基于TD3-PER的混合動力履帶車輛能量管理*
2022-10-11 07:44:32張旭東杜國棟孫文景
汽車工程 2022年9期
張 彬,鄒 淵,張旭東,杜國棟,孫文景,孫 巍
(北京理工大學機械與車輛學院,北京100081)
前言
混合動力電動履帶車輛(HETV)具有結構簡單、可靠性高、布置靈活等優(yōu)點。混合動力方案兼具了燃油車和純電動車的優(yōu)點,通過合適的能量管理策略(EMS)能使發(fā)動機工作在較經濟的狀態(tài),提高車輛的燃油經濟性和續(xù)航里程。對于油電混合系統(tǒng),EMS根據不同部件的狀態(tài)反饋,實現不同動力源的功率分配,達到提高燃油經濟性、減少排放等目的。由于各動力源的特性差異,各動力源之間的功率分配也不同。因此,EMS是最大化混合動力系統(tǒng)燃油經濟性、充分發(fā)揮混合動力系統(tǒng)的綜合性能的關鍵技術之一。
EMS的主要目的是合理地分配發(fā)動機和動力電池的輸出功率,提高車輛的燃油經濟性和續(xù)航里程。近年來出現的EMS主要分為基于規(guī)則的策略和基于優(yōu)化的策略兩大類。基于規(guī)則的策略具有良好的實時性和可靠性,在工程實踐中得到廣泛的應用,但其對不同工況和車型的可移植性較差,且很難取得最優(yōu)的控制效果。目前大部分EMS的研究集中在基于優(yōu)化的策略。基于優(yōu)化的策略旨在建立系統(tǒng)目標函數和約束條件后,通過優(yōu)化使目標成本最小化。但基于優(yōu)化的策略計算量大,須提前知道整個工況,對不同車型、不同運行工況的移植性差。但它可得到理論最優(yōu)或近似最優(yōu)解,常被作為參考基準用于評估或改進其他能量管理策略,如動態(tài)規(guī)劃(DP)算法等。
混合動力系統(tǒng)是典型的非線性多場耦合的復雜系統(tǒng),需要更加精細和智能的算法來構建EMS。強化學習(RL)算法在處理非線性、強耦合、高復雜度問題時更有優(yōu)勢,最近多用于解決能量管理問題。Liu等在混合動力履帶車輛上采用基于Q-learning和Dyna的能量管理策略,此策略對發(fā)動機燃油經濟性有一定的提高。但RL算法存在由離散化引起的“維數災害”,會導致訓練時間的大幅增加且難以收斂。為解決此問題,Zhao等采用基于深度強化學習(DRL)的能量管理策略,并將基于DRL算法的策略應用到混合動力公交車上,燃油經濟性相對于Q學習算法提高了10%,訓練時間也大幅縮短。雖然基于DRL的策略在狀態(tài)空間是連續(xù)的,但其控制量仍需降維和離散處理,導致了控制精度的降低。