合作網絡和知識網絡對AI企業專利創新的影響*
2022-09-20 14:35:40劉嘉明閔超嚴笑然
圖書館論壇 2022年9期
劉嘉明,閔超,嚴笑然
0 引言
在研究企業技術進步和創新活動時,與新想法、新技術密切相關的專利數據不僅能夠表征企業的技術創新產出,還能幫助企業挖掘領域內的知識流動方向和技術發展趨勢[1],是衡量技術創新能力的重要指標。技術創新是利用和組織知識資源的過程,離不開與其他個體的交流合作。合作網絡由個體與個體間的關系構成[2],知識網絡由知識元素及其關系構成[3],現有研究已證實組織的創新活動在一定程度上受到兩種網絡的影響,在兩種網絡中占據特定位置有助于企業進行專利創新[3-10]。探究合作網絡、知識網絡與企業專利創新之間的關系,能夠幫助企業及時調整發展戰略,在瞬息萬變的市場環境中持續創新。
隨著人工智能在基礎研究中升溫,近年工業界對人工智能技術的應用也愈發明顯,如智能導師和教育機器人[11]、新冠肺炎CT影像智能診斷系統[12],人工智能應用正逐步通過重塑交通、健康、金融等來改變現代生活。發達國家高度重視人工智能的發展與治理,我國也明確了人工智能的發展方向,推動人工智能技術和產業的發展[13]。目前國內圖書情報領域有關人工智能的研究大致基于主題、作者和機構三類研究對象,研究內容集中在主題演化與內容分析[14]、新興技術與研究前沿識別[15]、科研團隊的識別與比較[16]、人工智能技術與圖書館的結合[17]等,除宋凱[18]利用案例分析研究人工智能領域的校企合作伙伴選擇外,甚少有關于人工智能企業層面的研究。本文圍繞人工智能技術創新問題,從人工智能企業層面入手,系統解構合作網絡和知識網絡對人工智能企業專利創新的影響,為人工智能(AI)企業的發展與技術創新活動提供參考與建議。
1 理論背景與研究假設
合作網絡由個體及個體間的合作關系構成,網絡中的個體通過正式或非正式交流獲取知識[2]。學界普遍認為合作創新可以使合作企業相互交流技術新知識和信息[19],幫助企業實現資源的優化配置和創新績效的提升[20],使處于合作網絡中的企業更容易得到實現創新產出的機會。關于企業在合作網絡中所處的位置對企業創新產出的影響,大多數學者認為網絡結構會通過促進企業的知識交流和資源獲取來影響企業的創新能力,在合作網絡中居于中心地位的企業更容易得到更好的資源[21]。
知識可以表示為用于發明活動的知識元素的集合,知識網絡由知識元素及其關系構成,體現了離散的知識片段和它們之間的聯系,專利分類號是一種能夠量化知識元素的表現形式[3,22-24]。Yan等[3]利用專利所屬的美國專利分類(USPC)類別構建知識網絡,發現在替代能源領域,發明人在知識網絡中的中心性對其知識創造具有倒U型影響;Guan等[22]、俞榮建等[23]、Zhang等[24]均以專利所屬國際專利分類(IPC)類別為知識元素構建網絡,分別在不同領域考察了組織知識結構與其創新活動之間的關系。
