從中外專利客體保護水平差異淺談大數據領域客體審查規則調整①
2022-08-11 03:36:50趙小寧
專利代理 2022年2期
劉 佳 趙小寧
一、引言
隨著人類社會步入數據驅動的數字經濟時代,數據要素進一步提升了全要素生產率。相應地,數據量呈指數級增長,以數據服務為主要業務的企業所處理的數據量可達PB 級,而全球每年所產生的數據量更是達到驚人的ZB 級②2021 大數據獨角獸企業排行榜,互聯網周刊,2021 年8 月5 日。。目前,大數據相關專利申請呈快速上漲趨勢。現行《專利審查指南》(以下簡稱“指南”)中第九章第6 節雖然圍繞人工智能、互聯網+、大數據以及區塊鏈等新領域新業態相關發明專利申請做出規定,但其中并未提供大數據領域有強針對性的審查基準和審查示例,審查員在該領域的審查實踐中依然存在很多困惑,審查標準執行不一致的情形時有發生。同時,創新主體對完善大數據領域專利審查規則的需求非常迫切。
從指導案例和審查實踐來看,大數據各個技術分支上歐、美、日、韓四局和中國國家知識產權局的客體保護水平有所差異,如何從典型案例中厘清不同技術分支上的客體保護水平的差異程度,以及據此給出操作性較強的客體審查規則的調整建議是亟待解決的問題。本文從歐、美、日、韓四局與中國國家知識產權局在大數據領域專利客體保護水平上的差異分析入手,基于大數據領域關鍵技術分支的典型案例分析,結合國內創新主體需求,嘗試提出大數據領域客體審查規則的調整建議。
二、歐、美、日、韓四局與中國國家知識產權局在大數據領域專利客體保護水平上的差異
(一)歐、美、日、韓四局審查規則要點
歐、美、日、韓四局審查指南中均未設置針對大數據領域審查的章節,基于其軟件相關客體審查標準與指導案例,四局在大數據領域審查標準要點如下。
1.EPO 審查規則要點
區分基于分類、聚類、回歸和降維的計算模型和算法與計算模型以及算法在各種技術領域的具體應用和技術實施之間的區別,根據計算模型和算法是否涉及技術應用、技術實施,并用于技術目的來判斷是否屬于保護客體。
2.USPTO 審查規則要點
純粹的收集信息和分析收集到的信息都是抽象構思,在收集分析信息的基礎上,要增加特定的技術手段來解釋如何應用分析后的信息并產生有益的技術效果,才符合專利客體適格性要求。對于利用計算機系統運行神經網絡模型的方案,由于未引述司法例外,符合專利客體適格性要求。
3.JPO、KIPO 審查規則要點
KIPO 的專利法與審查指南早期從JPO 照搬,兩者客體判斷思路大致相同,都需判斷是否為“利用了自然規律的技術構思”,以及是否為“軟件的信息處理被具體地通過硬件資源實現”。另外,與USPTO 類似,兩局認為限定了數據采集分析而未明確采集分析目的的方案不屬于專利保護客體。
(二)大數據領域IP5 客體保護水平對比
IP5 中,EPO 的審查標準最為嚴格,從審查實踐來看,USPTO、JPO、KIPO 審查標準大致相當。圖1從數據采集、關聯分析等八個維度對USPTO、JPO、KIPO 的客體保護水平進行了比較。
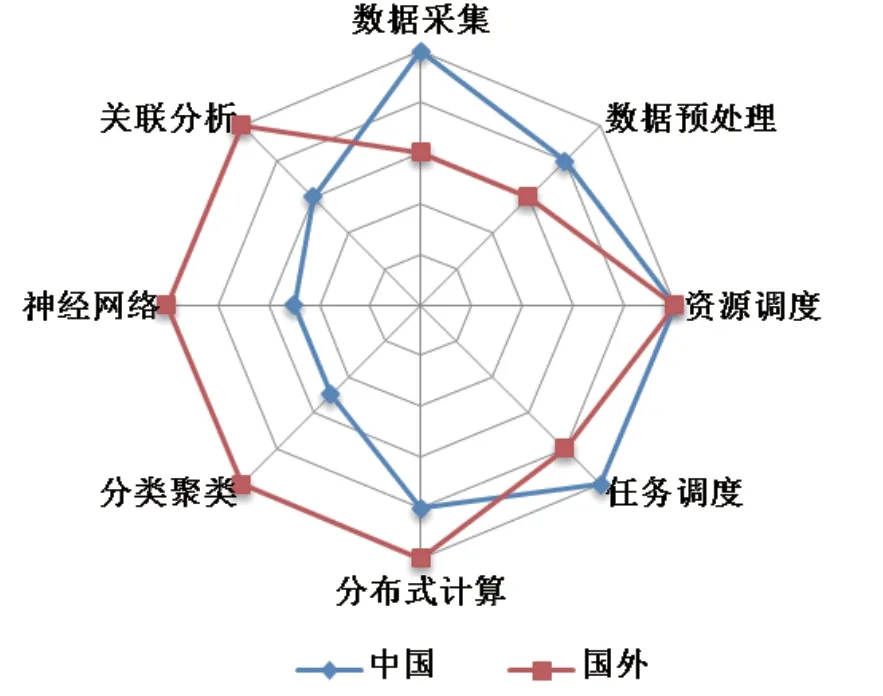
圖1 國家知識產權局與美、日、韓在大數據領域的客體保護水平對比
