基于FCN-CRF 的醫(yī)療命名實體識別
2022-09-14 08:19:52潘勝星唐雅娟
電子設計工程 2022年17期
潘勝星,唐雅娟
(汕頭大學電子工程系,廣東汕頭 515063)
在醫(yī)療領域中,存在大量的非結(jié)構化文本,如醫(yī)療主題的文獻、病歷記錄等。通過信息抽取技術,可以從大量非結(jié)構化文本中高效地抽取出感興趣的信息,在后續(xù)任務中使用,如自動醫(yī)療問答、智能醫(yī)療診斷等。
命名實體識別(Named Entity Reconition,NER)任務是信息抽取的一個基礎任務,旨在從非結(jié)構化文本中抽取出特定的實體。該任務可以被看作一個序列標注任務[1]。文獻[2-4]提出以LSTM-CRF 為基本框架的模型進行命名實體識別,該模型主要利用了字級別的信息進行標注。文獻[5-6]對LSTM 單元進行了修改,使其動態(tài)地結(jié)合詞信息,但無法并行計算。文獻[7]延續(xù)該思路,引入rethinking 機制,并將LSTM 單元換為CNN 單元,從而實現(xiàn)單樣本輸入的并行計算,提高GPU 的利用率。文獻[8-9]將圖神經(jīng)網(wǎng)絡引入NER 中,用節(jié)點之間的路徑表示詞匯信息,對節(jié)點進行信息的聚合從而得到標注結(jié)果。文獻[10]將表示詞BMES 信息的向量與字級別的向量表示拼接后送入模型中。整體來看,基于詞典增強的方法需要對每一個輸入模型的句子進行潛在詞匹配,該過程的時間復雜度通常是O(n2)級別的,而輸入文本長度通常在20~200 個字符之間,因此訓練模型所需的時間非常長。
語義分割任務同樣可以看作一個序列標注任務,區(qū)別在于語義分割作用于二維的圖像。語義分割與NER 類似,標注都具有連續(xù)性以及平移不變性。基于兩個任務的相似性,提出將FCN 模型引入NER 任務中。實驗結(jié)果表明,F(xiàn)CN 模型應用于命名實體識別時可以得到與基于詞典增強的方法相似的性能,同時無需詞信息,因此訓練所需的時間大幅度縮短,更易于在實踐中使用。
1 任務比較
從表面上看,語義分割與命名實體識別是不同的任務,一個來自計算機視覺領域,另一個來自自然語言處理領域。但事實上,這兩個任務具有頗多相似性。
1.1 標注的單位
圖像語義分割任務處理的對象是二維的圖像,而命名實體識別任務所處理的對象是一維的文本。二者都可以被看作是序列標注的問題,語義分割標注的單位是像素,而命名實體識別標注的單位是字。
1.2 最小單位的表示形式
圖像的像素在計算機中一般會被表示為一個RGB 三通道的向量,而文字在計算機中則會被映射為表示字符的向量。即兩個任務輸入的最小單位都是向量,輸入的是向量的序列。
1.3 平移不變性