同時由于最大化值函數逼近,DRL算法存在動作值過優(yōu)估計的問題,這可能會導致不穩(wěn)定或效果不佳的現象。為解決過優(yōu)估計問題,Han等應用基于雙深度強化學習(DDQL)的EMS到混合動力履帶車上,與DQL算法相比燃油經濟性提高了7.1%。為解決控制量離散問題,Zhang等提出基于深度確定性策略梯度(DDPG)的EMS,仿真結果表明該策略能實現更細化的油門開度控制,進一步提高燃油經濟性。但同DQL一樣,DDPG也存在動作值過優(yōu)估計的問題,可能導致訓練不穩(wěn)定。
為解決上述算法存在的問題,進一步提高車輛的燃油經濟性、獲得更好的電池SOC保持效果,提出基于優(yōu)先經驗采樣的雙延遲深度確定性策略梯度(TD3-PER)的能量管理策略,將其應用于串聯(lián)式混合動力履帶車輛。基于雙延遲深度確定性策略梯度(TD3)的策略能實現狀態(tài)空間和動作空間的連續(xù)控制,同時解決了動作值過優(yōu)估計的問題。為加快策略的收斂速度和達到更高的燃油經濟性,采用優(yōu)先經驗采樣算法(PER)來加速網絡訓練。
1 車輛參數配置和系統(tǒng)建模
1.1 車輛配置參數
圖1為課題組自研的串聯(lián)式混合動力電動履帶車輛(SHETV)。該車輛采用模塊化和動力履帶設計,將組件全布置于兩邊的履帶艙內,為中間平臺省出更多的承載空間。圖2為動力系統(tǒng)拓撲圖,主要包括發(fā)動機-發(fā)電機組、電池、功率分配單元、驅動電機總成和整車控制單元(VCU)。驅動電機的額定功率是25 kW,轉速范圍為2 000~2 500 r/min。發(fā)電機組通過AC/DC整流單元向直流母線提供電能,而電池組直接向母線提供電能。母線電壓為兩個驅動電機提供電能,用于驅動主動輪旋轉。VCU負責整車的控制策略、能量管理策略和功率匹配,是提高燃油經濟性的核心。表1為整車及其主要部件的參數。
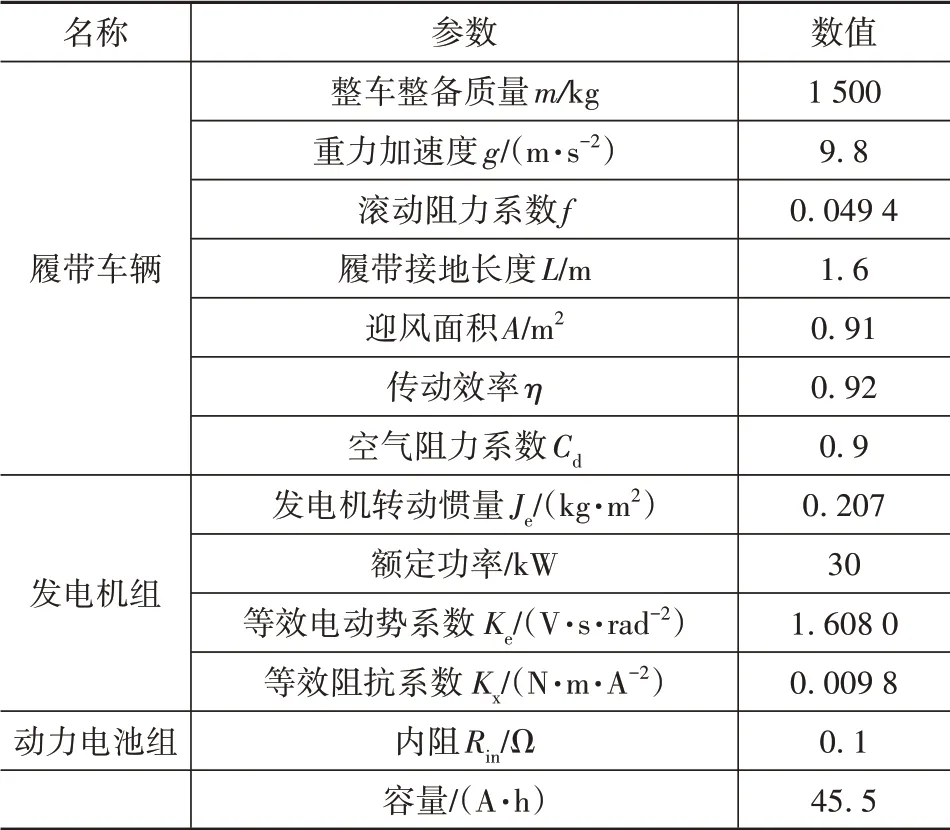
表1 串聯(lián)式混合動力履帶車輛主要參數

圖1 串聯(lián)式混合動力電動履帶車輛
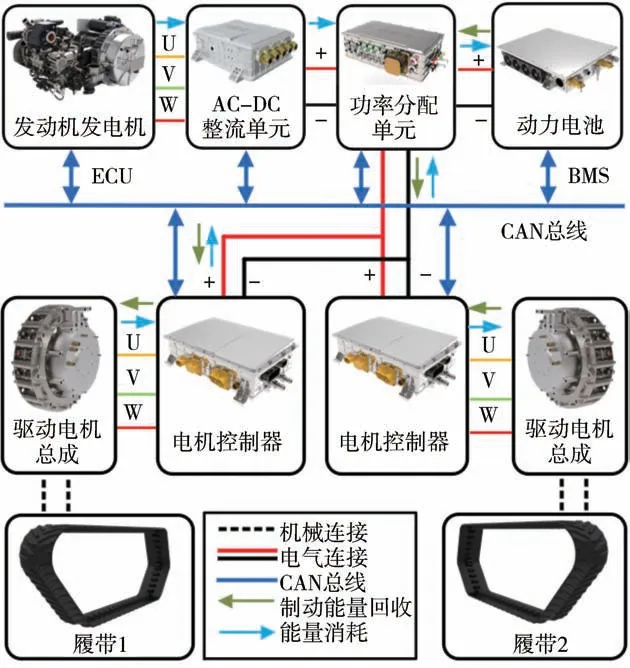
圖2 串聯(lián)式混合動力系統(tǒng)拓撲圖
1.2 車輛動力學模型和傳動系統(tǒng)模型
履帶車輛的動力學模型如圖3所示,圖中為橫擺角速度,為履帶車輛軌距。
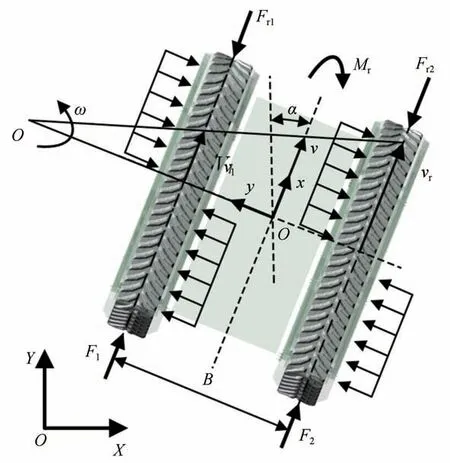
圖3 履帶車輛動力學模型
