車載遙感高速公路廣告影像的文本信息次過濾算法剔除了提取研究與應用
2022-08-18 08:53:10朱建偉李朝奎黃云濤王佳欣鐘森
遙感信息 2022年2期
朱建偉,李朝奎,黃云濤,王佳欣,鐘森
(1.湖南科技大學 地理空間信息技術國家地方聯合工程實驗室,湖南 湘潭 411201;2.湖南科技大學 測繪遙感信息工程湖南省重點實驗室,湖南 湘潭 411201;3.北京航天自動控制研究所,北京 100085)
0 引言
截至2021年四月,我國高速公路總里程已達160 000 km,高速公路廣告牌沿線設立,普通路段設立間隔約1 km,高速收費站、線路密集區域以及城市周圍則更為密集。單塊廣告牌造價(以常見雙面廣告牌為例)為8萬至12萬元,租賃費用則因地段因素差異較大。全國各省高速沿線廣告管理政策逐步完善,例如2014年湖南省人民政府辦公廳印發了《湖南省高速公路沿線廣告專項整治工作方案》。現階段高速公路的廣告牌管理主要采用沿線驅車,對高速沿線廣告牌逐一下車檢查的方式。現行方式不僅信息反饋遲緩、成本高昂,且作業人員存在安全隱患,因此,建立一個實現自動巡檢和信息管理的高速公路廣告牌智能管理系統已經成為當下迫切的需求。目前,在無人駕駛技術研究熱潮的推動下,車載平臺與遙感技術應用的結合被更加廣泛地鋪開。可以采用車載遙感技術采集高速公路廣告牌影像數據,并基于計算機技術解譯車載遙感獲取的影像數據中包含的文本信息和圖像信息,如空置的廣告牌、破損的廣告牌和非法占用的廣告牌等,實現類似人腦的問題甄別。
車載遙感影像數據隸屬于自然場景圖像,參照目前自然場景文本提取的方法來看,自然場景中的文字由于其相關屬性隨機性較大,相對文檔文本來說更加難于識別和提取。目前國內外諸多學者對自然場景靜態圖像中的文本信息識別與提取技術進行了挖掘。Veit等[1]設計了基于神經網絡的自然場景靜態圖像文本信息識別算法,使用從原始RGB圖像計算得到的復數值邊緣方向圖作為特征,通過訓練神經網絡對文本和非文本的區域進行分類。Frost等[2]提取邊緣部分相對應的主導像素的梯度矢量流(gradient vectorflow,GVF)鑒定方法,將Sobel邊緣圖作為候選文本區域。這些方法主要針對提取英文文本。肖珂等[3]提出一種ISODATA聚類和支持向量機結合的自然場景靜態圖像文本識別方法,該方法對中文字符的提取是魯棒的;楊宏志等[4]設計了基于改進Faster R-CNN的自然場景文本檢測算法,但上述方法對本文應用需求中文本提取效果均較差。參考現有的文字提取方法,依托廣告牌數據特性,本文提出了一種融合高精度MSER獲取與基于像素點的筆畫寬度變換字符識別優化算法,為實現高速公路廣告牌智能化管理提供了一種原創性的技術支持。
1 研究方法
首先,對無人機數據進行MSER(最大穩定極值區域)檢測得到所有可能包含文本信息的MSER區域;然后,根據廣告文本特征對MSER區域進行篩選,得到高精度MSER包圍盒;接著,利用MSER包圍盒進行基于像素點的SWT文字檢測,得到文本檢測結果;最后,以經典的圖像增強方法對結果進行降噪和整飾,得到影像中的文本信息,本文算法流程如圖1所示。
1.1 高精度的MSER圖像分割與篩選