兩個任務標注出的內(nèi)容均具有平移不變性。圖像中,分割出的物體不因位置改變而改變其所屬類別;文本中,抽取出的實體不因其在文本中位置的移動而改變類別。
1.4 語義連續(xù)性
每個最小單位并非孤立地標注,而是受周圍標注的影響。在圖像中,被標注為天空的像素點附近的像素點,其標簽更可能依然是天空,而有較小的可能性是人或者汽車。在文本中,被標注為B-類別1的文字之后,通常只能接續(xù)位置為M 或者E 的標簽,且不能被標注為1 之外的類別。由于該特性的存在,語義分割的模型中有引入CRF 優(yōu)化輸出的方法[11],而在NER 中,在最后輸出標簽之前使用CRF 則是幾乎目前所有方法的共同選擇。
2 FCN-CRF模型
該節(jié)將原本應用于語義分割的FCN 模型的結(jié)構進行修改,得到FCN-CRF 模型。
2.1 整體結(jié)構
FCN-CRF 整體結(jié)構與FCN 基本一致,保持了“編碼器-解碼器”結(jié)構。編碼器部分由多個卷積層組成,逐層抽取特征并映射為標簽分數(shù),在解碼器一側(cè),從最后一層卷積層輸出的標簽分數(shù)開始,往前逐層使用轉(zhuǎn)置卷積結(jié)合信息,輸出分數(shù)。
2.2 輸入層
在輸入層,對于一個輸入的文本序列X={x1,x2,...,xn}中的每一個字xk,通過一個嵌入查找表ec得到對應的向量,表示為ek[12],如式(1)所示:

2.3 編碼器
編碼器部分由數(shù)個卷積層組成。與圖像不同,文本由于長度相差較大,通常不會被全部填充到一樣長度,而是按照長度排序,分批送入模型前對該批次文本填充到統(tǒng)一長度[13],因此輸入文本長度是不統(tǒng)一的,模型在運算過程中需要保持輸入的長度不變。因此在編碼器中,卷積層使用尺寸為3、填充為1 的一維卷積,從而保持文本長度不變。需要注意的是,雖然文本序列可以被表示為向量序列,看作一個二維矩陣,但每一個向量是需要被整體看待的,如果使用二維卷積則會破壞每個向量的信息完整度,因此需要選擇一維卷積[14-15]。
此外,同樣是考慮到文本長度保持不變,因此池化操作被去除了。
2.4 解碼器
解碼器部分主要由轉(zhuǎn)置卷積層組成,例如,一個5 層的FCN-CRF。在編碼器的每一層,先抽取特征并映射到類別分數(shù),然后將第5 層的分數(shù)與第4 層融合,并使用轉(zhuǎn)置卷積重新映射到類別分數(shù),得到結(jié)合了兩層信息的結(jié)果。以此類推,然后將該結(jié)果與第3層的分數(shù)融合,再次使用轉(zhuǎn)置卷積。其中,轉(zhuǎn)置卷積與在語義分割中的設置不同,這里不需要對文本序列進行上采樣,因此填充設置為1,使得經(jīng)過轉(zhuǎn)置卷積后的長度與輸入時相等。
2.5 條件隨機場
