基于EWT-PSO-Elman耦合模型在徑流預測中的應用
2022-09-29 05:10:50莫崇勛鄧云阮俞理雷興碧麻榮永孫桂凱
科學技術與工程 2022年22期
關鍵詞:模型
莫崇勛, 鄧云, 阮俞理*, 雷興碧, 麻榮永, 孫桂凱
(1.廣西大學土木建筑工程學院, 南寧 530004; 2.廣西大學工程防災與結構安全教育部重點實驗室, 南寧 530004; 3.廣西大學廣西防災減災與工程安全重點實驗室, 南寧 530004)
由于氣候同人類活動等因素的影響,徑流序列常常表現出非平穩性、非線性特征,一般的回歸分析等預測方法較難取得理想的預測結果,因此需要不斷探索并應用新的方法以提高對徑流預測的準確性。Elman神經網絡[1]具有較強計算能力和時變適應能力,較經典非線性模型BP(back propagation)神經網絡,具備更好的全局穩定性,且擁有短期記憶功能等優點。但是,現有Elman算法是以梯度下降法為基準,易導致訓練速度慢和陷入極小點,致使神經網絡訓練容易陷入局部最優。目前遺傳算法[2]、粒子群算法[3]等已試用于Elman關鍵參數優化。李志新等[4]采用GA算法優化Elman參數以解決神經網絡靜態性及訓練算法易陷入局部極值缺陷,構建了GA-Elman預測模型,結果顯示預測平均相對誤差從7.07%降低到5.29%,預測模型性能得到明顯改善。但是,遺傳算法存在參數設置復雜、易過早收斂、效率低等問題。其中,粒子群算法是一種基于迭代的優化算法,無較多參數,容易實現,在一些工程方面已被證明優于遺傳算法[5]。但由于徑流序列復雜性和多周期的特征,僅僅對優化 Elman 參數難以達到較好的效果,因此需要尋求方法挖掘序列中的規律成分和關鍵成分,使得預測精度能進一步提高。
近年來,預測模型的耦合越來越受到水文研究者的關注,以分解算法為基礎,對數據進行預處理降低序列非平穩性來達到提高模型預測精度的目的。如經驗小波分解(empirical mode decomposition, EMD)[6]、集合經驗模態分解(ensemble empirical mode decomposition, EEMD)[7]方法常被應用于信號分解中,但其存在模態混疊、端點效應等特征,經驗小波變換算法(empirical wavelet transform,EWT)[8]具有良好理論基礎,且分解模態少,使得分解后序列更加平穩,減少混合建模的預測誤差。張先起等[9]基于小波分解與Elman網絡的優點,將其構建成組合模型小波分解-Elman,并與CEEMD-Elman 模型、BP模型作對比,并在地下水埋深的預測耦合模型進行驗證,結果表明小波分解-Elman模型的精度最高。鑒于此,現通過對徑流序列進行模態分解,進而建立一種基于EWT、PSO和Elman神經網絡的耦合月徑流預測模型(EWT-PSO-Elman),并將模型應用于西南典型巖溶區澄碧河流域壩首站月徑流預測中,驗證其預測精度和適應性,以期為非平穩、預測提供新思路。
1 基于神經網絡的EWT-PSO-Elman月徑流預測模型
1.1 EWT算法
經驗小波變換(EWT)通過在頻譜上的分割,從而在各頻帶上構建適合的正交小波濾波器組,并且結合了 EMD 的自適應優點,把信號分解成多個具有緊湊支撐特性的頻率特征信息相異的分量[10]。計算步驟如下。
步驟1通過使用最小二乘法處理原始信號,分離出其中的趨勢項,再進行去除。
步驟2對輸入信號頻譜進行傅里葉變換,歸一化至[0,π]。
步驟3設置模態個數M,并且計算其中兩個具有連續性的局部極大值的中間頻率,并將計算值作為頻譜劃分邊界ωn(n=1,2,…,M-1)。
步驟4根據各頻譜分割后的狀態分別構建尺度函數φn(ω)和小波函數ψn(ω);再次使用傅里葉變換計算F(ω)×φn(ω)和F(ω)×ψn(ω),最終得到各分量的時域表達式。
1.2 PSO算法
粒子群算法[11](particle swarm optimization,PSO)是美國的Kennedy和Eberhart受鳥群行為所啟迪并于1995年提出的。粒子群算法是一種全局優化算法,其基于鳥群的覓食行為,通過合作和信息傳遞尋找最優解,其設置參數少,收斂速度快,有較強的全局尋優能力。
Elman神經網絡中網絡連接權重、閾值和隱含層神經元數量會直接影響Elman模型預測精度,通過PSO算法迭代尋找最優的權重、閾值和隱含層個數,算法原理如下。
首先初始化隨機生成一群粒子,迭代過程中,各粒子由適應度值找到個體歷史最優和群體歷史最優解,根據式(1)和式(2)進而更新自己速度和位置。

