基于Mixer Layer的人臉表情識別①
2022-08-04 09:58:30簡騰飛曹少中楊樹林
計算機系統應用 2022年7期
關鍵詞:模型
簡騰飛,王 佳,曹少中,楊樹林,張 寒
(北京印刷學院 信息工程學院,北京 102600)
人臉表情是反映人類情感最普遍最重要的方式之一,面部表情傳達著人與人之間的社會和情感信息,面部基本表情可分為6 種(快樂,悲傷,驚訝,恐懼,憤怒和厭惡). 隨著人工智能和深度學習的興起,基于深度學習的人臉表情識別得到了廣泛的發展和應用,基于傳統特征提取方法的人臉表情識別,需要大量專業知識來設計提取器,同時傳統方法的泛化能力和魯棒性相對于深度學習的方法略有不足. 神經網絡可以獲得表情圖像中更抽象,更復雜的特征,使識別更加準確.隨著深度學習的發展,基于卷積神經網絡的人臉表情識別,取得了巨大的進步.
Shi 等[1]基于ResNet 提出一種多分支交叉卷積神經網絡(MBCC-CNN)提高了每個感受野的特征提取能力,在CK+數據集上的識別準確率達到了98.48%.Li[2]利用ResNet-101 使用文獻[3]中的數據集識別準確率達到了96.29%±0.78%. 魏赟等[4]提出了一種引入注意力機制的輕量級CNN 通道和卷積自編碼器預訓練通道的雙通道模型,在減少模型參數量的同時也保證了識別準確率. 江大鵬等[5]提出局部二值模式(LBP)圖像的卷積網絡對6 種面部表情識別,通過Viola-Jones 框架提取出面部表情感興趣區域,獲得感興趣區域的LBP 圖像,再輸入到卷積網絡進行識別. 申毫等[6]基于殘差網絡提出一種輕量卷積網絡的多特征融合的人臉表情識別方法,使用改進的倒置殘差網絡為基本單元,搭建輕量級卷積網絡,用11 層的卷積篩選網絡中的淺層特征,該模型的參數量僅有0.2×106,但在RAD-DB 數據集上的識別準確率達到了85.46%. 伊力哈木·亞爾買買提等[7]提出了一種融合局部特征與深度置信網絡(DBN)的人臉面部表情識別算法,融合表情局部敏感質量分布圖(LSH)非均勻光照不變特征和人臉面部表情的邊緣局部細節紋理特征,把融合后特征用于訓練深度置信網絡(DBN)模型,在JAFFE 數據集上達到了97.56% 的識別率. 崔子越等[8]通過改進VGGNet 結合Focal loss 的方法來處理面部表情數據集樣本不均衡,防止網絡過擬合,在數據集 CK+,JAFFE,Fer2013 上相比于傳統的損失函數,模型的準確率提升了1%–2%,模型的分類能力更加均衡. 在保證識別準確率的情況下,張宏麗等[9]通過優化剪枝GoogLeNet識別人臉表情,以達到簡化網絡結構的參數量,提高運行效率,網絡運行時間低于200 ms. Dhankhar[10]組合了ResNet-50 和VGG16 用于人臉表情識別,在數據集KDEF 上取得了較好的效果.
可以看出,對于人臉表情識別的研究方法,目前大多數是基于卷積神經網絡,同時對數據進行了一定預處理. 本文通過搭建無卷積結構的淺層神經網絡對人臉表情進行識別,該模型結構簡單,計算復雜度低.
1 人臉表識別方法
1.1 MLP-Mixer 網絡結構
2021年Google 提出來一種無卷積和注意力機制的網絡MLP-Mixer[11],網絡結構如圖1[11]所示.

圖1 MLP Mixer 網絡結構
圖1 展示了MLP-Mixer 的網絡結構,MLP-Mixer網絡的輸入是一串不重復的圖片塊序列S,把每一個圖片塊映射成指定的維度C,Mixer Layer 的輸入維度為X∈RS×C. 假設輸入的圖片的分辨率為(H,W),每個圖片塊的分辨率為(P,P),則S=(H×W)/P2. Mixer Layer接受一系列的線性投影的圖像塊,且輸入輸出形狀保持為X∈RS×C. Mixer Layer 由兩種MLP (多層感知機)組成: token-mixing (MLP1)和channel-mixing (MLP2).
每個MLP 包含兩個全連接層. channel-mixing 將不同的通道之間聯系起來,token-mixing 尋找圖片上不同空間位置的關系. MLP-Mixer 的整體結構包括Perpatch Fully-connected,Mixer Layer 和Global Average Pooling. Per-patch Fully-connected 將分割的圖片塊映射為指定維度. 網絡包含GELU[12]非線性激活函數,跨越連接和 Layer Normal 等結構. Mixer Layer 可表示為式(1).