中國國家知識產權局與USPTO、JPO、KIPO 相比,涉及數據采集、數據預處理的方案客體審查標準相對寬松;但是,國內創新主體對進一步放寬數據預處理的審查標準仍有訴求。國家知識產權局對涉及分類聚類、神經網絡等通用分析算法以及用戶協同過濾、知識圖譜、社交網絡等特定關聯分析算法或模型的方案客體審查標準比USPTO 要嚴格得多,不利于基礎算法技術創新。
三、大數據領域關鍵技術分支的典型案例分析
(一)涉及數據采集、數據預處理以及任務調度的典型案例
USPTO 指導性案例第40 號、第42 號分別涉及數據采集與數據預處理。在這兩個分支上,USPTO的客體審查標準比中國國家知識產權局嚴格得多。另外,從美局審查實踐來看,在任務調度這個分支上,也比中國國家知識產權局的客體審查標準嚴格。具體案例如下:
1.USPTO 指導性案例第40 號③https://www.uspto.gov/sites/default/files/documents/101_examples_37to42_20190107.pdf(2021 年8 月1 日最后訪問)。
該方案請求保護一種通過網絡中計算設備之間連接的網絡設備來自適應監視流量數據的方法,包括:通過所述網絡設備,收集與通過所述網絡設備的網絡流量相關的流量數據,所述流量數據包含網絡延遲、數據包丟失或抖動中的至少一者;通過所述網絡設備,將收集到的所述流量數據中的所述至少一者與預定義的閾值進行比較。
USPTO 認為,其他要素沒有將該申請中抽象概念“將收集到的所述流量數據中的至少一者與預定義的閾值進行比較”轉化成實際應用。其他要素有兩個:通過所述網絡設備,收集與通過所述網絡設備的網絡流量相關的流量數據,其中所述流量數據包含網絡延遲、數據包丟失或抖動中的至少一者;通過所述網絡設備實現比較步驟。但是,這些其他要素僅僅收集數據卻沒有根據收集到的數據提供一種特定的技術手段去解決特定的技術難題,相當于僅僅將該抽象構思應用于公知的計算機設備。因此,該方案不具備專利客體適格性。
2.USPTO 指導性案例第42 號④同注釋③
該方案請求保護一種方法,包括:以標準格式將患者病情的信息儲存在多個基于網絡的非臨時儲存裝置中,該儲存裝置存有醫療記錄集;通過網絡向用戶提供遠程訪問,以便任何一個用戶都可以通過圖形用戶界面實時更新在該醫療記錄集中的有關該患者病情的信息,其中該用戶以取決于該用戶使用的硬件和軟件平臺的非標準格式來提供更新后的信息;和通過內容服務器將該非標準格式的更新后的信息轉換為標準格式。
USPTO 認為,該方案僅僅涉及收集和更新患者信息,相當于將該抽象構思應用于公知的計算機設備,沒有提供特定技術手段。因此,該方案不具備專利客體適格性。
3.關于任務調度的審查實踐案例
一種集群中的任務執行方法,包括:獲取待執行任務;根據所述待執行任務的指定屬性,在預先劃分的各集群資源集合中,確定所述待執行任務對應的集群資源集合;利用確定出的集群資源集合中包含的集群資源,執行所述待執行任務。
USPTO 認為,“根據所述待執行任務的指定屬性,在預先劃分的各集群資源集合中,確定所述待執行任務對應的集群資源集合”即思維過程,“確定”的步驟并不明確執行主體是誰,不排除人來執行上述步驟的可能,從而方案中涉及了思維過程這種司法例外;進一步地,也未將司法例外轉換成實際應用,因此該方案不具備專利客體適格性。