車輛的受力主要包括滾動阻力與、驅動力與、加速阻力、空氣阻力、坡度阻力和轉向阻力矩。和分別為左、右側履帶的速度。履帶車輛的動力學方程為
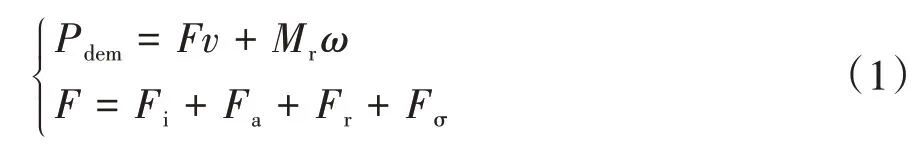
式中:為履帶車輛的需求功率;為縱向驅動力;為車輛的平均速度,=(+)/2。
、、、和的計算公式為
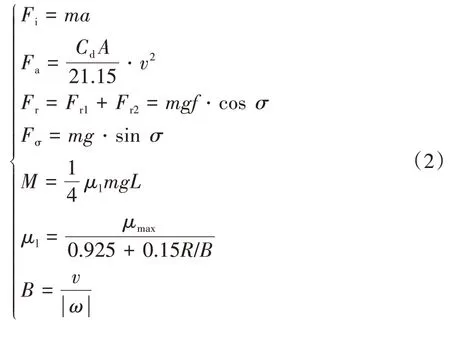
式中:為車輛加速度;為轉向半徑;為車輛受到的總滾動阻力;σ為道路坡度角;為車輛做半徑≥/2轉向時的轉向阻力系數;為車輛做半徑為/2轉向時的轉向阻力系數;車輛做半徑為0-/2轉向時轉向阻力系數。
根據功率平衡關系,直流母線需求功率和動力源輸出功率滿足:
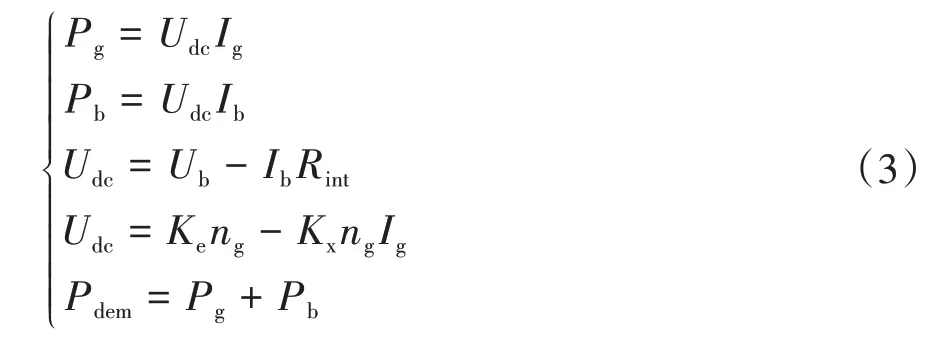
式中:和分別為發(fā)電機功率和電池組功率;為直流母線電壓;為發(fā)電機電流;為電池電流;和分別為電池的開路電壓和內阻;和分別為發(fā)電機等效電動勢系數和等效阻抗系數;為發(fā)電機轉速。
關于履帶車輛傳動系統(tǒng)中的發(fā)動機-發(fā)電機組模型、動力電池模型和驅動電機模型在以往的成果中已有詳細的介紹,請詳見文獻[17],在此不再贅述。
在Simulink中搭建車輛動力學仿真模型和傳動系統(tǒng)模型,如圖4所示。將實車采集的數據作為SHETV前向模型的目標工況進行仿真,仿真數據和實車數據的對比結果如圖5所示。從圖5(a)可知,車輛的仿真模型可很好地跟隨實測速度。由于實測環(huán)境存在噪聲等諸多影響,發(fā)動機轉速、電池SOC、母線電壓仿真數據與實測數據有一點偏差,但總體變化趨勢很好地吻合。說明所建立的模型能反映實車的基本物理特性。此外,EMS的開發(fā)主要關注需求功率的分配,允許模型有一定的偏差,因此建立的仿真模型可作為后續(xù)策略開發(fā)的驗證模型。
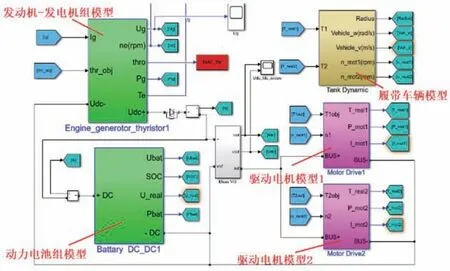
圖4 車輛Simulink模型
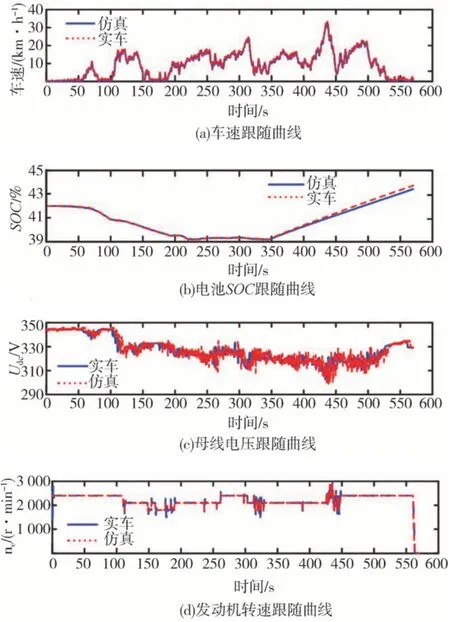
圖5 仿真數據與實車數據的對比曲線
1.3 能量管理問題
對所研究的SHETV,EMS的首要目標是找到最優(yōu)策略*在滿足系統(tǒng)性能要求和保持電池波動不大的情況下最小化燃油消耗。因此成本函數定義為燃油消耗和電池變化的組合:
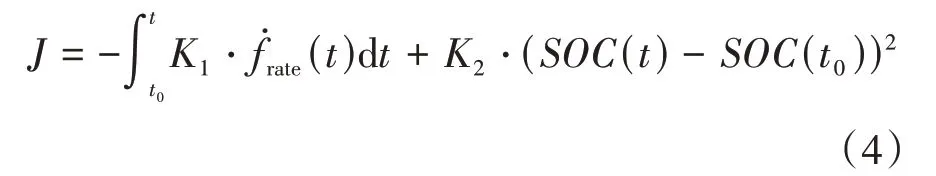

系統(tǒng)約束條件為