其中,σ表示GELU 激活函數,W為感知機權重,?為Layer Normal. 分別用DC和DS表示感知機channelm ixing 和token-mixing 中全連接層的節點個數.
1.2 遷移學習
遷移學習是從源域傳輸信息提高目標域的學習訓練效率,遷移學習的源域和目標域擔任的任務要相同,在深度學習中,遷移學習多用于解決數據量少,訓練樣本不充分這一問題,在圖像識別領域被廣泛運用.
用Mixer Layer 代替CNN ,使用ExpW 數據集預訓練主干網絡,將新的表情樣本輸入到網絡中進行微調. 實驗證明,通過該方法訓練完成的模型具有較好的表情識別效果,具體步驟如圖2 所示.
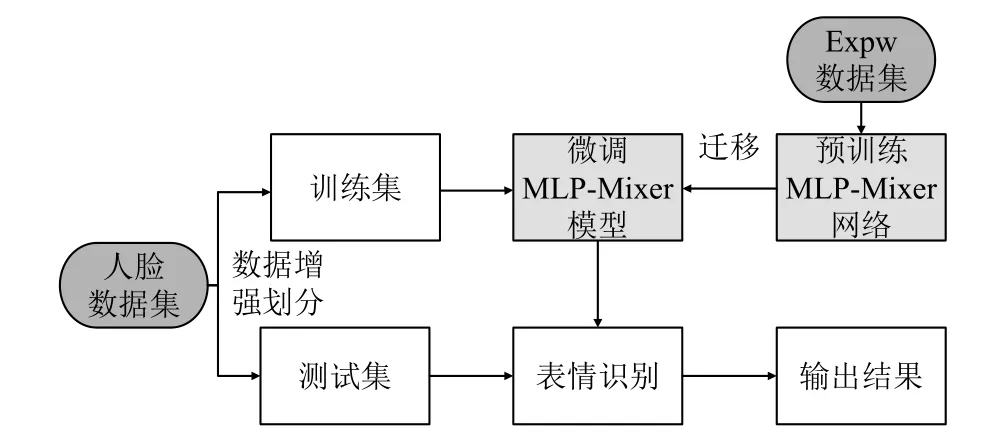
圖2 人臉表情識別方法結構圖
2 實驗過程
實驗運行環境: Windows 10 (64 位)操作系統,Intel(R)Xeon(R)Gold 6132 CPU,GPU 為NVIDIA GeForce RTX 2080 Ti 顯存大小為 11 GB,Python 版本為3.7.0.
2.1 人臉表情數據集
為了說明該方法的有效性,采用日本女性面部表情數據集(JAFFE),CK+ (Extended Cohn-Kanada)數據集和Fer2013 數據集進行實驗. 實驗采用的樣本數量分布如表1 所示.

表1 CK+、JAFFE、Fer2013 數據集實驗樣本選取數量分布表
其中 JAFFE 數據集包含10 位日本女性,每個人做出7 種表情,一共包含213 張大小為256×256 的人臉正面圖像,共分為angry,disgust,fear,happy,sad,surprise,neutral (憤怒,厭惡,恐懼,高興,悲傷,驚訝,自然)7 種標簽. 該數據集的樣本分布均勻,標簽準確,如圖3 所示.

圖3 JAFFE 數據集樣例圖
CK+ 數據集包含123 個對象的327 個被標記的表情圖片序列,包含angry,disgust,fear,happy,sadness,surprise,contempt (憤怒,厭惡,恐懼,高興,悲傷,驚訝,蔑視)7 種標簽. 每一個圖片序列的最后一幀被提供了表情標簽,所以共有327 個圖像被標記. 該數據集樣本分布較為不均勻,如圖4 所示.

圖4 CK+ 數據集樣例圖
Fer2013 數據集總共有35886 張人臉表情組成,分為angry,disgust,fear,happy,neutral,sad,surprise (憤怒,厭惡,恐懼,高興,自然,悲傷,驚訝)7 種表情,其中包含訓練集28708 張,共有驗證集和私有驗證集各3589張,每張圖片的固定大小為48×48 的灰度圖,該樣本數據分布不均衡且樣本中包含了錯誤樣本,較為混亂,分類難度大,如圖5,圖6 所示.