度中心性、中介中心性、接近中心性、聚集系數和結構洞是描述節點網絡位置的重要指標。度中心性描述網絡中節點與其他節點的連接程度,節點的鄰接節點越多,其度中心性越大,節點在網絡中的位置越重要[25]。接近中心性反映節點與其他節點的接近程度,節點的接近中心性越大,意味著它與其他節點的距離越近[26]。中介中心性是以經過某個節點的最短路徑數目來刻畫節點重要性的指標,可以衡量節點控制網絡中信息溝通與資源流通的能力[27]。聚集系數描述節點的相鄰節點的連結程度,節點的聚集系數越高,與該節點相鄰的其他節點之間聯系越多[28]。結構洞體現節點間的非冗余聯系[29],當節點A與節點B、節點C都相連,而節點B和節點C之間不存在聯系時,節點A就獲得了一個結構洞,占據結構洞的節點是其鄰接節點的橋梁。
1.1 合作網絡對企業專利創新的影響
在合作網絡中,企業的度中心性越大,意味著企業與越多的其他機構或個人存在聯系,企業與其合作者之間的知識流動也越多[4],越能在知識獲取、重組潛力等方面獲得優勢[5],也更能增加對潛在合作者的吸引力,為后期的合作提供保障[2]。接近中心性高的企業可以更快地聯系到網絡中的其他機構或個人,從而更加有效地獲取所需資源用于創新活動[6]。中介中心性高的企業在與機構或個人的合作中更容易獲得高質量、非重復性的信息和資源[7],占據信息優勢和控制優勢并決定資源的流動方向[8]。
企業的聚集系數越高,企業的合作者之間的聯系越多,合作網絡的信息傳輸能力越強[30],但高聚集系數也容易導致資源擴散和冗余聯系,降低具有聯系的群體的創造性[31],可能不利于企業進行創新活動。占據結構洞的企業是網絡中的中介人,能夠將彼此沒有聯系的機構或個人聯系起來,控制著關鍵信息和資源[9],對企業本身的發展大有益處。也有學者發現,結構洞數過高的企業由于占據網絡優勢地位而接觸過多信息,導致認知超載,反而降低企業的創新能力[32];結構洞較低的個體更容易跨越已有群體和領域邊界,在新領域進行探索和創新[33],也更容易與合作伙伴產生信任關系,利于資源共享和更高效的協作[34]。現有研究普遍認為,與其他機構或個人合作有助于企業提高創新能力,而企業在合作網絡中的位置越關鍵,越能通過合作獲取更多資源。因此,初步假設也與現有研究結論基本一致,即在合作網絡中占據重要位置有助于企業進行專利創新。
1.2 知識網絡對企業專利創新的影響