(1)
xi(t+1)=xi(t)+φvi(t+1)
(2)

1.3 Elman神經網絡
在局部回歸網絡中,Elman神經網絡是較為典型的一種。它是一種具有極強的計算能力的前向神經網絡,能夠組合局部反饋與局部記憶單元。Elman 神經網絡由輸入、隱含、輸出和承接層4層結構組合而成,相比于一般靜態神經網絡,具有逼近速度快、動態特性好等特點[12]。該模型的計算公式為

(3)
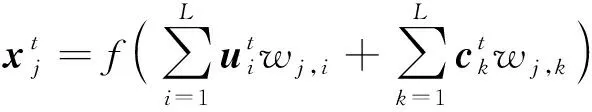
(4)

(5)
式中:

1.4 PSO-Elman算法
該優化算法的核心思想是通過PSO算法優化Elman網絡的權值和閾值,可改善Elman神經網絡的預測效果。
具體步驟如下。
步驟1將粒子群參數和Elman神經網絡進行初始化。Elman神經網絡的初始化主要包括確定輸入層、隱含層和輸出層的層數。粒子群參數的初始化主要有粒子位置和粒子速度的范圍限定,層數、學習因子、迭代次數和種群規模。
步驟2確定粒子評價函數。種群中粒子適應度函數表示為

(6)
式(6)中:n為種群規模;yi為實際輸出值;Yi為樣本輸出值。
步驟3據式(6)計算各粒子適應度值并排序,進一步創建粒子群的規則樹結構。
步驟4時刻更新各粒子位置,進一步尋求各粒子的全局和局部最優位置。
步驟5據式(2)中確定的粒子評價函數更新粒子位置和速度。
步驟6一旦達到迭代結束條件就結束,否則將繼續步驟三進行再次迭代。
步驟7將獲取的最優結果對Elman神經網絡權值和閾值進行賦值,Elman模型訓練后,輸出最優預測解。
1.5 基于EWT-PSO-Elman的組合預測模型
EWT方法繼承EMD和小波分析方法的各自優點。PSO算法屬于智能優化算法,屬于進化算法之一,能科學處理約束全局的優化問題。Elman神經網絡具有逼近速度快,動態特性好的優點。綜合以上兩種算法的優點,并與EWT結合對徑流序列進行預測,構建了EWT-PSO-Elman耦合預測模型。
基于EWT-PSO-Elman耦合模型的預測步驟如下。
步驟1采用EWT對實例月徑流數據先進行預處理,則得到幾種不同特征的經驗模態分量IMF,每個分量具有不同的頻率和周期,分別對應原始信號的不同特征。
步驟2進行各IMF的PSO-Elman時序預測。據各不相同頻率模態分量{IMF1,IMF2,…,IMFn}對應構建PSO-Elman模型,完成各分量預測后,對結果求和。
步驟3對預測結果進行計算。

圖1 EWT-PSO-Elman耦合模型預測流程圖Fig.1 EWT-PSO-Elman coupled model prediction flow chart
EWT-PSO-Elman耦合預測模型流程如圖1所示。
1.6 模型評價和優選
為評價預測模型的預測性能,參考《水文情報預報規范》[13],選取能夠對兩組非線性相關數據的擬合程度進行評價而被廣泛應用于水文模型性能評估中的納什效率系數(NSE)、均方根誤差(RMSE)和平均相對誤差絕對值(MAPE)共3種評價指標。

(7)

(8)

(9)

2 應用
2.1 數據來源
澄碧河流域位于百色市凌云縣北部的青龍山,平均海拔650 m,屬西江水系。流域總面積為 2 087 km2,其中巖溶區面積占總面積53.7%,干流河長151 km。該巖溶區是中國南方典型的巖溶區之一,具有高峰叢狀洼地的特征,屬喀斯特地貌。水庫壩址以上集雨面積2 000 km2,約占整個流域集雨面積的95.8%,年平均降水量為1 560 mm,汛期降水約占全年降水的87%,多年平均流量約為37.8% m3/s,且流域屬于亞熱帶季風氣候,雨熱同季,夏長冬短。以澄碧河水庫壩首站為例,搜集選取壩首站1979—2019年共492個月的歷史徑流數據作為EWT-PSO-Elman徑流預測模型數據集(圖2)進行研究,并將訓練集與測試集比例劃分為8∶2,即前394個月作為模型訓練期,后98個月作為檢驗期。流域位置圖和示意圖如圖3所示。

