基于自然語言處理與智能語義識別的輿情監測預警模型研究
2022-09-14 08:20:06張君第
電子設計工程 2022年17期
張君第
(陜西鐵路工程職業技術學院,陜西渭南 714000)
隨著互聯網技術的發展,用戶數量與日俱增。互聯網規模增長的一個重要體現就是社交媒體平臺的增加,互聯網用戶通過社交媒體平臺發表自身對某新聞的看法已成為常態,而社交媒體也已成為當前最為重要的輿情采集平臺。輿情指的是用戶對另外的人、事件或者物體所持有的態度、看法和意見[1-2]。
高校學生為互聯網用戶的主力,學生群體活躍度較高,上網時間也更長。高校輿情數據具有海量性和突發性兩大特征,同時,由于部分學生年齡偏小,心智尚未成熟,而不良信息通常會通過極端主義或者道德綁架等形式散播[3],學生極易被謠言輿情煽動,更有甚者會受到不良意識形態的影響走向歧途,這會對學生的管理和學校的形象造成負面影響。因此高校需建立輿情監測系統和輿情預警系統,及時發現偽輿情,并進行必要的辟謠和疏導,對高校意識形態的建設具有重要作用。
1 網絡輿情分析研究
網絡輿情的分析是社會各界密切關注的問題之一。網絡輿情分析主要是對輿情文本的情感進行分析,分析時需要對輿情數據進行數學計算,通過一定的數值來判斷輿情真偽。
目前常見的輿情分析方法有3 種:
1)傳統方法。傳統的網絡輿情分析方法依靠人工檢測,大部分算法均是主觀算法,例如文獻[4]中提到的層次分析算法,該算法使用主觀權重因子對輿情的真偽進行分辨,費時費力,僅適用于數據量較少的情形。
2)統計學方法。常見的統計算法為意見領袖模型[5-6],實際為馬爾科夫過程模型。其在所有輿情評論中尋找出影響力最高的用戶,將其權重調高,再對所有用戶分類,從而實現輿情的監測和預警。
3)深度學習方法。隨著機器學習的不斷發展,互聯網的海量數據已經實現了機器自動化訓練,而無需人工干預。如文獻[7]中構建的SVM 模型,使用基于詞向量的神經網絡模型對Twitter 輿情進行分析和判斷。
由此看出,傳統方法費時費力且準確性較低,統計學方法準確性較前者有所提高,但無法處理目前的海量數據。而深度學習方法可對海量的數據進行訓練,更無需人工干預,其準確性高。因此,該文使用深度學習的相關算法進行輿情模型的構建。