在知識網絡中,知識元素的組合構造出更大的知識體系。中心性高的知識元素更易到達其他元素,具有更強組合潛力[35],擁有高中心性知識元素的企業能夠在知識網絡中獲取大量的技術和經驗,并更快地接收信息[36]。但知識元素的組合潛力不會無限制上升,隨著組合次數的增加,知識元素的科技價值被逐漸耗盡,知識的成熟組合往往導致更多的漸進式創新或較小的修改,很難繼續創造出具有新穎性的成果[10]。另外,擁有高中心性知識元素的發明者會因接觸到過多的知識而造成信息過載,反而不利于繼續創新活動[3]。
知識聚集可能會為企業帶來競爭優勢,高水平的知識聚集意味著較高水平的知識網絡局部連通性,能夠形成對某一研究領域的深度思考[37],也意味著掌握知識的人員通過合作培養了信任和默契[38]。但知識網絡中的局部聚集往往意味著不同的研發團隊,研發團隊之間的資源競爭容易導致企業內部信息、技術的不流通[39];頻繁的局部知識組合也可能會使企業陷入固定的技術軌跡中無法自拔,難以在后續創新中有所作為[40]。一個在知識網絡中具有結構洞的知識元素與其他彼此之間沒有聯系的知識元素結合,形成以自我為中心的知識領域,其周圍的知識網絡中可能包含著豐富的組合機會[10,41];同時,占據知識網絡中豐富結構洞的元素具有控制知識流動的優勢,從而提高涉及該元素的個體的影響力[42]。與合作網絡不同,目前對知識網絡的研究較少,且不少學者認為知識元素的組合并非越多越好,組合次數的過度增加會使知識元素喪失后續組合所需的科技價值。因此,本研究認為容易組合的知識元素在提升企業專利創新方面存在閾值。
1.3 研究假設
目前缺乏針對人工智能企業專利創新的研究,尤其是從合作網絡與知識網絡的視角。基于上述分析,本文針對人工智能企業從事專利創新活動提出以下假設。
在合作網絡的影響方面:
H1a:合作網絡中的中心性(度中心性、接近
中心性、中介中心性)正向影響企業的
專利創新產出。
H1b:合作網絡中的聚集系數負向影響企業
的專利創新產出。
H1c:合作網絡中的結構洞數正向影響企業
的專利創新產出。
在知識網絡的影響方面:
H2a:知識元素在知識網絡中的中心性(度中
心性、接近中心性、中介中心性)倒U
型影響企業的專利創新產出。
H2b:知識元素在知識網絡中的聚集系數負
向影響企業的專利創新產出。
H2c:知識元素在知識網絡中的結構洞數正
向影響企業的專利創新產出。
2 研究設計
2.1 數據來源
本文所使用的專利數據來自LENS①。由于人工智能是一個綜合性領域,包含機器學習、自然語言處理、模式識別等子內容,本文通過限定專利標題中的關鍵詞和專利所屬IPC分類號構建檢索式,選取2011-2019年出版的355,638條公開專利進行分析。
