融合self_attention 的詞級交互文本分類模型研究*
2022-09-28 01:40:34吳思怡吳陳
計算機與數字工程 2022年8期
吳思怡 吳陳
(江蘇科技大學計算機學院 鎮江 212100)
1 引言
在互聯網和大數據時代,人人既是數據的接收者也是生產者,數據之間的互聯互通給我們帶來了便利,但同時也產生了限制。因為每個人的注意力是短暫的,精力也是有限的,如何在紛繁復雜的數據海洋中高效準確地找到所需的信息,似乎是一個難題。這也顯示出準確有效地將文本分類管理是具有重大意義的。
文本分類是自然語言處理研究中的任務之一,其目的就是將一段文本內容分類為一個或多個類別。它的應用也非常廣泛,比如:垃圾過濾,新聞分類,詞性標注等[1]。
深度神經網絡已成為文本分類的有效解決方案。深度神經網絡一般是學習輸入文本的單詞級表示,輸入文本通常是矩陣,每行/列作為文本中單詞的嵌入[2]。然后,將字級表示壓縮成具有聚合操作的文本級表示。然后通過最后一層(全連接層)作出最后的結果判斷。雖然已經取得了很大的成功,但是這些基于深度神經網絡的解決方案忽略了細粒度的分類線索,因為它們的分類是基于文本級表示。這樣,文本屬于某個類的概率很大程度上取決于它的整體匹配分數,而不是字級匹配信號,然而這些字級匹配信號將提供用于分類的顯式信號(例如,原子彈強烈地指示軍事的主題)[3]。
因此,為了解決上述問題,本文提出了一種新的融合自注意力機制的詞級交互模型,該模型主要分為三層:自注意力層,交互層,聚合層。
2 相關介紹
2.1 Self_Attention機制
受人類注意力觀察機制的啟發,注意力機制在20 世紀90 年代就被視覺領域作為一種理論思想,即人們在觀察一個事物時,是無法一次性觀察到整個事物細節形態,而是將注意力集中在某個部分,然后根據我們所觀察學習到的特征去尋找注意力應該集中的位置。直到2014 年,谷歌團隊發表了文章《Recurrent Models of Visual Attention》之后,注意力機制才真正被相關學者關注。次年,該機制被應用到自然語言處理當中的機器翻譯研究領域,其采用Seq2Seq+Attention 模型來進行機器翻譯,提高了現有模型準確率[4]。而在2017 年谷歌公司發表的《Attention is All You Need》文章中,其翻譯模型中只采用了注意力機制就取得了很好的結果[5],從此,對于注意力機制的研究和應用被推上了更高層次。注意力機制又分為層次注意力、循環注意力、多頭注意力等,因為本文主要針對長文本進行分類研究,所以在文中我們采用了注意力機制中的自注意力機制模型,該模型特點就是能夠使文本中的組成長句子的隨機兩個詞語產生聯系,所以即使是距離較遠的特征也能夠被充分利用。
2.2 Word2vec詞向量
