基于數據驅動的竊電行為預警綜合評分方法
2022-08-24 09:26:48許星煜王毅斌張建雄
電力系統及其自動化學報 2022年8期
武 旭,王 果,許星煜,王毅斌,張建雄
(1.蘭州交通大學自動化與電氣工程學院,蘭州 730070;2.甘肅省軌道交通電氣自動化工程實驗室(蘭州交通大學),蘭州 730070;3.國網甘肅省酒泉市供電公司,酒泉 735000)
竊電是指一種采用非法手段使用電能的行為。近年來,竊電造成的消極影響不斷增加,尤其對發展中國家的影響最大[1]。隨著雙碳視角下的電力系統轉型,竊電還會引起智能電網和新型電力系統在用電高峰期的超負荷現象,增加系統負擔,嚴重時會給電力系統運行的穩定性造成威脅[2]。因此,如何精準發現竊電用戶、排除竊電現象,是目前反竊電研究領域的一大重點和難點[3]。反竊電預警是基于電力大數據分析,構建典型竊電樣本,優勢明顯,應用前景廣泛。
國內外許多學者已對反竊電預警進行了大量研究。文獻[4]提出了一種基于時空關聯矩陣的反竊電預警方法,利用臺區線損波動率、線損與電流差異曲線的變點時間進行關聯分析,判斷是否存在竊電行為;文獻[5-6]提出了應用大數據技術的反竊電分析方法,通過二階聚類分析竊電用戶的特征,用深度學習和卡方自動交互檢測方法的決策樹分類評估用戶的竊電概率;文獻[7]針對傳統竊電檢測方法中分類單一問題,提出一種基于Bagging異質集成學習的竊電檢測方法;文獻[8]以線損與實際用電量之間的隱含關系為基礎,提出格蘭杰歸因分析的高損臺區竊電檢測方法;文獻[9]構建的模型方案加入超參數的調整以提升模型性能,可以識別用戶行為的異常;文獻[10-11]分別通過引入竊電比較集合和用電特征分析的方式進行竊電辨識;文獻[12]提出一種基于Wasserstein生成對抗網絡的竊電樣本過采樣方法;文獻[13]建立了一個基于消費模式的模型,來識別常規用戶和竊電用戶;文獻[14-15]提出了一種具有隱私保護的竊電檢測方案,使用組合卷積神經網絡CNN(convolutional neural network)識別檢測計量數據的竊電行為。由此可見,竊電行為預警相關研究方法較多且已取得不錯的成果,但上述預警方法在量化用戶竊電存在空檔,沒有考慮技術線損因素,缺乏對饋線上的用戶給定權重。目前存在的反竊電預警方法,未充分考慮用戶用電行為的多樣性,不能綜合考慮影響用戶用電行為的因素,存在一定的局限。
針對上述研究中在量化用戶竊電可能性上存在的空檔問題,缺乏考慮技術線損因素和用戶用電行為的多樣性,無法精確判斷竊電用戶。本文以K-means、支持向量機SVM(support vector machines)和長短期記憶LSTM(long short term memory)為基礎,提出一種用戶竊電行為預警綜合評分方法。該方法考慮日負荷特性、用戶用電行為及電量預測,從橫向、縱向兩個層面對用戶用電行為進行定量評分,同時考慮技術線損因素對饋線上的用戶給定權重實現綜合評分;通過實際算例對所提方法進行驗證。雖然此方法構架復雜,但通過對電力用戶大數據的分類、聚類、回歸,加之考慮線損和竊電權重,可以精確地定位竊電用戶,量化用戶竊電行為,對電力部門現場反竊電排查具有重大的現實意義。