2 網絡輿情監測預警模型設計
2.1 模型總體框架
該文構建的網絡輿情監測預警模型如圖1 所示。整個模型分為3 個模塊:數據爬取、數據預處理和數據分析。數據爬取模塊使用數據爬蟲腳本,對指定網頁的內容按照需求進行爬取,然后存儲到某文件中供后續使用;隨后使用預處理模塊對數據進行預處理,預處理部分使用詞向量化算法對抓取到的內容進行歸一化處理,主要是去重和去噪,以保證計算機可以識別到文本向量;接著將處理好的數據文件傳輸至模型分析模塊,使用語義關聯特征算法對文本內容進行分析,并送入至RBF 神經網絡模型中進行訓練,再對輿情的真偽進行判斷;最終,輸出判斷結果并預警。
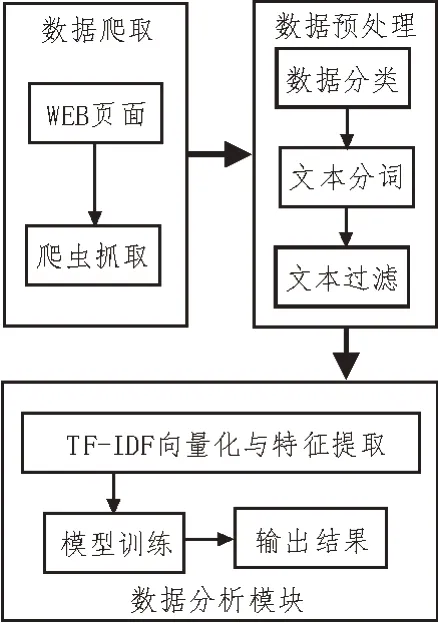
圖1 網絡輿情監測預警模型
2.2 數據爬取模塊
數據爬蟲種類繁多,但大部分爬蟲的功能是按照一定的規則對互聯網的網頁信息進行自動探測,高效率的數據爬蟲可以有效地采集目標消息。
該文使用的數據爬蟲基于Scrapy 框架,由該框架搭建的爬蟲使用Python 語言編寫,可以快速地根據用戶需求進行網站數據遍歷。其與傳統爬蟲程序不同的是,Scrapy 爬蟲還可對網站的API 數據接口進行爬取,從而大幅提高爬取信息的速度[8-10]。
基于Scrapy 框架的爬蟲結構包括爬蟲腳本主體、爬蟲引擎、調度插件、下載模塊、爬蟲中間件和管道。爬蟲腳本主體的目標就是URL 地址,爬蟲將目標URL 地址的內容送入管道中進行存儲;爬蟲引擎負責內容數據在所有模塊中傳遞;調度插件是將引擎所需的資源請求進行調度;下載模塊受爬蟲腳本的控制,當爬蟲需要下載網頁內容時,會調用下載器進行下載。
2.3 數據預處理模塊
數據預處理模塊分為3 個部分,分別為數據分類模塊、文本分詞模塊以及文本過濾模塊。
數據分類模塊即對采集得來的數據進行標注,例如負面評論標注a、中性評論標注b、正面評論標注c,這種分類數據作為驗證數據集使用;文本分詞模塊可以使用中文分詞腳本,該文使用Jieba 第三方分詞工具,該工具基于Python 語言開發,可以將文本進行準確的切分。此外,Jieba 有多種模式,文中使用Jieba.lcut 方法,該方法中的cut 和HMM 參數使用默認值。