1)MSER區域檢測。以車載遙感影像數據來建立候選文本區域的問題在于,如何在類文本區域冗雜和廣告牌文本信息形式多樣的條件下檢測出有效的文本區域。結合車載遙感廣告牌數據與當下主流區域檢測器各自的特點,本文選擇了MSER(最大穩定極值區域)方法用于無人機數據的文本區域檢測。該方法具備穩定性良好、可同時檢測不同精細程度的區域,并且對灰度圖像仿射變化具有不變性的優勢。
MSER檢測首先對影像數據進行灰度轉化處理,再將其各個像素量化,設立量化灰度級數為G=256,灰度取值范圍為0~255。對量化后的圖像二值化,生成二值圖像。在預設的灰度取值范圍內,生成的灰度圖像閾值每發生一次改變都會生成一幅與之對應的二值圖。當閾值取極小時圖像為全白,當閾值取極大時圖像為全黑,如圖2所示。在閾值不斷由極小向極大變化的過程中,會存在著一些與其周圍的灰度變化相比較變化非常小的連通域,這些連通域便是初步檢測到的MSER,即初步的文本候選區域。該方法提取的MSER,背景對比度較大,自身的灰度值較為穩定,并且該區域在梯度閾值變化下灰度值保持得較好。由于靜態場景圖像中,同等灰度變化條件下文字區域背景波動較強,而文字區域則在灰度變化時較穩定,因而應用該算法能夠提取常規方法例如顏色聚類等不能提取的一些連通域。

圖2 梯度閾值下的MSER
2)文本特征分析。本文結合最大穩定極值區域的提取結果和原始數據中的文本特征,制定了一些針對性較強的先驗知識,以此為約束條件過濾類文本區域,可以提高MSER的獲取精度。
(1)基于字符長短軸長度比的約束條件。中文字符的構成以筆畫為基礎,字符的構成特征鮮明,又被稱為方塊字。結合此特點,以字符中心為原點,穿過原點到達字符邊界的橫軸和縱軸比例是被約束在一定范圍內的。經過大量統計,可見MSER區域中兩軸比例(該比例不區分橫縱軸先后順序)大于4∶1的區域為類文本區域,不存在中文字符。除此之外,一些特殊結構的字符不能滿足先前的約束條件,如“1”和“一”等。經過研究發現,“1”和“一”等結構的擬合橢圓較易獲取且方向都靠近豎直或水平,當擬合橢圓長短軸大于8∶1時,候選區域不存在中文字符。
(2)基于字符孔洞數的約束條件。候選區域中的單個中文字符孔洞數目容易把控。候選區域中的單個字符的孔洞數目通常不會過多。對無人機高速公路廣告牌數據進行統計發現,區域內單個字符的孔洞數目最多不超過五個。
(3)基于字符占空比的約束條件。中文字符的構成區別于英文的構成方式,由筆畫“堆積”而成,所以字符本身的像素面積與其擬合橢圓面積的比例是約束在一定范圍內的,即占空比。由于字符偏旁部首的像素都散布松散,因此候選文本的擬合橢圓面積往往比候選的文本區域包圍盒大。實驗表明,候選文本區域中字符占空比小于0.15且大于0.8的文本包圍盒不存在中文字符。
3) MSER二次過濾。高速公路廣告牌數據中可識別出大量MSER,而其中還包含部分的類文本區域,如部分欄桿、廣告牌邊緣和鐵架等區域,如圖3、圖4所示。為保證提取進度,濾除類文本區域是必要的一步。

圖3 包含文本信息的MSER

圖4 類文本區域
MSER是目前檢測器中性能最優越的一種。但是其對模糊的高度敏感也使得它的應用產生了明顯的弊端。本實驗中高速公路廣告牌影像受光線變換、圖像迷糊和航拍姿態角度等因素的影響,將提取出的MSER直接納入文字算法檢測,不僅加大了計算量,而且大大降低了精度。