而根據中國國家知識產權局的客體審查標準,上述三個案例均屬于專利保護客體。根據中國國家知識產權局指南,這三個案例均處理的是技術領域中具有確切技術含義的數據,滿足“三要素”的要求,均屬于專利保護客體。
(二)涉及神經網絡等通用數據挖掘分析算法的典型案例
在通用算法分支中,美、日、韓審查標準差異不大,均比中國國家知識產權局審查標準寬松。美局認可在計算機上運行通用算法模型類的方案為專利保護客體,這與中國國家知識產權局審查標準差異較大。以下兩個案例為國內外業界均高度關注的USPTO 授權案例,專利權人為谷歌公司。
1.USPTO 授權案例1
一種計算機實現的方法,包括:獲取多個訓練樣例;和在多個訓練樣例上訓練具有多個層的神經網絡,每個層包括一個或多個特征檢測器,每個特征檢測器具有一組對應的權重,以及特征檢測器的子集在處理每個訓練樣例的過程中被禁用的概率,其中在多個訓練樣例上訓練神經網絡,對于每個訓練樣例分別包括:確定在訓練樣例的處理期間要禁用的一個或多個特征檢測器,包括基于與特征檢測器相關聯的相應概率來確定是否禁用子集中的每個特征檢測器,根據所述確定禁用一個或多個特征檢測器,以及使用神經網絡處理訓練樣例,并禁用一個或多個特征檢測器,以生成訓練樣例的預測輸出。
2.USPTO 授權案例2
一種由一個或多個計算機執行的方法,該方法包括:接收包括多個特征的輸入,其中每個特征具有不同的特征類型;使用第一個機器學習模型處理輸入以生成輸入的第一個替代表征,其中第一個機器學習模型是具有單層線性計算的線性模型;使用深度網絡處理所述輸入,以生成所述輸入的第二個替代表征,此處的深度神經網絡是由多級非線性運算組成的第二個機器學習模型;使用logistic 回歸分類器處理輸入的第一個替代表征和第二個替代表征,以預測輸入的標簽。
3.USPTO 授權案例分析
USPTO 認為,上述授權案例的權利要求并未引述司法例外,其未引述任何數學關系、公式或計算,也沒有引述思維過程,且沒有引述任何組織人類活動的方法,因此,在step 2A 的第一階段就可以直接認定上述權利要求具備專利客體適格性,從而無需進行后續步驟的判斷。
另外,按照日本和韓國的審查標準,雖然當前權利要求可能不屬于專利保護客體,但是仍然可以通過修改的方式克服專利保護客體的缺陷。例如,在權利要求中限定方法的各步驟由計算機硬件部件執行,從而體現出該方法由計算機硬件具體實現。
然而,根據中國國家知識產權局的審查標準,上述兩個案例在本質上都是使用計算機來執行通用算法的改進,計算機在整個方案中只是起到了執行載體的作用,整體方案未解決技術問題,未采用技術手段,未獲得技術效果,不屬于專利保護客體。根據2021年指南修改征求意見稿,上述案例也不是目前擬“定向放開”的情形,方案中涉及的算法沒有與計算機系統的內部結構存在特定技術關聯,不能解決如何提升硬件運算效率或執行效果的技術問題。
(三)涉及用戶協同過濾、知識圖譜等特定數據挖掘分析算法的典型案例
涉及用戶協同過濾、知識圖譜等特定數據挖掘分析算法的,中國國家知識產權局審查標準相比于美、日、韓也更加嚴格。典型案例如下:
1.用戶協調過濾算法相關案例
一種基于隨機森林修正的大數據下改進協同過濾推薦方法:提取用戶對每個物品的評分;建立當前用戶特征向量集合,利用特征向量集合,為用戶構造用戶喜好隨機森林分類模型;計算用戶間相似度,尋找用戶的k 個最近鄰;計算改進協同過濾算法預測評分得到初步推薦列表,使用隨機森林分類模型以對初步推薦列表分類,結合兩種方法進行修正得到最終推薦列表。