2.2 數據處理
專利申請人主要分為個人和機構兩類,其中機構包括企業、高校、研究所等。由于本文探討的主體對象為企業,因此以合作申請專利的企業為核心申請人,其合作者不限制類型。生成核心申請人列表的方法包括:(1)形成包含機構及個人的初始申請人列表;(2)根據co ltd、llc、corp等企業名稱常用縮寫,從初始申請人列表中篩選并形成初始核心申請人列表;(3)根據發明人字段從初始申請人列表中剔除部分個人申請人;(4)根據university、school、college等高校名稱常用詞和institute、research等研究所名稱常用詞,從初始申請人列表中排除高校和研究所;(5)人工篩選無法通過名稱辨別類型的初始申請人,與初始核心申請人列表整合形成最終核心申請人列表。由于本研究探討企業的合作、知識網絡特征對未來專利創新的影響,以3年為時間窗將數據分為2011-2013年、2014-2016年和2017-2019年3個時間段,選取2011-2016年的合作專利共35,162條(占6年內全部專利數量19.6%)和14,913家企業進一步分析,構建2011-2013年、2014-2016年的合作與知識網絡。在限制企業2011-2019年間專利申請數量不得少于5個、企業須在連續兩個時間窗內均有專利申請后,最終得到680家企業的1,061條樣本,每條樣本都代表一個企業在某一時間窗內的合作網絡、知識網絡特征及其在下一時間窗內的專利創新產出。
2.3 研究變量
(1)因變量。因變量為企業未來的專利創新產出,分別采用專利產出[7]及專利質量(即專利被引頻次)[1,3]來衡量。企業在某一時間周期內的專利產出以該周期申請的專利數量表示。考慮到申請時間較遙遠的專利可能會被更多后續專利引用,某專利的質量以被其他專利引用的年均頻次來衡量,每個企業的專利質量則為企業參與申請的所有專利的年均被引頻次之和。
(2)自變量。自變量包括企業在專利合作網絡中的、企業的知識元素在知識網絡中的度中心性、接近中心性、中介中心性、聚集系數和結構洞數(以下簡稱“位置指標”),自變量計算公式見表1。企業的知識元素在知識網絡中的位置指標為該企業參與申請的全部專利的知識網絡位置指標的平均值,專利在知識網絡中的位置指標為該專利涉及的所有IPC類別(完整分類號,如G06F17/50)的知識網絡位置指標的平均值。
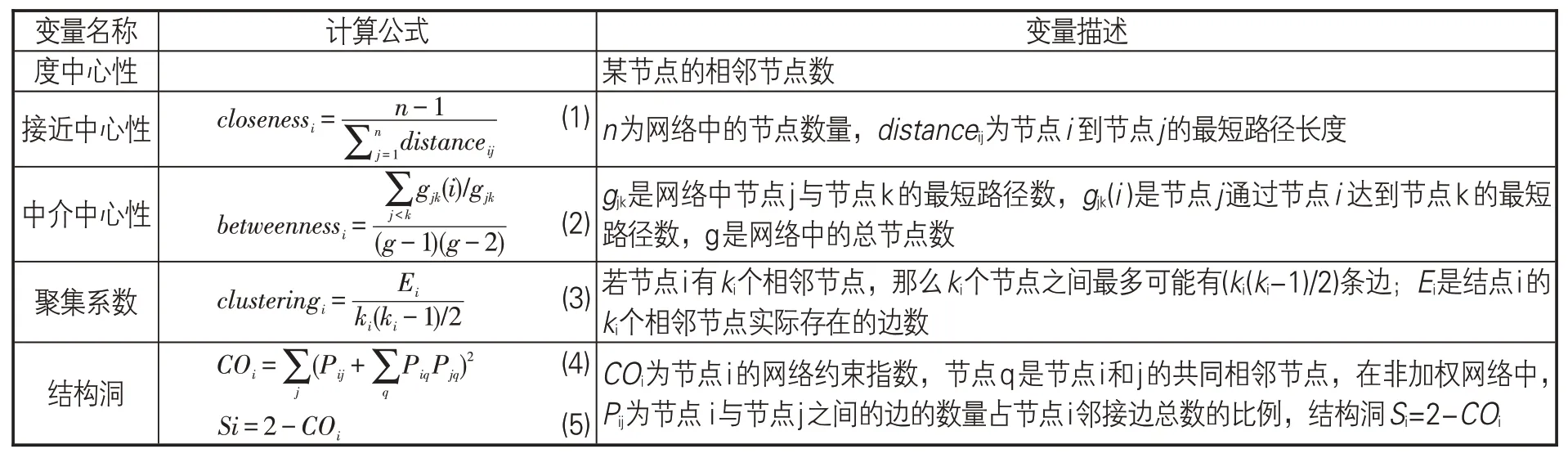
表1 自變量計算公式