1 竊電行為預警評分總架構
本文所述的竊電行為預警評分模型總架構如圖1所示。該評分架構由橫向評分、縱向評分、綜合評分三部分組成。橫向評分中,利用K-means算法對區域內用戶日負荷數據進行聚類,給出每種用電行為聚類標簽,利用SVM建立日負荷分類模型,通過橫向評分標準給出橫向評分。縱向評分中,利用LSTM算法對每個用戶建立短時間尺度用電量預測模型,通過縱向評分標準評估單個用戶的用電情況是否符合其一貫用電行為,給出縱向評分。綜合評分中,考慮技術線損因素,同時對饋線上的用戶給定權重,最終實現綜合評分。
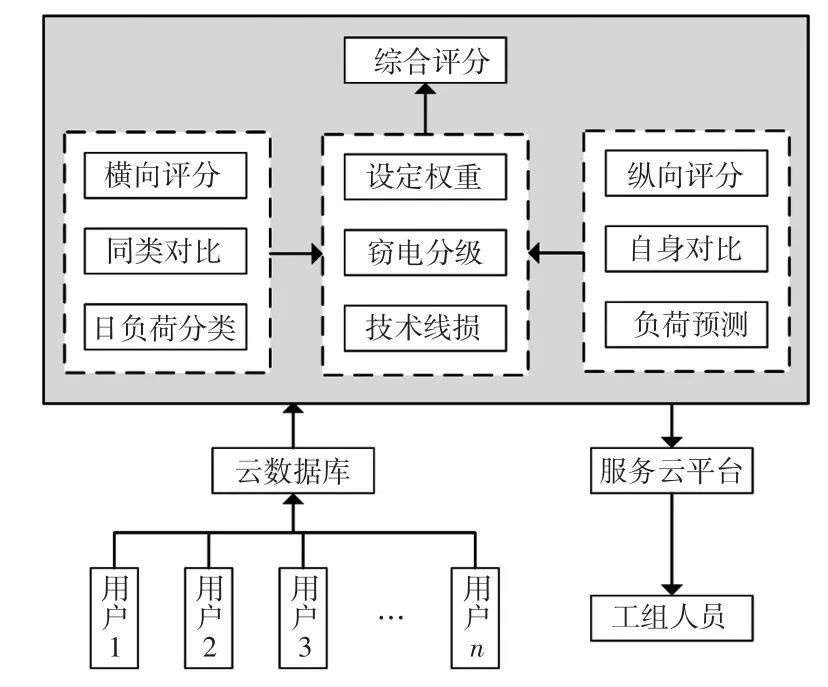
圖1 竊電行為預警模型總架構Fig.1 General framework of power theft early warning model
基于K-Means、SVM建立分類模型,從橫向作比較,目的是與周邊具有相似用電行為的用戶對比,給出橫向評分。基于LSTM網絡的用戶用電量預測模型,從縱向作比較,目的是與自身的日常用電行為對比,給出縱向評分。橫向評分與縱向評分均為單個用戶細化評分,通過乘以線損權重的方式,建立用戶用電行為綜合評分,從而判斷竊電用戶。若綜合評分過低,則通過服務云平臺發出報警信號,通知相關工作人員現場排查。
2 竊電行為預警評分模型
2.1 橫向評分模型
利用K-means算法將所有用戶經過歸一化的歷史日負荷數據進行聚類,確認用戶的用電行為,并對每種用電行為給出聚類標簽。將用戶歷史日負荷數據作為輸入,用電行為標簽作為輸出,利用SVM建立日負荷分類模型。在日常運行階段,對每個用戶日負荷進行分類,根據用戶橫向評分標準對同一類用戶給出橫向評分。
通過橫向評分,基于聚類、分類的思想對每個類別中用電量進行評分,對用電量較少的用戶給予較低的分數,提高其異常用電行為的可能性,但僅僅是橫向評分不能排除用戶一貫用電量較少的可能性。此外,比起傳統根據對歷史數據進行聚類的異常用電識別方法,對每天的用電行為進行分類更加具有可操作性和實時性。
2.1.1K-means聚類算法
K-means聚類算法中是一種以距離作為數據間相似性度量標準的聚類算法[16],其中K代表類簇個數,means代表類簇內數據對象的均值。當數據間的距離越小,則相似性越高,越有可能在同一個類簇。數據間的距離計算公式為
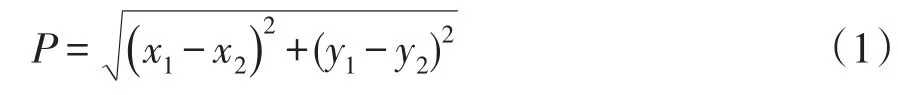
式中:(x1,y1)、(x2,y2)為數據坐標;P為數據之間的歐式距離。