2.知識圖譜、社區網絡相關案例
一種挖掘知識圖譜的方法:根據社區用戶的社區原始數據、所述社區用戶的用戶屬性、所述社區用戶屬于的主題論壇或所述社區用戶屬于的即時通信工作的聊天群,對所述社區用戶進行聚類并形成社區用戶圈子,所述社區原始數據包括所述社區用戶對其他社區用戶的關注度信息和所述社區用戶與所述其他社區用戶共同關注的話題個數;根據所述社區用戶圈子包括的社區用戶產生的用戶行為數據,創建所述社區用戶圈子的知識圖譜。
3.相關案例分析
從審查實踐來看,美、日、韓對于上述兩個案例類型通常不會質疑其客體問題,但中國國家知識產權局審查員對這類案例的觀點存在較大分歧。對于協同過濾的案例,一種觀點認為,權利要求中雖然提及了“獲取電子商務網站的記錄”以及“提取用戶對每個物品的評分”,但其所解決的問題僅僅是協同過濾算法本身存在的問題,所要解決的問題、實現的效果仍然是優化算法方面的,而非技術方面的。對于涉及知識圖譜、社區網絡的案例,一種觀點認為,該方法解決的問題為如何表達用戶關系的精細度,并非技術問題,構建知識圖譜所依據的社區用戶之間的關聯關系也不符合自然規律。根據上述觀點,這兩類案例并不屬于專利保護客體。
四、大數據領域客體審查規則調整
基于前述中外專利客體保護水平差異以及國內創新主體的需求,我們建議對中國國家知識產權局大數據領域客體審查規則進行調整。
(一)關于數據預處理的客體審查規則建議
雖然當前中國國家知識產權局對于數據預處理分支的申請的客體判斷標準比美局寬松,但是數據預處理與提升數據質量有直接關系,國內創新主體(例如京東集團等)對于進一步放開數據預處理客體審查標準仍有較強的訴求。因此,對于涉及利用具體的數據預處理手段來解決大數據的數據記錄的完整性、一致性、唯一性、有效性、準確性等技術問題,并獲得相應的技術效果的方案,建議將其認定為屬于專利保護客體。但是,需要注意區分相關方案是純粹的數據預處理算法還是大數據的數據記錄處理方案。例如:方案“一種基于數據預先補全方法,包括:對輸入的不完備數據矩陣求出其對應的正交映射算子來表示數據矩陣的對應項不為空的位置的集合;定義矩陣的Schatten Capped p 范數;求解最優化問題,直至收斂,輸出補全的數據矩陣”是純粹的數據預處理算法,而方案“一種數據預處理方法,包括:將待處理數據記錄集分解到可以表達所述待處理數據記錄集的至少一個特征上,以獲得特征值;根據特征值及其權重,獲得數據記錄之間的相似度;利用所述相似度,填充所述存在缺失值的數據記錄的缺失值”則是數據記錄的處理方案。純粹的數據預處理算法仍然是不能授予專利權的。
(二)關于通用算法的客體審查規則建議
美局授權的兩件申請對業界的影響較大。雖然谷歌方認為,其提出專利申請的目的主要是為了防止谷歌研究人員的成果被其他機構申請專利后進行訛詐,進而引發經濟損失,并明確表示其不會使用人工智能算法的專利來攻擊其他公司,也不會用這部分專利來獲利,但業界仍認為,專利制度的初衷是通過經濟學手段來促進創新,防止創意被其他公司竊取或復制,但當下的趨勢卻是一些巨型公司利用專利實現技術壟斷,并濫用專利制度所賦予它的權利,因此,應當重新思考算法這類抽象概念的專利申請是否應當被授權⑤量子位.