平衡算法的全局和局部搜索能力。在此基礎上,以最優個體適應度值的更新率和迭代步數作為自變量,提出了自適應慣性權重調節函數,并將其引入到TLBO算法中,具體函數如式(12)、式(13)所示。
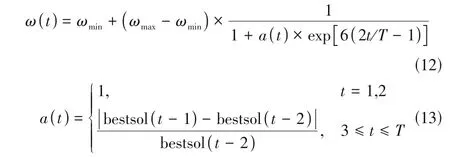
式中,()為第次迭代時的慣性權重;為最小慣性權重,取0.9;為最大慣性權重,取0.1;為最大迭代次數;()為種群最優個體適應度值的更新程度;bestsol(-1)為第-1 次迭代時最優個體的適應度值;bestsol(-2)為第-2 次迭代時最優個體的適應度值。
相應地,式(5)變為式(14)。

當相鄰兩次迭代最優個體的適應度值變化很小或不變時,算法可能陷入局部最優,增大慣性權重,可以使種群跳出局部最優。從圖6 中可以看到,自適應慣性權重函數還保證了算法在迭代前期擁有較大的慣性權重,提高了全局搜索能力,在迭代后期擁有較小的慣性權重,提高了局部搜索能力,有利于種群向最優解逼近。
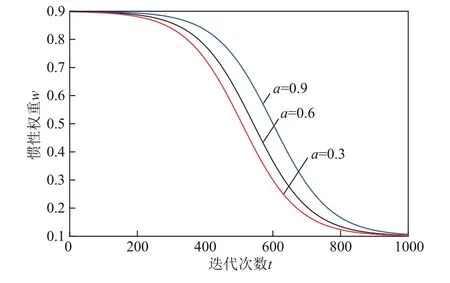
圖6 自適應慣性權重函數曲線
圖7為改進的教與學優化算法流程。與改進前的教與學優化算法相比,改進后的算法在種群的初始化階段使用改進的Tent 混沌映射替代了之前的偽隨機數法。同時,在教師階段和學生階段的計算公式中,均引入了自適應慣性權重,進一步提升了算法的尋優性能。
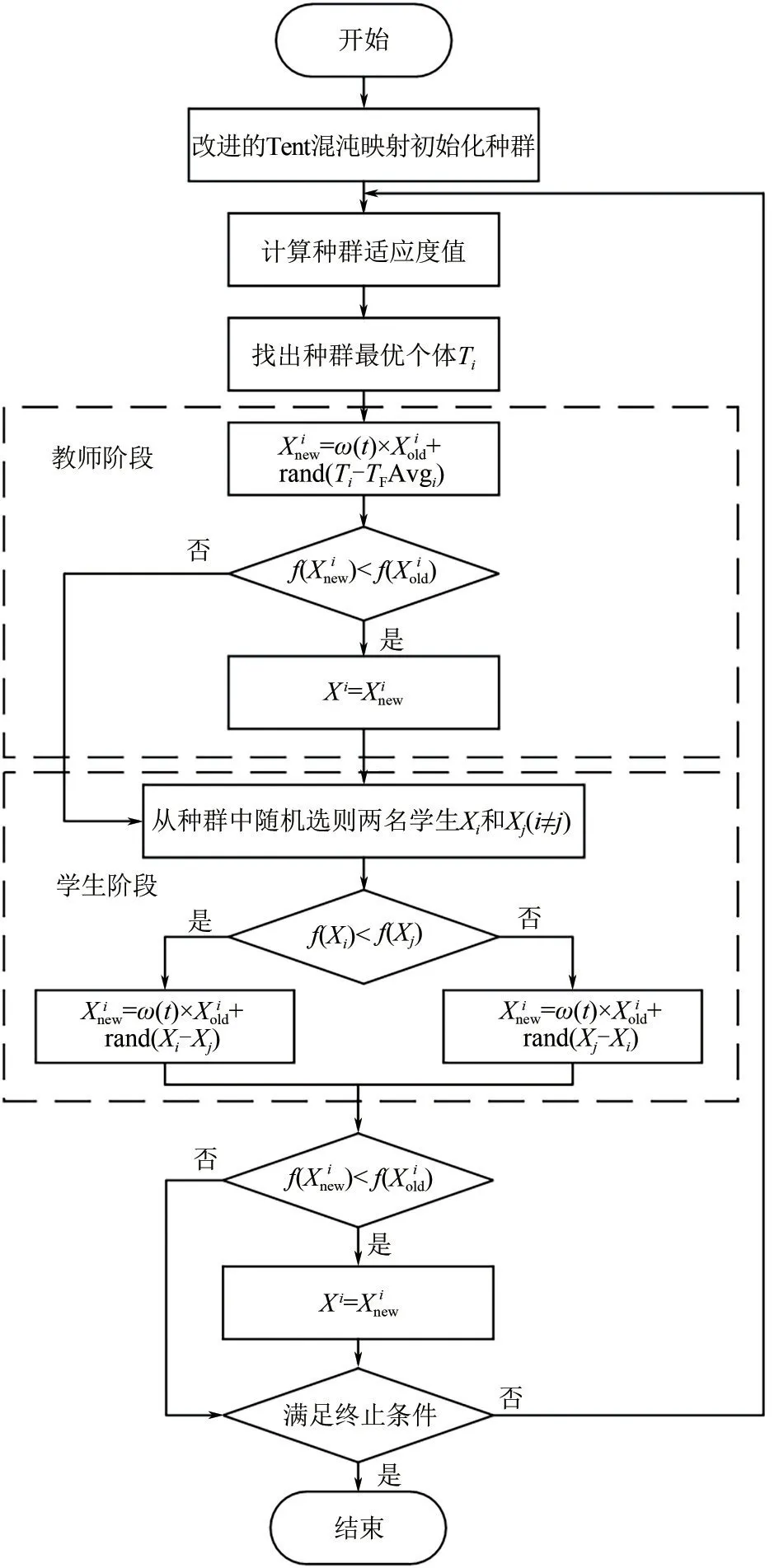
圖7 改進的教與學優化算法流程
2.3 改進算法的測試結果與分析
為檢驗改進的教與學優化算法(improved teaching-learning-based optimization,ITLBO)的尋優能力,選用:Sphere、:Sum Square、:Schwefel 2.22、:Ackley、:Griewank、:Rastrigin共6個常用的benchmark 測試函數對算法進行測試,這些函數的理論最小值均為0。將測試結果與使用教與學優化算法、粒子群算法(particle swarm optimization,PSO)和遺傳算法(genetic algorithm,GA)的結果進行了對比。所有優化算法的種群大小均為50,迭代次數均為1000,各算法在每個測試函數上均獨立運行30次,測試環境保持一致,表2統計了維度為二維時各算法對不同函數尋優結果的平均值和方差。
