隱私計算技術的金融應用思考
2022-09-17 03:42:14王國賽楊祖艷
金融發展研究 2022年8期
關鍵詞:金融
王國賽 李 藝 陳 琨 時 代 楊祖艷
(1.清華大學五道口金融學院,北京 100800;2.華控清交信息科技(北京)有限公司,北京 100129)
一、引言
近年來,針對大數據應用中頻頻發生的隱私泄露事件,不同國家及地區相繼加強數據隱私保護立法。同時,隨著數據不能流通帶來的壟斷問題日益嚴重,各行業面臨的數據壁壘問題亟待解決。特別地,金融業由于其數據的高敏感性和高價值性特點,在行業內及跨行業的數據共享流通頻頻受阻,使得行業無法充分利用數據要素的價值。2021年2月,《金融業數據能力建設指引》(JR/T 0218—2021)正式發布,首次將“可用不可見”作為金融業數據能力建設應遵循的基本原則,提出在保障原始數據“可用不可見”的前提下規范開展數據共享與融合應用。2022年1月,國務院辦公廳印發《要素市場化配置綜合改革試點總體方案》,明確提出要探索建立數據用途和用量控制制度,實現數據使用“可控可計量”。在旺盛的產業需求推動下,隱私計算技術開始受到各界廣泛關注。許多金融機構積極探索隱私計算技術方案,以合規高效地使用數據。
隱私計算技術亦被稱作隱私增強技術(Privacy Enhancing Technologies,PET)。但此處“隱私”(privacy)一詞指某方(包括個人和機構)不愿公開的信息,如個人隱私信息或機構的商業秘密信息,并非局限于法律意義上的“個人隱私”范疇。總體來看,國內外已有諸多金融機構、科技公司、行業組織及咨詢公司發布了關于隱私計算技術的金融應用報告,為金融業了解典型隱私計算技術的特點、發展現狀、可用場景及實踐案例提供指引(World Economic Forum 和
Deloitte,2019;UN Global Working Group on Big Data,2019;中國信息通信研究院和阿里安全和數牘科技,2020;強鋒等,2021)。
然而,已有研究多為典型隱私計算技術的羅列,并未對所有技術進行系統性梳理,且缺乏對數據流通底層理念的討論。這使得金融業目前對隱私計算的理解還不夠深入,一些底層影響仍值得更多討論。一方面,行業對不同隱私計算技術原理的認識尚不清晰,對不同技術的區別認識還比較模糊,導致一些金融機構在針對業務場景選擇技術時往往存在不少困惑。另一方面,行業尚未關注到隱私計算平臺架構邏輯可能帶來的重大影響。目前已有探討多偏向純技術本身,忽略了宏觀層面平臺架構邏輯對數據流通可監管性的影響。在這種局面下,不可監管的隱私計算平臺架構投入大規模應用,將引發嚴重的數據流通安全隱患。
對此,本文系統總結了當前已有隱私計算應用實踐,指出其大規模商業化應用仍亟待解決的瓶頸問題,并提出加強標準、立法等政策建議,為下階段金融業安全地挖掘數據要素價值、實現數據要素利用社會價值最大化提供參考。
二、隱私計算技術介紹