被罵了三年,谷歌Dropout 專利還是生效了,卡脖子預警[EB/OL].(2019-06-27)[2021-09-27].https://mp.weixin.qq.com/s/MZf9RRumKolnxSuerpC3Q.。就中國研發現狀而言,國內企業及科研機構較多的研發精力被放在了算法的應用上,而在基礎算法方面起步較晚,尤其相對美國發展滯后。同時,國內大部分創新主體對于通用算法改進類的專利申請的客體審查規則的需求并不強烈。因此,在通用基礎算法相關申請的客體放開的問題上,建議盡量謹慎對待。
另一方面,國內創新主體對于通用算法應用相關的申請,希望客體審查標準能進一步放開。例如,有些涉及通用算法應用的方案,其可在多領域應用,而并不局限于具體的某個領域。對這類申請,中國國家知識產權局目前的審查標準過于嚴格。即便是根據2021 年指南修改征求意見稿,國內創新主體的訴求也難以滿足。
(三)關于用戶協同過濾、知識圖譜、社區網絡等特定算法或模型的客體審查規則建議
用戶協同過濾、知識圖譜、社區網絡等特定算法或模型通常是用于解決特定場景下的特定問題,自身能體現用戶間、信息內容間或用戶與信息內容間的語義關系與其他關聯關系。這類算法或模型與分類聚類、神經網絡等抽象程度高的通用算法在技術本質上有一定區別。在調整客體審查規則時,應當關注特定算法與通用算法的差異。另外,這類申請通常與圖計算相關。圖計算也是大數據領域的重點發展方向之一,從國內申請量變化來看,與社區網絡、知識圖譜相關的專利申請量逐年增加。對于基于互聯網用戶之間關聯關系以及基于用戶與互聯網信息內容之間關聯關系、信息內容之間的關聯關系而進行數據處理的方案,提供數據服務行業的創新主體對其保護訴求強烈。適當放開關于該領域專利申請的客體審查標準,有利于鼓勵該領域的技術創新,促進技術發展。
五、結語
本文針對大數據領域審查工作中存在的缺少強針對性客體審查規則的問題,對歐、美、日、韓四局審查規則要點進行梳理,并結合七個典型案例從數據采集、數據預處理、任務調度、神經網絡等技術分支上分析了中外客體保護水平差異程度,進而針對數據預處理、通用算法、特定算法三個方面提出客體審查規則的調整建議。
專家點評
本文針對大數據領域審查實踐中的客體保護問題,對比介紹和分析了五局在大數據不同技術分支下的客體保護標準的差異,并結合相關典型案例進行了舉例說明。最后,結合國內創新主體訴求,針對大數據的數據預處理、通用及特定算法提供了具有針對性的客體審查規則調整方案,為大數據領域專利審查規則的不斷完善提供了有價值的參考。
猜你喜歡
少先隊活動(2021年2期)2021-03-29 05:40:48
中學生數理化(高中版.高二數學)(2019年6期)2019-06-24 03:37:50
中國公路(2017年7期)2017-07-24 13:56:38
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中學生數理化(高中版.高二數學)(2016年4期)2016-03-01 03:46:18
中國衛生(2015年4期)2015-11-08 11:16:06
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