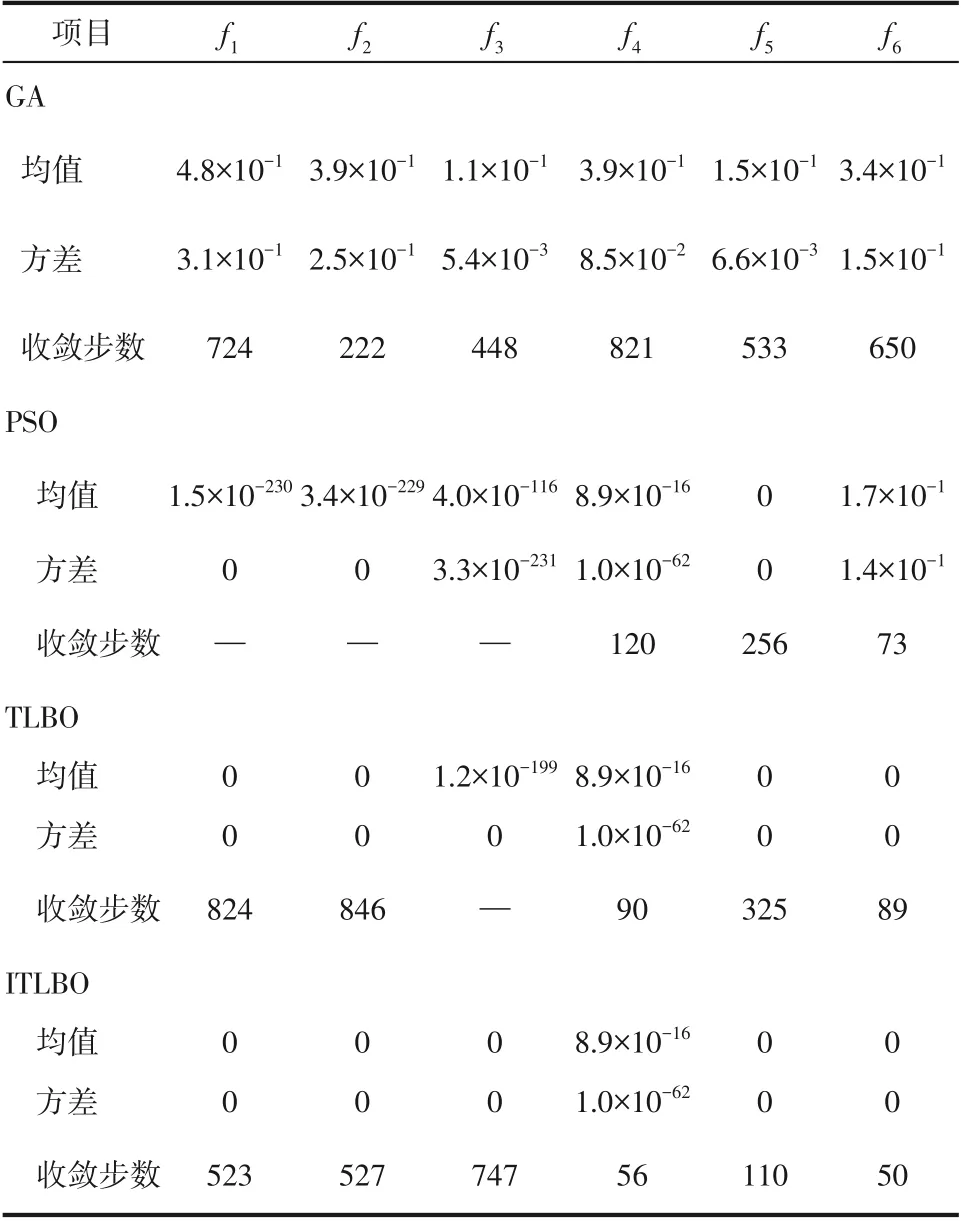
表2 benchmark函數測試結果
以函數為例,圖8為4種不同算法優化時的收斂曲線圖。當函數維度為二維時,從表2 和圖8中可以看到,對于單峰函數和,TLBO 算法和ITLBO算法均可以找到全局最優解,但ITLBO算法的收斂速度更快,而GA 和PSO 算法在有限的迭代步數內沒有找到全局最優解;對于單峰函數,只有ITLBO算法在有限的迭代步數內找到了全局最優解;對于多峰函數,GA、PSO、TLBO、ITLBO算法均沒有找到全局最優解,但ITLBO算法的收斂速度最快;對于多峰函數,PSO、TLBO、ITLBO 算法均找到了全局最優解,但ITLBO算法的收斂速度最快;對于多峰函數,TLBO 和ITLBO 算法均可以找到全局最優解,但ITLBO 算法的收斂速度更快。

圖8 f1函數的收斂曲線
計算結果顯示,ITLBO算法始終能找到大部分單峰函數和多峰函數的全局最優值,尋優結果的精度和收斂速度均優于改進前的TLBO算法和其他算法,說明提出的ITLBO算法具有較好的魯棒性和穩定性,算法的有效性得到了驗證。
3 案例分析
3.1 支持向量機識別壓降速率信號流程
支持向量機模型對壓降速率信號分類的準確率受到內部懲罰系數和核函數參數取值的影響。因此,分別使用GA、PSO、TLBO 和ITLBO 算法求解這兩個參數的最優值,并將分類結果進行對比。圖9為支持向量機識別不同工況壓降速率信號的過程,具體步驟如下:首先,為保證壓降速率信號具有多樣性,選取管道泄漏、壓縮機抽吸和截斷閥緊急截斷工況下不同閥室的壓降速率信號各200 組(共600 組)作為原始信號,這些信號均勻地覆蓋了輸量為(300~2100)×10m3/d、壓力為5~10MPa、泄漏孔徑為25~125mm、泄漏位置為兩閥室間10%~70%的位置、壓縮比為1.5~3.0 的邊界條件。