K-means算法中聚類個數要由人為指定,所以一般利用肘部法則[17]與輪廓系數[16]綜合判定聚類個數K值。K-means是以最小化樣本與質點平方誤差作為目標函數,將每個簇的質點與簇內樣本點的平方距離誤差和作為畸變程度,畸變程度越低,簇內樣本越密。輪廓系數是類的密集與分散程度的評價指標,表示為

式中:l為同簇與相鄰距離的均值;k為樣本與簇外最近簇內樣本距離的均值(除自身);s為輪廓系數,取值為[-1,1],越接近1代表K值越合理。
2.1.2 SVM分類算法
SVM是一個有監督的學習模型,需要找到一個超平面,SVM模型的超平面描述為

式中:ω為超平面的法向量;x為超平面上的點;b為超平面到原點的距離。目的在于盡量將兩類數據點準確分開,同時使這兩類數據點距離分類面最遠。
假設X(x1,x2,…,xn)為樣本中的一個點,其中xi表示為第i個特征,那么該點到超平面的距離d的計算公式為
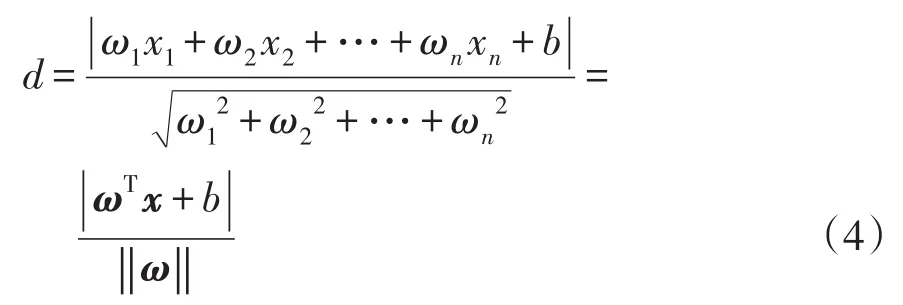
式中:‖ω‖為超平面的范數;T為數據訓練集;ωi為超平面第i(i=1,2,…,n)個點的法向量。若要使兩類數據點距離分類面最遠,則其目標函數為
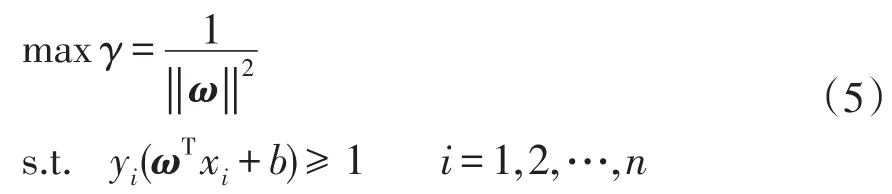
式中:yi為數據點標簽,值為1或-1;γ為樣本點間的距離。
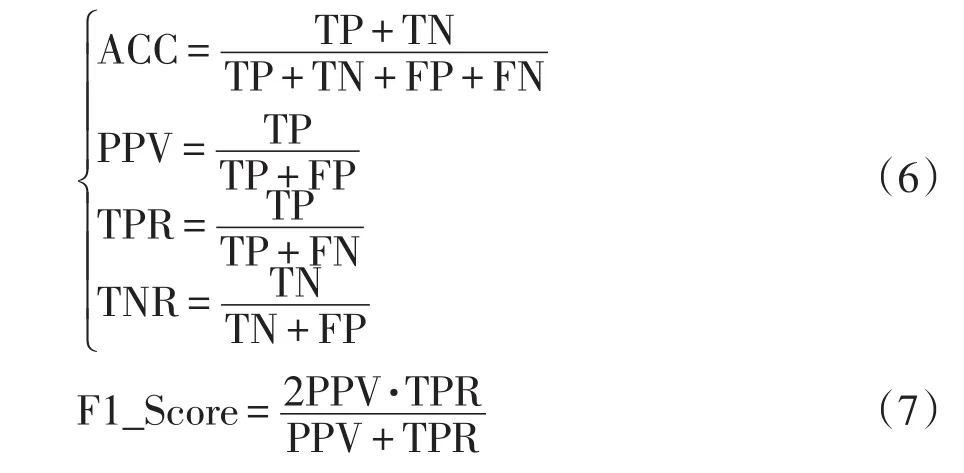
為了直觀地表示分類準確性,一般使用混淆矩陣[18]。本文采用二分類模型,最終輸出結果可以表示為positive或negative。通過采集樣本可以知道樣本的類別,即真實值。分類模型結果為預測值。則定義4個指標分別為:TP、FN、FP、TN。這4個指標在一張表格上呈現出來就是混淆矩陣,如表1所示。

表1 混淆矩陣Tab.1 Confusion matrix
混淆矩陣中,TP為真實值與預測值均正常;FP為真實值異常,預測值正常;FN為真實值正常,預測值異常;TN為真實值與預測值均異常。TP、TN內的樣本數越多,說明分類模型預測結果越好;FP、FN內樣本數越多,說明分類模型預測結果越差。此外,在混淆矩陣的基礎上定義了評價模型的二級指標和三級指標。通過三級指標可以更加準確地評價分類模型的好壞,其中二級指標為準確率ACC、精確率PPV、召回率TPR、特異度TNR,三級指標為F1_Score,計算公式分別為
2.1.3 橫向評分標準
橫向評分具體流程如下。首先,利用K-means算法進行聚類,并對每種用電行為設定聚類標簽。然后,將用戶歷史日負荷數據作為輸入,用電行為標簽作為輸出,建立基于SVM的分類模型。建立分類模型,可在離線情況下將用戶每天用電負荷分類。收集第k個類別中第j個用戶當日的總用電量Ek,j,并對應求得該類中用戶當日的用電量平均值Ek。在同類別中,對Ek,j與Ek進行比較。用戶橫向評分標準具體如表2所示。