圖2 壩首站月徑流序列Fig.2 Monthly runoff series at the dam head station
2.2 參數設置
在EWT-PSO-Elman模型對PSO的參數設置中,參考已有研究成果基礎上[14],經過反復測試和結合數據特征,設置種群規模為10;初始化種群粒子位置和速度設置在[0,1];學習因子,即每個粒子所需要的加速度參數,本文設定c1=2,c2=2;最大迭代次數設置為50;慣性權重,一般慣性權重的設置區間為0.3~0.9,本文設定為0.9。其中Elman的輸入層節點數設為1,以訓練目標最小誤差為目標進行隱含層層數動態尋優,對比測試后設定隱含層層數為10,隱含層節點數為11,訓練次數設為 1 000,輸出層節點數設為1,學習速率設為0.01,訓練目標最小誤差設為0.000 01。
2.3 預測及對比分析
2.3.1 EWT分解
在采用小波方法進行時間序列分析時,小波分解層數對結果有較大影響,其中,分解層數根據杜文遼等[14]提出的小波濾波分解層數的自適應方法確定,經反復測試,當進行4層分解時,模型性能能夠達到最佳,其每個IMF分量代表一組特征尺度(頻率),因此EWT分解實際上是將原始數據序列分解成不同尺度的疊加,各個IMF分量既可以是非線性的,也可以是線性的,而且各個IMF分量都有不同的物理背景相呼應。它不僅包含了原始序列的全部信息,而且突出了原始序列的不同特征,使得模型能夠更準確地學習徑流序列的周期性和規律性特征。小波分析具有強大的多尺度分辨功能,能識別水文序列的各種頻率成分,EWT分解如圖4所示。

圖4 EWT分解結果Fig.4 EWT decomposition results
各子序列表現出該徑流序列的振幅變化和頻率變化,其中,IMF1分量相較其余分量,頻率最小,振幅最小,波長最長,波動情況最為平緩,IMF2~IMF4頻率逐漸增大,波長隨之變短,振幅逐漸變大,且表現一定的周期性,其中IMF1的波動范圍為 30~75,IMF2的波動范圍為-50~38,IMF3的波動范圍為-110~98,IMF4的波動范圍為-55~124。
2.3.2 預測結果分析
EWT-PSO-Elman、EWT-PSO-BP、PSO-Elman、PSO-BP、Elman和BP模型月預測結果如圖5,預測效果如表1所示。

表1 各模型在驗證集上的預測效果
由圖5可知:①單一BP和Elman模型預測效果較差,只能反映出序列的大概趨勢,預測值與實測值的結果相差較大,單一BP和Elman模型對月徑流深峰值的預測效果較差,預測值與實測值相差約為54%、47%;②PSO優化的Elman模型較PSO優化的BP模型好,這取決于Elman模型的收斂速度快,訓練準確度和分類精度更高,但對月徑流深峰值的影響不明顯;③EWT-PSO-Elman耦合模型的預測精度最高,預測徑流序列趨勢與原序列趨勢的一致性最高,無較大差別,與其他模型相比,峰值優化明顯,預測值與實測值相差約4%,有效地降低了序列非平穩和非線性帶來的影響,取得較好的預測效果。
為進一步探索各模型的預測精度情況,對各評價指標進行分析,如表1所示。
(1)從參數優化前后性能來看:壩首站的PSO-Elman模型較Elman模型的NSE提高了約38.9%,MAPE減少了約41.8%,壩首站的PSO-BP模型較BP模型的NSE提高了15%,MAPE和RMSE分別減少約17.1%、21.5%。
(2)從小波分解前后性能來看:壩首站的EWT-PSO-Elman模型較PSO-Elman模型的NSE提高了47.5%,MAPE和RMSE分別減少約0.7%,52.3%,EWT-PSO-Elman模型較Elman模型的NSE提高了約 104.9%,MAPE和RMSE分別減少約42.2%、37.9%。壩首站的EWT-PSO-BP模型較PSO-Elman模型的NSE提高了82.4%,MAPE和RMSE分別減少約3%、46.2%,EWT-PSO-BP模型較BP模型的NSE值提高了109.8%,MAPE和RMSE分別減少約19.6%、58%。

圖5 月徑流模擬結果圖Fig.5 Monthly runoff simulation results
(3)從同一模型預測效果對比來看:在預測精度上,EWT-PSO-Elman>PSO-Elman>Elman,EWT-PSO-BP>PSO-BP>BP。
(4)從整體上看:EWT-PSO-Elman模型的預測精度最高,大于EWT-PSO-BP模型,表明在PSO有效優化Elman權值和閾值,EWT有效處理數據非平穩性和非線性特征的結合上能有效提高Elman預測精度,將EWT-PSO-Elman模型應用于徑流預測是可行的。
3 結論
通過構建EWT-PSO-Elman神經網絡模型,應用于月徑流深預測中并分析驗證,得到如下結論。
(1)所構造的耦合模型的預測精度遠大于單一模型,通過“分解-預測-重構”模式可有效提高預測精度。
(2)對比分析結果顯示,本文提出的EWT-PSO-Elman模型優于EWT-PSO-BP模型、PSO-Elman模型和PSO-BP模型,可為徑流預測工作提高一定的參考。
(3)本文所提的EWT-PSO-Elman耦合模型能提高徑流預測精度。但僅應用于月徑流中,今后可探討不同時間尺度的適用性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