2.4 數據分析模塊
2.4.1 基于TF-IDF的文本特征提取算法
TF-IDF 算法意為詞頻-逆向文本頻率,該算法中的TF 為詞頻,通常用于對某一詞語在整個文本出現的頻率進行衡量。算法中的IDF 為逆文本頻率,即在文本中出現次數的倒數。該算法可以表示某一詞語在文本中的重要程度[11-12]。TF 的計算公式如式(1)所示:
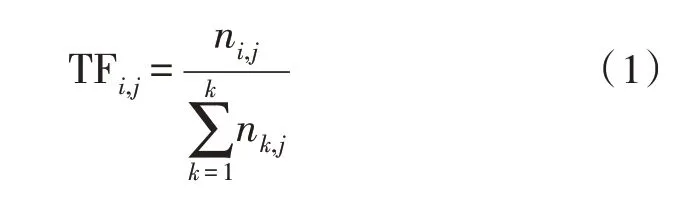
式中,TF 即為詞頻,ni,j為第i個詞語在第j個文本中出現的次數,分母為第j個文本中所有詞匯的個數。IDF 的計算公式如式(2)所示:
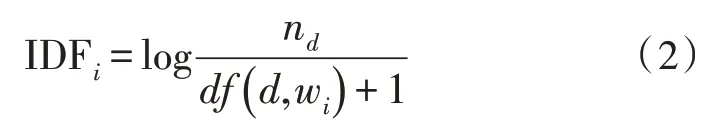
式中,IDF 為逆向文本頻率,nd為所有文本的個數,df(d,wi)為所有文本中包含有特定單詞的文本個數。最終的TF-IDF 公式如式(3)所示:
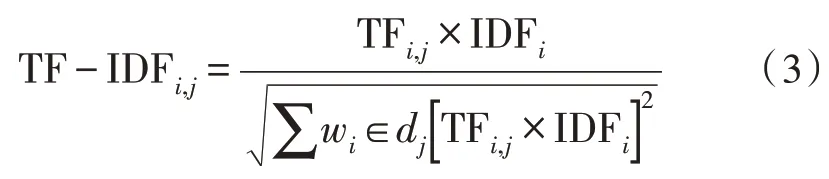
由式(3)可知,TF-IDF 傳統算法只考慮了某一特定單詞在文本中出現的頻率,并未考慮單詞所屬類別問題,由此會導致在模型訓練時對某一冷門類別有貢獻的單詞丟失。因此還需在TF-IDF 算法中加入統計學算法,對單詞所屬類別問題進行修正。文中加入方差因子,得到改進后的算法如下所示:
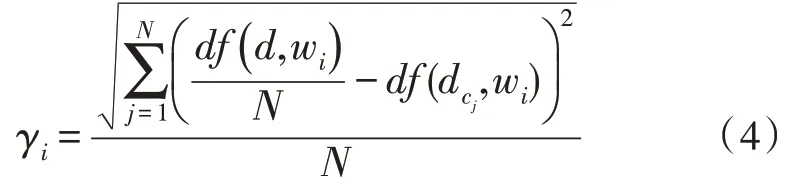
式中,γi為方差因子,N為文本的特征種類數目。可以看到,當某一特殊單詞在文本中波動時,γi便會發生變化。因此,加入方差因子的TF-IDF 算法如下所示:
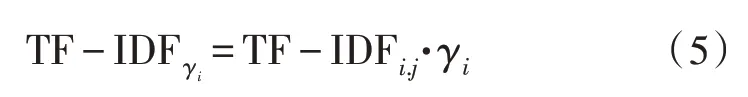
2.4.2 基于徑向基函數的神經網絡模型
使用神經網絡模型可對文本特征數據進行訓練。徑向基函數也被稱為RBF,由該函數組成的神經網絡包括輸入層、隱藏層以及輸出層[13-14]。RBF 神經網絡模型如圖2 所示。
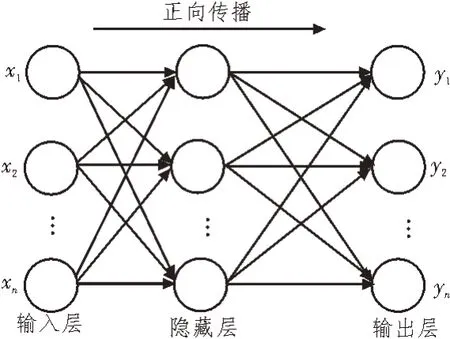
