一種無延遲的水文時間序列預測方法
2022-09-29 10:28:58馬心雨梁正和朱躍龍萬定生
科學技術與工程 2022年22期
馬心雨, 梁正和, 朱躍龍, 萬定生
(河海大學計算機與信息學院, 南京 211100)
近年來,洪水災害事件危及了人民的生命安全和財產安全。為了在災難發生前給人民預留足夠的時間做好撤離工作,需要對水文數據實施準確和準時的預測。
目前,用于水文預測的模型主要有概念模型、物理模型和數據驅動模型。前兩種模型需要水文現象的具體物理過程和大量的水文參數作支撐,具有一定的局限性。而數據驅動模型只需要歷史數據就能實現模型的建立與未來數據的預測,因此,它受到廣泛的應用。常見的數據驅動模型有長短期記憶神經網絡(long and short-term memory neural network,LSTM)[1]、支持向量機(support vector machine,SVM)[2]、極限學習機(extreme learning machine,ELM)[3]等,但單一的模型存在著預測的不足。為此,張洋銘等[4]利用改進粒子群算法優化LSTM,改善了傳統LSTM參數選取困難的問題,提高了預測的效率及時間序列的擬合能力。Li等[5]利用布谷鳥搜索算法(cuckoo search algorithm,CS)對LSTM的參數進行尋優,并利用自我注意機制捕捉時序數據之間的相關性,進一步提高了預測的精度。徐松金等[6]利用差分進化優化最小二乘支持向量機(least square support vector machine,LSSVM)的懲罰因子和核函數參數,避免了選擇參數的盲目和耗時。Zhao等[7]在學習水文數據具有的時間信息的基礎上,對研究區域內的空間信息進行了捕捉,降低了預測的誤差。以上方式均實現了對時間序列更加準確的預測,但對預測的準時問題思考不足,導致以上模型的預測結果存在預測峰值落后于真實峰值的現象,即預測延遲的問題,該問題可能會造成撤離工作的失敗。目前,在水文中,大多數數據驅動模型都存在準確性較高,而準時性不足的問題。
針對預測延遲問題,早期,De Vos等[8]通過分析預測模型,提出了兩點造成預測延遲的原因,第一,輸入歷史數據間高度的自相關性導致建立的模型傾向于對歷史數據的回歸輸出,因此導致預測結果與上一時刻已知數據的近似,表現出預測延遲的現象;第二,神經網絡優化時使用的目標函數過于單一,如均方根誤差只考慮了預測效果的準確性。針對上述原因,眾學者進行了分析和研究。對于第一個原因,通過設置不同的小波基函數對時間序列進行了多級分解,削弱輸入時間序列的相關性,并對得到的子序列進行預測模型的構建和預測結果的重構,有效解決了預測延遲問題。但是,Dixit等[9]利用試錯法選擇小波基函數和分解級數時,耗費了大量的時間,降低了效率,并且小波分解存在模態混疊的問題,影響預測模型的建立。Samanta等[10]建立雙層網絡,同時捕捉時間序列的動態信息和靜態信息,削弱了輸入的自相關成分實現了時間序列的準時預測。對于第二個原因,Abrahart等[11]利用神經進化工具箱優化神經網絡的參數,將預測結果的均方根誤差和時間校正因子相結合作為優化的目標函數,同時考慮了預測結果的準確性和準時性,實現了對時間序列的精準預測。
基于以上思考,現從以上兩個原因出發,首先利用變分模態分解(variational mode decomposition,VMD)作為時間序列的分解算法削弱時間序列的高自相關性,它克服了模態混疊的問題,并利用CS確定VMD參數的最優解,提高參數選擇的效率。CS選用的適應度函數將預測延遲變量與確定性系數相結合,同時考慮預測結果的準確性和準時性。其次,利用CS優化VMD的結果指導其對時間序列的分解過程。最后,基于LSTM和ELM神經網絡為分解的子序列建立預測模型,構成CSVMD-LSTM-ELM模型對水文中的預測延遲問題進行研究。
1 預測延遲問題
在水文時間序列的預測研究中,預測延遲現象很普遍。原因是衡量模型精度常用的評價指標,如均方根誤差等,本身沒有符號,無法對方向上的誤差進行衡量。因此,這些評價指標分數即使再好,卻沒有改善預測延遲的問題。
圖1為基于LSTM的水文時間序列預測局部圖,僅使用歷史水位作為輸入,未來水位作為輸出。由圖1可以看出,預測的波谷點落后于真實位置,并且,當水位的真實趨勢已經開始上升了,預測趨勢卻還是下降的。這樣將會得到錯誤的信息,造成判斷的失誤,可能帶來巨大的經濟損失。傳統降低誤差,提高模型評價指標分數的方式只能改善整體的擬合效果,并不能避免這樣的局部問題。因此,研究并對其進行解決,使建立的模型能夠實現準確且準時的預測,是具有重要意義的。