表2 用戶橫向評分標準Tab.2 User horizontal scoring standard
2.2 縱向評分模型
利用LSTM算法建立短期負荷預測模型[19]。在日常運行階段,對每個用戶用電量進行實時預測,輸入為前24 h的用戶實際用電量,輸出為第25 h的預測用電量。在第t+1天凌晨,整合第t天24 h的預測用電量和第t天24 h的實際用電量,根據用戶縱向評分標準,評估單個用戶第t天的用電情況是否符合其一貫用電行為,并且給出縱向評分。
通過縱向評分,基于回歸的思想,充分考慮了用戶用電行為的多樣性,彌補了橫向評分的缺陷,當用戶用電量低于預測用電量一定閾值后,說明存在較大的竊電可能性。
2.2.1 基于Embedding-LSTM的用電量預測模型
基于LSTM網絡的用戶用電量預測模型為:存在輸入層、Embedding層、LSTM層、輸出層的LSTM神經網絡,如圖2所示。其中,輸入層為多特征滾動窗口形式,考慮單個用戶縱向24 h、4種數據特征(天氣、溫度、濕度、用電量),故滾動窗口大小為24×4的形式。由于天氣是離散數據,因此首先經過Embedding層后,生成特征向量并與連續數據進行特征聯合,形成LSTM層的輸入向量。LSTM模型的輸出層為第25 h內的用戶用電量。
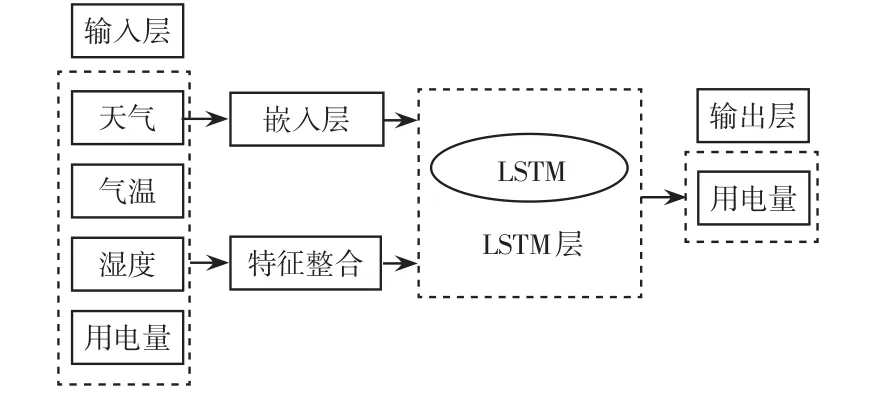
圖2 Embedding-LSTM用電量預測模型Fig.2 Embedding-LSTM power consumption prediction model
擬合優度的度量是可決系數R2,R2越接近1,說明回歸曲線的觀測值擬合程度越好[19]。假定目前存在n組數據樣本 (x1,y1)、(x2,y2)、…、(xn,yn),總平方和SST及回歸平方和SSR定義為
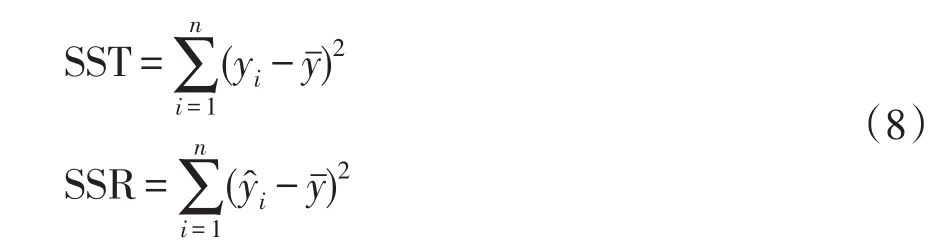
式中:為y的均值;yi為第i(i=1,2,…,n)個樣本的輸出真實值;?i為擬合值。則可決系數R2計算為

2.2.2 縱向評分標準
縱向評分標準定義為
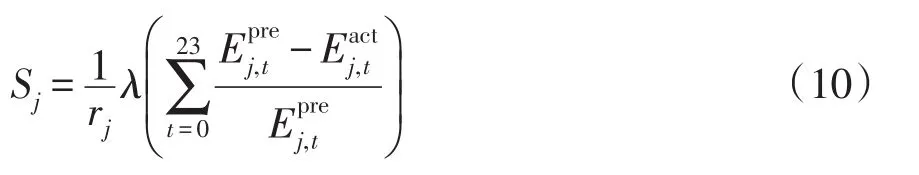
式中:Sj為該用戶當日實際用電量少于預測用電量的平均誤差和;為該用戶在第t時段內預測的用電量;為該用戶在第t時段內的實際用電量;rj為當日該用戶實際用電量少于預測用電量的時段個數;λ(·)表示為

式(11)具體含義為:將基于單個用戶的用電行為習慣預測的用電量與該時段內實際用電量對比,若,則用戶用能比預測用電量少,此時Sj,t>0;若,則用戶用電量比預測用電量多,此時Sj,t=0。考慮預測誤差閾值因素,根據Sj得分,給出用戶縱向評分標準,如表3所示。
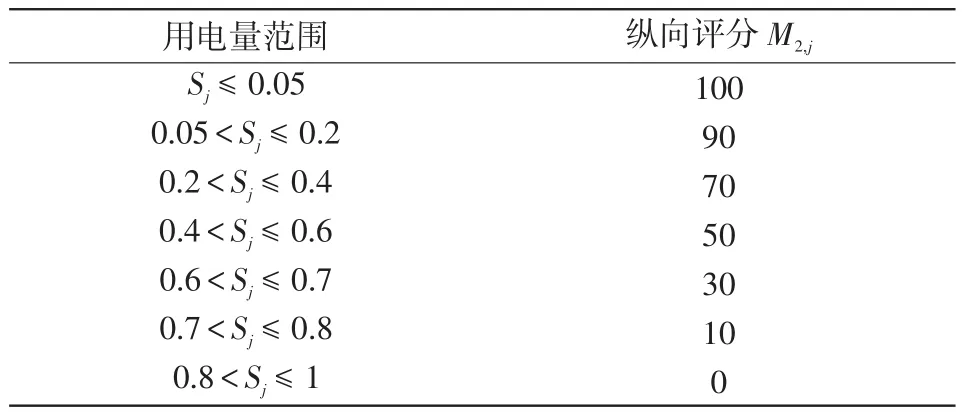