(一)隱私計算技術分類
按照技術原理,隱私計算技術基本可劃分為三個流派(見圖1)。
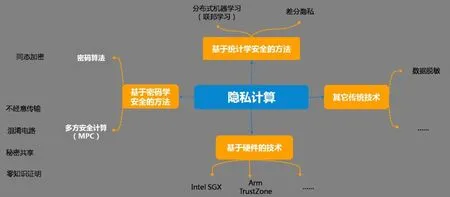
圖1:隱私計算技術流派劃分
1.基于密碼學方法的技術。基于密碼學的隱私計算技術的正確性和安全性具有密碼學證明,其特點是安全強度高,計算準確度高,但計算效率因密文計算有所下降。代表性的此類技術有同態加密和多方安全計算技術,其中,同態加密技術是一種密碼算法。技術理論由Yao(1982)通過提出并解答著名的“百萬富翁問題”而創立。該技術通常采用一系列基礎密碼技術實現,包括混淆電路(Garbled Circuit)、秘密共享(Secret Sharing)和同態加密(Homomorphic Encryption)。
2.基于統計學的技術。此類技術指基于明文數據變換的手段保護原始數據的計算技術,其安全性一般缺乏嚴格的密碼學證明,且計算結果有損。常見的此類技術包括差分隱私和聯邦學習。其中,差分隱私通過加入隨機化噪聲隱藏原始數據。聯邦學習作為一種分布式機器學習方法,是近年來隨著人工智能技術發展而最受關注的一項技術。它最早由Google 提出(McMahan 等,2016),能夠讓多個互不信任的訓練數據提供方在不交換原始數據的情況下,通過交換梯度或參數等中間計算結果協同訓練機器學習模型。通用性方面,聯邦學習主要適用于分布式機器學習模型訓練場景,而不能靈活應用于需要其他通用計算的業務場景。
3.可信執行環境(TEE)。可信執行環境是基于硬件機制的物理隔離,用Enclave 沙盒模型保證數據和計算的安全性和完整性,代表性的有Intel SGX 和ARM TrustZone。在計算過程中,參與計算的數據以加密形式進入可信執行環境,并解密為明文進行計算。因此,可信執行環境的硬件隔離保證了環境內部明文數據和計算邏輯的安全以及結果準確性,但可信執行環境的容量限制及數據出入環境時的加密和解密過程對整體計算性能有一定損耗。
(二)產品架構分類
本文將常見的隱私計算技術架構分為代理計算架構(數據方不互相直連)和無代理計算架構(數據方互相直連),其中后者亦可稱為直連架構。
1.無代理計算架構(直連架構)。無代理計算架構中,金融機構及其他數據源平臺作為數據方,直接參與隱私計算過程,即數據方同時擔任計算方的角色。該架構的常見形式是對等網絡(peer-to-peer)架構、客戶端—服務器(client-server)架構和主—從(master-worker)架構。對等網絡架構如圖2所示。具體地,兩個數據提供方A和B分別部署有一個計算節點,彼此通過網絡直連,在隱私計算過程中進行密文數據交互,從而實現雙方數據參與協同運算。
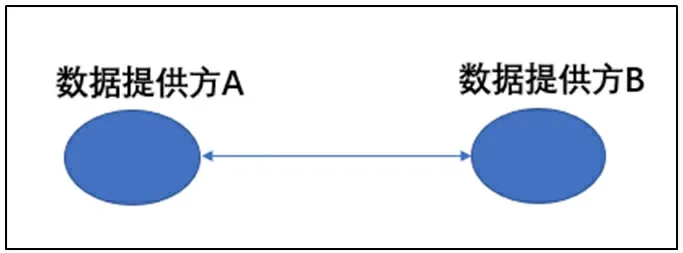
圖2:對等網絡(peer-to-peer)架構