圖5 Fer2013 數據集樣例圖

圖6 Fer2013 數據集錯誤樣本樣例圖
2.2 數據增強
由表1 可知CK+和JAFFE 數據集樣本數量較少,為了防止網絡過擬合,增加樣本的復雜度,在實驗中使用了數據增強的方法,如圖7 所示.

圖7 數據增強圖
通過數據增強后JAFFE 數據集一共有907 張圖片,CK+數據集一共有4905 張圖片,隨機抽取數據集中80%作為訓練集,其余部分為驗證集. 針對Fer2013數據集的特點,本文實驗剔除了數據集中不包含人臉樣本,并將所有樣本混合,隨機抽取和原測試集樣本同等數量的圖片作為測試集,其余部分為訓練集.
2.3 預訓練
為了防止網絡過擬合,在Fully-connected 后加入了Dropout. 如圖8 所示.
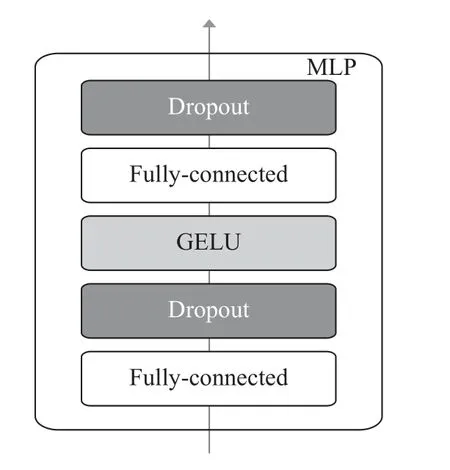
圖8 MLP 網絡結構
Expression in-the-Wild 數據庫 (ExpW)包含使用Google 圖片搜索下載的91793 張面孔. 每個人臉圖像都被手動注釋為7 個基本表情類別之一. 在注釋過程中去除了非人臉圖像. 如圖9 所示.

圖9 ExpW 數據集樣例圖
為保證預訓練模型特征提取的正確性,先從圖片中提取出人臉,再對人臉進行矯正,去除樣本中的錯誤樣本,剩余87305 張圖片,隨機抽取80%作為訓練集,將20%的圖片作為驗證集,驗證模型的有效性. 在預訓練過程中,會將圖像縮放為48×48 大小的灰度圖,使用自適應矩估計(Adam)的策略,設置學習率為0.001,Batch size 為64,Dropout 為0.2,使用交叉熵損失函數和cosine learning rate decay[13]學習率衰減策略,訓練至損失不再下降. Mixer Layer 網絡參數如表2 所示.

表2 Mixer 網絡參數表
為了驗證遷移學習的必要性,使用4 層Mixer 網絡,對遷移前后準確率進行對比,如表3 所示.

表3 數據集遷移學習前后準確率對比 (%)
由表3 可以看出在訓練小樣本數據集時遷移學習的重要性. 通過遷移學習的方法將該模型在JAFFE 數據集上的準確率提升了大約5%,在CK+數據集上的準確率大約提升了1%. 通過遷移學習,能提高模型的識別準確率. 由于Fer2013 數據集樣本豐富,因此該數據集不采取遷移學習策略.
3 實驗設置與結果
使用無卷積的Mixer 網絡結構,通過實驗證明,該網絡同樣具有提取人臉表情特征提取的能力,在人臉表情識別達到了很好的識別效果. 同時,在樣本充足的數據集上訓練過的Mixer Layer 神經網絡模型,再對其結果進行調整和訓練,能夠很好地遷移到其他小樣本的數據集上.
3.1 訓練過程
嘗試了不同層數的Mixer Layer 網絡對3 個數據集識別率的影響. 微調和訓練網絡時,網絡結構參數與表2 保持一致,其余參數如表4 所示. 模型準確率如表5 所示.
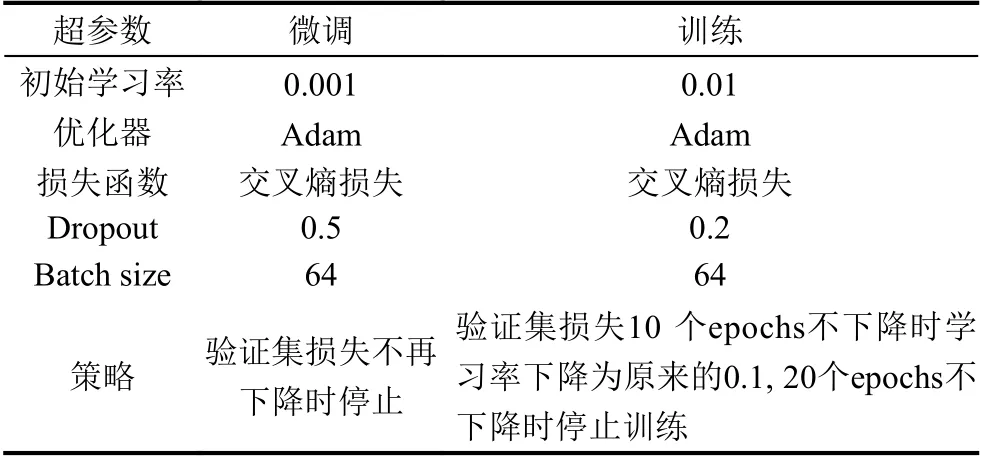
表4 微調和訓練參數表