圖1 預測延遲現象Fig.1 Prediction delay phenomenon
2 無延遲預測模型
水文時間序列的預測延遲問題是由于時間序列間的高自相關性引起的,因此首先利用VMD算法對時間序列進行分解,以削弱時間序列的相關性,并結合CS來尋找VMD分解算法的最優參數,目的是得到時間序列的最優分解程度,其既可以削弱時間序列的相關性,又保留它的時間特征。基于此再對神經網絡進行訓練,建立無延遲預測模型,解決水文時間序列中預測延遲的問題。
2.1 基于CSVMD的時間序列分解算法
2.1.1 VMD算法
基于數據驅動方式的水文時間序列預測大大減少了水文工作者的工作量,并且提高了準確性。但時間序列本身的特點也帶來一些新的問題。首先水文時間序列數據是不穩定和非線性的,并且包含著多個尺度的變化,如果直接對這樣的時間序列進行預測,多尺度的信息融合在一起,必定會對模型的訓練帶來一定的影響。其次是時間序列的連續值之間存在高自相關性,這樣得到的結果會出現預測延遲的問題。為了解決上述問題,傳統的小波分解是一種很好的預處理方式,它通過設置小波基函數和分解層級,就能將時間序列分解為多個細節分量和一個近似分量;同樣的,經驗模態分解(empirical mode decomposition,EMD),可以將時間序列分解為處在不同頻段的多個模態分量和一個殘余分量,相對于小波分解,它不需要人為設置小波基函數,并且分解過程具有自適應性,但是會出現模態混疊的現象和端點效應,為了解決這些問題,又出現了集合經驗模態分解 (ensemble empirical mode decomposition,EEMD)等方法,但它們都屬于遞歸分解法,且計算效率低下。而后出現的VMD分解算法是基于完全非遞歸性質的時間序列分解法,它不僅消除了分解過程中的模態混疊與端點效應問題,并且具有更高的計算效率。該分解算法的具體步驟參見文獻[12]。
2.1.2 CS算法
在VMD算法的兩個參數中,分解個數k和懲罰因子α是需要人為設定的,它們關系著VMD分解的程度,分解程度過高會使時間序列的時間特征丟失,過低則無法使多個尺度的信息分離,這都會導致預測模型建立的失誤,從而無法解決預測延遲問題。CS作為一種優化算法,可以通過設置適應度函數,尋找合適的VMD參數。它的適用性很廣,只要能夠公式化為函數的優化問題,都可以利用優化算法找到很好的解決方案,并且,CS需要調節的參數少,不易陷入局部最優。CS的具體步驟參見文獻[13]。
2.1.3 基于CS優化的VMD分解算法
為了高效地確定VMD參數的最優解,利用CS對VMD參數進行優化,構成了CSVMD分解算法。在CS與VMD進行結合時,大多數學者利用均方根誤差、平均絕對誤差、確定性系數等作為CS的適應度函數,通過優化提高了預測的精度。這種方式,在誤差相對大時會產生良好的效果,但是,當誤差已經縮小到一定的程度,如確定性系數已經達到0.99以上,再進行這種優化是沒有意義的。然而無論誤差降低到多小,“預測延遲”現象都是存在的。該現象導致預測的峰值出現的時間較晚,這無疑會帶來嚴重的后果。因此,只考慮誤差是不全面的。
為了同時考慮誤差和“預測延遲”帶來的影響,將確定性系數R2與延遲變量TLag進行結合,作為CS優化VMD時的適應度函數,這樣在保證緩解預測延遲問題的同時,使預測結果具有較低的誤差。
根據Conway等[14]的研究,并經過多次實驗,將適應度函數定義為
(1)