客戶端—服務器架構常用于特定場景的兩方或隱私計算,例如兩方隱私集合求交(Private Set Intersection)計算、隱私信息檢索(Private Information Retrieval)計算以及某些同態加密計算和部分聯邦學習場景的聯合建模計算。典型隱私計算場景的客戶端—服務器架構如圖3所示。各數據方通過網絡直連,其中不同的數據方作為服務器或客戶端協同參與計算任務。

圖3:多方無代理計算架構
2.代理計算架構。在代理計算架構中,計算方參與隱私計算的過程,數據方和計算方可以不同。這種數據和計算耦合的架構可以實現高可擴展性:隱私計算平臺可以在不定制化設計協議的情況下,支持接入任意兩方或多方的數據源完成計算任務。我們可以視為數據方將對其數據的計算任務代理給了其他節點(計算方)完成。
該架構有兩種常見的形式,一種是由一套分布式集群執行密碼學的協議(多方安全計算協議),其架構如圖4所示。我們可將這類架構中分布式的代理計算節點統一視為一個“虛擬的中心計算節點”。但這種“虛擬的中心計算節點” 和前文所述的無代理計算的客戶端—服務器架構有本質的不同:分布式的代理計算節點集群是通過分布式的密文數據計算實現了去中心化的信任,代理計算節點只執行密碼學協議計算,不提供輸入數據。其安全性假設和實現的安全特性也和客戶端—服務器架構不同。另一種形式的代理計算架構通過利用可信執行環境(TEE)技術構建一個可信第三方。各數據方將其數據進行非對稱加密后上傳至TEE節點,在TEE節點內部,數據被解密為明文,參與計算過程。
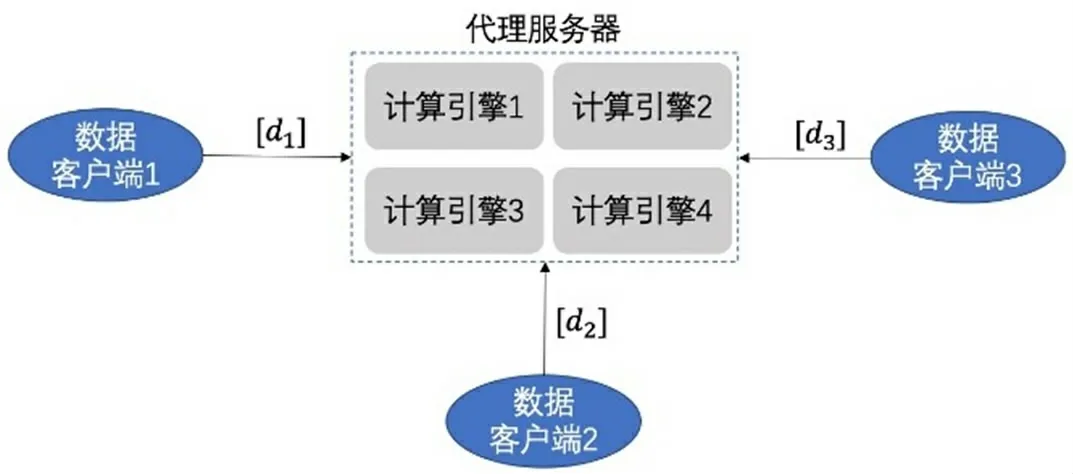
圖4:多方代理計算架構
3.兩種架構對比分析。首先,通用性方面。無代理計算的架構通常難以實現通用的隱私計算。代理計算架構通常支持任意多個數據方。如果數據方本地也有進行明文計算的能力,則代理計算架構除純密文計算外,也可支持更通用的明密文混合計算(明密文混合計算可用于實現聯邦學習)。
其次,可擴展方面。無代理平臺對于數據方數量變化的場景需要重新定制化地設計算法,可擴展性低。基于多方安全計算技術或TEE的代理計算架構可實現通用的安全計算,適用的金融場景更廣泛。
最后,可監管性方面。由于無代理計算沒有中心服務器,每個參與方的計算節點存證分布分散,監管方無法有效監測數據加密、傳輸及計算是否采用了正確的協議。因此,監管方難以避免參與方利用監管漏洞,通過平臺直接交換明文數據進行協同運算,導致嚴重的隱私泄露或數據不合規使用的風險。而在代理計算中,中間代理計算節點能為監管方提供持久化的數據和計算任務的存證,便于監管方進行統一監管和審計,及時發現惡意節點違背協議造成參與方之間數據不合規使用的問題,實現高效數據治理。因此,代理計算模式更易實現“技術去中心化、監管中心化”的安全數據融合。
三、隱私計算金融應用現狀