表3 用戶縱向評分標準Tab.3 User vertical scoring standard
在當日該用戶實際用電量少于預測用電量的時段內,考慮到用電量預測模型存在5%的預測誤差,則若實際用電量平均值少于預測用電量平均值的5%以內,此時縱向評分為滿分;若實際用電量與預測用電量的比值越小,說明縱向評分越低。通過與自身歷史用電行為對比的方式,彌補橫向對比時,可能存在該用電需求普遍較同類用戶較低的問題。當橫向和縱向評分綜合起來同時較低時,證明該用戶存在竊電的可能性。
2.3 竊電分級權重
由于周期性巡查的方法費時費力,因此建立針對竊電行為的分級管理制度,對不同竊電嚴重程度的臺區采用不同的竊電稽查手法。對重度竊電臺區采用較小權重,使得該區域用戶整體評分較低,采用較高頻度的周期性巡查;對中度竊電臺區,采取保證一定覆蓋率的隨機抽查;對其余區域,采用較高權重使得整體評分較高[20-21]。臺區竊電嚴重程度劃分為4檔,如表4所示。

表4 低壓臺區4級竊電嚴重程度的界定原則Tab.4 Definition principle for four levels of power theft severity in low-voltage station area
表中:ΔA%為實測線損率;為技術線損率標桿值;ΔA1%和ΔA2%為對應的ΔA%閾值,具體計算公式分別為
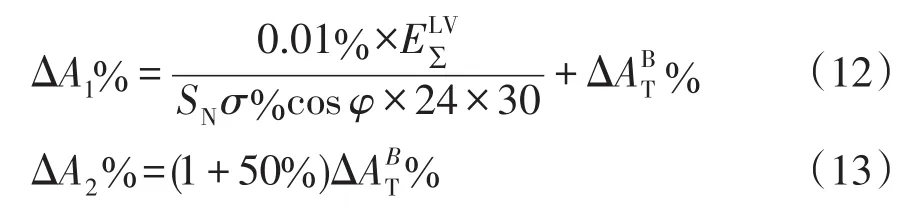
2.4 綜合評分模型
橫向評分與縱向評分均為單個用戶細化評分。通過乘以線損權重的方式,建立用戶用電行為綜合評分,判斷綜合評分是否符合標準。若綜合評分過低,則發出報警信號通知相關工作人員現場排查用戶竊電可能性。根據單個用戶的橫向、縱向用電情況,建立綜合評分,即

式中:Zj為第j個用戶綜合評分;η為竊電權重系數;α、β為修正系數,為保證綜合評分保持在100以內,α+β=1用于核定縱向評分與橫向評分的權重,根據實際情況制定修正系數的劃分限定標準。當用戶綜合評分低于限定標準時,發出異常用電警告,并由工作人員進行實地考證。
3 算例分析
選取酒泉地區不同的3類臺區中相同用電行為的30個用戶,采樣時間范圍為2020年1月1日至2020年12月31日,采樣間隔為1 h,包含天氣、溫度、星期、電價等特征。所采用的數據均已經過預處理,實驗基于Python3.7運行環境。首先,計算30個用戶的橫向與縱向評分,驗證橫向、縱向權重的設定對于綜合評分的影響;然后,模擬該30個用戶在不同環境、不同臺區下的技術竊電分級權重對于竊電判定的影響。
3.1 橫向評分
根據肘部法則與輪廓系數綜合判定K值,結果如圖3所示,圖中左y軸平均畸變程度為肘部法則所得結果,右y軸為輪廓系數所得結果。首先,根據肘部法則可知,聚類個數在2~3之間,根據輪廓系數盡可能大的原則,選擇聚類個數為2,根據聚類結果求取每類標準化后的用電行為的平均曲線,如圖4所示。