式(1)適應度函數指導CS對VMD的參數進行迭代,通過尋找該適應度函數的最小值,得到VMD的最優參數。它的意義在于,當具有預測延遲時,TLag將會放大預測結果的誤差,L將會很大,從而將優化的重點放在緩解預測延遲問題上,提高預測的準時性;當延遲時間幾乎為0時,優化算法將會尋找使誤差更低的參數組合,從而將優化重點轉移到預測的準確性方面。
基于CS的VMD優化過程如下。
(1)初始化鳥巢位置的集合。鳥巢位置即需要優化參數的隨機值的組合,該隨機值所屬范圍根據要解決的優化問題而定。
例如,對于一個二維的優化問題,第i個鳥巢的位置可以定義為
(2)
式(2)中:v1為要優化的參數1的隨機值;v2為要優化的參數2的隨機值。
那么,鳥巢位置的集合為
(3)
(2)根據所有參數組合建立神經網絡模型,計算對應適應度函數的值,尋找當前參數組合中的最優解。
(3)更新參數組合值,再次計算新組合的適應度。更新組合值時結合了Levy飛行的搜索方式。
(4)將新一批的參數組合中的最優解與前一次迭代的最優解進行比較,選出新的最優解。
(5)按照發現概率丟棄適應度差的解。
(6)繼續迭代,更新鳥巢位置,直到滿足指定的停止條件。
該算法的流程如圖2所示。

t為當前迭代次數,初始值為0;Max為最大迭代次數; pa為鳥巢被發現的概率圖2 基于CS的VMD參數尋優過程Fig.2 VMD parameter optimization process based on CS
2.2 基于LSTM-ELM的無延遲預測模型
現將無延遲預測模型的建立分為兩個階段,具體如圖3所示。首先,對于VMD參數設置階段,利用CS初始化一系列VMD的參數組合后進行迭代,找到最優的參數組合,該組參數指導訓練階段中的VMD分解過程。其次,在預測模型訓練階段,通過對子序列進行兩種神經網絡的訓練與模型評價等步驟,建立基于LSTM-ELM的神經網絡,從而構成無延遲預測模型。

k和α為VMD分解算法的兩個參數,分別是分解個數和懲罰因子圖3 無延遲預測模型建立步驟Fig.3 Steps for buildingdelay-free prediction model