其次,由于采集到的壓降速率信號維度較高,因此需要使用奇異值分解對壓降速率信號進行特征提取。式(16)為特征提取過程中構建的軌跡矩陣的表達式,對其求解即可得到該條壓降速率信號的特征信號。為了避免數量級的影響,還需對所有的特征信號進行歸一化處理,歸一化處理的表達式如式(17)。

圖9 SVM識別壓降速率信號過程

式中,,,…,x為各時刻對應的壓降速率;為時間序列,即壓降速率信號的長度,取60;為窗口長度,取10。

式中,為特征信號中的最小值;為特征信號中的最大值;為歸一化的下限,取-1;為歸一化的上限,取1。
然后均勻地將3類工況的特征信號各取70%作為訓練集(共420組)進行分類器訓練,剩余信號作為測試集(共180組)測試分類器的準確率,保證了訓練集內的各類工況在測試集里都有與之對應的測試信號,使測試結果具有公平性。最后,使用優化算法優化支持向量機模型內的懲罰系數和核函數參數,得到識別不同工況壓降速率信號的支持向量機模型后,將訓練集輸入模型中進行模型的訓練,再使用測試集對模型的分類效果進行測試。
3.2 結果分析
按照上述步驟,對模型的分類效果進行測試。在尋優過程中,初始種群數量為30,迭代步數為80,和的尋優范圍為[0.01,100]。支持向量機內其他參數固定,其中核函數類型為RBF 核函數,折交叉驗證為5折,各算法優化的模型均獨立運行30 次,取分類準確率的平均值作為結果,優化結果如表3所示。
由表3可知,ITLBO 算法優化的管道泄漏識別模型的準確率最高,整體平均分類準確率為98.5%,相比于TLBO算法提高了4.2%,且明顯優于PSO和GA 算法。圖10顯示,ITLBO 算法優化模型的收斂步數為15,TLBO 為19,PSO 為46,GA 為58,說明ITLBO算法優化的模型較其他模型具有更快的收斂速度。應用結果與benchmark 函數測試結果一致,證明了ITLBO算法優化的泄漏信號識別模型較其他算法優化的模型在分類準確率和收斂速度上都有所提高。

表3 不同優化算法下模型的分類結果

圖10 不同算法優化模型的收斂曲線