針對上述問題,對結果進行過濾:①濾除長短軸長度比大于8∶1的候選區域;②濾除孔洞數目大于5的候選區域;③濾除占空比小于0.2而大于0.85的候選區域。實驗結果表明,通過該方法,可以過濾一定數目為包含文本信息的MSER包圍盒。
1.2 SWT文字檢測
筆劃寬度變換(stroke width transform,SWT)字符識別算法是基于文字邊緣像素的向量字符識別算法。廣告牌包含的文本信息具有易辨識、邊緣對比度大等特性。針對該特點,本文對原有的SWT算法進行了優化,具體步驟如下。
步驟1:初始化SWT[5]圖像。
步驟2:計算原圖像的Canny邊緣和梯度方向。Canny能夠準確地識別圖像的實際邊緣并且還具備響應最小的優勢,故選用Canny檢測算子對MSER中的字符像素區域進行邊緣檢測,并生成邊緣圖。Sobel算子計算MSER中各字符實際邊緣的梯度,并在邊緣精細定位的基礎上生成梯度方向圖。將二者結合便得到了筆畫寬度變換。
邊緣檢測保障精度的前提是圖像噪聲需控制在合理范圍。采用高斯濾波可以保證原圖像的邊緣走向不變,且能較好地保留特征點及邊緣特性。字符筆畫的兩邊是否具有相反方向的Canny邊緣檢測點很大程度上決定了實驗結果的精度。字符邊界灰度值的變化是包含大小和方向的向量,用梯度表示。使用點與Sobel算子相乘等方式得到不同的梯度向量。
步驟3:濾除非邊緣點。字符邊緣在通過高斯濾波后部分邊緣的像素點存在被放大的問題,需要通過某種約束來濾除高斯濾波后才出現的非邊緣點,使邊緣盡可能平滑。某個像素點的位置處于圖像的實際邊緣上,則該邊緣像素點的梯度向量值應該是最大的,否則濾除該非最大值。具體方法為通過設置上下閾值提高邊緣檢測精度,只用單閾值檢測邊緣的精度并不是很理想。這里采用啟發式的方法便可以得到一個上閾值和一個下閾值,而處于下閾值之下的一定為非邊緣像素。首先選用兩個指標閾值,設置為上閾值(maxT)和下閾值(minT)。檢測過程中大于maxT的即判定為邊緣像素,低于minT的被判定為非邊緣,而位于上閾值和下閾值中間的部分看其是否與已確定的邊緣像素為鄰接關系,若與邊緣像素為鄰接關系的判斷為邊緣。
步驟4:邊緣檢測完成并生成邊緣的梯度方向圖后,沿邊緣尋找方向相反的一對梯度點,并且以兩梯度點間的像素數量作為其寬度大小為這對方向相反的梯度點賦值。求出所有一一對應的邊緣點,并將其相連后輸出,得到一幅由筆畫寬度組成的與原字符方向和大小一致的輸出圖,如圖5所示。

圖5 筆畫寬度計算
步驟5:二次過濾,得到SWT Map。
1.3 圖像增強
得到SWT Map以后,結果中字符的邊界存在模糊、裂隙、尖刺和小橋等問題。利用圖像增強的方法進行降噪處理,即進行開運算和閉運算處理,二者均可在保持原圖像面積不變或細微改動的基礎上處理SWT MAP中的邊界噪聲。
2 實驗及分析
本文以湖南省湘潭市長潭西高速公路勘測項目為依托。研究區域位于湖南省長株潭城市群長潭西高速路段,長度約24 km,沿線兩側廣告牌總計58個。