圖4 LSTM與ELM預測對比圖Fig.4 Comparison diagram of LSTM and ELM prediction
VMD將時間序列分解成不同頻率的子序列,為了訓練得到不同頻率的最佳預測模型,采用兩種神經網絡進行訓練,包括LSTM神經網絡和ELM神經網絡,并通過使用評價指標進行比較與選擇,構成整體的最佳預測模型,克服單神經網絡只能很好地提取某一特征的不足[15]。并且,LSTM在處理較長時間序列方面有很好的性能,但訓練速度較慢,這樣在對多個子序列進行訓練時,時間耗時將會成倍增長;ELM在速度方面有很好的性能,然而由于 ELM 隨機給定隱含層權重與偏置[16],導致ELM預測序列不如LSTM預測序列平穩,如圖4所示。可以看出,將LSTM與ELM進行結合的方式相較于單一神經網絡建立的模型,具有更好的預測性能。
為了對不同神經網絡的預測效果進行對比,選用以下的評價指標。
(1)均方根誤差(root mean square error,RMSE),它用來反映預測結果的離散程度。公式定義為
(4)
(2)平均絕對誤差(mean absolute error,MAE),它是真實值和預測值的絕對誤差的均值。公式定義為
(5)
(3)確定性系數(deterministic coefficient,DC),它反映了預測值與真實值之間的吻合程度,在統計學里,一般用R2表示。公式定義為
(6)
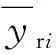
(4)預測延遲時間Lag,它表示預測序列落后于真實序列的時間,單位為h。它的值利用序列間的皮爾森相關系數進行求解,通過移動預測序列,計算其與真實序列的相關系數,記錄相關系數最大時的移動距離。該距離代表延遲的時間。
皮爾森相關系數(pearson correlation coefficient,PCC),一般用r表示,計算公式為
(7)
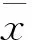
求解r最大值的過程為
Max{r(p[i:],q)},i=1,2,…,n
(8)
式(8)中:Max為求解最大值的函數;r為兩個時間序列間的皮爾森相關系數;p[i:]為預測序列從位置i到最終位置的截斷子序列;q為真實序列。
3 實驗分析
3.1 實驗準備
3.1.1 數據準備
以秦淮流域東山站的水位為研究對象,該流域地處我國長江中下游地區,是平原地區的中小河流域。該流域包含多個雨量計和水文站,數據資源豐富。選取2016年1月1日00:00—2018年12月31日23:00共26 304條數據作為數據集,水位數據的數據間隔為1 h。選取前17 544條數據作為訓練集,后8 760條數據作為測試集。輸入數據為歷史上前10 h的水位數據,即(rivert-10,rivert-9,…,rivert),輸出數據為未來第3小時的預測水位。即rivert+3。
3.1.2 CS參數設置
利用CS對VMD參數進行優化,在CS啟動前,需要對算法中的變量進行如下設置。
初始的參數組合數設置為50,由于需要優化的變量個數為2,因此,維度設為2,發現概率設為0.25。分解個數范圍設為2~10,懲罰因子設為500~5 000,分解個數的步長設為1,懲罰因子的步長設為參數范圍的5%,最大迭代數設為1 000。在CS的運行過程中,尋找使適應度值最小的參數組合。
3.2 基于CS的VMD參數設置
VMD主要有兩個參數,包括分解個數k和懲罰因子α,為了比較不同參數的預測結果,選擇了6組參數進行實驗,模型的預見期選為3 h,為了關注預測的延遲問題,除了采用三種常用的評價指標外,還計算了每個模型產生的預測延遲時間,如表1所示,為不同VMD參數預測結果的比較。可以看出,不同的參數組合建立的模型的預測誤差及預測延遲時間是不同的,效果最好的一組為α=500,k=6,效果最差的一組為α=1 500,k=6。下文對此進行單獨的分析。
通過比較分解之后的時間序列的自相關程度,從而分析兩組參數對預測的影響。如表2所示,為分解后的子序列與原序列的互相關系數,該系數絕對值越大,子序列對原序列的影響程度就越大。為了選擇相關系數較大的序列,將閾值設為0.3,因此,選出前兩個序列進行分析。如圖5所示,為兩組參數得到的分解序列的自相關性比較圖。可見,組合2的自相關性小于組合1,所以,組合2的分解程度更高,但它的預測效果卻很差。因此,并非分解程度越高越好,合適的分解程度才能解決預測延遲問題。為了尋找合適的分解參數,利用CS來初始化一系列參數,對VMD進行迭代尋優,優化得到的參數指導VMD對時間序列進行分解,經過實驗得出,k=4、α=1 625時預測效果最好。因此,后續將統一設置為k=4、α=1 625。
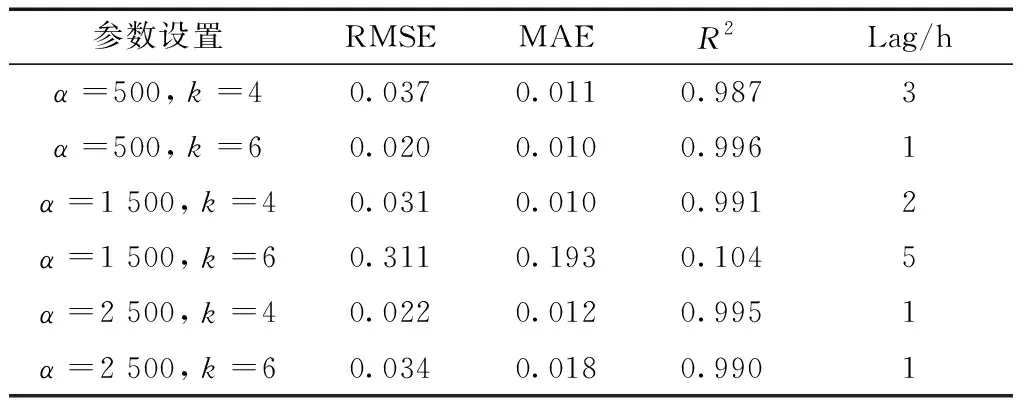
表1 不同VMD參數設置下模型預測效果對比Table 1 Comparison of model prediction effects of different VMD parameter settings