經(jīng)過解碼器后,模型得到了關于輸入序列的標注分數(shù)序列。但此時輸出的標簽,對于前后的關聯(lián)性考慮不夠強,因此,與目前的主流方法一致,在最后輸出之前使用條件隨機場對輸出序列進行約束[16-17]。
3 實驗結(jié)果
在瑞金糖尿病數(shù)據(jù)集上,對FCN-CRF 模型的性能進行測試,并選取了BiLSTM-CRF、Lattice LSTM、LGN 3 個模型作為對照。其中BiLSTM-CRF 是基于字級別信息的模型,而Lattice LSTM 與LGN 則是基于詞典增強的模型。
瑞金數(shù)據(jù)集包含493 篇糖尿病領域的醫(yī)學文獻,標注者都具有醫(yī)學背景。首先,對數(shù)據(jù)集進行預處理,包括去除無效字符,劃分句子,限制句子長度在20~200 個字符之間。防止過長的序列使訓練時中間保存的梯度過多導致顯存不足,也防止過長的序列導致CRF 進行解碼時效率過度下降。
模型的隱藏層單元數(shù)均為200,dropout 設置為0.1,優(yōu)化器使用Adam,權值衰減為10-8。每個模型訓練20 個epoch。對數(shù)據(jù)集做十折交叉驗證得到實驗結(jié)果。輸入部分使用word2vec 在中文語料上訓練得到的長度為100 維的詞向量。
實驗在Windows10 系統(tǒng)下進行,IDE 是Pycharm,深度學習框架為Pytorch。評價指標選擇準確率(P)、召回率(R)以及F1,按照NER 中的嚴格F1 標準進行結(jié)果統(tǒng)計,記S為預測出的實體集合,G為句子中真實的實體集合,P、R、F1 的計算方式分別如式(2)-(4)所示。
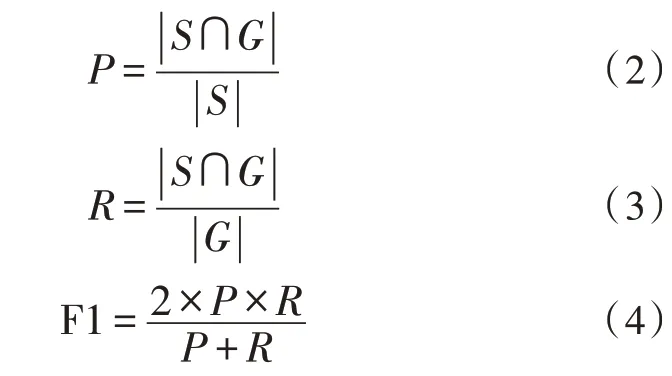
FCN-CRF 模型最佳性能與其他模型對比的結(jié)果如表1 所示。可以看到FCN-CRF 超過BiLSTMCRF 約2.6%。與Lattice LSTM、LGN 模型的表現(xiàn)非常接近,F(xiàn)1 值差距在1%以內(nèi)。表1 中展示的時間為FCN-CRF 在瑞金數(shù)據(jù)集上訓練100 個epoch 后求得每個epoch 的平均訓練時間,可以看到FCN-CRF 的時間僅為基于詞典的方法的不到2%。
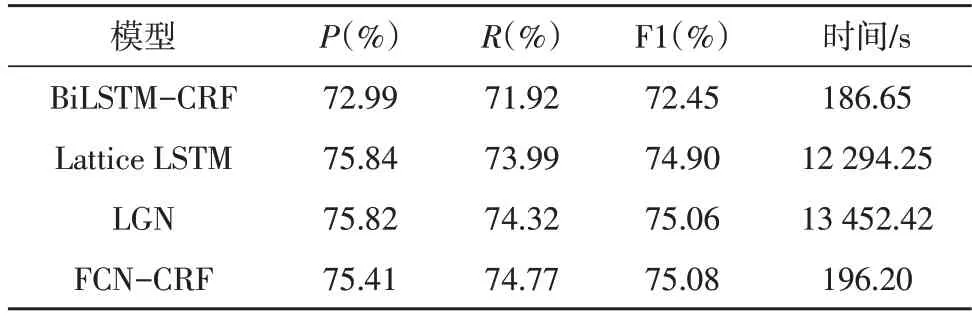
表1 各模型的實驗結(jié)果
接下來,對不同層數(shù)的FCN-CRF 進行了實驗。不同層數(shù)的性能如圖1 所示,從圖中可看出在瑞金數(shù)據(jù)集上,7 層的FCN-CRF 可以達到最好的效果。當層數(shù)堆疊更多時,模型性能反而下降,因為此時模型的參數(shù)冗余開始產(chǎn)生過擬合。