根據公開資料,當前國內外金融業已有的隱私計算技術應用主要有三種:一是通過聯邦學習實現的聯合建模,并結合多方安全計算技術、差分隱私以及基于硬件的可信執行環境保護參與方的數據隱私;二是使用多方安全計算技術直接實現隱私查詢、聯合建模及聯合統計,通過密碼學協議保障參與方的數據信息安全;三是部署可信執行環境,如Intel SGX 和ARM TrustZone,通過物理隔離各參與方的數據而進行的安全多方聯合統計及聯合建模。上述應用主要來自銀行業和保險業,所覆蓋的場景包括產品營銷、風控及反洗錢業務等。根據金融機構的反饋,這些技術在試點中均實現了內外部數據的安全連通,聯合建立的模型預測準確度有顯著提升。
(一)聯邦學習應用逐步興起
近年來,隨著人工智能金融應用逐步興起,基于該分支的聯邦學習金融應用逐步增多。由于交換的梯度或參數往往可用來推斷甚至恢復原始數據信息(Kairouz等,2019;Zhu等,2019),這些中間計算結果的交換過程通常需采用基于密碼學的技術(如多方安全計算)及差分隱私技術來規避這些風險。因此,在實踐中,聯邦學習往往與多種隱私計算技術相結合,以規避中間信息交互存在的隱私安全隱患。具體包括:
1.“聯邦學習+同態加密”較為流行。當前,由于某開源框架帶來的易獲得性,國內金融業的聯邦學習試點應用多數采用基于同態加密的多方安全計算協議,在模型訓練環節將交換的梯度或參數進行加密以保證各建模參與方的數據隱私性。較為代表性的案例有神盾—聯邦計算平臺、FATE、百度金融安全計算平臺、蜂巢聯邦智能平臺以及Fedlearn。其中,蜂巢聯邦智能平臺亦可選擇差分隱私技術,通過給交換的中間數據加入噪聲而避免各方信息被直接泄露(蔡芳芳,2020)。這些平臺已分別聯合商業銀行、互聯網金融平臺、消費金融機構及保險公司開展試點應用,利用自身沉淀的用戶行為數據,和銀行或保險機構的客戶金融數據進行聯邦學習建模,建立更精準的保險產品定價(蔡芳芳,2020)、信貸風險預測(騰訊安全,2020;謝國斌,2020)以及洗錢行為偵測模型(FedAI 聯邦學習,2020)。
從平臺架構角度看,上述試點應用的聯邦學習計算平臺架構均為對等網絡模式,無法支持集中監管和審計的功能。一旦出現以隱私計算技術的名義進行非法數據交易的現象,其難以監管的潛在風險應引起高度警惕。
2.“聯邦學習+秘密共享”優勢初顯。基于秘密共享的多方安全計算協議實現的聯邦學習應用中,典型的有PrivPy 平臺。該平臺架構為代理計算模式,各參與方在每輪迭代中在本地執行明文數據的模型訓練,并將梯度或參數通過秘密共享加密后發送給代理計算中心進行密文聚合計算。計算完成后,更新的參數以密文形式發送給各參與方用于本地下一輪訓練。由于PrivPy平臺實現的是明密文混合計算,即本地訓練基于明文數據,中間結果加密,其在保證無梯度信息泄露的情況下實現了高效建模(中國信息通信研究院,2021)。
