改進的混沌理論和BP神經網絡化工產品需求預測模型設計
2022-08-19 07:47:16李永鋒
粘接 2022年8期
關鍵詞:模型
李永鋒
(西安航空職業技術學院 現代教育技術中心,陜西 西安 710089)
隨著中國“世界工廠”地位逐漸凸顯,化工產品的個性化定制需求越來越多。如何精準預測化工產品需求,避免資源浪費,減少企業不必要的生產成本從而提高工業產品利潤率顯得尤為重要。
人工神經網絡(artificial neural networks,ANN)是基于生物神經網絡對信息進行自動優化的方法,該方法具有很高的容錯性、魯棒性及自組織性。雖然人工神經網絡不能和生物神經網絡等價,但在一些方面取得了優越的性能。當前,該網絡已經廣泛應用在了智能語言處理、人工智能等領域。
混沌時間序列在實際環境中廣泛存在。所謂混沌時間序列,是指由混沌非線性動力系統產生的時間序列。其外在表現類似隨機,對初值十分敏感,因此這類系統對長期預測十分困難,但內在的非線性動力學特性又是具有確定性的,這使得短期預測成為可能。
有學者利用多指標與卷積神經網絡的化工產品需求預測;利用基于實驗數據改進的人工神經網絡進行學習訓練,進行銷售預測,將結果與未改進的人工神經網絡和較先進的卷積神經網絡和高斯混合模型以及銷售公司的銷售數據作比較,從準確率、召回率和F值3個指標分析改進人工神經網絡的預測精度,能夠較好地預測銷售成交情況。還有通過GRU-BP組合神經網絡預測模型,研究在不同時間序列上各型號產品相互制約影響下產生的不同需求形態;同時考慮產品自身屬性差異、供應鏈環境等影響因素,可以預測出某型號產品未來一段時間內的需求量。為提高制造企業產品需求預測的精度,提出了產品數據空間和一維卷積神經網絡——長短期記憶神經網絡的深度學習算法,預測效果優于神經網絡模型和單一的LSTM模型。為了克服關鍵質量變量測量滯后所帶來的不利因素,提高氟化工過程先進控制系統的控制精度,提出了一種具有輸入數據注意力機制的卷積神經網絡用于產品質量預測。
針對目前研究的結果,本文提出了一種基于混沌理論相空間重構算法的BP神經網絡化工產品需求預測模型,分析其發展趨勢,構建其混沌系統相空間,利用BP神經網絡深度學習算法模型,對未來產品需求進行預測,最后進行實驗論證該方法的有效性與可行性。
2 方法框架