(3)控制變量。①專利族數:包括簡單專利族數(Simple Patent Family)和擴展專利族數(Extended Patent Family)。簡單專利族指一組專利族中的所有專利都以共同的一個或共同的幾個專利申請為優先權。擴展專利族指一組專利族中的每個專利與該組中的至少一個其它專利至少共同具有一個專利申請為優先權。專利族大小可以體現發明在技術和經濟上的重要程度[43]。②非專利參考文獻數:專利文獻引用非專利文獻的數量,體現專利對科學知識的吸收與利用[44]。③技術寬度:本文按照專利所屬的IPC號前4位(如G06F)統計技術寬度。專利涉及的技術分類越多,專利所覆蓋的技術范圍越廣,越有可能被更多的專利引用,專利的影響力越大[4]。④布局國家數:企業專利的布局國家數反映了企業的國際市場開拓程度,布局國家數越高意味著專利的地域保護范圍和影響力越大[45]。⑤技術基尼系數:基尼系數是用于衡量居民收入差距的常用指標[46],本文利用基尼系數來衡量企業的技術分散程度,見公式(6)。其中,|Yj-Yi|是某一企業參與申請的所有專利中,任意兩個技術分類出現頻次的差值的絕對值;n是該企業參與申請的所有專利包含的技術分類的個數;u是該企業參與申請的所有專利中,技術分類出現頻次的平均值。基尼系數越接近1,意味著企業的技術布局越集中;基尼系數越接近0,意味著企業的技術布局越分散。
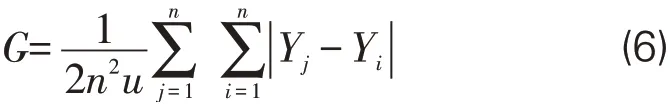
3 研究結果與分析
3.1 變量統計特征及相關性
本研究所使用變量的類型、名稱及縮寫如表2所示。由于一些自變量之間相關系數較大且顯著②,為保證結果不受到多重共線性的影響,將每個自變量單獨納入模型中;每個模型的VIF值均不超過10,不存在多重共線性問題。
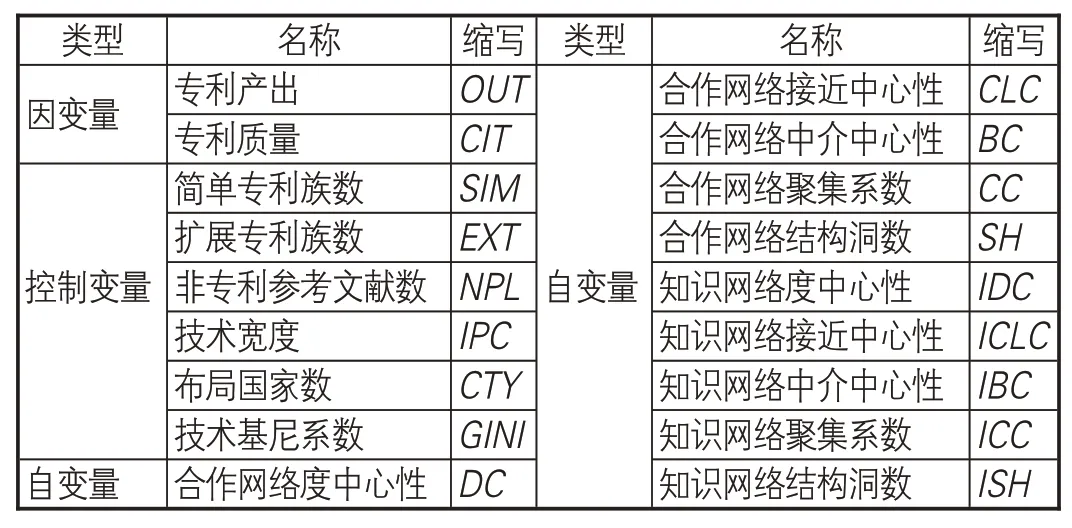
表2 研究變量
3.2 假設檢驗及分析
以專利產出為因變量時,鑒于因變量為計數變量且均值與標準差不相等,采用負二項回歸方法,顯著的回歸結果見表3模型(1)-(7)。以專利質量為因變量時,由于因變量為連續變量,采用多元線性回歸方法,顯著的回歸結果見表3模型(8)-(10)。模型(8)-(10)驗證了H1a中有關企業合作網絡中心性與專利質量的正向影響關系(模型(8):r=0.890,p<0.01;模 型(9):r=95.522,p<0.05;模型(10):r=2,913.260,p<0.01),說明AI企業能夠通過廣泛、密切的合作交換信息總結經驗,進而提升專利創新質量,但合作并不一定帶來創新產出的增加,H1a中有關專利產出的部分未能得到驗證。H1b、H1c分別通過模型(2)和模型(3)驗證了企業在合作網絡中的聚集系數與專利產出的負向關系(r=-0.504,p<0.01)、結構洞與專利產出的正向關系(r=0.612,p<0.01),說明在合作中占據橋梁位置有助于AI企業產出更多專利,但專利數量與質量的提升不具有一致性,H1b、H1c中有關專利質量的部分未能得到驗證。