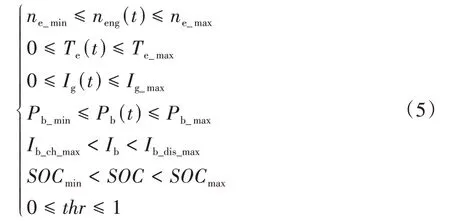
式中:和分別為發(fā)動機最低和最高轉速;為發(fā)動機最大轉矩;為發(fā)電機最大放電電流;和分別為電池最小功率和最大功率;和分別為電池最大充電和放電電流;為電子油門開度系數。
2 基于TD3-PER算法的能量管理策略研究
圖6為基于深度強化學習(DRL)的EMS理論框架。TD3算法是基于Actor-Critic框架的DRL算法,圖7為基于TD3-PER的EMS具體框架。選取車速、發(fā)電機轉速、電池荷電狀態(tài)和車輛當前時刻的需求功率作為狀態(tài)矢量,即s=[,,,]。為提高算法訓練時的收斂速度,對、和進行歸一化處理。履帶車輛為EMS中的環(huán)境,智能體根據車輛的狀態(tài)s和智能體中的策略在每步選擇一個動作a作用于車輛,車輛反饋即時獎勵r和下一刻狀態(tài)s。經驗池(replay buffer)存儲當前的狀態(tài)、動作、即時獎勵、下一刻狀態(tài)矢量(s,a,r,s),形成歷史經驗數據;通過優(yōu)先經驗采樣方式從經驗池中抽取歷史數據送入智能體中的網絡進行訓練。智能體通過與環(huán)境的不斷交互來調整網絡權重得到最優(yōu)策略,即燃油消耗最低且具有保持能力。經驗池的使用有效消除了相鄰狀態(tài)間的相關性,同時優(yōu)先經驗采樣(PER)算法的引入加速了網絡的收斂并提高了訓練的效果。
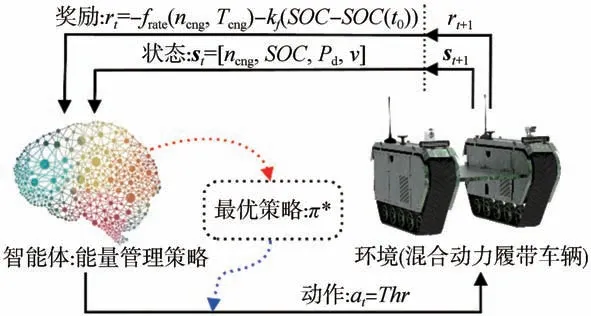
圖6 基于深度強化學習算法理論框架

圖7 基于TD3-PER的能量管理策略框架
TD3算法包含策略網絡Actor和評判網絡Critic。其中Actor網絡以車輛的狀態(tài)作為輸入并根據網絡參數輸出控制動作,Critic網絡用于評判Actor網絡執(zhí)行動作的優(yōu)劣。TD3算法能同時處理連續(xù)動作空間和策略值函數過優(yōu)估計的問題。EMS的控制變量為發(fā)動機電子油門開度,因此TD3算法的控制動作為[0,1]的連續(xù)值。具體來說,TD3算法是在DDPG的基礎上,同時對Actor網絡和Critic網絡進行優(yōu)化,主要包括:(1)Critic網絡包含Critic1和Critic2兩個獨立網絡,通過選取兩個網絡中最小的值作為目標值,解決了DDPG中對值持續(xù)過優(yōu)估計的問題,如式(6)所示;(2)算法采用兩個隨機噪聲,其中在線策略網絡的隨機噪聲用來保證動作的探索能力,而目標策略網絡中加入隨機噪聲,則用來增加算法的穩(wěn)定性;(3)降低了在線策略網絡的更新頻率,使得actor的訓練更加穩(wěn)定。