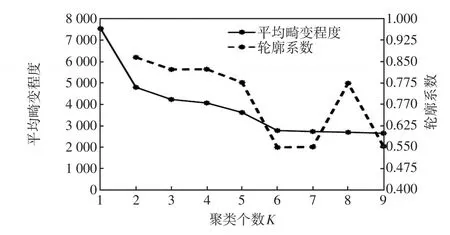
圖3 聚類個數判定Fig.3 Determination of clustering number
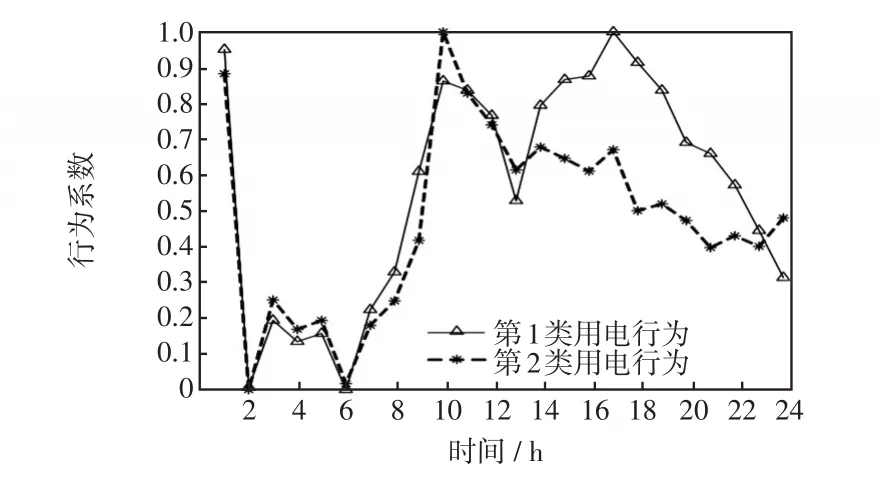
圖4 每類用電行為平均曲線Fig.4 Average curve of each type of power consumption behavior
通過聚類結果可以看出,兩種用電行為的差異主要體現在14~24 h這段時間內。聚類分析得到用戶用電行為標簽后,將用戶歷史日負荷數據作為輸入,用戶用電行為標簽作為輸出,采用SVM建立用戶用電行為分類模型。其中將用戶日負荷數據按9∶1比例劃分為訓練集和測試集。分類模型結果如圖5所示。
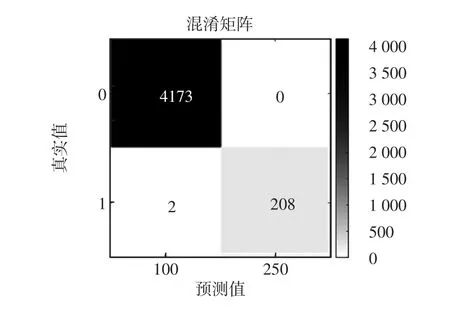
圖5 分類模型結果Fig.5 Result of classification model
本文隨機選取了30名用戶在測試集上第45日的用戶日負荷數據。分別給出了30名用戶的用電行為類別以及用戶橫向評分,如表5所示。
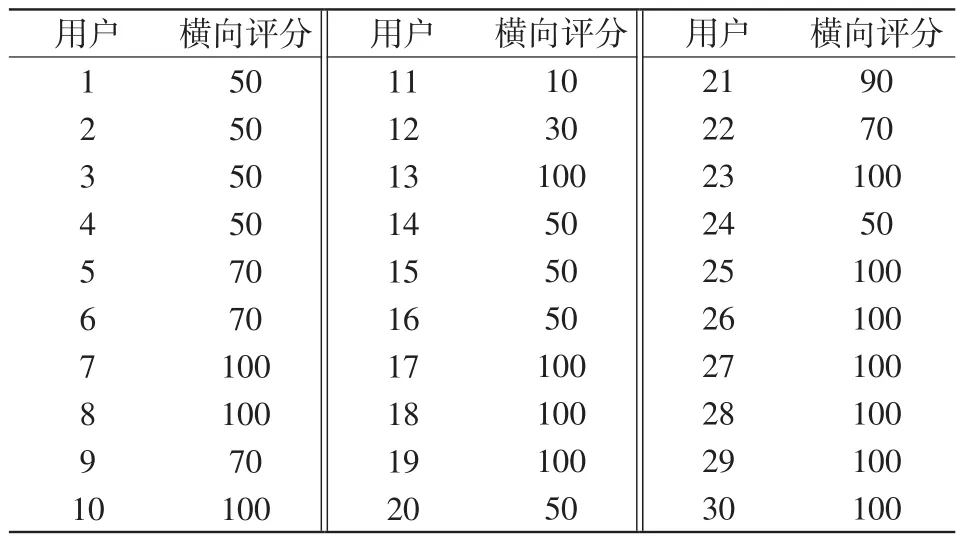
表5 用戶橫向評分Tab.5 User horizontal scoring
由圖6可見,用戶16、17、19、23、24這5位用戶的用電行為為第2類用電行為,其余用戶均為第1類用電行為。
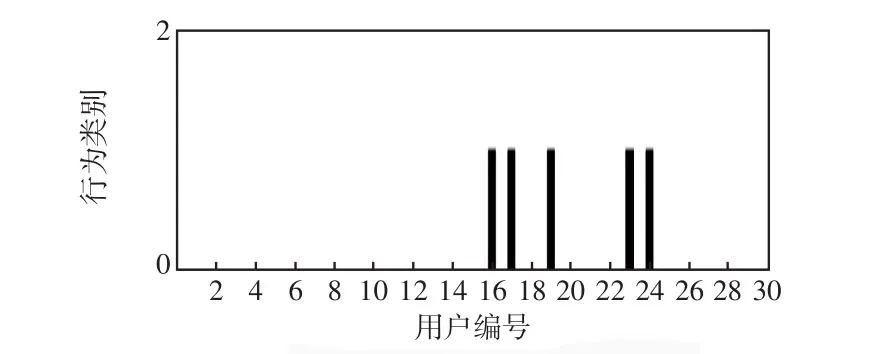
圖6 用戶用電行為標簽Fig.6 Label of user power consumption behavior
通過橫向評分,對每個類別中用電量進行評分,當用戶用電量大于同類別用戶平均用電量時橫向評分為滿分。隨著用電量逐漸降低,其橫向評分也逐漸降低,提高了該用戶異常用電行為的可能性。但是,僅僅是橫向評分不能排除用戶由于用電人數、用電習慣等用電量較少的可能性。因此,需要縱向評分對該缺點進行彌補。
3.2 縱向評分
利用數據建立LSTM網絡的用戶用電量預測模型,進行用戶用電量預測。其中,天氣為離散數據,使用Embedding學習離散型數據后,生成特征向量并與連續數據用電量、溫度、濕度進行特征聯合,形成LSTM輸入向量。LSTM輸出層為第25 h內的用戶用電量。模型訓練結果如圖7所示。
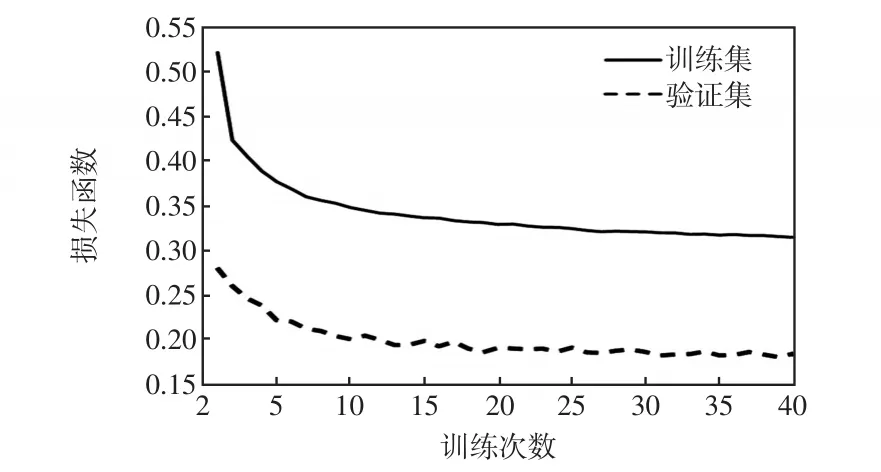
圖7 模型訓練結果Fig.7 Model training results
利用測試集對該模型進行驗證,并針對用戶用電量預測模型對比了主要參數(神經元個數、訓練次數)對預測精度的影響,如表6所示。LSTM模型設置了1個全連接層作為輸入層、1個LSTM層作為隱藏層,其中,神經元個數分別設為50、70、100,最后通過全連接層輸出指定格式的向量[21]。