3.“聯邦學習+可信執行環境”在國外發展迅速。目前,也有一些金融機構在聯邦學習建模過程中采用可信執行環境實現各方數據及計算節點的物理隔離,從而防止數據在計算過程中被竊取。基于可信執行環境的聯邦學習案例中,較為代表性的是美國金融科技公司Consilient 與Intel 合作建立的聯邦學習反洗錢平臺(Shiffman等,2020)。該平臺的架構為代理計算模式,參與建模的銀行和中心計算服務器均部署有Intel SGX 提供的可信執行環境。在建模過程中,各參與銀行在其可信執行環境內明文訓練本地模型,并將中間梯度或參數以加密形式傳輸至中心計算服務器的可信執行環境內進行聚合并計算,從而更新整體模型。隨后,新的參數再以加密形式反饋至各銀行的可信執行環境內進行解密并計算,更新本地模型。根據Consilient 的報告,與傳統反洗錢模型高達95%的誤報比例相比,該平臺聯合5 家銀行建立的反洗錢模型的誤報比例低至12%,在降低傳統反洗錢業務成本的同時大幅度提高了預測精準度(Shiffman 等,2020)。目前,該平臺處于測試階段,可實現大于兩家機構的聯邦學習建模。
(二)多方安全計算金融試點全面鋪開
相較于聯邦學習,多方安全計算的通用性更強。除聯合建模外,后者亦可實現隱私查詢、聯合統計、數據交易等計算場景。在我國,金融行業充分重視多方安全計算技術,頂層設計頻頻出臺。2019年8月22日,中國人民銀行發布《金融科技(FinTech)發展規劃(2019—2021年)》,要求“構建適用互聯網時代的移動終端可信環境,充分利用可信計算、安全多方計算、密碼算法、生物識別等信息技術,建立健全兼顧安全與便捷的多元化身份認證體系”。2020年11月24日,《多方安全計算金融應用技術規范》(JR/T 0196—2020)(以下簡稱《技術規范》)正式發布,其規定了多方安全計算技術金融應用的基礎要求、安全要求、性能要求等,為技術服務提供商、解決方案提供商和金融機構在產品設計、開發和應用方面提供了指引。2021年7月,《多方安全計算金融應用評估規范》(T/PCAC 0009-2021)正式出臺,作為進一步落實《技術規范》的具體舉措,對《技術規范》中的各項條目明確了其適用性、評估方法和通過標準,為金融檢測評估機構順利開展對多方安全計算產品的相關檢測認證工作提供依據,將推動多方安全計算金融應用產品的大規模有序落地,在保障信息安全前提下實現多個主體間的數據共享與融合應用。
實踐方面來看,自2020年金融科技試點項目推廣以來,我國目前已有十個涉及多方安全計算技術的項目成功進入創新試點,涉及場景包括金融消費者人臉信息保護、產品營銷、跨境結算、小微企業融資和信貸風控等。筆者根據公開材料對相關試點進行了總結,如表1所示。
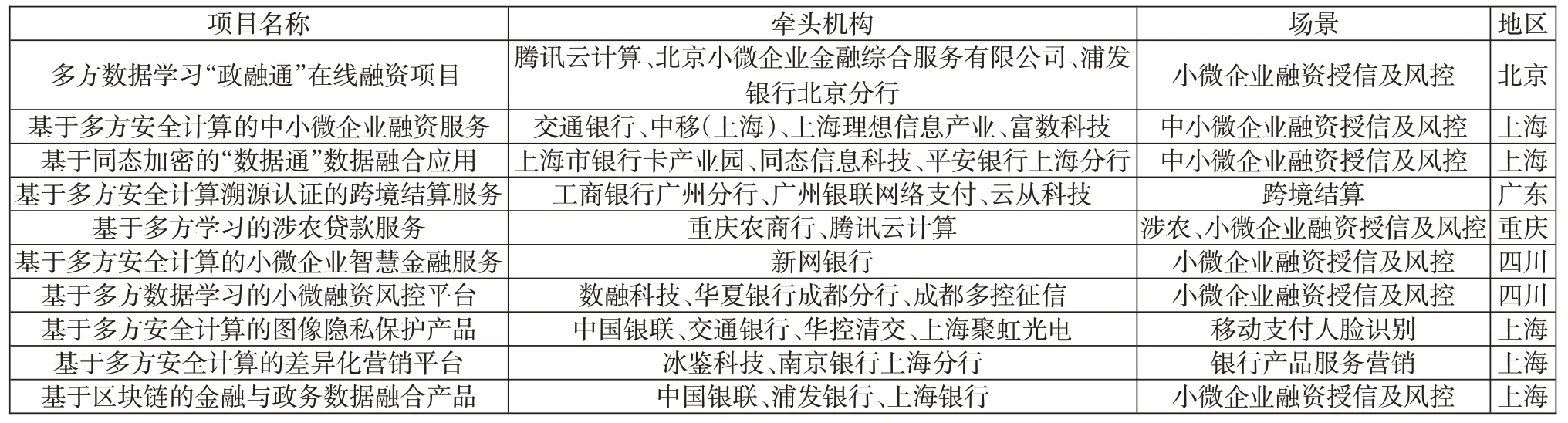
表1:基于多方安全計算的金融科技創新應用試點總結