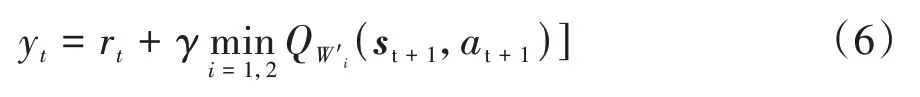
式中:r為時刻的即時獎勵;為折扣因子;Q(s,a)為根據+1時刻的狀態(tài)值s、動作值a和網絡參數'得到的目標網絡的值。
目標函數為
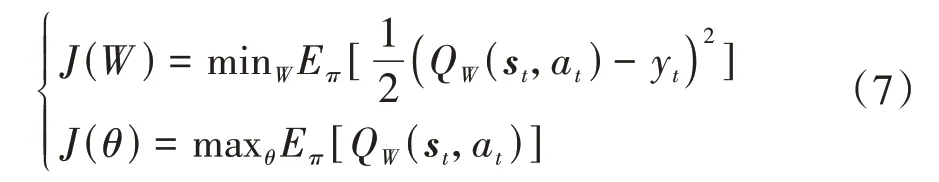
在線網絡參數的更新方式為梯度下降法。Critic網絡采用時序差分誤差(TD-error)的均方差來評價近似的準確性。Critic網絡的權重參數、通過梯度下降法最小化損失函數()來更新,如式(8)和式(9)所示。在線Actor網絡參數的更新通過梯度上升法使值關于迭代增加:
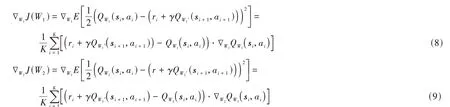
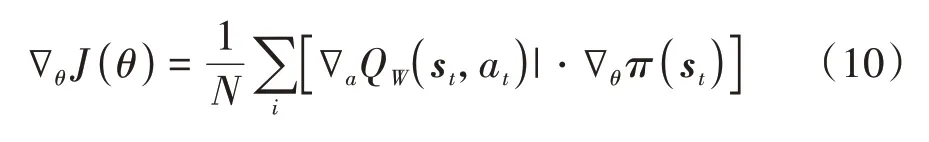
目標網絡的權重參數更新采用滑動平均的軟更新方式,如式(11)所示,將在線網絡中的參數以一定的權重更新到目標網絡中:
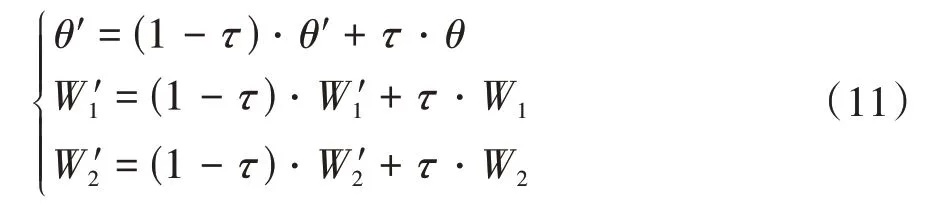
式中:為軟更新參數;為在線策略網絡參數;'為目標策略網絡參數;和分別為在線網絡1和在線網絡2的網絡參數;'和'分別為目標網絡1和目標網絡2的網絡參數。
在傳統(tǒng)的DRL算法中,從經驗池中抽取片段時是以等概率隨機抽取。事實上經驗池中片段的難易程度和從中學習到的知識都不同。為加速網絡訓練且得到更好的訓練效果,本文中采用了優(yōu)先經驗采樣(PER)算法,并結合不同的經驗給予一定的權重,例如在交互過程中表現越差的片段給予更高的權重,則這些片段有更高的概率被網絡重新學習,這樣模型的學習效率就會大大提高。相反,在交互過程中表現較好的片段給予較低的采樣權重。
TD-error的值越大,片段越有價值。因此,用TD-error的絕對值來表征片段的重要性。TD-error的值σ為
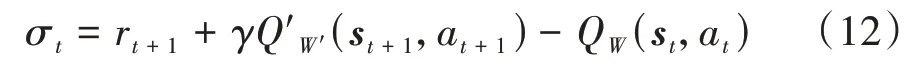
式中為折扣因子。
經驗片段的優(yōu)先級有兩種形式:(1)直接用TDerror的絕對值|σ|來表征,如式(13)所示,為較小的正常數,用于保證在邊緣概率為0的片段也有一定的概率被采樣;(2)根據|σ|的大小對經驗樣本進行排序,然后得到樣本的序列(),如式(14)所示的優(yōu)先級指標D。第2種形式具有更好的魯棒性,本文中采用第2種形式。