在NLP中,最細粒度的對象是詞語。我們最常使用的詞性標注方法是貝葉斯等傳統算法,即利用樣本數據(x,y),其中x表示詞語,y表示詞性,然后找到x→y的映射關系。但在自然語言中,我們所使用的文字、圖標等都是符號化的,要將這些信息加入到數學模型當中,就必須將其轉換為數值形式進行處理。這個過程也可以理解成將符號信息對應地嵌入到數學空間中,即詞嵌入(word embedding)。Word2vec 是詞嵌入的一種,其是用一層的神經網絡(即CBOW)把one-hot 形式的稀疏詞向量映射成為一個n維稠密向量的過程[7]。其優勢在于能夠利用詞的上下文信息,使語義信息更加飽滿,較于傳統NLP 的高維、稀疏的表示法(One-hot Representation),Word2vec訓練出的詞向量是低維、稠密的[8]。Word2vec常應用兩個方面:
1)使用訓練出的詞向量作為輸入特征,提升現有系統,如應用在情感分析、詞性標注、語言翻譯等神經網絡中的輸入層。
2)直接從語言學的角度對詞向量進行應用,如使用向量的距離表示詞語相似度、query相關性等[9]。
3 模型實現
在本文中,我們提出的模型如圖1 所示,主要包含以下幾層:自注意力層,交互層,聚合層。
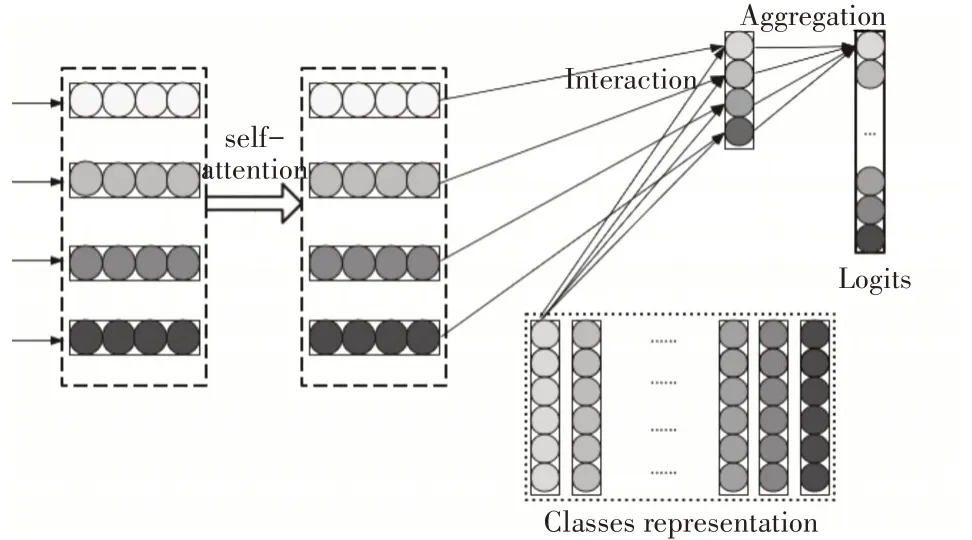
圖1 基于自注意力機制的顯式交互文本分類模型
3.1 自注意力層
這一層主要是從輸入文檔的詞向量矩陣中獲得相互聯系的特征向量矩陣。將文檔D={x1,x2,…,xn},n代表的是文檔中詞的個數,xi代表是文檔中第i個詞的詞向量,其維度為d。將文本D通過全連接,再激活得到新的矩陣Q,Q∈Rn×d。公式即為
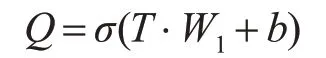
其中σ代表激活函數,激活函數有tanh 函數,sigmoid 函數,relu 函數等,此處選擇relu 函數作為激活函數。
如圖2所示,原詞向量矩陣D激活后得到矩陣Q,通過D矩陣與Q的轉置矩陣做點乘運算:
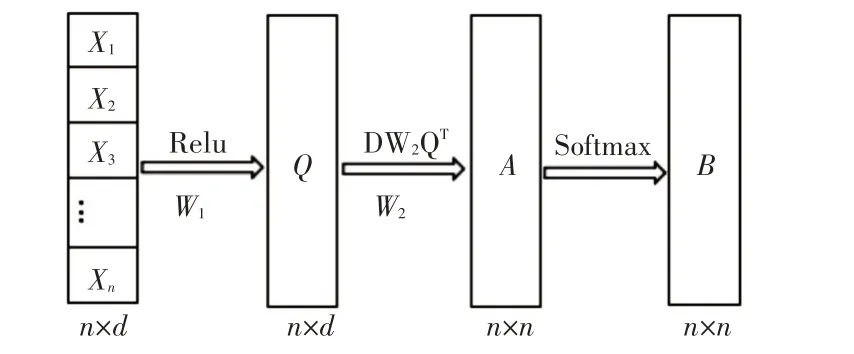
圖2 詞向量處理
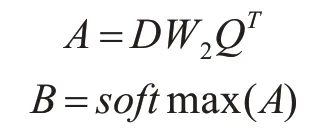
自注意力矩陣B(B∈Rn×n)中每一個元素是矩陣A(A∈Rn×n)中的每一行通過softmax 函數分類所得:
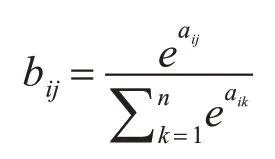
其中aij表示矩陣A中的第i行第j列元素,bij代表B矩陣中第i行第j列元素。
將矩陣B與原詞向量矩陣D進行如下計算得到自注意力矩陣C(C∈Rn×d):
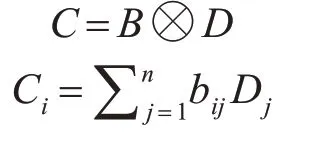
其中U代表B矩陣中每一行元素bij與D矩陣中每一行Dj向量相乘累加得到C矩陣中的一行Ci。
3.2 交互層