以某化工企業 2018年1月到2019年9月的202 種具體產品的需求訂單作為數據源,利用混沌理論相空間重構算法計算其相空間的參數構建對應的相空間;然后將重構后的相空間作為BP神經網絡的輸入,使用更新數據集的方法,達到工業產品需求預測的目的。預測方法的框架如圖1所示。
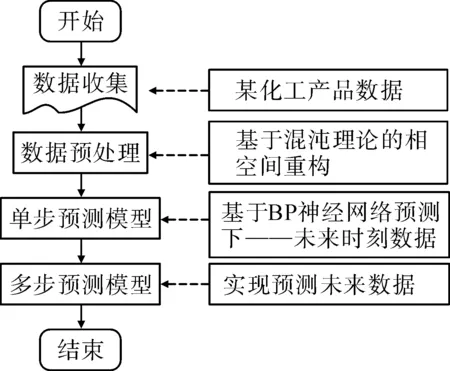
圖1 化工產品需求預測方法框架圖Fig.1 Framework of method for chemical products demand prediction
由圖1可知,整個方法分為4步,即從數據收集、數據預處理和后續的單步預測模型以及過渡到最后的多步預測模型。在最重要的第3步,通過BP神經網絡結合構造相關模型,可以很好地化工產品需求進行預測,方便后續對工廠生產做出及時調整。
2.1 數據獲取
本文使用八爪魚采集器軟件實現了一個針對特定數據的爬蟲。目標數據是某化工企業2018年1月到2019年9月的202 種具體產品的需求訂單作為數據源。
2.2 混沌理論
首先,量子力學中的不確定性原理表明,如果想同時知道一個微觀粒子的動量和位置,是永遠不可能做到的,并且波函數證明了在沒有進行測量的時候,微觀粒子在空間當中的位置是服從概率分布的。舉個例子,就目前來看人們還不能精準的去預測地震和天氣預報,因為天氣預報只能大范圍的,短期的預測不是每次都很準。如果想要精準的預測,比如這片云要下雨,能落到哪一條街、哪個人身上,這肯定是做不到的。這一切的背后有一套理論在做支撐,叫做混沌理論。混沌狀態區別于隨機狀態,這兩種狀態差異化很大。隨機狀態就是純概率的事件,如擲骰子一般。而混沌系統,它雖然有解,但要解開難度極大,并且混沌系統總是在變化之中,它的狀態稍微有一丁點系統內的變化到最后都有可能引起巨大的改變。
總而言之,混沌理論表明一切看似沒有關系離散的事件,在其內部都有一定的聯系。人們肉眼能觀察到的,可能都是一個混沌系統的局部,所以看不到其聯系,可見混沌系統暗含了混沌系統是具有局部隨機整體有序的特點。隨著混沌理論的深入研究,人們可能會解釋或預測出某些事件現象的發展趨勢。
2.3 重構相空間
相空間理論