直接采用式(14)的采樣方式為貪婪抽樣,會導致初始TD-error較小時長時間不被抽樣和TD-error較大時被高頻重復抽樣,從而導致缺乏樣本多樣性。為解決此問題,采用均勻采樣和貪婪抽樣結合的方式,經驗池中每個樣本的采樣概率()為
式中:D為第個樣本的優(yōu)先級指標;為超參數。當為0時為均勻抽樣;當為1時為貪婪抽樣;當0<<1時為兩種采樣的結合。
PER的另一問題是對模型的更新會引入偏差。為使模型更新無偏,引入更新權重:

式中:為經驗池大小;為介于0至1之間的調節(jié)因子,較小時樣本利用率高,較大時更新偏向于無偏。
基于TD3-PER的能量管理策略的流程和有關的偽代碼如表2所示。

表2 TD3-PER算法計算流程
3 仿真與驗證
3.1 TD3-PER算法模型訓練
采用SHETV實車采集的信息作為訓練用的循環(huán)工況,其速度變化曲線和對應的需求功率如圖8所示,工況的總時間為1 000 s,訓練時采樣頻率為10 Hz。最大車速為39.5 km/h,車輛的需求功率范圍為-1.06~15.49 kW。需求功率的負值為混合動力驅動系統(tǒng)的制動能量再生能源。
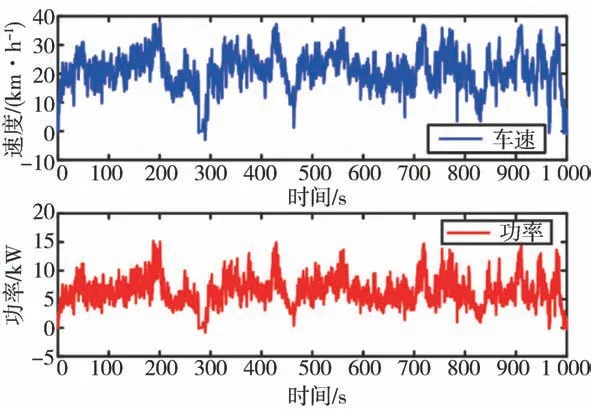
圖8 TD3-PER算法訓練工況
狀態(tài)矢量的初始向量為=[2000,0.75,0,0],將其作為TD3-PER算法的初始向量輸入網絡中進行訓練。TD3-PER算法網絡的超參數如表3所示。圖9為在訓練過程中的回報函數曲線、損失函數曲線和每一回合的油耗值曲線。從圖中可以看出,隨著訓練進程的進行,回報函數不斷增大且油耗值不斷減小,在訓練的第23個回合左右,算法的回報函數曲線和損失函數曲線都趨近于0,這表明算法的訓練已經收斂,相應的控制策略即將達到最優(yōu)值附近。
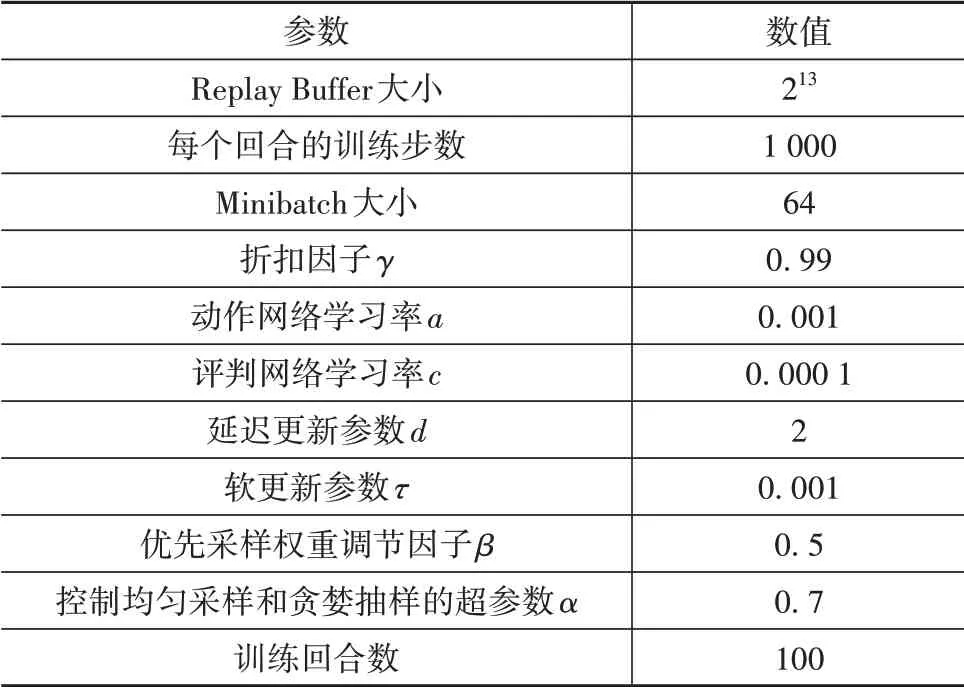
表3 TD3-PER算法網絡超參數定義
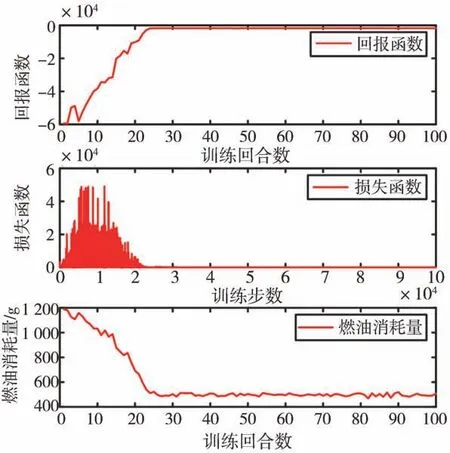
圖9 訓練過程的總回報、損失函數和燃油消耗量
3.2 控制性能對比驗證
為驗證TD3-PER算法的性能,將相同的行駛工況分別作為DP、DDPG、TD3、TD3-PER 4種算法的訓練工況,通過神經網絡訓練后對比其性能,其中基于全局優(yōu)化算法DP的EMS作為其他3種算法的對比基準。圖10為3種算法的動力電池變化曲線。從圖中可以看出,3種算法的變化趨勢具有相似性且變化都不大,這是由于TD3算法為DDPG算法的改進算法,都能實現油門開度的連續(xù)控制。但是基于TD3-PER算法的波動更小,在初始值0.75附近波動。這是由于TD3算法作為DDPG的改進算法,能實現值更穩(wěn)定的迭代,因此能使在初始值附近更小的波動。同時PER算法的加入使TD3算法的訓練過程更快,控制效果更好。