交互機制的關鍵思想是使用小單元之間的交互特征(例如文本內容中的單詞)來推斷兩個內容是否匹配的細粒度線索[10]。受基于編碼的方法的交互機制以匹配文本內容的方法的成功啟發,我們將交互機制引入到將文本內容與其類(即文本分類)匹配的任務中。本文設計一個交互層,主要用來計算單詞與類之間的匹配度。使用可訓練的表示矩陣T∈Rk×d來編碼類(其中每一行表示一個類),k表示類的數量,d是維度,等于單詞的大小。通過點積作為交互函數來估計目標詞i與類j的匹配程度,公式如下:
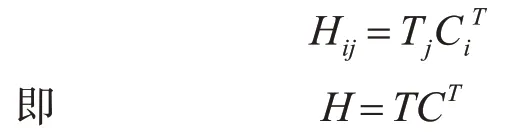
其中C∈Rn×d是自注意力層處理過得到的關于文本的字級表示,其中n代表文本的長度。經過以上這種方式我們可以得到交互矩陣H∈Rk×n。
3.3 聚合層
該層被設計為將每個類是s的交互特征聚合成logits Ois,其表示類s和輸入文本xi之間的匹配數。聚合層可以使用CNN 或者LSTM,但是,為了保持模型的簡單性和高效性,這里我們只使用具有兩個FC 層的MLP,其中relu 是第一層的激活函數。形式上,MLP聚合類s的交互特征Hs,并計算其關聯的logits如下:
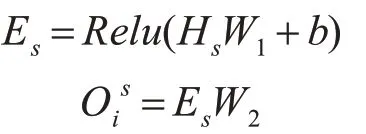
其中W1和W2是可訓練參數,b是第一層中的偏差。然后,我們將logits oi=歸一化為概率pi,根據前人的實驗,我們使用sigmoid 函數對新聞文本進行多標簽分類。
4 實驗研究
4.1 實驗方案
本文是采用的是對比實驗,在數據集下,通過跟不同的文本分類模型對比文本分類準確度和召回率等。我們采用的兩個數據集,中文數據集有復旦中文文本分類數據集,此數據集中一共有19637篇文檔,其中測試語料有9833 篇,訓練語料9804篇,分為20 個類別;英文數據集有DBpedia 兩個數據集,其中DBpedia數據集中包含14個不重疊的類別,含40000個訓練樣本和5000 個測試樣本。
4.2 評估標準
在分類模型中,有很多用于評估模型的標準,本文中主要用到的有準確率,召回率和F1 函數。準確率是指正例判斷正確的個數與模型預測輸出的正例的總個數之比[11]。模型預測為正例的情況有兩種:一種是將正例預測為正例(TP),另外一種是將負例預測為正例(FP)。準確率計算表達式如下:
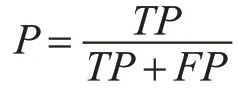
召回率是指正例判斷正確的個數與真正的正例樣本的總個數,這其中也有兩種預測情況,一是將樣本中的正例預測為正例(TP),二是將樣本中的正例預測為負例(FN)[12]。召回率計算公式如下:
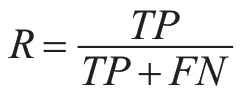
理想情況下,精確率和召回率兩者都越高越好。然而事實上這兩者在某些情況下是矛盾的,精確率高時,召回率低;精確率低時,召回率高[13]。綜合考慮之下,我們引入F1 函數,F1 值是精確率和召回率的調和均值,具體公式如下:
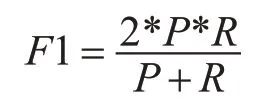
4.3 實驗結果分析