在數學和物理領域,定義一個動力系統所有可能的狀態空間,并且系統中每一個可能的狀態都與唯一一點相對應。這些點的組合空間稱作相空間,系統的每個變量可以用相空間中的一個維度來表示。動力系統的單個狀態被稱作相空間點的狀態向量。將相空間中的點連接起來,就得到了系統的相空間軌跡,該軌跡反映了動力系統的狀態隨時間演化的過程。
重構相空間方法
一般來說,相空間是高維的。肉眼可見的時間序列往往都是整個動力系統的一維時間序列,稱為單變量混沌時間序列見式(1)。
={:=1,2,…,}
(1)
式中:為時間長度;為第時刻的序列值。
重構相空間的坐標延遲法和導數重構法是由時序序列進行相空間重構得來的。由于導數重構法是需要對數值進行微分,所以該方法對數據的噪聲十分明顯。因此在實際應用中常采用坐標延遲重構法。
假設單變量混沌時間序列為式(1)所示,坐標重構法需要2個重要參數,延遲時間和嵌入維數。將時刻之后每個時刻的序列值插入到當前向量中,直到組成一個維向量,該向量就為重構相空間的第時刻對應的狀態向量。
=(,+,+2,…,+(-1)),=1,2,…,
(2)
式中:=-(-1),為重構相空間的所有狀態數目。最后得到了重構后的相空間。
=(,,…,)
(3)
(1)自相關法選取延遲時間()。在重構相空間的實際運用中,延遲時間不能過大也不能過小,如果太小,那么重構相空間中的+(-1)與+會十分相近,使得重構相空間中的相鄰狀態向量相關性較強,無法表現出系統的動力特征。同理,如果太大,那么重構相空間的響鈴狀態向量相關性會十分小,使得簡單的軌道看上去也會十分復雜。
實驗中選擇了自相關法來選取延遲時間,對于混沌時間序列,其自相關函數定義:
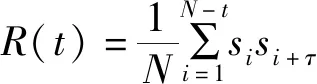
(4)
自相關法規定,當自相關函數的值()下降到初始值(0)的(1-1/e)倍時,所對應的的為合適的延遲時間值,但可以根據具體情形進行調節;
(2)Cao氏法選取嵌入維數()。Cao氏法是對虛假最近鄰法的改進,其優點是只需要參數延遲時間。在重構相空間中,計算每兩對狀態點的歐氏距離,即:
,=|-|
(5)
將與擴展一維之后,再次計算其歐氏距離:

(6)
Cao氏法中,直接用′,與,的比值定義指標:

(7)
距離度量選擇無窮范數,定義:
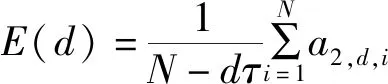
(8)
式中:()的值為總體的虛假近鄰情況,當嵌入維數從變化到+1時,()的變化情況,定義:
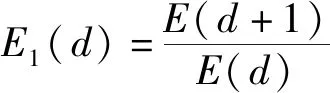
(9)
如果時間序列是具有混沌性的,那么()會在大于某個特定值后將趨于穩定,那么將該值作為嵌入維數是比較合適的。
2.4 BP神經網絡預測模型
單步BP網絡預測模型
單步BP網絡預測模型,如圖2所示。

圖2 單步預測模型Fig.2 Single-step prediction model
由圖2可以看出,依據狀態序列的定義,相空間中最后一個狀態向量為=(,+,+2,…,+(-1)),則對應的下一時刻的狀態向量應為+1=(+1,+1+,…,+1+(-1))。因此,下一時刻的狀態向量中只有最后一個分量+1+(-1)是未知的,這一分量也就是單步預測模型需要預測的下一時刻序列值。故單步預測模型需要在已有時序中預測出下一未來時刻的數據。
多步BP網絡預測模型
多步BP網絡預測模型,結果如圖3所示。
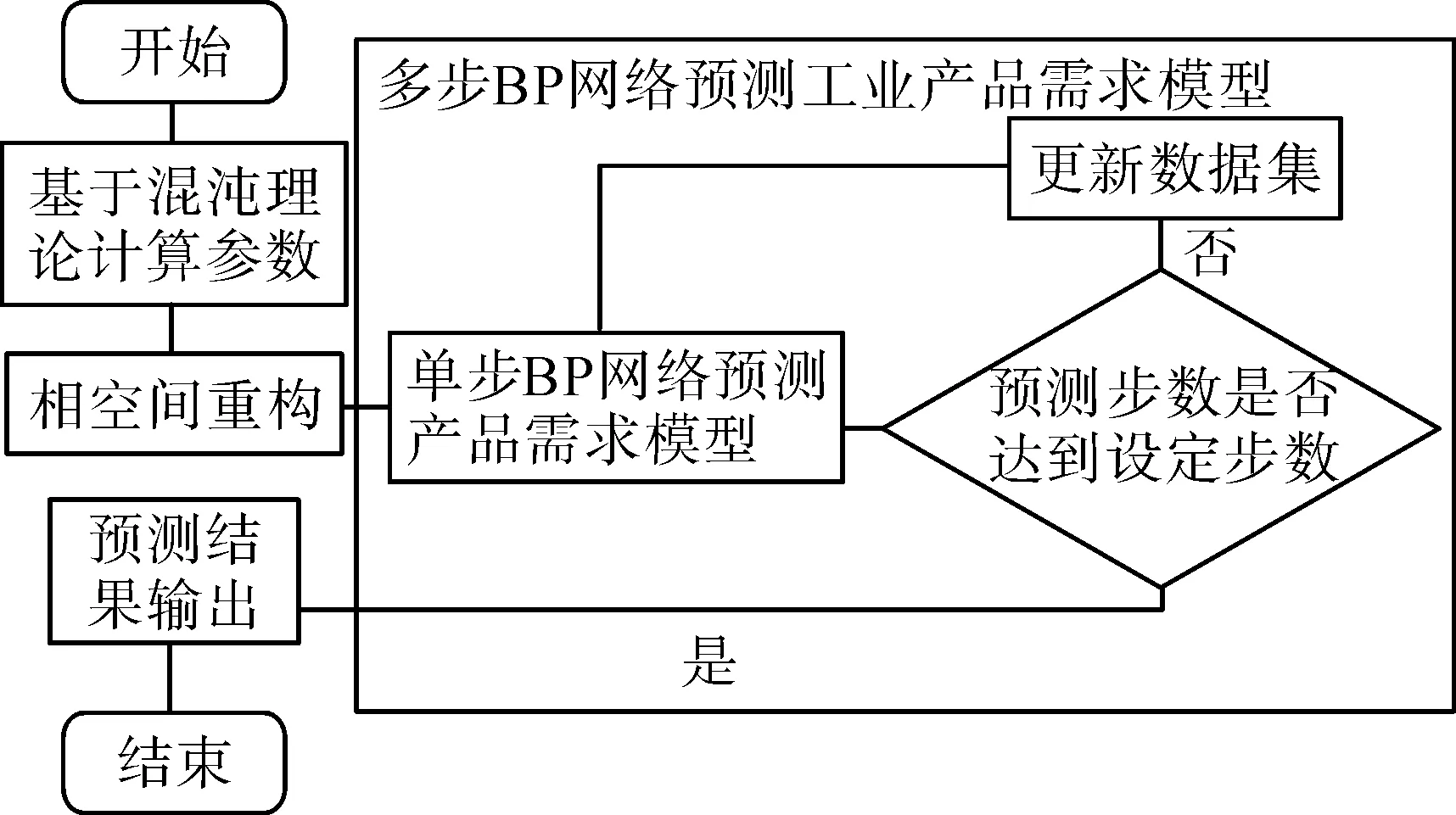
圖3 多步預測模型Fig.3 Multi-step prediction model
由圖3可以看出,多步預測模型是在單步的基礎上,通過更新數據集的方法,實現多步預測的目的。多步預測方法是以預測值作為已知數據更新狀態向量完成的,那么隨著步數的擴大,理論上預測收益率誤差會越來越大,所以該方法只能進行短期預測。
3 實驗研究
3.1 實驗工具
使用八爪魚采集器收集數據,使用Python語言基于Tensorflow2.4.1構建模型。
3.2 數據集及處理
通過自相關法計算自相關函數(),選擇其值約為(0)的(1-1/e)倍的值作為延遲時間,自相關函數隨延遲時間變化情況如圖4所示。
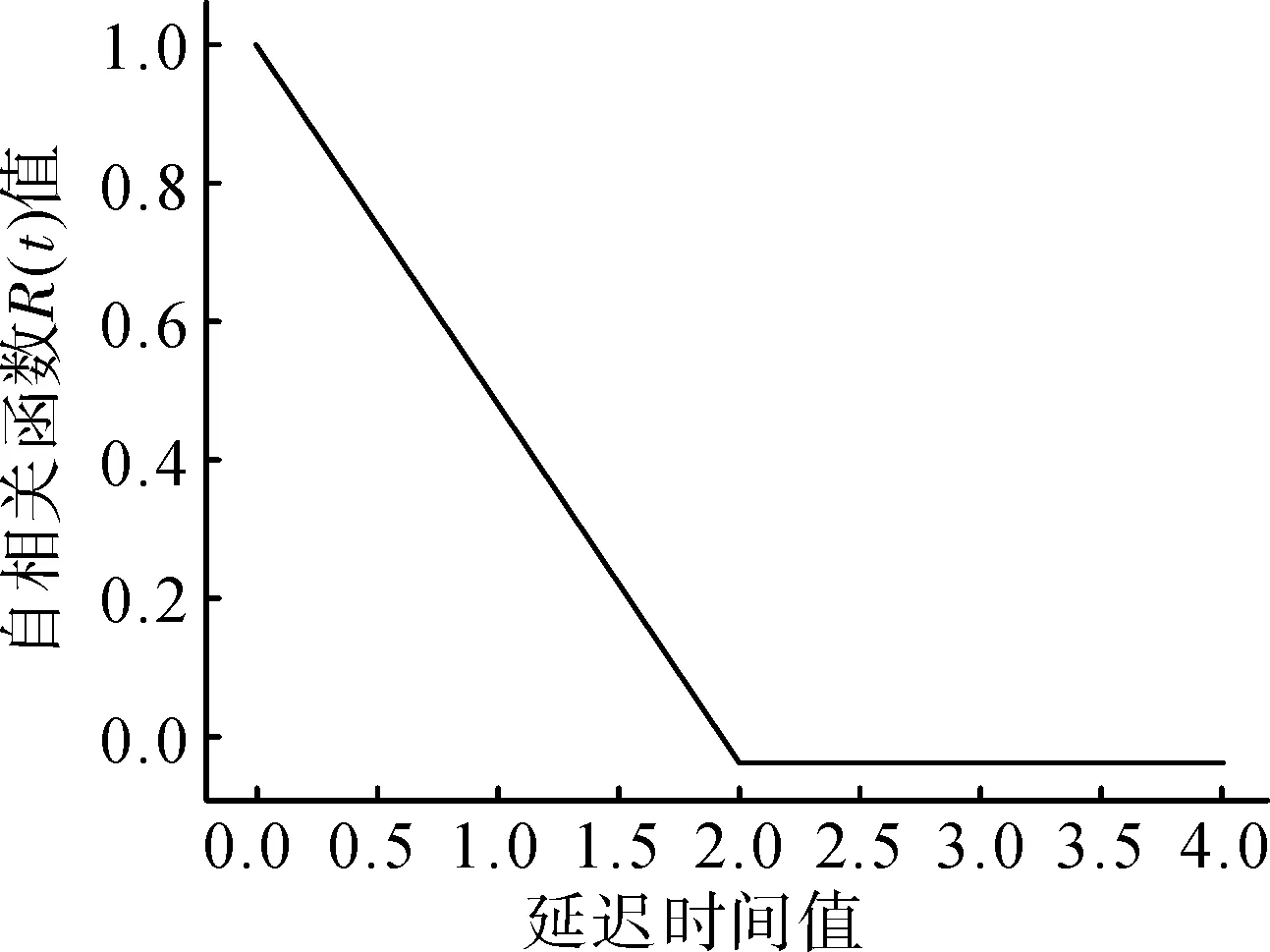
圖4 自相關函數隨延遲時間變化Fig.4 The varies of autocorrelation function with delay time
由圖4可以發現,本次試驗中為1是比較好的延遲時間。
使用Cao氏法計算時序的總體虛假鄰近值(),再根據時序相鄰點的鄰近值比值()選擇合適的嵌入維數;總體虛假鄰近情況隨嵌入維數變化情況,結果如圖5所示。
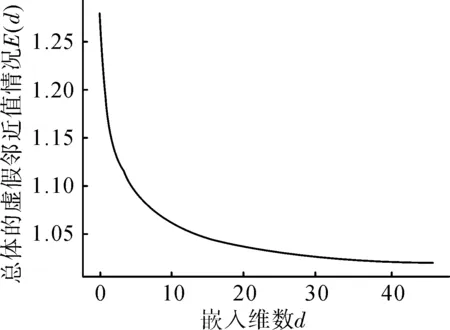