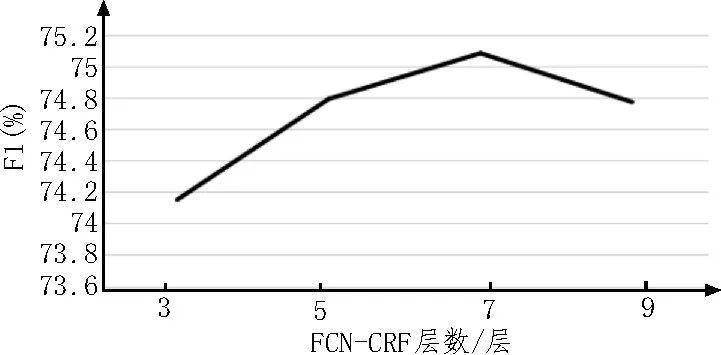
圖1 不同層數(shù)的性能
表2 中展示了轉(zhuǎn)置卷積層對于模型性能的影響。可以看到,將解碼器部分的轉(zhuǎn)置卷積層全部換為卷積層時,在FCN-CRF 為7 層時,性能出現(xiàn)明顯下降。該現(xiàn)象可以解釋為,在解碼器部分使用卷積層時,相當于繼續(xù)向更高層次抽取特征,該操作反而使得模型性能下降。
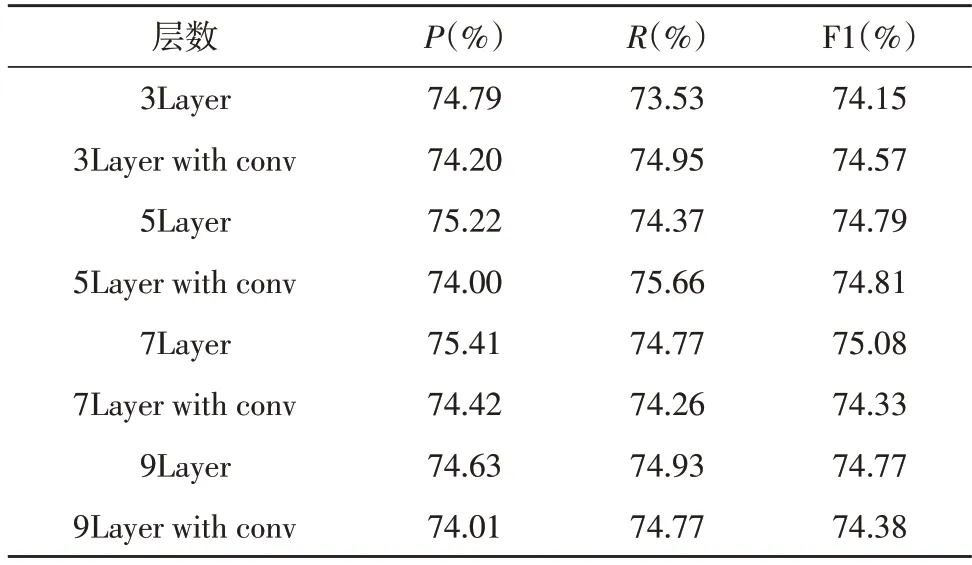
表2 轉(zhuǎn)置卷積對模型的性能影響
在FCN 模型用于圖像語義分割時,實驗結(jié)果顯示,模型從編碼器的最后一層逐層往前結(jié)合淺層的特征,并非越多越好,結(jié)合到過于低層的信息時,反而會影響模型的性能。對于該現(xiàn)象,同樣希望了解在NER 中是否出現(xiàn),因此對于不同層數(shù)的FCN-CRF模型均進行了對比測試,觀察融合特征層數(shù)對模型的性能影響,如圖2 所示。
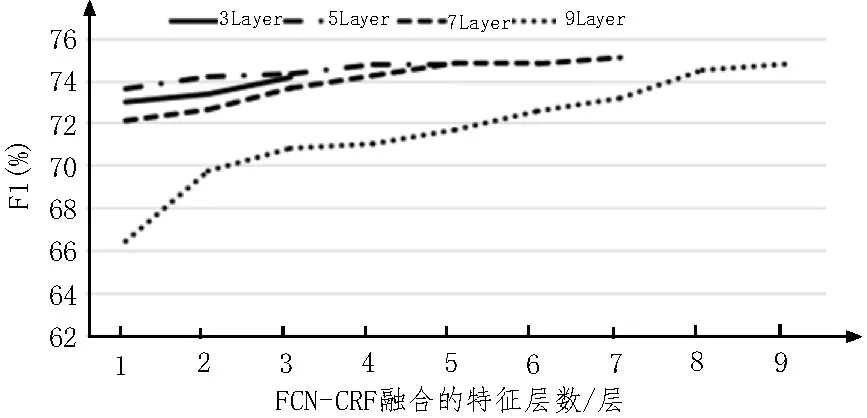
圖2 融合特征層數(shù)對性能的影響
從圖2可以觀察得知,對于不同層數(shù)的FCN-CRF,均有類似的結(jié)果,即隨著往淺層方向融合的特征層數(shù)減少,模型的性能下降。但在圖像語義分割任務中,融合特征層數(shù)較多反而影響性能。針對這一結(jié)果的解釋是,因為圖像的輸入最小單位是像素,像素是僅包含3 維RGB 通道信息的很短的向量,每個最小單位包含的信息量較少,因此FCN 最初幾層抽取圖像特征時,包含的信息相對較低級,信息量較少,對于最終標注結(jié)果影響較小。而在文本數(shù)據(jù)中,輸入的最小單位是字符,每個字符均會被映射為高維的詞向量,此時每個最小單位所攜帶的信息量較多,在淺層時抽取的特征已經(jīng)包含較多信息,若不對這部分信息加以融合,則可能較大程度上影響模型的最終性能。該部分實驗結(jié)果說明,在NER 中使用FCN-CRF 模型時,為了得到更好的性能表現(xiàn),應該把每一層輸出的特征分數(shù)都融合到一起來獲得最終的輸出。
4 結(jié)論
目前,NER 模型大多需要結(jié)合詞典信息,效率較低。該文提出將FCN-CRF 模型應用于NER 任務。實驗結(jié)果證明,F(xiàn)CN-CRF 無需結(jié)合詞典信息,也能達到和現(xiàn)有模型相似的性能,同時大幅度降低了模型訓練所需的時間,提高了在實踐中的應用性。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
外語學刊(2011年1期)2011-01-22 03:38:33