在海外,諸多國家和地區的金融監管當局亦認識到多方安全計算技術對監管科技發展的重要性,并積極在反金融犯罪領域開展試點。例如,英國金融行為監管局(Financial Conduct Authority,FCA)在2019年舉辦了全球反洗錢和反欺詐技術競賽(2019 Global AML and Financial Crime TechSprint),共有由世界知名科技公司、金融集團及咨詢公司構成的140 余個小組參賽。在勝出的十個小組中,三個小組應用了基于多方安全計算的技術方案,解決了欺詐行為識別、反洗錢客戶身份識別(Know Your Customer,KYC)、交易關聯分析等場景的數據壁壘痛點(Financial Conduct Authority,2019),具體信息如表2所示。
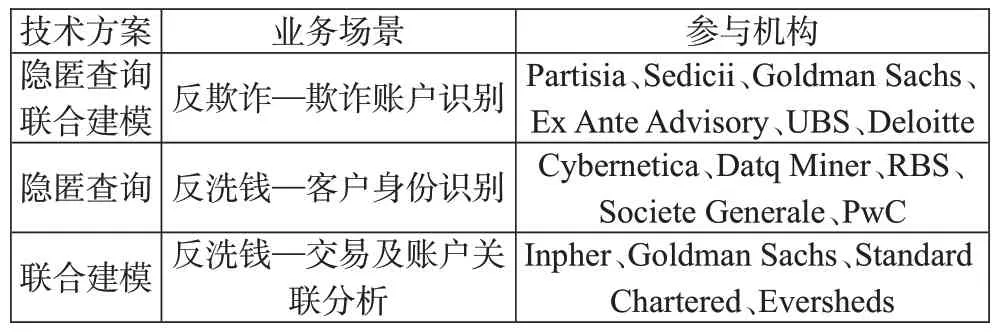
表2:2019年全球反洗錢和反欺詐技術競賽中多方安全計算試點匯總
具體應用方面,國內外金融業已有一些多方安全計算技術的落地應用,典型的有螞蟻鏈摩斯多方安全計算平臺、XOR Secret Computing 平臺、Duality SecurePlus系列產品以及PrivPy平臺。其中,前三者主要針對的是銀行業信用卡評分及反欺詐場景。這些平臺應用基于同態加密及秘密共享協議的多方安全計算技術,安全融合不同銀行沉淀的用戶金融數據以及外部機構存儲的行為數據,聯合建立信用卡評分模型以及信用卡反欺詐模型。PrivPy 平臺實現的應用更為全面,其定位為數據要素流通的基礎設施平臺,已落地的金融應用場景包括企業級數據融合平臺—人臉識別隱私保護、行業級數據融合平臺—個人合格投資者(QI)認證以及跨行業數據融合平臺——政務金融數據融合應用等(王云河和李藝,2021)。根據公開資料及市場調研結果,上述平臺中,前三者均采用的是對等網絡架構,因而存在較難監管、潛在數據安全風險大的問題;PrivPy 采取的是代理計算模式,支持“中心化管理”,便于監管方有效監測數據交易的合規性。
(三)可信執行環境應用尚不突出
當前一些金融機構也實現了僅依賴可信執行環境進行的多方協同計算,典型的應用有百度安全開發的Mesa TEE 計算平臺。該平臺為全球首個通用安全計算平臺,通過Intel SGX 提供的可信空間物理隔離各方數據,從而完成安全的多方協同計算任務。Mesa TEE提供的安全計算解決方案包括金融聯合建模及可信身份認證,能夠幫助金融機構在風控環節融合多維度的用戶特征數據,建立跨機構的精準風控模型。另外,Mesa TEE 采用代理計算模式,用可信中心節點代替多方互信,參與方的數據交互至中心節點進行計算,避免了各參與方兩兩交互數據造成的延遲和吞吐開銷,同時支持對數據使用情況的中心化監管(FreeBuf,2019)。
四、隱私計算金融應用現狀思考
上述實踐表明,金融業已經領先其他行業,先行探索隱私計算技術的各種應用。總體來看,這些應用存在以下特點:
一是重視技術應用,但對產品架構關注不足。特別是整個行業在認知方面,雖已體現出技術組合的思路,但仍存在重視技術而忽略產品架構的問題。多數探索應用采用的仍為網絡直連架構,其大規模商業化應用可能帶來的數據流通中負外部性及風險監管值得高度關注(徐葳和楊祖艷,2021)。在整個行業發展初期,忽略上述安全隱患,可能造成后期一旦爆發嚴重的數據安全事件,出現“一刀切”的行業集中整治,導致“劣幣驅逐良幣”的不良后果。因此,在大規模商業化應用之前,金融業應就上述問題在業內組織各方專家充分論證、審慎推進。
二是單點應用較多,尚未實現系統全面的業務創新。目前來看,已有探索均是單個機構、單個集團基于自身需要,聯合相關機構進行試點,而行業內及跨行業的數據要素流通還有待進一步加強。從需求來看,金融業的數據融合需求,除涉及銀行、證券和保險等不同細分行業外,更多涉及政務、醫療、教育等行業外數據。要推動整個金融行業通過隱私計算,實現數據要素價值的充分釋放,更大的推動力來自金融業務人員認識到隱私計算技術的價值。因此,金融機構還需進一步推動相關科技部門、業務管理部門加強溝通,為通過數據要素融合實現金融業務創新奠定基礎。另外,金融業現有隱私計算產品多由不同技術廠商自行搭建,造成產品間的差異性較大,難以互聯互通。隨著此類產品的建設及使用規模逐漸擴大,金融業極易出現“技術孤島”現象。同時,部分金融機構及技術廠商已在小范圍內自行探索產品互聯互通方案,將進一步造成行業“數據群島”的局面,將對日后實現金融業整體數據流通共享、數據生態建設造成阻礙。
三是微觀討論較多,對數據要素化的宏觀影響關注較少。長期以來,傳統金融機構在數據維度、數據實時性等方面處于劣勢,不得不“讓資本去找數據”,出現金融業務“無牌經營”的一系列市場亂象,給金融監管帶來較大挑戰。與此同時,金融行業自身積累的在資本要素配置上的優勢卻無法得到發揮。隱私計算技術為金融科技賦能,本質上應致力于推動整個金融行業打破“擇數據而產”的低效狀態。特別是金融行業可構建自身數據生態,實現“數據找資本”,充分利用數據要素在信息獲取、風險判斷方面的核心價值,幫助互聯網平臺輸出數據使用價值,獲取有利報酬,實現互聯網平臺和傳統金融業的共同健康發展。
因此,金融業要實現隱私計算技術的商業化推廣,還需要解決以下四個方面問題:一是在技術層面,行業應統一對各技術原理和特性的認識,同時要提高技術架構對數據安全、可監管性影響的重要性認識,凝集行業共識,以易監管的數據流通模式,提前防范技術錯用或濫用造成的信息泄露風險。二是在業務層面,金融機構中目前關注隱私計算技術的多為技術部門,業務部門對這些新興技術的認識還較為有限,也沒有打開能充分利用數據要素的想象空間,基于數據融合的業務創新活力亟待激活。三是在行業統籌層面,金融業應適時規劃隱私計算平臺進行互聯互通,避免產品算法差異造成“技術孤島”。具體地,先在集團級、行業級、跨行業層級分別建立數據流通基礎設施,形成各層級的數據融合基礎設施。隨后,該三級生態體系的基礎設施可進行互聯互通,前一層級生態作為后一層級生態的有機組成部分,共同形成互利互惠、良性循環的金融數據生態圈(中國工商銀行股份有限公司金融科技研究院和華控清交信息科技(北京)有限公司,2021)。四是在法律層面,推廣隱私計算技術要能實現數據安全和數據開發利用并重,打破數據立法基于明文的隱憂,構建一套符合我國國情需要的、讓數據流通和數據安全有效平衡的數據法律體系,為金融業數據生態健康發展提供司法保障。