圖5 總體虛假鄰近情況隨嵌入維數變化Fig.5 The varies of overall false proximity with embedding dimension
由圖5可以看出,當延遲時間為1時,最佳嵌入維數為10。
3.3 化工產品需求預測實驗
模型參數設置
數據集輸入為時序序列構成的相空間,由“3.2”節得出,相空間的延遲時間為1,嵌入維數為10,狀態向量一共有411個。選取某化工企業2018年1月到2019年9月的202 種具體產品的需求訂單時序作為訓練集,即選用相空間中前406個狀態向量。BP神經網絡模型學習率為0.01,激活函數選擇tanh函數。通過實驗對比,選擇2層隱藏層每層選擇15個神經元。反向損失函數選擇均方誤差,反向傳播優化方法使用AdamOptimizer優化器。
模型訓練與評估
根據“3.3.1”節的實驗設計,評價指標有預測精度、相對誤差和均方誤差。實驗結果表明,模型在未來兩天的平均預測精度為90.87%,平均相對誤差為9.13%,最小相對誤差為1.19%,均方誤差為0.001 5。雖然模型在未來兩天后的預測精度不高,但依然具有預測趨勢的價值。在預測實驗中,預測模型平均預測精度大于90%,則說明模型預測效果良好。預測結果見圖6。
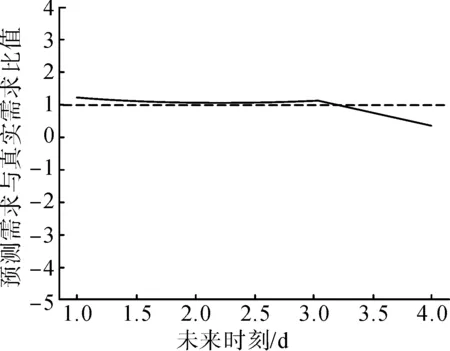
圖6 模型預測結果Fig.6 Results of model prediction
4 結語
本文基于混沌理論和4層BP神經網絡進行化工產品需求預測。使用自相關法和Cao氏法來確定相空間參數,重構其相空間;通過實驗確定BP神經網絡隱藏層結點個數分別為15個時,預測精度較高。該預測模型在未來2 d的平均預測精度為90.87%,最高預測精度可達98.81%,平均相對誤差為9.13%,最小相對誤差為1.19%,均方誤差為0.001 5,并且在第3 d和第4 d能夠預測出其發展趨勢。故該模型能夠為工廠供需關系提供參考,具有現實使用意義。同時,該方法還有優化的空間,本方法只能預測短期時序,具有一定的局限性。未來可以在數據集上加入多個屬性,使得重構后的相空間內容更加豐富,進而降低多步預測的誤差,使得預測模型具有更高的可擴展性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