圖11 為ITLBO 算法優化的管道泄漏信號識別模型的分類結果,圖中縱坐標“1”代表泄漏工況、“0”代表壓縮機抽吸工況、“-1”代表截斷閥緊急截斷工況,每種工況各有60 組測試信號。對于泄漏工況,測試信號的泄漏孔徑為25~125mm,壓降速率為0.001~0.1MPa/min,其中有1 組誤識別為壓縮機抽吸信號,準確率為98.3%;對于壓縮機抽吸工況,測試信號的壓縮比為1.5~3.0,壓降速率為0.001~0.15MPa/min,其中有2 組誤識別為泄漏工況,準確率為96.7%;對于截斷閥緊急截斷工況,測試信號的壓降速率為0.02~0.1MPa/min,識別準確率為100%。
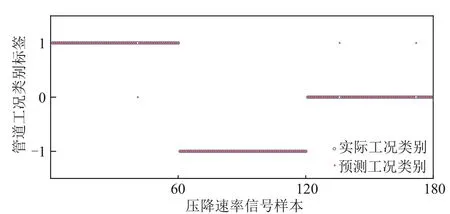
圖11 ITLBO-SVM模型識別結果(相國寺儲氣庫)
泄漏工況中識別錯誤的信號為50mm 泄漏孔徑的信號,壓降速率為0.01MPa/min;壓縮機抽吸工況中識別錯誤的信號為壓縮比1.5 時閥室的壓降速率信號,壓降速率分別為0.003MPa/min 和0.006MPa/min,分別對應泄漏孔徑25mm 和50mm時的壓降速率,這些信號的壓降速率均小于0.01MPa/min。模擬了大量壓降速率信號后發現,管段泄漏孔徑小于50mm的上下游閥室、壓縮機抽吸時距離壓氣站越遠的閥室和距緊急截斷的閥室越遠的閥室,它們采集到的壓降速率信號普遍小于0.01MPa/min,可能會出現個別信號識別不準確的情況。
如圖12 所示,當壓降速率小于0.01MPa/min時,壓縮機抽吸工況和泄漏工況的壓降速率信號在數值上和曲線特征上相近,進而導致模型分類失誤。為此,針對50mm以下的小孔泄漏,建議通過氣液聯動閥與SCADA 系統數據監測的特征進行綜合判斷。例如,壓縮機抽吸時的特征表現為各閥室的壓降速率依次減小;管道泄漏時的特征表現為沿線某一個閥室的壓降速率突然增大,其余閥室壓降速率不變。根據這些特征可綜合判斷是否需要遠程控制截斷閥關斷。
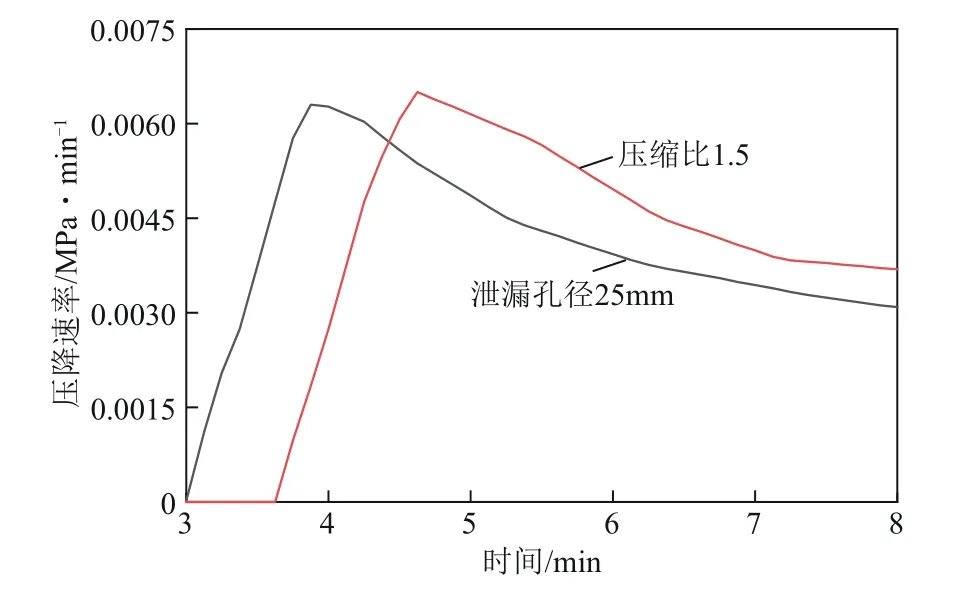
圖12 壓降速率信號對比
3.3 模型普適性驗證