表2 子序列與原序列的相關系數Table 2 Correlation coefficient between subsequences and original sequence

圖5 子序列的自相關性比較Fig.5 Comparison of autocorrelation of subsequences
3.3 子序列的分解與預測
通過對時間序列進行分解,以削弱時間序列間的自相關。首先按上述得到的VMD參數對時間序列進行分解,如圖6所示,為分解后的4個子序列按頻率從低到高排列的結果,可見,分解能夠將多個尺度的信息分離開。其次,基于LSTM和ELM神經網絡為每個子序列建立了兩種預測模型。它們的預測效果如表3所示。

表3 子序列的預測結果比較Table 3 Comparison of prediction results of subsequences
由表3的指標可以看出,對于序列1、序列2和序列4,基于ELM的神經網絡預測結果具有更低的均方根誤差、平均絕對誤差和更高的確定性系數,而對于序列3,基于LSTM的神經網絡預測表現較好,因此對于序列1、序列2以及序列4選擇使用基于ELM的神經網絡,對于序列3選擇使用基于LSTM的神經網絡,從而建立水文時間序列無延遲預測模型。
3.4 實驗比較

圖6 時間序列分解結果Fig.6 Time series decomposition results
為了驗證所提出的CSVMD-LSTM-ELM無延遲模型在解決預測延遲問題的有效性,分別與VMD-LSTM-ELM和LSTM進行對比。不同模型的預測趨勢對比如圖7所示;不同模型的每個評價指標的結果如表4所示。可以看出,三種模型的預測趨勢都與真實趨勢類似,其中,LSTM模型可以實現有效的預測,但是它相對于真實趨勢是落后的,且落后時間為3 h。結合VMD算法對時間序列分解之后,可以將時間序列不同尺度的信息分隔開,因此,VMD-LSTM-ELM模型降低了延遲時間,均方根誤差降低了0.01,得到了更好地預測效果,但由于其模型的VMD參數不是最優的,并非完全消除了預測延遲。在其模型基礎上利用CS對VMD參數進行尋優,建立的CSVMD-LSTM-ELM模型得到的預測結果在該數據集上幾乎沒有延遲,并將預測誤差降低到0.026,其預測序列更加接近真實序列。因此,本文所提模型在解決預測延遲問題上取得了良好的效果。

圖7 不同方法下的預測趨勢比較Fig.7 Comparison of prediction trends of different methods

表4 不同方法下的預測評價指標比較Table 4 Comparison of prediction evaluation indexes under different methods
4 結論
針對水文時間序列預測的延遲問題,提出一種基于CSVMD-LSTM-ELM無延遲預測方法,采用秦淮河流域的數據集進行預測,得到以下結論。
(1)VMD算法對時間序列進行分解,可以去除時間序列連續值之間的高自相關性,減小預測的延遲時間。
(2)通過CS算法可以得到VMD參數的最優組合,有效解決了VMD參數選擇困難的這一問題,進一步解決了“預測延遲”的現象,并具有較低的誤差。
但本文仍有許多不足,單一的優化算法并不能同時兼顧尋優的準確性和效率,今后可以嘗試使用多種優化算法結合進行提高。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