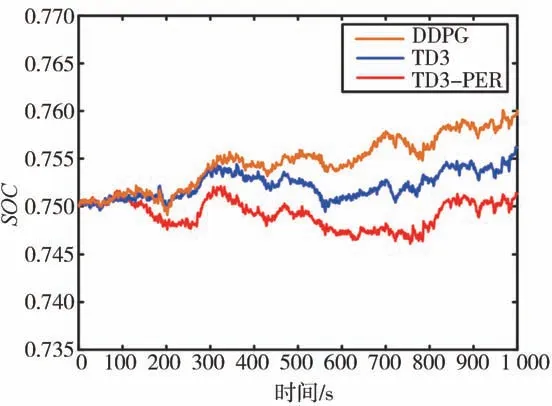
圖10 3種算法的SOC曲線對比
圖11為基于3種算法的EMS的發(fā)動機工作點分布圖。3種算法的發(fā)動機工作點具有一定的相似性,這是由于基于3種算法的EMS在狀態(tài)空間都是連續(xù)的且都能實現油門開度的連續(xù)控制。但TD3算法的發(fā)動機工作點相對于DDPG更多地位于燃油消耗較低的高效區(qū),同時PER算法的加入使得TD3算法的燃油經濟性進一步提升。
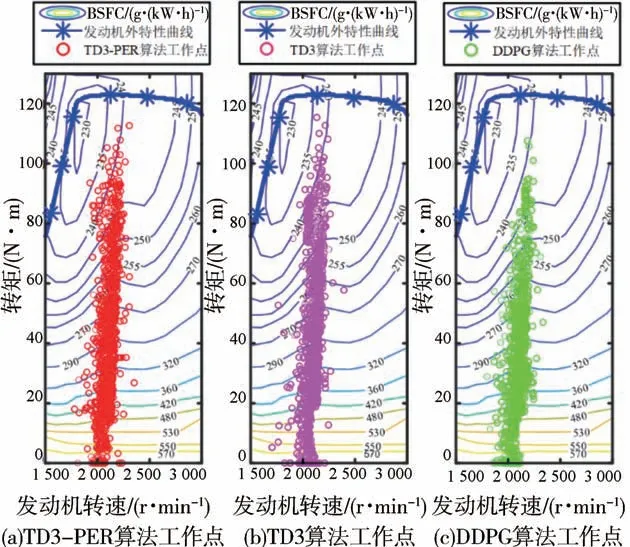
圖11 發(fā)動機工作點分布對比
由于發(fā)動機工作點分布和的終端值不同,4種算法的仿真油耗也存在差異。為消除算法在終端狀態(tài)下的差異,采用修正方法對燃油消耗進行補償。表4是經修正后的燃油消耗量對比。在所給定的真實循環(huán)工況下,DP、DDPG、TD3和TD3-PER算法分別消耗燃油499.02、546.24、532.21和525.01 g,TD3-PER算法的燃油消耗比DDPG降低了3.89%,燃油經濟性達到DP基準的95.05%。同時,相對于離散算法DP,連續(xù)型算法的訓練時間也大大縮短。以上仿真結果表明TD3-PER算法具有更好的優(yōu)化控制效果,驗證了基于TD3-PER算法的能量管理策略的最優(yōu)性和有效性。
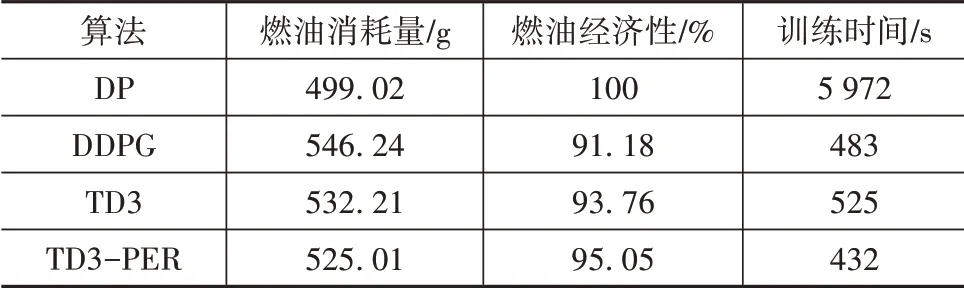
表4 3種算法SOC修正后的燃油消耗量
3.3 基于TD3-PER算法的EMS的適應性驗證
為驗證所提出的能量管理策略的適應性和優(yōu)化性能,在訓練好的TD3-PER網絡參數中采用實車采集的新工況進行仿真對比。新工況信息如圖12所示,工況的最高車速為26 km/h,最大需求功率為14.56 kW,最小功率為-4.21 kW。
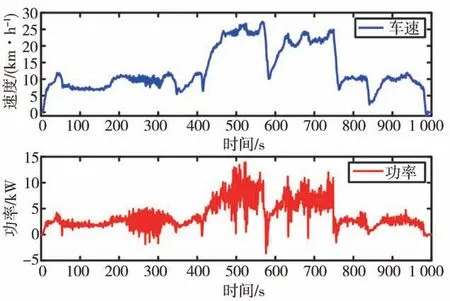
圖12 算法適應性和最優(yōu)性驗證工況
將新的工況輸入到DDPG、TD3、TD3-NAF算法中進行仿真驗證,結果如圖13和圖14所示。從圖13可見,3種算法都能實現較好的保持能力,但TD3-PER算法的波動性更小。從圖14可見,3種對比算法的發(fā)動機工作點分布類似,但相對于DDPG算法,TD3算法和TD3-PER算法使更多的發(fā)動機工作點分布在經濟區(qū)。