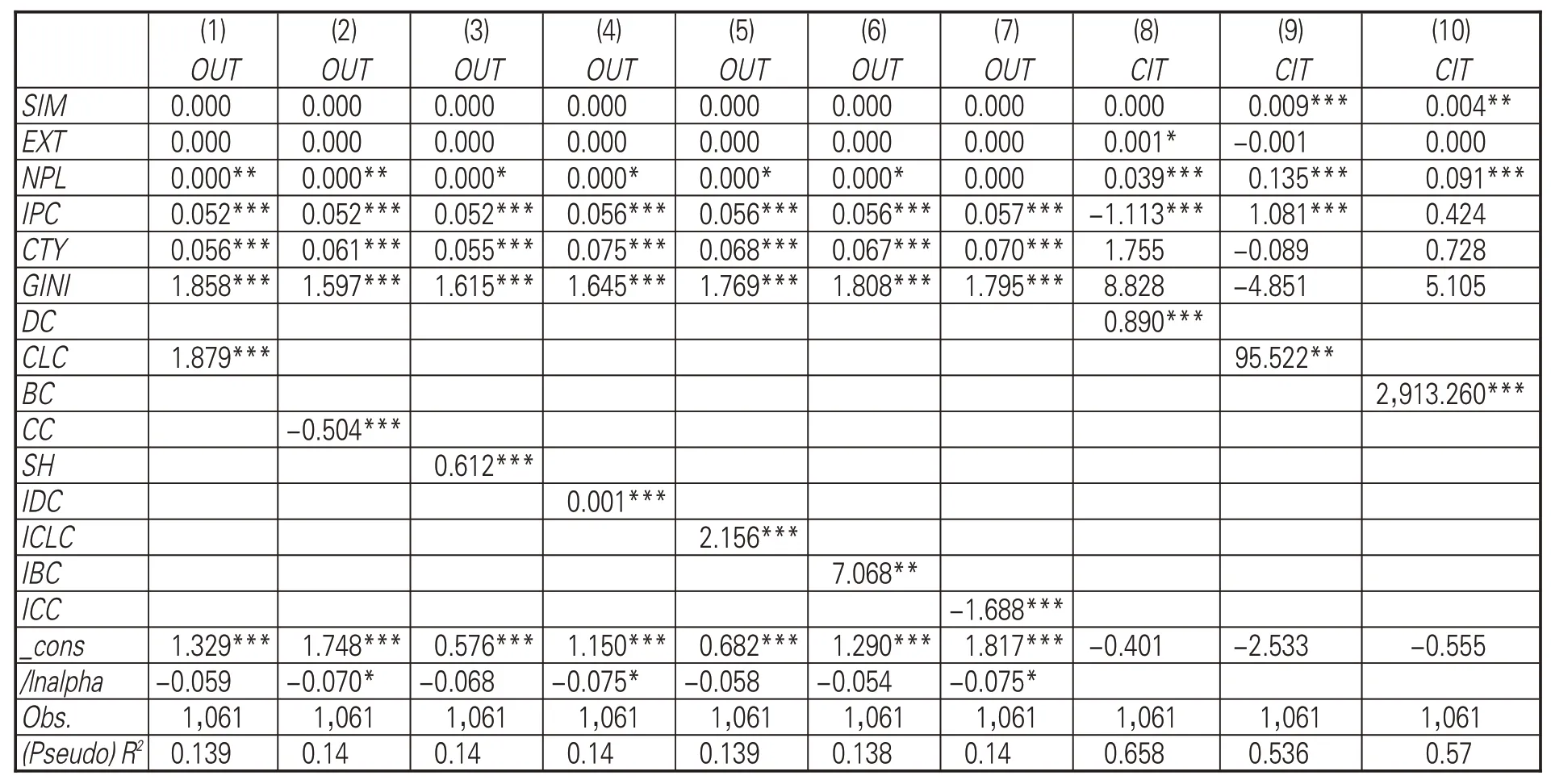
表3 回歸結果
依據模型(4)-(6),知識元素在知識網絡中的度中心性、接近中心性和中介中心性都對企業專利產出具有顯著正向影響,對H2a在專利產出部分是否成立的驗證將在下一節中與其他一次項顯著的變量一起進行。知識元素聚集系數與企業專利產出的負向影響關系在模型(7)中得以驗證(r=-1.688,p<0.01),表明知識局部聚集容易使AI企業喪失持續創新能力,H2b專利產出部分成立。而知識元素結構洞數對企業專利產出及專利質量均不具有顯著影響,H2c不成立。知識元素位置不能顯著影響企業專利質量,說明提升創新質量需要對知識元素進行更深層次的探索,而非對知識元素進行簡單組合。
3.3 非線性效應及穩健性檢驗
為探討知識網絡中心性是否對專利產出和專利質量具有倒U型影響,將知識網絡中心性的平方項加入模型中進行分析,同時將其他一次項顯著的變量的平方項納入回歸進行穩健性檢驗。因變量為專利產出的分析結果如表4模型(1)-(5)所示,因變量為專利質量的分析結果如表4模型(6)-(8)所示。
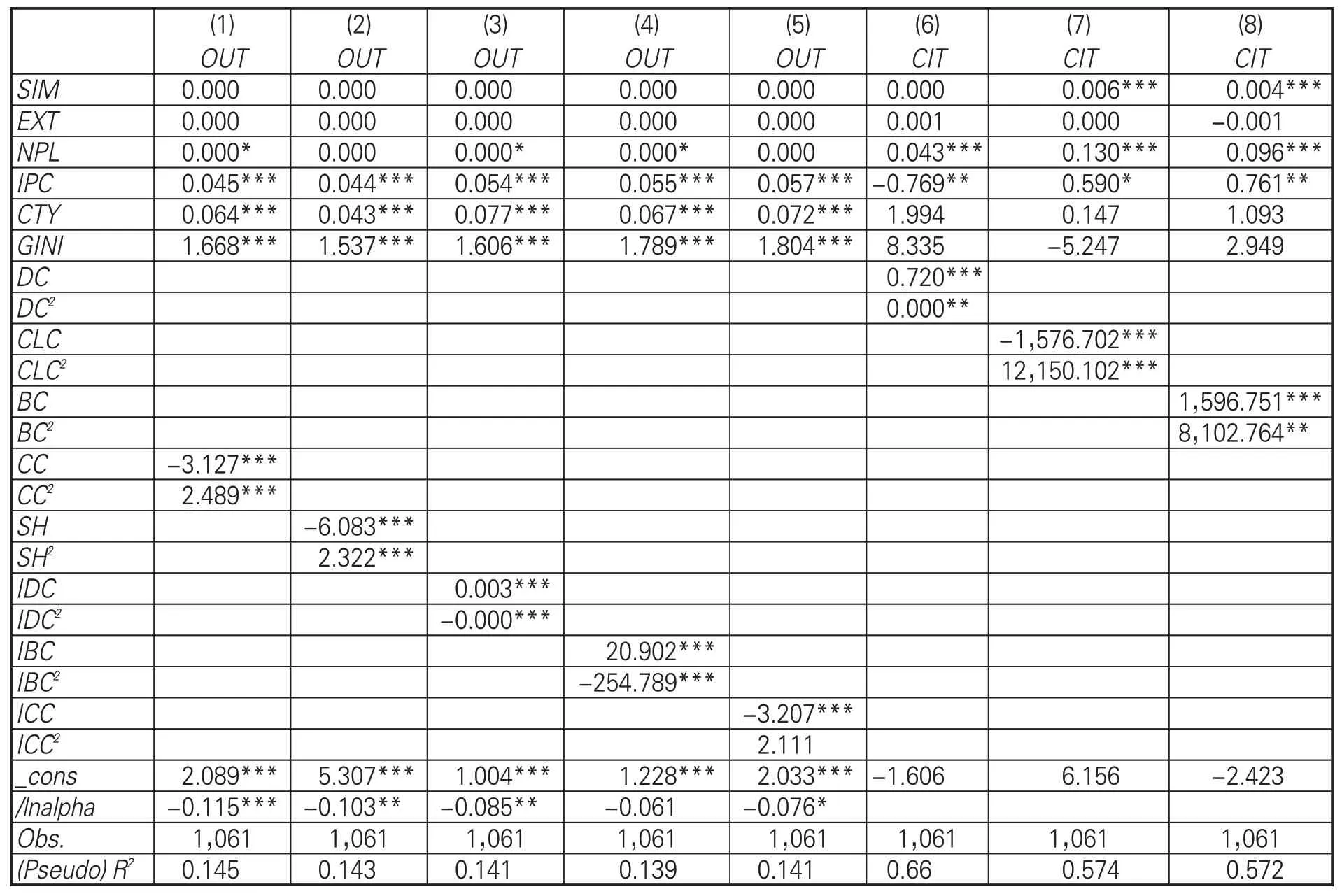
表4 平方項回歸結果
因變量為專利產出時,合作網絡接近中心性、知識網絡接近中心性、知識網絡聚集系數的平方項均不顯著,與專利產出的非線性關系不成立。模型(1)-(2)表明,合作網絡聚集系數、結構洞數可能與專利產出存在非線性關系;由模型(6)-(8)可見,合作網絡中心性可能與專利質量存在非線性關系。模型(3)-(4)中,知識網絡度中心性和中介中心性的平方項均顯著且系數為負,可能與專利產出存在倒U型關系。
為進一步驗證平方項顯著的自變量與因變量是否存在顯著的非線性關系,以各自變量與各因變量的散點圖及二次曲線擬合圖作為輔助工具繼續探究。因變量為專利質量,自變量為合作網絡中心性時,二次項為正的曲線均集中分布在曲線對稱軸右側,即合作網絡中心性對專利質量具有正向影響,H1a在專利質量部分成立。當因變量為專利產出、自變量為合作網絡聚集系數時,曲線二次項為正,且集中分布在曲線對稱軸左側,證明合作網絡聚集系數對專利產出具有負向影響;因變量為專利產出、自變量為合作網絡結構洞數時,曲線二次項為正,且集中分布在曲線對稱軸右側,證明合作網絡結構洞數對專利產出具有正向影響,H1b和H1c在專利產出部分成立。