從下面的對比結果表1 中可以看出,本文模型在基于詞級的新聞文本分類中顯示出了一定的優勢;圖3 為不同模型下的分類指標的柱狀對比圖,從準確率和F1 兩方面來看,相對于CNN、RCNN 兩個模型,我們的模型有了顯著的提高。在現有的文本分類性模型中,主要分為兩類:一種是基于特征的模型,另外一種是深度神經網絡分類模型[14]。前者比較偏向為人工特征,采用機器學習算法作為分類器。后者深度神經模型,利用神經網絡完成數據模型學習,已成為文本分類的很有前景的一種解決方案。目前已經提出的深度網絡學習模型有很多,例如,Iyyer 等提出深度平均網絡(DAN)和Grave 等提出了FastText,兩者都很簡單但效率很高[15]。為了獲得文本中單詞之間的時間特征,一些模型如TextCNN(Kim 2014)和Char-CNN(Zhang,Zhao 和LeCun 2015)利用卷積神經網絡,還有一些模型基于遞歸神經網絡(RNN)[16]。約翰遜等研究了剩余架構并建立了一個名為VD-CNN 和Qiao 等的模型。后來又有人提出了一種用于文本分類的區域嵌入的新方法。但是,如簡介中所述,所有這些方法都是文本級模型,而本文所提出的模型是在單詞級別進行匹配。交互機制在自然語言處理中應用很廣泛,它的關鍵思想是使用小單元之間的交互特征(如句子中的單詞)進行匹配[17]。王等提出了一個“匹配-聚合”框架來執行自然語言推理中的交互。再后來Munkhdalai 等提出了一個密集交互式的推理網絡,使用DenseNet 來聚合密集的交互功能[18]。我們的工作與他們的研究有所不同,因為他們主要將這種機制應用于文本匹配而不是分類。
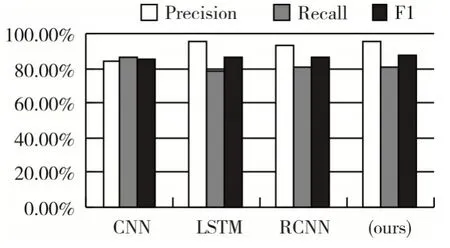
圖3 不同分類模型下的分類指標柱狀圖
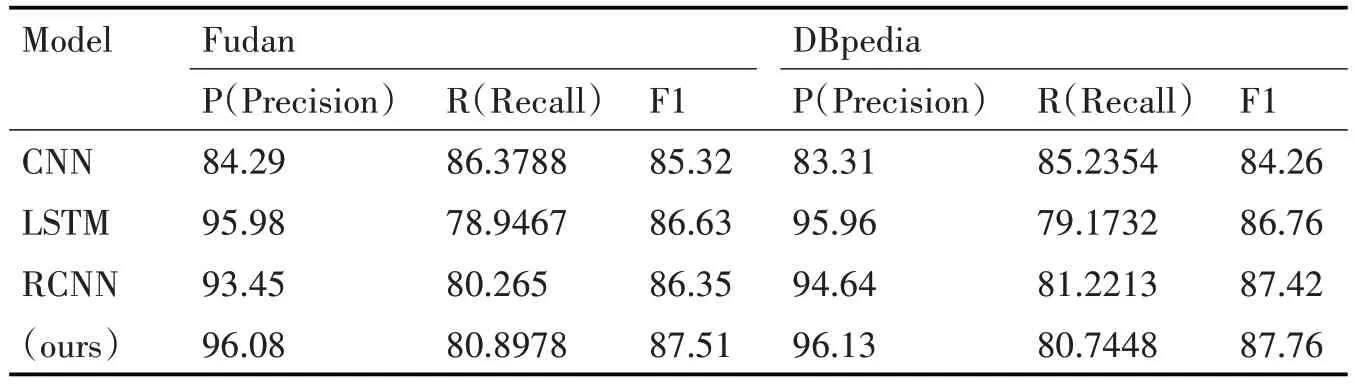
表1 中英文數據集下各個模型的準確率
5 結語
在本文的模型中,我們為了充分利用長文本中兩個詞向量之間的依賴特征,而選擇采用了注意力機制中的自注意力模型,其能將兩個長距離的詞之間的關系直接計算出來,并從中了解句子的內部結構,使模型中得到更為精準的詞向量特征。我們將這種處理機制融合到交互分類模型中,應用交互機制來明確地計算文本分類的單詞級交互信號。本文在中英文文本數據集上面測試模型性能,該模型優化了當前已有模型中的基于文本級匹配而忽略詞級匹配的缺點,通過具體計算詞與類之間的匹配度,充分利用詞與類的關系來完成更精細的分類問題。在未來的研究工作中,我們將會在準確度以及運行耗時方面進一步優化模型。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
文苑(2018年21期)2018-11-09 01:23:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
中國衛生(2015年9期)2015-11-10 03:11:12
中國衛生(2014年3期)2014-11-12 13:18:12