圖2 RBF神經網絡模型
由圖2 可知,輸入層X為文本數據,數據向量可表示為:
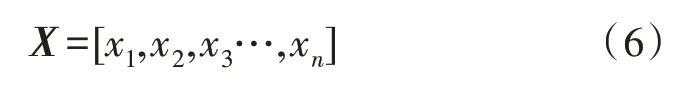
輸出層Y為模型的預測結果,可表示為:
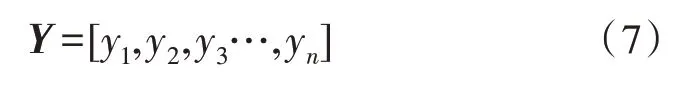
隱藏層函數可定義為:
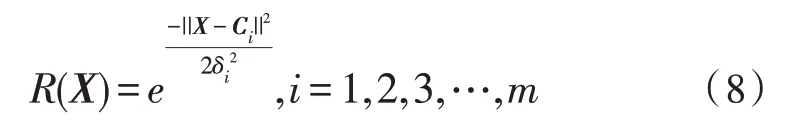
式中,Ci為隱藏層中的中心向量;m為隱藏層中神經元的個數;δi為隱藏層寬度。
由式(8)可知,輸入層神經元和中心向量相隔越遠,隱藏層作用函數的值就越低。同時還可以觀察出,X和R(X)之間的映射關系屬于非線性的。而輸出層數據和R(X)的關系是線性的,則有:
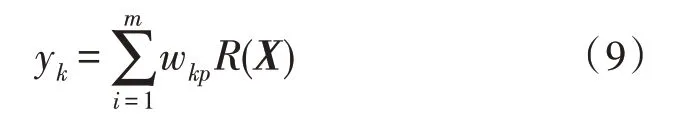
式中,wkp為輸出向量權重值。按照權重值對輸出數據進行排序,即可得到輿情數據的分析結果。
2.5 評價指標
在機器學習領域,常見的模型精度評價指標共有3 種,分別為準確率P、召回率R以及F1值[15-16]。準確率是指模型輸出結果中正確數據占總數據的比例;召回率是指模型輸出結果中正確數據占實際正確數據的比例;而F1 值是準確率和召回率的綜合計算結果。評價指標的公式如下所示:
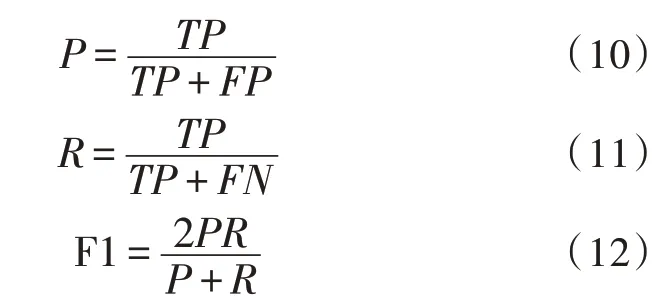
3 實驗分析
3.1 數據處理與環境配置
首先使用該文設計的Scrapy 爬蟲對該校學生在微博、貼吧等社交平臺的發言進行爬取,此次共爬取了20 000 條學生對于時事熱點的發言。其中使用16 000 條作為訓練樣本集,使用4 000 條作為測試樣本集合。表1 為此次測試的數據環境配置。
表1 數據環境配置
3.2 數據分類
對抓取到的數據進行預警監控,首先需要對數據的主題進行分類。分類后對句子的情感進行判斷,篩選出負面消息進行輿情真假判別。
對句子的主題情感進行分類,共篩選出9 個與政治相關的輿情話題,按照大類共分為國家安全、政府執政以及社會穩定3 個主題。對上述話題按照一定次序排列,如表2 所示。
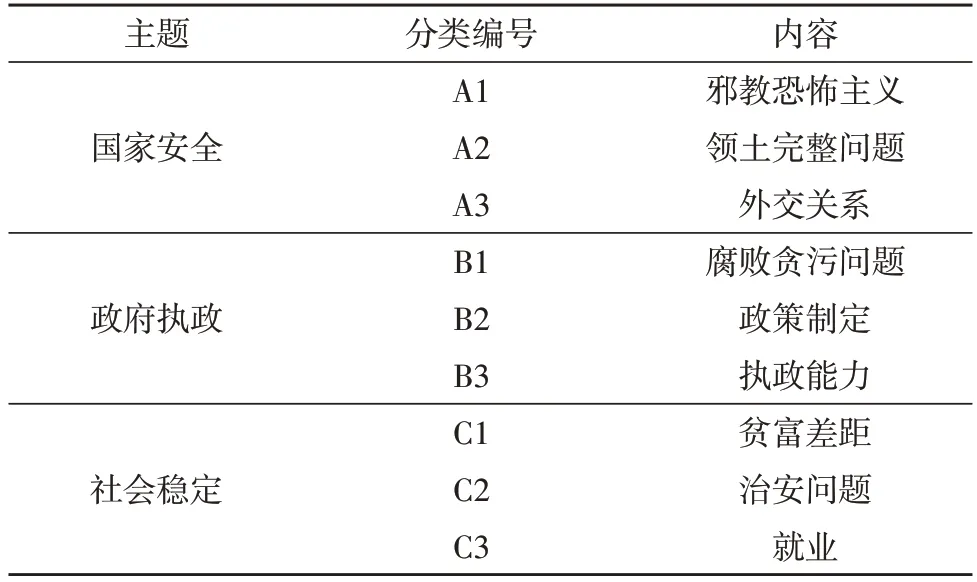