表5 不同網絡層數準確率
將增強后的目標數據集微調預訓練好的網絡,綜合考慮訓練代價和識別準確率,對數據集CK+,JAFFE 采用含4 層Mixer Layer 網絡. Fer2013 數據集采用含8 層Mixer Layer 網絡. 訓練精度和訓練損失精度如圖10 所示.
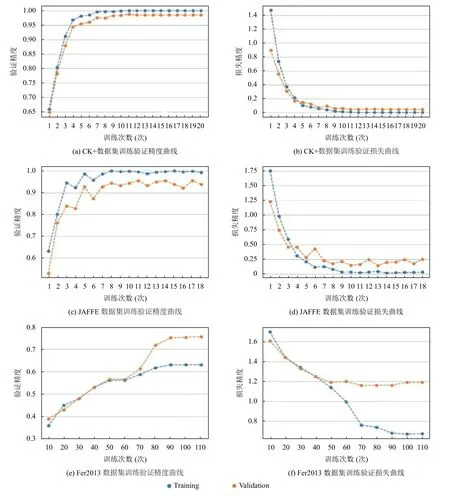
圖10 訓練準確率和損失曲線
從圖中的準確率可以看出,模型收斂快,訓練過程沒有發生過擬合,且在CK+和JAFFE 數據集上表現能力良好,無卷積的Mixer Layer 網絡具有良好的學習能力和泛化能力. 將該方法與國內外優秀的人臉表情識別算法進行對比,在CK+ 數據集上準確率有1%–4%的提升,在JAFFE 數據集上有1%–2%的提升. Fer2013數據集人為識別準確率為(65±5)%,8 層 Mixer Layer模型的識別準確率達到了這一范圍,且準確率有1%–2%的提升. 驗證了Mixer Layer 結構在人臉表情識別上的有效性,對比結果如表6–表8 所示.

表6 不同方法在CK+數據集上識別準確率

表8 不同方法在Fer2013 數據集上識別準確率
為了進一步驗證該算法,根據CK+和JAFFE 數據集上的實驗結果繪制混淆矩陣,其中橫坐標代表真實類別,對角線代表該類樣本預測正確的樣本數,其余為該類樣本預測錯誤類別數,該方法對于數據集CK+和JAFFE 法分類結果均勻,各類表情樣本更傾向于所屬的類別,具有良好的分類表現能力. 如圖11 所示.

圖11 數據集混淆矩陣
4 結論與展望
本文基于Mixer Layer 提出了一種結構簡單的人臉表情識別方法. 針對數據集樣本不足問題,通過遷移學習和數據增強的方法提升了模型的識別準確率和泛化能力. 本文分別在CK+,JAFFE 和Fer2013 數據集上做了對比實驗,最終實驗結果表明,無卷積的Mixer Layer 網絡對人臉表情也有很好的識別性.
雖然基于Mixer Layer 的網絡在人臉表情識別取得了很好的識別效果,但樣本差異大,有錯誤標注的數據集對網絡識別準確率影響依然較大. 后續工作會在本文的基礎上,改進網絡結構,提升模型在復雜環境下的識別準確率.

表7 不同方法在JAFFE 數據集上識別準確率
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