五、下階段應用建議與展望
展望未來,解決隱私計算大規模應用的問題,需從行業和立法兩方面入手。首先,金融領域應圍繞標準制定加強行業交流,重視對于數據外部性風險治理的考量,并將其根植于隱私計算平臺架構。具體地,標準應納入“代理計算”架構,引領行業打造支持“去中心化計算、中心化監管”的數據安全融合平臺,實現可監管、可審計的安全數據流通。其次,金融機構內部應將隱私計算技術的理念從技術部門擴展到業務部門,讓后者能夠針對場景的數據需求廣泛開闊思路,更好發揮數據要素的倍增作用,實現各項金融業務創新發展。在此基礎上,金融業權威第三方機構應統籌規劃隱私計算平臺互聯互通建設,形成支持全行業范圍的數據融合共享基礎設施,促進金融數據生態共榮發展。最后,在法律層面,數據立法應加強技術思維,明晰隱私計算技術應用可以實現的數據共享價值,避免因立法思維止步于明文數據共享而無法取得數據融合與數據安全的平衡。
上述問題的有效解決將使機構合理運用技術,政府實施有效監管,助力隱私計算技術在金融業的商業化應用。通過可監管的技術架構,金融行業將有效避免利用隱私計算技術進行非法數據交易的行為,整體實現行業健康發展,同時為我國數據要素市場建設提供行業標桿性示范。
①兩方各有一個樣本集合,在每方不向對方暴露自身不屬于交集的樣本子集的情況下求解兩個集合的交集。
②一方查詢另外一方或幾方的數據,但不暴露自身的查詢條件。
③騰訊安全開發。
④深圳前海微眾銀行股份有限公司開發。
⑤北京百度網訊科技有限公司開發。
⑥平安科技(深圳)有限公司開發。
⑦京東科技集團開發。
⑧華控清交信息科技(北京)有限公司開發。
⑨螞蟻集團開發。
⑩美國隱私計算技術公司Inpher開發。
?美國隱私計算技術公司Duality Technologies開發。
?百度安全官方網站:https://anquan.baidu.com/product/mesatee.
猜你喜歡
中國外匯(2019年20期)2019-11-25 09:55:00
中國外匯(2019年7期)2019-07-13 05:44:54
中國外匯(2019年7期)2019-07-13 05:44:50
金橋(2018年12期)2019-01-29 02:47:36
知識經濟·中國直銷(2018年12期)2018-12-29 12:22:40
新財富(2017年7期)2017-09-02 20:06:58
新財富(2017年7期)2017-09-02 20:03:21
中國工程咨詢(2016年10期)2016-01-31 03:12:10
股市動態分析(2015年50期)2015-01-05 10:50:34
金融法苑(2014年2期)2014-10-17 02:53:24