表2 部分數據分類特征
3.3 算法對比分析
首先對模型的分類能力進行測試,分類數據集合按照表2 的主題進行分類。使用訓練數據集對模型進行訓練,然后對可行性進行驗證。
例如,爬蟲抓取到的輿情發言為“臺灣是中國不可分割的一部分”、“今年就業太難”以及“這項政策對學生是有利的”,將這3 句話以編號T1、T2、T3 進行指代。模型的分類結果如表3 所示。
由表3 可知,該文的神經網絡模型可以對訓練集中的句子進行恰當的內容分類。下面驗證輿論情感判斷的性能,該文使用其他神經網絡模型進行相關指標對比,使用到的對比算法為CNN、KNN 和BP神經網絡模型。評價指標為準確率、召回率以及F1值。對比測試結果如表4 所示。

表3 分類能力驗證
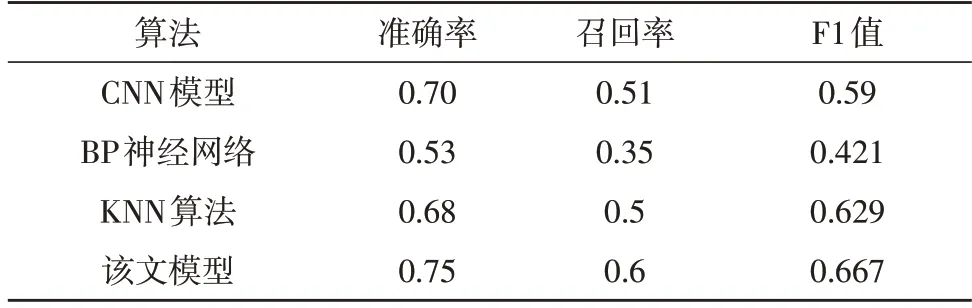
表4 數據集測試結果
由表4 可知,該文模型的準確率、召回率以及F1值三項指標均為最優。在F1 值指標中,相較其他算法提高0.077、0.246 以及0.038,說明該文算法在輿情敏感話題中有較大優勢。
除了對算法準確率進行對比外,還需對算法的運行時間進行分析,進而得到算法的效率。該文以算法訓練樣本所需時間對算法的效率進行判斷,文中訓練集合共有16 000 條,不同訓練樣本數量的訓練時間如表5 所示。
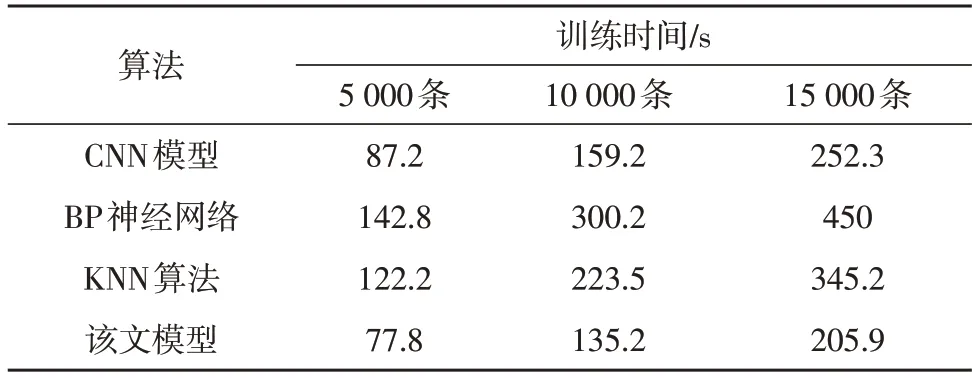
表5 訓練時間對比
由表5 可以看出,該文模型在相同樣本數量下所需要的訓練時間最短,說明該算法同時兼具有高效性。因此,該文模型的綜合性能良好,說明所構建的輿情預警模型可以滿足設計需求。
4 結束語
高校輿情數據具有海量和突發兩大特點,學生極易被謠言輿情所煽動,因此針對高校的輿情管理極為重要。該文針對傳統輿情分析方法的不足,基于自然語言技術和深度學習技術設計了高校網絡輿情分析預警系統。該系統設計了TF-IDF 文本分類算法,同時還使用RBF 對數據進行訓練。訓練測試結果表明,所設計模型的準確率和效率指標均優于其他對比方法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