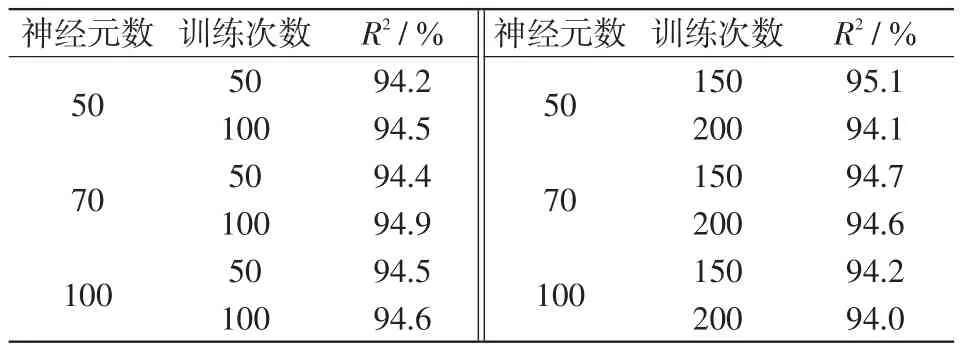
表6 不同參數下預測模型精度對比Tab.6 Comparison of prediction model accuracy under different parameters
可見,當神經元個數為50個,訓練次數為150次時,預測模型的最高預測精度達到95.1%,因此前文中縱向評分的誤差閾值設為0.05。此外,參數的變動對于結果的改變不明顯,說明模型結構穩定,且與輸入輸出契合。取30名用戶第44日的用電量來預測第45日的用電量。圖8為用戶1的預測結果。表7為第45日的縱向評分。
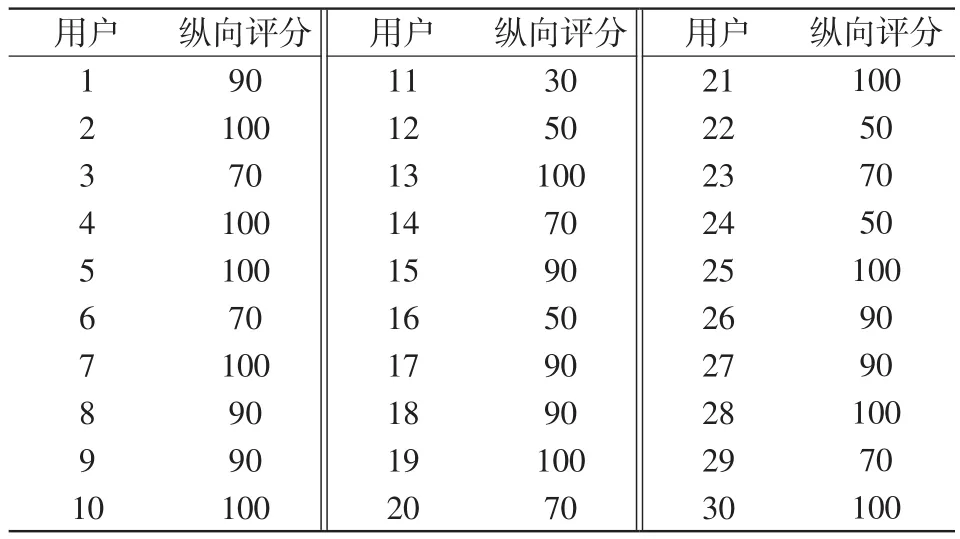
表7 用戶縱向評分Tab.7 User vertical scoring
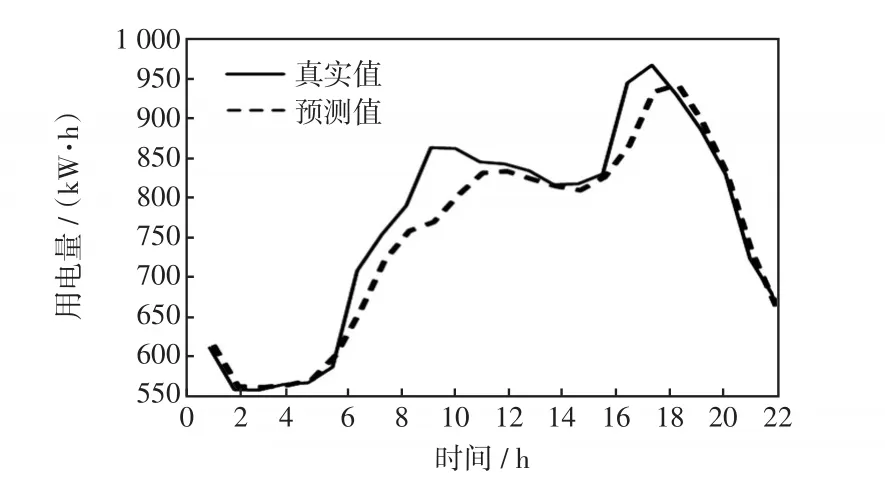
圖8 用戶1預測結果Fig.8 Forecasting results of User 1
在當日該用戶實際用電量少于預測用電量的時段內,考慮到用電量預測模型存在5%的預測誤差,則若實際用電量平均值少于預測用電量平均值的5%,此時縱向評分為滿分;縱向評分越低,說明實際量與預測量的比值越小。通過與自身歷史用電行為對比的方式,彌補橫向對比時,可能存在該用電需求普遍較同類用戶較低的問題。當橫向和縱向評分綜合起來同時較低時,證明該用戶竊電的可能性較大。
3.3 綜合評分
首先不考慮竊電分級權重,為了選取合適修正系數α和β,對酒泉地區所屬48個配電臺區2019-01-01至2020-12-30共730日負荷采集數據進行修正測試,最終確定選取如表8所示的3種典型情況。
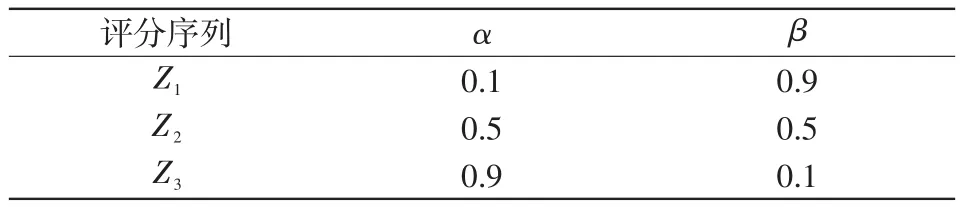
表8 修正系數選擇Tab.8 Selection of correction coefficients
表中:Z1為修正系數α=0.1、β=0.9下的評分序列;Z2為修正系數α=0.5、β=0.5下的評分序列;Z3為修正系數α=0.9、β=0.1下的評分序列。在3類修正系數下,不考慮竊電分級權重的綜合評分如表9所示。在第1組修正系數α=0.1,β=0.9下,用戶11、12、16、22、24這5名用戶的綜合得分明顯偏低,所以存在極大的竊電嫌疑;在第2組修正系數α=0.5,β=0.5下,用戶11、12、16、24這4名用戶的綜合得分明顯偏低,所以存在極大的竊電嫌疑;用戶3、14、20、22這4名用戶的得分為60,也存在竊電嫌疑;在第3組修正系數α=0.9,β=0.1下,用戶1、2、3、4、11、12、14、15、16、20、24這11名用戶的綜合得分明顯偏低,所以存在極大的竊電嫌疑。