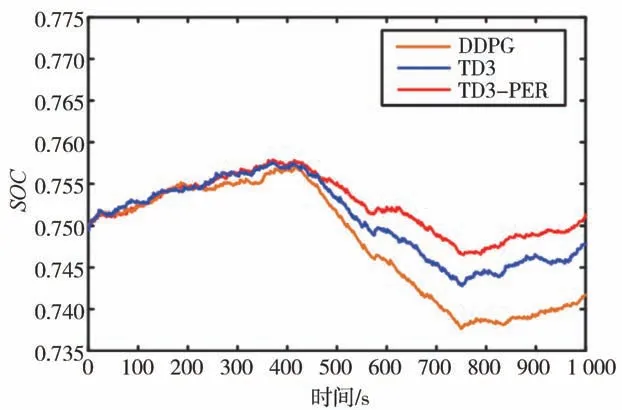
圖13 3種算法的SOC曲線
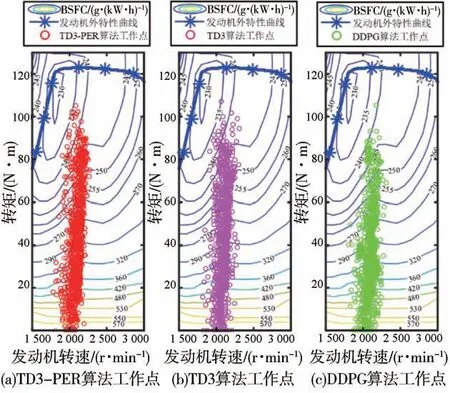
圖14 發(fā)動機工作點分布
采用與3.2節(jié)中同樣的方法修正油耗來消除終端值不同帶來的影響,結果如表5所示。由表可見,TD3-PER修正后的油耗為417.53 g,與TD3算法相比下降了15.7 g,與DDPG算法相比下降了34.11 g。仿真結果表明了TD3-PER算法具有更好的節(jié)油效果,同時也驗證了基于TD3-PER算法對工況的適應能力。
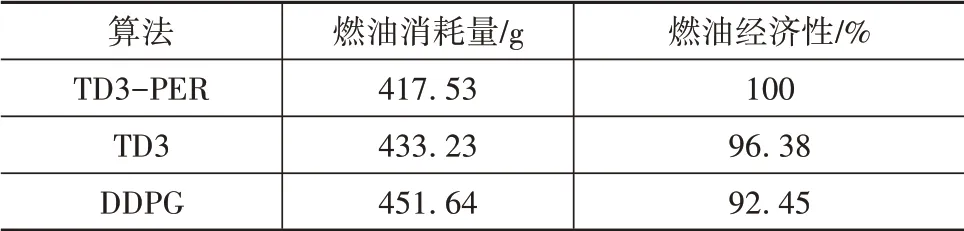
表5 3種算法對于新工況的燃油消耗量
4 結論
為優(yōu)化混合動力電動履帶車輛的燃油經濟性和動力電池性能,提出了一種基于優(yōu)先經驗采樣的雙延遲深度確定性策略梯度(TD3-PER)能量管理策略。TD3算法采用雙Critic網絡解決了DDPG算法過優(yōu)估計問題,PER算法提高了算法的收斂速度和訓練效果。因此,TD3-PER算法解決了能量管理策略無法處理連續(xù)控制和過優(yōu)估計的問題,同時加速了神經網絡的訓練。具體結論如下:
(1)將提出的基于TD3-PER的能量管理策略應用于串聯(lián)式混合動力履帶車輛中,通過實車采集的工況仿真對比了TD3-PER、TD3和DDPG算法的燃油經濟性和電池的波動。基于TD3-PER算法的EMS的燃油經濟性比TD3提高了1.29%、比DDPG提高了3.87%,若以DP算法為基準,可達到95.05%。
(2)通過實車采集的新工況驗證了訓練好的網絡數據的燃油經濟性,TD3-PER算法修正后的油耗比TD3下降了15.7 g,比DDPG下降了34.11 g,同時驗證了算法對于工況的適應性。
為了使TD3-PER算法能更好地適應復雜越野工況,下一步工作將開展在線更新網絡參數的研究,進一步提高算法對于工況的適應性和燃油經濟性。
猜你喜歡
房地產導刊(2022年4期)2022-04-19 09:04:10
汽車工程師(2021年12期)2022-01-17 02:29:58
汽車工程師(2021年11期)2021-12-21 06:23:12
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
四川電力技術(2015年5期)2015-12-19 11:04:54
減速頂與調速技術(2015年4期)2015-03-16 03:39:41