全部實驗及數據采集均在相同條件下進行。實驗平臺為惠普筆記本電腦Envy15,CPU為Intel core i5處理器。實驗開發工具為MATLAB2016a。車載相機型DSC-RX1RM2,像素為4 020萬,焦距為35 mm。
根據實際情況和實驗數據特點等條件,隨機抽取部分數據并對提取的實際結果進行前后對比。影像中由人工目視數得的字符數量為實際字符數,記為T,由本文算法識別并提取出的字符數量為算法提取數,記為E,如表1所示。

表1 算法提取結果對比
目前該領域內普遍采用國際會議ICDAR所提出對于場景文本提取算法優劣的評價模型。該模型包含召回率(r)和準確率(ρ)兩個評價因子。其中,召回率針對的是車載遙感影像數據中原有的文本連通域,準確率則表示預測的提取結果中符合要求的正樣本有多少,表達如式(1)、式(2)所示。
(1)
(2)
式中:C表示E和T的交集。為了更加直觀地評估該算法,通過式(3)所示的方法計算其綜合性能。
(3)
式中:f表示綜合性能,上限為1,越逼近極限則表示算法性能越好;α為準確率和召回率的權重因子。本文算法結果與其他方法的性能比較如表2所示。
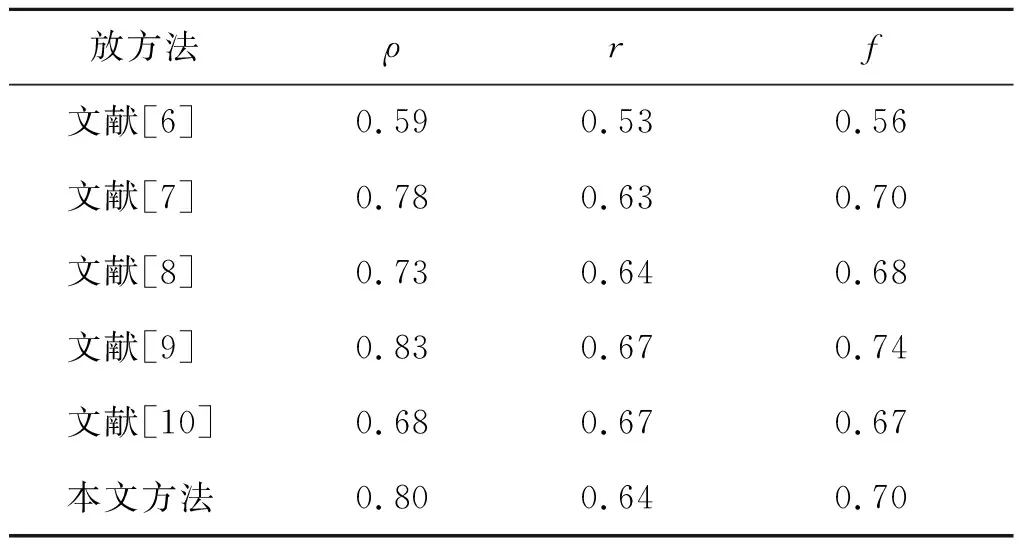
表2 六種自然場景文本提取方法性能比較
實驗結果表明,本文基于車載遙感數據的文本識別方法是魯棒的,該方法對廣告牌問題甄別提供了有力支持。其中,文本信息提取結果為0的廣告牌為空置廣告牌;文本信息提取結果中字符數量未達要求的廣告牌為破損、污損、褶皺廣告牌;文本提取內容存在非原廣告牌字跡的為非法廣告牌等。選取部分較為具有代表性的實驗結果如圖6所示。

圖6 算法實驗結果展示
3 結束語
本文設計的MSER檢測與二次過濾算法剔除了大量類文本信息的干擾,減少了計算量,且對于車載遙感廣告牌數據中包含多樣性的文本區域識別表現是魯棒和高效的。本文落足當下高速公路廣告牌巡檢中的應用需求,以車載遙感廣告牌影像數據為研究對象,將現有自然場景文本算法針對車載遙感數據的特點進行了改進和優化,實現了車載遙感廣告牌數據中文本信息的高精度提取,為智能廣告牌巡檢中的自動化問題甄別提供了新的技術支持。
首次提出了一種車載遙感高速公路廣告牌影像文本信息提取算法,并成功應用于高速公路廣告牌巡檢中,解決了現有方法效率低、危險性較高等難題。該技術支持了實現建立完善的智能化高速公路廣告牌巡檢管理系統,同時一定程度上解決了當下自然場景文本信息識別與提取方法只對英文文本信息的提取較為成熟的問題,克服了既有方法對該應用需求中文本提取效果欠佳的問題。研究結論如下。
1)以長潭西高速路段為實驗載體,驗證了車載遙感高速公路廣告牌巡檢的應用前景。
2)提出的廣告牌文本信息提取方法的精度足以滿足搭建計算機高速公路廣告牌智能巡檢管理系統的需求。
本文局限性在于該方法對極少數包含藝術字、手寫體等較復雜情況下的廣告牌文本識別效果欠佳,后續將作為研究重點。廣告牌中的圖像信息的檢測與提取也是進一步研究的重點,是開發廣告牌智能巡檢管理系統的重要組成部分。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
小學教學參考(2015年20期)2016-01-15 08:44:38
電測與儀表(2015年5期)2015-04-09 11:30:52