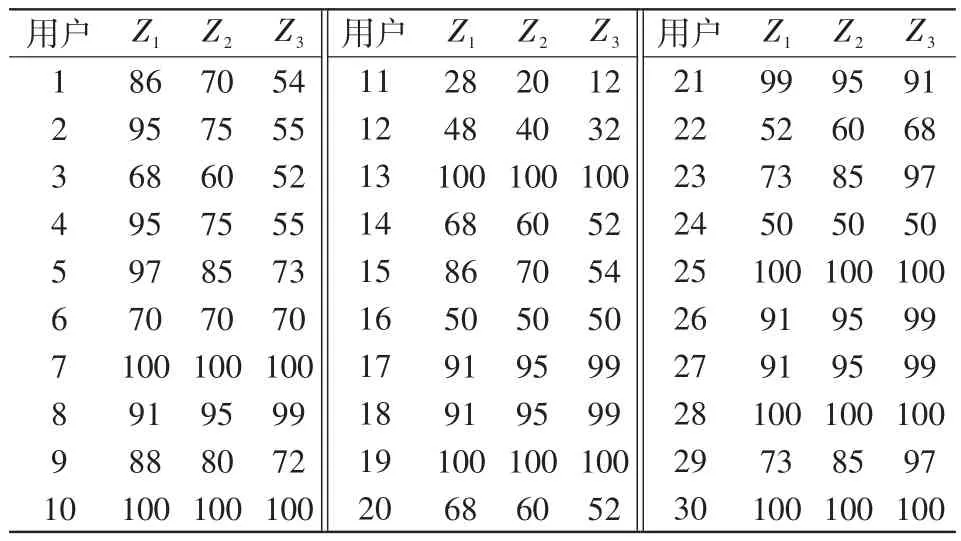
表9 不考慮竊電分級權重的綜合評分Tab.9 Comprehensive scoring without considering the graded weight of power theft
α與β分別代表著橫向評分與縱向評分對于綜合評分的重要程度。對比3組系數下的結果,當橫向修正系數大時,用戶的綜合評分偏低,此時被判定為異常用電的用戶比較多。當縱向修正系數較大時,用戶的綜合評分偏高,此時被判定為異常用電的用戶較少。當橫向修正系數和縱向修正系數取值適中時,被判定為竊電的用戶是以上兩種情況結果的交集。說明在沒有竊電的先驗信息的條件下,選用參數為α=0.5、β=0.5較為合適。在有歷史竊電數據的情況下,工作人員可以根據歷史信息對α、β進行回歸擬合,得到適用于實際情況的修正系數。
數據中包含如表10所示3種場景,基于修正系數α=0.5、β=0.5,考慮竊電分級程度,對綜合評分進行調整。此時,相同30個用戶在考慮竊電分級權重的綜合評分如表11所示。在不考慮竊電分級前,僅用戶11、12、16、24這4名用戶的綜合得分明顯偏低,存在極大的竊電嫌疑。
引入竊電分級后,隨著臺區的竊電風險增大,更多用戶將被作為潛在竊電用戶,將由工作人員定時進行排查。
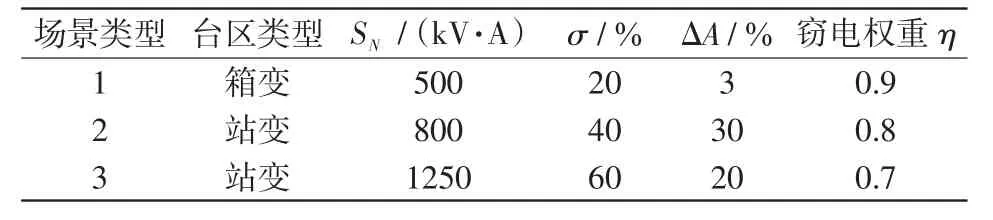
表10 3類場景下竊電權重Tab.10 Power theft weight under three scenarios
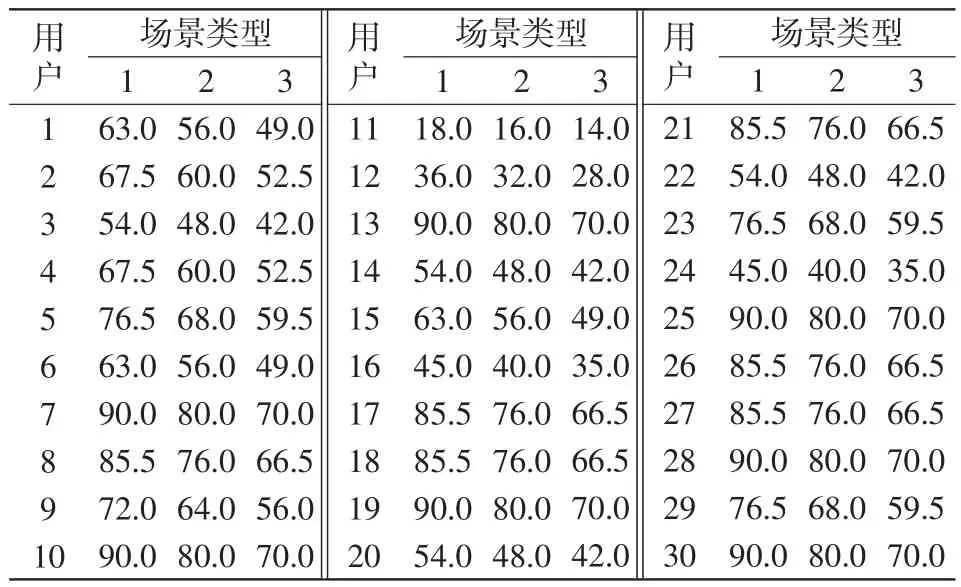
表11 考慮竊電分級權重的綜合評分Tab.11 Comprehensive scoring considering graded weight of power theft
4 結語
本文利用區域內實時數據提出了一種用戶竊電行為預警綜合評分方法。基于K-means以及SVM建立分類模型,從橫向作比較,給出橫向評分;基于LSTM網絡的用戶用電量預測模型,縱向作比較,給出縱向評分。最后,根據實測線損考慮竊電管理分級,進行綜合評分。
通過橫向、縱向兩個方面的評分,綜合性地輔助工作人員進行異常用電識別,精準定位單個具有竊電可能性的用戶,解決以往整個臺區排查費時費力的問題。綜合評分的修正系數,根據實際情況選定,在沒有竊電的先驗信息的條件下,選用參數為α=0.5、β=0.5較為合適,在有歷史竊電數據的情況下,工作人員可以根據歷史信息對α、β進行回歸擬合,得到適用于實際情況的修正系數。最后,經過算例分析,證明其性能準確,對于多種用電行為的用戶,在橫向評分和縱向評分上均能獲得較高精確度,可以實現異常用電行為預警。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