因變量為專利產出、自變量為知識網絡度中心性和中介中心性時,二次曲線圖像均為倒U型,即知識網絡中心性倒U型影響專利產出,說明企業初期利用組合潛力高的知識元素能夠促進自身專利產出,但重復組合的知識元素不能持續推動企業專利創新,H2a在專利產出部分成立。另外,為保證研究結果的可靠性,以IPC分類號前4位(如G06F)區分知識元素并重復了研究過程,得到的結果與采用完整分類號的結果基本保持一致。
可見,企業在合作網絡中占據中心性較高的位置有助于提升其專利創新質量,但無益于增加專利產出數量;合作網絡中處于低聚集系數、高結構洞的位置的企業更容易申請更多專利,但在創新質量上的優勢不明顯;知識元素在知識網絡中的中心性對專利創新數量存在先促進后抑制的作用,知識元素的聚集系數負向影響專利創新數量,但知識元素的位置對企業的專利創新質量并無顯著影響。
4 結論與啟示
4.1 研究結論
合作網絡層面,企業占據合作網絡中心性較高的位置有助于提升專利創新質量,占據橋梁位置有利于提升專利創新數量。社會關系廣泛、密切的企業更容易與合作者交換資源和信息,從而吸取經驗,在高效的合作中開發出具有實用價值的高質量專利。但密切的合作不意味著專利產出的增加,處于成長初期的企業研發能力較弱,傾向于尋求外部合作以滿足創新需求,而具有完善設備和技術的企業研發能力較強,往往偏好獨立研發。在合作中占據橋梁位置的企業通常擁有關鍵技術和資源,這類企業在合作中不可或缺,因此容易產出更多的專利,但受到合作企業水平、市場導向等因素的影響,能夠充分利用企業資源為后續產業發展帶來持續價值的創新仍是少數,創新數量上的優勢并不能保證創新質量的同步提高。
知識網絡層面,容易組合的知識元素對企業的專利創新數量具有先促進后抑制的作用,頻繁局部組合的知識元素會抑制企業產出更多專利。在創新過程的初期,企業充分利用可行性高、組合潛力強的知識元素能夠極大程度提高專利產出數量,但隨著頻繁的局部知識組合和市場的成熟,企業容易面臨同質化的風險,陷入陳舊的技術軌跡,難以持續拓展創新。另外,知識元素的簡單組合不意味著高質量創新的產生,知識元素組合難易程度并不能顯著影響企業的專利創新質量。
以往研究大多認為合作網絡對企業技術創新產出具有良好的促進作用[2,4-9,30-31],而知識網絡對企業技術創新的作用則是先促進后抑制[3,35,40,42]。本文在人工智能領域,不僅驗證了其他領域的早期研究結果,還進一步證明:占據合作網絡的橋梁位置有助于提升專利創新數量,無助于專利創新質量,但是占據合作網絡的中心位置則有助于提升其專利創新質量,而企業擁有的知識元素在知識網絡中的位置同樣不能影響其專利的創新質量。