基于陜京三線實際運行數據,建立了榆林首站至臨縣壓氣站的仿真模型,管線全長181.1km,管徑1016mm,沿線共有8 座閥室。同樣模擬了泄漏工況、壓縮機抽吸工況和截斷閥緊急截斷工況,所研究的輸量為(2300~3450)×10m3/d、壓力為7.5~8.8MPa、泄漏孔徑為25~125mm、泄漏位置為兩閥室間10%~70%的位置、壓縮比為1.5~3.0。3 類工況各模擬了30 組壓降速率信號,作為測試集對模型進行驗證,見圖13。

圖13 ITLBO-SVM模型識別結果(陜京三線)
從圖13 中可以看到,模型對于管道泄漏工況和截斷閥緊急截斷工況識別的準確率為100%;而對于壓縮機抽吸工況,有1組信號被錯誤識別,識別的準確率為96.7%。該信號為壓縮比為1.5 時遠離壓氣站的某閥室的壓降速率信號,壓降速率為0.008MPa/min,被誤識別為50mm 的泄漏工況壓降速率信號,說明此時兩種工況的壓降速率信號近似。從模型整體的識別效果來看,90 組信號中僅有1 組信號識別錯誤,模型整體識別的準確率為98.9%,說明提出的模型能夠適應不同屬性的管道,模型具有一定的普適性。
4 結論
(1)提出的混沌映射和自適應慣性權重的教與學優化算法在種群初始化和平衡全局與局部最優能力方面得到提升。優化后的支持向量機模型對管道泄漏、壓縮機抽吸、截斷閥緊急截斷工況識別的準確率為98.5%,較優化前提高了4.2%,模型具有一定的普適性。
(2)模型可識別當量直徑為50~125mm的小孔泄漏,壓降速率范圍0.01~0.1MPa/min,識別準確率為100%。
(3)模型可識別的壓縮機抽吸工況壓降速率范圍為0.001~0.15MPa/min,識別準確率為96.7%;可識別的截斷閥緊急截斷工況壓降速率范圍為0.02~0.1MPa/min,識別準確率為100%。
(4)當泄漏孔徑小于50mm、壓降速率小于0.01MPa/min 時,管道泄漏工況和壓縮機抽吸工況的壓降速率信號特征相似,導致模型對個別信號分類不準,此時建議通過氣液聯動閥與SCADA 系統監測數據綜合判斷管道是否泄漏。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年11期)2018-08-04 03:25:42