4.2 管理啟示
首先,管理者應該從單純關注技術知識的內容特征轉向同時關注技術知識的結構性特征在創新中的作用。即便是相同數量和類型的技術知識,通過不同組合形式也會形成多樣的知識結構,管理者應該花更多資源來優化企業的技術知識結構。人工智能是我國大力支持的高端產業,各地“一哄而上”的產業布局容易引發重復建設和同質化問題[47]。人工智能企業應該選擇在知識網絡中處于核心邊緣位置、具有重要發展潛力的新興技術領域進行重點投入研發,在關鍵領域和“卡脖子”技術上尋求突破。
其次,作為高端技術領域內的企業,人工智能企業在合作研發中應該更多承擔“挑大梁”的中心研發角色,而不僅是資源傳遞者的中介角色,以此發揮社會資本的最優價值。為了掌握高質量的創新技術,人工智能企業需要成為外部合作網絡的核心行動者,占據領導地位。當前,人工智能產業的技術深度與產業發展均處于初級階段,商業化過程仍將十分漫長[48]。充分借助社會資本,加強與其他企業、高校、研究所等機構以及個人的合作,有助于為人工智能企業構建起資源共享、人才集聚、協同創新的產業鏈條。
基于2011-2019年人工智能領域的全球專利數據,本文構建680家企業的合作網絡及知識網絡,實證檢驗了不同網絡位置對人工智能企業技術創新的作用機制,彌補了人工智能相關實證研究大多集中在基礎科學或院所層面的不足,從企業角度揭示促進人工智能技術創新的機制與建議。本研究的不足之處在于,文章采集的數據是切片數據,不能體現企業創新產出的動態變化,未來研究可以考慮采用時間序列數據,并加入合作網絡與知識網絡對人工智能企業技術創新的交互作用。
注釋
①資料來源:https://www.lens.org/.
②受篇幅限制,不一一呈現。相關系數較大的幾對自變量:DC和BC(r=0.927,p<0.01),CC和SH(r=-0.782,p<0.01),IDC和IBC(r=0.844,p<0.01),ICLC和ISH(r=0.870,p<0.01)。
猜你喜歡
當代水產(2022年8期)2022-09-20 06:44:30
西安航空學院學報(2022年2期)2022-07-04 07:45:42
當代水產(2022年6期)2022-06-29 01:11:44
當代水產(2022年5期)2022-06-05 07:55:06
當代水產(2022年3期)2022-04-26 14:27:04
當代水產(2022年2期)2022-04-26 14:25:10
云南畫報(2020年9期)2020-10-27 02:03:26
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
